

अगर आपने कभी लक्षित बिक्री सूची बनाने, नए बाज़ार खोजने, या प्रतिस्पर्धियों की तुलना करने की कोशिश की है, तो आप जानते होंगे कि Google Maps कितना बड़ा खज़ाना है। लेकिन असली बात यह है: हर महीने 1.5 अरब से अधिक “near me” सर्च और 76% स्थानीय खोजकर्ताओं का 24 घंटे के भीतर किसी व्यवसाय पर जाना (thinkwithgoogle.com) — ऐसे में ताज़ा, लोकेशन-आधारित बिज़नेस डेटा की मांग पहले से कहीं ज़्यादा है।
चाहे आप सेल्स में हों, मार्केटिंग में हों, या ऑपरेशंस में, Google Maps से संरचित डेटा निकालना एक ठंडी कॉल और एक गर्म, उच्च-रूपांतरण वाले लीड के बीच का फर्क तय कर सकता है।
मैंने सालों तक SaaS और ऑटोमेशन में काम किया है, और मैंने अपनी आँखों से देखा है कि टीमें Python (और अब Thunderbit जैसे AI-संचालित टूल) का इस्तेमाल करके Google Maps को कैसे एक रणनीतिक संपत्ति में बदल रही हैं।
इस गाइड में, मैं 2026 में Python के साथ Google Maps डेटा स्क्रैप करने का बिल्कुल सही तरीका बताऊँगा—स्टेप बाय स्टेप, कोड, अनुपालन सुझावों, और नो-कोड समाधानों से तुलना के साथ। चाहे आप Python के प्रो हों या बस कार्रवाई योग्य डेटा तक सबसे तेज़ रास्ता चाहते हों, आप सही जगह पर हैं।
Python से Google Maps स्क्रैप करने का मतलब क्या है?
बुनियादी बात से शुरू करें: Python से Google Maps स्क्रैप करना मतलब है प्रोग्राम के जरिए व्यवसाय संबंधी जानकारी—जैसे नाम, पता, रेटिंग, समीक्षाएँ, फ़ोन नंबर, और निर्देशांक—Google Maps से निकालना, ताकि आप उसे विश्लेषित, फ़िल्टर, और बिज़नेस उपयोग के लिए एक्सपोर्ट कर सकें।

इसे करने के दो मुख्य तरीके हैं:
- Google Maps Places API: आधिकारिक, लाइसेंस प्राप्त तरीका। आप एक API key का उपयोग करके Google के सर्वर को क्वेरी करते हैं और बदले में संरचित JSON डेटा पाते हैं। यह स्थिर, अनुमानित, और (अधिकांशतः) अनुपालन योग्य है, लेकिन इसमें quotas और लागत आती है।
- HTML का वेब स्क्रैपिंग: आप एक ब्राउज़र (Playwright या Selenium जैसे टूल्स के साथ) को ऑटोमेट करते हैं ताकि Google Maps लोड हो, सर्च की जाए, और रेंडर किए गए पेज को पार्स किया जाए। यह ज़्यादा लचीला है, लेकिन नाज़ुक भी—Google अपनी साइट संरचना अक्सर बदलता रहता है, और HTML स्क्रैपिंग Google की शर्तों का उल्लंघन कर सकती है।
आम तौर पर निकाले जा सकने वाले डेटा फ़ील्ड:
- व्यवसाय का नाम
- श्रेणी/प्रकार
- पूरा पता (साथ में शहर, राज्य, पोस्टल कोड, देश)
- अक्षांश और देशांतर
- फ़ोन नंबर
- वेबसाइट URL
- रेटिंग और समीक्षाओं की संख्या
- मूल्य स्तर
- व्यवसाय की स्थिति (खुला/बंद)
- खुलने का समय
- Place ID (Google का विशिष्ट पहचानकर्ता)
- Google Maps URL
यह क्यों महत्वपूर्ण है? क्योंकि यही फ़ील्ड लीड जनरेशन, क्षेत्रीय योजना, प्रतिस्पर्धी बेंचमार्किंग, और मार्केट रिसर्च—सब कुछ चलाते हैं। असली कुंजी है अपने बिज़नेस लक्ष्यों के लिए सही डेटा को लक्षित करना—बस आँख मूँदकर स्क्रैप मत कीजिए।
सेल्स और मार्केटिंग टीमें Python से Google Maps डेटा क्यों निकालती हैं
आइए इसे व्यावहारिक बनाते हैं। 2026 में इतनी सारी सेल्स और मार्केटिंग टीमें Google Maps डेटा पर क्यों फ़िदा हैं?
- लीड जनरेशन: स्थानीय व्यवसायों की बेहद लक्षित सूचियाँ बनाइए, जिनमें संपर्क जानकारी और रेटिंग शामिल हों, आउटरीच कैंपेन के लिए।
- क्षेत्रीय योजना: वास्तविक व्यवसाय घनत्व और प्रकारों के आधार पर सेल्स टेरिटरी, डिलीवरी ज़ोन, या सर्विस एरिया मैप कीजिए।
- प्रतिस्पर्धी निगरानी: प्रतिस्पर्धियों के स्थान, रेटिंग, और समीक्षाओं को समय के साथ ट्रैक कीजिए ताकि रुझान और अवसर पकड़ सकें।
- बाज़ार अनुसंधान: व्यवसाय श्रेणियों, खुलने के घंटे, और समीक्षा भावना का विश्लेषण करके go-to-market रणनीति को दिशा दीजिए।
- साइट चयन: रियल एस्टेट और रिटेल के लिए, आसपास की सुविधाओं, पैदल यातायात, और प्रतिस्पर्धा के आधार पर संभावित स्थानों का मूल्यांकन कीजिए।
वास्तविक प्रभाव: HubSpot 2025 State of Sales के अनुसार, 92% सेल्स संगठन AI/data निवेश बढ़ाने की योजना बना रहे हैं, और लक्षित, स्थानीय डेटा का उपयोग करने वाली टीमों की conversion दरें सामान्य cold lists पर निर्भर टीमों से 8× तक अधिक होती हैं (martal.ca). एक franchise lead-gen अध्ययन में पाया गया कि Google Maps-आधारित lead lists पर खर्च किए गए हर $1 पर $15 नई आय मिली।
व्यावसायिक लक्ष्यों को Google Maps फ़ील्ड्स से जोड़ना:
| व्यावसायिक लक्ष्य | ज़रूरी Google Maps फ़ील्ड्स |
|---|---|
| स्थानीय लीड सूची | name, address, phone, website, category |
| क्षेत्रीय योजना | name, lat/lng, business_status, opening_hours |
| प्रतिस्पर्धी बेंचमार्किंग | name, rating, userRatingCount, priceLevel, reviews |
| साइट चयन | category, lat/lng, review density, openingDate |
| भावना/मेनू इंटेलिजेंस | reviews, editorialSummary, photos, types |
| ईमेल/फ़ोन आउटरीच | nationalPhoneNumber, websiteUri (फिर ज़रूरत अनुसार समृद्ध करें) |
आपका Python Google Maps स्क्रैपर सेट अप करना: टूल्स और ज़रूरतें
स्क्रैपिंग शुरू करने से पहले, आपको अपना Python वातावरण सेट अप करना होगा और सही टूल्स इकट्ठा करने होंगे। 2026 में आपको ये चाहिए:
1. Python और ज़रूरी लाइब्रेरीज़ इंस्टॉल करें
सुझाई गई Python version: 3.10 या उससे ऊपर।
मुख्य लाइब्रेरीज़ इंस्टॉल करें:
pip install \
requests==2.33.1 httpx==0.28.1 \
beautifulsoup4==4.14.3 lxml==6.0.3 \
pandas==2.3.3 \
selenium==4.43.0 playwright==1.58.0 \
googlemaps==4.10.0 google-maps-places==0.8.0 \
schedule==1.2.2 APScheduler==3.11.2 \
python-dotenv==1.2.2 tenacity==9.1.4
playwright install chromium
ये क्या करते हैं:
requests,httpx: HTTP अनुरोध (API कॉल्स)beautifulsoup4,lxml: HTML पार्सिंग (वेब स्क्रैपिंग के लिए)pandas: डेटा सफ़ाई, विश्लेषण, एक्सपोर्टselenium,playwright: ब्राउज़र ऑटोमेशन (HTML स्क्रैपिंग के लिए)googlemaps,google-maps-places: Google Maps API क्लाइंट्सschedule,APScheduler: कार्य शेड्यूलिंगpython-dotenv:.envफ़ाइलों से API keys सुरक्षित रूप से लोड करनाtenacity: त्रुटि प्रबंधन के लिए retry logic
2. Google Maps API Key लें (API-आधारित स्क्रैपिंग के लिए)
- Google Cloud Console पर जाएँ।
- एक project बनाएँ या चुनें।
- billing सक्षम करें (free-tier उपयोग के लिए भी आवश्यक)।
- APIs & Services > Library में “Places API (New)” सक्षम करें।
- Credentials > Create Credentials > API Key पर जाएँ।
- सुरक्षा के लिए अपनी key को विशिष्ट APIs और IPs तक सीमित करें।
- अपनी API key को
.envफ़ाइल में रखें (इसे कभी code में commit न करें):
GOOGLE_MAPS_API_KEY=your_actual_api_key_here
नोट: मार्च 2025 तक, Google अब सार्वभौमिक $200/माह मुफ्त क्रेडिट नहीं देता। इसके बजाय, हर API tier के लिए आपको मुफ्त मासिक thresholds मिलते हैं (official pricing).
Python का उपयोग करके Google Maps से डेटा कैसे निकालें: स्टेप-बाय-स्टेप गाइड
आइए दोनों मुख्य तरीकों—API-आधारित और HTML स्क्रैपिंग—को तोड़कर समझें, ताकि आप अपनी ज़रूरत के हिसाब से चुन सकें।
तरीका 1: Google Maps Places API का उपयोग करना (सुझाया गया)
चरण 1: ज़रूरी लाइब्रेरीज़ इंस्टॉल और इंपोर्ट करें
import os
import httpx
import pandas as pd
from dotenv import load_dotenv
चरण 2: अपनी API Key सुरक्षित रूप से लोड करें
load_dotenv()
API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]
चरण 3: अपनी सर्च क्वेरी बनाएँ
आप अपनी शर्तों से मेल खाते व्यवसायों को खोजने के लिए Text Search endpoint का उपयोग करेंगे।
URL = "https://places.googleapis.com/v1/places:searchText"
FIELD_MASK = ",".join([
"places.id", "places.displayName", "places.formattedAddress",
"places.location", "places.rating", "places.userRatingCount",
"places.priceLevel", "places.types",
"places.nationalPhoneNumber", "places.websiteUri",
"nextPageToken",
])
चरण 4: API अनुरोध भेजें
def text_search(query, lat, lng, radius=3000, min_rating=4.0):
body = {
"textQuery": query,
"minRating": min_rating, # server-side filter
"includedType": "restaurant",
"openNow": False,
"pageSize": 20,
"locationBias": {
"circle": {
"center": {"latitude": lat, "longitude": lng},
"radius": radius,
}
},
}
headers = {
"Content-Type": "application/json",
"X-Goog-Api-Key": API_KEY,
"X-Goog-FieldMask": FIELD_MASK, # हमेशा सेट करें!
}
r = httpx.post(URL, json=body, headers=headers, timeout=30)
r.raise_for_status()
return r.json()
चरण 5: Pagination संभालें और परिणाम इकट्ठा करें
def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
results = []
next_page_token = None
while True:
data = text_search(query, lat, lng, radius, min_rating)
places = data.get('places', [])
results.extend(places)
next_page_token = data.get('nextPageToken')
if not next_page_token:
break
return results
चरण 6: Pandas के साथ डेटा एक्सपोर्ट करें
df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
df.to_csv("brooklyn_coffee_shops.csv", index=False)
प्रो टिप्स:
- लागत नियंत्रित करने के लिए हमेशा
X-Goog-FieldMaskheader सेट करें। अगर आप reviews या photos माँगते हैं, तो आपकी कीमत प्रति 1,000 अनुरोध $5 से $25 तक जा सकती है (pricing details). - बेकार परिणामों पर credits बर्बाद करने से बचने के लिए server-side filters (
minRating,includedType,locationBias) का उपयोग करें। - डुप्लिकेट हटाने और भविष्य के अपडेट के लिए
place_idvalues cache करें।
तरीका 2: Google Maps HTML को वेब स्क्रैप करना (शिक्षण/एक बार के उपयोग के लिए)
चेतावनी: Google Maps एक single-page app है। आपको browser automation (Playwright या Selenium) का उपयोग करना होगा, और HTML स्क्रैपिंग Google की शर्तों का उल्लंघन कर सकती है। इसका उपयोग शोध के लिए करें, production के लिए नहीं।
चरण 1: Playwright इंस्टॉल करें और ब्राउज़र लॉन्च करें
from playwright.sync_api import sync_playwright
import time, re
def scrape_maps(query, max_results=100):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
ctx = browser.new_context(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
locale="en-US",
)
page = ctx.new_page()
page.goto("https://www.google.com/maps", timeout=60_000)
page.fill("#searchboxinput", query)
page.click('button[aria-label="Search"]')
page.wait_for_selector('div[role="feed"]')
feed = page.locator('div[role="feed"]')
prev = 0
while True:
feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
time.sleep(2)
count = page.locator('div[role="feed"] > div > div[jsaction]').count()
if count == prev or count >= max_results:
break
prev = count
if page.locator("text=You've reached the end of the list").count():
break
rows = []
cards = page.locator('div[role="feed"] > div > div[jsaction]')
for i in range(cards.count()):
c = cards.nth(i)
name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
rating_el = c.locator('span[role="img"]').first
raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
rating = float(m.group(1)) if m else None
reviews = int(m.group(2).replace(",", "")) if m else None
rows.append({"name": name, "rating": rating, "reviews": reviews})
browser.close()
return rows
सुझाव:
- Google कुछ हफ़्तों में CSS classes को यादृच्छिक कर देता है, इसलिए इस कोड को नियमित अपडेट की ज़रूरत पड़ सकती है।
- ब्लॉक होने के जोखिम को कम करने के लिए मानवीय-से विलंब रखें और बहुत तेज़ी से स्क्रैप न करें।
- कभी भी CAPTCHAs या Google के SearchGuard सिस्टम को बायपास करने की कोशिश न करें—इससे कानूनी जोखिम हो सकता है।
आँख मूँदकर स्क्रैप करने से बचें: अपनी ज़रूरत के डेटा को सटीकता से कैसे लक्षित करें
सब कुछ स्क्रैप करना समय की बर्बादी और फूले हुए datasets का नुस्खा है। यहाँ बताया गया है कि केवल वही डेटा कैसे लक्षित करें जो मायने रखता है:
- लक्षित URL सूचियाँ बनाएँ: स्क्रैपिंग से पहले परिणामों को सीमित करने के लिए Google Maps के अपने search filters (category, location, rating, open now) का उपयोग करें।
- phrase matching का उपयोग करें: व्यवसाय के सटीक प्रकार या keywords खोजें (जैसे, “vegan bakery in Austin”).
- लोकेशन फ़िल्टर: सटीकता के लिए शहर, मोहल्ला, या यहाँ तक कि coordinates और radius भी निर्दिष्ट करें।
- server-side filtering (API): अपने API request body में
minRating,includedType, औरlocationBiasका उपयोग करें। - client-side filtering (Python): स्क्रैपिंग के बाद, pandas से 4.0 से ऊपर rating, 50 से अधिक reviews, या विशिष्ट categories वाले व्यवसाय फ़िल्टर करें।
उदाहरण: Manhattan में केवल 4.0 से ऊपर रेटिंग वाले restaurants फ़िल्टर करना
df = pd.DataFrame(results)
filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
filtered.to_csv("manhattan_top_restaurants.csv", index=False)
Google Maps डेटा को व्यवस्थित और एक्सपोर्ट करने के लिए Python लाइब्रेरीज़ का उपयोग
एक बार डेटा स्क्रैप हो जाए, तो उसे साफ़ करने, विश्लेषित करने, और अपनी टीम के लिए एक्सपोर्ट करने का समय आ गया है।
Pandas से डेटा साफ़ और संरचित करना
import pandas as pd
df = pd.read_json("brooklyn_restaurants.json")
df = (
df.dropna(subset=["name", "address"])
.drop_duplicates(subset=["place_id"])
.assign(
name=lambda d: d["name"].str.strip(),
phone=lambda d: d["phone"].astype(str)
.str.replace(r"\D", "", regex=True)
.str.replace(r"^1?(\d{10})$", r"+1\1", regex=True),
rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
user_ratings_total=lambda d: pd.to_numeric(
d["user_ratings_total"], errors="coerce"
).fillna(0).astype("int32"),
)
)
डेटा का विश्लेषण और सारांश बनाना
उदाहरण: पड़ोस के अनुसार औसत रेटिंग
by_neighborhood = (
df.groupby("neighborhood", as_index=False)
.agg(avg_rating=("rating", "mean"),
n_places=("place_id", "nunique"),
median_reviews=("user_ratings_total", "median"))
.sort_values("avg_rating", ascending=False)
)
Excel या CSV में एक्सपोर्ट करना
df.to_csv("brooklyn_top.csv", index=False)
df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")
बड़े datasets? गति और आकार की दक्षता के लिए Parquet format का उपयोग करें:
df.to_parquet("brooklyn_top.parquet", compression="zstd")
Thunderbit: Python Google Maps स्क्रैपर का AI-संचालित विकल्प
अब, अगर आप सोच रहे हैं, “एक साधारण lead list के लिए यह बहुत सारी सेटअप है,” तो आप अकेले नहीं हैं। इसी वजह से हमने Thunderbit बनाया—एक AI-संचालित, नो-कोड वेब स्क्रैपर, जो Google Maps डेटा (और बहुत कुछ) निकालना बस कुछ क्लिक जितना आसान बना देता है।
Thunderbit क्यों?
- कोडिंग या API key की ज़रूरत नहीं: बस Thunderbit Chrome Extension खोलें, Google Maps पर जाएँ, और “AI Suggest Fields” पर क्लिक करें।
- AI field detection: Thunderbit का AI पेज पढ़ता है और सही columns सुझाता है—नाम, पता, रेटिंग, फ़ोन, वेबसाइट, और भी बहुत कुछ।
- Subpage scraping: क्या आप हर व्यवसाय की वेबसाइट से डेटा जोड़कर अपनी table को समृद्ध करना चाहते हैं? Thunderbit हर subpage पर जाकर अतिरिक्त जानकारी अपने आप खींच सकता है।
- Excel, Google Sheets, Airtable, या Notion में export: pandas की जद्दोजहद ख़त्म—बस “Export” क्लिक करें और आपका डेटा टीम के लिए तैयार है।
- Scheduled scraping: प्रतिस्पर्धियों की निगरानी या लीड सूची को अपने आप ताज़ा करने के लिए recurring jobs सेट करें।
- Zero maintenance: Thunderbit का AI साइट बदलावों के साथ ढल जाता है, इसलिए आपको बार-बार टूटे हुए scripts ठीक नहीं करने पड़ते।
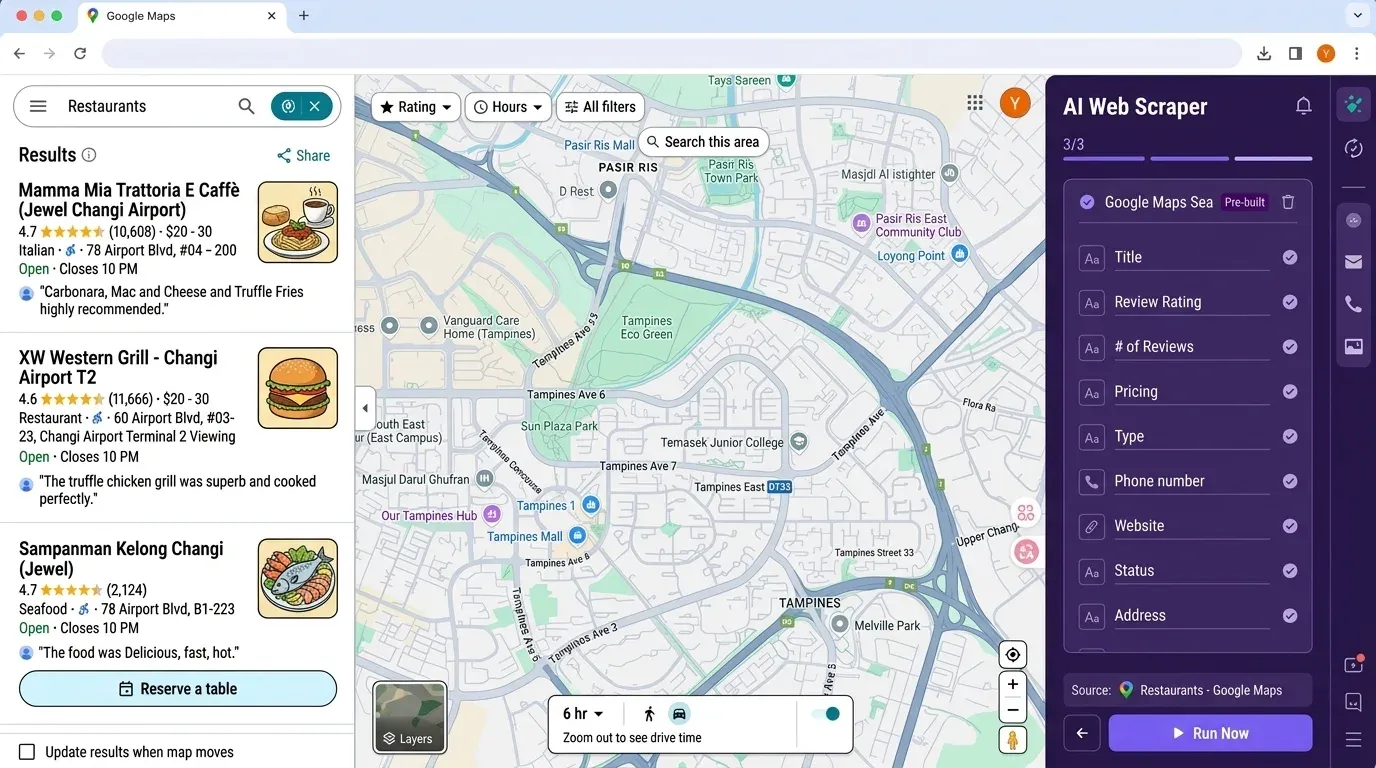
Thunderbit बनाम Python workflow:
| चरण | Python स्क्रैपर | Thunderbit |
|---|---|---|
| टूल्स इंस्टॉल | 30–60 मिनट (Python, pip, लाइब्रेरीज़) | 2 मिनट (Chrome Extension) |
| API key सेटअप | 10–30 मिनट (Cloud Console) | ज़रूरत नहीं |
| फ़ील्ड चयन | मैनुअल कोड, field masks | AI Suggest Fields (1 क्लिक) |
| डेटा निष्कर्षण | scripts लिखें/चलाएँ, त्रुटियाँ संभालें | “Scrape” क्लिक करें |
| एक्सपोर्ट | pandas से CSV/Excel | Excel/Sheets/Notion में export |
| रखरखाव | साइट बदलने पर मैनुअल अपडेट | AI अपने आप अनुकूलित होता है |
बोनस: Thunderbit पर दुनिया भर के 30,000+ उपयोगकर्ता भरोसा करते हैं, और free tier आपको बिना किसी लागत के 6 पेज तक (या trial boost के साथ 10 तक) स्क्रैप करने देता है।
अनुपालन बनाए रखें: Google Maps की सेवा शर्तें और स्क्रैपिंग नैतिकता
यहीं पर ज़्यादातर Python tutorials खतरनाक रूप से पुराने हो जाते हैं। 2026 में आपको यह जानना चाहिए:
- Google Maps Platform ToS §3.2.3 आधिकारिक APIs के बाहर डेटा को स्क्रैप करने, cache करने, या export करने पर सख्त रोक लगाता है (cloud.google.com). एकमात्र अपवाद: अक्षांश/देशांतर मान 30 दिनों तक cache किए जा सकते हैं; Place IDs अनिश्चितकाल तक संग्रहीत किए जा सकते हैं।
- API उपयोगकर्ता अनुबंध से बंधे होते हैं: अगर आप API key इस्तेमाल करते हैं, तो आप Google की शर्तों से सहमत हो चुके हैं—भले ही आप केवल सार्वजनिक डेटा ही क्यों न स्क्रैप कर रहे हों।
- तकनीकी बाधाओं (CAPTCHAs, SearchGuard) को बायपास करना अब संभावित DMCA §1201 उल्लंघन हो सकता है, जिससे आपराधिक दंड तक लग सकते हैं (ppc.land).
- GDPR और गोपनीयता कानून: अगर आप Google Maps से personal data (emails, phones, reviewer names) इकट्ठा करते हैं, तो आपके पास वैध आधार होना चाहिए और deletion requests का सम्मान करना होगा। फ्रेंच CNIL ने 2024 में LinkedIn contacts को स्क्रैप करने पर KASPR पर €200,000 का जुर्माना लगाया था (edpb.europa.eu).
- सर्वोत्तम अभ्यास:
- जहाँ संभव हो, डिफ़ॉल्ट रूप से Places API का उपयोग करें।
- अनुरोधों की गति सीमित करें (API के लिए ≤10 QPS, HTML scraping के लिए 1–2 req/s)।
- कभी भी CAPTCHAs या तकनीकी अवरोधों को बायपास न करें।
- स्क्रैप किए गए personal data को पुनर्वितरित न करें।
- opt-out और deletion अनुरोधों का सम्मान करें।
- हमेशा स्थानीय कानूनों की समीक्षा करें—GDPR, CCPA, और अन्य नियम सक्रिय रूप से लागू किए जा रहे हैं।
सार: अगर अनुपालन चिंता है, तो API पर टिके रहें और जो डेटा इकट्ठा करें उसे कम से कम रखें। ज़्यादातर व्यवसायिक उपयोगकर्ताओं के लिए, Thunderbit जैसा no-code टूल जोखिम को कम करता है (न API key, न पुनर्वितरण)।
Python के साथ Google Maps स्क्रैपिंग को शेड्यूल और ऑटोमेट करना
अगर आपको अपना डेटा ताज़ा रखना है—मान लीजिए, साप्ताहिक प्रतिस्पर्धी निगरानी या मासिक lead list अपडेट के लिए—तो automation आपका दोस्त है।
schedule के साथ सरल शेड्यूलिंग
import schedule, time
from my_scraper import run_job
schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
while True:
schedule.run_pending()
time.sleep(30)
APScheduler के साथ production-grade शेड्यूलिंग
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.triggers.cron import CronTrigger
sched = BackgroundScheduler(timezone="America/New_York")
sched.add_job(
run_job,
CronTrigger(hour=3, minute=15, jitter=600), # सुबह 3:15 ± 10 मिनट
kwargs={"query": "restaurants in Brooklyn"},
id="brooklyn_daily",
max_instances=1,
coalesce=True,
misfire_grace_time=3600,
)
sched.start()
सुरक्षित automation के लिए सुझाव
- अनुमानित पैटर्न से बचने के लिए अपने schedule में random jitter जोड़ें।
- HTML scraping के लिए, कभी भी प्रति सेकंड 1–2 से अधिक अनुरोध न चलाएँ।
- API उपयोग के लिए, अपनी quota पर नज़र रखें और billing alerts सेट करें।
- हमेशा errors log करें और असफल अनुरोधों के लिए “dead-letter” फ़ाइल बनाएँ।
Thunderbit बोनस: Thunderbit के साथ, आप सीधे UI में recurring scrapes शेड्यूल कर सकते हैं—न code, न cron jobs, न server setup।
मुख्य निष्कर्ष: कुशल, लक्षित, और अनुपालन योग्य Google Maps डेटा निष्कर्षण
आइए ज़रूरी बातों को फिर से समेटें:
- Google Maps व्यवसायिक लोकेशन डेटा का #1 स्रोत है, जो lead gen से लेकर market research तक सब कुछ चलाता है।
- Python scraping लचीलापन और नियंत्रण देता है, लेकिन इसके साथ setup, maintenance, और compliance का बोझ भी आता है—खासकर जब Google के anti-bot उपाय और कानूनी प्रवर्तन तेज़ हो रहे हों।
- API-आधारित निष्कर्षण ज़्यादातर टीमों के लिए सबसे सुरक्षित और सबसे scalable रास्ता है। लागत नियंत्रित करने के लिए हमेशा field masks और server-side filters का उपयोग करें।
- HTML scraping नाज़ुक और जोखिम भरा है—इसे केवल एक-बार के research के लिए इस्तेमाल करें, और कभी भी तकनीकी बाधाओं को बायपास न करें।
- अपने डेटा को लक्षित करें: सिर्फ़ वही निकालने के लिए phrase matching, location filters, और pandas workflows का उपयोग करें जिसकी आपको सच में ज़रूरत है।
- गैर-कोडर्स के लिए Thunderbit सबसे तेज़ रास्ता है: AI-संचालित, कोई सेटअप नहीं, तुरंत export, और बिल्ट-इन scheduling।
- अनुपालन मायने रखता है: कानूनी परेशानियों से बचने के लिए Google की शर्तों, गोपनीयता कानूनों, और rate limits का सम्मान करें।
अधिक tutorials और सुझावों के लिए, Thunderbit Blog और हमारा YouTube Channel देखें।
अक्सर पूछे जाने वाले प्रश्न
1. क्या 2026 में Python के साथ Google Maps डेटा स्क्रैप करना कानूनी है?
आधिकारिक API के माध्यम से Google Maps स्क्रैप करना Google की शर्तों के भीतर अनुमति है, बशर्ते आप quotas का सम्मान करें और प्रतिबंधित डेटा को पुनर्वितरित न करें। Google Maps की HTML scraping पर Google की ToS स्पष्ट रूप से रोक लगाती है और कानूनी जोखिम पैदा करती है, खासकर अगर आप तकनीकी बाधाओं को बायपास करते हैं या बिना सहमति personal data इकट्ठा करते हैं। हमेशा स्थानीय कानून (GDPR, CCPA, आदि) जाँचिए और अनुपालन के लिए सर्वोत्तम अभ्यास अपनाइए।
2. Google Maps API और HTML वेब स्क्रैपिंग में क्या अंतर है?
API स्थिर, लाइसेंस प्राप्त, और डेटा निष्कर्षण के लिए डिज़ाइन की गई है, लेकिन इसके लिए API key चाहिए और यह quotas तथा लागतों के अधीन है। HTML scraping रेंडर किए गए पेज से डेटा निकालने के लिए browser automation का उपयोग करती है, लेकिन यह नाज़ुक होती है (साइट अक्सर बदलती है), शर्तों का उल्लंघन कर सकती है, और कानूनी रूप से अधिक जोखिमभरी है। अधिकतर बिज़नेस उपयोग के लिए API सुझाया गया रास्ता है।
3. 2026 में Python से Google Maps डेटा निकालने में कितना खर्च आता है?
Google की Places API pricing प्रति 1,000 अनुरोधों पर आधारित है, जो आपके द्वारा माँगे गए फ़ील्ड्स के अनुसार $5 (Essentials) से $25 (Enterprise+Atmosphere) तक होती है। मुफ्त मासिक thresholds भी हैं (Essentials के लिए 10,000, Pro के लिए 5,000, Enterprise के लिए 1,000), लेकिन बड़े पैमाने पर scraping जल्दी महँगी हो सकती है। लागत नियंत्रित करने के लिए हमेशा field masks और server-side filters का उपयोग करें।
4. Thunderbit, Python-आधारित Google Maps स्क्रैपर्स से कैसे तुलना करता है?
Thunderbit एक नो-कोड, AI-संचालित web scraper है जो आपको प्रोग्रामिंग, API keys, या maintenance के बिना Google Maps डेटा (और बहुत कुछ) निकालने देता है। यह सेल्स और मार्केटिंग टीमों के लिए आदर्श है जिन्हें Excel, Google Sheets, Airtable, या Notion में तेज़, भरोसेमंद exports चाहिए। कस्टम logic की ज़रूरत वाले technical users के लिए Python ज़्यादा लचीलापन देता है, लेकिन इसमें अधिक setup और compliance प्रबंधन चाहिए।
5. मैं बार-बार होने वाले Google Maps डेटा निष्कर्षण को कैसे ऑटोमेट कर सकता हूँ?
Python में, schedule या APScheduler जैसी scheduling libraries का उपयोग करके अपने scraper को तय अंतराल पर (रोज़, हफ़्ते में, आदि) चलाएँ। detection से बचने के लिए random jitter जोड़ें और अपनी API quota पर नज़र रखें। Thunderbit के साथ, आप सीधे UI में recurring scrapes शेड्यूल कर सकते हैं—कोई code या server setup ज़रूरी नहीं।
क्या आप Google Maps को अपनी सेल्स और मार्केटिंग की सुपरपावर में बदलने के लिए तैयार हैं? चाहे आप Python के उत्साही हों या सबसे तेज़, no-code समाधान चाहते हों, 2026 में टूल्स तैयार हैं। तुरंत, AI-संचालित scraping के लिए Thunderbit आज़माइए—या अपनी आस्तीनें चढ़ाइए और API में उतर जाइए। किसी भी तरह, आपकी lead lists ताज़ा रहें, exports साफ़ रहें, और campaigns उच्च-रूपांतरण वाले स्थानीय prospects से भरे रहें। हैप्पी स्क्रैपिंग!
और जानें




