

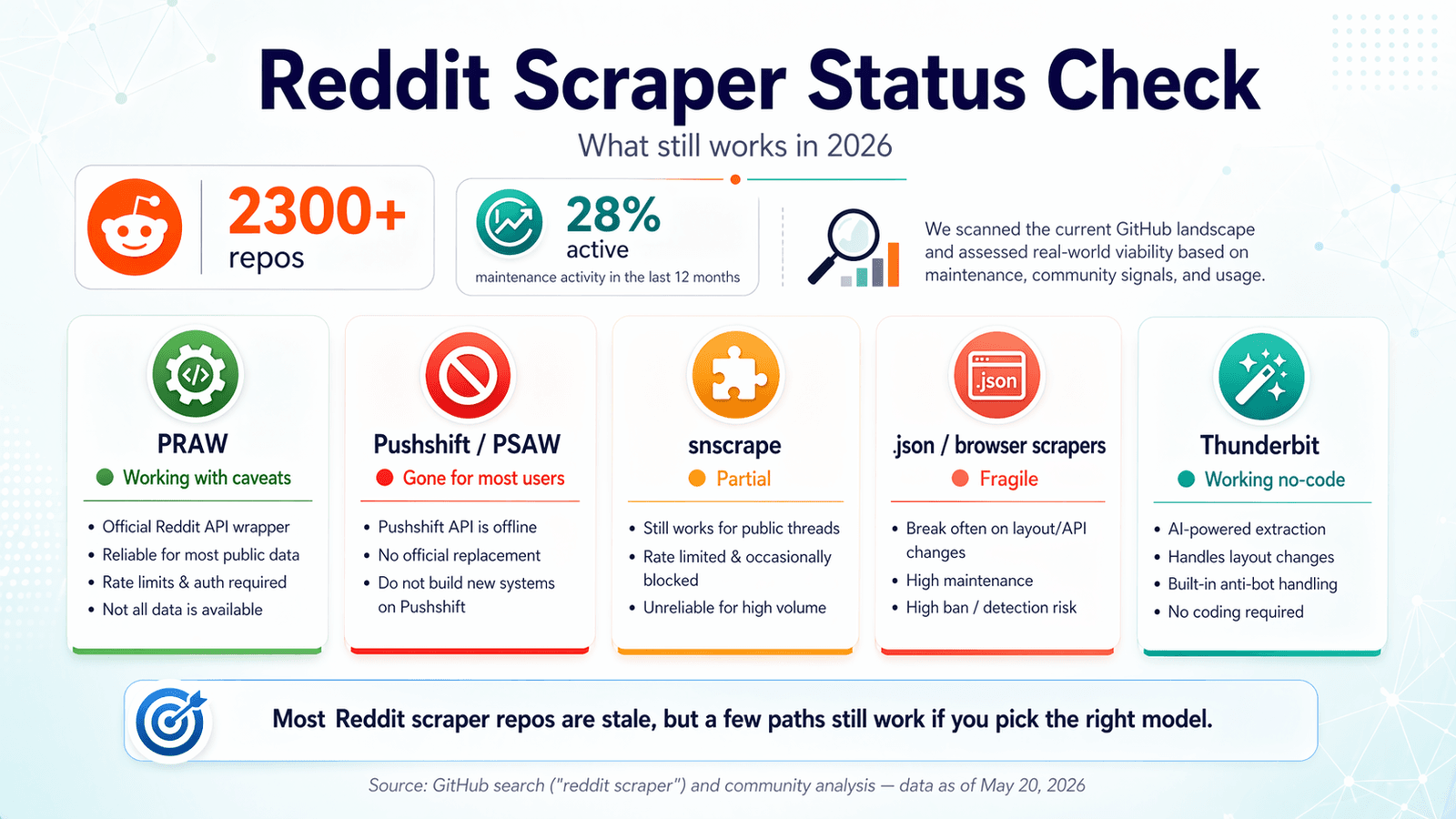
GitHub अभी 2,300 से ज़्यादा Reddit scraper repos दिखा रहा है। सुनने में यह किसी बुफे जैसा लगता है। लेकिन असली बात यह है: पिछले बारह महीनों में सिर्फ़ लगभग 28% में ही कोई maintenance activity दिखती है। पिछले कुछ हफ्तों से मैं इन repos को खंगाल रहा हूँ, endpoints टेस्ट कर रहा हूँ, issue queues पढ़ रहा हूँ, और Reddit के अपने policy updates से तुलना कर रहा हूँ। मकसद था: आपको किसी repo को clone करने, OAuth से जूझने, और आधी रात को यह समझने से बचाना कि 2024 में सब कुछ चुपचाप टूट चुका था। 2026 में Reddit scraper GitHub का परिदृश्य अच्छी नीयतों के कब्रिस्तान जैसा है, जिसमें कुछ ही सचमुच उपयोगी tools हैं। यह गाइड बताता है कि क्या अभी भी काम करता है, क्या टूट चुका है, कब code को पूरी तरह छोड़ देना चाहिए, और Reddit की लगातार सख़्त होती enforcement के सही side पर कैसे रहा जाए। अगर आपको shortcut चाहिए, तो Thunderbit वह no-code option है जिसे हमने ठीक इसी तरह की समस्या के लिए बनाया है—लेकिन मैं यह भी साफ़ बताऊँगा कि कहाँ code-based solutions अब भी ज़्यादा समझदारी भरे हैं।
Reddit Scraper GitHub Repo क्या होता है (और इतने सारे क्यों टूटे हुए हैं)
एक "reddit scraper github" repo आम तौर पर एक open-source Python (या कभी-कभी JavaScript) project होता है जो Reddit से posts, comments, user data, या media खींचने को automate करता है। ये आम तौर पर चार श्रेणियों में बँटते हैं:
- API wrappers (जैसे PRAW): Reddit के official API का इस्तेमाल करते हैं, OAuth की ज़रूरत होती है, और Reddit के नियमों के हिसाब से चलते हैं।
- Pushshift/PSAW-based tools: historical data के लिए Pushshift के बड़े Reddit archive तक पहुँचने के लिए बनाए गए थे।
- Public
.jsonendpoint scrapers: Reddit URLs के साथ.jsonजोड़कर या public-facing endpoints hit करके बिना authentication data निकालते हैं। - Browser-based scrapers: Playwright, Selenium, या browser extensions का उपयोग करके Reddit pages load करते हैं और rendered content extract करते हैं।
इतने सारे क्यों टूट गए? तीन वजहें हैं।
- 2023 के मध्य में Reddit ने API pricing overhaul किया। Free API limits घटकर OAuth के साथ प्रति मिनट 100 queries और बिना OAuth सिर्फ़ 10 रह गईं। ज़्यादा commercial usage अब प्रति 1,000 API calls पर $0.24 से शुरू होता है। कई repos उस दुनिया के लिए बनाए गए थे जहाँ API access लगभग unlimited था—और वह दुनिया अब नहीं रही।
- Pushshift की public access वापस ले ली गई। Historical Reddit research की रीढ़ Pushshift था। Reddit ने इसे restrict किया तो "historical scraper" repos का बड़ा हिस्सा अपने मुख्य data source से कट गया। कुछ README अभी भी इन्हें ज़िंदा दिखाते हैं, लेकिन नीचे वाला dependency सामान्य users के लिए अब गायब है।
- Reddit ने policy और enforcement दोनों कड़े कर दिए। 2024 का robots.txt update, 2025 की Public Content Policy, और मार्च 2026 की Responsible Builder Policy साफ़ संकेत देते हैं कि Reddit bulk scraping को अब हानिरहित background noise नहीं मानता। उन्होंने Anthropic और SerpApi के खिलाफ unauthorized data access को लेकर शिकायतें भी दर्ज की हैं।
निष्कर्ष: "reddit scraper github" खोजेंगे तो सैकड़ों results मिलेंगे। लेकिन आख़िरी commit dates और open-issue counts एक बिल्कुल अलग कहानी बताते हैं।
2026 Reddit Scraper GitHub Status Check: क्या अब भी काम करता है
ज़्यादातर competing articles 2023 या 2024 में लिखे गए थे और फिर कभी अपडेट नहीं हुए। Forum users ऐसे repos पर error झेलते रहते हैं जो एक साल पहले ठीक चलते थे—एक user की गुहार, "Keep running into Reddit API limitation error :\ Any ideas how I can get past this?" दरअसल 2026 के Reddit scraper अनुभव का सार है।
मैंने एक freshness audit चलाया, और अप्रैल 2026 तक सत्यापित किया। यह रहा जो मिला।
PRAW: आधिकारिक Python Wrapper
स्थिति: ✅ अब भी काम करता है, कुछ caveats के साथ।
PRAW (Python Reddit API Wrapper) Reddit scraping के लिए सबसे भरोसेमंद open-source foundation बना हुआ है। यह actively maintained है—4,099 stars, आख़िरी push 20 अप्रैल 2026, सिर्फ़ 6 open issues, और PyPI पर praw 7.8.1 सूचीबद्ध है (अक्टूबर 2024 में जारी)।
मज़बूतियाँ: आधिकारिक, अच्छी तरह documented, Reddit API की ज़्यादातर जटिलता को abstract कर देता है।
2026 की सीमाएँ:
- OAuth requirements ज़्यादा सख़्त हैं। आपको approved use-case description वाला registered Reddit app चाहिए।
- 2024 के बाद rate limits कम हो गईं (OAuth के साथ 100 queries/मिनट, बिना 10)।
- लगभग 1,000 posts की hard listing cap अभी भी मौजूद है। r/redditdev और Stack Overflow पर community threads पुष्टि करते हैं: किसी listing endpoint से 1,000 से ज़्यादा posts निकालने का कोई तरीका नहीं है।
अगर आप API की सीमाओं के भीतर रह सकते हैं, तो PRAW सबसे सुरक्षित विकल्प है।
यह अब मुक्त-रूप bulk scraper नहीं रहा।
अगर आप official API route का practical walkthrough चाहते हैं, तो यह tutorial इस section के लिए अच्छी तरह फिट बैठता है:
Pushshift / PSAW: वह archive जो अंधेरे में चला गया
स्थिति: ❌ Public access समाप्त।
PSAW Pushshift के लिए जाने-माने Python wrapper था, जो कभी historical Reddit data पाने का सबसे आसान रास्ता था। 2026 में यह repo archived है, README में literally लिखा है "THIS REPOSITORY IS STALE," और हाल के open issues में "Pushshift.io UNABLE to connect" और "The code not working. Possibly due to pushshift api." जैसी पंक्तियाँ शामिल हैं।
Academic access कुछ खास channels के ज़रिए अभी भी हो सकता है, लेकिन आज "reddit scraper github" खोजने वाले ज़्यादातर लोगों के लिए Pushshift/PSAW व्यावहारिक विकल्प नहीं है। अगर आपको गहरा historical Reddit data चाहिए, तो approved academic data access या licensed routes देखने होंगे।
snscrape (Reddit Module): आंशिक और अविश्वसनीय
स्थिति: ⚠️ आंशिक — बीच-बीच में टूटता है, और काफी हद तक unmaintained है।
snscrape के 5,337 stars हैं, लेकिन आख़िरी push 15 नवंबर 2023 का है। README अब भी कहती है कि Reddit scraping "via Pushshift" supported है। Reddit से जुड़े open issues में "Error reddit scraping" और "Reddit scraper returns no submissions before 2022-11-03" शामिल हैं, और हाल में किसी ठोस repair activity का नामोनिशान नहीं है।
यह कुछ environments में छोटे, one-off pulls के लिए काम कर सकता है, लेकिन production या recurring scrapes के लिए भरोसेमंद नहीं है। इसे legacy मानिए।
Playwright और .json Endpoint Scrapers: workaround जो काम करता है (कभी-कभी)
स्थिति: ✅ काम करता है, लेकिन नाज़ुक है।
यहाँ idea सीधा है: headless browser (Playwright, Puppeteer) से Reddit pages load करें और rendered content scrape करें, या Reddit URLs में .json जोड़कर official API के बिना structured data लें।
मज़बूतियाँ: API key की ज़रूरत नहीं, 1k-post cap को bypass कर सकता है, rendered content तक पहुँच मिलती है।
कमज़ोरियाँ: Reddit जब front-end layout या JSON structure बदलता है तो टूट जाता है, anti-bot measures trigger हो सकते हैं, और सेटअप ज़्यादा technical है। इस महीने मेरे अपने परीक्षण में public Reddit .json endpoints पर direct requests ने 403 responses दिए। इसका मतलब यह नहीं कि हर environment block होगा, लेकिन इतना ज़रूर है कि .json shortcut को अब "बस चल ही जाएगा" मानना ठीक नहीं।
yars जैसे repos इस बारे में काफ़ी ईमानदार हैं: README users को चेतावनी देती है कि "Use with rotating proxies, or Reddit might gift you with an IP ban." अप्रैल 2026 की कहानी यही एक वाक्य में कह देता है।
अगर आप browser-automation workaround path पर विचार कर रहे हैं, तो नीचे वाले section के लिए यह Playwright tutorial एक मज़बूत साथी है:
Thunderbit: AI-संचालित browser scraping (no code, no API key)
स्थिति: ✅ काम करता है — page changes के साथ अपने-आप adapt होता है।
Thunderbit एक बिल्कुल अलग तरीका अपनाता है। यह एक Chrome Extension है जो AI की मदद से Reddit pages पढ़ता है, data fields सुझाता है (post title, author, upvotes, timestamp, URL, आदि), और दो clicks में structured data निकालता है। OAuth setup नहीं, API key registration नहीं, Python environment नहीं, dependency management नहीं। AI हर बार page को fresh पढ़ता है, इसलिए जब Reddit अपना layout बदलता है, Thunderbit quietly टूटता नहीं—वह अपने-आप adapt हो जाता है।
CSV, Google Sheets, Airtable, या Notion में free export। Pagination और subpage scraping को संभालता है (जैसे subreddit listing scrape करना, फिर comments निकालने के लिए हर post पर जाना)। जिन लोगों को GitHub repo में maintenance किए बिना Reddit data चाहिए, उनके लिए यह सबसे आसान रास्ता है।
(पूरा disclosure: हमने Thunderbit बनाया है, इसलिए मेरी राय थोड़ी झुकी हुई है—लेकिन मैं बाद में साफ़ बताऊँगा कि code-based solutions कहाँ अब भी बेहतर समझ में आते हैं।)
Side-by-Side Status Summary Table
| टूल / श्रेणी | अप्रैल 2026 में अब भी काम करता है? | API Key चाहिए? | नोट्स |
|---|---|---|---|
| PRAW | ✅ हाँ, कुछ caveats के साथ | हाँ (OAuth) | सबसे बेहतर maintained open-source foundation. Rate limits और 1k-post cap से सीमित. |
| Pushshift / PSAW | ❌ नहीं (ज़्यादातर users के लिए) | लागू नहीं | Public access समाप्त. Repo archived. |
| snscrape (Reddit module) | ⚠️ आंशिक / अविश्वसनीय | नहीं | अभी भी Reddit को "via Pushshift" के रूप में दस्तावेज़ करता है. Maintenance 2023 से रुकी हुई. |
| .json / public-endpoint scrapers | ⚠️ आंशिक | नहीं | काम कर सकते हैं, लेकिन direct requests पर बढ़ती हुई रोक. Proxy पर निर्भर. |
| Playwright / browser scrapers | ✅ हाँ, लेकिन नाज़ुक | आम तौर पर नहीं | बिना API वाला सबसे व्यावहारिक DIY workaround. Page changes और anti-bot checks फिर भी मायने रखते हैं. |
| Thunderbit | ✅ हाँ | नहीं | AI/browser workflow. OAuth नहीं, selectors नहीं. गैर-डेवलपर्स के लिए सबसे उपयुक्त. |
Rate Limits, 1k-Post Cap, और असल में क्या मदद करता है
यह Reddit scraper GitHub project इस्तेमाल करने वाले किसी भी व्यक्ति के लिए #1 दर्द बिंदु है। Forum threads frustration से भरे हैं: "tired of runs dying halfway through because of rate limits," "Why am I only getting around 1,000 items?" दो मूल constraints हैं Reddit की API rate limits (requests per minute) और लगभग 1,000-post listing cap (API हर listing endpoint के लिए केवल सबसे हाल के लगभग 1,000 posts लौटाती है)।
Rate-Limit Management की सर्वोत्तम प्रथाएँ
Reddit का मौजूदा public baseline: OAuth के साथ प्रति मिनट 100 queries, बिना 10। व्यावहारिक रूप से इसे ऐसे संभालें:
- Exponential backoff. अगर rate-limit response मिले, तो रुकें, फिर हर बार थोड़ी लंबी देरी के बाद retry करें (1s, 2s, 4s, 8s…). Endpoint पर लगातार hammer न करें।
X-Ratelimit-Remainingheaders पढ़ें। Reddit API responses में ऐसे headers होते हैं जो बताते हैं कि कितनी requests बची हैं और window कब reset होगी। Requests को अनुमान से नहीं, इन्हीं values के आधार पर pace करें।- Rotating user-agents. कुछ repos detection से बचने के लिए यह सुझाते हैं। यह मदद कर सकता है, लेकिन इसे नैतिक तरीके से इस्तेमाल करें—जिन bans के आप हकदार हैं, उनसे बचने के लिए नहीं।
- सब कुछ log करें। API responses, rate-limit headers, और errors का logging जोड़ें। जब scraper 2 AM पर मर जाए, logs आपका सबसे अच्छा दोस्त होते हैं।
1,000-Post की दीवार तोड़ना
API की लगभग 1,000-item listing cap का सबसे विश्वसनीय workaround है time-window chunking:
beforeऔरaftertimestamp parameters के साथ एक time slice query करें।- Window को आगे (या पीछे) बढ़ाएँ।
- Repeat करें।
- Post ID पर deduplicate करें।
यह elegant नहीं है, लेकिन यह यह दिखाने से ज़्यादा ईमानदार है कि एक request loop किसी listing endpoint से मनचाहा इतिहास खींच सकता है। सचमुच historical data के लिए आपको approved academic access या licensed path चाहिए होगा—Pushshift अब default उत्तर नहीं रहा।
Browser-based scraping (Playwright या Thunderbit) इस cap को पूरी तरह bypass कर देता है, क्योंकि यह API के लौटाए data को नहीं, बल्कि page पर rendered चीज़ों को scrape करता है। Thunderbit की pagination feature आपको pages के बीच click करने और जितने चाहें उतने pages से data इकट्ठा करने देती है।
Deduplication और Error Recovery
ज़्यादातर Reddit scraper GitHub repos dedup या error recovery को out of the box संभालते नहीं हैं। Users साफ़-साफ़ शिकायत करते हैं कि "none had deduping, rate limit avoidance after errors, checking if files are already downloaded." आपको यह करना चाहिए:
- Deduplication: हर post के ID (या ID + content) का hash बनाएँ। देखे गए hashes को एक सरल SQLite database या यहाँ तक कि flat file में रखें। Insert करने से पहले जाँचें कि hash पहले से मौजूद है या नहीं। यह खास तौर पर तब ज़रूरी है जब आप time windows chunk कर रहे हों या failed jobs को फिर चला रहे हों।
- Error recovery: हर N records के बाद progress को checkpoint file में सेव करें। अगर run fail हो जाए, तो शुरू से नहीं बल्कि आख़िरी checkpoint से restart करें। इससे 3 घंटे का काम, जो 2 घंटे पर मर जाता है, 1 घंटे के resume में बदल जाता है।
अलग-अलग approaches इन constraints को कैसे संभालती हैं

| तरीका | Rate-limit handling | >1k Posts? | Auto-dedup? | Error recovery? |
|---|---|---|---|---|
| PRAW (raw) | Manual (sleep/retry) | ❌ (API cap) | ❌ | ❌ |
| PRAW + time-window chunking | Manual | ✅ (workaround) | ❌ | ❌ (जब तक आप इसे जोड़ें नहीं) |
| Playwright .json scraping | लागू नहीं (कोई API नहीं) | ✅ | ❌ | ❌ |
| Thunderbit (browser scraping) | Built-in (AI pacing) | ✅ (pagination) | लागू नहीं (visual review) | Built-in |
जब Reddit Scraper GitHub Repo जवाब नहीं है: No-Code रास्ता
ज़्यादातर Reddit scraper GitHub articles मान लेते हैं कि आपको Python आती है। लेकिन Reddit scraping solutions खोजने वाले बहुत से लोग marketers, sales reps, researchers, या indie founders होते हैं जो रोज़ Python नहीं लिखते। ऐसे लोगों के लिए GitHub repo में छिपी लागतें होती हैं:
- OAuth credentials और Reddit developer app सेट करना
- Python virtual environments और dependency conflicts संभालना
- जब PRAW के internals बदलें तो cryptic error messages debug करना
- अगर Reddit आपके use case को approved न माने तो API key revocation संभालना
- Reddit कुछ बदलते ही script का maintenance करना
ये काल्पनिक नहीं हैं। bulk-downloader-for-reddit के 2,563 stars और 107 open issues हैं। हाल की reports में "Struggling to install," "PRAW module error," और "Exception not allowing to even authenticate." शामिल हैं।
GitHub Repo का उपयोग करें अगर...
- आपको custom scraping logic चाहिए (जैसे specific comment tree traversal, custom NLP pipeline integration)।
- आप इसे किसी मौजूदा Python data pipeline में integrate करना चाहते हैं।
- आपको custom storage (database, data warehouse) के साथ बहुत बड़े scale पर scrape करना है।
- आप code maintain करने और breaking changes संभालने में सहज हैं।
No-Code Tool का उपयोग करें अगर...
- आपको Reddit data जल्दी चाहिए—setup के घंटों के बजाय मिनटों में।
- आप API keys, OAuth apps, या Python environments नहीं संभालना चाहते।
- आप data को सीधे spreadsheets, Notion, या Airtable में तुरंत इस्तेमाल के लिए export करना चाहते हैं।
- Reddit का layout बदले तो आप चाहते हैं कि tool अपने-आप adapt हो जाए।
Thunderbit पूरी तरह no-code lane में फिट बैठता है। Users Reddit posts, comments, और user data scrape कर सकते हैं, AI-suggested fields के साथ 2 clicks में, CSV/Google Sheets/Airtable/Notion में free export कर सकते हैं, और code लिखे बिना pagination संभाल सकते हैं। इसका browser-based scraping मतलब OAuth setup और API-key registration की ज़रूरत नहीं।
त्वरित walkthrough: Thunderbit से Reddit scraping (Step by Step)
- Thunderbit Chrome Extension इंस्टॉल करें।
- उस Reddit page पर जाएँ जिसे आप scrape करना चाहते हैं (subreddit, search results, user profile)।
- "AI Suggest Fields" पर क्लिक करें। Thunderbit page पढ़कर columns सुझाता है—post title, author, upvotes, timestamp, URL, आदि।
- ज़रूरत हो तो fields समायोजित करें, फिर "Scrape" पर क्लिक करें।
- Data table की समीक्षा करें। चाहें तो "Scrape Subpages" पर क्लिक करके हर post पर जाएँ और comments या अतिरिक्त details निकालें।
- अपनी पसंद की जगह export करें: Google Sheets, Excel, Airtable, Notion, CSV, या JSON।
दो मिनट। कोड की एक भी line नहीं। अगर आप इसे काम करते देखना चाहते हैं, तो Thunderbit YouTube channel देखें।
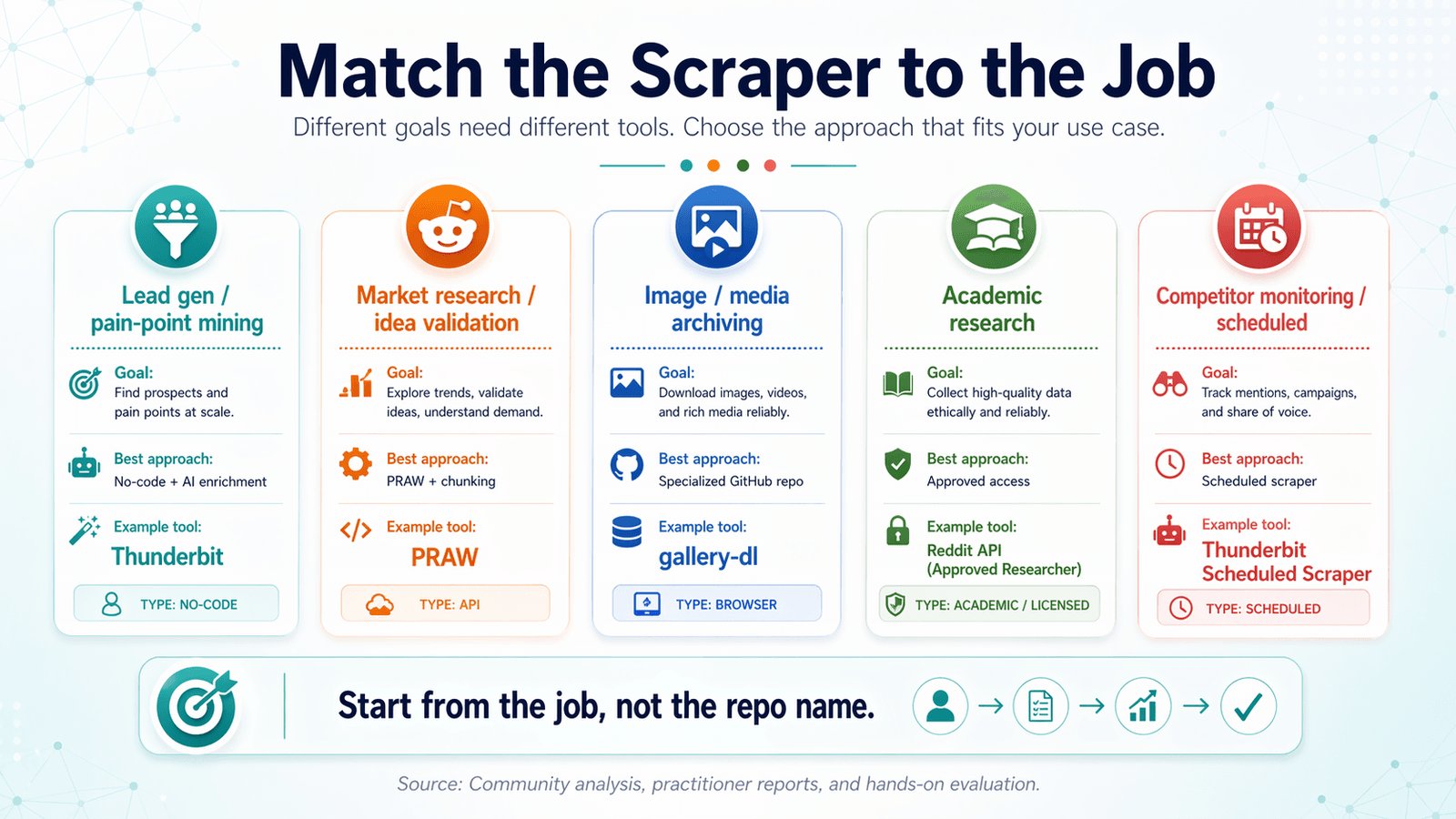
काम के हिसाब से सही Reddit Scraper चुनें: Use-Case Decision Matrix
ज़्यादातर Reddit scraper GitHub articles tool के हिसाब से व्यवस्थित होते हैं। यह उल्टा है।
अपनी ज़रूरत से शुरू करें और पीछे जाकर सही tool चुनें।
Lead Generation और Pain-Point Mining
आपको क्या चाहिए: keyword filtering के साथ posts + comments, AI tagging/labeling, CRM-ready formats में export।
सबसे अच्छा तरीका: AI enrichment वाला no-code scraper।
सुझाया गया tool: Thunderbit (AI labeling + CRM import के लिए Google Sheets/Airtable में export)।
उदाहरण workflow: किसी subreddit को ऐसे posts के लिए scrape करें जिनमें कोई specific pain point का ज़िक्र हो। Sentiment categorise करने या topics tag करने के लिए Thunderbit का Field AI Prompt इस्तेमाल करें। परिणाम sales टीम के Airtable या Google Sheet में export करें।
Market Research और Idea Validation
आपको क्या चाहिए: ज़्यादा मात्रा में post titles + scores, subreddit-level trend data।
सबसे अच्छा तरीका: volume के लिए time-window chunking के साथ PRAW, या तेज़ pulls के लिए Thunderbit।
उदाहरण: पिछले 90 दिनों में trending topics और upvote patterns के लिए r/SaaS या r/startups को scrape करना।
Image और Media Archiving
आपको क्या चाहिए: media URLs, deduplication, scheduled runs।
सबसे अच्छा तरीका: विशेष GitHub repo (जैसे bulk-downloader-for-reddit) + cron job।
नोट: यहाँ dedup बहुत मायने रखता है—एक ही image का अलग-अलग subreddits में post होना आम है।
Academic Research और Historical Data
आपको क्या चाहिए: historical data, पूरी comment trees, बड़े datasets।
सबसे अच्छा तरीका: approved academic access या licensed data path। Pushshift अब general-purpose answer नहीं है।
सच्चाई जाँच: Pushshift restrictions और Reddit की कड़ी data policies के कारण 2026 में यह सबसे कठिन use case है।
Competitor Monitoring और Scheduled Scraping
आपको क्या चाहिए: तय अंतराल पर बार-बार scraping, change detection।
सबसे अच्छा तरीका: Thunderbit का Scheduled Scraper (plain English में time interval बताइए, URLs डालिए, Schedule क्लिक कीजिए) या code-based users के लिए cron + script।
Use-Case Decision Matrix Table
| उपयोग-क्षेत्र | आपको क्या चाहिए | सबसे अच्छा तरीका | उदाहरण tool |
|---|---|---|---|
| Lead gen / pain-point mining | Posts + comments, keyword filtering, AI tagging | No-code scraper + AI enrichment | Thunderbit |
| Market research / idea validation | High-volume post titles + scores, subreddit-level data | PRAW + time-window chunking या Thunderbit | PRAW या Thunderbit |
| Image/media archiving | Media URLs, dedup, scheduled runs | Specialised GitHub repo + cron | bulk-downloader-for-reddit |
| Academic research | Historical data, full comment trees | Approved academic access या Playwright | Pushshift academic API (if accessible) |
| Competitor monitoring / scheduled | Recurring scrapes, change detection | Scheduled scraper | Thunderbit Scheduled Scraper या cron + script |
Commit करने से पहले किसी भी Reddit Scraper GitHub Repo का मूल्यांकन कैसे करें
Repo clone करने और debug शुरू करने से पहले यह 5-minute health check चलाएँ। इससे आपके घंटों बचेंगे।
5-Minute Repo Health Check
- Last commit date. अगर 6 महीने से ज़्यादा हो गए हैं, तो सावधानी से आगे बढ़ें। Reddit के API changes बार-बार होते हैं।
- Open issues बनाम closed issues का अनुपात। बहुत सारे अनुत्तरित issues red flag हैं। देखें कि हाल के issues में auth failures, 403s, या Pushshift outages का ज़िक्र है या नहीं।
- LICENSE file. देखें कि मौजूद है या नहीं। License नहीं = कानूनी रूप से अस्पष्ट (नीचे इस पर और)।
- Dependencies. क्या आवश्यक libraries अपडेटेड हैं? क्या deprecated packages का इस्तेमाल हो रहा है? 2022 के pinned versions वाली
requirements.txtचेतावनी का संकेत है। - README quality. क्या setup साफ़ समझाया गया है? क्या usage examples हैं? खराब docs = आपके लिए ज़्यादा debugging time।
- Stars बनाम forks बनाम recent activity. बहुत stars लेकिन कम recent activity का मतलब हो सकता है कि project कभी लोकप्रिय था, पर अब छोड़ दिया गया है। Stars की तुलना
pushed_atdate से करें।
एक त्वरित उदाहरण: PSAW के 364 stars हैं—पहली नज़र में भरोसेमंद लगता है। लेकिन repo archived है और README कहती है "THIS REPOSITORY IS STALE."
सिर्फ़ stars पूरी कहानी नहीं बताते।
अपने Reddit Scraper GitHub Setup से ज़्यादा फायदा कैसे लें
अगर आप code route चुनते हैं, तो कुछ परेशानियाँ बचाने का तरीका यह है।
हमेशा Virtual Environment इस्तेमाल करें
Virtual environment आपके scraper की dependencies को अलग रखता है ताकि वे दूसरे Python projects से टकराएँ नहीं। एक command: python -m venv venv और फिर कुछ भी install करने से पहले इसे activate करें। यह basic hygiene है, लेकिन मैंने "module not found" शीर्षक वाले इतने GitHub issues देखे हैं कि इसे दोहराना वाजिब है।
Credentials सुरक्षित रखें
अपने Reddit API client ID या secret को script में कभी hardcode न करें। Environment variables या .env file का उपयोग करें, और .env को अपनी .gitignore में जोड़ें। अगर credentials गलती से GitHub पर push हो जाएँ, तो उन्हें तुरंत rotate करें—bots exposed API keys स्कैन करते हैं।
सब कुछ log करें
API responses, rate-limit headers, और errors का logging जोड़ें। जब कुछ टूटता है, logs "मुझे ठीक-ठीक पता है क्या हुआ" और "मुझे पता ही नहीं क्यों रुक गया" के बीच का फर्क होते हैं।
समझदारी से schedule और automate करें
अगर recurring scrapes चला रहे हैं, तो cron (Linux/Mac) या Task Scheduler (Windows) का इस्तेमाल करें—लेकिन failures पर नज़र रखें। एक cron job जो दो हफ्ते तक silently fail करती रहे, वह automation न होने से भी बदतर है।
विकल्प: Thunderbit का Scheduled Scraper आपको plain English में interval बताने देता है, cron syntax की ज़रूरत नहीं।
Reddit Scraping के लिए कानूनी और नैतिक सर्वोत्तम प्रथाएँ
यह कोई फालतू disclaimer नहीं है। 2023 के API changes के बाद से Reddit ने अपनी terms को सख़्ती से लागू किया है, और personal data scraping के साथ वास्तविक कानूनी जोखिम जुड़ता है।
असल में क्या मायने रखता है, यह रहा।
Reddit की Terms of Service: वे वास्तव में क्या कहती हैं
Reddit का User Agreement (31 मार्च 2026 तक revised) साफ़ तौर पर automated means से services से data access, search, या collection को प्रतिबंधित करता है, जब तक terms या किसी अलग agreement में अनुमति न हो। Data API Terms और Developer Terms और विवरण जोड़ते हैं: Reddit developer use को monitor और audit कर सकता है, access बदल या बंद कर सकता है, और excessive या abusive usage पर access स्थायी रूप से block कर सकता है। Commercial use के लिए आम तौर पर स्पष्ट approval चाहिए।
मार्च 2026 की Responsible Builder Policy इससे भी आगे जाती है: API के ज़रिए Reddit data access करने से पहले approval ज़रूरी है, unapproved commercialization और AI/data-mining uses प्रतिबंधित हैं, और enforcement में tokens revoke करना, apps या accounts suspend करना, और संबंधित bots या domains को suspend करना शामिल हो सकता है।
robots.txt अनुपालन
Reddit का मौजूदा robots.txt असामान्य रूप से सख़्त है:
User-agent: *
Disallow: /
यह सभी automated user agents के लिए blanket disallow है। इसमें Public Content Policy का संदर्भ भी है। यह पुराने web-scraping norms से कुछ developers को याद रहने वाले permissive robots.txt patterns से कहीं ज़्यादा सख़्त है।
सर्वोत्तम प्रथा: scraping से पहले हमेशा robots.txt जाँचें, भले ही आपका tool इसे अपने-आप enforce न करता हो।
Personal Data और Privacy (GDPR/CCPA)
अगर आप usernames, post history, या कोई भी personally identifiable information scrape कर रहे हैं, तो GDPR (EU) और CCPA (California) लागू हो सकते हैं। सर्वोत्तम प्रथा: personal data को store करने से पहले anonymize या aggregate करें। वैध आधार के बिना individual users के प्रोफ़ाइल न बनाएँ।
GitHub Repo Licensing: Build करने से पहले जाँचें
कई Reddit scraper GitHub repos MIT या Apache licenses (permissive) का उपयोग करते हैं, लेकिन कुछ में LICENSE file होती ही नहीं—जिसका कानूनी अर्थ है "all rights reserved." Fork करने, modify करने, या किसी repo पर build करने से पहले हमेशा LICENSE file देखें। License नहीं = कानूनी रूप से अस्पष्ट, चाहे stars कितने भी हों।
2025–2026 में enforcement वास्तविक है
Reddit की enforcement कहानी 2023 पर खत्म नहीं हुई। Reddit ने 2025 में Anthropic के खिलाफ शिकायत दर्ज की, जिसमें Reddit content के unauthorized scraping/use का आरोप था, और late 2025 में Reddit v. SerpApi भी आगे बढ़ाया। ये संकेत हैं कि Reddit सिर्फ़ तकनीकी blocking नहीं, कानूनी enforcement भी करने को तैयार है।
2026 में सही Reddit Scraper GitHub Approach कैसे चुनें
2023 के बाद से Reddit scraper GitHub का परिदृश्य बहुत बदल गया है। ज़्यादातर repos outdated हैं। Rate limits और 1k-post cap वास्तविक सीमाएँ हैं। सामान्य users के लिए Pushshift अब उपलब्ध नहीं है। और Reddit की policy stack पहले से कहीं ज़्यादा स्पष्ट और ज़्यादा enforced है।
संक्षेप में:
- PRAW अब भी सबसे भरोसेमंद open-source foundation है, अगर आप Reddit की API सीमाएँ स्वीकार कर सकते हैं और custom logic बनाना चाहते हैं।
- Pushshift/PSAW अब general-purpose answer नहीं है।
- snscrape का Reddit module legacy है और भरोसेमंद नहीं।
- .json और public-endpoint scrapers नाज़ुक हैं और 2026 में अक्सर block हो जाते हैं।
- Browser-based tools—चाहे Playwright repos हों या Thunderbit जैसे no-code options—कई users, ख़ासकर non-developers, के लिए सबसे व्यावहारिक रास्ता हैं।
Tool से नहीं, use case से शुरू करें। किसी भी GitHub project पर commit करने से पहले 5-minute repo health check चलाएँ।
और अगर आप setup छोड़कर कुछ ही मिनटों में Reddit scraping शुरू करना चाहते हैं, तो Thunderbit आज़माइए.
Reddit Scraping के लिए Thunderbit आज़माएँ Get Started Free
अक्सर पूछे जाने वाले प्रश्न
2026 में GitHub पर सबसे अच्छे open-source Reddit scrapers कौन से हैं?
PRAW अब भी सबसे भरोसेमंद API wrapper है, अच्छी documentation और सक्रिय maintenance के साथ। URS PRAW पर बना एक भरोसेमंद maintained CLI tool है। Playwright-based scrapers non-API scraping के लिए काम करते हैं, और snscrape का Reddit module आंशिक रूप से काम करता है लेकिन अधिकांशतः unmaintained है। किसी भी repo का उपयोग करने से पहले last-commit date और open issues ज़रूर जाँचें—GitHub पर मौजूद 2,300+ Reddit scraper repos में से ज़्यादातर stale हैं।
क्या Reddit scrape करना legal है?
सार्वजनिक रूप से उपलब्ध data को scrape करना कानूनी gray area में आता है, लेकिन Reddit की अपनी terms काफ़ी सख़्त हैं। User Agreement, Data API Terms, Public Content Policy, Responsible Builder Policy, और robots.txt सभी unauthorized bulk scraping के खिलाफ़ हैं। Scraped data का commercial redistribution Reddit की स्पष्ट अनुमति माँग सकता है। अगर आप personal data scrape कर रहे हैं, तो GDPR और CCPA भी लागू हो सकते हैं।
मैं Reddit की API rate limits को कैसे पार करूँ?
Exponential backoff इस्तेमाल करें, X-Ratelimit-Remaining headers पर नज़र रखें, और limits के भीतर काम करने के लिए time-window chunking पर विचार करें। Browser-based scraping (Playwright या Thunderbit) API rate limits को bypass करता है क्योंकि यह rendered pages scrape करता है, लेकिन इसके अपने considerations हैं (page-load speed, anti-bot measures)। Rate limits को पूरी तरह हटाने का कोई जादुई तरीका नहीं है—वे server-side enforced होती हैं।
क्या मैं बिना API key के Reddit scrape कर सकता हूँ?
हाँ। Playwright-based scrapers और .json URL trick के लिए API key की ज़रूरत नहीं होती। Thunderbit को भी API key नहीं चाहिए, क्योंकि यह browser के ज़रिए scrape करता है। Trade-offs: .json endpoints पर अब ज़्यादा रोक लग रही है (अप्रैल 2026 तक कई environments में 403 लौट रहे हैं), और browser-based scraping API calls की तुलना में धीमा और ज़्यादा resource-intensive है।
Reddit scraping के लिए Pushshift का क्या हुआ?
2023 में Reddit की data licensing changes के बाद Pushshift की public API access हटा दी गई। PSAW wrapper archived और stale है। कुछ सीमित academic access specific approved channels के ज़रिए मौजूद हो सकता है, लेकिन आज "reddit scraper github" खोजने वाले ज़्यादातर users के लिए Pushshift अब व्यावहारिक विकल्प नहीं है। अगर आपको गहरा historical Reddit data चाहिए, तो Reddit के approved academic या licensed data paths देखें।
और जानें




