

Het internet barst van de data—zoveel zelfs dat het de levensader van moderne bedrijven is geworden. Of je nu in sales, e-commerce of vastgoed werkt, of gewoon je concurrenten in de gaten wilt houden: goede data binnen handbereik kan echt het verschil maken. Maar laten we eerlijk zijn: niemand wil urenlang informatie van websites kopiëren en plakken naar spreadsheets. Dáár komt webscraping om de hoek kijken, en geloof me: het is een stuk minder intimiderend dan het klinkt.
In deze gids laat ik je zien hoe je een webscraper maakt—of je nu een beginner bent die wil leren programmeren in Python, of liever de code overslaat en een no-code, AI-gestuurde tool zoals Thunderbit gebruikt. Ik leg de basis uit, laat beide aanpakken stap voor stap zien en help je kiezen welke route het beste bij jouw behoeften past. Klaar om tijd te besparen en de kracht van geautomatiseerde dataverzameling te benutten? Laten we beginnen.
Wat is een webscraper? De basis begrijpen
Een webscraper is simpelweg een tool—software of een dienst—die automatisch informatie van websites haalt. Stel je voor dat je een lijst nodig hebt van alle koffiebars in jouw stad, inclusief adressen en telefoonnummers. Dan kun je urenlang door pagina’s klikken en elk detail handmatig overnemen (hallo, Ctrl+C-vermoeidheid), of je laat een webscraper het zware werk voor je doen.
Zie een webscraper als een digitale assistent die webpagina’s leest, de data vindt die je zoekt (zoals prijzen, productnamen of contactgegevens) en alles netjes ordent in een spreadsheet of database. In plaats van handmatig te schakelen tussen browsertabbladen en Excel, automatiseert de scraper het proces—hij haalt de data op, parseert die en slaat alles op in een fractie van de tijd.
Zo werkt het onder de motorkap:
- Verzoek: De scraper stuurt een verzoek naar een webpagina en downloadt de ruwe HTML.
- Parseren: De HTML wordt geanalyseerd om de specifieke data te vinden die je zoekt (zoals de prijs in een
<span>-tag). - Extraheren: De data wordt eruit gehaald en opgeslagen in een gestructureerd formaat (CSV, Excel, Google Sheets, enz.).
Handmatig kopiëren en plakken is alsof je met een lepel een gat probeert te graven. Webscraping is een graafmachine erbij halen.
Waarom een webscraper maken belangrijk is voor bedrijven
Webscraping is niet alleen iets voor techneuten of data scientists—het is inmiddels onmisbaar voor iedereen die betrouwbare, actuele informatie nodig heeft. Bijna 97% van de grote organisaties investeert nu in datagedreven besluitvorming, en analisten verwachten dat de webscrapingmarkt de komende jaren gestaag blijft groeien tot het einde van dit decennium.
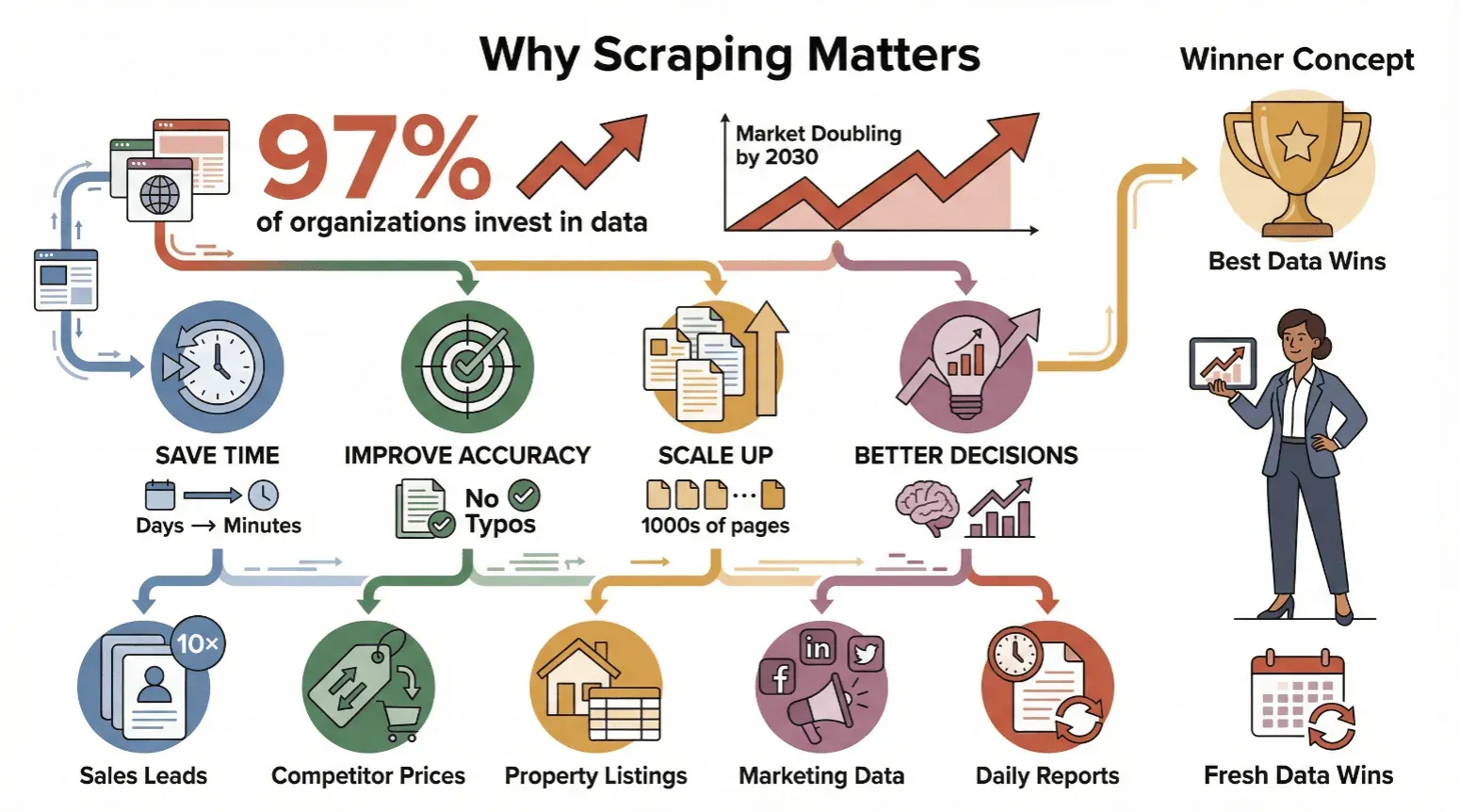
Daarom zetten bedrijven van alle groottes webscraping in:
- Bespaar tijd: Geautomatiseerde scraping verandert dagen handwerk in minuten.
- Verbeter de nauwkeurigheid: Software wordt niet moe en maakt geen typfouten.
- Schaal op: Scrape duizenden pagina’s, niet slechts een handvol.
- Neem betere beslissingen: Verse data betekent slimmere keuzes—of je nu prijzen aanpast, leads zoekt of trends volgt.
Laten we eens kijken naar een paar praktijkvoorbeelden:
| Gebruikssituatie | Wie profiteert | Typisch resultaat |
|---|---|---|
| Salesleads uit directories halen | Salesteams | 10× meer leads, uren bespaard op prospectie |
| Prijzen van concurrenten op e-commercesites volgen | E-commercemanagers | Prijzen in realtime aanpassen, marges beschermen |
| Vastgoedaanbod uit listings bundelen | Vastgoedkantoren | Sneller deals vinden, actuele marktgegevens |
| Marketingdata uit web/social media verzamelen | Marketingteams | Beter gerichte campagnes, betere prestatiebewaking |
| Dagelijkse webdatarapporten automatiseren | Operations, analisten | Lagere arbeidskosten, minder fouten, consistente en tijdige rapportage |
Kortom: wie de beste en meest actuele data heeft, wint.
Beginnersgids: hoe maak je een eenvoudige webscraper met Python
Als je benieuwd bent hoe webscraping “onder de motorkap” werkt, is Python een uitstekende plek om te beginnen. Ook als je nog niet kunt coderen, kun je in slechts een paar stappen een basis-scraper bouwen. Zo pak je het aan:
Je omgeving instellen
Eerst heb je Python nodig op je computer. Download de nieuwste versie via python.org en volg de instructies voor jouw besturingssysteem (Windows of Mac). Vink tijdens de installatie zeker “Add Python to PATH” aan.
Open daarna je terminal of opdrachtprompt en installeer de libraries die je nodig hebt:
pip install requests
pip install bs4
pip install pandas
requestslaat je webpagina’s ophalen.bs4(Beautiful Soup) helpt je HTML te parseren.pandasis handig om data op te slaan als CSV of Excel.
De structuur van de website inspecteren
Voordat je code schrijft, moet je weten waar je data in de HTML staat. Open je doelwebsite in Chrome, klik met de rechtermuisknop op de data die je wilt hebben (zoals een functietitel) en kies “Inspecteren”. Je ziet dan het HTML-element gemarkeerd—misschien een <a>-tag met een klasse zoals jobtitle. Noteer deze tags en klassen; je gebruikt ze om je scraper te vertellen waar hij naar moet zoeken.
De scraper schrijven en uitvoeren
Stel dat je functietitels en bedrijfsnamen wilt scrapen van een pagina met vacatures. Hier is een eenvoudig script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Vervang door je doel-URL
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Vind alle functietitels en bedrijfsnamen (pas selectors aan indien nodig)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Opslaan als CSV
df = pd.DataFrame({'Functietitel': titles, 'Bedrijf': companies})
df.to_csv('jobs.csv', index=False)
print("Scraping voltooid! Gegevens opgeslagen in jobs.csv")
- Pas de URL en klassennamen aan zodat ze overeenkomen met jouw doelwebsite.
- Voer het script uit in je terminal:
python yourscript.py - Open
jobs.csvom je resultaten te bekijken.
Pro-tip: Voor complexere sites (met paginering of dynamische content) moet je loops toevoegen of tools zoals Selenium gebruiken. Maar voor veel statische pagina’s werkt deze aanpak prima.
No-code eenvoud: hoe maak je een webscraper met Thunderbit
Wat als je helemaal niet met code wilt rommelen? Dan komt Thunderbit van pas—een no-code, AI-gestuurde webscraper voor zakelijke gebruikers. Voor duidelijke, goed gestructureerde pagina’s brengt Thunderbit je van "ik heb deze data nodig" naar een bruikbare spreadsheet in slechts een paar klikken — zwaardere sites met logins, anti-botbeveiliging of vreemde lay-outs vragen nog steeds wat finetuning, maar de instapdrempel is veel lager dan zelf een parser schrijven.
Data van elke website scrapen met AI Get Started Free
Zo werkt het:
Stap 1: installeer de Thunderbit Chrome-extensie
Ga naar de downloadpagina van de Thunderbit Chrome-extensie en voeg de extensie toe aan je browser. Maak een gratis account aan (met het gratis plan kun je een paar pagina’s scrapen om het uit te proberen).
Stap 2: ga naar je doelwebsite
Open de pagina die je wilt scrapen in Chrome. Log in als dat nodig is en scroll omlaag om dynamische content te laden.
Stap 3: beschrijf je databehoefte
Klik op het Thunderbit-pictogram om de zijbalk te openen. Je kunt dan:
- Klikken op “AI-veldsuggesties” en Thunderbit’s AI de pagina laten scannen en kolommen laten voorstellen (zoals “Productnaam”, “Prijs”, “Afbeelding”).
- Of een gewone Nederlandstalige prompt typen (bijvoorbeeld: “Extraheer alle boektitels en auteurs van deze pagina”).
Thunderbit’s AI beveelt automatisch velden en gegevenstypen aan. Je kunt velden hernoemen, toevoegen of verwijderen zoals nodig.
Stap 4: je eerste scrape uitvoeren
Zodra je velden zijn ingesteld, klik je gewoon op “Scrapen”. Thunderbit haalt de data op, verwerkt paginering indien nodig en toont alles in een nette tabel. Wil je meer details van subpagina’s (zoals individuele productpagina’s), klik dan op “Subpagina’s scrapen”—Thunderbit bezoekt dan elke link en haalt extra info op.
Stap 5: resultaten controleren en exporteren
Controleer je data in de Thunderbit-tabel. Als alles klopt, klik je op “Exporteren” en kies je formaat: Excel, CSV, Google Sheets, Airtable, Notion of JSON. Exporteren is gratis en onbeperkt.
Dat is alles. Geen code, geen sjablonen, geen hoofdbrekens.
Probeer Thunderbit AI Web Scraper gratis
Traditionele vs. no-code webscraperoplossingen vergelijken
Laten we zien hoe de twee benaderingen zich tot elkaar verhouden:
| Oplossing | Insteltijd | Benodigde vaardigheden | Onderhoud | Flexibiliteit | Exportopties |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Uren/dagen | Coderen, HTML-basis | Hoog (breekt snel) | Zeer hoog | CSV, Excel, JSON (via code) |
| Oudere no-code tools | 30-60 min | Enige technische kennis | Gemiddeld (handmatig) | Goed voor statische sites | CSV, Excel |
| Thunderbit (AI no-code) | Minuten | Geen (gewoon Engels/Nederlands) | Laag (AI past zich aan) | Hoog (dynamische sites) | Excel, CSV, Sheets, Notion... |
Thunderbit’s AI-gedreven aanpak zorgt ervoor dat je minder tijd kwijt bent aan het opzetten en repareren van scrapers, en meer tijd overhoudt om je data echt te gebruiken.
Veelvoorkomende uitdagingen bij traditionele webscrapers oplossen
Traditionele scrapers hebben een paar beruchte pijnpunten:
- Wijzigingen aan websites: Als een site zijn lay-out aanpast, kan je code breken. Thunderbit’s AI past zich automatisch aan de meeste wijzigingen aan, zodat je niets opnieuw hoeft te coderen.
- Anti-botmaatregelen: Veel sites blokkeren geautomatiseerde scripts. Thunderbit kan in je browser draaien (met je eigen login/sessie) of in de cloud voor snelheid.
- Dynamische content: Pagina’s met infinite scroll of knoppen zoals “Meer laden” kunnen basis-scrapers in de war brengen. Thunderbit’s AI verwerkt automatisch scrollen en interactieve elementen.
- Data achter een login: Met Thunderbit’s browsermodus geldt: als jij het in Chrome kunt zien, kun je het scrapen.
Kortom, Thunderbit is ontworpen om de rommelige realiteit van moderne websites aan te kunnen—zodat jij dat niet hoeft te doen.
Efficiënter werken: Thunderbit’s geavanceerde webscrapingfuncties
Thunderbit draait niet alleen om data ophalen—het gaat erom dat je de data snel, schoon en direct bruikbaar krijgt. Hier zijn een paar functies waar ik dol op ben:
Automatische paginering en scraping van subpagina’s
Moet je honderden producten over meerdere pagina’s scrapen? Thunderbit herkent paginering (knoppen Volgende, infinite scroll) en haalt alles in één keer binnen. Wil je meer details van subpagina’s? Klik op “Subpagina’s scrapen” en Thunderbit bezoekt elke link en haalt extra velden op (zoals verkopersinformatie of productspecificaties).
AI-veldsuggesties en datastructurering
Thunderbit’s AI gokt niet alleen op kolommen—het begrijpt de context. Het kan kolommen labelen, gegevenstypen toewijzen (tekst, getal, afbeelding, e-mail) en zelfs aangepaste instructies toepassen (zoals “alleen prijzen boven €100” of “vertaal beschrijvingen naar het Engels”). Je kunt prompts toevoegen om data te categoriseren, samen te vatten of opnieuw op te maken terwijl die wordt gescrapet.
Sjablonen en direct scrapen
Voor populaire sites (Amazon, Zillow, Google Maps, Instagram) biedt Thunderbit directe sjablonen—kies gewoon je site en alle velden staan al klaar. Geen configuratie nodig.
Plannen en automatisering
Heb je elke dag verse data nodig? Stel een schema in (“elke maandag om 9.00 uur”) en Thunderbit scrapt automatisch, waarna je Google Sheet of database wordt bijgewerkt zonder dat je er iets voor hoeft te doen.
Cloud versus lokaal scrapen
Kies ervoor om scrapes in je browser uit te voeren (handig voor ingelogde of interactieve sites) of in de cloud (sneller voor publieke data—tot 50 pagina’s tegelijk).
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Thunderbit’s geavanceerde functies maken het een topkeuze voor zakelijke gebruikers die betrouwbare, schaalbare en gebruiksvriendelijke webscraping nodig hebben.
Stapsgewijze handleiding: hoe maak je een webscraper met Thunderbit
Hier is je snelle-startchecklist:
- Installeer Thunderbit: Voeg de Chrome-extensie toe en maak een account aan.
- Open je doelwebsite: Log in als dat nodig is en scroll om content te laden.
- Open de Thunderbit-zijbalk: Klik op het extensiepictogram.
- Beschrijf je data: Klik op “AI-veldsuggesties” of typ je prompt.
- Controleer velden: Hernoem, voeg toe of verwijder kolommen indien nodig.
- Klik op “Scrapen”: Laat Thunderbit zijn werk doen.
- (Optioneel) Subpagina’s scrapen: Klik op “Subpagina’s scrapen” voor diepere data.
- Controleer de resultaten: Kijk de tabel na op juistheid.
- Data exporteren: Kies Excel, CSV, Google Sheets, Notion, Airtable of JSON.
- Opslaan/sjabloon/plannen: Sla je configuratie op voor later of plan terugkerende scrapes.
Tips voor probleemoplossing:
- Als data ontbreekt, probeer je prompt anders te formuleren of gebruik aangepaste instructies.
- Voor dynamische content moet je in browsermodus werken.
- Als je de limiet van het gratis plan bereikt, overweeg dan te upgraden voor meer pagina’s.
Bekijk Thunderbit-prijzen en -plannen
Conclusie en belangrijkste inzichten
Een webscraper maken is allang niet meer alleen iets voor programmeurs. Of je nu zelf aan de slag wilt en Python wilt schrijven, of liever AI het zware werk laat doen: de tools zijn toegankelijker dan ooit.
Dit moet je onthouden:
- Webscraping bespaart tijd, verhoogt de nauwkeurigheid en maakt datagedreven beslissingen mogelijk.
- Python is ideaal om te leren en voor maatwerkprojecten, maar vereist coderen en onderhoud.
- Thunderbit biedt een snelle no-code oplossing—beschrijf gewoon wat je wilt en klik op “Scrapen.”
- Geavanceerde functies zoals automatische paginering, scraping van subpagina’s en AI-veldsuggesties maken Thunderbit tot een krachtpatser voor zakelijke gebruikers.
- Je kunt Thunderbit gratis uitproberen en binnen enkele minuten resultaat zien.
Klaar om te stoppen met kopiëren en plakken en te beginnen met automatiseren? Download Thunderbit en ontdek hoe eenvoudig webscraping kan zijn. En als je dieper wilt graven, bekijk dan de Thunderbit-blog voor meer tutorials en tips.
Probeer Thunderbit AI Web Scraper gratis Get Started Free
FAQ’s
1. Moet ik kunnen coderen om een webscraper te maken?
Nee! Hoewel coderen (zoals Python + Beautiful Soup) je volledige controle geeft, laten no-code tools zoals Thunderbit iedereen krachtige webscrapers maken met gewone prompts en een paar klikken.
2. Welke soort data kan ik met Thunderbit scrapen?
Thunderbit kan tekst, cijfers, afbeeldingen, e-mails, telefoonnummers en meer extraheren van bijna elke website—including lijsten met paginering en subpagina’s. Je kunt ook sjablonen gebruiken voor populaire sites.
3. Hoe gaat Thunderbit om met websites die van lay-out veranderen?
Thunderbit’s AI past zich automatisch aan de meeste lay-outwijzigingen aan. In tegenstelling tot traditionele scrapers die vastlopen wanneer een site wordt bijgewerkt, gebruikt Thunderbit semantisch begrip om met minimale aanpassingen te blijven werken.
4. Is webscraping legaal en veilig?
Webscraping is legaal wanneer je publiek beschikbare data verzamelt en de gebruiksvoorwaarden van een site respecteert. Thunderbit moedigt verantwoord gebruik aan en biedt functies die je helpen compliant te blijven.
5. Kan ik terugkerende scrapes plannen of exports automatiseren?
Ja! Thunderbit laat je scrapes op elk interval plannen (dagelijks, wekelijks, enz.) en resultaten rechtstreeks exporteren naar Google Sheets, Notion, Airtable, Excel of CSV—zonder handmatig werk.
Klaar om je dataverzameling te automatiseren? Probeer Thunderbit gratis en ontdek hoe eenvoudig webscraping voor iedereen kan zijn.
Meer lezen




