

टर्मिनल खोलना, एक ही कमांड टाइप करना, और कच्चा वेब डेटा ऐसे आते देखना जैसे आपने अभी-अभी मैट्रिक्स का रहस्य खोल दिया हो—इसमें कुछ तो कालातीत-सा है। डेवलपर्स और तकनीकी पावर यूज़र्स के लिए, cURL वही जादुई छड़ी है—एक साधारण-सा कमांड-लाइन टूल, जो चुपचाप अरबों डिवाइसों पर काम कर रहा है, क्लाउड सर्वरों से लेकर आपके स्मार्ट फ्रिज तक। और 2026 में भी, इतने सारे नो-कोड और AI स्क्रैपिंग टूल्स के बीच, कर्ल के साथ वेब स्क्रैपिंग अब भी उन सभी के लिए एक पसंदीदा तरीका है जिन्हें गति, नियंत्रण और स्क्रिप्टेबिलिटी चाहिए।
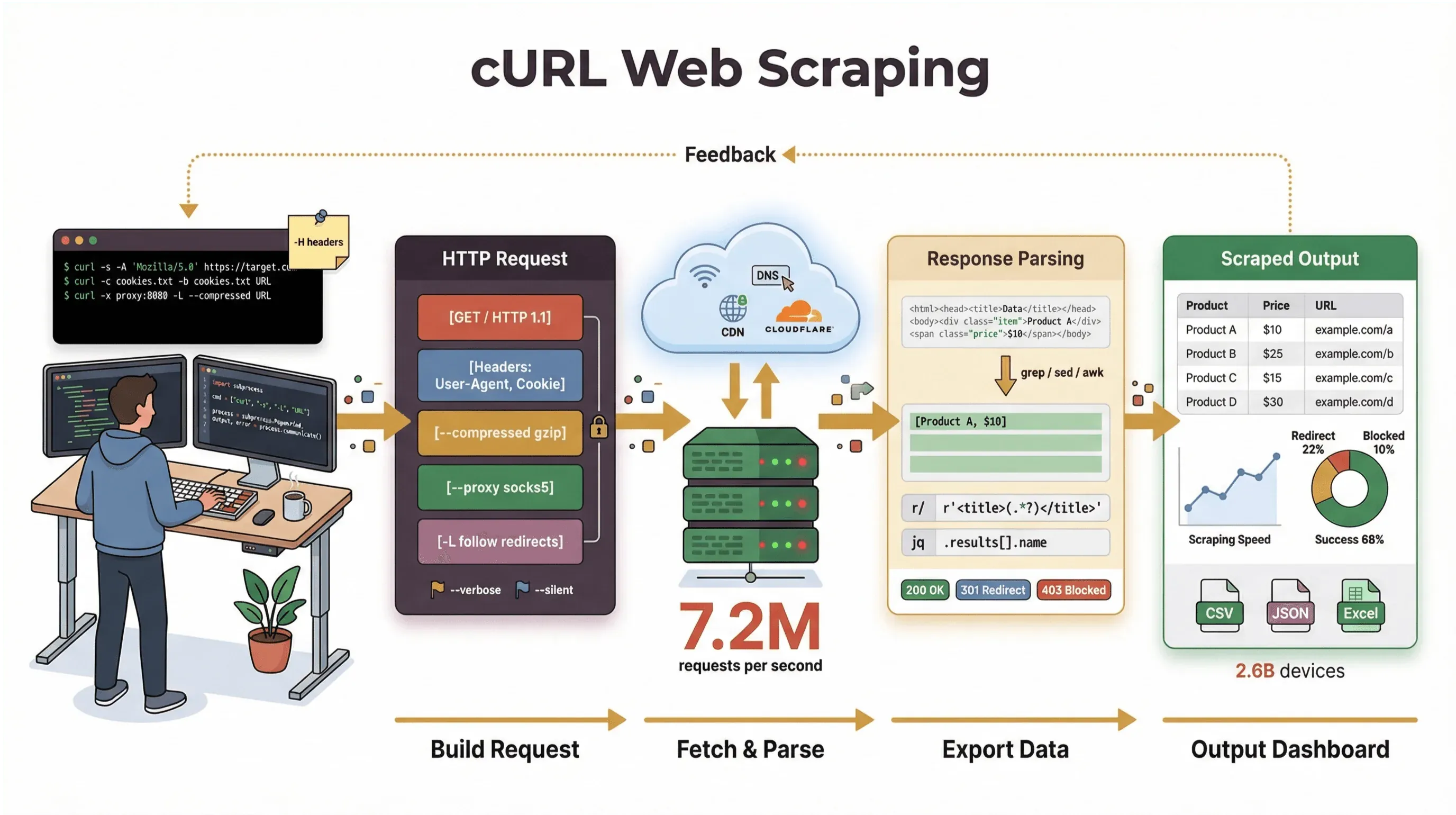 मैंने सालों तक ऑटोमेशन टूल्स बनाए हैं और टीमों को वेब डेटा संभालने में मदद की है, फिर भी जब मुझे किसी पेज को तुरंत पकड़ना हो, किसी API को डिबग करना हो, या किसी स्क्रैपिंग वर्कफ़्लो का प्रोटोटाइप बनाना हो, तो मैं आज भी cURL का ही सहारा लेता हूँ। इस गाइड में, मैं आपको कर्ल वेब स्क्रैपिंग ट्यूटोरियल के जरिए बेसिक्स और प्रो-ट्रिक्स—दोनों—समझाऊँगा। इसमें असली कमांड उदाहरण, व्यावहारिक टिप्स, और यह साफ़-साफ़ आकलन भी होगा कि cURL कहाँ चमकता है और कहाँ अटक जाता है। और अगर आप ऐसे बिज़नेस यूज़र हैं जो कमांड लाइन से छेड़छाड़ नहीं करना चाहते, तो मैं दिखाऊँगा कि हमारा AI-संचालित वेब स्क्रैपर Thunderbit आपको “मुझे यह डेटा चाहिए” से “लो, मेरी स्प्रेडशीट” तक सिर्फ दो क्लिक में कैसे पहुँचा सकता है—कोड की ज़रूरत नहीं।
मैंने सालों तक ऑटोमेशन टूल्स बनाए हैं और टीमों को वेब डेटा संभालने में मदद की है, फिर भी जब मुझे किसी पेज को तुरंत पकड़ना हो, किसी API को डिबग करना हो, या किसी स्क्रैपिंग वर्कफ़्लो का प्रोटोटाइप बनाना हो, तो मैं आज भी cURL का ही सहारा लेता हूँ। इस गाइड में, मैं आपको कर्ल वेब स्क्रैपिंग ट्यूटोरियल के जरिए बेसिक्स और प्रो-ट्रिक्स—दोनों—समझाऊँगा। इसमें असली कमांड उदाहरण, व्यावहारिक टिप्स, और यह साफ़-साफ़ आकलन भी होगा कि cURL कहाँ चमकता है और कहाँ अटक जाता है। और अगर आप ऐसे बिज़नेस यूज़र हैं जो कमांड लाइन से छेड़छाड़ नहीं करना चाहते, तो मैं दिखाऊँगा कि हमारा AI-संचालित वेब स्क्रैपर Thunderbit आपको “मुझे यह डेटा चाहिए” से “लो, मेरी स्प्रेडशीट” तक सिर्फ दो क्लिक में कैसे पहुँचा सकता है—कोड की ज़रूरत नहीं।
आइए शुरू करें और देखें कि 2026 में भी वेब स्क्रैपिंग के लिए cURL क्यों प्रासंगिक है, इसे प्रभावी ढंग से कैसे इस्तेमाल करें, और कब किसी और भी ताकतवर टूल की तरफ बढ़ना चाहिए।
cURL क्या है? कर्ल के साथ वेब स्क्रैपिंग की नींव
मूल रूप से, cURL एक कमांड-लाइन टूल और लाइब्रेरी है जो URL के जरिए डेटा ट्रांसफर करने के लिए बनाई गई है। यह लगभग 30 सालों से मौजूद है (हाँ, सच में), और हर जगह है—ऑपरेटिंग सिस्टम्स में एम्बेडेड, स्क्रिप्ट्स को पावर देता हुआ, और चुपचाप बीस अरब से अधिक इंस्टॉलेशनों में डेटा ट्रांसफ़र संभालता हुआ। अगर आपने कभी जल्दी से कोई वेब पेज फ़ेच करने, किसी API को टेस्ट करने, या कोई फ़ाइल डाउनलोड करने के लिए कमांड चलाया है, तो बहुत संभव है कि आपने cURL इस्तेमाल किया हो।
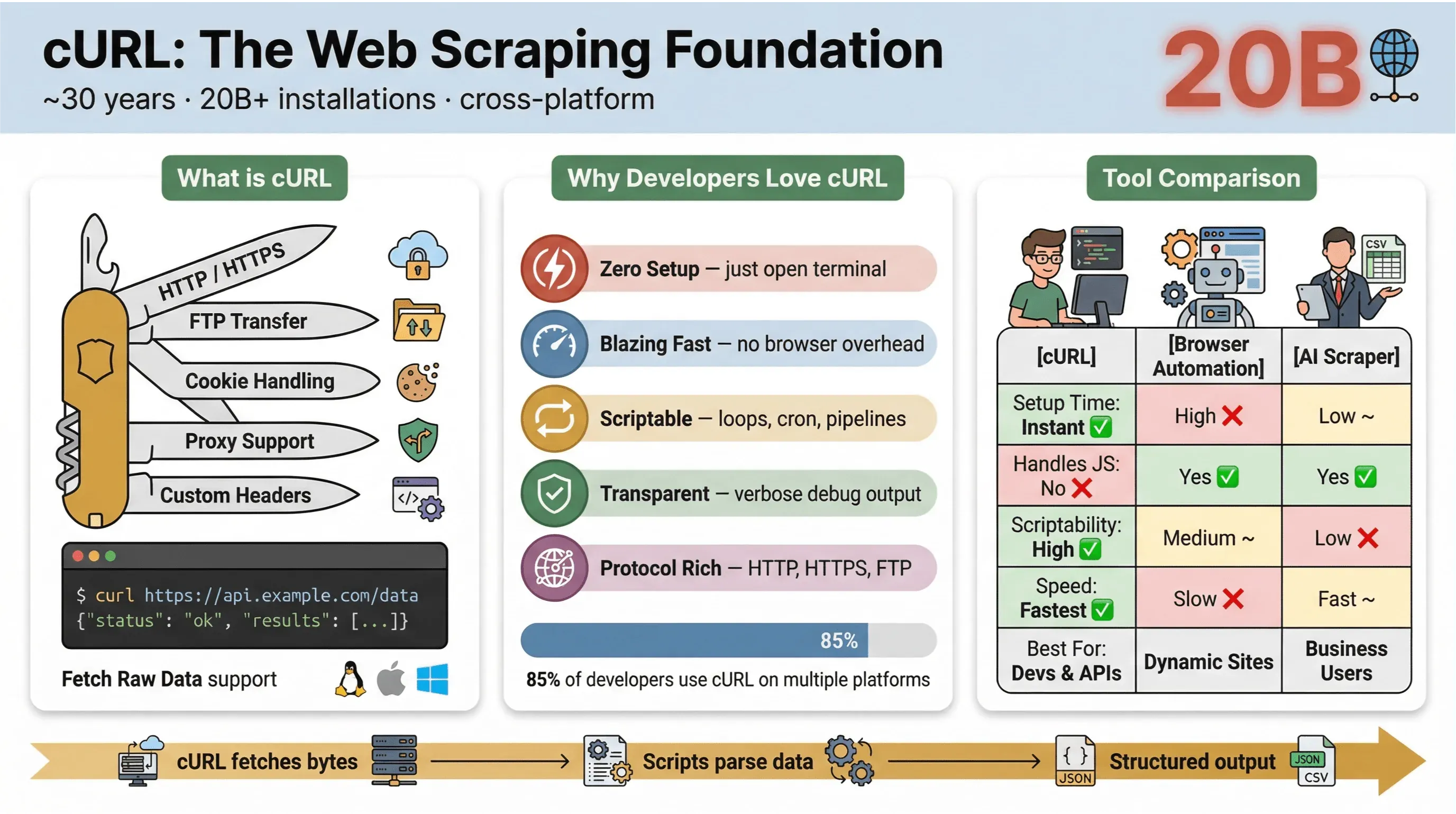 वेब स्क्रैपिंग के लिए cURL इतना लोकप्रिय क्यों है, इसकी वजहें ये हैं:
वेब स्क्रैपिंग के लिए cURL इतना लोकप्रिय क्यों है, इसकी वजहें ये हैं:
- हल्का और क्रॉस-प्लेटफ़ॉर्म: Linux, macOS, Windows, और यहाँ तक कि एम्बेडेड डिवाइसों पर भी चलता है।
- प्रोटोकॉल सपोर्ट: HTTP, HTTPS, FTP, और बहुत कुछ संभालता है।
- स्क्रिप्ट करने योग्य: ऑटोमेशन, cron jobs, और glue code के लिए बिल्कुल उपयुक्त।
- यूज़र इंटरैक्शन की ज़रूरत नहीं: बिना इंटरैक्शन के काम करने के लिए बनाया गया—बैच जॉब्स और पाइपलाइनों के लिए बढ़िया।
लेकिन साफ़ बात यह है कि cURL का मुख्य काम कच्चा डेटा—HTML, JSON, इमेज, जो भी हो—फ़ेच करना है। यह उस डेटा को आपके लिए पार्स, रेंडर, या संरचित नहीं करता। cURL को वेब स्क्रैपिंग का “पहला मील” समझिए: यह आपको बाइट्स तक पहुँचाता है, लेकिन उन्हें संरचित जानकारी में बदलने के लिए आपको अन्य टूल्स (जैसे Python स्क्रिप्ट्स, grep/sed/awk, या कोई AI वेब स्क्रैपर) चाहिए होंगे।
अगर आप आधिकारिक डॉक्यूमेंटेशन देखना चाहते हैं, तो cURL की HTTP scripting guide देखें।
वेब स्क्रैपिंग के लिए cURL क्यों इस्तेमाल करें? (कर्ल वेब स्क्रैपिंग ट्यूटोरियल)
तो इतने सारे नए टूल्स होने के बावजूद डेवलपर्स और तकनीकी यूज़र वेब स्क्रैपिंग के लिए बार-बार cURL की ओर क्यों लौटते हैं? इसकी खास बातें ये हैं:
- कम से कम सेटअप: न इंस्टॉल की झंझट, न डिपेंडेंसी—बस टर्मिनल खोलिए और शुरू हो जाइए।
- गति: ब्राउज़र के लोड होने का इंतज़ार किए बिना तुरंत डेटा फ़ेच करें।
- स्क्रिप्टेबिलिटी: URLs पर आसानी से लूप चला सकते हैं, रिक्वेस्ट्स ऑटोमेट कर सकते हैं, और कमांड्स चेन कर सकते हैं।
- प्रोटोकॉल और फीचर सपोर्ट: कुकीज़, प्रॉक्सी, रीडायरेक्ट्स, कस्टम हेडर्स, और बहुत कुछ संभाल सकता है।
- पारदर्शिता: verbose/debug आउटपुट के साथ ठीक-ठीक देख सकते हैं कि क्या हो रहा है।
2025 cURL user survey में, 85.7% उत्तरदाताओं ने कहा कि वे cURL कमांड-लाइन टूल का उपयोग करते हैं, और 96.2% ने बताया कि वे इसे Linux पर इस्तेमाल करते हैं — जो अब भी cURL के लिए सबसे बड़ा प्लेटफ़ॉर्म है।
--- यह अब भी HTTP रिक्वेस्ट्स, तेज़ डेटा पुल्स, और ट्रबलशूटिंग के लिए स्विस आर्मी नाइफ जैसा है।
यहाँ cURL और दूसरे स्क्रैपिंग तरीकों की एक तेज़ तुलना है:
| विशेषता | cURL | ब्राउज़र ऑटोमेशन (जैसे Selenium) | AI वेब स्क्रैपर (जैसे Thunderbit) |
|---|---|---|---|
| सेटअप समय | तुरंत | अधिक | कम |
| स्क्रिप्टेबिलिटी | उच्च | मध्यम | कम (कोड की ज़रूरत नहीं) |
| JavaScript संभालता है | नहीं | हाँ | हाँ (Thunderbit: ब्राउज़र के जरिए) |
| कुकी/सेशन सपोर्ट | मैनुअल | स्वचालित | स्वचालित |
| डेटा संरचना | मैनुअल (बाद में पार्स करें) | मैनुअल (बाद में पार्स करें) | AI/टेम्पलेट-आधारित |
| सबसे अच्छा किसके लिए है | डेवलपर्स, तेज़ पुल्स | जटिल, डायनेमिक साइट्स | बिज़नेस यूज़र्स, संरचित एक्सपोर्ट |
संक्षेप में: तेज़, स्क्रिप्ट करने योग्य डेटा निकालने के लिए cURL का कोई जवाब नहीं—खासकर स्टैटिक पेजों, APIs, या जब आप सरल वर्कफ़्लोज़ ऑटोमेट करना चाहते हों। लेकिन जैसे ही आपको जटिल HTML पार्स करना हो, JavaScript संभालना हो, या संरचित डेटा एक्सपोर्ट करना हो, आपको कुछ अधिक विशेषीकृत चाहिए होगा।
शुरुआत करें: कर्ल वेब स्क्रैपिंग के बुनियादी कमांड उदाहरण
चलो हाथ आज़माते हैं। यहाँ बताया गया है कि बुनियादी वेब स्क्रैपिंग कार्यों के लिए cURL का उपयोग कैसे करें, चरण-दर-चरण।
cURL से कच्चा HTML फ़ेच करना
सबसे सरल उपयोग: किसी वेब पेज का HTML पकड़ लीजिए।
curl https://books.toscrape.com/
यह कमांड Books to Scrape के होमपेज को फ़ेच करती है, जो वेब स्क्रैपिंग के लिए एक सार्वजनिक डेमो साइट है। आपको अपने टर्मिनल में कच्चा HTML आउटपुट दिखेगा—<title> जैसे टैग्स या “In stock” जैसे स्निपेट्स देखें।
आउटपुट को फ़ाइल में सेव करना
क्या आप बाद में पार्सिंग के लिए HTML सहेजना चाहते हैं? -o फ़्लैग का इस्तेमाल करें:
curl -o page.html https://books.toscrape.com/
अब आपके पास पूरा HTML कंटेंट वाली page.html फ़ाइल होगी। आगे विश्लेषण या अन्य टूल्स से पार्सिंग के लिए यह बहुत उपयोगी है।
cURL से POST रिक्वेस्ट भेजना
क्या आपको कोई फ़ॉर्म सबमिट करना है या API से इंटरैक्ट करना है? POST रिक्वेस्ट के लिए -d फ़्लैग का उपयोग करें। यहाँ httpbin का उदाहरण है, जो HTTP टेस्टिंग के लिए बनाया गया है:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
आपको JSON रिस्पॉन्स मिलेगा जो आपके भेजे गए डेटा को वापस दिखाएगा—टेस्टिंग और प्रोटोटाइपिंग के लिए बढ़िया।
हेडर्स देखना और डिबग करना
कभी-कभी आप रिस्पॉन्स हेडर्स देखना चाहते हैं या रिक्वेस्ट को डिबग करना चाहते हैं:
-
सिर्फ हेडर्स (HEAD रिक्वेस्ट):
curl -I https://books.toscrape.com/ -
बॉडी के साथ हेडर्स शामिल करें:
curl -i https://httpbin.org/get -
verbose/debug आउटपुट:
curl -v https://books.toscrape.com/
ये फ़्लैग्स आपको यह समझने में मदद करते हैं कि भीतर क्या हो रहा है—ट्रबलशूटिंग के लिए बेहद ज़रूरी।
इन कमांड्स के लिए एक तेज़ संदर्भ तालिका यहाँ है:
| कार्य | कमांड उदाहरण | नोट्स |
|---|---|---|
| HTML फ़ेच करें | curl URL | HTML को टर्मिनल में आउटपुट करता है |
| फ़ाइल में सेव करें | curl -o file.html URL | आउटपुट को फ़ाइल में लिखता है |
| हेडर्स देखें | curl -I URL या curl -i URL | -I केवल HEAD के लिए, -i बॉडी के साथ हेडर्स भी शामिल करता है |
| POST फ़ॉर्म डेटा | curl -d "a=1&b=2" URL | फ़ॉर्म-एन्कोडेड डेटा भेजता है |
| रिक्वेस्ट/रिस्पॉन्स डिबग करें | curl -v URL | विस्तृत रिक्वेस्ट/रिस्पॉन्स जानकारी दिखाता है |
और उदाहरणों के लिए, आधिकारिक cURL scripting docs देखें।
आगे बढ़ें: cURL के साथ उन्नत वेब स्क्रैपिंग (कर्ल के साथ वेब स्क्रैपिंग)
बेसिक्स में सहज होने के बाद, cURL अधिक जटिल स्क्रैपिंग कार्यों के लिए उन्नत फीचर्स की दुनिया खोल देता है।
कुकीज़ और सेशन्स संभालना
कई साइट्स लॉगिन सेशन बनाए रखने या यूज़र्स को ट्रैक करने के लिए कुकीज़ की ज़रूरत होती है। cURL के साथ, आप रिक्वेस्ट्स के बीच कुकीज़ सेव और दोबारा इस्तेमाल कर सकते हैं:
# लॉगिन के बाद कुकीज़ स्टोर करें
curl -c cookies.txt https://example.com/login
# अगली रिक्वेस्ट्स के लिए कुकीज़ इस्तेमाल करें
curl -b cookies.txt https://example.com/account
इससे आप ब्राउज़र सेशन की नकल कर सकते हैं और लॉगिन-प्रोटेक्टेड पेजों तक पहुँच सकते हैं (जब तक वहाँ JavaScript challenge न हो)।
User-Agent और कस्टम हेडर्स स्पूफ़ करना
कुछ वेबसाइटें आपके User-Agent या हेडर्स के आधार पर अलग कंटेंट देती हैं। डिफ़ॉल्ट रूप से, cURL खुद को “curl/VERSION” के रूप में पहचानता है, जिससे ब्लॉक्स या अलग कंटेंट मिल सकता है। ब्राउज़र जैसा दिखाने के लिए:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
आप भाषा प्राथमिकताओं जैसे कस्टम हेडर्स भी सेट कर सकते हैं:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
इससे आपको वही कंटेंट मिल सकता है जो एक वास्तविक ब्राउज़र देखता।
वेब स्क्रैपिंग के लिए प्रॉक्सी का उपयोग
क्या आपको अपनी रिक्वेस्ट्स किसी प्रॉक्सी के जरिए भेजनी हैं (जैसे geo-testing के लिए या IP bans से बचने के लिए)? -x फ़्लैग का उपयोग करें:
curl -x http://proxy.example.org:4321 https://remote.example.org/
बस यह सुनिश्चित करें कि आप प्रॉक्सी का उपयोग ज़िम्मेदारी से और साइट की सेवा-शर्तों के भीतर कर रहे हैं।
कई पेजों की स्क्रैपिंग ऑटोमेट करना
क्या आप कई पेज स्क्रैप करना चाहते हैं—जैसे paginated product listings? एक साधारण shell loop इस्तेमाल करें:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
यह Books to Scrape कैटलॉग के पेज 2 से 5 तक लाता है और हर पेज को अलग फ़ाइल में सेव करता है। (पेज 1 होमपेज है।)
कर्ल वेब स्क्रैपिंग की सीमाएँ: आपको क्या जानना चाहिए
मुझे cURL बहुत पसंद है, लेकिन यह कोई जादुई समाधान नहीं है। यहाँ इसकी सीमाएँ हैं:
- JavaScript निष्पादन नहीं: cURL उन पेजों को संभाल नहीं सकता जिन्हें कंटेंट रेंडर करने या anti-bot challenges हल करने के लिए JavaScript की ज़रूरत हो (developers.cloudflare.com).
- मैनुअल पार्सिंग ज़रूरी: आपको कच्चा HTML या JSON मिलता है, लेकिन उसे स्वयं पार्स करना होगा—अक्सर अतिरिक्त स्क्रिप्ट्स या टूल्स के साथ।
- सीमित सेशन हैंडलिंग: जटिल लॉगिन, टोकन, या मल्टी-स्टेप फ़ॉर्म को संभालना जल्दी ही उलझ सकता है।
- बिल्ट-इन डेटा संरचना नहीं: cURL वेब पेजों को पंक्तियों, तालिकाओं, या स्प्रेडशीट में नहीं बदलता।
- anti-bot detection का असर: कई साइट्स अब उन्नत बॉट डिफ़ेन्स (JavaScript, fingerprinting, CAPTCHAs) का इस्तेमाल करती हैं, जिन्हें cURL बस बायपास नहीं कर सकता (datadome.co).
यहाँ एक तेज़ तुलना तालिका है:
| सीमा | सिर्फ cURL | आधुनिक स्क्रैपिंग टूल्स (जैसे Thunderbit) |
|---|---|---|
| JavaScript सपोर्ट | नहीं | हाँ |
| डेटा संरचना | मैनुअल | स्वचालित (AI/टेम्पलेट) |
| सेशन हैंडलिंग | मैनुअल | स्वचालित |
| anti-bot बायपास | सीमित | उन्नत (ब्राउज़र-आधारित/AI) |
| उपयोग में आसानी | तकनीकी | गैर-तकनीकी |
स्टैटिक पेजों और APIs के लिए cURL शानदार है। लेकिन अधिक डायनेमिक या संरक्षित चीज़ों के लिए, आपको टूलचेन में आगे बढ़ना होगा।
Thunderbit बनाम cURL: गैर-तकनीकी यूज़र्स के लिए सर्वोत्तम वेब स्क्रैपिंग तरीका
अब Thunderbit की बात करते हैं, हमारा AI-संचालित वेब स्क्रैपर Chrome Extension। अगर आप सेल्स, मार्केटिंग, या ऑपरेशंस में हैं और बस किसी वेबसाइट से डेटा Excel, Google Sheets, या Notion में चाहते हैं—वह भी कमांड लाइन छुए बिना—तो Thunderbit आपके लिए ही बनाया गया है।
cURL की तुलना में Thunderbit कुछ ऐसा दिखता है:
| विशेषता | cURL | Thunderbit |
|---|---|---|
| यूज़र इंटरफ़ेस | कमांड लाइन | क्लिक-करके चलाने वाला (Chrome Extension) |
| AI फ़ील्ड सुझाव | नहीं | हाँ (AI पेज पढ़ता है, कॉलम सुझाता है) |
| Pagination/Subpages संभालना | मैनुअल स्क्रिप्टिंग | स्वचालित (AI पहचानता है और स्क्रैप करता है) |
| डेटा एक्सपोर्ट | मैनुअल (पार्स + सेव) | सीधे Excel, Google Sheets, Notion, Airtable में |
| JavaScript/Protected Pages | नहीं | हाँ (ब्राउज़र-आधारित स्क्रैपिंग) |
| No-Code की ज़रूरत नहीं | नहीं (स्क्रिप्टिंग चाहिए) | हाँ (कोई भी इस्तेमाल कर सकता है) |
| Free Tier | हमेशा मुफ़्त | 6 पेज तक मुफ़्त (trial boost के साथ 10) |
Thunderbit में, बस एक्सटेंशन खोलिए, “AI Suggest Fields” पर क्लिक कीजिए, और AI को डेटा निकालने दीजिए। आप टेबल्स, लिस्ट्स, प्रोडक्ट डिटेल्स, और यहाँ तक कि subpages भी अपने-आप विज़िट कर सकते हैं। फिर अपना डेटा सीधे अपने पसंदीदा बिज़नेस टूल्स में एक्सपोर्ट करें—न पार्सिंग, न सिरदर्द।
Thunderbit पर दुनिया भर में 100,000+ यूज़र्स भरोसा करते हैं, और यह खासकर sales, ecommerce, और real estate टीमों में लोकप्रिय है जिन्हें जल्दी संरचित डेटा चाहिए।
वेब स्क्रैपिंग के लिए Thunderbit Chrome Extension आज़माएँ
इसे आज़माना चाहते हैं? Chrome Extension यहाँ डाउनलोड करें।
cURL और Thunderbit को मिलाकर इस्तेमाल करना: लचीली वेब स्क्रैपिंग रणनीतियाँ
अगर आप तकनीकी यूज़र हैं, तो सिर्फ एक टूल चुनने की ज़रूरत नहीं है। सच तो यह है कि कई टीमें अधिकतम लचीलापन पाने के लिए cURL और Thunderbit दोनों का साथ में इस्तेमाल करती हैं:
- cURL से प्रोटोटाइप बनाएँ: cURL से जल्दी endpoints टेस्ट करें, हेडर्स देखें, और समझें कि साइट कैसे जवाब देती है।
- Thunderbit से स्केल करें: जब आपको संरचित डेटा, multi-page scraping, या दोहराए जा सकने वाला वर्कफ़्लो चाहिए, तो point-and-click extraction और direct exports के लिए Thunderbit पर स्विच करें।
मार्केट रिसर्च के लिए एक नमूना वर्कफ़्लो:
- cURL से कुछ पेज फ़ेच करें और HTML संरचना देखें।
- जिन डेटा फ़ील्ड्स की ज़रूरत है उन्हें पहचानें (जैसे product names, prices, reviews)।
- Thunderbit खोलें, “AI Suggest Fields” पर क्लिक करें, और AI को scraper सेट अप करने दें।
- सभी पेज स्क्रैप करें (subpages या paginated lists सहित) और Google Sheets में एक्सपोर्ट करें।
- अपने डेटा का विश्लेषण, साझा करना, और उस पर कार्रवाई करें—मैनुअल पार्सिंग की ज़रूरत नहीं।
यहाँ एक तेज़ निर्णय तालिका है:
| परिदृश्य | cURL इस्तेमाल करें | Thunderbit इस्तेमाल करें | दोनों इस्तेमाल करें |
|---|---|---|---|
| त्वरित API या स्टैटिक पेज फ़ेच | ✅ | ||
| स्प्रेडशीट में संरचित डेटा चाहिए | ✅ | ||
| हेडर्स/कुकीज़ डिबग करना | ✅ | ||
| डायनेमिक/JavaScript-heavy पेज स्क्रैप करना | ✅ | ||
| दोहराया जा सकने वाला, नो-कोड वर्कफ़्लो बनाना | ✅ | ||
| पहले प्रोटोटाइप, फिर स्केल अप | ✅ | ✅ | हाइब्रिड वर्कफ़्लो |
cURL के साथ वेब स्क्रैपिंग में सामान्य चुनौतियाँ और गलतियाँ
cURL के साथ बहुत आगे बढ़ने से पहले, असली दुनिया की चुनौतियों पर बात कर लेते हैं:
- anti-bot सिस्टम: कई साइट्स अब उन्नत डिफ़ेन्स (JavaScript challenges, CAPTCHAs, fingerprinting) इस्तेमाल करती हैं, जिन्हें cURL बायपास नहीं कर सकता (developers.cloudflare.com).
- डेटा गुणवत्ता की समस्याएँ: HTML में बदलाव, फ़ील्ड्स का गायब होना, या inconsistent layouts आपकी स्क्रिप्ट्स तोड़ सकते हैं।
- मेंटेनेंस का बोझ: जब भी साइट बदलती है, आपको अपनी पार्सिंग लॉजिक अपडेट करनी होगी।
- कानूनी और अनुपालन जोखिम: स्क्रैप करने से पहले हमेशा साइट की सेवा-शर्तें, robots.txt, और संबंधित कानून जाँचें। सिर्फ इसलिए कि डेटा सार्वजनिक है, इसका मतलब यह नहीं कि उसका इस्तेमाल मुफ़्त है (calawyers.org, polsinelli.com).
- स्केलिंग सीमाएँ: cURL छोटे कामों के लिए बढ़िया है, लेकिन बड़े पैमाने पर स्क्रैपिंग के लिए आपको प्रॉक्सी, rate limits, और error handling संभालना होगा।
ट्रबलशूटिंग और अनुपालन बनाए रखने के टिप्स:
- हमेशा अनुमति वाले या डेमो साइट्स से शुरू करें (जैसे Books to Scrape)।
- rate limits का सम्मान करें—endpoints पर अनावश्यक बोझ न डालें।
- व्यक्तिगत डेटा स्क्रैप करने से बचें, जब तक आपके पास वैध आधार न हो।
- अगर JavaScript या CAPTCHA की दीवार मिले, तो Thunderbit जैसे ब्राउज़र-आधारित टूल पर स्विच करने पर विचार करें।
चरण-दर-चरण सारांश: cURL से वेबसाइटें कैसे स्क्रैप करें
कर्ल के साथ वेब स्क्रैपिंग के लिए आपकी त्वरित-संदर्भ चेकलिस्ट यह है:
- अपने target URL(s) पहचानें: किसी स्टैटिक पेज या API endpoint से शुरू करें।
- पेज फ़ेच करें:
curl URL - आउटपुट को फ़ाइल में सेव करें:
curl -o file.html URL - हेडर्स देखें/डिबग करें:
curl -I URL,curl -v URL - POST डेटा भेजें:
curl -d "a=1&b=2" URL - कुकीज़/सेशन्स संभालें:
curl -c cookies.txt ...,curl -b cookies.txt ... - कस्टम हेडर्स/User-Agent सेट करें:
curl -A "..." -H "..." URL - रीडायरेक्ट्स फ़ॉलो करें:
curl -L URL - प्रॉक्सी इस्तेमाल करें (अगर ज़रूरत हो):
curl -x proxy:port URL - कई पेजों की स्क्रैपिंग ऑटोमेट करें: shell loops या scripts का उपयोग करें।
- डेटा पार्स और संरचित करें: ज़रूरत के अनुसार अतिरिक्त टूल्स/स्क्रिप्ट्स इस्तेमाल करें।
- संरचित, नो-कोड स्क्रैपिंग या डायनेमिक पेजों के लिए Thunderbit पर स्विच करें।
निष्कर्ष और मुख्य बातें: सही वेब स्क्रैपिंग टूल चुनना
AI का उपयोग करके किसी भी वेबसाइट से डेटा स्क्रैप करें Get Started Free
कर्ल के साथ वेब स्क्रैपिंग 2026 में भी तकनीकी यूज़र्स के लिए एक शक्तिशाली कौशल है—खासकर त्वरित डेटा पुल्स, प्रोटोटाइपिंग, और ऑटोमेशन के लिए। cURL की गति, स्क्रिप्टेबिलिटी, और सर्वव्यापकता इसे हर डेवलपर के टूलबॉक्स का स्थायी हिस्सा बनाती है। लेकिन जैसे-जैसे वेब अधिक डायनेमिक और संरक्षित होता जा रहा है, और जैसे-जैसे बिज़नेस यूज़र्स को बिना कोड के संरचित डेटा चाहिए, Thunderbit जैसे टूल्स यह फिर से परिभाषित कर रहे हैं कि क्या संभव है।
मुख्य बातें:
- स्टैटिक पेजों, APIs, और त्वरित प्रोटोटाइपिंग के लिए cURL का उपयोग करें—खासकर जब आप पूरा नियंत्रण चाहते हों।
- जब आपको संरचित डेटा चाहिए, डायनेमिक/JavaScript-heavy पेज संभालने हों, या नो-कोड, बिज़नेस-फ्रेंडली वर्कफ़्लो चाहिए, तब Thunderbit (या इसी तरह के AI वेब स्क्रैपर्स) पर जाएँ।
- अधिकतम लचीलापन पाने के लिए दोनों को मिलाकर इस्तेमाल करें: cURL से प्रोटोटाइप बनाइए, Thunderbit से स्केल और संरचना कीजिए।
- हमेशा जिम्मेदारी से स्क्रैप करें—साइट की शर्तों, rate limits, और कानूनी सीमाओं का सम्मान करें।
देखना चाहते हैं कि वेब स्क्रैपिंग कितनी आसान हो सकती है? Thunderbit का मुफ़्त Chrome Extension आज़माएँ और खुद AI-संचालित डेटा एक्सट्रैक्शन का अनुभव करें। और अगर आप और गहराई में जाना चाहते हैं, तो अधिक ट्यूटोरियल्स, टिप्स, और इंडस्ट्री इनसाइट्स के लिए Thunderbit Blog देखें। आपको ये भी पसंद आ सकते हैं:
- AI का उपयोग करके किसी भी वेबसाइट को कैसे स्क्रैप करें
- AI का उपयोग करके वेबसाइट डेटा को Excel में कैसे स्क्रैप करें
- डेटा स्क्रैपिंग क्या है और 2025 में इसे कैसे करें
खुश रहकर स्क्रैपिंग करें—और आपका डेटा हमेशा साफ़, संरचित, और बस एक कमांड (या क्लिक) दूर रहे।
स्केलेबल वेब स्क्रैपिंग के लिए Thunderbit योजनाएँ देखें
अक्सर पूछे जाने वाले प्रश्न
1. क्या cURL JavaScript-rendered वेब पेज संभाल सकता है?
नहीं, cURL JavaScript निष्पादित नहीं कर सकता। यह सर्वर द्वारा दी गई कच्ची HTML फ़ाइल ही फ़ेच करता है। अगर किसी पेज को कंटेंट रेंडर करने या anti-bot challenges हल करने के लिए JavaScript चाहिए, तो cURL उस डेटा तक पहुँच नहीं पाएगा। ऐसे मामलों में Thunderbit जैसे ब्राउज़र-आधारित टूल्स इस्तेमाल करें।
2. cURL आउटपुट को सीधे फ़ाइल में कैसे सेव करूँ?
-o फ़्लैग का उपयोग करें: curl -o filename.html URL. इससे रिस्पॉन्स बॉडी टर्मिनल में दिखाने के बजाय फ़ाइल में लिख दी जाती है।
3. वेब स्क्रैपिंग के लिए cURL और Thunderbit में क्या अंतर है?
cURL एक कमांड-लाइन टूल है जो कच्चा वेब डेटा फ़ेच करता है—तकनीकी यूज़र्स और ऑटोमेशन के लिए बढ़िया। Thunderbit एक AI-संचालित Chrome Extension है, जिसे उन बिज़नेस यूज़र्स के लिए बनाया गया है जो किसी भी वेबसाइट से संरचित डेटा निकालना चाहते हैं, डायनेमिक पेज संभालना चाहते हैं, और सीधे Excel या Google Sheets जैसे टूल्स में एक्सपोर्ट करना चाहते हैं—कोड की ज़रूरत नहीं।
4. क्या cURL से वेबसाइटें स्क्रैप करना कानूनी है?
हालिया कोर्ट फ़ैसलों के बाद सार्वजनिक डेटा को स्क्रैप करना आम तौर पर अमेरिका में कानूनी है, लेकिन हमेशा वेबसाइट की सेवा-शर्तें, robots.txt, और संबंधित कानून जाँचें। बिना अनुमति के निजी या संरक्षित डेटा स्क्रैप करने से बचें, और rate limits तथा नैतिक दिशानिर्देशों का सम्मान करें (calawyers.org, polsinelli.com).
5. मुझे cURL से Thunderbit जैसे अधिक उन्नत टूल पर कब स्विच करना चाहिए?
अगर आपको dynamic/JavaScript-heavy पेज स्क्रैप करने हैं, स्प्रेडशीट में संरचित डेटा चाहिए, या नो-कोड वर्कफ़्लो पसंद है, तो Thunderbit बेहतर विकल्प है। cURL का उपयोग तेज़, तकनीकी कार्यों के लिए करें; Thunderbit का उपयोग बिज़नेस-फ्रेंडली, दोहराए जा सकने वाले डेटा एक्सट्रैक्शन के लिए करें।
और वेब स्क्रैपिंग टिप्स व ट्यूटोरियल्स के लिए Thunderbit Blog देखें या हमारा YouTube Channel देखें।
Thunderbit AI वेब स्क्रैपर आज़माएँ Get Started Free




