

2025년의 웹은 좀 혼란스러운 공간이에요. 보이는 트래픽의 절반은 사람도 아니거든요. 맞아요. 이제 봇이랑 크롤러가 전체 인터넷 활동의 50% 이상을 차지하고 있어요(Thales Group). 그중에서 정말 반가운 “좋은” 봇은 일부뿐이에요. 검색엔진, 소셜 미디어 미리보기 봇, 분석 보조 도구 정도죠. 나머지요? 글쎄요, 항상 도와주러 오는 친구라고 보긴 어렵잖아요. Thunderbit에서 오랫동안 자동화랑 AI 도구를 만들어온 사람으로서 말씀드리면, 좋은 크롤러든 나쁜 크롤러든 SEO를 살리거나 망가뜨리고, 분석 수치를 왜곡하고, 대역폭을 갉아먹고, 심하면 보안 사고까지 일으킬 수 있다는 걸 직접 봐왔거든요.
비즈니스를 하시거나, 웹사이트를 관리하시거나, 그냥 디지털 환경을 깔끔하게 정리해두고 싶으시다면, 지금 누가 서버 문을 두드리고 있는지 아는 게 그 어느 때보다 중요해요. 그래서 이 2025년 가이드를 준비했어요. 꼭 알아야 할 크롤러가 뭘 하는 친구인지, 어떻게 구분하는지, 좋은 봇은 들여보내고 나쁜 봇은 막는 방법까지 한번에 정리해봤어요.
크롤러가 “알려진” 크롤러가 되는 기준은 뭘까요? 사용자 에이전트, IP, 그리고 검증
기본부터 한번 짚어볼게요. “알려진” 크롤러란 뭐냐면요. 가장 단순하게 말하면, 일관된 사용자 에이전트 문자열(예: Googlebot/2.1 또는 bingbot/2.0)로 자기 신원을 밝히고, 이상적으로는 확인 가능한 공개 IP 대역이나 ASN 블록에서 크롤링하는 봇이에요(Googlebot verification). Google, Microsoft, Baidu, Yandex, DuckDuckGo 같은 주요 서비스들은 자사 봇 문서를 공개하고 있고, 어떤 곳은 공식 IP 목록이 담긴 도구나 JSON 파일까지 제공해요(Googlebot IP list, Bingbot IP list, DuckDuckBot IPs).
근데 여기엔 함정이 있거든요. 사용자 에이전트만 믿는 건 위험해요. 스푸핑이 너무 흔하니까요. 악성 봇이 방어를 뚫으려고 Googlebot이나 Bingbot인 척하는 경우가 진짜 많아요(SecurityWeek). 그래서 가장 확실한 방법은 이중 검증이에요. 사용자 에이전트랑 IP 주소(또는 ASN)를 둘 다 확인하고, 역방향 DNS 조회나 공개 목록을 같이 활용하시면 돼요. Thunderbit 같은 도구를 쓰면 이 과정을 자동화할 수 있거든요. 로그를 뽑아내서 사용자 에이전트랑 매칭하고 IP를 대조해서, 누가 사이트를 크롤링하는지 믿을 만한 실시간 목록을 만들 수 있죠.
이 크롤러 목록을 어떻게 활용할까요?
알려진 크롤러 목록을 실제로 어떻게 써먹어야 할까요? 제가 추천드리는 방법은 이래요.
- 허용 목록 관리: 원하는 봇(검색엔진, 소셜 미디어 미리보기 봇)이 방화벽이나 CDN, WAF에 실수로 차단되지 않게 해주세요. 공식 IP랑 사용자 에이전트로 정확하게 허용 목록을 관리하면 돼요.
- 분석 필터링: 분석 도구에서 봇 트래픽을 걸러내야 수치가 Googlebot이나 AhrefsBot이 사이트를 빙빙 돈 결과가 아니라 실제 사람 방문자를 반영하거든요(SecurityWeek).
- 봇 관리: 너무 공격적인 SEO 도구한테는 crawl-delay나 속도 제한 규칙을 걸어두고, 알 수 없거나 악성인 봇은 차단하거나 추가 검증을 거쳐주세요.
- 자동 로그 분석: Thunderbit 같은 AI 도구로 로그 속 크롤러 활동을 추출, 분류, 라벨링하면 추세를 잡고, 사칭 봇을 찾아내고, 정책을 최신 상태로 유지할 수 있어요.
크롤러 목록을 최신으로 유지하는 건 “한 번 해두고 끝”나는 일이 아니에요. 새 봇은 계속 생기고, 기존 봇은 행동을 바꾸고, 공격자는 해마다 더 교묘해지거든요. Thunderbit으로 공식 문서나 GitHub 저장소를 스크래핑해서 업데이트를 자동화하면 시간도 아끼고 골치도 덜 수 있어요.
1. Thunderbit: AI 기반 크롤러 식별 및 데이터 관리
Thunderbit으로 하는 AI 기반 크롤러 관리 Get Started Free
Thunderbit은 단순한 AI 웹 스크래퍼가 아니에요. 크롤러 트래픽을 이해하고 관리하려는 팀을 위한 데이터 어시스턴트거든요. Thunderbit이 뭐가 다른지 짚어볼게요.
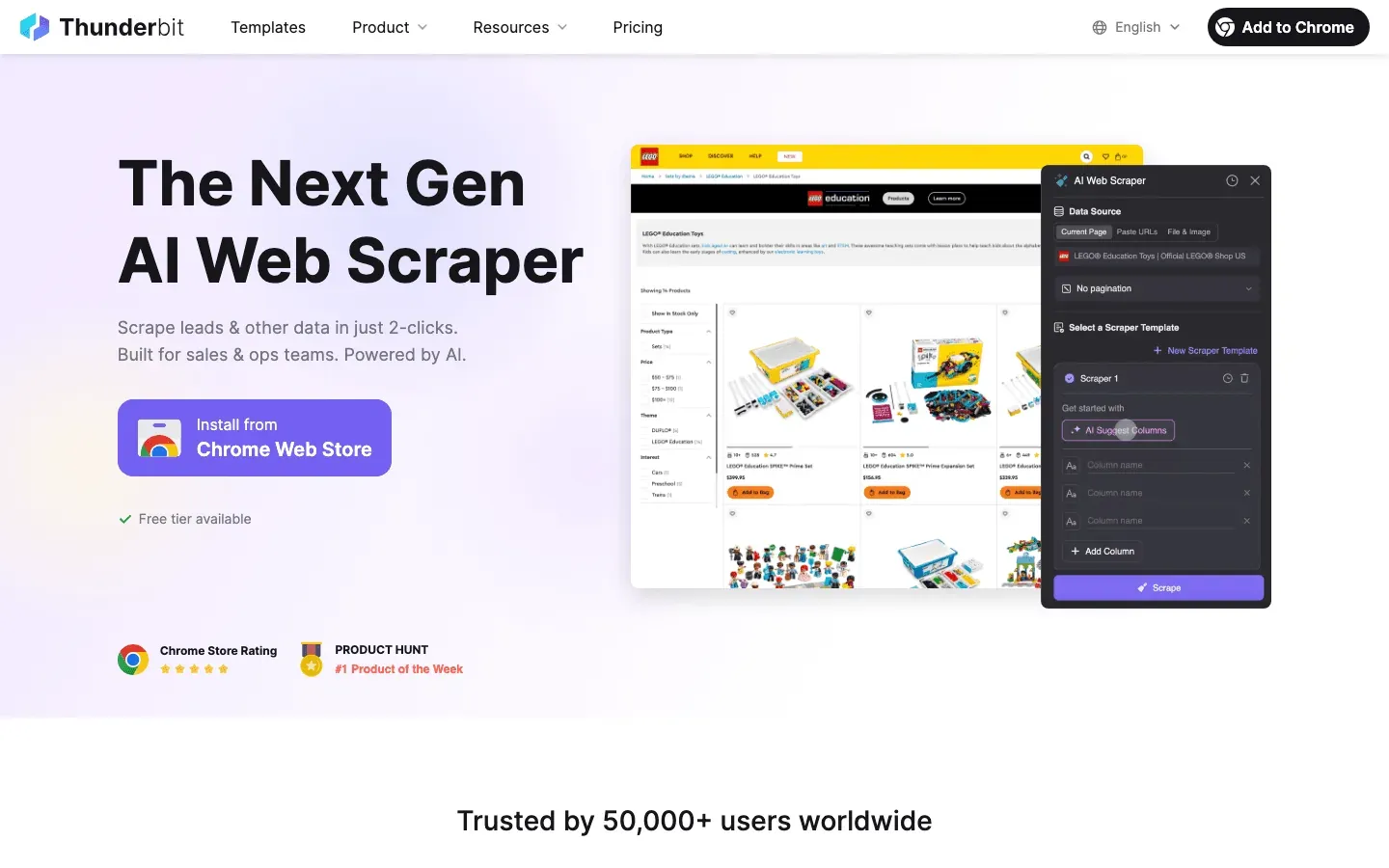
- 의미 기반 전처리: 데이터를 추출하기 전에 Thunderbit이 웹페이지랑 로그를 마크다운 스타일의 구조화된 콘텐츠로 바꿔줘요. 이 “의미 수준” 전처리 덕분에 AI가 읽는 내용의 맥락, 필드, 로직을 진짜로 이해할 수 있어요. Facebook Marketplace처럼 복잡하고 동적이거나 JavaScript가 많은 페이지, 또는 긴 댓글 스레드처럼 기존 DOM 기반 스크래퍼가 잘 못 버티는 환경에서 특히 유용해요.
- 이중 검증: Thunderbit은 공식 크롤러 IP 문서랑 ASN 목록을 빠르게 모아서, 서버 로그랑 대조할 수 있어요. 그 결과로 실제로 믿고 쓸 수 있는 “신뢰 가능한 크롤러 허용 목록”을 만들 수 있죠. 이제 수동으로 하나하나 대조 안 해도 돼요.
- 자동 로그 추출: 원시 로그를 Thunderbit에 넣으면 Excel, Sheets, Airtable 같은 구조화된 표로 변환해주고, 고빈도 방문자, 의심스러운 경로, 알려진 봇까지 라벨링해줘요. 그 다음 결과를 WAF나 CDN에 연결해서 자동 차단, 속도 제한, CAPTCHA 검증에 활용할 수 있고요.
- 규정 준수 및 감사: Thunderbit의 의미 기반 추출이 누가, 언제, 뭐에 접근했고, 그에 대해 어떻게 처리했는지 명확한 감사 기록을 남겨줘요. GDPR, CCPA 같은 규정 준수에 정말 든든해요.
저는 실제로 팀들이 Thunderbit을 써서 크롤러 관리 업무량을 80%까지 줄이고, 어떤 봇이 도움이 되고 어떤 봇이 해가 되며 어떤 봇이 그냥 사칭만 하는지 마침내 파악하는 모습을 봤거든요.
2. Googlebot: 검색엔진의 기준점
Googlebot은 웹 크롤러의 표준이라고 할 만해요. Google Search에 사이트를 색인하는 역할을 하거든요. 이걸 막으면 디지털 매장에 “영업 종료” 팻말 걸어두는 거랑 똑같아요.
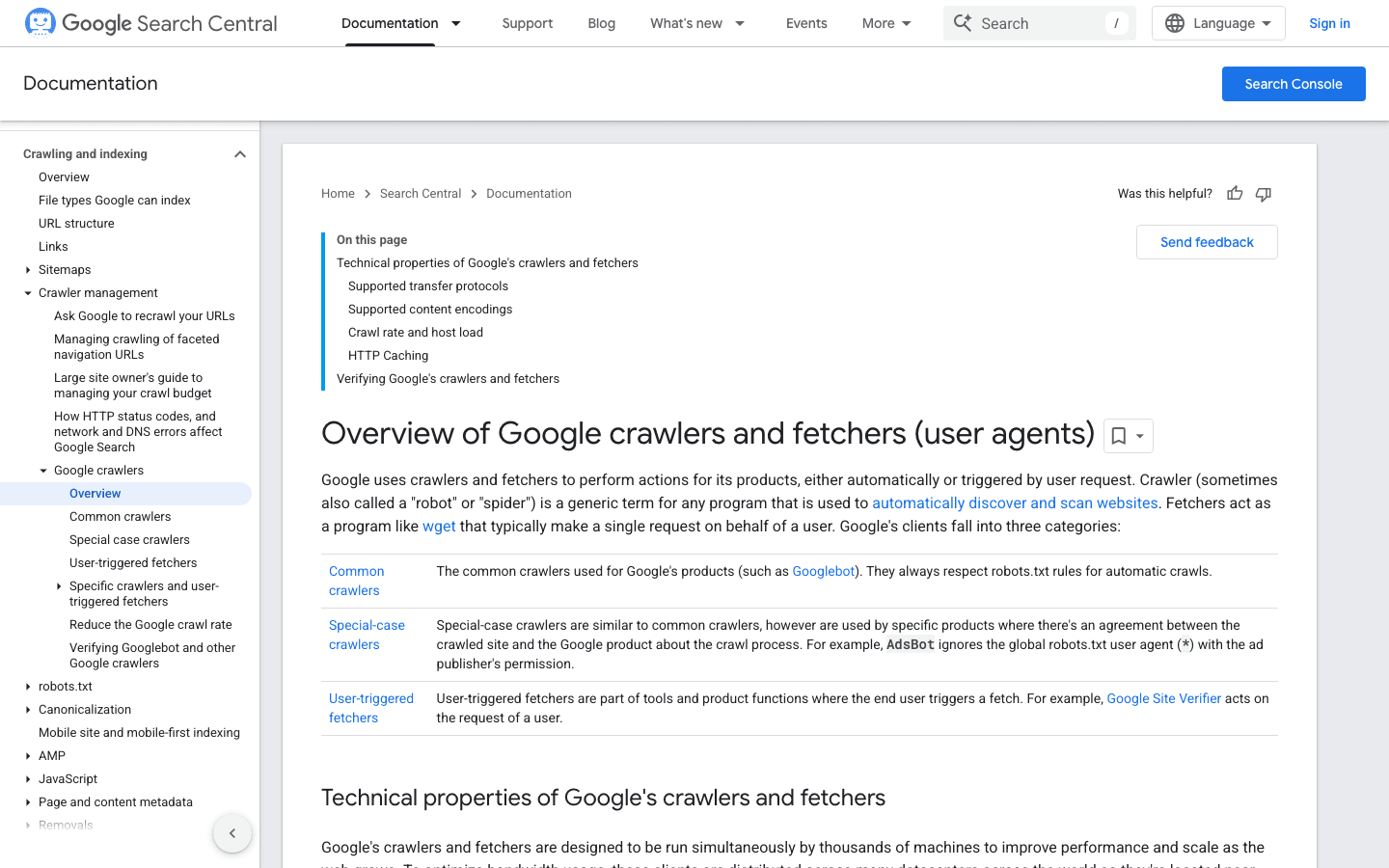
- 사용자 에이전트:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - 검증: Google의 역방향 DNS 방법이나 공식 IP 목록을 사용하세요.
- 관리 팁: Googlebot은 무조건 허용해주세요. robots.txt는 차단용이 아니라 크롤링 방향을 안내하는 용도로 쓰고, 필요하시면 Google Search Console에서 크롤링 속도를 조정하세요.
3. Bingbot: Microsoft의 웹 탐색기
Bingbot은 Bing이랑 Yahoo 검색 결과를 굴려요. 대부분 사이트에서 두 번째로 중요한 크롤러라고 보시면 돼요.
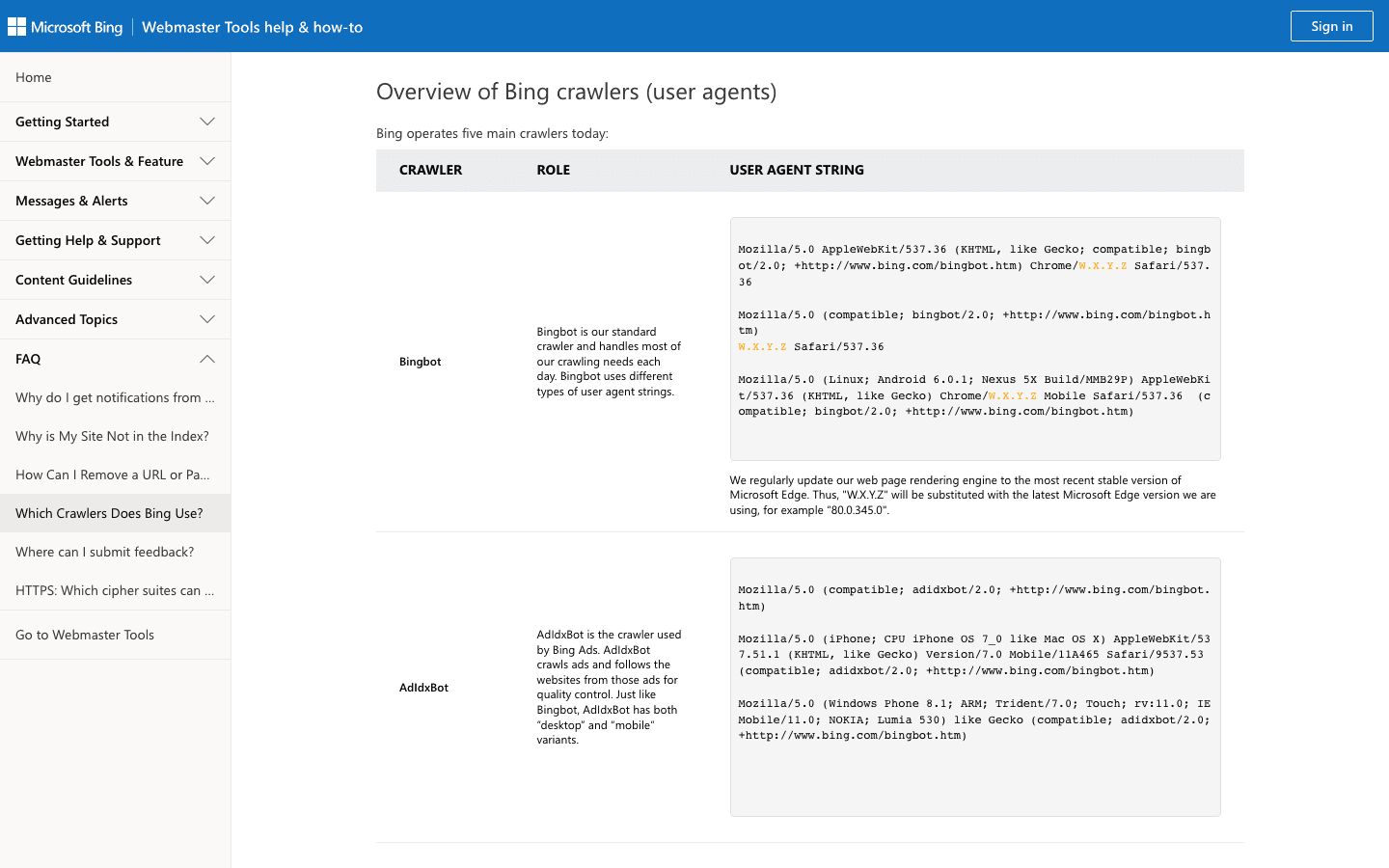
- 사용자 에이전트:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - 검증: Microsoft의 검증 도구랑 공식 IP 목록을 활용하세요.
- 관리 팁: Bingbot은 허용하고, Bing Webmaster Tools에서 크롤링 속도를 관리해주세요. 세부 조정은 robots.txt로 하면 돼요.
4. Baiduspider: 중국의 대표 검색 크롤러
Baiduspider는 중국 검색 트래픽으로 들어가는 관문이에요.
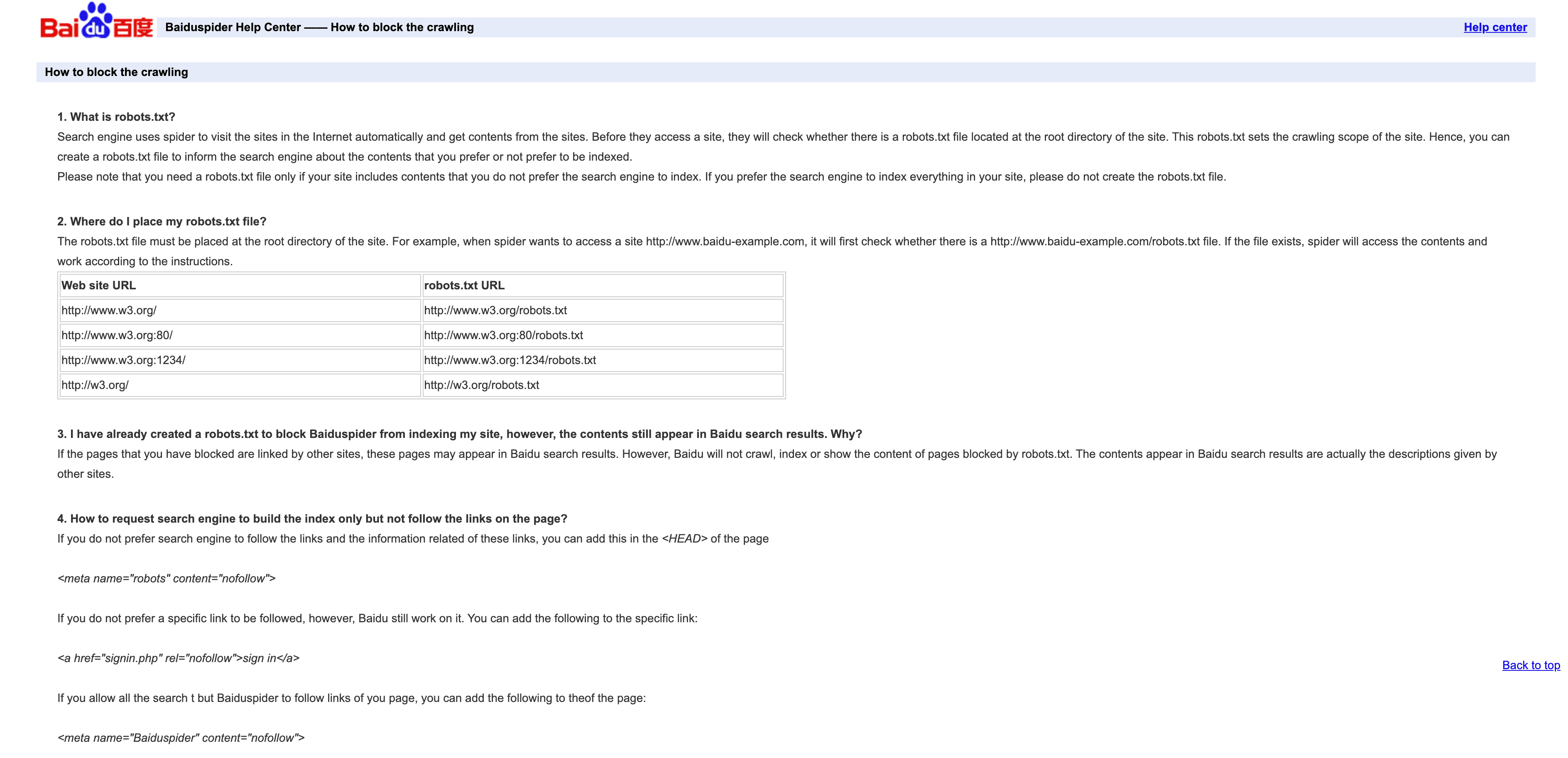
- 사용자 에이전트:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - 검증: 공식 IP 목록이 따로 없어요. 역방향 DNS에서
.baidu.com을 확인할 수는 있는데, 한계가 있다는 점만 기억해두세요. - 관리 팁: 중국 트래픽이 필요하시면 허용하세요. robots.txt로 규칙을 걸 수는 있는데, Baiduspider가 무시하는 경우도 있어요. 중국 SEO가 안 필요하시면 대역폭 절약을 위해 속도 제한이나 차단도 고려해보세요.
5. YandexBot: 러시아의 검색 엔진 크롤러
YandexBot은 러시아랑 CIS 시장에서 필수예요.
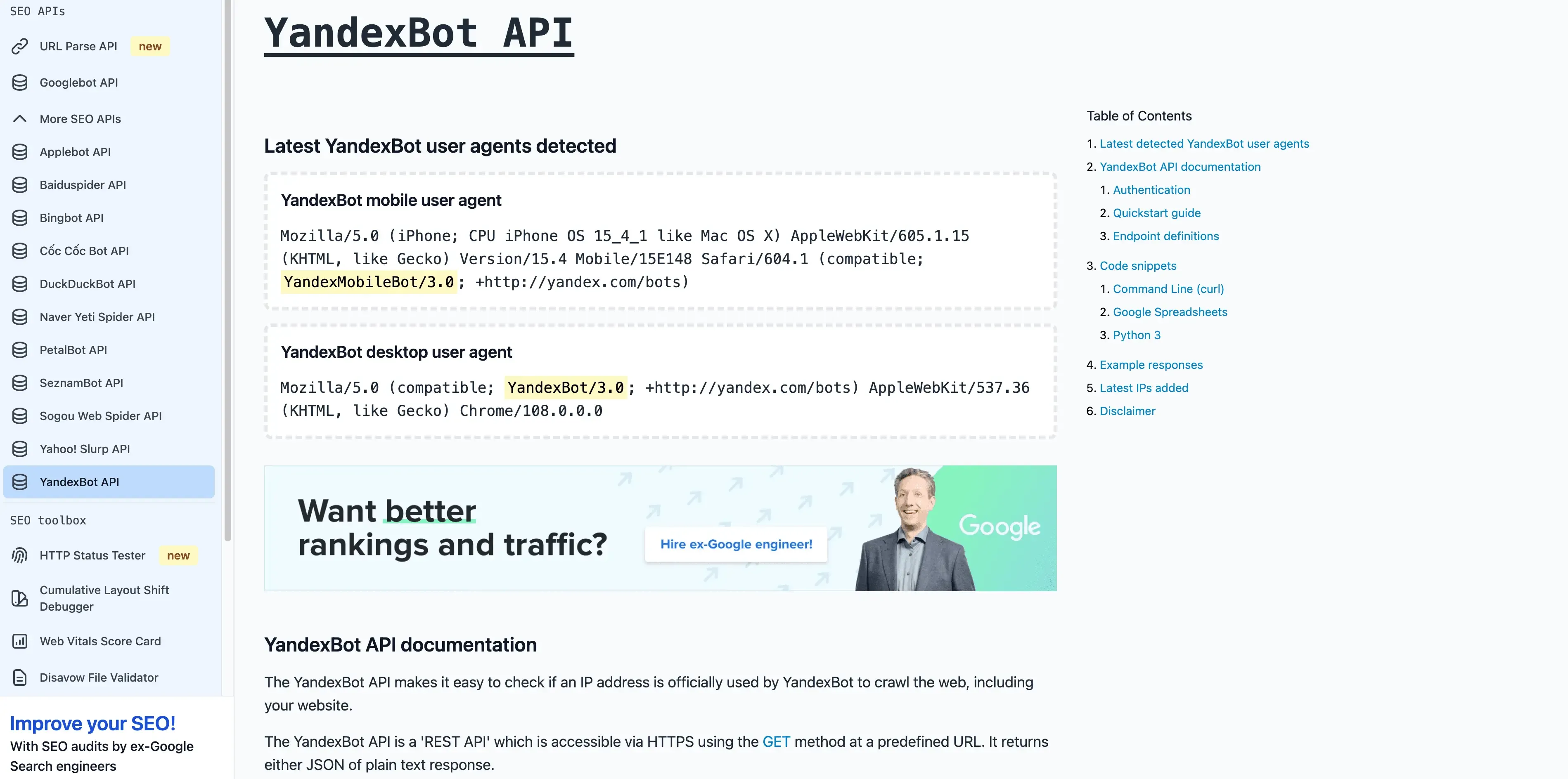
- 사용자 에이전트:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - 검증: 역방향 DNS가
.yandex.ru,.yandex.net, 또는.yandex.com으로 끝나야 해요. - 관리 팁: 러시아어 사용자를 타깃으로 하신다면 허용해주세요. 크롤링 제어는 Yandex Webmaster를 쓰시면 돼요.
6. DuckDuckBot: 프라이버시 중심 검색 크롤러
DuckDuckBot은 DuckDuckGo의 프라이버시 중심 검색을 굴려요.
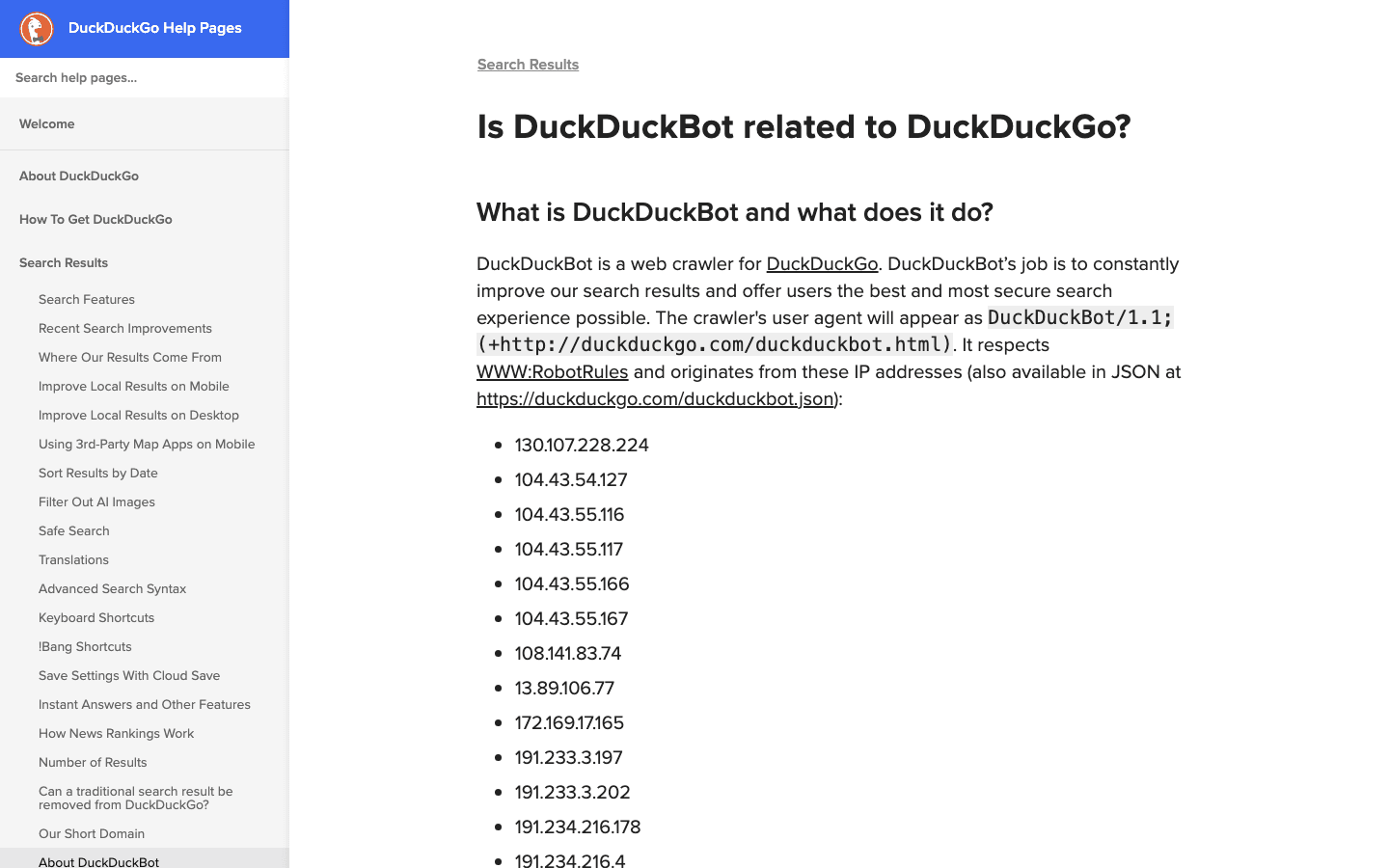
- 사용자 에이전트:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - 검증: 공식 IP 목록(JSON)
- 관리 팁: 프라이버시 중시 사용자한테 관심이 전혀 없으시면 모를까, 그렇지 않으면 허용해주세요. 크롤링 부하도 낮아서 관리도 편해요.
7. AhrefsBot: SEO 및 백링크 분석
AhrefsBot은 대표적인 SEO 도구 크롤러예요. 백링크 분석에는 좋은데, 대역폭을 좀 많이 써요.
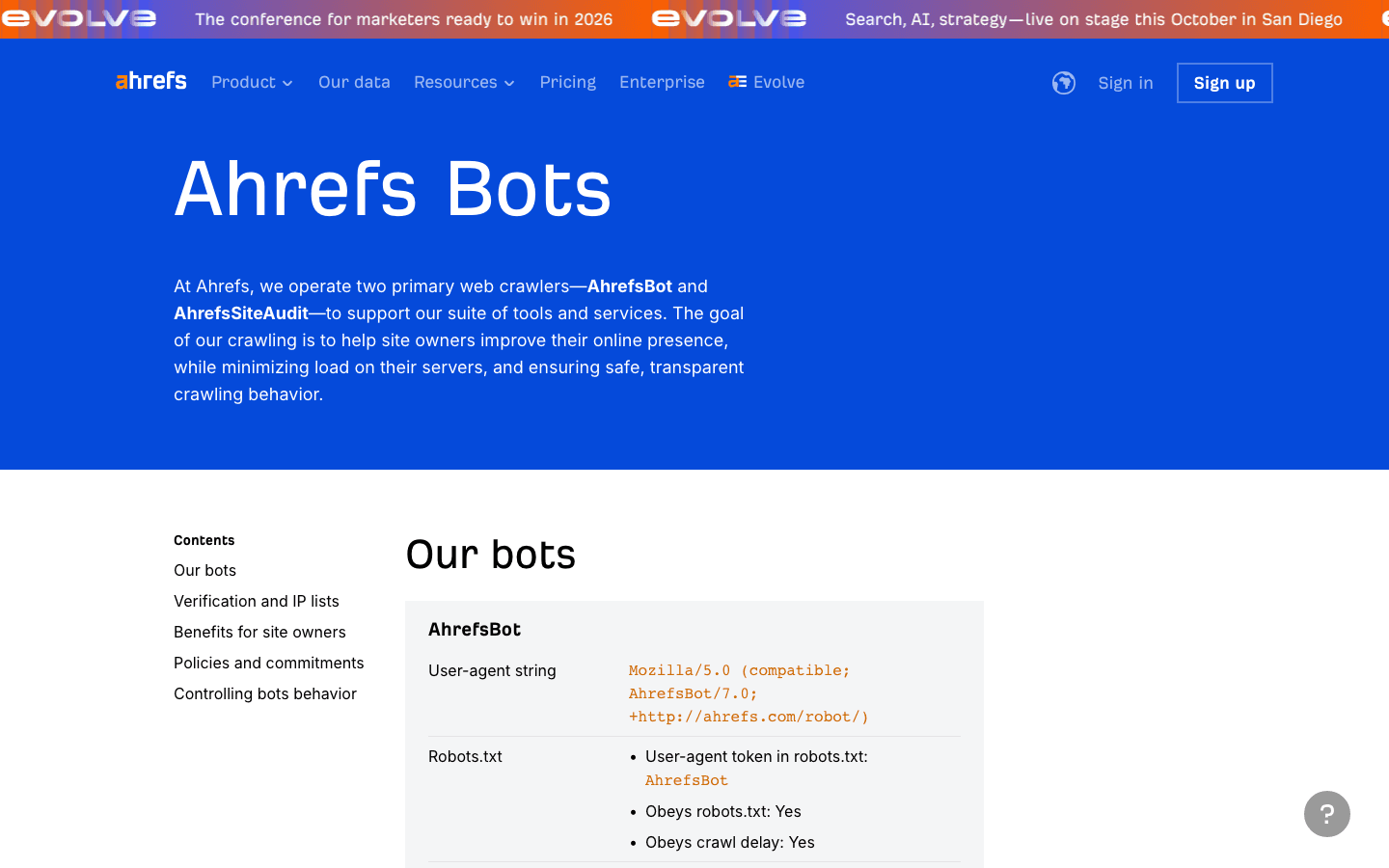
- 사용자 에이전트:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - 검증: 공개 IP 목록은 따로 없어요. 사용자 에이전트랑 역방향 DNS로 확인하세요.
- 관리 팁: Ahrefs를 쓰신다면 허용하세요. robots.txt로 crawl-delay를 적용하거나 차단할 수도 있어요. 이메일로 제외 요청도 가능하고요.
8. SemrushBot: 경쟁 SEO 인사이트
SemrushBot도 또 다른 주요 SEO 크롤러예요.
- 사용자 에이전트:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(그리고SemrushBot-BA,SemrushBot-SI같은 변형 포함) - 검증: 사용자 에이전트로 확인해요. 공개 IP 목록은 따로 없어요.
- 관리 팁: Semrush를 쓰시면 허용하시고, 안 쓰시면 robots.txt나 서버 규칙으로 속도를 제한하거나 차단해주세요.
9. FacebookExternalHit: 소셜 미디어 미리보기 봇
FacebookExternalHit은 Facebook이랑 Instagram 링크 미리보기를 위한 Open Graph 데이터를 가져와요.
- 사용자 에이전트:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - 검증: 사용자 에이전트로 확인하고, IP는 Facebook의 ASN에 속해요.
- 관리 팁: 풍성한 소셜 미리보기를 위해 허용해주세요. 차단하면 Facebook이랑 Instagram에 썸네일이나 요약이 안 떠요.
10. Twitterbot: X(Twitter) 링크 미리보기 크롤러
Twitterbot은 X(Twitter)용 Twitter Card 데이터를 가져와요.
- 사용자 에이전트:
Twitterbot/1.0 - 검증: 사용자 에이전트랑 Twitter ASN(AS13414)으로 확인해요.
- 관리 팁: Twitter 미리보기를 위해 허용하세요. 가장 좋은 결과를 보려면 Twitter Card 메타 태그를 활용하세요.
비교 표: 한눈에 보는 크롤러 목록
| 크롤러 | 용도 | 사용자 에이전트 예시 | 검증 방법 | 비즈니스 영향 | 관리 팁 |
|---|---|---|---|---|---|
| Thunderbit | AI 로그/크롤러 분석 | 해당 없음(도구, 봇 아님) | 해당 없음 | 데이터 관리, 봇 분류 | 로그 추출, 허용 목록 구축에 사용 |
| Googlebot | Google Search 색인 | Googlebot/2.1 | DNS 및 IP 목록 | SEO에 매우 중요 | 항상 허용, Search Console로 관리 |
| Bingbot | Bing/Yahoo 검색 | bingbot/2.0 | DNS 및 IP 목록 | Bing/Yahoo SEO에 중요 | 허용, Bing Webmaster Tools로 관리 |
| Baiduspider | Baidu 검색(중국) | Baiduspider/2.0 | 역방향 DNS, UA 문자열 | 중국 SEO에 핵심 | 중국을 타깃으로 할 때 허용, 대역폭 모니터링 |
| YandexBot | Yandex 검색(러시아) | YandexBot/3.0 | .yandex.ru로 끝나는 역방향 DNS | 러시아/동유럽에 핵심 | RU/CIS를 타깃으로 할 때 허용, Yandex 도구 사용 |
| DuckDuckBot | DuckDuckGo 검색 | DuckDuckBot/1.1 | 공식 IP 목록 | 프라이버시 중심 사용자층 | 허용, 영향 낮음 |
| AhrefsBot | SEO/백링크 분석 | AhrefsBot/7.0 | UA 문자열, 역방향 DNS | SEO 도구, 대역폭 소모 가능 | robots.txt로 허용/제한/차단 |
| SemrushBot | SEO/경쟁 분석 | SemrushBot/1.0(변형 포함) | UA 문자열 | SEO 도구, 공격적일 수 있음 | robots.txt로 허용/제한/차단 |
| FacebookExternalHit | 소셜 링크 미리보기 | facebookexternalhit/1.1 | UA 문자열, Facebook ASN | 소셜 미디어 참여 | 미리보기를 위해 허용, OG 태그 사용 |
| Twitterbot | Twitter 링크 미리보기 | Twitterbot/1.0 | UA 문자열, Twitter ASN | Twitter 참여 | 미리보기를 위해 허용, Twitter Card 태그 사용 |
크롤러 목록 관리: 2025년의 모범 사례
AI로 목록 크롤링 더 알아보기 Get Started Free
- 정기적으로 업데이트하기: 크롤러 환경은 빠르게 변하거든요. 분기별 검토 일정을 잡고, Thunderbit 같은 도구로 공식 목록을 스크래핑해서 비교해보세요(Human Security).
- 믿지 말고 검증하기: 사용자 에이전트랑 IP/ASN을 항상 둘 다 확인하세요. 사칭 봇이 들어와서 분석 수치를 왜곡하거나 데이터를 스크래핑하지 못하게 막아주세요(FriendlyCaptcha).
- 좋은 봇은 허용 목록에 추가하기: 검색이나 소셜 크롤러가 봇 차단 규칙이나 방화벽에 막히지 않게 해주세요.
- 공격적인 봇은 속도 제한 또는 차단: 너무 강하게 요청하는 SEO 도구한테는 robots.txt, crawl-delay, 서버 규칙을 활용하세요.
- 로그 분석 자동화: AI 기반 도구(예: Thunderbit)로 크롤러 활동을 추출, 분류, 라벨링하면 시간을 아끼면서 놓치기 쉬운 추세도 잡아낼 수 있어요.
- SEO, 분석, 보안의 균형 맞추기: 비즈니스를 굴리는 봇은 막지 마시고, 나쁜 봇은 마음대로 날뛰게 두지 마세요.
Thunderbit Chrome 확장 프로그램 다운로드
결론: 크롤러 목록을 최신 상태로, 그리고 실행 가능하게 유지하기
2025년에 크롤러 목록을 관리하는 일은 단순한 IT 업무가 아니에요. SEO, 분석, 보안, 규정 준수까지 다 연결되는 비즈니스 핵심 작업이거든요. 이제 봇이 웹 트래픽 대부분을 차지하는 만큼, 누가 방문하는지, 왜 방문하는지, 그에 대해 뭘 해야 하는지 알아둬야 해요. 목록은 최신으로 유지하고, 자동화할 수 있는 부분은 자동화하고, Thunderbit 같은 도구로 한발 앞서가세요. 웹은 앞으로도 계속 더 바빠질 거예요. 그리고 봇이 지배하는 세상에서는 똑똑하고 실행 가능한 크롤러 전략이 가장 좋은 방어이자 공격이에요.
자주 묻는 질문
1. 왜 최신 크롤러 목록을 유지하는 게 중요할까요?
이제 봇이 전체 웹 트래픽의 절반 이상을 차지하고 있고, 그중 유용한 봇은 일부뿐이거든요. 목록을 최신으로 유지해야 좋은 봇(SEO랑 소셜 미리보기용)은 허용하고, 나쁜 봇은 차단하거나 속도를 제한해서 분석, 대역폭, 데이터 보안을 지킬 수 있어요.
2. 크롤러가 진짜인지 가짜인지 어떻게 알 수 있어요?
사용자 에이전트만 믿지 마세요. 공식 목록이나 역방향 DNS 조회로 IP 주소나 ASN을 꼭 확인하셔야 해요. Thunderbit 같은 도구는 공개된 봇 IP랑 사용자 에이전트에 로그를 대조해서 이 과정을 자동화해줘요.
3. 알 수 없는 봇이 내 사이트를 크롤링하면 어떻게 해야 해요?
사용자 에이전트랑 IP를 한번 조사해보세요. 허용 목록에 없고 알려진 봇이랑도 안 맞으면 속도 제한을 걸거나, 추가 검증을 요구하거나, 차단을 고려해보세요. AI 도구로 새 크롤러를 분류하고 모니터링하는 것도 추천해요.
4. Thunderbit은 크롤러 관리에 어떻게 도움이 되나요?
Thunderbit은 AI로 로그에서 크롤러 활동을 추출, 구조화, 분류해주거든요. 그래서 허용 목록 만들기, 사칭 봇 찾아내기, 정책 집행 자동화가 다 한결 수월해져요. 특히 의미 기반 전처리는 복잡하거나 동적인 사이트에서 진가를 발휘해요.
5. Googlebot이나 Bingbot 같은 주요 크롤러를 차단하면 어떤 위험이 있어요?
검색엔진 크롤러를 막아버리면 사이트가 검색 결과에서 사라져서 유기적 트래픽이 확 줄어들 수 있어요. 방화벽, robots.txt, 봇 차단 규칙을 꼼꼼히 살펴서 정말 중요한 봇은 실수로 막지 않게 해주세요.
더 알아보기:
- AI를 사용해 어떤 웹사이트든 스크래핑하는 방법
- 웹 스크래핑 Python 가이드: 실제 예제로 배우기
- 2025년 최고의 웹 크롤러와 좋은 봇 목록: 식별, 예시, 모범 사례
- 가장 인기 있는 웹 크롤러 봇
AI 기반 크롤러 관리를 위해 Thunderbit 체험하기 Get Started Free




