
스크롤할 때마다 내용이 로드되거나, 가격이 로그인 뒤에 숨겨져 있거나, 몇 주마다 레이아웃이 바뀌는 웹사이트에서 데이터를 가져보려 한 적이 있다면, 그 일이 얼마나 번거로운지 아실 거예요. 정적인 스크래퍼만으로는 이제 부족합니다. 실제로 은 이미 대체 데이터 확보를 위해 웹 스크래핑을 활용하고 있고, 는 경쟁사 가격 모니터링을 자동화하고 있어요. 그런데 핵심은, 이런 데이터의 상당수가 JavaScript로 로드되고 사용자 상호작용 뒤에 숨어 있는 동적 사이트에 있다는 점입니다. 바로 이런 상황에서 헤드리스 브라우저 자동화, 그리고 Puppeteer 같은 도구가 필요해요.
오랫동안 자동화와 AI 도구를 만들어 왔고, 영업 및 운영팀을 위해 적잖은 웹사이트를 스크래핑해 온 사람으로서 말씀드리자면, Puppeteer는 전통적인 스크래퍼가 놓치는 데이터를 정말 많이 열어 줍니다. 하지만 비즈니스 사용자에게는 코딩 부담이 큰 걸림돌이 되기도 해요. 그래서 이 가이드에서는 Puppeteer 스크래퍼가 정확히 무엇인지, 웹 스크래핑에 어떻게 쓰는지, 그리고 처럼 더 간단한 AI 기반 노코드 웹 스크래퍼를 언제 선택하면 좋은지도 함께 살펴볼게요.
Puppeteer 스크래퍼란? 간단한 개요
 기본부터 시작해 볼게요. 는 Google이 만든 오픈소스 Node.js 라이브러리로, JavaScript를 사용해 헤드리스 Chrome 또는 Chromium 브라우저를 제어할 수 있게 해 줍니다. 쉽게 말하면, 웹페이지를 열고 버튼을 클릭하고, 폼을 작성하고, 스크롤하고, 가장 중요한 데이터까지 가져올 수 있는 로봇을 하나 두는 것과 같아요. 화면에는 아무것도 띄우지 않은 채로요.
기본부터 시작해 볼게요. 는 Google이 만든 오픈소스 Node.js 라이브러리로, JavaScript를 사용해 헤드리스 Chrome 또는 Chromium 브라우저를 제어할 수 있게 해 줍니다. 쉽게 말하면, 웹페이지를 열고 버튼을 클릭하고, 폼을 작성하고, 스크롤하고, 가장 중요한 데이터까지 가져올 수 있는 로봇을 하나 두는 것과 같아요. 화면에는 아무것도 띄우지 않은 채로요.
Puppeteer가 특별한 이유는 무엇일까요?
- 동적 콘텐츠를 렌더링할 수 있어요. 즉, 실제 사용자처럼 JavaScript 로딩을 기다립니다.
- 사용자 동작을 시뮬레이션할 수 있어요. 클릭, 입력, 스크롤, 팝업 처리까지 가능합니다.
- 이커머스 목록, 소셜 피드, 대시보드처럼 상호작용 후에야 데이터가 나타나는 사이트를 스크래핑하는 데 아주 적합해요.
다른 도구와 비교하면 어떨까요?
- Selenium: 브라우저 자동화의 원조예요. 다양한 브라우저와 언어를 지원하지만, 다소 무겁고 조금 더 예전 방식에 가깝습니다. 크로스 브라우저 테스트에는 좋지만, Chrome/Node.js 프로젝트에서는 Puppeteer가 더 빠릿해요.
- Thunderbit: 제가 가장 기대하는 부분이에요. Thunderbit는 브라우저 안에서 작동하는 AI 기반 노코드 웹 스크래퍼입니다. 스크립트를 직접 작성하는 대신 “AI 필드 추천”만 클릭하면 AI가 무엇을 추출해야 할지 알아서 판단해 줘요. 코딩 없이 결과만 얻고 싶은 비즈니스 사용자에게 딱 맞습니다(이 부분은 뒤에서 더 자세히 설명할게요).
한마디로 정리하면: Puppeteer = 최대한의 제어력(코딩할 수 있다면). Thunderbit = 최대한의 편의성(코딩하고 싶지 않다면).
비즈니스 사용자에게 Puppeteer 웹 스크래핑이 중요한 이유
현실적으로 말해 볼게요. 웹 스크래핑은 더 이상 해커나 데이터 과학자만의 일이 아니에요. 영업, 운영, 마케팅, 심지어 부동산 팀까지 웹 데이터를 활용해 경쟁 우위를 만들고 있습니다. 그리고 중요한 비즈니스 정보가 동적 사이트 뒤에 갇혀 있는 경우가 많기 때문에, Puppeteer가 이를 열어 주는 핵심 열쇠가 되곤 해요.
실제 활용 사례를 보면:
| 활용 사례 | 혜택을 보는 팀 | 영향 / 투자수익률(ROI) |
|---|---|---|
| 리드 생성 | 영업, 사업개발 | 잠재 고객 리스트 구축을 자동화하고, 담당자당 주 8시간 이상 절약(사례 연구) |
| 가격 모니터링 | 이커머스, 제품 운영 | 경쟁사 가격을 실시간 추적하고, 한 대기업은 연간 380만 달러를 절감(출처) |
| 시장 조사 | 마케팅, 전략, 재무 | 투자 자문사의 67%가 웹 스크래핑 데이터를 사용하며, 일부 사례에서는 최대 890% ROI 달성(출처) |
| 부동산 데이터 통합 | 중개인, 분석가 | 50개 이상의 매물 페이지를 몇 시간 대신 몇 분 만에 스크래핑(출처) |
| 컴플라이언스 추적 | 운영, 법무 | 모니터링을 자동화해 한 보험사는 5천만 달러의 벌금을 피함(출처) |
그리고 이것도 잊으면 안 돼요: 은 주간 업무의 4분의 1을 데이터 수집 같은 반복 작업에 씁니다. 웹 스크래핑으로 이를 자동화하는 건 단순히 있으면 좋은 기능이 아니라, 경쟁력 그 자체예요.
시작하기: Puppeteer 스크래퍼 설정하기
이제 직접 해 볼 준비가 되셨나요? JavaScript를 조금 다룰 수 있다는 전제하에, 10분 안에 Puppeteer를 실행하는 방법을 알려드릴게요.
1. Node.js 설치하기
Puppeteer는 Node.js에서 실행됩니다. 에서 최신 LTS 버전을 다운로드하세요.
2. 새 프로젝트 폴더 만들기
터미널을 열고 다음을 실행하세요:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Puppeteer 설치하기
1npm install puppeteer이 과정에서 호환되는 Chromium 버전도 함께 다운로드됩니다(약 100MB).
4. 첫 스크립트 만들기
scrape.js라는 파일을 만드세요:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('페이지 제목:', title);
8 await browser.close();
9})();다음과 같이 실행합니다:
1node scrape.js“페이지 제목: Example Domain”이 보이면 성공이에요. 방금 Chrome 자동화를 해낸 거예요!
첫 번째 Puppeteer 웹 스크래핑 스크립트 만들기
이제 실전으로 가 볼게요. 예를 들어 에서 명언을 스크래핑하고 싶다고 해봅시다(스크래퍼 학습용 데모 사이트예요).
1단계: 페이지로 이동하기
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });2단계: 데이터 추출하기
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);3단계: 페이지네이션 처리하기
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // 위와 같이 명언 추출
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}4단계: JSON으로 저장하기
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));이제 기본적인 Puppeteer 스크래퍼가 페이지를 이동하고, 데이터를 추출하고, 페이지네이션을 따라가고, 저장까지 해냈습니다.
고급 Puppeteer 스크래퍼 기법: 동적 콘텐츠 처리하기
실제 사이트는 정적인 목록처럼 단순하지 않은 경우가 많아요. 이런 까다로운 요소를 어떻게 다루는지 살펴볼게요.
1. 동적 요소를 기다리기
1await page.waitForSelector('.product-list-item');이렇게 하면 원하는 콘텐츠가 로드된 뒤에 데이터를 가져올 수 있어요.
2. 사용자 동작 시뮬레이션하기
- 버튼 클릭:
await page.click('#load-more'); - 필드에 입력:
await page.type('#search', 'laptop'); - 무한 스크롤 처리:
1// 참고: page.waitForTimeout은 Puppeteer v22에서 제거되었습니다. 대신 일반 promise를 사용하세요. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. 로그인 처리하기**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. AJAX로 로드된 데이터 처리하기 때로는 데이터가 DOM에 있지 않고 API 호출로 들어오기도 해요. 이런 경우 네트워크 응답을 가로챌 수 있습니다:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // 데이터 처리
5 }
6});실제 예시: 이커머스 사이트에서 제품 데이터 스크래핑하기
이제 모든 걸 한 번에 적용해 볼게요. 로그인 후 데모 이커머스 사이트에서 제품명, 가격, 이미지를 스크래핑한다고 상상해 봅시다.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // 1단계: 로그인
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // 2단계: 카테고리 페이지로 이동
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // 3단계: 제품 추출
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // 4단계: JSON으로 저장
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();이 스크립트는 로그인하고, 이동하고, 스크래핑하고, 저장까지 모두 자동으로 해 줍니다. 더 고급 작업이 필요하다면 페이지네이션 루프를 추가하거나 각 제품 페이지를 클릭해 더 자세한 정보까지 가져올 수 있어요.
Thunderbit: AI로 Puppeteer 스크래퍼를 더 간단하게
여기까지 읽고 “좋긴 한데, 새 데이터셋이 필요할 때마다 코드를 쓰고 싶지는 않다”라고 생각하셨다면, 그건 아주 자연스러운 반응이에요. 바로 그 이유로 를 만들었습니다.
Thunderbit가 다른 이유는 무엇일까요?
- 코드가 필요 없어요: 을 설치하고, 스크래핑할 페이지를 연 뒤 “AI 필드 추천”을 클릭하기만 하면 됩니다.
- AI 기반 필드 감지: Thunderbit가 페이지를 읽고 “제품명”, “가격”, “이미지” 같은 추출할 최적의 열을 추천해 줘요.
- 동적 콘텐츠 처리: 무한 스크롤, 팝업, 하위 페이지도 괜찮아요. Thunderbit의 AI가 페이지네이션을 따라가고, 필요하면 각 제품 상세 페이지까지 방문해 데이터를 풍부하게 만들어 줍니다.
- 즉시 내보내기: Excel, Google Sheets, Notion, Airtable로 데이터를 한 번에 보낼 수 있어요. 내보내기에 추가 요금도 없습니다.
- 인기 사이트용 템플릿: Amazon, Zillow, LinkedIn을 스크래핑해야 하나요? Thunderbit에는 바로 쓸 수 있는 템플릿이 있어 설정이 필요 없어요.
- 클라우드 또는 브라우저 스크래핑: 대규모 작업이라면 Thunderbit가 클라우드에서 한 번에 최대 50페이지까지 스크래핑할 수 있어요.
저는 사용자들이 “이 데이터를 얻을 수만 있으면 좋겠다”에서 “벌써 스프레드시트가 준비됐어요”로 바뀌는 과정을 5분도 안 돼서 보는 일을 자주 해요. 그리고 가장 좋은 점은? 웹사이트가 바뀔 때마다 스크립트가 깨질까 걱정하지 않아도 된다는 거예요. Thunderbit의 AI가 그때그때 적응해 주니까요.
Puppeteer vs. Thunderbit: 올바른 웹 스크래핑 도구 고르기
그렇다면 무엇을 써야 할까요? 팀 관점에서 이렇게 정리할 수 있어요.
| 요인 | Puppeteer(코드 기반) | Thunderbit(노코드, AI) |
|---|---|---|
| 사용 편의성 | JavaScript와 DOM 지식이 필요함 | 클릭만 하면 됨, AI가 필드를 추천함 |
| 설정 속도 | 복잡한 작업은 몇 시간에서 며칠까지 걸릴 수 있음 | 몇 분이면 충분—설치하고 바로 사용 |
| 제어력/유연성 | 최고 수준: 어떤 맞춤 로직이든 스크립트로 구현하고 다른 코드와 통합 가능 | 일반적인 경우에는 충분히 강력하지만, 아주 복잡한 워크플로에는 덜 적합 |
| 동적 콘텐츠 처리 | 대기, 클릭, 스크롤을 직접 스크립팅해야 함 | 내장된 AI가 동적 콘텐츠, 페이지네이션, 하위 페이지를 자동으로 처리 |
| 유지보수 | 스크립트는 직접 관리해야 하며, 사이트가 바뀌면 업데이트가 필요함 | AI가 레이아웃 변경에 적응해 사용자 유지보수 부담이 적음 |
| 데이터 내보내기 | 내보내기 로직을 직접 작성해야 함 | Excel, Sheets, Notion, Airtable, CSV, JSON으로 한 번에 내보내기 |
| 최적의 대상 | 개발자, 고도로 맞춤화된 작업, 대규모 스크래핑 | 비즈니스 사용자, 빠른 프로젝트, 비기술팀 |
| 비용 | 무료(시간과 인프라 비용은 제외) | 무료 플랜 제공, 크레딧 기반 유료 플랜(자세한 내용은 Thunderbit 요금제 참고) |
결론적으로:
- Puppeteer를 사용하세요: 완전한 제어가 필요하거나, 코딩 리소스가 있거나, 스크래핑을 더 큰 앱에 통합해야 할 때요.
- Thunderbit를 사용하세요: 빠르게 결과를 얻고 싶거나, 코딩을 원하지 않거나, 비기술 팀원도 쓸 수 있게 하고 싶을 때요.
솔직히 말하면, 두 가지를 함께 쓰는 팀도 많이 봤어요. Thunderbit는 빠른 성과와 프로토타입 제작에, Puppeteer는 깊은 통합이나 예외 사례에 활용하는 식이죠.
단계별 체크리스트: 성공적인 Puppeteer 웹 스크래핑 프로젝트 운영하기
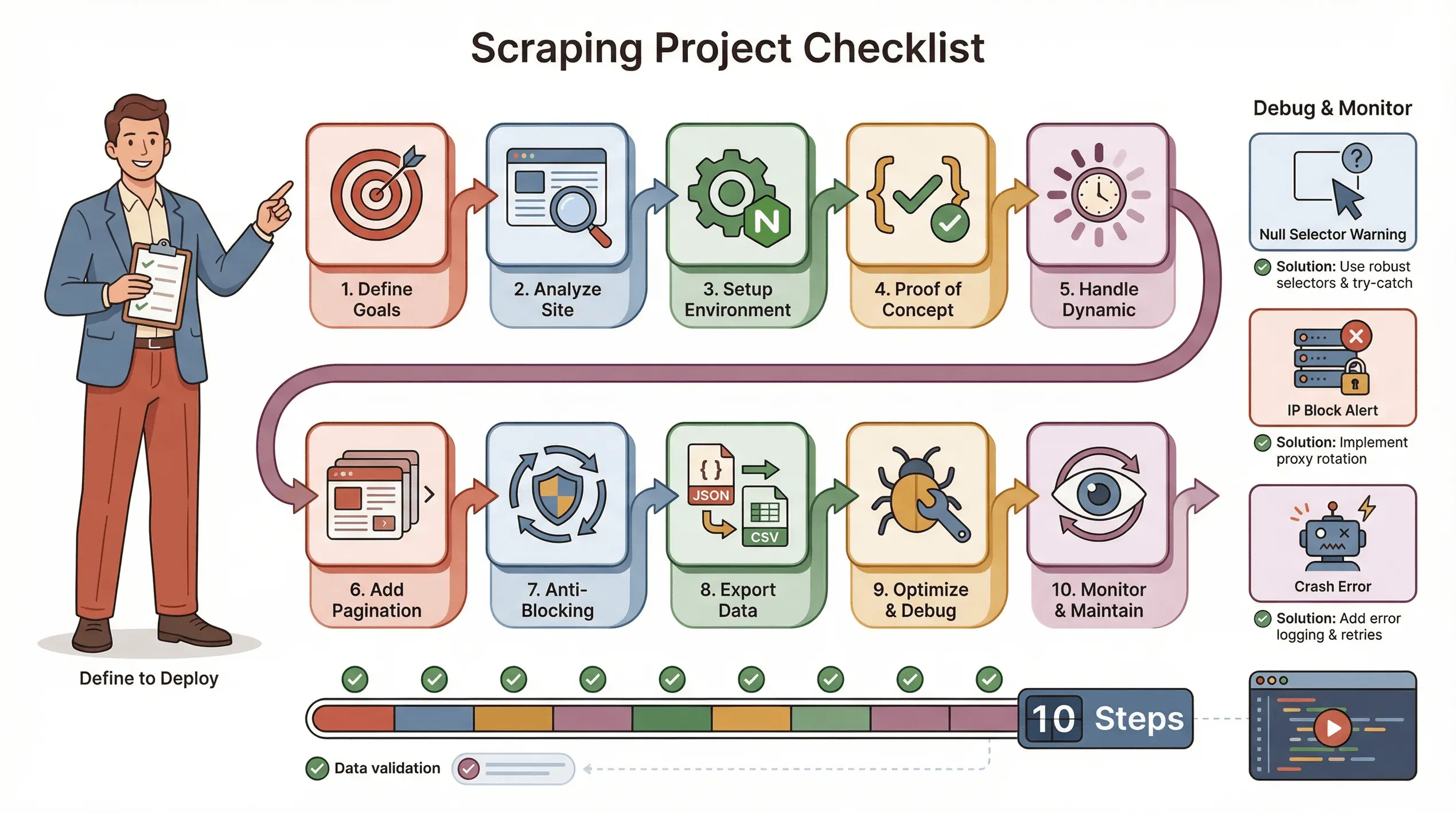 원활한 Puppeteer 스크래핑 프로젝트를 위한 제 기본 체크리스트는 다음과 같아요.
원활한 Puppeteer 스크래핑 프로젝트를 위한 제 기본 체크리스트는 다음과 같아요.
- 목표 정의하기: 어떤 데이터가 필요한가요? 어디에 있나요?
- 사이트 분석하기: 동적인가요? 로그인이 필요한가요? 봇 차단 장치가 있나요?
- 환경 설정하기: Node.js, Puppeteer, 그리고 필요한 보조 라이브러리.
- 개념 검증용 프로토타입 작성하기: 한 페이지부터 시작해서 셀렉터를 정확히 잡으세요.
- 동적 콘텐츠 처리하기:
waitForSelector를 사용하고, 필요하면 클릭/스크롤을 시뮬레이션하세요. - 페이지네이션 또는 반복 로직 추가하기: 한 페이지만이 아니라 전체 페이지를 스크래핑하세요.
- 차단 방지 전략 구현하기: 지연 시간을 랜덤화하고, 실제 User-Agent를 설정하고, 필요하면 프록시를 사용하세요.
- 데이터 내보내기 및 검증하기: JSON/CSV로 저장하고, 누락이 없는지 확인하세요.
- 최적화 및 오류 처리하기: try/catch를 추가하고, 진행 상황을 기록하고, 누락 데이터를 자연스럽게 처리하세요.
- 모니터링 및 유지보수하기: 사이트는 바뀝니다. 스크립트를 업데이트할 준비를 해 두세요.
문제 해결 팁:
- 셀렉터가 null을 반환하면 HTML을 다시 확인하고 대기 로직을 사용하세요.
- 차단당하면 속도를 낮추고, IP를 바꾸거나, 스텔스 플러그인을 사용하세요.
- 스크립트가 충돌하면 메모리 누수나 처리되지 않은 예외를 확인하세요.
결론 및 핵심 요점
웹 스크래핑은 이제 데이터 중심 팀에게 꼭 필요한 역량이 되었어요. Puppeteer는 가장 동적이고 JavaScript가 많이 쓰인 사이트에서도 데이터를 추출할 수 있는 강력한 도구이지만, 어느 정도 코딩 실력과 지속적인 유지보수가 필요합니다. 반면, 코드를 건너뛰고 바로 데이터로 가고 싶은 비즈니스 사용자에게는 Thunderbit가 빠르고 유연하며 생각보다 강력한 AI 기반 노코드 대안을 제공합니다.
제가 추천하는 방법은 이렇습니다:
- 기술 역량이 있고 세밀한 커스터마이징이 필요하다면 Puppeteer로 시작하세요.
- 속도와 단순함, 적은 유지보수를 원한다면 를 써 보세요(부터 시작하면 좋아요).
- 대부분의 팀은 두 도구를 함께 쓰면 웹 데이터 요구의 99%를 커버할 수 있어요.
이런 가이드를 더 보고 싶으신가요? 튜토리얼, 비교 글, 최신 AI 웹 스크래핑 소식은 에서 확인해 보세요.
자주 묻는 질문
1. Puppeteer 스크래퍼란 무엇이며 웹 스크래핑에 왜 쓰이나요?
Puppeteer는 JavaScript로 헤드리스 Chrome 브라우저를 제어할 수 있게 해 주는 Node.js 라이브러리예요. 동적 콘텐츠를 로드하고, 사용자 동작을 시뮬레이션하고, 전통적인 스크래퍼가 처리하지 못하는 사이트에서도 데이터를 추출할 수 있어서 웹 스크래핑에 사용됩니다.
2. Puppeteer는 Selenium과 Thunderbit와 어떻게 다른가요?
Selenium은 여러 브라우저와 언어를 지원하지만 다소 무거워요. Puppeteer는 Chrome/Node.js에 맞게 최적화되어 있어 많은 스크래핑 작업에서 더 빠릅니다. 반면 Thunderbit는 노코드 AI 도구로, 비기술 사용자도 몇 번의 클릭만으로 데이터를 스크래핑할 수 있어요.
3. Puppeteer 웹 스크래핑의 주요 비즈니스 이점은 무엇인가요?
데이터 수집을 자동화하면 시간을 절약하고, 오류를 줄이며, 영업·마케팅·운영 등에서 실시간 인사이트를 얻을 수 있어요. 활용 범위는 리드 생성부터 가격 모니터링, 시장 조사까지 다양합니다.
4. Puppeteer 스크래핑의 가장 큰 어려움은 무엇인가요?
가장 큰 어려움은 동적 콘텐츠 처리, 봇 차단 우회, 그리고 사이트 변경 시 스크립트 유지보수예요. 대기 로직 관리, 상호작용 시뮬레이션, 오류 처리를 위해 코드를 작성해야 합니다.
5. 언제 Puppeteer 대신 Thunderbit를 사용해야 하나요?
코딩을 건너뛰고 싶거나, 결과가 빨리 필요하거나, 비기술 팀원도 쓸 수 있게 하고 싶다면 Thunderbit를 사용하세요. 일반적인 스크래핑 작업, 빠른 프로젝트, 또는 Excel이나 Google Sheets로 간단히 내보내고 싶을 때 특히 잘 맞습니다.
더 똑똑한 방법으로 스크래핑을 시작해 볼 준비가 되셨나요? 하거나 에서 더 많은 가이드를 확인해 보세요. 즐거운 스크래핑 되세요!
더 알아보기