आप ScraperAPI के लिए साइन अप करते हैं, अपने Hobby प्लान में "100,000 credits" देखते हैं, और डेटा स्क्रैप करना शुरू कर देते हैं। तीन दिन बाद डैशबोर्ड दिखाता है कि उन क्रेडिट्स का 80% खत्म हो चुका है — और आपने शायद 6,000 पेज ही निकाले हैं। आखिर हुआ क्या? वजह है क्रेडिट मल्टीप्लायर सिस्टम, और ScraperAPI के बारे में यह सबसे अहम बात है जिसे लगभग कोई भी समीक्षा ठीक से नहीं समझाती। मैंने हफ्तों तक ScraperAPI की डॉक्यूमेंटेशन खंगाली, पाँच प्रतिस्पर्धी प्रोवाइडर्स की असली प्राइसिंग निकाली, और Reddit तथा Capterra पर हर उपलब्ध थ्रेड और रिव्यू पढ़ा। यह ScraperAPI समीक्षा वही है जैसी मुझे तब चाहिए थी जब हमारी टीम पहली बार scraping APIs का मूल्यांकन कर रही थी। यहां मैं क्रेडिट्स का असली गणित समझाऊँगा, दिखाऊँगा कि ScraperAPI कहाँ अच्छा करता है और कहाँ पूरी तरह चूक जाता है, G2, Capterra और Reddit पर यूज़र्स क्या कह रहे हैं उसका सार दूँगा, और — ईमानदारी से — यह तय करने में मदद करूँगा कि आपको scraping API की जरूरत भी है या नहीं।
ScraperAPI क्या है और यह किन लोगों के लिए बना है?
ScraperAPI एक web scraping API है जो बड़े पैमाने पर स्क्रैपिंग के पीछे की मुश्किल infrastructure संभालता है: में proxy rotation, automatic CAPTCHA solving, JavaScript rendering, और automatic retries। आप एक साधारण API call के जरिए इसे URL भेजते हैं, और यह HTML लौटाता है (या structured data endpoints इस्तेमाल करने पर parsed JSON देता है)। कंपनी की स्थापना 2018 में Daniel Ni ने की थी, इसका मुख्यालय Las Vegas में है, और अब यह को सेव करती है — जिनमें Deloitte, Sony, और Alibaba शामिल हैं — और प्रोसेस करती है।
इसका मुख्य उपयोग developer teams और technical ops करते हैं जो custom scraping pipelines बनाते हैं। अगर आप code नहीं लिखते, तो ScraperAPI आपके लिए नहीं बना है (इस पर आगे बात करेंगे)।
मुख्य फीचर्स: proxy rotation, JavaScript rendering, geotargeting, लोकप्रिय साइटों के लिए structured data endpoints, और failed requests के लिए automatic retries।
लेकिन सबसे अहम बात जिसे अधिकतर reviews हल्का छोड़ देती हैं: ScraperAPI के pricing page पर दिखने वाले headline credit numbers तब तक बेहद भ्रामक हैं जब तक आप multipliers का सिस्टम नहीं समझते। इसलिए शुरू वहीं से करते हैं।
ScraperAPI का Credit System असल में कैसे काम करता है (वह हिस्सा जिसे ज़्यादातर reviews छोड़ देती हैं)
ScraperAPI billing के लिए credit system इस्तेमाल करता है। बुनियादी नियम आसान है: 1 API request = 1 credit। लेकिन असल में लगभग कभी ऐसा नहीं होता। असली credit cost दो चीज़ों पर निर्भर करती है: आप किस domain को scrape कर रहे हैं, और कौन-कौन से feature flags enabled हैं। और ये costs ऐसे जुड़ती हैं जो सहज नहीं लगतीं।
Credit Multiplier Table जो हर यूज़र को signup से पहले देखनी चाहिए

एक भी parameter बदलने से पहले, जिस वेबसाइट को आप scrape कर रहे हैं उसका प्रकार ही आपकी base credit cost तय करता है:
| Domain Category | Base Credits per Request | Examples |
|---|---|---|
| Normal websites | 1 | Blogs, news sites, simple HTML |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (search engines) | 25 | Google, Bing |
| Social media | 30 |
इसके ऊपर, feature flags extra credits जोड़ते हैं:
| Parameter | Extra Credits | Notes |
|---|---|---|
render=true (JS rendering) | +10 | All plans |
screenshot=true | +10 | All plans |
premium=true (premium proxy) | +10 | All plans |
ultra_premium=true | +30 | Paid plans only |
| Anti-bot bypass (Cloudflare, DataDome, PerimeterX) | +10 each | Auto-detected — you don't choose this |
premium=true + render=true combined | +25 | NOT +20 |
ultra_premium=true + render=true combined | +75 | NOT +40 |
ऊपर की आखिरी पंक्ति असली झटका है। फीचर्स को साथ में इस्तेमाल करने पर उनकी individual costs का जोड़ भी नहीं लगता — उससे ज़्यादा लगता है। Premium proxy (+10) और JavaScript rendering (+10) को मिलाकर तर्क से +20 extra credits लगने चाहिए, लेकिन ScraperAPI लेता है। Ultra-premium (+30) और JavaScript rendering (+10) मिलकर +40 लगना चाहिए, लेकिन असल में लगता है — लगभग दोगुना। यह non-linear stacking साफ तौर पर prominently document नहीं किया गया है, और यही मुख्य वजह है कि यूज़र credits के उम्मीद से तेज़ी से खत्म होने की शिकायत करते हैं।
वे parameters जिन पर extra credits नहीं लगते: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true।
Free से लेकर Enterprise तक हर प्लान वास्तव में क्या देता है
यह रहे ScraperAPI के :
| Plan | Monthly Price | Annual (per mo) | API Credits | Concurrent Threads | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1,000 | 5 | No |
| Hobby | $49 | $44 | 100,000 | 20 | US & EU only |
| Startup | $149 | $134 | 1,000,000 | 50 | US & EU only |
| Business | $299 | $269 | 3,000,000 | 100 | Country-level (50+ countries) |
| Scaling | $475 | $427 | 5,000,000 | 200 | Country-level |
| Enterprise | Custom | Custom | 5,000,000+ | 200+ | Country-level |
अब multipliers को ध्यान में रखकर, हर tier पर 1,000 requests की effective cost देखिए:
| Plan | Standard (1×) | JS Rendering (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
$49/month का प्लान जिसे "100,000 credits" कहा जाता है, protected sites पर ultra-premium plus JavaScript rendering के साथ सिर्फ 1,333 actual requests देता है। इसका मतलब हुआ — जो कई fully managed scraping services से भी महँगा है।
Credits आपकी उम्मीद से तेज़ क्यों खत्म होते हैं
तीन बातें यूज़र्स को चौंकाती हैं।
पहली: domain-based pricing automatic है। आप Amazon के 5× multiplier या Google के 25× multiplier को opt-in नहीं करते। जैसे ही ScraperAPI domain detect करता है, यह लागू हो जाता है। यही बात anti-bot bypass credits (+10 for Cloudflare, DataDome, PerimeterX) पर भी लागू होती है — detect होते ही ये अपने-आप जुड़ जाते हैं।
दूसरी: credits अगले billing cycle में carry over नहीं होते। जो credits इस्तेमाल नहीं हुए, वे हो जाते हैं। कोई accumulation नहीं।
और तीसरी — यह खास तौर पर चुभती है — Pay-As-You-Go सिर्फ Scaling plan ($475/month) और उससे ऊपर उपलब्ध है। अगर आप Hobby, Startup, या Business पर हैं और बीच cycle में credits खत्म हो जाते हैं, तो अगली billing period तक आपकी सेवा बस रुक जाती है। अगले tier में upgrade करना ही एकमात्र रास्ता है।
Reddit पर एक यूज़र ने बताया कि 60 million credits के लिए, Amazon request पर 1 credit के हिसाब से उन्हें $3,600 quote किया गया था, लेकिन भुगतान के बाद बिना पहले बताए 5-credit multiplier लागू कर दिया गया। उनका 60M plan वास्तव में सिर्फ 12M requests के बराबर निकला — उनकी उम्मीद से ।
DataPipeline Credit Trap
ScraperAPI का no-code DataPipeline feature (scheduled scraping with webhook delivery) एक अलग और काफी ऊँची credit schedule इस्तेमाल करता है। एक basic normal request standard API के जरिए 1 credit की बजाय DataPipeline में :
| Request Type | Standard API | DataPipeline | Ratio |
|---|---|---|---|
| Basic normal request | 1 | 6 | 6× |
| E-commerce basic | 5 | 10 | 2× |
| SERP basic | 25 | 30 | 1.2× |
| Ultra-premium + JS (normal) | 75 | 80 | 1.07× |
जो लोग no-code pipelines बनाते समय standard credit costs मान लेते हैं, उन्हें पता चलता है कि basic requests पर 6× credits जल रहे हैं। यह document तो है, लेकिन आपको खुद खोजकर पढ़ना पड़ता है।
असली Cost Per Request: ScraperAPI बनाम प्रतियोगी
Multipliers को ध्यान में रखे बिना headline pricing का कोई अर्थ नहीं। मैंने पाँच providers की current pricing ली और लगभग $300/month tier पर तीन सामान्य scenarios की तुलना standardize की।
Basic HTML Scrape (No JS, No Premium Proxy)
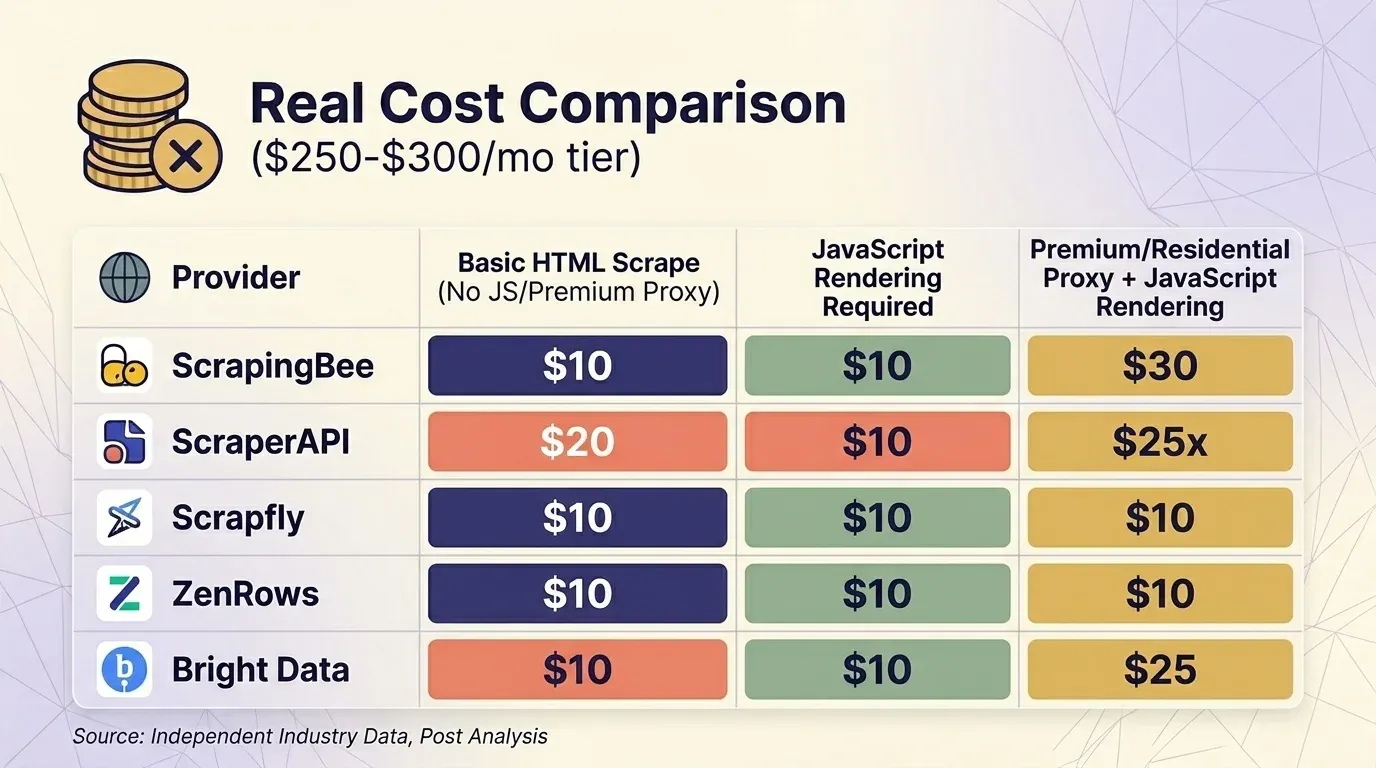
| Provider | Plan | Credits per Request | Actual Requests | Cost per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200,000 | $1.50 |
JavaScript Rendering Required
| Provider | Plan | Credits per Request | Actual Requests | Cost per 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (default on) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | PAYG | flat | ~200,000 | $1.50 |
Premium/Residential Proxy + JavaScript Rendering (Protected Sites)
| Provider | Plan | Credits per Request | Actual Requests | Cost per 1K |
|---|---|---|---|---|
| Bright Data | PAYG | flat | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
Bright Data का Web Unlocker — सभी requests की flat rate एक जैसी है। लगभग $300 tier पर, protected-site scraping के लिए ScrapingBee और ScraperAPI ठीक-ठाक प्रतिस्पर्धी हैं, जबकि ZenRows सबसे महँगा पड़ता है।
एक महत्वपूर्ण व्यवहारिक नोट: ScrapingBee और उसकी लागत 5× होती है। अगर आप ScrapingBee और ScraperAPI की सीधी तुलना कर रहे हैं, तो यह सुनिश्चित करें कि rendering settings एक जैसी हों।
Scrape.do के एक independent analysis के अनुसार ScraperAPI की औसत लागत निकलती है — "हर दूसरे tested provider से ज़्यादा" — और औसत response time बताया गया है, जिससे यह "available सबसे slow providers में से एक" बनता है। commit करने से पहले यह जानना उपयोगी है।
Site-Specific Success Rates: कहाँ ScraperAPI चमकता है और कहाँ संघर्ष करता है
कोई भी scraping API हर वेबसाइट पर समान रूप से अच्छा काम नहीं करता। Scrapeway (April 2026) के independent benchmarks एक बहुत साफ़ bimodal story बताते हैं।
साइट कैटेगरी के हिसाब से प्रदर्शन
| Target Site | Success Rate | Avg Speed | Cost per 1K (Business Plan) | |---|---|---|---|---| | Zillow | 100% | 10.5s | $0.49 | | Etsy | 99% | 4.8s | $4.90 | | Amazon | 98% | 6.5s | $2.45 | | LinkedIn | 95% | 17.8s | $14.70 | | Walmart | 93% | 11.4s | $2.45 | | Indeed | 90% | 15.8s | $4.90 | | StockX | 84% | 3.9s | $4.90 | | Realtor.com | 12% | 11.8s | $0.49 | | Instagram | 0% | — | — | | Booking.com | 0% | — | — | | Twitter/X | 0% | — | — |
कुल औसत success rate: , जो उद्योग औसत 58.2–59.5% से थोड़ा ऊपर है। औसत response time: 5.2–7.3 seconds, जो उद्योग औसत 9.8 seconds से बेहतर है।
ScraperAPI कहाँ अच्छा काम करता है
ScraperAPI वास्तव में e-commerce (Amazon, Walmart, Etsy) और real estate (Zillow) पर मज़बूत है। इन साइटों के structured data endpoints high reliability के साथ parsed JSON देते हैं। अगर आपका मुख्य use case Amazon product pages या Google SERPs को scrape करना है, तो ScraperAPI एक समझदार विकल्प है।
ScraperAPI कहाँ कमजोर पड़ता है
Social media dead zone है। Instagram, Twitter/X, और Booking.com — तीनों का independent testing में 0% success rate निकला। LinkedIn 95% पर काम करता है, लेकिन 30 credits per request की लागत काफी अधिक है।
Login-required sites explicitly off-limits हैं। ScraperAPI session_number parameter से session persistence support करता है, लेकिन यह । यह form filling, two-factor authentication, या complex auth flows संभाल नहीं सकता।
Protected targets पर stale data। ScraperAPI कठिन targets पर लागू करता है, यानी अगर आप time-sensitive data (pricing, stock levels) scrape कर रहे हैं, तो आपको 10 मिनट पुराना result भी मिल सकता है।
Proxyway के 2025 benchmark में, ScraperAPI का 81.72% था।
Site Category Performance Summary
| Site Category | ScraperAPI Performance | Known Issues | Potential Alternative |
|---|---|---|---|
| Amazon / e-commerce | ✅ Strong (SDP endpoints) | Credit-heavy at scale | Thunderbit templates (1-click, no credits per row for template) |
| Google SERPs | ✅ Strong | Geotargeting costs extra; lowest Google success rate in one benchmark | — |
| Real estate (Zillow) | ✅ Excellent (100%) | — | — |
| Instagram / social media | ❌ 0% success | Complete failure | Playwright + proxies (DIY) |
| JS-heavy SPAs | ⚠️ Moderate | Requires 10× credit headless rendering | Scrapfly, ZenRows |
| Sites requiring login | ❌ Forbidden by ToS | No session/auth support | Thunderbit browser scraping (uses your login session) |
| Booking.com / travel | ❌ 0% success | Complete failure | Bright Data |
असली यूज़र्स क्या कहते हैं: G2, Capterra, और Reddit sentiment summary
मैंने तीन platforms से feedback निकाला। ये हैं मौजूदा ratings:
| Platform | Rating | Reviews |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterra sub-ratings: Ease of Use 4.9/5, Customer Service 4.6/5, Features 4.5/5, Value for Money 4.5/5.
Theme के हिसाब से Sentiment Summary
| Theme | Positive Signals | Negative Signals | |---|---|---|---| | Ease of setup / docs | "Super easy to set up. You can start scraping in minutes." — Latenode community; Capterra Ease of Use 4.9/5 | — | | Pricing transparency | "Affordable entry tier" (multiple Capterra reviews) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (Feb 2025); "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (Sep 2022) | | Reliability | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) | | Customer support | "Responsive team" (Capterra) | User reported being quoted one price, then billed at 5× the rate with no upfront disclosure (Reddit) | | Value over time | Only charges for successful (200/404) requests | "If you're running large-scale operations, the expenses can add up quickly" and building custom infrastructure is "more cost-effective in the long run" — mikezhang, Latenode |
निष्कर्ष: ScraperAPI को initial setup की सरलता के लिए अच्छी रेटिंग मिलती है और लोकप्रिय, अच्छी तरह समर्थित targets पर यह भरोसेमंद भी है। शिकायतें ज़्यादातर pricing surprises (multipliers, unexpected increases) और मुश्किल targets पर reliability को लेकर हैं।
ScraperAPI के Structured Data Endpoints: क्या ये extra credits वाकई वाजिब हैं?
ScraperAPI 5 platforms पर देता है, जो raw HTML की बजाय parsed JSON लौटाते हैं:
- Amazon (3 endpoints): ASIN के आधार पर product details, search results, competitor offers। 18+ fields लौटाता है, जिनमें pricing, ratings, descriptions, reviews, BSR, images, seller info शामिल हैं। supported हैं।
- Google (5 endpoints): (organic results, knowledge graph, videos, related questions, pagination), Shopping, Maps, News, Jobs.
- Walmart (4 endpoints): Product, Search, Category, Reviews.
- eBay (2 endpoints): Product, Search.
- Redfin (4 endpoints): Search, Agent Details, Rental Properties, For Sale.
SDEs सभी plans पर उपलब्ध हैं, Free पर भी। ScraperAPI का दावा है कि समर्थित SDE domains पर मिलता है — हालांकि independent benchmarks site के हिसाब से थोड़ी अलग तस्वीर दिखाते हैं।
Data Completeness
Amazon SDP, ScraperAPI का सबसे मज़बूत offering है। यह fields का व्यापक set लौटाता है: price, reviews, BSR, variants, images, seller info, और बहुत कुछ। Google SERP SDP organic results, ads, featured snippets, और People Also Ask लौटाता है। इन दो platforms पर data completeness सचमुच अच्छी है।
Credit Efficiency: SDP बनाम DIY Parsing
Business plan ($299/month, 3M credits) पर 10,000 Amazon products को SDE से scrape करने पर 50,000 credits खर्च होंगे (हर request 5 credits) — यानी plan की कीमत का लगभग $5। अगर आप standard request (1 credit each) के साथ अपना parser खुद बनाते, तो सिर्फ 10,000 credits लगते, लेकिन parser बनाने और maintain करने में developer time लगती।
छोटी टीमों के लिए, जिनके पास developers नहीं हैं, SDEs असली समय बचाते हैं।
लेकिन engineering capacity वाली और scale पर scraping करने वाली टीमों के लिए 5× credit premium को justify करना मुश्किल है।
SDPs बनाम No-Code Scraper Templates
यह तुलना उतनी महत्वपूर्ण है जितनी ज़्यादातर reviews मानती नहीं। Amazon, Shopify, Zillow, और के लिए instant scraper templates देता है, जिनमें zero coding लगती है और template itself के लिए zero per-row credit cost होती है।
| Factor | ScraperAPI SDP (Amazon) | Thunderbit Amazon Template |
|---|---|---|
| Setup time | 30–60 min (code + API integration) | ~2 minutes (install extension, open Amazon, click template) |
| Cost per 1,000 products (Business plan) | ~$5 (50,000 credits at $0.10/credit) | ~$16.50 (1,000 rows × 1 credit at $0.0165/credit on Pro) |
| Fields returned | 18+ (comprehensive) | Product name, price, rating, reviews, images, URL, and more |
| Export options | JSON (requires code to parse) | Excel, CSV, Google Sheets, Airtable, Notion — 1 click |
| Maintenance | ScraperAPI maintains the SDP | Thunderbit team maintains templates |
| Technical skill | Python/Node.js required | None |
High-volume Amazon scraping करने वाली developer teams के लिए, ScraperAPI का SDP scale पर प्रति product ज़्यादा cost-efficient हो सकता है। लेकिन जिन business users को बिना code लिखे Amazon data spreadsheet में चाहिए, उनके लिए Thunderbit setup और usage में बहुत तेज़ है।
क्या आपको scraping API की वाकई जरूरत भी है? वह no-code रास्ता जिसे ज़्यादातर reviews अनदेखा करती हैं
"Scraper API review" खोजने वाले कई लोग अभी API-based workflow तय ही नहीं कर पाए होते। वे पहले यह समझना चाहते हैं कि क्या उन्हें इसकी जरूरत है भी या नहीं।
हैरानी की बात है कि बहुत से लोगों को नहीं होती। web scraping API market एक है जो 14–18% CAGR से बढ़ रही है, लेकिन यह growth मुख्यतः enterprise engineering teams से आती है — न कि उस sales ops manager से जिसे एक website से 500 leads चाहिए।
Scraping API बनाम No-Code Tool: एक side-by-side decision framework
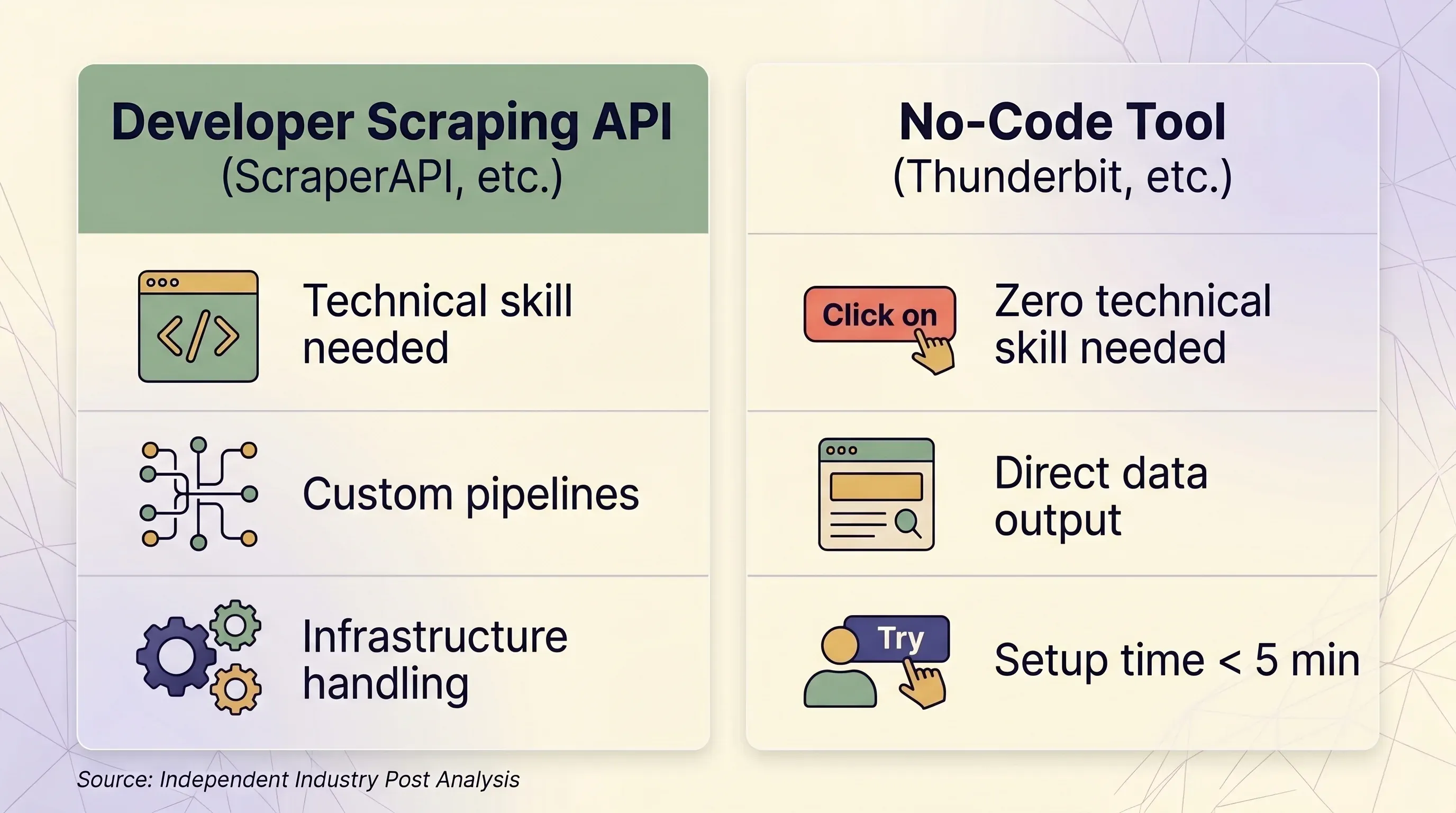
| Factor | Scraping API (ScraperAPI, etc.) | No-Code Tool (Thunderbit, etc.) | |---|---|---|---| | Best for | Developers building data pipelines at scale | Business users, marketers, sales teams, researchers | | Technical skill needed | Python/Node.js, HTTP concepts, JSON parsing | None — point-and-click in browser | | Setup time | 1–2 hours minimum (code + test + debug) | Under 5 minutes | | Anti-bot handling | Premium proxies (10–75 credits/request) | Real browser session — naturally bypasses fingerprinting | | Login-required sites | ❌ Forbidden by ScraperAPI ToS | ✅ Browser Scraping uses your existing session | | Scale (pages/day) | 100K–3M+ requests/month | Ad-hoc, typically under 1,000 pages/day | | Data output | Raw HTML or JSON (requires parsing code) | Structured rows/columns — ready to use | | Export | JSON, CSV (via code) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Maintenance | Must update selectors, retry logic, infrastructure | None — AI re-reads page structure each time | | Pricing unit | Per-request credits (variable: 1–75 credits/request) | Per-row credits (1 credit = 1 row, 2 for subpages) | | Entry price | $49/month for 100K credits | $9/month for 5,000 credits (yearly) | | Free tier | 1,000 credits/month, 5 concurrent | 6 pages/month, 30 credits/page | | Pricing predictability | Low — multipliers create surprise costs | High — 1 row always = 1 credit |
Scraping API कब समझदारी है
- आपके पास developer या engineering team हो
- आपको programmatically 100K+ pages/day scrape करने हों
- आपको request headers, sessions, और retry logic पर गहरी customization चाहिए
- आपके targets अच्छी तरह supported हों (Amazon, Google, Walmart, Zillow)
Thunderbit जैसे No-Code Tool कब बेहतर हैं
- आप sales, e-commerce ops, marketing, या real estate में हैं — engineering में नहीं
- आपको दर्जनों अलग-अलग sites से data चाहिए, हर एक के लिए custom parser बनाए बिना
- आपको सीधे Excel, Google Sheets, Airtable, या Notion में export चाहिए
- आपको login-required sites scrape करनी हैं (Thunderbit का आपका session इस्तेमाल करता है)
- आप चाहते हैं कि AI हर बार page को fresh पढ़े — sites के layout बदलने पर code maintenance न करनी पड़े
- आपको subpage scraping चाहिए: Thunderbit हर detail page पर जाकर rows को अपने-आप enrich कर सकता है
का workflow सचमुच आसान है: extension install करें, किसी भी page पर जाएँ, "AI Suggest Fields" पर क्लिक करें, फिर "Scrape" करें, और export कर दें। AI page पर मौजूद data समझकर columns suggest करता है — selectors या code लिखने की जरूरत नहीं। यह कैसे काम करता है, इस पर अधिक जानकारी के लिए हमारी देखें।
ने 2024 में cloud cost overruns का सामना किया, और usage-based pricing इस्तेमाल करने वाली companies अगर safeguards न रखें तो bill shock के कारण देखती हैं। अगर आप variable API costs से पहले ही झुलस चुके हैं, तो per-row credit model की predictability पर गंभीरता से विचार करना चाहिए।
एक नज़र में ScraperAPI के Pros और Cons
| Pros | Cons |
|---|---|
| Strong proxy infrastructure (40M+ IPs, 50+ countries) | Confusing credit multiplier system — combining features costs more than the sum |
| Excellent documentation and easy initial setup (Capterra Ease of Use: 4.9/5) | Credits do NOT roll over month to month |
| Reliable on Amazon, Google, Zillow, Etsy | 0% success on Instagram, Twitter/X, Booking.com |
| Only charges for successful requests (200/404) | 404 responses do consume credits |
| 18 structured data endpoints with parsed JSON output | Login-required sites explicitly forbidden |
| Available on all plans including Free | Pay-As-You-Go only on Scaling ($475/mo) and above |
| 7-day no-questions-asked refund policy | 10-minute forced cache on difficult targets — stale data risk |
| 30–35% YoY revenue growth suggests active development | DataPipeline costs up to 6× standard API credits |
| — | Geotargeting beyond US & EU requires Business plan ($299/mo) |
| — | No proactive usage alerts — must manually check dashboard |
अगर आप ScraperAPI इस्तेमाल करने का सोच रहे हैं, तो कुछ practical tips
अपने credit consumption को रोज़ monitor करें
ScraperAPI का usage statistics देता है, जिनमें average latency, scraped domains, और concurrency metrics शामिल हैं। लेकिन कोई proactive usage alert नहीं है — credits कम होने पर email या SMS नहीं आता। आपको खुद manually check करना होगा। Analytics history Hobby/Startup plans पर 2 हफ्ते और Business+ पर 6 महीने तक सीमित है।
पहले महीने में हर दिन dashboard देखने के लिए calendar reminder लगाइए। आपको अपने specific targets पर credits कितनी तेज़ी से खर्च होते हैं, इसकी आदत डालनी होगी।
Free tier से अपने target sites test करें
Paid plan लेने से पहले 1,000 free credits (और 5,000 credits वाले 7-day trial) का उपयोग करके अपने target sites पर success rate test करें। नोट करें कि किन sites को JavaScript rendering या premium proxies चाहिए, ताकि multipliers लगाकर realistic monthly cost का अंदाज़ा लगाया जा सके।
Premium features तभी चालू करें जब target सच में मांगता हो
ScraperAPI premium proxies या JavaScript rendering अपने-आप enable नहीं करता — आपको render=true, premium=true, या ultra_premium=true explicitly set करना होता है। लेकिन domain-based pricing automatic है: Amazon हमेशा 5 credits, Google हमेशा 25, LinkedIn हमेशा 30 लेता है। Anti-bot bypass credits (+10 for Cloudflare, DataDome, PerimeterX) भी detect होते ही अपने-आप जुड़ जाते हैं। batch चलाने से पहले यह समझ लें।
Supported sites पर structured data endpoints इस्तेमाल करें
अगर आप Amazon या Google scrape कर रहे हैं, तो SDEs development time बचाते हैं, भले ही वे अधिक credits लें। Unsupported sites के लिए यह आकलन करें कि custom parser बनाने से तेज़ और सस्ता होगा या नहीं।
Unreliable targets के लिए backup plan रखें
अगर किसी specific site पर ScraperAPI की success rate 90% से कम है, तो requests को किसी दूसरे provider से route करने या browser-based tool इस्तेमाल करने पर विचार करें। Login-required sites के लिए ScraperAPI काम नहीं करेगा — आपको जैसे tool की जरूरत होगी जो आपके browser session के भीतर काम करता है।
जानने योग्य gotchas
- 404 responses पर credits लगते हैं — ScraperAPI 200 और 404, दोनों status codes के लिए charge करता है
- Cancelled requests भी charge होती हैं अगर आप 70-second processing window पूरी होने से पहले cancel करते हैं
- Difficult targets पर 10-minute forced caching — stale data मिल सकता है
- Pay-As-You-Go सिर्फ Scaling ($475/month) और ऊपर है — lower-tier users के credits खत्म होने पर service रुक जाती है
- US & EU से बाहर geotargeting के लिए Business plan ($299/month) चाहिए
मुख्य निष्कर्ष: क्या ScraperAPI आपके लिए सही टूल है?
सारी रिसर्च के बाद मैं यहाँ पहुँचा हूँ:
- Developer teams के लिए ScraperAPI एक ठोस विकल्प है अगर वे Amazon, Google, Walmart, और Zillow जैसे high-volume, well-supported targets scrape कर रहे हैं। Structured data endpoints सचमुच उपयोगी हैं, proxy infrastructure बड़ा है, और documentation औसत से बेहतर है।
- Credit multiplier system सबसे बड़ा जोखिम है। अगर आपको multipliers का stacking समझ नहीं आया, तो आप ज़रूरत से ज़्यादा खर्च करेंगे। Advertised credits और actual requests के बीच का अंतर 5–75× तक हो सकता है। Paid plan लेने से पहले अपने use case का गणित ज़रूर निकालें।
- Reliability site पर निर्भर करती है। ScraperAPI e-commerce और real estate पर शानदार है, job boards और social media पर औसत, और Instagram, Twitter/X, तथा Booking.com पर पूरी तरह बेकार। हर साइट पर एक जैसा प्रदर्शन मानकर न चलें।
- Non-technical teams के लिए ScraperAPI गलत टूल है। अगर आप sales, marketing, या ops में हैं और code लिखे बिना structured data चाहिए, तो जैसा no-code tool दो क्लिक में काम कर देता है — AI-powered field detection, direct spreadsheet export, subpage enrichment, और कोई maintenance overhead नहीं। देखें या पर tutorials देखें।
- Budget पर काम कर रहे developers के लिए, ScraperAPI का free tier अपने specific targets पर test करें, फिर चुनने से पहले effective per-request costs की तुलना ScrapingBee, Scrapfly, और Bright Data से करें। सबसे सस्ता विकल्प पूरी तरह आपके use case और feature needs पर निर्भर करता है।
क्या आप देखना चाहते हैं कि आपके scraping needs के लिए numbers कैसे बैठते हैं? ScraperAPI के free tier से अपने target sites test करना शुरू करें, या और देखें कि दो clicks आपको कहाँ तक ले जा सकते हैं। के बारे में और जानने के लिए हमारे plans देखें।
FAQs
क्या ScraperAPI free है?
हाँ, ScraperAPI एक free tier देता है जिसमें और 5,000 credits वाला 7-day trial शामिल है। लेकिन JavaScript rendering, premium proxies, या high-cost domains (Amazon = 5×, Google = 25×, LinkedIn = 30×) के लिए credit multipliers होने की वजह से आपकी वास्तविक क्षमता 1,000 requests से काफी कम हो सकती है। Free tier पर ultra-premium proxies उपलब्ध नहीं हैं।
ScraperAPI प्रति request कितनी लागत लेता है?
यह feature flags और target domain पर बहुत निर्भर करता है। किसी साधारण HTML site पर standard request 1 credit की होती है। Amazon request 5 credits लेती है। Google SERP request 25 credits लेती है। JavaScript rendering जोड़ने पर 10 credits और जुड़ते हैं। Ultra-premium proxy को JavaScript rendering के साथ मिलाने पर प्रति request 75 credits लगते हैं। Hobby plan ($49/month, 100K credits) पर यह standard के लिए $0.00049 per request से लेकर ultra-premium + JS के लिए $0.0368 per request तक हो सकता है। पूरी जानकारी ऊपर दिए cost tables में देखें।
क्या ScraperAPI Amazon scraping के लिए अच्छा है?
ScraperAPI का Amazon Structured Data endpoint इसकी सबसे मजबूत विशेषताओं में से एक है, और independent benchmarks में इसका तथा 18+ fields वाला comprehensive parsed JSON output मिलता है। हालांकि, हर Amazon request कम से कम 5 credits लेती है, इसलिए scale पर लागत बढ़ जाती है। छोटी टीमों के लिए जो code लिखे बिना spreadsheet में Amazon data चाहती हैं, direct export के साथ 1-click विकल्प देता है।
सबसे अच्छे ScraperAPI alternatives कौन से हैं?
Developers के लिए: (basic HTML के लिए सबसे सस्ता), (अच्छा JavaScript rendering), (protected sites के लिए सबसे अच्छा — rendering हो या न हो flat rate), और । Non-technical users के लिए: — एक no-code, AI-powered Chrome extension जो सीधे Excel, Google Sheets, Airtable, और Notion में export करता है। गहराई से देखने के लिए हमारी देखें।
क्या ScraperAPI login-required sites scrape कर सकता है?
ScraperAPI session_number parameter के जरिए session persistence सपोर्ट करता है (multiple requests में same IP), लेकिन यह । यह form filling, two-factor authentication, या complex auth flows नहीं संभाल सकता। Login-required sites के लिए जैसे browser-based tools — जो आपके मौजूदा browser session का उपयोग करके आप जो देख सकते हैं उसे scrape करते हैं — अधिक भरोसेमंद विकल्प हैं।
और जानें