
Google elabora ben oltre —alcune stime arrivano a —e questo numero continua a crescere. Tutti questi dati di ricerca sono una miniera d’oro per i team SEO, le operations di vendita, gli analisti ecommerce e, sempre più spesso, per gli agenti AI che hanno bisogno di prove web in tempo reale. Il problema? Scegliere una SERP API nel 2026 sembra meno una scelta di strumento e più un tentativo di decifrare un labirinto di pagine prezzi, sistemi a crediti e promesse vaghe su un "JSON strutturato".
Nelle ultime settimane ho analizzato otto fornitori di SERP API—testando i tempi di risposta, uniformando i prezzi tra modelli di fatturazione confusi e controllando quali funzionalità SERP ciascuno riesce davvero a trasformare in campi strutturati. L’obiettivo: offrirti un confronto onesto, realmente comparabile, che nessun altro articolo fornisce. Parleremo di velocità, costo reale su larga scala, copertura del parsing, prontezza per agenti AI e affidabilità in produzione. Se ti ha frustrato il classico "stai confrontando le pagine prezzi, non la spesa reale" (una citazione vera da un che ho trovato), questo articolo è per te.
Perché ti serve una SERP API nel 2026 (e perché sceglierne una è difficile)
Una SERP API è un servizio hostato che invia una query di ricerca a un motore di ricerca e restituisce la pagina dei risultati in un formato leggibile dalle macchine, di solito JSON. Invece di costruire da zero rotazione di proxy, gestione dei CAPTCHA, rendering del browser e parser, chiami un endpoint e ottieni dati strutturati in risposta. Concetto semplice, mercato complicato.
I casi d’uso si sono estesi ben oltre il ranking tracking:
- I team SEO hanno bisogno di posizionamenti, proprietà degli snippet, domande People Also Ask e visibilità dei competitor.
- I team sales e GTM usano le SERP per scoprire aziende, pagine di recensioni, directory e segnali di acquisto.
- I team ecommerce monitorano Google Shopping, annunci a pagamento e i prezzi dei competitor.
- Gli sviluppatori AI alimentano dati SERP in agenti LLM, pipeline RAG e strumenti di workflow come n8n e LangChain.

Il dovrebbe raggiungere , con una crescita annua composta di circa il 13,78%. Le SERP API rappresentano una fetta importante di questa torta.
Ecco la frustrazione di fondo: ogni fornitore promette "JSON strutturato", ma gli elementi SERP effettivamente parsati—PAA, knowledge panel, local pack, shopping ads, featured snippet—variano enormemente tra loro. Anche i prezzi sono un disastro. Alcuni fatturano per ricerca, altri per credito, altri per risultato, e altri ancora applicano tariffe diverse in base al livello di velocità o alla geolocalizzazione. Un utente Reddit l’ha detta bene: "SerpApi fattura per ogni ricerca riuscita, ScraperAPI incapsula tutto in crediti e Serperdev sembra economico finché non converti i crediti nel tuo carico di lavoro reale."
Questo articolo colma le lacune che non sono riuscito a trovare altrove: una matrice di parsing che mostra cosa restituisce davvero ogni API, prezzi normalizzati su 1K/10K/100K query, compatibilità con agenti AI e dati di prontezza per la produzione.
Come abbiamo testato: criteri per scegliere la migliore SERP API
Ho valutato ogni fornitore su otto dimensioni che corrispondono direttamente a ciò che conta davvero per chi usa il prodotto in produzione. La maggior parte degli articoli concorrenti ne copre due o tre in modo superficiale. Io volevo tutte e otto, con prove.
Velocità e tempo di risposta. Ho preso come riferimento benchmark di terze parti—in particolare il —e la documentazione dei fornitori. La velocità conta quando costruisci dashboard in tempo reale o agenti AI che devono fare chiamate agli strumenti e non possono aspettare 30 secondi per una risposta.
Prezzi su larga scala (1K, 10K, 100K query). Ho normalizzato i prezzi di ogni fornitore in termini di costo per 1.000 query riuscite. È l’unico modo corretto per confrontare modelli a crediti, abbonamenti a pacchetto e pay-as-you-go.
Funzionalità SERP parsate (oltre i risultati organici). Ho controllato documentazione e risposte di esempio per verificare quali elementi SERP ogni API restituisce come campi strutturati, non solo come HTML grezzo.
Disponibilità di piano gratuito e pay-as-you-go. Un ingresso a basso impegno conta. Se non puoi testare un fornitore sul tuo carico di lavoro reale prima di impegnare centinaia di dollari, è un campanello d’allarme.
Integrazione con AI e automazione. Nel 2026, più team hanno bisogno di SERP API che alimentino agenti AI piuttosto che dashboard. Stabilità dello schema, output pulito e conversione in Markdown contano per il consumo a valle da parte degli LLM.
Supporto multi-motore. La maggior parte degli articoli si concentra solo su Google. Ho verificato quali fornitori supportano Bing, Yandex, DuckDuckGo, Baidu e altri.
Limiti di richiesta e prontezza per la produzione. Nessun articolo concorrente confronta in modo sistematico limiti di richiesta, politiche di retry o SLA. Eppure i team che scalano a migliaia di query al giorno ne hanno bisogno.
Facilità per gli sviluppatori. Qualità della documentazione, disponibilità di SDK e tempo per ottenere il primo risultato.
1. Thunderbit
adotta un approccio fondamentalmente diverso dalle SERP API tradizionali. Invece di offrire endpoint fissi che parsano elementi SERP predeterminati, l’Extract API di Thunderbit ti permette di definire il tuo JSON Schema—e l’AI estrae esattamente i campi che specifichi da qualsiasi pagina di risultati di ricerca. La Distill API converte qualsiasi URL in un Markdown pulito, pronto per gli LLM.
Questo significa che Thunderbit funziona con Google, Bing, Yandex, DuckDuckGo o qualsiasi altro motore di ricerca—l’AI legge ogni volta la pagina da zero invece di affidarsi a selettori hardcoded. I layout SERP cambiano di continuo. Non devi aspettare che un provider aggiorni un parser.
Funzionalità principali
- Extract API: definisci uno JSON Schema personalizzato (risultati organici, domande PAA, aziende del local pack, prodotti shopping—qualsiasi cosa ti serva) e ottieni esattamente quei campi come dati strutturati.
- Distill API: converte qualsiasi pagina SERP in Markdown pulito, ideale per pipeline RAG e sintesi LLM.
- Multi-motore per progettazione: funziona su qualsiasi pagina di ricerca accessibile, non solo Google.
- Elaborazione batch: gestisce più URL in parallelo.
- Gestione anti-bot integrata: risoluzione CAPTCHA, rendering JS e rotazione proxy sono inclusi.
- Limiti di richiesta per livello: Free (10 req/min, 2 concorrenti), Pro (100 req/min, 10 concorrenti), Enterprise (1.000 req/min, 50 concorrenti).
Prezzi
Modello a crediti. Distill costa 1 credito per pagina; Extract costa 20 crediti per pagina. Sono disponibili crediti gratuiti per i test. Usando i calcoli del piano annuale, il costo marginale di Distill può scendere fino a circa 0,80 USD per 1K pagine, mentre Extract si aggira intorno a 16 USD per 1K pagine a pieno utilizzo. Il valore di Extract è che ottieni esattamente lo schema richiesto dal tuo sistema downstream, senza post-elaborazione.
Consulta i per i pacchetti aggiornati.
Ideale per
Workflow di agenti AI, pipeline RAG, scraping multi-motore, team che hanno bisogno di uno schema flessibile invece di un output fisso e chiunque sia stanco di aspettare che un provider aggiunga supporto per una nuova funzionalità SERP.
2. SerpApi
è il veterano di questo settore—attivo dal 2016 con la più ampia gamma di endpoint specifici per Google. Copre Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos e altro ancora.
Funzionalità principali
- Endpoint dedicati per i diversi prodotti Google con geo-targeting maturo (fino al livello città).
- Parsea PAA, knowledge panel, local pack, annunci, risultati shopping, featured snippet, answer box e ricerche correlate come campi strutturati.
- Documentazione ben mantenuta e librerie client in più linguaggi.
Prezzi
. Piano Starter: 25 USD/mese per 1.000 ricerche (di fatto 25 USD per 1K). Piano Popular: 130 USD/mese per 15.000 ricerche (~8,67 USD per 1K). Big Data: 2.750 USD/mese per 500.000 ricerche (~5,50 USD per 1K). Nessuna opzione pay-as-you-go semplice—si tratta di pacchetti in abbonamento.
Velocità e affidabilità
Il benchmark di HasData riporta circa 5,49 secondi di tempo medio di risposta—non il più veloce, ma stabile. SerpApi pubblicizza uno SLA di uptime del 99,95% sui piani a pagamento, e i limiti di richieste concorrenti variano in base al piano.
Ideale per
Team che hanno bisogno della copertura più ampia dei prodotti Google (Maps, Scholar, Shopping, Jobs) con alta precisione e schemi stabili. Progetti enterprise con budget per prezzi premium.
3. Serper
punta su velocità e costo. È un attore più recente, focalizzato su scraping rapido delle SERP Google a prezzi estremamente competitivi, ed è diventato popolare nelle comunità n8n e LangChain per le integrazioni con agenti AI.
Funzionalità principali
- Output JSON pulito per Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents e Autocomplete.
- Setup minimale: puoi iniziare a ottenere risultati in meno di un minuto.
- Abbastanza semplice da essere integrato nativamente dai framework per agenti AI.
Prezzi
2.500 query gratuite alla registrazione. Prezzo iniziale intorno a 0,001 USD per ricerca, che scende a circa 0,00075 USD ad alto volume. Amico del pay-as-you-go. Un’avvertenza: richiedere più di 10 risultati per query può costare 2 crediti (verifica il comportamento attuale nella tua dashboard).
Velocità e affidabilità
Tra i più rapidi nei benchmark—HasData riporta circa 2,87 secondi di media. Il supporto è solo via email e il team mantiene un profilo pubblico relativamente basso, cosa che per alcuni utenti è un motivo di cautela. A concorrenze molto alte, alcuni recensori segnalano dubbi sull’affidabilità. Per la maggior parte dei carichi di lavoro, però, è solido.
Ideale per
Progetti attenti al budget, startup, integrazioni con agenti AI che richiedono dati SERP Google veloci ed economici. Tracking dei ranking ad alto volume dove il costo per query è il vincolo principale.
4. Scrapingdog
è presente sul mercato da oltre 5 anni e compare costantemente come il più veloce nei benchmark di terze parti. HasData lo ha misurato a con un tasso di successo del 100%.
Funzionalità principali
- La Google SERP API restituisce risultati organici, PAA, featured snippet, annunci e risultati locali come JSON strutturato.
- Disponibili sia HTML grezzo sia JSON parsato.
- Documentazione in più lingue con snippet di codice per la maggior parte dei linguaggi di programmazione: iniziare richiede minuti, non ore.
- Supporto 24/7.
Prezzi
. I piani a pagamento partono da circa 40 USD/mese. Il prezzo per chiamata parte da circa 0,001 USD e scende drasticamente ad alto volume—alcuni confronti citano tariffe fino a 0,000058 USD ai livelli più alti.
Velocità e affidabilità
I numeri di velocità sono davvero impressionanti. Se il tuo flusso di lavoro è sensibile alla latenza e devi fare estrazione Google SERP ad alto volume con schema fisso, Scrapingdog è difficile da battere sul tempo di risposta puro.
Ideale per
Strumenti SEO ad alto volume e rank tracker che hanno bisogno di bassa latenza e costi contenuti. Team che costruiscono sistemi di produzione in cui ogni millisecondo del tempo di risposta API conta.
5. DataForSEO
non è solo una SERP API: è una suite completa di API progettata per aziende che costruiscono prodotti SEO. Copre SERP, keyword, backlink, dati aziendali, Google Ads, Trends e altro ancora.
Funzionalità principali
- Parsing estremamente completo delle funzionalità SERP—organiche, a pagamento, local pack, knowledge graph, PAA, featured snippet, shopping, immagini, video, top stories e altro.
- Due modalità: Live (sincrona) per dashboard in tempo reale, e Standard (asincrona) per workflow batch in cui metti in coda i task e recuperi i risultati più tardi.
- Multi-motore: Google, Bing, Yahoo, Baidu, Naver, Seznam e altri.
Prezzi
Modello pay-as-you-go, ma il costo varia in base all’endpoint, al motore, al dispositivo, alla priorità e alla modalità. Il prezzo SERP in genere varia da circa 0,0006 USD a 0,002 USD per task per Google organico, a seconda di standard vs live e delle impostazioni di priorità. La documentazione è densa: preparati a dedicare tempo al calcolatore prezzi. .
Velocità e affidabilità
La modalità standard asincrona può essere più lenta (~10 secondi) perché i task vengono messi in coda. Le modalità Live/ad alta velocità costano di più ma sono adatte a dashboard in tempo reale. Lunga esperienza, stabilità comprovata e supporto enterprise disponibili.
Ideale per
Aziende SaaS che costruiscono piattaforme SEO, dashboard di ranking tracking e strumenti di ricerca keyword. Team a proprio agio con documentazione complessa e infrastruttura di livello enterprise.
6. Bright Data
è il colosso enterprise. La sua SERP API è solo uno dei tanti prodotti—proxy, dataset, Web Unlocker e strumenti di scraping. La proposta di valore è scala, affidabilità e infrastruttura.
Funzionalità principali
- Endpoint dedicati per Google Maps, Shopping e ricerca generale—oltre al supporto multi-motore tramite infrastruttura proxy che copre Bing, Yahoo, Yandex e DuckDuckGo.
- Afferma un tasso di successo del 100% con tecnologia di sblocco integrata.
- Dove Bright Data brilla davvero: geo-targeting, concorrenza e sblocco su scala enterprise.
Prezzi
Orientato all’enterprise. I prezzi pubblici mostrano opzioni pay-as-you-go e in abbonamento, con molti confronti che citano impegni iniziali intorno a 499 USD/mese. Il costo per chiamata parte da circa 0,005 USD ma scende con il volume. . Crediti di prova disponibili (5 USD di valore).
Velocità e affidabilità
I benchmark spesso mostrano tra 2 e 5,58 secondi. Il motivo per scegliere Bright Data non è la latenza mediana pura, ma lo SLA enterprise, il supporto dedicato e un’infrastruttura che gestisce milioni di richieste concorrenti senza degradarsi. La consiglia di aumentare il carico gradualmente.
Ideale per
Team enterprise che raccolgono milioni di SERP al mese. Organizzazioni che hanno bisogno di dati Google Maps/local business su larga scala. Team che già usano i prodotti proxy di Bright Data.
7. ScraperAPI
è una web scraping API generica che offre anche endpoint strutturati per Google SERP. È l’opzione "uno strumento per tutto"—facile da integrare, con un pool proxy di oltre 40 milioni di IP.
Funzionalità principali
- Endpoint di dati strutturati per Google Search, Shopping, News e Jobs.
- Anti-blocking basato su machine learning e risoluzione CAPTCHA, con rendering JavaScript incluso senza costi aggiuntivi.
- Supporto al geotargeting per risultati localizzati.
Prezzi
Prova gratuita di 7 giorni con 5.000 crediti. I piani a pagamento partono da circa 49 USD/mese. Il punto critico: le chiamate SERP possono consumare crediti diversi rispetto alle normali richieste di scraping, quindi normalizza sempre in base alle query SERP effettivamente riuscite erogate. .
Velocità e affidabilità
Ecco la parte sincera: il benchmark di HasData riporta circa 33,66 secondi di tempo medio di risposta per le query SERP. È significativamente più lento delle SERP API dedicate. Tasso di successo alto (99,9%), ma la latenza lo rende meno adatto alle applicazioni in tempo reale. Meglio per elaborazione batch.
Ideale per
Team che hanno bisogno di una soluzione di web scraping generale con SERP come funzionalità aggiuntiva. Progetti in cui la velocità conta meno dell’affidabilità e della semplicità di configurazione. Sviluppatori che già usano ScraperAPI per altri task di scraping e vogliono consolidare i fornitori.
8. Apify
non è una SERP API pura. È una piattaforma di scraping e automazione costruita attorno agli "Actors"—script riutilizzabili per task come scraping di Google Search, estrazione da Maps e automazione dei workflow. Pensalo come un marketplace dove scegli (o costruisci) lo scraper che si adatta esattamente al tuo bisogno.
Funzionalità principali
- Marketplace di predefiniti con copertura di funzionalità variabile.
- Altamente personalizzabile—crea workflow di scraping su misura, collega più actor, pianifica le esecuzioni.
- Output JSON; flessibilità nel parsare specifiche funzionalità SERP tramite configurazione dell’actor.
- Forte quando combini estrazione SERP con altri task di scraping/automazione.
Prezzi
Piano gratuito con crediti mensili della piattaforma (circa 5 USD di valore, circa 1.400 risultati). I piani a pagamento partono da circa 49 USD/mese. Il costo a livello di actor varia—alcuni fatturano per risultato, altri per unità di calcolo. I confronti di terze parti collocano spesso Apify intorno a 0,003 USD per ricerca su piccola scala. .
Velocità e affidabilità
HasData riporta circa 8,2 secondi di media. L’architettura basata su actor introduce overhead rispetto agli endpoint SERP dedicati. Meglio per workflow programmati o batch che per query in tempo reale.
Ideale per
Team che hanno bisogno di workflow personalizzati di scraping + automazione oltre ai semplici dati SERP. Progetti che combinano estrazione SERP con altri task di web scraping. Sviluppatori che vogliono massima flessibilità rispetto agli endpoint predefiniti.
Matrice di parsing delle funzionalità SERP: cosa restituisce davvero ogni API
Questo è il confronto che non sono riuscito a trovare altrove. Ogni fornitore dice "JSON strutturato", ma gli elementi SERP effettivamente parsati come campi di primo livello variano enormemente. Ho controllato la documentazione e le risposte di esempio per ciascuno.
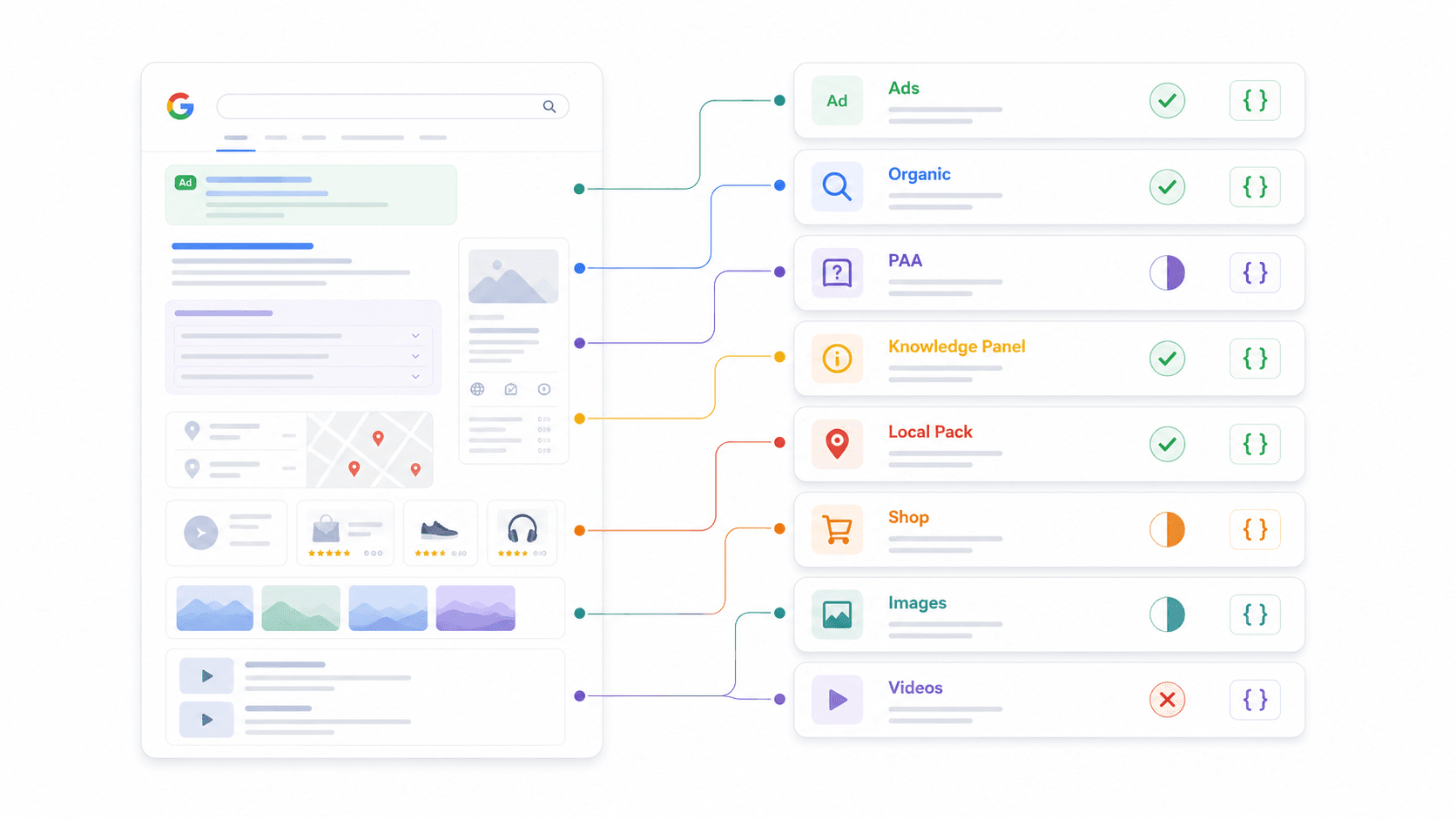
| Funzionalità SERP | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Risultati organici | Schema personalizzato | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Dipende dall’actor |
| People Also Ask | Schema personalizzato | ✅ | ✅ | ✅ | ✅ | Parziale | Parziale | Dipende dall’actor |
| Knowledge Panel | Schema personalizzato | ✅ | Parziale | Parziale | ✅ | Parziale | Parziale | Dipende dall’actor |
| Local Pack / Maps | Schema personalizzato | ✅ | ✅ | Parziale | ✅ | ✅ | Parziale | Dipende dall’actor |
| Risultati Shopping | Schema personalizzato | ✅ | ✅ | Parziale | ✅ | ✅ | ✅ | Dipende dall’actor |
| Featured Snippets | Schema personalizzato | ✅ | Parziale | ✅ | ✅ | Parziale | Parziale | Dipende dall’actor |
| Annunci (in alto/in basso) | Schema personalizzato | ✅ | Parziale | ✅ | ✅ | Parziale | Parziale | Dipende dall’actor |
| Image Pack | Schema personalizzato | ✅ | ✅ | ✅ | ✅ | Parziale | Parziale | Dipende dall’actor |
| Risultati video | Schema personalizzato | ✅ | ✅ | Parziale | ✅ | Parziale | Parziale | Dipende dall’actor |
Cosa significa "Schema personalizzato" per Thunderbit: invece di predefinire quali funzionalità SERP parsare, definisci il tuo JSON Schema per estrarre esattamente i campi che ti servono. Vuoi le domande PAA insieme ai riepiloghi delle risposte e ai segnali di intento commerciale? Definisci lo schema e l’AI lo restituisce. Questa flessibilità è il motivo per cui Thunderbit funziona con qualsiasi motore di ricerca, non solo Google.
Perché questo conta per il tuo workflow: se ti servono dati PAA per la strategia contenuti, verifica che il fornitore li parsifichi davvero. Se monitori gli annunci shopping per ecommerce, conferma che esistano campi strutturati per lo shopping. Non dare per scontato che "JSON strutturato" significhi copertura completa.
Costo reale su larga scala: confronto del prezzo per query
I prezzi pubblicati sui siti web non raccontano tutta la storia. Ho normalizzato tutto in termini di costo per 1.000 query riuscite su tre livelli di volume.
| Fornitore | Costo per 1K query | Costo per 10K query | Costo per 100K query | Pay-as-you-go? | Piano gratuito |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ~0,80–3,20 USD | ~8–32 USD | ~80–320 USD | Pacchetto a crediti | Crediti gratuiti |
| Thunderbit (Extract) | ~16–64 USD | ~160–640 USD | ~1.600–6.400 USD | Pacchetto a crediti | Crediti gratuiti |
| SerpApi | 25 USD (Starter) | ~87 USD (Popular) | ~550 USD (Big Data) | No (abbonamento) | 250/mese |
| Serper | ~1 USD | ~10 USD | ~75–100 USD | Sì | 2.500 query |
| Scrapingdog | ~1 USD | ~10 USD o meno | Può scendere ben sotto 10 USD | Piano/crediti | 1.000 crediti |
| DataForSEO | ~0,60–2 USD | ~6–20 USD | ~60–200 USD | Sì | Crediti di prova |
| Bright Data | ~0,50–5+ USD | Dipende dal preventivo | Migliore su volumi enterprise | Sì/piano | Crediti di prova (5 USD) |
| ScraperAPI | Dipende dai crediti | Dipende dai crediti | Dipende dai crediti | Piano/crediti | 5.000 crediti di prova |
| Apify | ~3 USD (piccola scala) | Dipende dall’actor | Dipende dall’actor | Crediti piattaforma | Crediti gratuiti mensili |
Costi nascosti da tenere d’occhio:
- L’eventuale addebito di 2 crediti di Serper per più di 10 risultati per query.
- Le differenze di prezzo di DataForSEO tra modalità standard e live/ad alta priorità.
- I moltiplicatori di crediti di ScraperAPI per SERP rispetto allo scraping normale.
- Gli impegni minimi enterprise di Bright Data.
Valore per ogni fascia:
- Progetti secondari (50 USD/mese): Serper o Scrapingdog per JSON SERP Google fisso.
- Team in crescita (10K–50K query/mese): Serper, Scrapingdog o DataForSEO a seconda della profondità di parsing.
- Enterprise (100K+ query/mese): DataForSEO, Bright Data o SerpApi Big Data.
- Estrazione AI-first: Thunderbit, perché lo schema corrisponde alle aspettative dell’agente downstream senza post-elaborazione.
La migliore SERP API per agenti AI e workflow LLM nel 2026
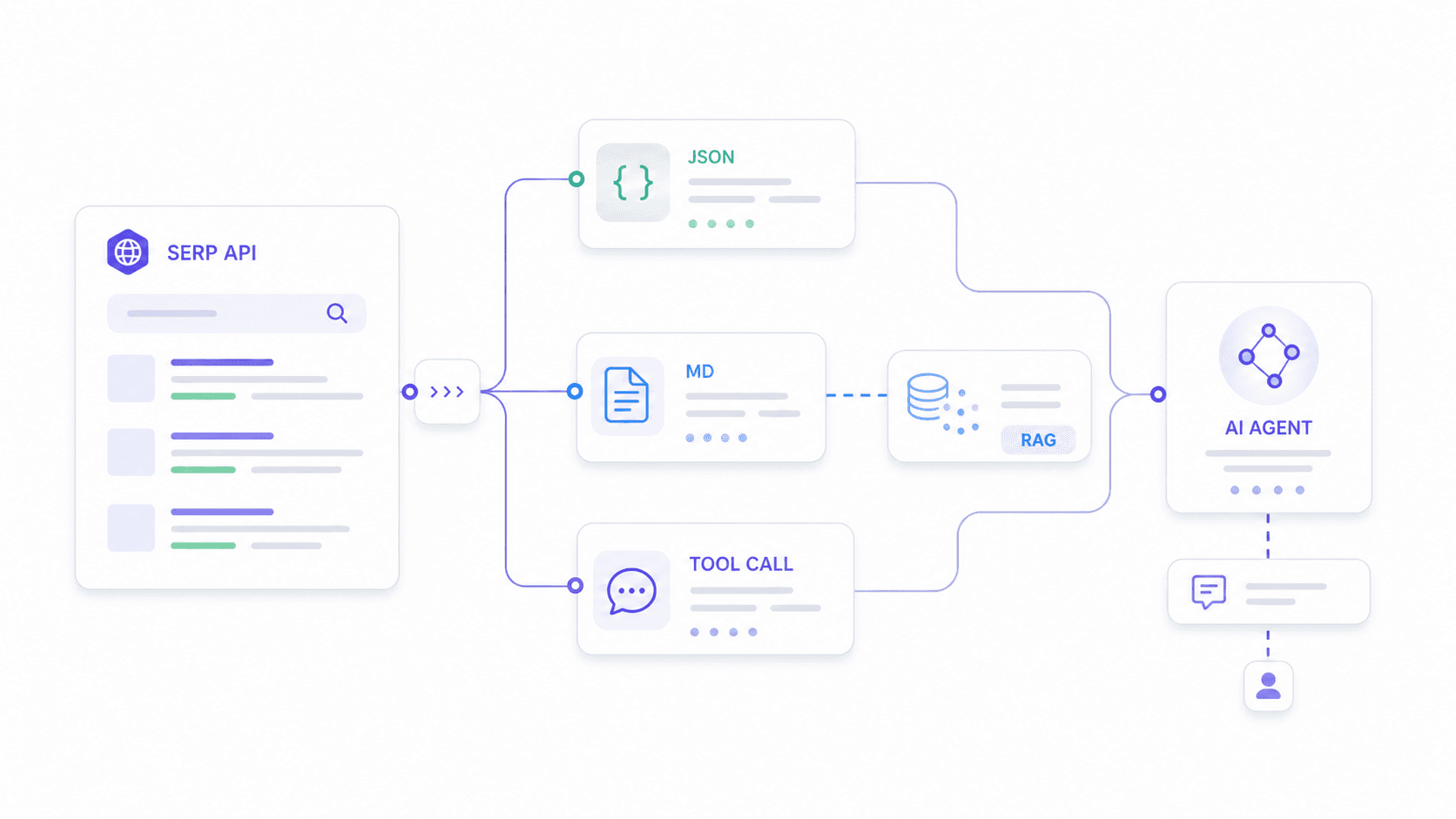
Questo è il caso d’uso che nessun altro tratta bene. Ho trovato almeno tre in cui gli utenti raccontano di aver provato a integrare SERP API con workflow n8n e agenti AI, e uno afferma esplicitamente di "non aver capito come farlo funzionare correttamente con un agente AI".
Gli agenti AI hanno esigenze diverse dalle dashboard di ranking tracking. Hanno bisogno di:
- JSON con schema stabile che non rompa la logica di parsing quando un fornitore aggiorna il formato di output.
- Campi di output personalizzati che corrispondano a ciò che il modello downstream si aspetta, non un dump generico di tutto.
- Markdown o testo puliti per pipeline di embedding RAG.
- Latenza abbastanza bassa per il tool calling in tempo reale.
Come ogni fornitore si inserisce in uno stack di agenti AI
| Fornitore | Adatto agli agenti AI | Perché |
|---|---|---|
| Thunderbit | Eccellente | JSON Schema personalizzato (Extract API) + Markdown per RAG (Distill API). Il più flessibile per l’estrazione specifica per agente. |
| Serper | Molto buono | JSON veloce e pulito, popolare nelle comunità n8n/LangChain. Semplice ed economico per chiamate di ricerca di base. |
| SerpApi | Buono | Schema stabile, documentazione eccellente. Funziona bene quando gli agenti hanno bisogno di verticali Google (Maps, Scholar, Shopping). |
| DataForSEO | Buono | Migliore quando l’agente fa parte di una pipeline dati SEO più ampia. |
| Scrapingdog | Buono | Veloce ed economico; lo schema è stabile per la SERP Google. |
| Bright Data | Buono | Raccolta dati fresca su scala enterprise tra motori e regioni. |
| ScraperAPI | Moderato | Meglio quando l’agente ha bisogno anche di crawling web generale. |
| Apify | Da moderato a buono | Flessibile ma più lento; meglio per workflow batch programmati. |
Esempio pratico con Thunderbit: immagina che il tuo agente AI debba analizzare l’intento di ricerca per "miglior CRM per real estate". Definisci uno schema che richieda risultati organici (titolo, URL, snippet, posizione), domande People Also Ask con riepiloghi delle risposte e una classificazione dell’intento commerciale. L’Extract API di Thunderbit restituisce esattamente quella struttura—né più né meno. Il tuo agente non spreca token per fare parsing di campi irrilevanti o pulire artefatti HTML.
Per le pipeline RAG, la Distill API di Thunderbit converte la pagina SERP in Markdown pulito, pronto per l’embedding. La maggior parte delle SERP API dedicate restituisce schemi JSON fissi; l’approccio di Thunderbit permette agli sviluppatori di adattare l’output a ciò che il modello downstream si aspetta.
Matrice decisionale per i casi d’uso: se ti serve X, usa Y
Gli utenti dei forum continuano a chiedere raccomandazioni specifiche, mappate sui loro workflow reali, non consigli generici del tipo "dipende". Quindi l’ho costruita.
| Il tuo caso d’uso | Scelta migliore | Seconda scelta | Perché |
|---|---|---|---|
| Ranking tracking SEO (alto volume) | DataForSEO | Scrapingdog | Endpoint nativi SEO, prezzi bulk, parsing completo |
| Dati Google Maps / local business | SerpApi | Bright Data | Endpoint Maps maturo; Bright Data si adatta al local scraping enterprise-scale |
| Agente AI / automazione n8n | Thunderbit | Serper | Schema personalizzato + Markdown per RAG; Serper è veloce ed economico per chiamate semplici |
| MVP a budget ridotto / side project (<50 USD/mese) | Serper | Scrapingdog | Piani gratuiti generosi, pay-as-you-go, setup minimo |
| Multi-motore (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | Thunderbit funziona su qualsiasi motore di ricerca tramite estrazione AI; DataForSEO ha endpoint multi-motore |
| Aggregazione recensioni Google | SerpApi | DataForSEO | Endpoint dedicati al parsing delle recensioni |
| Monitoraggio ecommerce / shopping | SerpApi | DataForSEO | Copertura forte di Google Shopping e campi strutturati |
| Workflow di scraping personalizzati | Apify | ScraperAPI | Flessibilità degli actor; ScraperAPI è facile per scraping generale + SERP |
Guida rapida per persona:
- Team SEO: parti da DataForSEO se stai costruendo dashboard; usa SerpApi se la copertura dei verticali Google e la documentazione contano più del prezzo.
- Team sales: usa Thunderbit quando il workflow attraversa SERP, pagine directory e enrichment; usa Serper per semplici query di lead discovery.
- Sviluppatore di tool AI: Thunderbit per schemi personalizzati/RAG, Serper per ricerche economiche e veloci, SerpApi per verticali Google robusti.
- Imprenditore individuale: inizia con i piani gratuiti di Serper, Scrapingdog, SerpApi e Thunderbit. Esegui le stesse 20 query simili alla produzione prima di impegnarti.
Limiti di richiesta, affidabilità e prontezza per la produzione a confronto
Vorrei che questa sezione esistesse quando ho valutato per la prima volta i fornitori per workflow di produzione. I team che scalano a migliaia di query al giorno hanno bisogno di limiti di richiesta prevedibili, retry automatici e garanzie di uptime—e nessun altro articolo di confronto li copre in modo sistematico.
| Fornitore | Limite di richiesta | Richieste concorrenti | Retry in caso di errore | SLA / uptime |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | Integrato (anti-bot, CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | Integrato | — |
| Thunderbit Enterprise | 1.000 req/min | 50 | Integrato | Termini personalizzati |
| SerpApi | Basato sul piano (ricerche/ora) | Basato sul piano | Il provider gestisce proxy/CAPTCHA | SLA 99,95% |
| Serper | Basato su account/piano | Non pubblicato ampiamente | Consigliato retry manuale lato client | Nessun SLA pubblico |
| Scrapingdog | Basato sul piano | Controlla i termini del piano | Anti-blocking gestito | Non sempre pubblico |
| DataForSEO | Documentato per endpoint/modalità | Varia in base alla modalità | L’asincrono supporta polling/retry | Supporto enterprise |
| Bright Data | Documentato, aumentare gradualmente | Scala enterprise | Sblocco integrato | SLA enterprise |
| ScraperAPI | Concorrenza basata sul piano | Dipendente dai crediti | Gestisce retry/proxy | Opzioni di supporto a pagamento |
| Apify | Dipendente da actor/memoria/compute | Limiti della piattaforma | Configurazione a livello di actor | Affidabilità della piattaforma |
Checklist di produzione prima di impegnarti:
- Chiedi se il fornitore addebita le richieste fallite o bloccate.
- Conferma concorrenza esatta, richieste al minuto e comportamento nei picchi.
- Verifica se geo-targeting, mobile vs desktop e rendering JS cambiano il consumo di crediti.
- Salva risposte JSON di esempio per 20–50 query reali e confronta i nomi dei campi nel tempo per verificare la stabilità dello schema.
- Aggiungi retry lato client e budget di timeout se i dati SERP sono mission-critical.
Riassunto rapido: confronto di tutte le 8 SERP API
| Fornitore | Velocità media | Costo per 1K | Piano gratuito | Copertura parsing | Adatto all’AI | Multi-motore | Verdetto |
|---|---|---|---|---|---|---|---|
| Thunderbit | Medio (estrazione AI) | Da basso (Distill) a premium (Extract) | Sì | Personalizzata (qualsiasi funzionalità) | Eccellente | Eccellente | Migliore per estrazione SERP custom nativa AI e RAG |
| SerpApi | ~5,5s | Premium | 250/mese | Eccellente (fissa) | Buono | Ampi verticali Google | Migliore copertura Google matura |
| Serper | ~2–3s | Molto basso | 2.500 query | Buono | Molto buono | Principalmente Google | Migliore API veloce ed economica per AI/MVP |
| Scrapingdog | ~1,25s | Molto basso su scala | 1.000 crediti | Buono | Buono | Verificare i motori | Migliore combinazione velocità/costo |
| DataForSEO | Medio-lento (standard) | Basso–moderato | Crediti di prova | Eccellente | Buono | Eccellente | Migliore infrastruttura per piattaforme SEO |
| Bright Data | ~2–5,5s | Enterprise | Prova (5 USD) | Buono (dipende dal prodotto) | Buono | Eccellente | Migliore raccolta su scala enterprise |
| ScraperAPI | ~33s | Dipendente dai crediti | 5.000 di prova | Moderato | Moderato | Endpoint Google | Migliore se la SERP è solo una parte di uno scraping più ampio |
| Apify | ~8s | Dipendente dall’actor | Crediti mensili | Dipendente dall’actor | Moderato–Buono | Dipendente dall’actor | Migliore per workflow di automazione personalizzati |
Come Thunderbit si inserisce nel tuo workflow SERP
Un po’ di contesto in più sul perché il nostro team ha costruito l’API di Thunderbit in questo modo. Il modello tradizionale delle SERP API—endpoint fissi, campi di output predeterminati, solo Google—funziona bene per il rank tracking lineare. Ma nel momento in cui ti serve qualcosa di leggermente diverso (risposte PAA con sentiment, risultati del local pack con conteggio delle recensioni, o dati shopping formattati per uno schema database specifico), ti ritrovi bloccato a fare post-elaborazione o a cambiare fornitore.
L’Extract API di Thunderbit ribalta quel modello. Gli dici cosa vuoi tramite uno JSON Schema, e l’AI capisce come ottenerlo dalla pagina di ricerca che le indichi. Google oggi, Bing domani, un motore di ricerca verticale di nicchia la prossima settimana—stessa API, stesso approccio.
La Distill API risolve un problema diverso: trasformare pagine SERP confuse in Markdown pulito che gli LLM possano davvero consumare senza impattare contro artefatti HTML, elementi di navigazione e script di tracciamento. Se stai costruendo una pipeline RAG che ha bisogno di evidenze di ricerca fresche, questo è il percorso più rapido da "SERP live" a "contenuto embedded".
Entrambi gli endpoint includono gestione anti-bot, risoluzione dei CAPTCHA e rendering JS out of the box. Non paghi extra per queste funzioni: sono incluse nel costo in crediti.
Provalo tu stesso: per l’estrazione dal browser, oppure usa direttamente l’API per workflow programmatici. Il nostro ha guide passo passo se vuoi vederlo in azione prima di scrivere codice.
Una nota sulla legalità
Questa domanda emerge in ogni FAQ, quindi ecco la versione breve: la legalità dello scraping delle SERP dipende dai fatti specifici e dalla giurisdizione. Il caso ha stabilito che lo scraping di dati pubblicamente accessibili non è necessariamente un reato informatico, ma non fornisce un permesso generale. Google ha per lo scraping delle SERP, segno di una pressione commerciale attiva sull’accesso.
Consiglio pratico: usa le API dei fornitori secondo i loro termini, evita di raccogliere dati personali salvo che sia necessario e chiedi ai fornitori come gestiscono la conformità. Non dare per scontato che lo scraping delle SERP sia privo di rischi.
Conclusione
Nessun fornitore vince su tutte le dimensioni—la scelta giusta dipende dal tuo caso d’uso, dal budget e dallo stack tecnico. Dopo aver normalizzato i prezzi, testato la velocità, mappato la copertura del parsing e valutato la prontezza per agenti AI, ecco il mio schema decisionale:
- Ti servono flessibilità + prontezza per agenti AI? → Thunderbit
- Ti serve una copertura ampia dei prodotti Google? → SerpApi
- Ti servono velocità + costo più basso? → Serper o Scrapingdog
- Stai costruendo una piattaforma SEO? → DataForSEO
- Scala enterprise con SLA? → Bright Data o DataForSEO
- Scraping generale + SERP occasionale? → ScraperAPI o Apify
Parti dai piani gratuiti. Esegui 20–50 query reali che rispecchino il tuo carico di produzione. Confronta le risposte JSON. Verifica il costo reale dopo crediti e moltiplicatori. Poi decidi.
I prezzi cambiano spesso in questo mercato—questo confronto è stato normalizzato a partire dalle pagine pubbliche disponibili a maggio 2026. Se lo stai leggendo mesi dopo, ricontrolla prima di acquistare.
Per approfondire gli approcci al e come si confrontano con i metodi tradizionali, abbiamo scritto molto sull’argomento. E se stai valutando il , anche l’estensione Chrome di Thunderbit copre quel lato del lavoro.
FAQ
1. Cos’è una SERP API e chi ne ha bisogno?
Una SERP API è un servizio che invia query di ricerca a motori come Google, Bing o Yandex e restituisce i risultati come dati strutturati (di solito JSON). I professionisti SEO le usano per il ranking tracking, i team sales per la scoperta di lead, i team ecommerce per il monitoraggio dei prezzi e gli sviluppatori AI per alimentare dati di ricerca live in agenti e pipeline RAG.
2. Quanto costa estrarre 1.000 risultati di ricerca Google via API?
La fascia è molto ampia—da circa 0,60 USD per 1K (DataForSEO al livello standard) fino a circa 25 USD per 1K (piano SerpApi Starter). Gli sconti per alto volume variano notevolmente tra i fornitori. Normalizza sempre il costo per 1.000 query riuscite, invece di confrontare solo i prezzi in evidenza.
3. Posso usare una SERP API con agenti AI come LangChain o n8n?
Sì. Serper è popolare nella comunità n8n per semplici chiamate di ricerca. Thunderbit è il più forte quando il tuo agente ha bisogno di JSON Schema personalizzati o Markdown per RAG. SerpApi funziona bene per agenti che richiedono dati verticali Google stabili (Maps, Scholar, Shopping).
4. Qual è la SERP API con il miglior piano gratuito per i test?
Serper offre 2.500 query gratuite alla registrazione—il più generoso in termini di volume puro. SerpApi offre 250/mese, Scrapingdog 1.000 crediti, ScraperAPI 5.000 crediti di prova (7 giorni) e Thunderbit include crediti gratuiti per il prototyping. Apify ha crediti mensili della piattaforma per un valore di circa 5 USD.
5. Quali funzionalità SERP dovrei verificare che un fornitore parsifichi prima di acquistare?
Non dare per scontato che "JSON strutturato" significhi copertura completa. Verifica se l’API restituisce campi strutturati per: People Also Ask, Knowledge Panel, Local Pack/Maps, risultati Shopping, Featured Snippets, annunci (in alto e in basso), Image Pack e risultati video. Usa la matrice di parsing di questo articolo come checklist iniziale e testa con query reali prima di impegnarti in un piano.
Scopri di più