Als je in 2026 webscraping-tools vergelijkt, ben je meestal niet op zoek naar een filosofieles. Je wilt een shortlist waar je op kunt vertrouwen, een snelle manier om tools voor zakelijke gebruikers te scheiden van technisch zware stacks, en genoeg echt bewijs om te voorkomen dat je de verkeerde keuze maakt. Precies daarvoor is deze pagina bedoeld.
Het korte antwoord
Als je alleen de beslislogica nodig hebt, gebruik dan dit:
- Kies een AI-webscraper als je de snelste route van website naar spreadsheet wilt, met minimale installatie.
- Kies een no-code scraper als je meer controle wilt over taken, planning of cloud-runs, zonder code te schrijven.
- Kies een API-platform als je team rendering, proxy-rotatie, anti-botafhandeling of integratie in een intern product nodig heeft.
- Kies een open-sourcebibliotheek als je volledige controle wilt en onderhoud, selectors, infrastructuur en fouten zelf wilt dragen.
In dit artikel blijven alle 20 tools staan, maar de aanbevelingslogica is bewust simpel: begin met de lichtste tool die je workflow betrouwbaar aankan, en ga pas een stap verder omlaag in de stack als onderhoud, blokkades of schaal dat echt afdwingen.
Snelle vergelijkingstabel: de beste webscraping-tools in 2026
De prijzen en abonnementsmodellen hieronder zijn op 8 mei 2026 gecontroleerd aan de hand van officiële product- of prijspagina’s. Waar leveranciers gebruiksgebaseerde tarieven of maatwerk enterprise-offertes hanteren, beschrijf ik het prijsmodel in plaats van te doen alsof er één universeel betrouwbare stickerprijs bestaat.
| Tool | Type | Beste keuze voor | Waarom het op de lijst van 2026 staat | Prijsmodel (gecontroleerd in mei 2026) |
|---|---|---|---|---|
| Thunderbit | AI-webscraper | Sales, operations, ecommerce, vastgoed | Snelste route voor niet-programmeurs; AI-veldaanbeveling, subpagina’s, exports, browser- + cloud-workflow | Gratis versie, betaalde abonnementen, maatwerk voor bedrijven |
| Browse AI | AI-webscraper | Zakelijke gebruikers die websites monitoren | Sterke no-code robots, monitoring en spreadsheet/API-achtige output | Gratis plan, betaalde abonnementen, premium managed tier |
| Bardeen | AI-automatisering + scraping | Revenue ops en browser-workflows | Beter wanneer scraping één stap is binnen een bredere automatiseringsworkflow | Gratis plan en betaalde abonnementen |
| Diffbot | AI-extractieplatform | Enterprise- en datateams | Sterkste keuze als je AI-extractie plus grootschalige gestructureerde data-workflows wilt | Enterprise-prijsmodel |
| Instant Data Scraper | Lichtgewicht browserscraper | Incidentele gebruikers en snelle tabellen | Nog steeds een van de simpelste manieren om snel een zichtbare lijst of tabel naar CSV te halen | Gratis |
| Octoparse | No-code scraper | Analisten en operationele teams met grotere terugkerende jobs | Volwassen visuele bouwer met cloud-extractie, anti-blokkering en templates | Gratis plan, betaald vanaf $69/maand, enterprise op maat |
| ParseHub | Low-code scraper | Analisten die logica en desktopcontrole nodig hebben | Flexibele projectlogica en geneste navigatie, met een steilere leercurve dan nieuwere AI-first tools | Gratis plan en betaalde abonnementen |
| Web Scraper | No-code scraper | Beginners en lichte cloudtaken | Goede instap als je houdt van sitemap-gebaseerd scrapen en browser-first setup | Gratis extensie, betaalde cloudplannen |
| Data Miner | Browserscraper | Onderzoekers en growth operators | Nog steeds handig voor snelle extractie op basis van recepten in de browser | Gratis plan en betaalde abonnementen |
| Apify | API- en actorplatform | Technische teams en hybride operators | Uitstekend ecosysteem van Actors plus custom runtime zodra browserextensies niet meer volstaan | Gratis plan, starter vanaf $29/maand plus gebruik, grotere betaalde niveaus |
| ScrapingBee | Scraping API | Ontwikkelaars die JS-zware sites scrapen | Goede keuze als je rendering en proxy-afhandeling wilt zonder zelf de browserlaag te bouwen | Gratis proefperiode en betaalde abonnementen |
| ScraperAPI | Scraping API | Ontwikkelaars die snel opschalen | Eenvoudige API, proefcredits, gestructureerde producten en makkelijkere uitbesteding van infrastructuur | 7-daagse proef met 5.000 credits, betaald vanaf $49/maand |
| Bright Data | Enterprise API + proxyplatform | Programma’s met hoog volume en strenge compliance-eisen | Breedste dataverzameling-stack wanneer unblock, proxy en managed acquisition belangrijker zijn dan eenvoud | Gebruiksgebaseerde en productgebaseerde prijzen |
| Oxylabs | Enterprise API + proxyplatform | Teams die scraping als infrastructuur inkopen | Sterk voor grootschalige verzameling, vooral bij prijs-, SEO- en marktonderzoekstaken | Web Scraper API vanaf $49/maand; bredere proxyprijzen variëren |
| Zyte | API + anti-botstack | Developer- en datateams | Goede keuze als je API-first extractie wilt met sterke browser-, rotatie- en anti-detectie-primitieven | Proef met $5 gratis credit, gebruiksgebaseerde verplichtingen |
| Selenium | Open-source browserautomatisering | QA-achtige automatisering en moeilijke interactiestromen | Nog steeds nuttig wanneer de nauwkeurigheid van gebruikersinteractie belangrijker is dan scraper-throughput | Gratis en open source |
| BeautifulSoup4 | Open-source parser | Beginners en lichte parsing | Het best als parser in een eenvoudige stack, niet als volledig scrapingplatform | Gratis en open source |
| Scrapy | Open-source crawlingframework | Productie-crawlers op maat | Beste balans tussen kracht en volwassenheid als je de pipeline zelf wilt beheren | Gratis en open source |
| Puppeteer | Open-source browserautomatisering | Node-first scraping en browserscripting | Geweldig als je team zich al thuis voelt in het Chrome/Node-ecosysteem | Gratis en open source |
| Playwright | Open-source browserautomatisering | Moderne automatisering voor meerdere browsers | Vaak de schoonste keuze voor moderne browserautomatisering met sterke ontwikkelaars-ergonomie | Gratis en open source |
Hoe ik deze tools heb beoordeeld
Ik gebruikte vier filters:
- Tijd tot eerste succesvolle scrape
Als een niet-technische gebruiker niet snel bruikbare data kan ophalen, dan telt dat zwaar. - Onderhoudsbelasting
Snelle installatie is waardeloos als de workflow breekt zodra een site verandert. - Schaallimiet
Sommige tools zijn ideaal voor 50 pagina’s per week en waardeloos voor 5 miljoen verzoeken per maand. - Workflow-fit
De beste tool voor een revenue ops-team is zelden de beste tool voor een dataplatformteam.
Het resultaat is dus geen universele ranglijst. Het is een beslispagina om eerst de juiste toolcategorie te kiezen, en daarna het juiste product binnen die categorie.
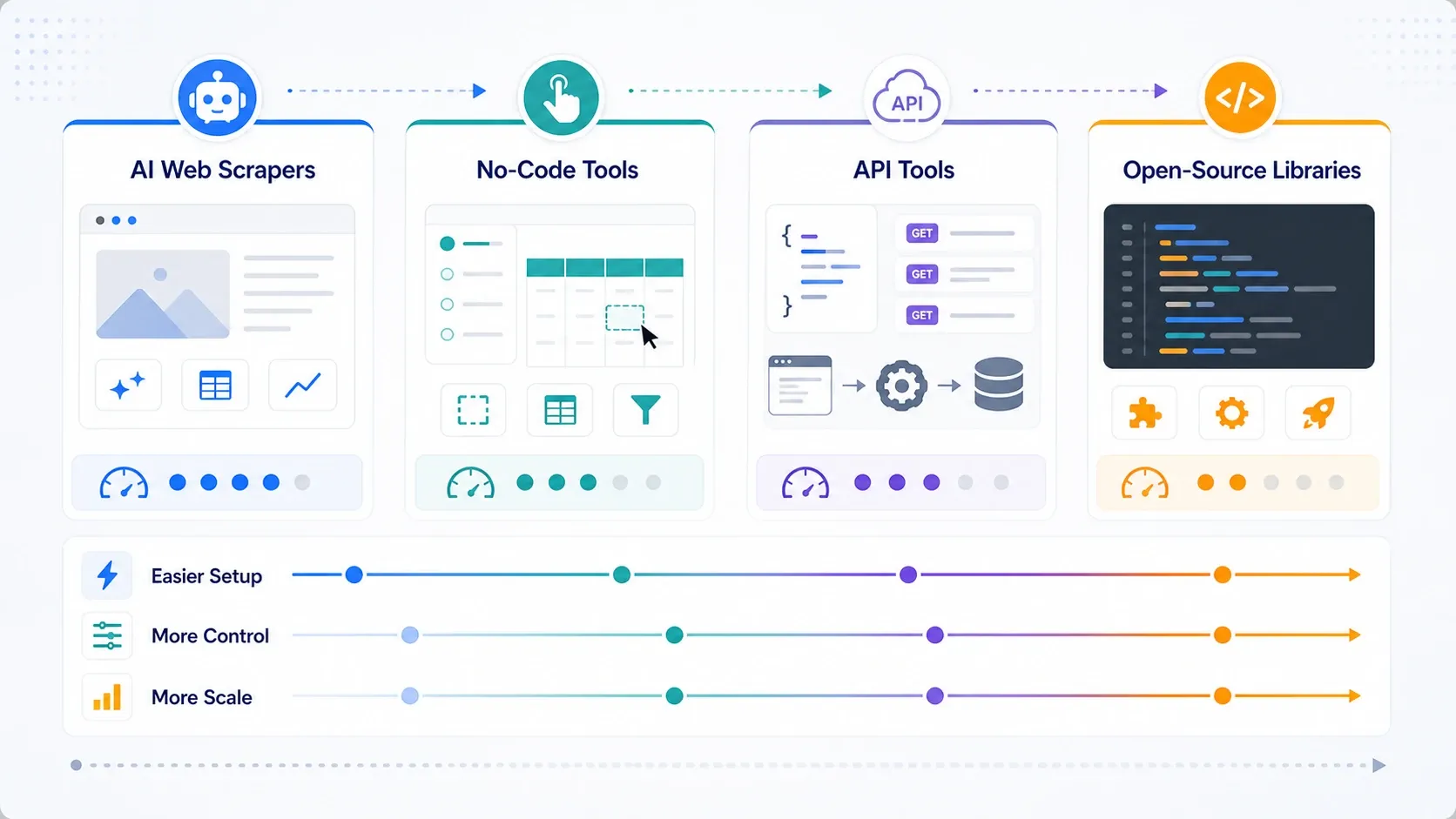
Welk type webscraping-tool heb je eigenlijk nodig?
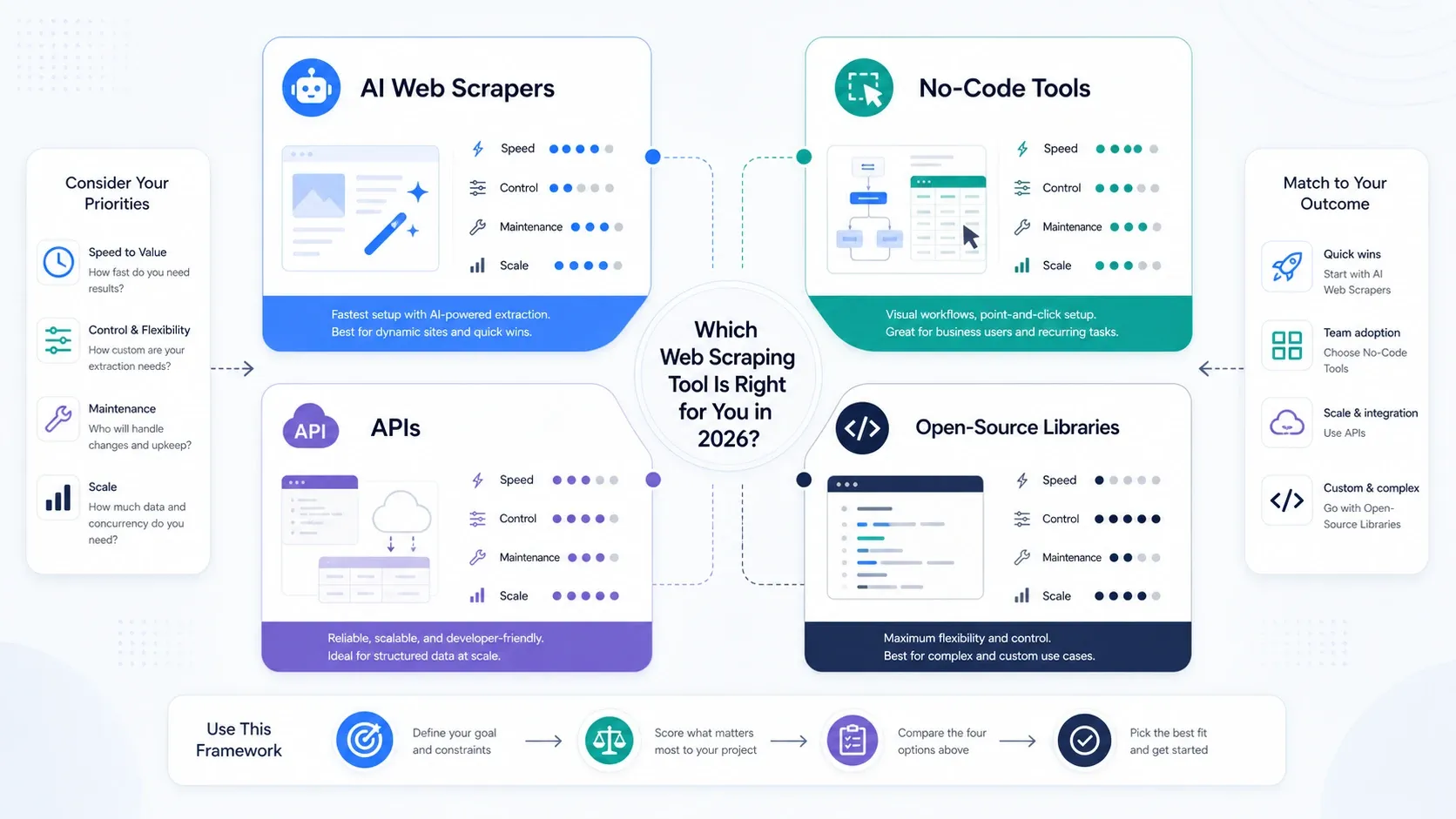
- Kies AI-webscrapers als je primaire doel operationele snelheid is.
- Kies no-code tools als je meer paginering, planning en herhaalbare controle over taken nodig hebt.
- Kies API’s en scrapingplatforms als rendering, rotatie en unblock-capaciteit nu de bottleneck zijn.
- Kies open-sourcebibliotheken als je team controle belangrijker vindt dan gemak en de stack intern kan ondersteunen.
Als je team nog twijfelt of scraping bij operations of engineering moet landen, begin dan eerst met een AI- of no-code tool. Je leert sneller wat echt telt door echte taken uit te voeren dan door de stack vooraf te over-engineeren.
Beste AI-webscrapers voor zakelijke teams
Dit zijn de tools waar ik als eerste naar zou kijken als je spreadsheet-klare data wilt met zo weinig mogelijk installatie.
1. Thunderbit
Thunderbit is hier de makkelijkste optie als je team gestructureerde data wil extraheren zonder selectors, browserscripting of scraping-infrastructuur te leren. De workflow is gebouwd rond AI-veldaanbeveling, verrijking van subpagina’s en directe export naar de tools waar zakelijke gebruikers al mee werken.
- Beste voor: sales, operations, ecommerce, vastgoed en andere browser-intensieve teams.
- Waarom het opvalt: het verkort de insteltijd voor niet-programmeurs beter dan iets anders op deze lijst.
- Let op: als je diepe custom crawler-logica of zeer gespecialiseerde engineeringcontrole nodig hebt, ga je uiteindelijk verder omlaag in de stack.
- Prijsmodel: gratis versie, zelf te gebruiken betaalde abonnementen en zakelijke prijzen.
Als je de snelste echte workflow wilt zien voordat je meer tools vergelijkt, is deze walkthrough de beste plek om te beginnen:
2. Browse AI
Browse AI blijft een sterke keuze voor zakelijke gebruikers die point-and-click-installatie plus terugkerende monitoring willen. Het robotmodel is vooral handig wanneer scraping en wijzigingsdetectie even belangrijk zijn.
- Beste voor: het monitoren van prijspagina’s, concurrentenpagina’s en herhaalbare lijst-extractie.
- Waarom het opvalt: verzorgde onboarding, kant-en-klare robots en een duidelijke route van website naar spreadsheet of API-achtige output.
- Let op: complexe, grootschalige jobs kunnen sneller duur of operationeel onhandig worden dan bij API-first stacks.
- Prijsmodel: gratis plan, betaalde abonnementen, premium/managed tier.
3. Bardeen
Bardeen is vooral interessant wanneer scraping slechts één actie is binnen een bredere browserautomatisering. Als je data in CRM’s, spreadsheets of outbound-workflows zet, dan telt de automatiseringskant zwaarder dan de pure extractiediepte.
- Beste voor: revenue ops, lead-workflows en browser-native taakautomatisering.
- Waarom het opvalt: sterker verhaal rond workflow-automatisering dan pure extractietools.
- Let op: het is minder geschikt wanneer de scraping zelf complex en bedrijfskritisch is.
- Prijsmodel: gratis plan en betaalde abonnementen.
4. Diffbot
Diffbot is er voor teams die AI-extractie op enterprise-schaal nodig hebben, niet voor gebruikers die de goedkoopste of simpelste route zoeken. Het is logischer wanneer kwaliteit van gestructureerde data en grootschalige ingest belangrijker zijn dan hands-on controle.
- Beste voor: enterprise datateams, content intelligence en grote extractieprogramma’s.
- Waarom het opvalt: extractie in de stijl van computer vision en een sterke focus op gestructureerde output.
- Let op: overkill voor kleine teams en onhandig als je use case licht is.
- Prijsmodel: enterprise-abonnementen en maatwerkverkoop.
5. Instant Data Scraper
Instant Data Scraper verdient nog steeds een plek, omdat er genoeg situaties zijn waarin je gewoon direct de zichtbare tabel, directory of lijst nodig hebt. Het is geen platform, maar vaak wel genoeg.
- Beste voor: eenmalige extractie, snelle leadlijsten, eenvoudige directories en zichtbare tabellen.
- Waarom het opvalt: bijna geen frictie op de juiste pagina’s.
- Let op: beperkte automatisering, beperkte diepgang en minder geschikt voor geavanceerde workflows.
- Prijsmodel: gratis.
Beste no-code webscraping-tools voor herhaalbare jobs
Zodra de job meer is dan een incidentele scrape, worden visuele builders en cloud-executie belangrijk.
6. Octoparse
Octoparse blijft een van de sterkste no-code platforms als je cloud-runs, template-ondersteuning en geavanceerder taakbeheer nodig hebt dan een browserextensie kan bieden.
- Beste voor: analisten, prijs-teams en operators die terugkerende verzameljobs draaien.
- Waarom het opvalt: volwassen task builder, cloud-extractie, anti-blokkering en een groot template-ecosysteem.
- Let op: het is krachtiger dan AI-first browsertools, maar dat betekent ook meer instelwerk.
- Prijsmodel: gratis plan, betaald vanaf $69/maand, enterprise op maat.
7. ParseHub
ParseHub blijft relevant voor gebruikers die meer controle willen dan een AI-scraper, maar geen codebase willen bouwen. Het beloont geduld, niet snelheid.
- Beste voor: analisten en technisch nieuwsgierige operators die een steilere leercurve kunnen accepteren.
- Waarom het opvalt: flexibele navigatielogica en meer controle dan lichte browsertools.
- Let op: de productervaring voelt zwaarder dan die van nieuwere spelers, zeker voor snel bewegende zakelijke teams.
- Prijsmodel: gratis plan en betaalde abonnementen.
8. Web Scraper
Web Scraper is nog steeds een redelijk startpunt als je van het sitemap-model houdt en iets wilt dat in de browser begint, en later kan doorgroeien naar cloudplanning.
- Beste voor: beginners, hobbyprojecten en kleinere herhaalbare jobs.
- Waarom het opvalt: toegankelijke sitemap-workflow en eenvoudige browser-first adoptie.
- Let op: het wordt beperkend zodra je meer adaptieve extractielogica nodig hebt.
- Prijsmodel: gratis browserextensie en betaalde cloudplannen.
9. Data Miner
Data Miner kun je het best zien als een snelle extractietool, niet als een compleet scrapingplatform. Toch verdient het een plek, omdat receptgestuurd werken nuttig is voor veel research- en prospecting-taken.
- Beste voor: onderzoekers, growth teams en snelle browser-side exporttaken.
- Waarom het opvalt: receptmodel, weinig frictie en makkelijke browserexport.
- Let op: niet de juiste tool voor serieuze scraping op platform-schaal.
- Prijsmodel: gratis plan en betaalde abonnementen.
Beste API-platforms wanneer schaal en blokkades het echte probleem worden
Dit is de laag waar engineeringteams stoppen met denken: “hoe scrape ik deze pagina?” en beginnen met denken: “hoe maak ik dit betrouwbaar op volume?”
10. Apify
Apify is het meest flexibele platform in deze groep als je zowel een marktplaats van herbruikbare scrapers wilt als een plek om je eigen code uit te voeren. Het overbrugt no-code ontdekking en developer-executie beter dan de meeste concurrenten.
- Beste voor: hybride teams, scraping onder leiding van developers en herbruikbare automatiseringsworkflows.
- Waarom het opvalt: Actor-ecosysteem plus custom runtime geeft een ongebruikelijke reikwijdte.
- Let op: zodra je custom gaat, zit je weer in engineeringland en vervaagt het eenvoudsvoordeel.
- Prijsmodel: gratis plan, starter vanaf $29/maand plus gebruik, grotere gebruiksniveaus en enterprise.
11. ScrapingBee
ScrapingBee is een goede keuze wanneer je echte behoefte is: “geef me een gerenderde pagina en regel de lelijke infrastructuur voor me.” Het past goed bij JS-zware doelen.
- Beste voor: developers die dynamische sites scrapen met beperkte behoefte aan infra-werk.
- Waarom het opvalt: eenvoudige API rond rendering, proxies en browserautomatisering.
- Let op: het is een infrastructuurdienst, dus parsing, retry-logica en kwaliteit stroomafwaarts blijven jouw verantwoordelijkheid.
- Prijsmodel: proefperiode en betaalde abonnementen.
12. ScraperAPI
ScraperAPI blijft een van de makkelijkste manieren om proxybeheer en succesvolle verzoeken uit te besteden wanneer je snel wilt opschalen.
- Beste voor: developers die snel van prototype naar volume moeten gaan.
- Waarom het opvalt: duidelijke API, proefcredits, gestructureerde producten en schaalniveaus.
- Let op: net als alle API-first producten neemt het niet de noodzaak weg van engineering-oordeelsvorming rond parsing en datavalidatie.
- Prijsmodel: 7-daagse proef met 5.000 credits, betaald vanaf $49/maand.
13. Bright Data
Bright Data is de zwaargewichtoptie wanneer unblock-capaciteit, proxyvoorraad en managed acquisition belangrijker zijn dan tool-eenvoud.
- Beste voor: enterprise-programma’s, grootschalige verzameling met compliance-eisen en managed data-acquisitie.
- Waarom het opvalt: breed aanbod aan proxy-, scraper-, browser- en datasetproducten.
- Let op: duur en makkelijk te veel inkopen als je kernworkflow nog relatief simpel is.
- Prijsmodel: gebruiksgebaseerde en productgebaseerde prijzen voor API’s, proxies en managed services.
14. Oxylabs
Oxylabs blijft een sterke keuze voor teams die scraping als infrastructuur inkopen in plaats van als browsertool. Het is vooral relevant wanneer betrouwbaarheid en inkoopvolwassenheid belangrijk zijn.
- Beste voor: enterprise-verzameling, prijsmonitoring, SEO-monitoring en marktonderzoek.
- Waarom het opvalt: robuust infrastructuurverhaal, diepe proxycapaciteit en een duidelijker enterprise-verkooptraject.
- Let op: niet ideaal als je team een losse self-service workflow wil.
- Prijsmodel: Web Scraper API vanaf $49/maand; andere producten verschillen per eenheid en gebruik.
15. Zyte
Zyte verdient nog steeds serieuze aandacht van developer- en datateams die anti-detectie, browseracties, JS-rendering en roterende IP’s willen binnen één API-first verhaal.
- Beste voor: technische teams die herhaalbare extractiesystemen bouwen.
- Waarom het opvalt: browseracties, JS-rendering, IP-rotatie en anti-bothouding in één stack.
- Let op: beter voor teams met engineering-eigenaarschap dan voor niet-technische operators.
- Prijsmodel: proef met $5 gratis credit en gebruiksgebaseerde maandelijkse verplichtingen.
Beste open-sourcebibliotheken voor developers die volledige controle willen
Als je de scraper-stack end-to-end zelf wilt bezitten, zijn dit in 2026 de nuttigste bouwstenen.
16. Selenium
Selenium is nog steeds nuttig wanneer je QA-achtige interactienauwkeurigheid nodig hebt, oudere browserautomatiseringsworkflows of heel expliciete controle over gebruikersstromen.
- Beste voor: automatisering met veel interactie, overlap met QA en sites waar browsergedrag belangrijker is dan crawl-throughput.
- Waarom het opvalt: volwassen ecosysteem en brede browserondersteuning.
- Let op: zwaarder en trager dan nieuwere browsertooling voor veel scraping-workloads.
- Prijsmodel: gratis en open source.
17. BeautifulSoup4

BeautifulSoup is geen volledig scrapingplatform, maar blijft een van de makkelijkste manieren om rommelige HTML te parsen in lichte workflows.
- Beste voor: beginners, snelle scripts en parser-first taken.
- Waarom het opvalt: eenvoudige API en lage cognitieve belasting.
- Let op: combineer het met request-, browser- of crawlertools; op zichzelf is het alleen een parser.
- Prijsmodel: gratis en open source.
18. Scrapy
Scrapy is nog steeds het beste antwoord wanneer je een echt crawlingframework nodig hebt in plaats van een handvol scripts.
- Beste voor: productie-crawlers op maat en datapijplijnen die intern eigendom zijn.
- Waarom het opvalt: hoge prestaties, pipelines, middleware en langdurige uitbreidbaarheid.
- Let op: er is echte engineering-overhead, en JS-zware doelen vragen vaak aanvullende tooling.
- Prijsmodel: gratis en open source.
19. Puppeteer
Puppeteer blijft een sterke keuze voor Node-first teams die directe controle over Chromium en browserscripting willen.
- Beste voor: Node-gebaseerde scraping, screenshots en browserautomatiseringstaken.
- Waarom het opvalt: directe, krachtige controle over Chromium-gedrag.
- Let op: smaller browserverhaal dan Playwright en nog steeds zwaar in gebruik op schaal.
- Prijsmodel: gratis en open source.
20. Playwright
Playwright is mijn standaardaanbeveling voor moderne browserautomatisering als je team code schrijft en een nieuwere abstractielaag wil dan Selenium.
- Beste voor: moderne browserautomatisering, JS-zware sites en teams die ontwikkelaars-ergonomie belangrijk vinden.
- Waarom het opvalt: sterk model voor meerdere browsers, betrouwbaar wachtgedrag en nette API’s.
- Let op: je blijft zelf verantwoordelijk voor browserinfra, concurrency, selector-drift en datavalidatie.
- Prijsmodel: gratis en open source.
Mijn shortlist per teamtype
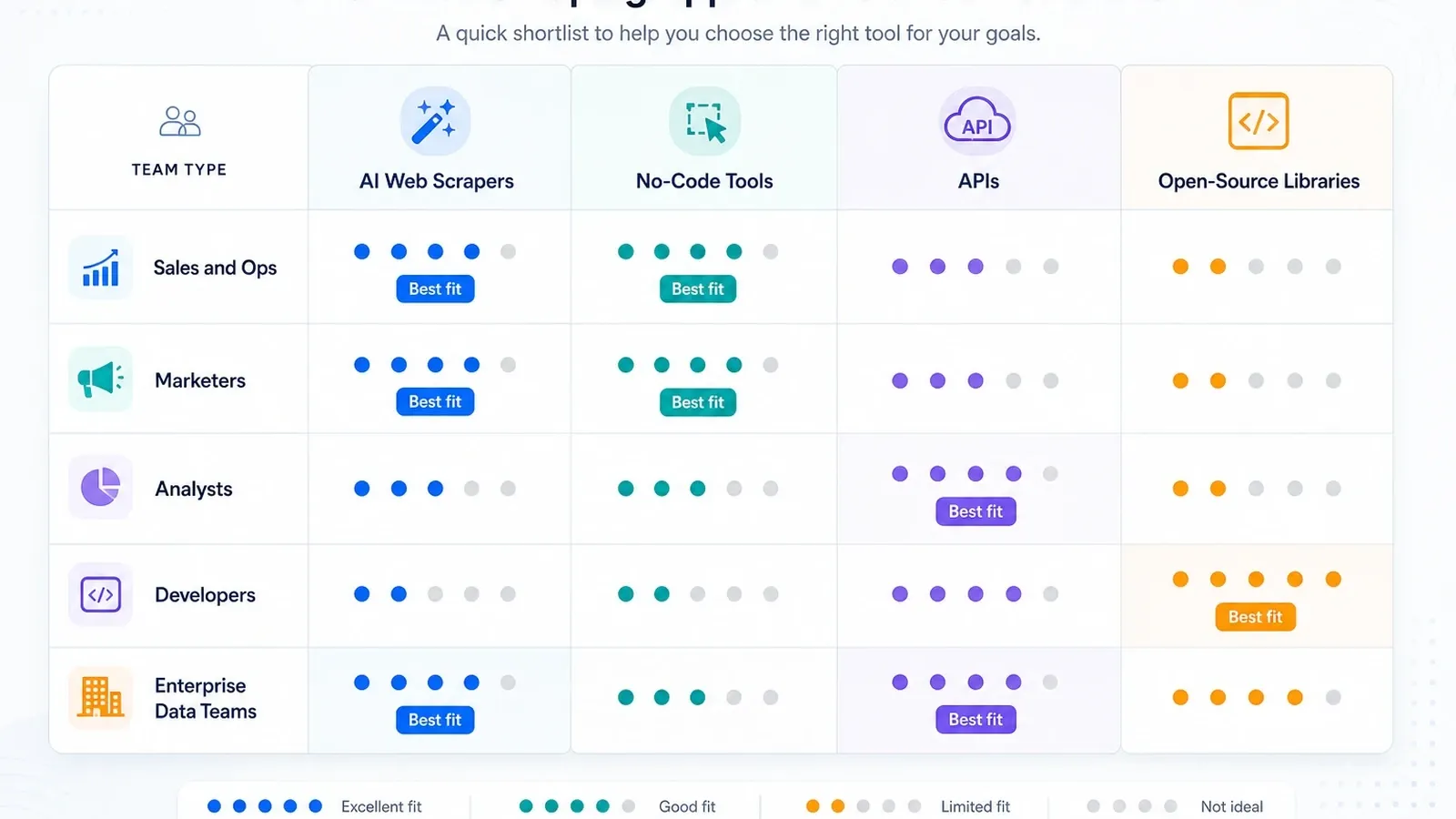
- Sales- en operationele teams: begin met Thunderbit en bekijk daarna Browse AI als monitoring belangrijker is dan verrijking van subpagina’s.
- Analisten- en onderzoeksteams: eerst Octoparse als terugkerende jobs groter zijn dan browserextensies comfortabel aankunnen.
- Automation-zware GTM-teams: Bardeen als scraping slechts één stap is in een bredere workflow.
- Developer-teams die interne tooling bouwen: Apify, Zyte, ScraperAPI of Playwright, afhankelijk van hoeveel eigenaarschap over de stack je wilt.
- Enterprise dataprogramma’s: Bright Data, Oxylabs, Diffbot en Zyte zijn de serieuze infrastructuurgesprekken.
Wanneer je een stap verder omlaag in de stack moet gaan
Gebruik deze regel:
- Blijf bij AI-tools totdat je tegen beperkingen van herhaalbaarheid of edge cases aanloopt.
- Ga naar no-code tools wanneer planning, paginering, anti-blokkering of cloud-runs belangrijker worden dan één-klik-eenvoud.
- Ga naar API’s wanneer unblock-rate, JS-rendering en concurrency de echte bottlenecks worden.
- Ga naar open-sourcebibliotheken wanneer de kosten van vendor-abstrahering hoger worden dan de kosten van het volledig zelf bezitten van de stack.
De meeste teams gaan te vroeg een stap verder omlaag in de stack. Dat is een van de meest voorkomende fouten die ik zie.
Slotgedachte
Voor de meeste niet-technische teams is het juiste antwoord in 2026 niet “de krachtigste scraper”. Het is de tool die nauwkeurige data met zo min mogelijk onderhoud naar de volgende workflow brengt. Daarom winnen AI-first tools nog steeds voor operators, terwijl API’s en open-source stacks beter passen bij technische teams met duidelijke schaalvereisten.
Als je de kortste route van pagina naar gestructureerde output wilt, begin dan met Thunderbit. Als je al weet dat je job zware infrastructuur nodig heeft, ga dan direct naar de API- en developerlagen. Verwar complexiteit alleen niet met verfijning.
Veelgestelde vragen
1. Wat is in 2026 de beste webscraping-tool voor niet-technische gebruikers?
Voor de meeste niet-technische gebruikers bieden AI-first tools zoals Thunderbit en Browse AI de snelste route naar bruikbare data, omdat ze selectorwerk, installatiefrictie en onderhoudsdruk verminderen.
2. Wat moet ik kiezen als mijn sites zwaar op JavaScript leunen of verzoeken agressief blokkeren?
Kijk richting ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright of Selenium, afhankelijk van of je een managed service wilt of directe engineeringcontrole.
3. Zijn no-code tools nog relevant nu AI-webscrapers beter zijn?
Ja. No-code tools zoals Octoparse en ParseHub blijven belangrijk wanneer je meer expliciete controle nodig hebt over taaklogica, cloud-executie en herhaalbaar jobbeheer.
4. Welke tools zijn het meest logisch voor engineeringteams?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer en Selenium zijn de meest natuurlijke keuzes wanneer developers de workflow beheren.
5. Hoe maak ik snel een shortlist zonder te veel onderzoek te doen?
Kies eerst het type tool, niet de leverancier. Bepaal of je AI-eenvoud, no-code controle, API-infrastructuur of open-source eigenaarschap nodig hebt. Vergelijk daarna de producten binnen die laag.
Verder lezen