
웹사이트에서 데이터 수집을 시도하다 보면, 스크롤할 때마다 새로운 내용이 나타나거나, 가격 정보가 로그인 뒤에 숨어 있거나, 레이아웃이 자주 바뀌는 상황을 한 번쯤 겪어보셨을 거예요. 이런 경우 기존의 정적인 웹 스크래퍼로는 한계가 뚜렷하죠. 실제로 는 이미 웹 스크래핑을 통해 대체 데이터를 확보하고 있고, 는 경쟁사 가격 모니터링을 자동화하고 있습니다. 중요한 건, 이 데이터의 상당수가 자바스크립트로 동적으로 로드되거나 사용자 행동 뒤에 숨어 있다는 점입니다. 바로 이런 상황에서 헤드리스 브라우저 자동화, 그리고 Puppeteer 같은 도구가 진가를 발휘합니다.
저는 수년간 자동화와 AI 도구를 개발해왔고, 영업 및 운영팀을 위해 웹사이트를 스크래핑한 경험도 많아요. 그 과정에서 Puppeteer가 기존 스크래퍼로는 접근하기 힘든 데이터를 얼마나 쉽게 뽑아낼 수 있는지 직접 체감했습니다. 하지만 동시에, 코딩이 필요하다는 점이 비즈니스 사용자에게는 큰 허들이 될 수 있다는 것도 느꼈죠. 그래서 이번 가이드에서는 Puppeteer 스크래퍼가 뭔지, 어떻게 활용하는지, 그리고 더 간단한 대안(예: 같은 AI 기반 노코드 웹 스크래퍼)이 필요한 상황까지 꼼꼼하게 안내해드릴게요.
Puppeteer 스크래퍼란? 한눈에 보기
 먼저 기본부터 짚고 넘어가죠. 는 구글에서 만든 오픈소스 Node.js 라이브러리로, 자바스크립트로 헤드리스 Chrome 또는 Chromium 브라우저를 마음대로 조작할 수 있게 해줍니다. 쉽게 말해, 웹페이지를 띄우고, 버튼을 누르고, 폼을 입력하고, 스크롤하고, 데이터를 뽑아내는 모든 과정을 실제 화면 없이 자동으로 처리하는 ‘로봇’을 만드는 셈이죠.
먼저 기본부터 짚고 넘어가죠. 는 구글에서 만든 오픈소스 Node.js 라이브러리로, 자바스크립트로 헤드리스 Chrome 또는 Chromium 브라우저를 마음대로 조작할 수 있게 해줍니다. 쉽게 말해, 웹페이지를 띄우고, 버튼을 누르고, 폼을 입력하고, 스크롤하고, 데이터를 뽑아내는 모든 과정을 실제 화면 없이 자동으로 처리하는 ‘로봇’을 만드는 셈이죠.
Puppeteer의 강점은 뭘까요?
- 동적 콘텐츠 렌더링: 자바스크립트로 불러오는 데이터도 실제 사용자처럼 기다렸다가 추출할 수 있습니다.
- 사용자 행동 시뮬레이션: 클릭, 입력, 스크롤, 팝업 처리 등 다양한 상호작용을 자동화할 수 있어요.
- 상호작용 뒤에 데이터가 나타나는 사이트(예: 이커머스, 소셜 피드, 대시보드 등)에서 특히 강력합니다.
다른 도구와 비교하면?
- Selenium: 브라우저 자동화의 원조 격 도구로, 다양한 브라우저와 언어를 지원하지만 다소 무겁고 구식입니다. 크로스 브라우저 테스트에는 좋지만, Chrome/Node.js 환경에서는 Puppeteer가 더 빠르고 간편하죠.
- Thunderbit: 제가 개인적으로 가장 추천하는 도구입니다. Thunderbit는 브라우저에서 바로 쓸 수 있는 노코드, AI 기반 웹 스크래퍼예요. 스크립트 작성 없이 "AI 필드 추천" 버튼만 누르면 AI가 추출할 데이터를 자동으로 찾아줍니다. 코딩 없이 결과만 빠르게 얻고 싶은 비즈니스 사용자에게 딱이죠(아래에서 더 자세히 설명할게요).
정리하자면: Puppeteer = 코딩이 가능하다면 최대한의 제어력. Thunderbit = 코딩 없이 최대의 편의성.
비즈니스 사용자를 위한 Puppeteer 웹 스크래핑의 가치
이제 웹 스크래핑은 해커나 데이터 과학자만의 영역이 아닙니다. 영업, 운영, 마케팅, 부동산 등 다양한 팀에서 웹 데이터를 활용해 경쟁력을 높이고 있죠. 특히 중요한 정보가 동적 사이트에 숨어 있는 경우, Puppeteer가 그 데이터를 여는 열쇠가 됩니다.
실제 활용 사례를 보면:
또한 이 업무 시간의 1/4을 반복적인 데이터 수집에 쓰고 있다는 점을 생각하면, 웹 스크래핑 자동화는 이제 선택이 아니라 필수 경쟁력입니다.
시작하기: Puppeteer 스크래퍼 환경 세팅
이제 직접 해볼 차례예요. 자바스크립트에 익숙하다면 10분 안에 Puppeteer를 실행할 수 있습니다.
1. Node.js 설치
Puppeteer는 Node.js 환경에서 동작합니다. 에서 최신 LTS 버전을 받아 설치하세요.
2. 새 프로젝트 폴더 만들기
터미널에서 아래처럼 입력하세요:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteer 설치
1npm install puppeteer설치하면 약 100MB의 Chromium 브라우저도 같이 받아집니다.
4. 첫 스크립트 작성
scrape.js 파일을 만들어 아래처럼 작성하세요:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();실행:
1node scrape.js“Page title: Example Domain”이 뜨면, 크롬 자동화에 성공한 겁니다!
Puppeteer 웹 스크래핑 스크립트 실전 예제
실제 데이터를 추출해볼까요? 예를 들어 에서 명언을 수집한다고 가정해봅시다.
1단계: 페이지 이동
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });2단계: 데이터 추출
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);3단계: 페이지네이션 처리
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // 위와 같이 명언 추출
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}4단계: JSON 파일로 저장
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));이렇게 하면 페이지 이동, 데이터 추출, 페이지네이션, 저장까지 한 번에 끝낼 수 있습니다.
고급 Puppeteer 스크래퍼: 동적 콘텐츠 제대로 다루기
실제 사이트는 단순 리스트가 아닌 경우가 많죠. 이런 상황은 어떻게 처리할까요?
1. 동적 요소 대기
1await page.waitForSelector('.product-list-item');원하는 데이터가 로드될 때까지 기다립니다.
2. 사용자 행동 시뮬레이션
- 버튼 클릭:
await page.click('#load-more'); - 입력 필드에 타이핑:
await page.type('#search', 'laptop'); - 무한 스크롤 처리:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. 로그인 처리
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. AJAX 데이터 처리 데이터가 DOM이 아니라 API 응답으로 올 때는 네트워크 응답을 가로채서 처리할 수 있습니다:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // 데이터 처리
5 }
6});실전 예시: 이커머스 사이트에서 상품 데이터 스크래핑
이제 모든 과정을 합쳐볼게요. 로그인 후 (데모) 이커머스 사이트에서 상품명, 가격, 이미지를 추출한다고 가정합니다.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // 1단계: 로그인
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // 2단계: 카테고리 페이지 이동
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // 3단계: 상품 데이터 추출
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // 4단계: JSON 파일로 저장
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();이 스크립트 하나로 로그인, 이동, 추출, 저장까지 자동으로 처리할 수 있습니다. 더 복잡한 작업이 필요하다면 페이지네이션 반복이나 상세 페이지 진입도 추가할 수 있어요.
Thunderbit: Puppeteer 스크래퍼를 AI로 더 쉽게
여기까지 읽으셨다면, "좋긴 한데 매번 코드를 짜는 건 부담스럽다"는 생각이 드실 수도 있습니다. 그래서 저희는 을 만들었어요.
Thunderbit의 차별점은?
- 코딩 필요 없음: 만 설치하면, 원하는 페이지에서 "AI 필드 추천"만 누르면 데이터 추출이 시작됩니다.
- AI 기반 필드 자동 인식: Thunderbit가 페이지를 분석해 "상품명", "가격", "이미지" 등 주요 컬럼을 자동으로 추천해줘요.
- 동적 콘텐츠 완벽 지원: 무한 스크롤, 팝업, 하위 페이지 등도 AI가 알아서 클릭하고, 상세 페이지까지 방문해 데이터를 풍부하게 수집합니다.
- 즉시 내보내기: 추출한 데이터를 엑셀, 구글 시트, Notion, Airtable 등으로 한 번에 내보낼 수 있습니다. 추가 비용 없이 바로 사용 가능해요.
- 인기 사이트 템플릿 제공: Amazon, Zillow, LinkedIn 등 자주 쓰는 사이트는 바로 쓸 수 있는 템플릿이 준비되어 있습니다.
- 클라우드/브라우저 동시 지원: 대량 작업이 필요할 때는 클라우드에서 최대 50개 페이지를 동시에 스크래핑할 수 있습니다.
Thunderbit를 써본 분들은 "이 데이터만 있으면 좋겠는데..."에서 "엑셀 파일로 바로 받았습니다!"로 단 5분 만에 바뀌는 경험을 하셨죠. 그리고 가장 큰 장점은, 웹사이트가 바뀌어도 스크립트가 깨질 걱정 없이 Thunderbit의 AI가 자동으로 대응한다는 점입니다.
Puppeteer vs. Thunderbit: 어떤 웹 스크래핑 도구를 골라야 할까?
그럼 어떤 도구를 써야 할까요? 팀별로 아래처럼 정리해볼 수 있습니다:
| 비교 항목 | Puppeteer (코드 기반) | Thunderbit (노코드, AI) |
|---|---|---|
| 사용 난이도 | 자바스크립트 및 DOM 지식 필요 | 클릭만으로 사용, AI가 필드 추천 |
| 설정 속도 | 복잡한 작업은 수 시간~수일 소요 | 몇 분 만에 설치 후 바로 사용 |
| 제어/유연성 | 최대: 모든 로직 커스터마이즈, 코드 통합 가능 | 표준 작업에 매우 강력, 복잡한 커스텀 워크플로우에는 제한 |
| 동적 콘텐츠 처리 | 대기, 클릭, 스크롤 등 직접 스크립팅 필요 | AI가 동적 콘텐츠, 페이지네이션, 하위 페이지 자동 처리 |
| 유지보수 | 스크립트 직접 관리, 사이트 변경 시 직접 수정 필요 | AI가 레이아웃 변경에 자동 대응, 사용자 유지보수 부담 적음 |
| 데이터 내보내기 | 내보내기 로직 직접 작성 | 엑셀, 시트, Notion, Airtable, CSV, JSON 등 원클릭 내보내기 |
| 추천 대상 | 개발자, 고도화/대규모 스크래핑 필요 시 | 비즈니스 사용자, 빠른 프로젝트, 비전문가 팀 |
| 비용 | 무료(시간 및 인프라 제외) | 무료 플랜 제공, 유료는 크레딧 기반 (자세한 내용은 Thunderbit 가격 참고) |
핵심 요약:
- Puppeteer는 완전한 제어가 필요하거나, 개발 리소스가 있고, 대규모 통합이 필요한 경우에 적합합니다.
- Thunderbit는 빠른 결과, 코딩 없는 사용, 비전문가 팀의 데이터 활용에 최적입니다.
실제로 많은 팀이 두 가지를 병행합니다. Thunderbit로 빠른 프로토타입과 단기 프로젝트를, Puppeteer로 복잡한 통합이나 특수 케이스를 처리하는 식이죠.
단계별 체크리스트: 성공적인 Puppeteer 웹 스크래핑 프로젝트
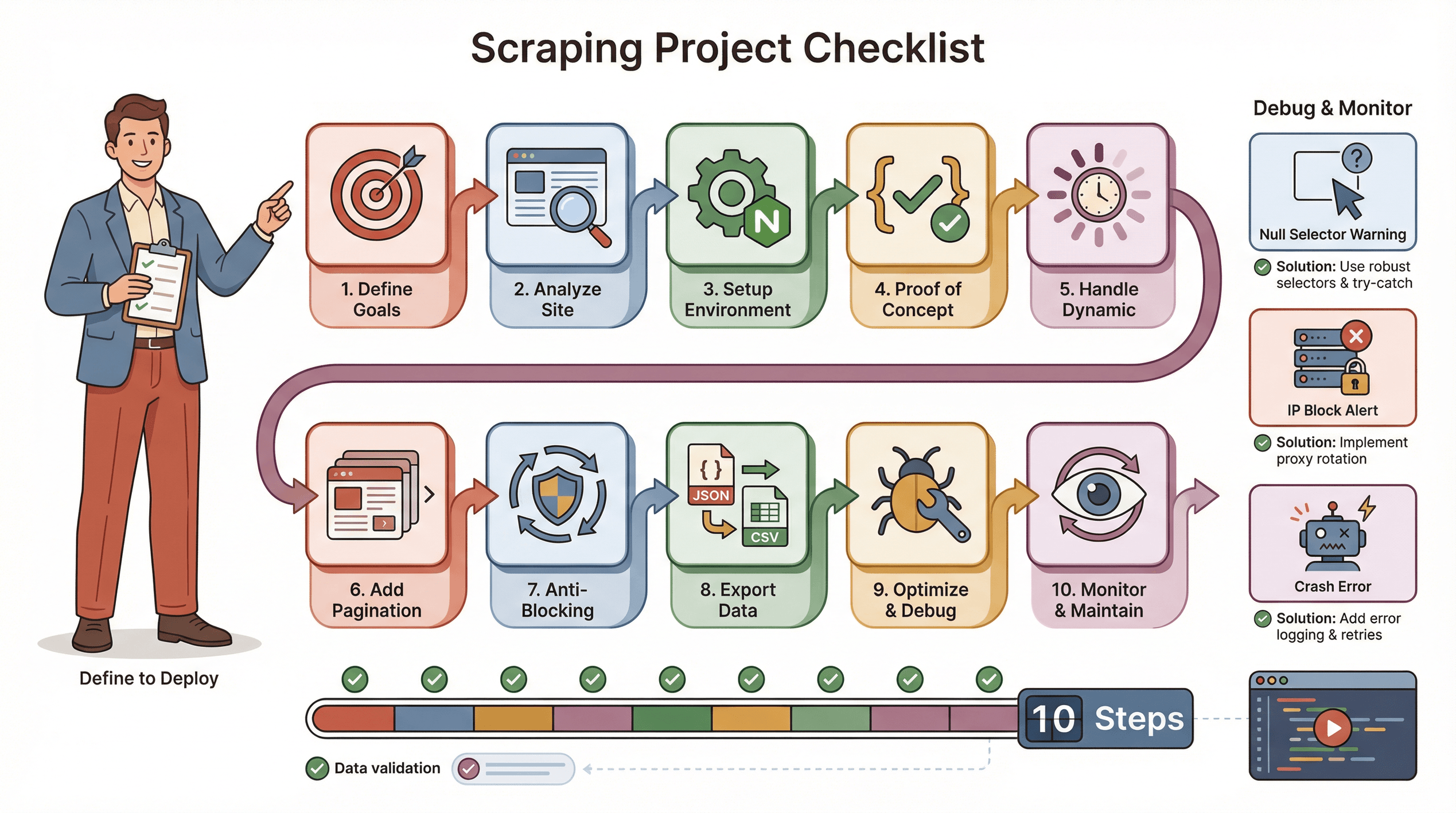 Puppeteer 스크래핑 프로젝트를 매끄럽게 진행하려면 아래 체크리스트를 참고하세요:
Puppeteer 스크래핑 프로젝트를 매끄럽게 진행하려면 아래 체크리스트를 참고하세요:
- 목표 정의: 어떤 데이터를, 어디서 추출할지 명확히 정하세요.
- 사이트 분석: 동적 사이트인지, 로그인 필요 여부, 봇 차단 여부를 확인합니다.
- 환경 구축: Node.js, Puppeteer, 보조 라이브러리 설치.
- PoC 작성: 한 페이지에서 셀렉터를 정확히 잡아 테스트합니다.
- 동적 콘텐츠 처리:
waitForSelector, 클릭/스크롤 등 시뮬레이션 추가. - 페이지네이션/반복 처리: 전체 페이지를 빠짐없이 수집합니다.
- 차단 방지 전략: 지연 랜덤화, User-Agent 설정, 프록시 활용 등 적용.
- 데이터 내보내기 및 검증: JSON/CSV로 저장 후 데이터 완성도 확인.
- 최적화 및 예외 처리: try/catch, 진행 로그, 누락 데이터 처리 등 추가.
- 모니터링 및 유지보수: 사이트 변경에 대비해 스크립트 업데이트 준비.
문제 해결 팁:
- 셀렉터가 null이면 HTML 구조와 대기 조건을 다시 확인하세요.
- 차단되면 속도를 늦추거나 IP를 바꾸고, 스텔스 플러그인도 고려해보세요.
- 스크립트가 중단되면 메모리 누수, 예외 미처리 여부를 점검하세요.
결론 및 핵심 요약
웹 스크래핑은 데이터 중심 조직의 필수 역량이 됐습니다. Puppeteer는 동적, 자바스크립트 기반 사이트에서도 강력한 데이터 추출력을 제공하지만, 코딩과 유지보수가 필요합니다. 반면, Thunderbit는 코딩 없이 빠르고 유연하게 데이터를 추출할 수 있는 AI 기반 노코드 대안으로, 비즈니스 사용자에게 특히 잘 맞아요.
추천 가이드:
- 기술적 커스터마이징이 필요하다면 Puppeteer로 시작하세요.
- 속도, 간편함, 유지보수 최소화를 원한다면 를 써보세요(무료 크롬 확장 프로그램도 있습니다).
- 대부분의 팀은 두 가지를 병행하면 웹 데이터 수집의 99%를 커버할 수 있습니다.
이런 가이드가 더 궁금하다면 에서 다양한 튜토리얼, 비교, AI 웹 스크래핑 최신 정보를 확인해보세요.
자주 묻는 질문(FAQ)
1. Puppeteer 스크래퍼란 무엇이며, 왜 웹 스크래핑에 쓰이나요?
Puppeteer는 자바스크립트로 헤드리스 크롬 브라우저를 제어할 수 있는 Node.js 라이브러리입니다. 동적 콘텐츠 로딩, 사용자 행동 시뮬레이션, 기존 스크래퍼로는 어려운 데이터 추출이 가능해 웹 스크래핑에 널리 활용됩니다.
2. Puppeteer와 Selenium, Thunderbit의 차이점은?
Selenium은 다양한 브라우저와 언어를 지원하지만 무겁고 느릴 수 있습니다. Puppeteer는 Chrome/Node.js에 최적화되어 빠르고 간결합니다. Thunderbit는 코딩 없이 AI로 누구나 쉽게 데이터 추출이 가능한 노코드 도구입니다.
3. Puppeteer 웹 스크래핑의 주요 비즈니스 효과는?
데이터 수집 자동화로 시간 절약, 오류 감소, 실시간 인사이트 확보가 가능합니다. 리드 생성, 가격 모니터링, 시장 조사 등 다양한 업무에 활용됩니다.
4. Puppeteer 스크래핑의 가장 큰 어려움은?
동적 콘텐츠 처리, 봇 차단 우회, 사이트 변경 시 스크립트 유지보수가 가장 큰 도전입니다. 대기, 상호작용, 예외 처리를 직접 코딩해야 합니다.
5. Puppeteer 대신 Thunderbit를 써야 하는 경우는?
코딩 없이 빠른 결과가 필요하거나, 비전문가 팀이 데이터를 활용해야 할 때 Thunderbit가 적합합니다. 표준 스크래핑, 단기 프로젝트, 엑셀/구글 시트 내보내기 등에서 강점을 보입니다.
더 똑똑한 웹 스크래핑을 원한다면 또는 에서 더 많은 가이드를 확인해보세요. 즐거운 스크래핑 하세요!
더 알아보기