
आज की डिजिटल खबरों की रफ्तार सच में सिर घुमा देने वाली है। हर मिनट, हजारों हेडलाइनें प्रकाशित, अपडेट या चुपचाप संपादित होती रहती हैं—मुख्यधारा के समाचार संस्थानों, विशिष्ट ब्लॉगों और सोशल फ़ीड्स में। एक उदाहरण के तौर पर, हर दिन 40 लाख से अधिक समाचार लेख इकट्ठा करता है, जबकि 100+ भाषाओं में खबरों को ट्रैक करता है और अपनी वैश्विक फ़ीड को हर 15 मिनट में अपडेट करता है। मीडिया, शोध या बिज़नेस इंटेलिजेंस में काम करने वाले किसी भी व्यक्ति के लिए इस सैलाब के साथ हाथ से कदम मिलाकर चलना ऐसा है जैसे कॉफ़ी मग से डूबती नाव से पानी निकालना।
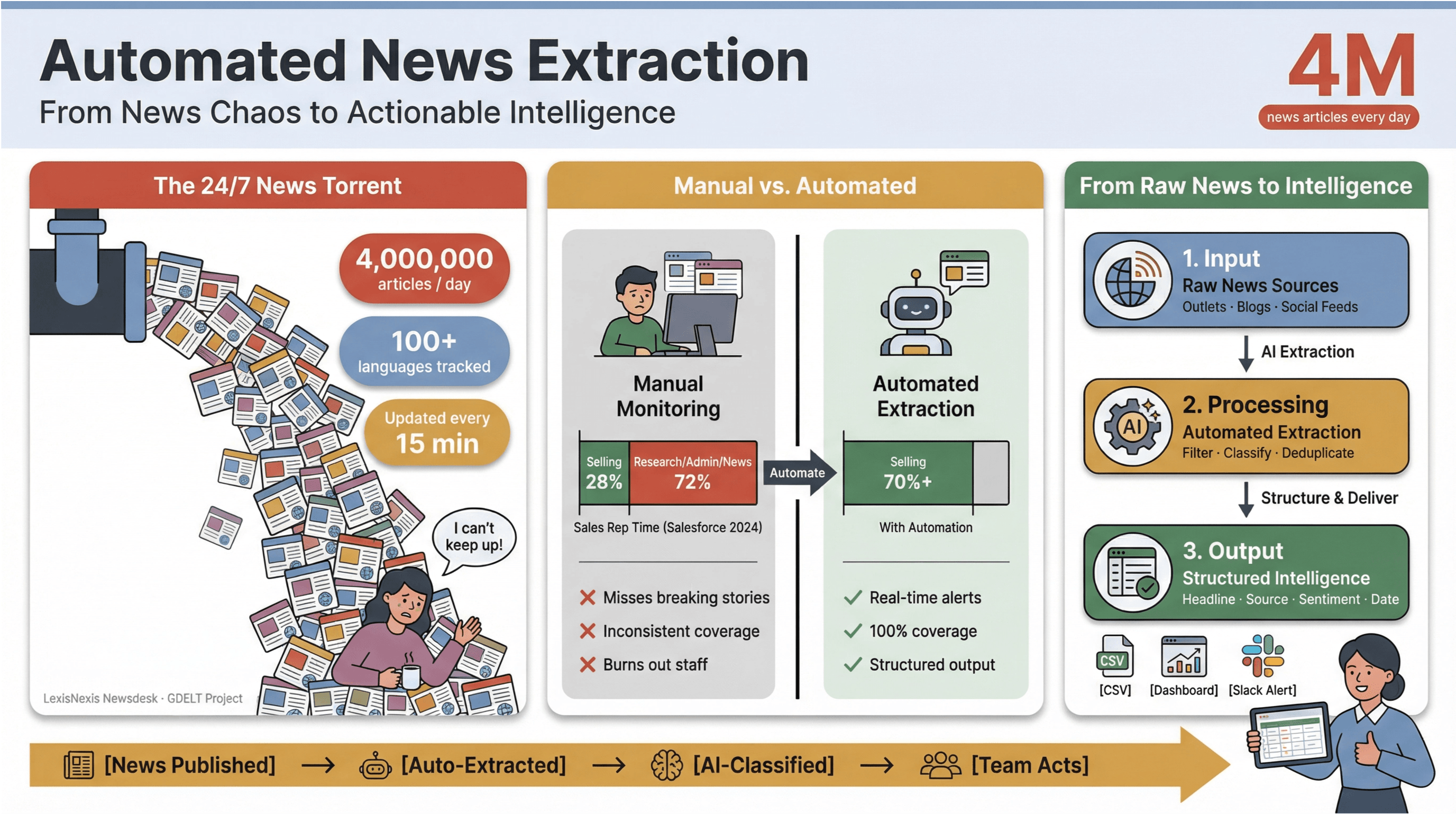
मैंने खुद देखा है कि मैन्युअल समाचार मॉनिटरिंग कितना समय खा जाती है और संसाधन चूस लेती है। बिक्री टीमें अपना हफ़्ते का एक-तिहाई से भी कम समय असल में बेचने में बिताती हैं——बाकी समय रिसर्च, प्रशासनिक कामों और हाँ, लगातार समाचार टैब बदलने में चला जाता है। इसी वजह से ऑटोमेटेड समाचार एक्सट्रैक्शन आधुनिक टीमों के लिए एक गुप्त हथियार बन गया है: 24/7 समाचार चक्र की अफ़रा-तफ़री को संरचित, कार्रवाई योग्य इंटेलिजेंस में बदलने का यही एक तरीका है—वो भी अपनी टीम को थकाए बिना या सबसे ज़रूरी खबरें मिस किए बिना।
आइए समझते हैं कि ऑटोमेटेड समाचार एक्सट्रैक्शन का असल मतलब क्या है, रियल-टाइम समाचार डेटा की परवाह करने वाले किसी भी व्यक्ति के लिए यह क्यों ज़रूरी है, और सबसे अच्छे टूल्स का उपयोग करके एक मज़बूत, अनुपालन-योग्य वर्कफ़्लो कैसे बनाया जाए (जिसमें गैर-तकनीकी लोगों जैसे मेरी माँ के लिए भी पूरे प्रोसेस को आश्चर्यजनक रूप से आसान बना देता है)।
ऑटोमेटेड समाचार एक्सट्रैक्शन: आधुनिक न्यूज़रूम्स के लिए यह क्यों अनिवार्य है
ऑटोमेटेड समाचार एक्सट्रैक्शन बिल्कुल वही है जो नाम से लगता है: सॉफ़्टवेयर की मदद से समाचार सामग्री को अपने-आप इकट्ठा करना और उसे संरचित, खोजने योग्य डेटा में बदलना—यानि गंदे-से वेब पेज या PDF की बजाय रो और कॉलम। व्यवहार में, इसका मतलब है कि आप सैकड़ों (या हज़ारों) स्रोतों की निगरानी कर सकते हैं, हेडलाइन, टाइमस्टैम्प, लेखक और बॉडी टेक्स्ट जैसे मुख्य फ़ील्ड्स निकाल सकते हैं, और उस डेटा को डैशबोर्ड, अलर्ट या डाउनस्ट्रीम एनालिटिक्स में भेज सकते हैं—बिना Ctrl+C/Ctrl+V किए।
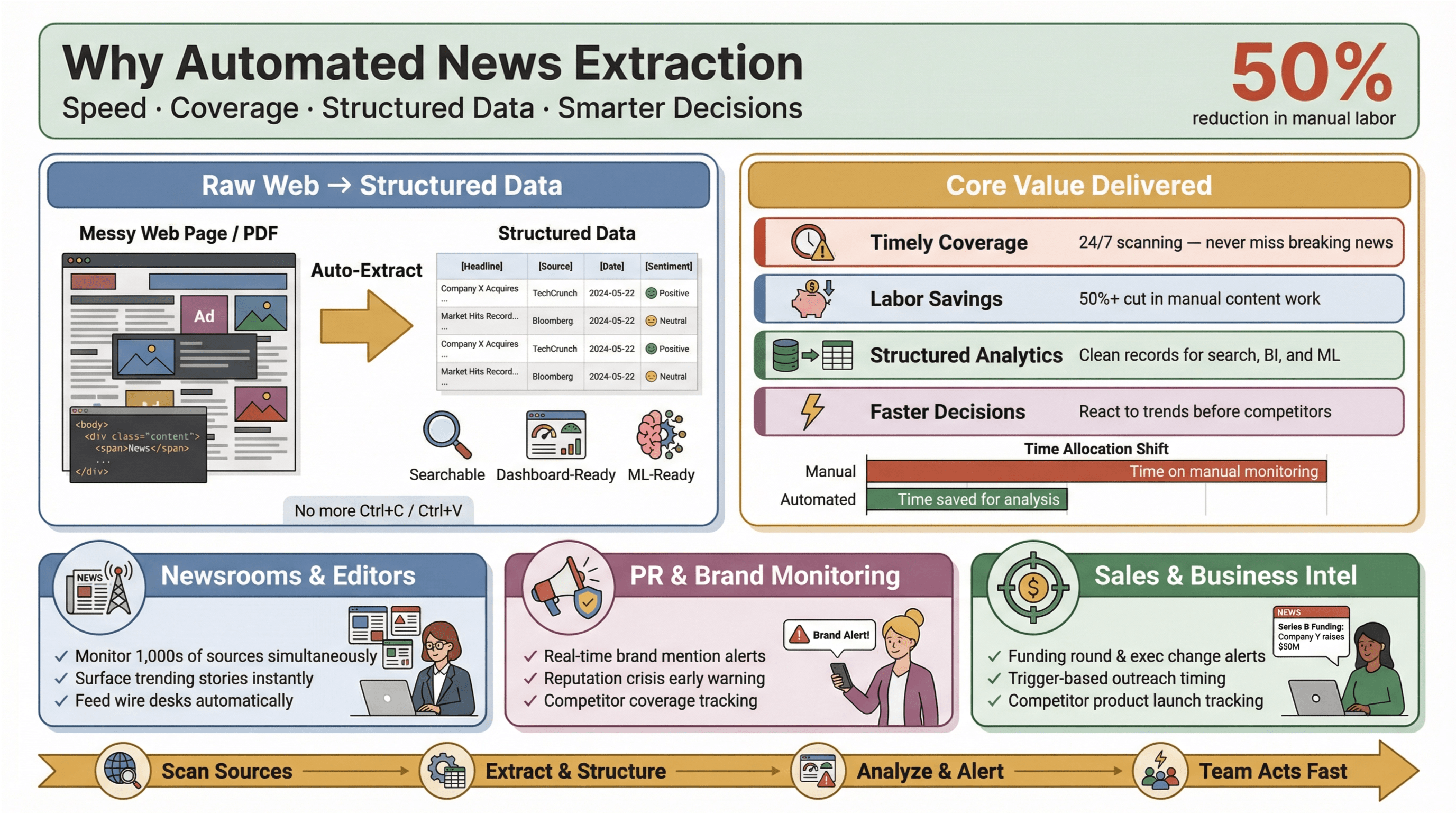 यह इतना महत्वपूर्ण क्यों है? क्योंकि आज के समाचार परिदृश्य में गति ही सब कुछ है। चाहे आप न्यूज़रूम एडिटर हों, ब्रांड मेंशन पर नज़र रखने वाले PR मैनेजर हों, या प्रतिस्पर्धी चालों को ट्रैक करने वाले बिज़नेस एनालिस्ट—पहले जान लेना किसी मौके को भुनाने और बस पीछे-पीछे दौड़ते रहने के बीच फ़र्क पैदा कर सकता है। ऑटोमेटेड एक्सट्रैक्शन टूल्स छोटी टीमों को भी उनकी क्षमता से कहीं आगे काम करने देते हैं—वेब भर से रियल-टाइम समाचार डेटा इकट्ठा करना, मैन्युअल बोझ कम करना, और सबसे ज़रूरी खबरों को सामने लाना।
यह इतना महत्वपूर्ण क्यों है? क्योंकि आज के समाचार परिदृश्य में गति ही सब कुछ है। चाहे आप न्यूज़रूम एडिटर हों, ब्रांड मेंशन पर नज़र रखने वाले PR मैनेजर हों, या प्रतिस्पर्धी चालों को ट्रैक करने वाले बिज़नेस एनालिस्ट—पहले जान लेना किसी मौके को भुनाने और बस पीछे-पीछे दौड़ते रहने के बीच फ़र्क पैदा कर सकता है। ऑटोमेटेड एक्सट्रैक्शन टूल्स छोटी टीमों को भी उनकी क्षमता से कहीं आगे काम करने देते हैं—वेब भर से रियल-टाइम समाचार डेटा इकट्ठा करना, मैन्युअल बोझ कम करना, और सबसे ज़रूरी खबरों को सामने लाना।
और इसका असर वास्तविक है: अध्ययन दिखाते हैं कि ऑटोमेशन कंटेंट अपडेट्स के लिए मैन्युअल श्रम को कम से कम 50% तक घटा सकता है, जिससे असली विश्लेषण और निर्णय लेने के लिए समय बचता है।
समाचार उद्योग में ऑटोमेटेड समाचार एक्सट्रैक्शन का मुख्य मूल्य
आइए इसे व्यावहारिक रूप में देखें। न्यूज़रूम्स और बिज़नेस टीमों के लिए ऑटोमेटेड समाचार एक्सट्रैक्शन असल में क्या देता है?
- समय पर, व्यापक कवरेज: अब ब्रेकिंग स्टोरी इसलिए नहीं छूटेगी क्योंकि किसी ने फ़ीड चेक करना भूल गया। ऑटोमेटेड टूल्स 24/7 स्रोतों को स्कैन करते हैं, ताकि आप कुछ भी मिस न करें।
- श्रम और लागत की बचत: छोटी और मध्यम टीमें भी उतने ही स्रोतों की निगरानी कर सकती हैं जितनी बड़ी कंपनियाँ—बिना इंटर्नों की फ़ौज रखे।
- एनालिटिक्स के लिए संरचित डेटा: असंरचित लेखों में उलझने के बजाय, आपको साफ़-सुथरे, संरचित रिकॉर्ड मिलते हैं जो सर्च, डैशबोर्ड और मशीन लर्निंग के लिए तैयार होते हैं।
- तेज़ और बेहतर निर्णय: रियल-टाइम समाचार डेटा का मतलब है कि आप बाज़ार के बदलाव, PR संकट या उभरते रुझानों पर अपने प्रतिस्पर्धियों से पहले प्रतिक्रिया दे सकते हैं।
PR और कम्युनिकेशंस को ही लें: और जैसे प्लेटफ़ॉर्म रियल-टाइम मीडिया मॉनिटरिंग को प्रतिष्ठा की रक्षा और हानिकारक कवरेज पर तेज़ी से कार्रवाई के लिए अनिवार्य मानते हैं। बिक्री में, रियल-टाइम समाचार अलर्ट प्रॉस्पेक्टिंग के लिए “कॉन्टेक्स्ट कार्ड” बन जाते हैं—जैसे फंडिंग राउंड, कार्यकारी बदलाव या प्रोडक्ट लॉन्च, जो सही समय पर आउटरीच ट्रिगर करते हैं।
अलग-अलग परिस्थितियों के लिए सही समाचार स्क्रैपिंग टूल्स कैसे चुनें
सभी समाचार स्क्रैपिंग टूल्स एक जैसे नहीं होते। सही चुनाव आपके लक्ष्यों, तकनीकी सहजता और आप किस तरह की खबरों में रुचि रखते हैं, इस पर निर्भर करता है। बेहतर फिट चुनने के लिए यह ढाँचा देखें:
उपयोग में आसानी और पहुँच का मूल्यांकन
अधिकांश बिज़नेस यूज़र्स और पत्रकारों के लिए उपयोग में आसानी पर कोई समझौता नहीं किया जा सकता। आपको ऐसा टूल चाहिए जो सीधे काम करे, जिसमें कोडिंग या जटिल सेटअप की ज़रूरत न हो। Thunderbit जैसे नो-कोड और लो-कोड प्लेटफ़ॉर्म, , और आपको विज़ुअली स्क्रैपर बनाने देते हैं—बस पॉइंट करें, क्लिक करें, और डेटा निकालें।
Thunderbit खास तौर पर अपने दो-चरणीय प्रोसेस के लिए अलग दिखता है: आप बताइए क्या चाहिए, AI फ़ील्ड्स सुझा देगा, और फिर “स्क्रैप” दबाइए। गैर-तकनीकी यूज़र भी मिनटों में, घंटों में नहीं, एक समाचार डेटा पाइपलाइन सेट कर सकते हैं।
सुरक्षा और डेटा गोपनीयता पर विचार
जहाँ डेटा बड़ी ताक़त है, वहाँ ज़िम्मेदारी भी उतनी ही बड़ी होती है। समाचार स्क्रैपिंग टूल्स अक्सर संवेदनशील सामग्री तक पहुँचते हैं, इसलिए सुरक्षा और अनुपालन सबसे ऊपर होने चाहिए। इन बातों पर ध्यान दें:
- डेटा एन्क्रिप्शन (ट्रांज़िट में और स्टोरेज में)
- स्पष्ट गोपनीयता नीतियाँ (उदाहरण के लिए, Thunderbit कहता है कि वह यूज़र डेटा नहीं बेचता और सिर्फ़ वही सामग्री एक्सेस करता है जिसे आप स्क्रैप करना चुनते हैं)
- सूक्ष्म परमिशन (खासकर ब्राउज़र एक्सटेंशनों के लिए—हमेशा जाँचें कि टूल किस डेटा तक पहुँच सकता है)
- स्थानीय कानूनों का पालन (GDPR, CCPA, और EU यूज़र्स के लिए )
अतिरिक्त भरोसे के लिए, प्रतिष्ठित विक्रेताओं को चुनें, एक्सटेंशन परमिशन की पुष्टि करें, और केवल उतनी ही पहुँच दें जितनी ज़रूरी हो।
टूल्स को समाचार प्रकारों और उद्योग की ज़रूरतों से मिलाना
कुछ टूल्स खास समाचार डोमेनों में बेहतर काम करते हैं:
- वित्त: और जैसे APIs वित्तीय खबरों के लिए क्लस्टरिंग, सेंटिमेंट और इवेंट डिटेक्शन देते हैं।
- टेक और स्टार्टअप्स: Thunderbit या Octoparse से कस्टम स्क्रैपिंग करके आप विशिष्ट ब्लॉग, प्रेस रिलीज़ या इवेंट लिस्टिंग को टार्गेट कर सकते हैं।
- राजनीति और नीति: और जैसे लाइसेंस प्राप्त डेटाबेस प्रीमियम स्रोतों और आर्काइव्स तक पहुँच देते हैं।
अगर आपको मुख्यधारा, विशिष्ट और अंतरराष्ट्रीय स्रोतों का मिश्रण मॉनिटर करना है—उन स्रोतों सहित जिनके APIs नहीं हैं—तो Thunderbit जैसे लचीले AI-चालित स्क्रैपर्स आपका सबसे अच्छा दाँव हैं।
रियल-टाइम समाचार डेटा एक्सट्रैक्शन के लिए Thunderbit के अनोखे फायदे
अब बात करते हैं कि ऑटोमेटेड समाचार एक्सट्रैक्शन के लिए को एक बेहतरीन विकल्प क्या बनाता है—खासकर तब, जब आप तकनीकी झंझट के बिना रियल-टाइम समाचार डेटा चाहते हों।
Thunderbit एक AI-संचालित वेब स्क्रैपर Chrome एक्सटेंशन है, जिसे बिज़नेस यूज़र्स, पत्रकारों और एनालिस्ट्स के लिए बनाया गया है जिन्हें किसी भी वेबसाइट से ताज़ा, संरचित समाचार सामग्री चाहिए। यही वजह है कि यह मेरा पसंदीदा टूल बन गया है:
- AI सुझावित फ़ील्ड्स: Thunderbit समाचार पेज पढ़ता है और अपने-आप सबसे उपयुक्त कॉलम सुझाता है—हेडलाइन, टाइमस्टैम्प, लेखक, सारांश और भी बहुत कुछ। सेलेक्टर्स या टेम्पलेट्स से जूझने की ज़रूरत नहीं।
- सबपेज स्क्रैपिंग: सिर्फ़ हेडलाइन नहीं, पूरा लेख चाहिए? Thunderbit हर समाचार लिंक पर जा सकता है, बॉडी टेक्स्ट, एंटिटीज़ और टैग्स निकाल सकता है, और सब कुछ एक ही संरचित टेबल में मिला सकता है।
- बल्क एक्सपोर्ट और तुरंत अपडेट: अपने समाचार डेटा को एक क्लिक में Excel, Google Sheets, Airtable या Notion में एक्सपोर्ट करें। लंबी कॉपी-पेस्ट कवायद या CSV झंझट अब नहीं।
- शेड्यूल्ड स्क्रैपिंग: ब्रेकिंग न्यूज़, बाज़ार मॉनिटरिंग या चल रहे शोध के लिए अपने समाचार पाइपलाइन को ताज़ा रखने हेतु आवर्ती जॉब्स (प्रति घंटे, दैनिक या कस्टम अंतराल) सेट करें।
- अनुकूलनशीलता: Thunderbit का AI लेआउट बदलावों और लंबे-पूँछ वाले समाचार साइट्स के अनुसार ढल जाता है, इसलिए आप टूटे हुए स्क्रैपर्स ठीक करने में कम और डेटा का विश्लेषण करने में अधिक समय लगाते हैं।
और 4.8-स्टार रेटिंग के साथ, यह PR मॉनिटरिंग से लेकर प्रतिस्पर्धी इंटेलिजेंस तक हर काम के लिए दुनिया भर की टीमों का भरोसेमंद साथी है।
AI-संचालित फ़ील्ड पहचान और सबपेज स्क्रैपिंग
Thunderbit की सबसे दमदार विशेषताओं में से एक है इसकी AI-संचालित फ़ील्ड पहचान। बस “AI Suggest Fields” पर क्लिक करें, और टूल समाचार पेज को स्कैन करके शीर्षक, तारीख, लेखक और सारांश जैसे मुख्य फ़ील्ड पहचान लेता है। आप कस्टम फ़ील्ड्स को बदल या जोड़ सकते हैं (उदाहरण के लिए, “अगर यह लेख तिमाही नतीजों का ज़िक्र करे तो इसे ‘earnings’ टैग करें”), और बाकी काम Thunderbit का AI संभाल लेता है।
समाचारों के लिए सबपेज स्क्रैपिंग एक गेम-चेंजर है: होमपेज या सेक्शन लिस्टिंग से हेडलाइन स्क्रैप करें, फिर Thunderbit को हर लेख URL पर जाकर पूरी कहानी, एंटिटीज़ और यहाँ तक कि इमेजेज़ निकालने दें। इसका मतलब है कि आपको पूर्ण, समृद्ध समाचार रिकॉर्ड मिलते हैं—सर्च, डैशबोर्ड या डाउनस्ट्रीम AI विश्लेषण के लिए तैयार।
बल्क एक्सपोर्ट और तुरंत अपडेट
Thunderbit समाचार डेटा को एक्सपोर्ट करना बेहद आसान बना देता है। एक क्लिक में आप अपनी संरचित समाचार फ़ीड को Google Sheets, Airtable, Notion में भेज सकते हैं, या CSV/Excel के रूप में डाउनलोड कर सकते हैं। जो टीमें स्प्रेडशीट्स या BI टूल्स पर निर्भर रहती हैं, उनके लिए यह बहुत बड़ा समय-बचत लाभ है।
और क्योंकि Thunderbit शेड्यूल्ड स्क्रैपिंग सपोर्ट करता है, आप इसे हर घंटे, हर दिन या अपनी कस्टम समय-सारणी पर चला सकते हैं—ताकि आपका समाचार डेटा हमेशा अपडेट रहे। अब Google Alerts के दिनों-पुरानी खबरें इंडेक्स करने का इंतज़ार नहीं।
रियल-टाइम समाचार डेटा सॉल्यूशंस में ऑपरेशनल चुनौतियों पर काबू पाना
बेहतरीन टूल्स के बावजूद, रियल-टाइम समाचार एक्सट्रैक्शन अपनी कुछ चुनौतियाँ लाता है। सबसे आम समस्याओं से निपटने का तरीका यहाँ है:
लेटेंसी और डेटा ताज़गी का प्रबंधन
- समाचार की गति के अनुसार स्क्रैप शेड्यूल करें: ब्रेकिंग न्यूज़ के लिए, स्क्रैपर्स को हर 15–30 मिनट पर चलाएँ ( से मेल खाते हुए)। धीमे क्षेत्रों के लिए, रोज़ाना या प्रति घंटा पर्याप्त हो सकता है।
- प्रकाशन और फ़ेच समय के बीच की देरी पर नज़र रखें: यह ट्रैक करें कि लेख कब प्रकाशित हुआ और आपका सिस्टम उसे कब लाया। अगर अंतर बढ़े, तो ब्लॉक या स्लोडाउन की जाँच करें।
- “चुपचाप किए गए संपादन” के लिए दोबारा स्क्रैप करें: समाचार लेख अक्सर प्रकाशित होने के बाद अपडेट होते हैं। सुधारों या चुपके से किए गए संपादनों को पकड़ने के लिए 24 घंटे बाद दूसरा स्क्रैप शेड्यूल करें ()।
API सीमाएँ और स्रोत विविधता को संभालना
- API कोटा का सम्मान करें: अगर आप समाचार APIs का उपयोग करते हैं, तो रेट लिमिट्स पर ध्यान रखें—अनुरोध समय में फैलाएँ, और संभव हो तो परिणाम कैश करें ()।
- डुप्लिकेट हटाएँ और कैनोनिकलाइज़ करें: समाचार कहानियाँ अक्सर कई URLs पर दिखती हैं या अपडेट होती हैं। डुप्लिकेट से बचने के लिए canonical URLs कैप्चर करें और hashes (जैसे शीर्षक + तारीख) का उपयोग करें ()।
- डायनामिक कंटेंट संभालें: infinite scroll या lazy loading वाली साइट्स के लिए ऐसे टूल्स उपयोग करें जो dynamic rendering सपोर्ट करते हों, और लेआउट बदलावों की निगरानी करें ()।
स्मार्ट समाचार डेटा विश्लेषण: AI और मशीन लर्निंग की भूमिका
समाचार निकालना तो सिर्फ़ पहला कदम है। असली मूल्य उस डेटा का विश्लेषण करने और उस पर कार्रवाई करने में है—और यहीं AI और मशीन लर्निंग चमकते हैं।
- एंटिटी एक्सट्रैक्शन: NLP का उपयोग करके हर लेख में उल्लिखित लोगों, संगठनों और स्थानों को निकालें ()।
- विषय वर्गीकरण: लेखों को विषय, भावना या तात्कालिकता के आधार पर अपने-आप टैग करें—ताकि डैशबोर्ड और अलर्ट और भी स्मार्ट बनें ()।
- इवेंट क्लस्टरिंग: अलग-अलग आउटलेट्स पर छपी समान या संबंधित कहानियों को एक समूह में रखें, ताकि आपको बड़ी तस्वीर दिखे (सिर्फ़ लगभग एक जैसी हेडलाइनों की बाढ़ नहीं)।
- व्यक्तिकरण और टार्गेटिंग: ऑडियंस को विभाजित करने, विज्ञापन टार्गेटिंग सुधारने या कंटेंट सुझाने के लिए रियल-टाइम समाचार डेटा का उपयोग करें—जिससे एंगेजमेंट और ROI बढ़े।
उदाहरण के लिए, PR टीमें उभरते संकटों को वायरल होने से पहले पकड़ने के लिए रियल-टाइम समाचार एनालिटिक्स का उपयोग करती हैं, जबकि बिक्री टीमें फंडिंग राउंड या कार्यकारी नियुक्तियों जैसे “ट्रिगर इवेंट्स” से प्रॉस्पेक्ट लिस्ट को समृद्ध करती हैं।
ऑटोमेटेड समाचार एक्सट्रैक्शन के लिए सर्वोत्तम अभ्यास चेकलिस्ट
यहाँ एक त्वरित-उपयोग चेकलिस्ट है, जिससे आपकी समाचार एक्सट्रैक्शन पाइपलाइन सुचारु रूप से चलती रहे:
| सर्वोत्तम अभ्यास | यह क्यों महत्वपूर्ण है | इसे कैसे लागू करें |
|---|---|---|
| बार-बार स्क्रैप शेड्यूल करें | डेटा लैग कम करें, ब्रेकिंग न्यूज़ पकड़ें | अपडेट फ़्रीक्वेंसी को समाचार की गति से मिलाएँ (जैसे तेज़ बीट के लिए हर 15 मिनट) |
| AI-चालित एक्सट्रैक्शन उपयोग करें | लेआउट बदलावों के अनुसार ढलें, सेटअप समय घटाएँ | Thunderbit, Diffbot, Zyte API जैसे टूल्स |
| डुप्लिकेट हटाएँ और कैनोनिकलाइज़ करें | डुप्लिकेट अलर्ट से बचें, साफ़ डेटा सुनिश्चित करें | canonical URLs कैप्चर करें, डुप्लिकेट हटाने के लिए hashes का उपयोग करें |
| एक्सट्रैक्शन गुणवत्ता की निगरानी करें | गायब फ़ील्ड, ड्रिफ्ट या विफलताएँ पकड़ें | पूर्ण रिकॉर्ड प्रतिशत, लैग और त्रुटि दर ट्रैक करें |
| कानूनी/अनुपालन सीमाओं का सम्मान करें | कानूनी जोखिम से बचें, भरोसा बनाए रखें | आधिकारिक APIs/फ़ीड्स को प्राथमिकता दें, शर्तों की समीक्षा करें, व्यक्तिगत डेटा कम से कम रखें |
| संरचित फ़ॉर्मैट्स में एक्सपोर्ट करें | डाउनस्ट्रीम एनालिटिक्स सक्षम करें | CSV, Excel, Sheets, Notion, Airtable |
| संपादनों के लिए दोबारा स्क्रैप शेड्यूल करें | प्रकाशन के बाद हुए बदलाव पकड़ें | 24 घंटे/1 सप्ताह बाद लेखों पर दोबारा जाएँ (GDELT मॉडल) |
| अपनी पाइपलाइन सुरक्षित करें | संवेदनशील डेटा की रक्षा करें | एन्क्रिप्शन, एक्सेस कंट्रोल, प्रतिष्ठित टूल्स |
एक मज़बूत ऑटोमेटेड समाचार एक्सट्रैक्शन वर्कफ़्लो बनाना
क्या आप समाचार डेटा के लिए अपना खुद का “ब्लैक बॉक्स” बनाना चाहते हैं? यहाँ चरण-दर-चरण वर्कफ़्लो है:
- अपने स्रोत पहचानें: जिन समाचार साइट्स, ब्लॉग्स या APIs की आप निगरानी करना चाहते हैं, उनकी सूची बनाएँ।
- एक्सट्रैक्शन सेट करें: फ़ील्ड्स परिभाषित करने के लिए Thunderbit या अपने पसंदीदा टूल का उपयोग करें (AI Suggest Fields इसे बेहद आसान बनाता है)।
- स्क्रैप शेड्यूल करें: समाचार की गति के अनुसार फ़्रीक्वेंसी तय करें—ब्रेकिंग न्यूज़ के लिए प्रति घंटा, धीमे क्षेत्रों के लिए दैनिक।
- सबपेज एन्हांसमेंट: हर हेडलाइन के लिए, पूरे लेख से बॉडी टेक्स्ट, एंटिटीज़ और टैग्स निकालें।
- डुप्लिकेट हटाएँ और सामान्यीकृत करें: canonical URLs कैप्चर करें, रिकॉर्ड्स को hash करें और फ़ील्ड्स को मानकीकृत करें।
- एक्सपोर्ट और इंटीग्रेट करें: विश्लेषण के लिए संरचित डेटा को Excel, Google Sheets, Airtable या Notion में भेजें।
- निगरानी करें और अनुकूलित करें: एक्सट्रैक्शन गुणवत्ता ट्रैक करें, लेआउट बदलावों पर नज़र रखें, और ज़रूरत के अनुसार समायोजन करें।
- अनुपालन बनाए रखें: शर्तों की समीक्षा करें, robots.txt का सम्मान करें, और व्यक्तिगत डेटा को कम से कम रखें।
दृश्य वर्कफ़्लो के लिए, इसे ऐसे सोचें:
स्रोत → एक्सट्रैक्शन (AI फ़ील्ड्स) → सबपेज एन्हांसमेंट → डुप्लिकेशन हटाना → एक्सपोर्ट → विश्लेषण/अलर्ट → निगरानी
निष्कर्ष और मुख्य बातें
ऑटोमेटेड समाचार एक्सट्रैक्शन अब सिर्फ़ “अच्छा हो तो ठीक” वाली चीज़ नहीं रह गई है—यह हर उस व्यक्ति के लिए ज़रूरी है जिसे ऐसी दुनिया में आगे रहना है जहाँ खबरें हर मिनट टूटती और बदलती हैं। सर्वोत्तम अभ्यासों का पालन करके और सही टूल्स का उपयोग करके आप डिजिटल खबरों के फायरहोज़ को कार्रवाई योग्य, संरचित इंटेलिजेंस की एक स्थिर धारा में बदल सकते हैं।
मुख्य बातें:
- ऑनलाइन खबरों का पैमाना और रफ्तार ऑटोमेशन की माँग करती है—मैन्युअल मॉनिटरिंग इसके साथ कदम नहीं मिला सकती।
- ऑटोमेटेड समाचार एक्सट्रैक्शन टूल्स समय बचाते हैं, लागत कम करते हैं, और छोटी टीमों को बड़े संगठनों जैसी कवरेज देने में सक्षम बनाते हैं।
- सही टूल चुनने का मतलब है उपयोग में आसानी, सुरक्षा और अनुकूलनशीलता के बीच संतुलन बनाना—Thunderbit अपनी AI-चालित सरलता और रियल-टाइम एक्सपोर्ट विकल्पों के कारण अलग दिखता है।
- विश्वसनीय, कार्रवाई योग्य समाचार डेटा सुनिश्चित करने के लिए अपने वर्कफ़्लो को ताज़गी, डुप्लिकेशन हटाने, अनुपालन और गुणवत्ता निगरानी के इर्द-गिर्द बनाएँ।
- AI और मशीन लर्निंग और भी बड़ा मूल्य खोलते हैं—स्मार्ट टार्गेटिंग, व्यक्तिकरण और निर्णय लेने को संभव बनाते हैं।
अगर आप अभी भी हेडलाइन कॉपी-पेस्ट कर रहे हैं या Google Alerts के पीछे-पीछे चल रहे हैं, तो अब स्तर ऊपर उठाने का समय है। और देखें कि ऑटोमेटेड समाचार एक्सट्रैक्शन कितना आसान हो सकता है। और टिप्स, वर्कफ़्लो और गहन विश्लेषण के लिए देखें।
अक्सर पूछे जाने वाले प्रश्न
1. ऑटोमेटेड समाचार एक्सट्रैक्शन क्या है, और यह कैसे काम करता है?
ऑटोमेटेड समाचार एक्सट्रैक्शन वह प्रक्रिया है जिसमें सॉफ़्टवेयर का उपयोग करके समाचार लेख इकट्ठा किए जाते हैं और उन्हें विश्लेषण, खोज या अलर्ट के लिए संरचित डेटा (जैसे टेबल या JSON) में बदला जाता है। Thunderbit जैसे टूल्स AI का उपयोग करके मुख्य फ़ील्ड्स (हेडलाइन, टाइमस्टैम्प, लेखक, बॉडी टेक्स्ट) पहचानते हैं और उन्हें वेब पेजों या APIs से अपने-आप निकालते हैं।
2. व्यवसायों के लिए रियल-टाइम समाचार डेटा इतना महत्वपूर्ण क्यों है?
रियल-टाइम समाचार डेटा व्यवसायों को बाज़ार घटनाओं, PR संकटों या प्रतिस्पर्धियों की चालों पर तेज़ी से प्रतिक्रिया देने देता है। चाहे आप बिक्री, PR या शोध में हों, ताज़ा समाचार होने का मतलब है कि आप बेहतर, तेज़ निर्णय ले सकते हैं और प्रतिस्पर्धा से आगे रह सकते हैं।
3. Thunderbit गैर-तकनीकी यूज़र्स के लिए समाचार स्क्रैपिंग को कैसे आसान बनाता है?
Thunderbit एक सरल, दो-चरणीय प्रक्रिया देता है: आप बताइए कि आपको कौन सा डेटा चाहिए, और AI फ़ील्ड्स सुझा देगा। सबपेज स्क्रैपिंग और Excel या Google Sheets में तुरंत एक्सपोर्ट जैसी सुविधाओं के साथ, गैर-तकनीकी यूज़र भी मिनटों में मज़बूत समाचार डेटा पाइपलाइन बना सकते हैं।
4. समाचार स्क्रैपिंग के लिए कानूनी और अनुपालन संबंधी विचार क्या हैं?
हमेशा लक्षित साइट्स की सेवा शर्तों की समीक्षा करें, जहाँ उपलब्ध हों वहाँ आधिकारिक APIs या फ़ीड्स को प्राथमिकता दें, और robots.txt निर्देशों का सम्मान करें। अनुमति के बिना लॉगिन-आवश्यक या पेवॉल्ड सामग्री को स्क्रैप करने से बचें, और गोपनीयता कानूनों का पालन बनाए रखने के लिए व्यक्तिगत डेटा संग्रह को न्यूनतम रखें।
5. मैं यह कैसे सुनिश्चित करूँ कि मेरा समाचार एक्सट्रैक्शन वर्कफ़्लो समय के साथ भरोसेमंद बना रहे?
नियमित स्क्रैप शेड्यूल करें, एक्सट्रैक्शन गुणवत्ता की निगरानी करें, और ऐसे टूल्स का उपयोग करें जो लेआउट बदलावों के अनुसार ढलते हों (जैसे Thunderbit का AI-चालित एक्सट्रैक्शन)। रिकॉर्ड्स से डुप्लिकेट हटाएँ, प्रकाशन और एक्सट्रैक्शन के बीच देरी ट्रैक करें, और विफलताओं या गायब फ़ील्ड्स के लिए अलर्ट सेट करें ताकि आपकी पाइपलाइन स्वस्थ और अपडेटेड रहे।
और जानें