
वेब उपयोगी डेटा से भरा पड़ा है—चाहे आप सेल्स में हों, ईकॉमर्स में, या मार्केट रिसर्च में, वेब स्क्रैपिंग लीड जनरेशन, कीमतों की निगरानी, और प्रतिस्पर्धी विश्लेषण के लिए एक गुप्त हथियार है। लेकिन दिक्कत यह है: जैसे-जैसे ज़्यादा बिज़नेस स्क्रैपिंग का इस्तेमाल कर रहे हैं, वेबसाइटें पहले से कहीं ज़्यादा सख़्ती से जवाब दे रही हैं। सच यह है कि अब , और अब आम बात हो गई है। अगर आपने कभी अपना Python स्क्रिप्ट 20 मिनट तक बिना समस्या के चलते देखा हो—और फिर अचानक 403 एरर की दीवार से टकरा गया हो—तो आप जानते हैं कि यह झुंझलाहट असली है।
मैंने SaaS और ऑटोमेशन में कई साल बिताए हैं, और मैंने अपनी आँखों से देखा है कि कैसे स्क्रैपिंग प्रोजेक्ट्स पलभर में “वाह, यह तो आसान है” से “मुझे हर जगह ब्लॉक क्यों किया जा रहा है?” तक पहुँच जाते हैं। तो चलिए व्यावहारिक बात करते हैं: मैं आपको बताऊँगा कि Python में ब्लॉक हुए बिना वेब स्क्रैपिंग कैसे करें, सबसे अच्छे तरीक़े और कोड स्निपेट्स साझा करूँगा, और यह भी दिखाऊँगा कि कब जैसे AI-संचालित विकल्पों पर विचार करने का समय आ जाता है। चाहे आप Python के प्रो हों या बस किसी तरह स्क्रैपिंग कर रहे हों, आप एक ऐसा टूलकिट लेकर लौटेंगे जिससे भरोसेमंद, ब्लॉक-फ्री डेटा एक्सट्रैक्शन किया जा सके।
Python में ब्लॉक हुए बिना वेब स्क्रैपिंग क्या है?
मूल रूप से, ब्लॉक हुए बिना वेब स्क्रैपिंग का मतलब है वेबसाइटों से ऐसा डेटा निकालना कि उनकी एंटी-बॉट सुरक्षा सक्रिय न हो। Python की दुनिया में, यह सिर्फ़ requests.get() लूप लिखने से कहीं आगे की चीज़ है—इसमें ऐसे व्यवहार करना शामिल है जैसे आप एक असली यूज़र हों, डिटेक्शन सिस्टम से एक कदम आगे रहना, और भीड़ में घुल-मिल जाना।
Python ही क्यों? —इसके सरल सिंटैक्स, विशाल इकोसिस्टम (जैसे: requests, BeautifulSoup, Scrapy, Selenium), और तेज़ स्क्रिप्ट से लेकर डिस्ट्रिब्यूटेड क्रॉलर तक हर चीज़ के लिए इसकी लचीलापन की वजह से। लेकिन लोकप्रियता के साथ एक कीमत भी आती है: अब कई एंटी-बॉट सिस्टम Python-आधारित स्क्रैपिंग पैटर्न पहचानने के लिए ट्यून किए जा चुके हैं।
इसलिए, अगर आप भरोसेमंद तरीके से स्क्रैप करना चाहते हैं, तो आपको बेसिक्स से आगे जाना होगा। इसका मतलब है यह समझना कि साइटें बॉट्स को कैसे पहचानती हैं, और आप उन्हें कैसे मात दे सकते हैं—बिना नैतिक या कानूनी सीमाएँ पार किए।
Python वेब स्क्रैपिंग प्रोजेक्ट्स में ब्लॉक से बचना क्यों ज़रूरी है
ब्लॉक हो जाना सिर्फ़ एक तकनीकी अड़चन नहीं है—यह पूरे बिज़नेस वर्कफ़्लो को बिगाड़ सकता है। आइए इसे समझते हैं:
| उपयोग का मामला | ब्लॉक होने का प्रभाव |
|---|---|
| लीड जनरेशन | अधूरी या पुरानी संभावित ग्राहक सूचियाँ, बिक्री का नुकसान |
| कीमतों की निगरानी | प्रतिस्पर्धी कीमतों में बदलाव छूट जाना, गलत मूल्य निर्धारण निर्णय |
| कंटेंट एग्रीगेशन | समाचार, रिव्यू, या रिसर्च डेटा में खालीपन |
| मार्केट इंटेलिजेंस | प्रतिस्पर्धी या उद्योग ट्रैकिंग में अंधे क्षेत्र |
| रियल एस्टेट लिस्टिंग | गलत या पुराना संपत्ति डेटा, मौके छूटना |
जब कोई स्क्रैपर ब्लॉक होता है, तो आप सिर्फ़ डेटा नहीं खो रहे होते—आप संसाधन बर्बाद कर रहे होते हैं, अनुपालन जोखिम बढ़ा रहे होते हैं, और अधूरी जानकारी के आधार पर गलत बिज़नेस फ़ैसले ले सकते हैं। ऐसी दुनिया में जहाँ , भरोसेमंदी ही सब कुछ है।
वेबसाइटें Python वेब स्क्रैपर्स को कैसे पहचानती और ब्लॉक करती हैं
वेबसाइटें अब बॉट्स को पकड़ने में काफ़ी चतुर हो गई हैं। यहाँ सबसे आम एंटी-स्क्रैपिंग सुरक्षा उपाय दिए गए हैं जिनका सामना आपको करना पड़ सकता है (, ):
- IP एड्रेस ब्लैकलिस्टिंग: एक ही IP से बहुत ज़्यादा अनुरोध? ब्लॉक।
- User-Agent और Header जाँच: गायब या सामान्य हेडर वाले अनुरोध (जैसे Python का डिफ़ॉल्ट
python-requests/2.25.1) तुरंत अलग दिखते हैं। - रेट लिमिटिंग: कम समय में बहुत ज़्यादा अनुरोध throttling या बैन ट्रिगर करते हैं।
- CAPTCHA: “साबित करो कि तुम इंसान हो” वाले पहेली-नुमा टेस्ट जिन्हें बॉट आसानी से हल नहीं कर सकते।
- व्यवहारिक विश्लेषण: साइटें रोबोट-जैसे पैटर्न देखती हैं—जैसे हर बार एक ही अंतराल पर एक ही बटन क्लिक करना।
- हनीपॉट्स: छिपे हुए लिंक या फ़ील्ड जिनसे सिर्फ़ बॉट्स ही इंटरैक्ट करेंगे।
- ब्राउज़र फ़िंगरप्रिंटिंग: आपके ब्राउज़र और डिवाइस की जानकारी इकट्ठा करके ऑटोमेशन टूल्स की पहचान करना।
- कुकी और सत्र ट्रैकिंग: जो बॉट्स कुकीज़ या सत्रों को ठीक से हैंडल नहीं करते, वे फ़्लैग हो जाते हैं।
इसे एयरपोर्ट सिक्योरिटी की तरह समझिए: अगर आप दिखने, व्यवहार करने और चलने में सबकी तरह हैं, तो आप आराम से निकल जाते हैं। अगर आप ट्रेंच कोट और धूप के चश्मे में पहुँचते हैं, तो ज़्यादा सवालों के लिए तैयार रहें।
ब्लॉक हुए बिना वेब स्क्रैपिंग के लिए ज़रूरी Python तकनीकें
अब आते हैं सबसे काम की बात पर: Python के साथ स्क्रैपिंग करते समय ब्लॉक से कैसे बचा जाए। हर स्क्रैपर को ये मुख्य रणनीतियाँ पता होनी चाहिए:

रोटेटिंग प्रॉक्सी और IP पते
यह क्यों ज़रूरी है: अगर आपके सारे अनुरोध एक ही IP से आते हैं, तो आप IP बैन के लिए आसान निशाना हैं। रोटेटिंग प्रॉक्सी आपको कई IPs पर अनुरोध बाँटने देती हैं, जिससे ब्लॉक करना कहीं कठिन हो जाता है।
Python में कैसे करें:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...more proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # process responseआप ज़्यादा भरोसेमंदी के लिए पेड प्रॉक्सी सेवाओं का इस्तेमाल कर सकते हैं (जैसे residential या rotating proxies) ()।
User-Agent और कस्टम हेडर सेट करना
यह क्यों ज़रूरी है: Python के डिफ़ॉल्ट हेडर साफ़ बताते हैं कि यह बॉट है। असली ब्राउज़र जैसा दिखने के लिए user-agent और अन्य हेडर सेट करें।
उदाहरण कोड:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)अतिरिक्त गुमनामी के लिए user-agent बदलते रहें ()।
अनुरोधों का समय और पैटर्न यादृच्छिक बनाना
यह क्यों ज़रूरी है: बॉट तेज़ और अनुमानित होते हैं; इंसान धीमे और यादृच्छिक। देरी जोड़ें और अपनी ब्राउज़िंग शैली में बदलाव करें।
Python टिप:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # 2–7 सेकंड प्रतीक्षा करेंअगर आप Selenium इस्तेमाल कर रहे हैं, तो क्लिक पाथ और स्क्रॉल पैटर्न को भी यादृच्छिक बना सकते हैं।
कुकीज़ और सत्रों का प्रबंधन
यह क्यों ज़रूरी है: कई साइटें कंटेंट एक्सेस करने के लिए कुकीज़ या सत्र टोकन मांगती हैं। इन्हें न संभालने वाले बॉट्स ब्लॉक हो जाते हैं।
Python में कैसे मैनेज करें:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session will handle cookies automaticallyज़्यादा जटिल फ़्लो के लिए, कुकीज़ कैप्चर और दोबारा इस्तेमाल करने हेतु Selenium का उपयोग करें।
हेडलेस ब्राउज़र्स के साथ इंसानी व्यवहार की नकल करना
यह क्यों ज़रूरी है: कुछ साइटें JavaScript, माउस मूवमेंट, या स्क्रॉलिंग को असली यूज़र के संकेत मानती हैं। Selenium या Playwright जैसे हेडलेस ब्राउज़र इन क्रियाओं की नकल कर सकते हैं।
Selenium के साथ उदाहरण:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))यह व्यवहारिक विश्लेषण और डायनेमिक कंटेंट को बायपास करने में मदद करता है ()।
उन्नत रणनीतियाँ: Python में CAPTCHA और हनीपॉट्स को बायपास करना
CAPTCHA बॉट्स को तुरंत रोकने के लिए बनाए जाते हैं। हालांकि कुछ Python लाइब्रेरी साधारण CAPTCHA हल कर सकती हैं, लेकिन ज़्यादातर गंभीर स्क्रैपर्स उन्हें फ़ीस देकर हल कराने के लिए 2Captcha या Anti-Captcha जैसी थर्ड-पार्टी सेवाओं पर निर्भर करते हैं ()।
उदाहरण इंटीग्रेशन:
1# Pseudocode for using 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# समाधान आने तक प्रतीक्षा करें, फिर अपने अनुरोध के साथ सबमिट करेंहनीपॉट्स छिपे हुए फ़ील्ड या लिंक होते हैं जिनसे सिर्फ़ बॉट्स ही इंटरैक्ट करते हैं। ऐसी किसी चीज़ पर क्लिक या सबमिट करने से बचें जो असली ब्राउज़र में दिखाई नहीं देती ()।
Python लाइब्रेरियों के साथ मज़बूत अनुरोध हेडर डिज़ाइन करना
User-Agent के अलावा, आप Referer, Accept, Origin आदि जैसे अन्य हेडर को भी रोटेट और रैंडमाइज़ कर सकते हैं ताकि आपका ट्रैफ़िक और स्वाभाविक लगे।
Scrapy के साथ:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # More headers
7 }
8 }Selenium के साथ: हेडर सेट करने के लिए ब्राउज़र प्रोफ़ाइल या एक्सटेंशन का उपयोग करें, या JavaScript के ज़रिए उन्हें इंजेक्ट करें।
अपनी हेडर सूची अपडेटेड रखें—प्रेरणा के लिए ब्राउज़र DevTools से असली ब्राउज़र अनुरोध कॉपी करें।
जब पारंपरिक Python स्क्रैपिंग पर्याप्त नहीं होती: एंटी-बॉट टेक्नोलॉजी का उदय
सच यह है: जैसे-जैसे स्क्रैपिंग लोकप्रिय हो रही है, वैसे-वैसे एंटी-बॉट अपग्रेड भी बढ़ रहे हैं। । AI-संचालित डिटेक्शन, डायनेमिक अनुरोध सीमाएँ, और ब्राउज़र फ़िंगरप्रिंटिंग, यहाँ तक कि उन्नत Python स्क्रिप्ट्स के लिए भी बिना पकड़े रहना पहले से कहीं कठिन बना रहे हैं ()।
कभी-कभी, आपका कोड कितना भी चतुर हो, आप एक दीवार से टकरा ही जाते हैं। तब एक अलग तरीका अपनाने का समय आ जाता है।
Thunderbit: Python स्क्रैपिंग का AI Web Scraper विकल्प
जब Python अपनी सीमाओं पर पहुँच जाता है, तो एक no-code, AI-संचालित web scraper के रूप में सामने आता है, जो सिर्फ़ डेवलपर्स के लिए नहीं, बल्कि बिज़नेस यूज़र्स के लिए बनाया गया है। प्रॉक्सी, हेडर, और CAPTCHA से जूझने के बजाय, Thunderbit का AI एजेंट वेबसाइट को पढ़ता है, निकालने के लिए सबसे अच्छे फ़ील्ड सुझाता है, और सबपेज नेविगेशन से लेकर डेटा एक्सपोर्ट तक सब कुछ संभालता है।
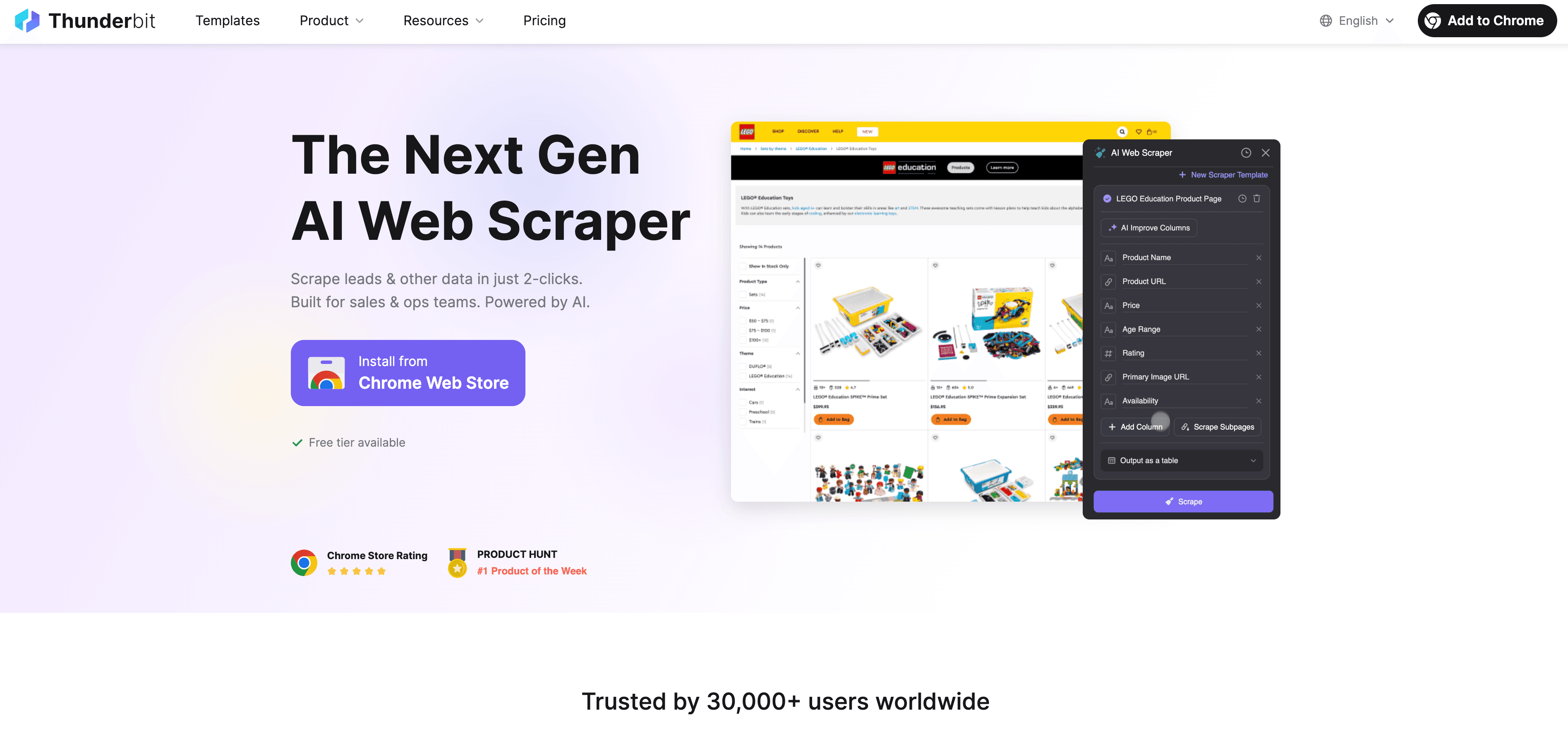
Thunderbit को अलग क्या बनाता है?
- AI फ़ील्ड सुझाव: “AI Suggest Fields” पर क्लिक करें और Thunderbit पेज स्कैन करके कॉलम सुझाता है, साथ ही एक्सट्रैक्शन निर्देश भी बनाता है।
- सबपेज स्क्रैपिंग: Thunderbit हर सबपेज (जैसे प्रोडक्ट डिटेल्स या LinkedIn प्रोफ़ाइल्स) पर जाकर आपकी टेबल को अपने आप समृद्ध कर सकता है।
- क्लाउड या ब्राउज़र स्क्रैपिंग: सबसे तेज़ विकल्प चुनें—पब्लिक साइट्स के लिए क्लाउड, लॉगिन-संरक्षित पेजों के लिए ब्राउज़र।
- शेड्यूल्ड स्क्रैपिंग: सेट करें और भूल जाएँ—Thunderbit शेड्यूल के अनुसार स्क्रैप कर सकता है, ताकि आपका डेटा हमेशा ताज़ा रहे।
- तुरंत टेम्पलेट्स: लोकप्रिय साइट्स (Amazon, Zillow, Shopify, आदि) के लिए Thunderbit 1-क्लिक टेम्पलेट्स देता है—कोई सेटअप नहीं।
- मुफ़्त डेटा एक्सपोर्ट: Excel, Google Sheets, Airtable, या Notion में एक्सपोर्ट करें—कोई अतिरिक्त शुल्क नहीं।
Thunderbit पर दुनिया भर में का भरोसा है, और आपको एक भी लाइन कोड लिखने की ज़रूरत नहीं पड़ती।
Thunderbit उपयोगकर्ताओं को ब्लॉक से बचने और डेटा एक्सट्रैक्शन ऑटोमेट करने में कैसे मदद करता है
Thunderbit का AI सिर्फ़ इंसानी व्यवहार की नकल नहीं करता—यह हर साइट के अनुसार रियल टाइम में खुद को ढालता है, जिससे ब्लॉक होने का जोखिम कम होता है। यह कैसे काम करता है:
- AI लेआउट बदलावों के अनुसार ढलता है: जब कोई साइट अपना डिज़ाइन बदलती है, तब भी स्क्रिप्ट टूटती नहीं।
- सबपेज और पेजिनेशन हैंडलिंग: Thunderbit असली यूज़र की तरह लिंक और पेजिनेटेड सूचियों का अपने आप अनुसरण करता है।
- स्केल पर क्लाउड स्क्रैपिंग: एक बार में 50 पेज तक स्क्रैप करें, बेहद तेज़ी से।
- कोडिंग नहीं, मेंटेनेंस नहीं: समय विश्लेषण में लगाइए, डिबगिंग में नहीं।
और गहराई से जानने के लिए देखें ।
Python स्क्रैपिंग बनाम Thunderbit: आपको क्या चुनना चाहिए?
आइए इन्हें आमने-सामने रखते हैं:
| फ़ीचर | Python स्क्रैपिंग | Thunderbit |
|---|---|---|
| सेटअप समय | मध्यम–उच्च (स्क्रिप्ट, प्रॉक्सी, आदि) | कम (2 क्लिक, बाकी AI करता है) |
| तकनीकी कौशल | कोडिंग ज़रूरी | कोडिंग की ज़रूरत नहीं |
| विश्वसनीयता | अलग-अलग (आसानी से टूट सकती है) | उच्च (AI बदलावों के अनुसार ढलता है) |
| ब्लॉक का जोखिम | मध्यम–उच्च | कम (AI यूज़र जैसा व्यवहार करता है, ढलता है) |
| स्केलेबिलिटी | कस्टम कोड/क्लाउड सेटअप चाहिए | बिल्ट-इन क्लाउड/बैच स्क्रैपिंग |
| मेंटेनेंस | बार-बार (साइट बदलाव, ब्लॉक) | न्यूनतम (AI अपने आप समायोजित करता है) |
| एक्सपोर्ट विकल्प | मैन्युअल (CSV, DB) | सीधे Sheets, Notion, Airtable, CSV में |
| लागत | मुफ़्त (लेकिन समय लेने वाला) | फ्री टियर, बड़े पैमाने के लिए पेड प्लान |
Python कब इस्तेमाल करें:
- आपको पूरा नियंत्रण, कस्टम लॉजिक, या अन्य Python वर्कफ़्लोज़ के साथ इंटीग्रेशन चाहिए।
- आप ऐसे साइट्स स्क्रैप कर रहे हैं जिनमें एंटी-बॉट सुरक्षा कम है।
Thunderbit कब इस्तेमाल करें:
- आपको तेज़ी, भरोसेमंदी, और शून्य सेटअप चाहिए।
- आप जटिल या अक्सर बदलने वाली साइट्स स्क्रैप कर रहे हैं।
- आप प्रॉक्सी, CAPTCHA, या कोड से निपटना नहीं चाहते।
चरण-दर-चरण गाइड: Python में ब्लॉक हुए बिना वेब स्क्रैपिंग सेट अप करना
आइए एक व्यावहारिक उदाहरण देखें: एक नमूना साइट से प्रोडक्ट डेटा स्क्रैप करना, और साथ ही एंटी-ब्लॉकिंग की सर्वोत्तम प्रथाएँ लागू करना।
1. ज़रूरी लाइब्रेरियाँ इंस्टॉल करें
1pip install requests beautifulsoup4 fake-useragent2. अपना स्क्रिप्ट तैयार करें
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # अपने URLs से बदलें
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # यहाँ डेटा निकालें
16 print(soup.title.text)
17 else:
18 print(f"{url} पर ब्लॉक या त्रुटि: {response.status_code}")
19 time.sleep(random.uniform(2, 6)) # यादृच्छिक देरी3. प्रॉक्सी रोटेशन जोड़ें (वैकल्पिक)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # और प्रॉक्सी
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...बाक़ी कोड4. कुकीज़ और सत्रों को संभालें
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...बाक़ी कोड5. समस्या-समाधान टिप्स
- अगर आपको बहुत सारे 403/429 एरर दिखें, तो अनुरोध धीमे करें या नए प्रॉक्सी आज़माएँ।
- अगर CAPTCHA आएँ, तो Selenium या CAPTCHA-हल सेवा का उपयोग करने पर विचार करें।
- हमेशा साइट की
robots.txtऔर सेवा की शर्तें जाँचें।
निष्कर्ष और मुख्य बातें
Python में वेब स्क्रैपिंग शक्तिशाली है—लेकिन एंटी-बॉट टेक्नोलॉजी के विकसित होने के साथ ब्लॉक होने का जोखिम हमेशा बना रहता है। ब्लॉक से बचने का सबसे अच्छा तरीका क्या है? तकनीकी सर्वोत्तम प्रथाओं को (रोटेटिंग प्रॉक्सी, स्मार्ट हेडर, यादृच्छिक देरी, सत्र प्रबंधन, और हेडलेस ब्राउज़र्स) साइट नियमों और नैतिकता के सम्मान के साथ मिलाएँ।
लेकिन कभी-कभी, सबसे अच्छे Python ट्रिक्स भी पर्याप्त नहीं होते। वहीं AI-संचालित टूल्स जैसे चमकते हैं—एक no-code, ब्लॉक-प्रतिरोधी, और बिज़नेस-फ्रेंडली तरीका प्रदान करते हुए, जिससे आपको जो डेटा चाहिए, वह तेज़ी से मिल जाता है।
क्या आप देखना चाहते हैं कि स्क्रैपिंग कितनी आसान हो सकती है? और खुद आज़माएँ—या अधिक स्क्रैपिंग टिप्स और ट्यूटोरियल के लिए हमारा देखें।
अक्सर पूछे जाने वाले सवाल
1. वेबसाइटें Python वेब स्क्रैपर्स को क्यों ब्लॉक करती हैं?
वेबसाइटें अपने डेटा की सुरक्षा, सर्वर पर अत्यधिक लोड से बचाव, और ऑटोमेटेड बॉट्स द्वारा सेवाओं के दुरुपयोग को रोकने के लिए स्क्रैपर्स को ब्लॉक करती हैं। अगर Python स्क्रिप्ट डिफ़ॉल्ट हेडर इस्तेमाल करती हैं, कुकीज़ संभालती नहीं हैं, या बहुत तेज़ी से बहुत सारे अनुरोध भेजती हैं, तो उन्हें पहचानना आसान होता है।
2. Python के साथ स्क्रैपिंग करते समय ब्लॉक से बचने के सबसे प्रभावी तरीके कौन से हैं?
रोटेटिंग प्रॉक्सी का उपयोग करें, यथार्थवादी user-agent और हेडर सेट करें, अनुरोधों का समय यादृच्छिक करें, कुकीज़/सत्रों का प्रबंधन करें, और Selenium या Playwright जैसे टूल्स के साथ इंसानी व्यवहार की नकल करें।
3. Thunderbit, Python स्क्रिप्ट्स की तुलना में ब्लॉक से बचने में कैसे मदद करता है?
Thunderbit AI का उपयोग करके साइट लेआउट के अनुसार ढलता है, इंसानी ब्राउज़िंग की नकल करता है, और सबपेज तथा पेजिनेशन को अपने आप हैंडल करता है। यह रियल टाइम में अपना तरीका अपडेट करके और सहजता से घुल-मिलकर ब्लॉक के जोखिम को कम करता है—कोड या प्रॉक्सी की ज़रूरत नहीं।
4. मुझे Python स्क्रैपिंग बनाम Thunderbit जैसे AI टूल का उपयोग कब करना चाहिए?
जब आपको कस्टम लॉजिक, अन्य Python कोड के साथ इंटीग्रेशन, या सरल साइट्स स्क्रैप करनी हों, तब Python इस्तेमाल करें। तेज़, भरोसेमंद, और स्केलेबल स्क्रैपिंग के लिए Thunderbit इस्तेमाल करें—खासकर तब जब साइटें जटिल हों, बार-बार बदलती हों, या स्क्रिप्ट्स को बहुत आक्रामक तरीके से ब्लॉक करती हों।
5. क्या वेब स्क्रैपिंग कानूनी है?
सार्वजनिक रूप से उपलब्ध डेटा के लिए वेब स्क्रैपिंग कानूनी है, लेकिन आपको हर साइट की सेवा शर्तों, गोपनीयता नीतियों, और लागू कानूनों का सम्मान करना होगा। कभी भी संवेदनशील या निजी डेटा स्क्रैप न करें, और हमेशा नैतिक व ज़िम्मेदार तरीके से स्क्रैपिंग करें।
क्या आप और होशियारी से, कम मेहनत में स्क्रैप करने के लिए तैयार हैं? Thunderbit आज़माइए, और ब्लॉक को पीछे छोड़ दीजिए।
और जानें:
- Python के साथ Google News स्क्रैपिंग: चरण-दर-चरण गाइड
- Python का उपयोग करके Best Buy के लिए प्राइस ट्रैकर टूल बनाएँ
- ब्लॉक हुए बिना वेब स्क्रैपिंग के 14 तरीके
- वेब स्क्रैपिंग करते समय ब्लॉक न होने के 10 बेहतरीन टिप्स