Apollo list queries को ऑप्टिमाइज़ करना सिर्फ़ एक टेक्निकल टास्क नहीं—ये उन सबके लिए एक “must-have skill” है जो रियल-टाइम न्यूज़ डेटा, ऑटोमेटेड न्यूज़ एक्सट्रैक्शन, या तेज़-तर्रार सेल्स/ऑप्स वर्कफ़्लो पर चलते हैं। मैंने खुद देखा है कि एक स्लो list query कैसे एक बढ़िया डैशबोर्ड को पूरा bottleneck बना देती है—सेल्स टीम बस loader घूमता हुआ देखती रह जाती है, और ऑप्स टीम स्प्रेडशीट में जुगाड़ ढूँढने लगती है। और जब , तो हर मिलीसेकंड सच में मायने रखता है।

तो Apollo Client की list queries को बिजली जैसी तेज़, भरोसेमंद और स्केलेबल कैसे बनाओ—खासकर जब तुम न्यूज़ स्क्रैप कर रहे हो, लीड्स ट्रैक कर रहे हो, या कोई mission-critical डैशबोर्ड चला रहे हो? इस गाइड में मैं वो best practices आसान भाषा में खोलकर बताऊँगा जो मैंने सीखी हैं (और कुछ तो “ट्रायल-बाय-फायर” से सीखी हैं)—query design से लेकर caching, pagination, और यहाँ तक कि जैसे no-code टूल्स जोड़कर न्यूज़ एक्सट्रैक्शन का भारी काम ऑटोमेट करने तक। तुम developer हो, product manager हो, या वो इंसान जिस पर “डैशबोर्ड स्लो है” का इल्ज़ाम आता है—ये तुम्हारा Apollo GraphQL list performance playbook है।
Apollo List Queries को ऑप्टिमाइज़ क्यों करें? (apollo client list performance, optimize apollo list queries)
सीधी बात: कोई भी न्यूज़ हेडलाइन्स या सेल्स लीड्स के लोड होने का इंतज़ार नहीं करना चाहता। बिज़नेस सेटअप में—खासकर जहाँ या रियल-टाइम डेटा पर काम होता है—धीमी Apollo list queries सिर्फ़ irritate नहीं करतीं; ये पैसे जलाती हैं, फैसले लेट कराती हैं, और लोगों को वापस मैनुअल काम की तरफ धकेल देती हैं। के हिसाब से desk workers अपने दिन का लगभग एक-तिहाई हिस्सा low-value tasks में लगा देते हैं—अक्सर इसलिए क्योंकि टूल्स स्लो होते हैं या बिखरे हुए होते हैं।
जब list queries ऑप्टिमाइज़ नहीं होतीं, तो आमतौर पर ये होता है:
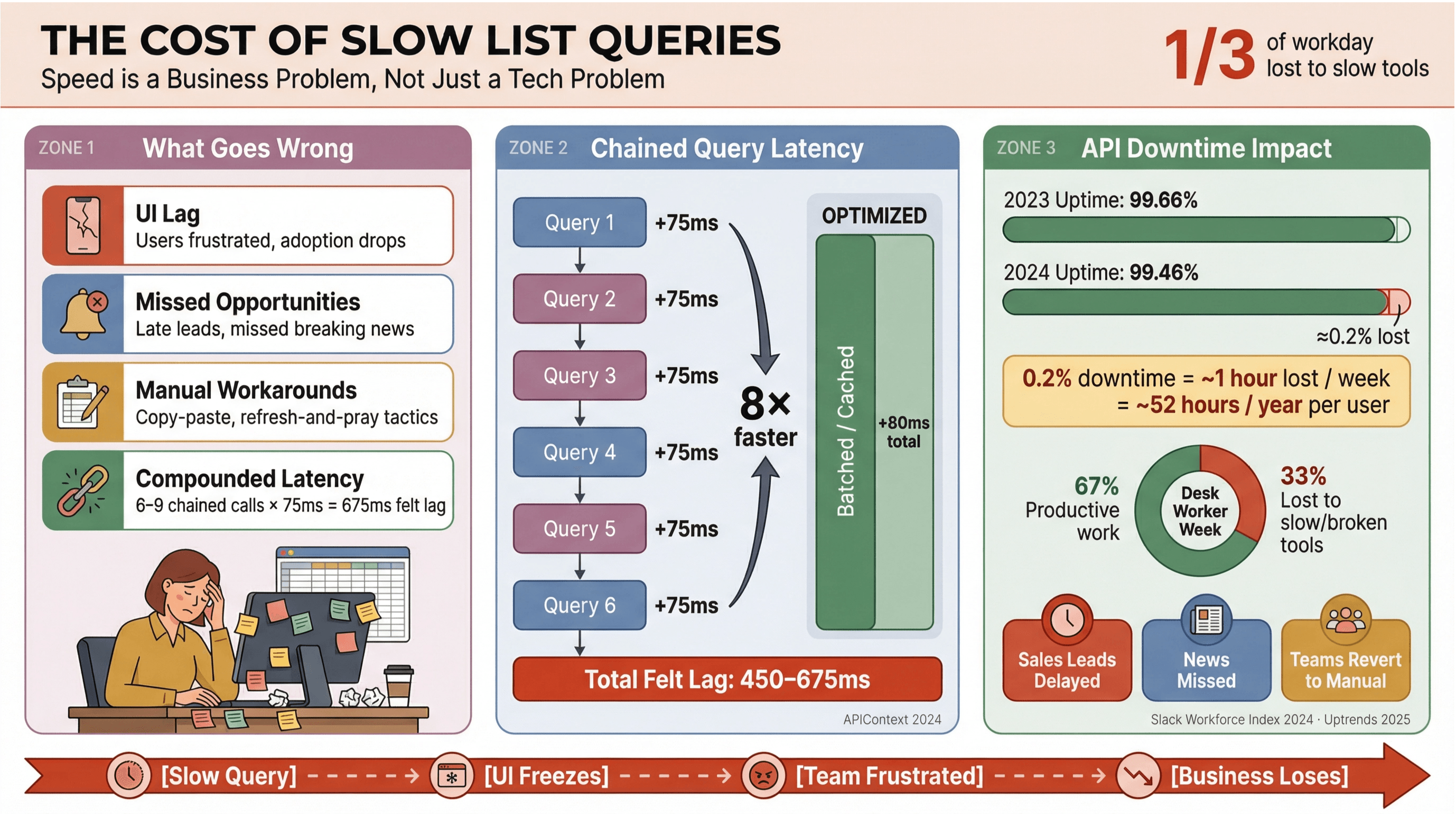
- UI Lag: यूज़र को देरी साफ़ महसूस होती है, झुंझलाहट बढ़ती है और adoption गिरता है।
- Missed Opportunities: सेल्स या न्यूज़ मॉनिटरिंग में कुछ सेकंड की देरी भी hot lead या breaking news मिस करा सकती है।
- Manual Workarounds: टीम फिर से copy-paste, spreadsheets, या “refresh करो और दुआ करो” वाली तरकीबों पर लौट आती है।
- Compounded Latency: हर स्लो API call जुड़ता जाता है—अगर तुम्हारा वर्कफ़्लो 6–9 dependent queries ट्रिगर करता है, तो प्रति call 75ms की छोटी देरी भी 450–675ms की “felt” lag बन सकती है ()।
और ये सिर्फ़ speed की कहानी नहीं है। : औसत uptime एक साल में 99.66% से 99.46% तक गिरा है—मतलब list-heavy apps के लिए हफ्ते में लगभग एक घंटे की productivity loss हो सकती है। जब तुम्हारा बिज़नेस रियल-टाइम न्यूज़ डेटा पर टिका हो, तो ये रिस्क लेना भारी पड़ सकता है।
सही Data Structure और Fields चुनना (apollo graphql list best practices)
सबसे कॉमन गलती जो मैं देखता हूँ (और हाँ, मैंने भी की है) वो ये कि हर list query को detail query की तरह ट्रीट कर दिया जाता है। GraphQL में तुम उतना ही डेटा मँगवा सकते हो जितना चाहिए—तो उसी का फायदा उठाओ। Overfetching performance का सबसे बड़ा दुश्मन है, खासकर न्यूज़ स्क्रैपिंग टूल्स और रियल-टाइम डैशबोर्ड में।
ऑटोमेटेड न्यूज़ एक्सट्रैक्शन के लिए Fields को सही ढंग से चुनें
मान लो तुम एक news feed बना रहे हो। क्या list query में तुम्हें पूरा article body, सारे tags, comments, और author bios चाहिए? ज़्यादातर केस में नहीं। फर्क देखो:
Efficient List Query:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Inefficient List Query (ऐसा मत करना):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}पहली query हल्की-फुल्की और फुर्तीली है—ranking, filtering और rows render करने के लिए एकदम सही। दूसरी query? असल में detail query ही है, बस list के कपड़ों में छुपी हुई—payload भारी हो जाता है और सब कुछ सुस्त पड़ जाता है (, )।
Pro tip: two-tier approach अपनाओ—list में सिर्फ़ lightweight fields लाओ, और heavy details (जैसे full text या NLP enrichment) तभी लोड करो जब यूज़र item खोले या hover करे।
तेज़ Queries के लिए Apollo Client Cache का इस्तेमाल (apollo client list performance)
Apollo Client का cache तुम्हारी list queries को snappy बनाने का सबसे बड़ा हथियार है। सही तरीके से सेटअप हो जाए, तो ये मदद करता है:
- बार-बार चलने वाली queries को तुरंत दिखाने में (network round-trip के बिना)
- server load और API cost घटाने में
- back/forward navigation और filter changes को smooth बनाने में
लेकिन caching कोई जादू की छड़ी नहीं—थोड़ा setup और discipline चाहिए।
प्रभावी Cache Policies सेट करना
Apollo कई तरह की सपोर्ट करता है:
| Policy | यह क्या करता है | News Lists के लिए सबसे अच्छा उपयोग |
|---|---|---|
| cache-first | cache से पढ़ता है, न मिले तो network से लाता है | lists दोबारा खोलना, filters बदलना, back/forward navigation |
| network-only | हर बार network से ही fetch करता है | manual refresh, “latest headlines” |
| cache-and-network | पहले cache दिखाता है, फिर network response से अपडेट करता है | तेज़ initial paint + background update (news feeds के लिए बढ़िया) |
| no-cache | fetch तो करता है, लेकिन cache में स्टोर नहीं करता | one-off sensitive queries (lists में कम ही) |
रियल-टाइम न्यूज़ डेटा के लिए मुझे cache-and-network सबसे बढ़िया लगता है—यूज़र को तुरंत रिज़ल्ट दिखते हैं और बैकग्राउंड में अपडेट भी हो जाता है। बस ध्यान रहे: refresh पर अगर data reorder हो जाए तो UI flicker हो सकता है ()।
Cache configuration tips:
- normalization के लिए stable IDs (
idया_id) यूज़ करो ()। - बड़ी lists के लिए cache size और garbage collection ट्यून करो ()।
ROOT_QUERYके नीचे बड़े unnormalized blobs स्टोर करने से बचो—ऐसा करने पर app अटक सकता है ()।
Pagination लागू करें और Item Count सीमित रखें (apollo graphql list best practices)
अगर तुम एक साथ सैकड़ों/हज़ारों न्यूज़ articles या सेल्स leads लोड कर रहे हो, तो दिक्कत पक्की है। Pagination सिर्फ़ UX फीचर नहीं—ये performance की ज़रूरत है।
Apollo और दोनों pagination सपोर्ट करता है। तुलना देखो:
| Pagination Type | फायदे | नुकसान | किसके लिए बेहतर |
|---|---|---|---|
| Offset-based | सरल, implement करना आसान | data बदलने पर items skip/duplicate हो सकते हैं | स्थिर या छोटी lists |
| Cursor-based | स्थिर, data changes को बेहतर संभालता है | थोड़ा अधिक complex | news feeds, बड़ी lists |
अधिकांश रियल-टाइम न्यूज़ या lead lists के लिए cursor-based pagination सबसे सही बैठता है। नए items आने या पुराने delete होने पर भी consistency बनी रहती है ()।
Apollo pagination tips:
- paginated fields के cache keys कंट्रोल करने के लिए
keyArgsसेट करो ()। - cache में pages जोड़ने के लिए
mergefunction implement करो। fetchMoreका इस्तेमाल करो ताकि नई pages लोड हों और पुराने results overwrite न हों।
News Scraping Tools के लिए Practical Pagination Patterns
एक typical news scraping UI आमतौर पर:
- latest 20–50 headlines दिखाता है (सिर्फ़ lean fields)
- scroll या “next page” पर और लोड करता है
- details तभी fetch करता है जब सच में ज़रूरत हो
इससे UI तेज़ रहता है, API पर दबाव कम होता है, और यूज़र का काम बिना रुके चलता रहता है।
ऑटोमेटेड न्यूज़ एक्सट्रैक्शन के लिए Thunderbit को इंटीग्रेट करना
अब असली सवाल: ये structured news data आता कहाँ से है? यहीं काम आता है।
Thunderbit एक no-code AI web scraper Chrome Extension है, जो लगभग किसी भी वेबसाइट से news headlines, URLs, sources, authors, publication dates, summaries और images निकाल सकता है—बिना कोड लिखे। मैंने टीमों को Thunderbit से पूरा news extraction process ऑटोमेट करते देखा है: unstructured web pages को साफ़, structured data में बदलकर सीधे database या GraphQL API में feed कर देते हैं।
Real-Time News Data के लिए Thunderbit + Apollo का कॉम्बिनेशन
सेल्स और ऑप्स टीमों के लिए एक वर्कफ़्लो जो मुझे बहुत काम का लगता है:
- Extraction Layer: Thunderbit के से target sites से scheduled तरीके से structured news data निकालो।
- Storage Layer: scraped data को ऐसे database में रखो जो fast retrieval के लिए optimized हो।
- GraphQL Layer: API में
newsFeedlist field औरnewsArticle(id)detail field expose करो। - Client Layer: Apollo Client से list (lean fields + pagination) fetch करो, और details सिर्फ़ जरूरत पर।
ये “scrape → store → query” pipeline सुनिश्चित करता है कि Apollo queries हमेशा fresh, structured data पर चलें—बिना manual copy-paste या fragile scripts के।
Bonus: Thunderbit अपने AI-powered field suggestions से sentiment या category जैसे extra fields जोड़कर तुम्हारी lists को और richer बना सकता है—जिससे news feed और स्मार्ट लगने लगता है।
Step-by-Step Guide: Apollo List Queries को ऑप्टिमाइज़ करना
अब इसे लागू करने का टाइम है। Apollo list query optimization के लिए मेरी go-to checklist:
-
Queries को Slim करें
- list render करने के लिए जितने fields चाहिए, उतने ही माँगो (title, URL, timestamp आदि)।
- heavy fields (full text, images, enrichment) को detail queries में शिफ्ट करो।
-
Pagination लागू करें
- बड़ी या dynamic lists के लिए cursor-based pagination अपनाओ।
- cache correctness के लिए
keyArgsऔरmergefunctions कॉन्फ़िगर करो।
-
Apollo Cache का फायदा उठाएँ
- stable IDs के साथ entities normalize करो।
- सही fetch policy चुनो (news के लिए
cache-and-networkबढ़िया है)। - data volume के हिसाब से cache size और garbage collection ट्यून करो।
-
Automated Extraction जोड़ें
- Thunderbit से news scraping ऑटोमेट करो और डेटा हमेशा fresh रखो।
- structured data को सीधे database या spreadsheet में export करो।
-
Monitor और Troubleshoot करें
- queries, cache और performance देखने के लिए इस्तेमाल करो।
- बड़े cache writes, जरूरत से ज्यादा watched queries, और UI stutter पर नज़र रखो।
- p95/p99 latency और error rates ट्रैक करो (, )।
Query Performance की Monitoring और Troubleshooting
Apollo Devtools यहाँ सच में बहुत काम आते हैं। तुम:
- active queries और cache state inspect कर सकते हो
- duplicate queries या excessive watchers पकड़ सकते हो
- बड़े cache blobs या normalization issues पहचान सकते हो
अगर UI lag या slow updates दिखें, तो चेक करो:
- list queries जरूरत से ज्यादा भारी तो नहीं (slim करो)
- cache normalization कमजोर तो नहीं (IDs ठीक करो)
- pagination merge issues तो नहीं (अपने
keyArgsऔरmergeaudit करो)
और सिर्फ़ average नहीं—tail latency भी मापो। असली user pain अक्सर वहीं छुपा होता है।
Traditional बनाम AI-Driven News Scraping Approaches की तुलना
सच बताऊँ तो पहले news scraping का मतलब था custom scripts लिखना, headless browsers संभालना, और उम्मीद करना कि साइट का layout रातों-रात न बदल जाए। अब Thunderbit जैसे AI-driven टूल्स के साथ तुम पूरा प्रोसेस ऑटोमेट कर सकते हो—no code, no drama।
| Approach | ताकत | Business Users के लिए सीमाएँ |
|---|---|---|
| Scripted scraping | पूरी तरह customizable, scale पर सस्ता | high maintenance, engineering time चाहिए |
| Managed scraping platforms | जल्दी शुरू, anti-bot handling आउटसोर्स | फिर भी config चाहिए, usage बढ़ने पर cost बढ़ती |
| AI-driven extraction (Thunderbit) | messy layouts संभालता है, no-code | output की QA चाहिए, schema integration जरूरी |
| No-code visual scrapers | non-engineers के लिए आसान | UI changes पर टूट सकता है, scale सीमित |
| Proxy/unlocker infra | blocks bypass, high throughput सपोर्ट | extraction logic फिर भी चाहिए, compliance risks |
Legal note: public data scraping आम तौर पर legal माना जाता है, लेकिन terms of service और rate limits का सम्मान करना ज़रूरी है ()।
Apollo GraphQL List Best Practices: मुख्य बातें
चलो essentials फिर से समेट लेते हैं:
- Speed और clarity के लिए optimize करो: list queries slim रखो, pagination लगाओ, और caching का सही इस्तेमाल करो।
- Structure मायने रखता है: जितना चाहिए उतना ही fetch करो—heavy fields को detail queries में रखो।
- Cache तुम्हारा दोस्त है: Apollo normalization और fetch policies से data तुरंत serve करो।
- Extraction ऑटोमेट करो: जैसे टूल्स news scraping और list enrichment को सबके लिए आसान बनाते हैं।
- Monitor और iterate करो: Devtools और observability dashboards से bottlenecks जल्दी पकड़ो।
सेल्स, ऑप्स और न्यूज़ टीमों के लिए मतलब साफ़ है: कम इंतज़ार, ज़्यादा action—और “ये इतना slow क्यों है?” वाले Slack messages भी कम।
निष्कर्ष: Apollo List Queries को ऑप्टिमाइज़ करने के अगले कदम
अगर तुम अभी भी heavy, unpaginated, या cache-unfriendly list queries चला रहे हो, तो अब audit और upgrade करने का सही वक्त है। छोटे कदमों से शुरू करो: fields trim करो, pagination जोड़ो, और cache ट्यून करो। फिर next level पर जाओ— जैसे automated extraction tools जोड़कर डेटा को हमेशा fresh और actionable बनाए रखो।
और deep dive चाहिए? , देखो, या real-world tips के लिए जॉइन करो। और अगर तुम news extraction ऑटोमेट करना चाहते हो, तो Thunderbit का ज़रूर ट्राय करो—रियल-टाइम डेटा चाहिए और सिरदर्द नहीं, तो ये सच में game-changer है।
Happy querying—और तुम्हारी lists हमेशा कॉफी ठंडी होने से पहले लोड हो जाएँ।
FAQs
1. रियल-टाइम न्यूज़ या सेल्स डैशबोर्ड में Apollo list queries धीमी क्यों हो जाती हैं?
जब queries जरूरत से ज्यादा डेटा fetch करती हैं, pagination नहीं होता, या caching सही से सेट नहीं होती, तो list queries स्लो हो जाती हैं। न्यूज़ मॉनिटरिंग जैसे high-frequency वर्कफ़्लो में छोटी देरी भी जुड़कर UI lag और productivity loss बन जाती है।
2. ऑटोमेटेड न्यूज़ एक्सट्रैक्शन के लिए Apollo list queries को कैसे structure करना सबसे अच्छा है?
list render करने के लिए जरूरी fields ही माँगो (जैसे title, URL, timestamp)। heavy fields (जैसे पूरा article text या images) को detail queries में रखो, और results को paginate करो ताकि payload छोटा रहे और speed बनी रहे।
3. Apollo Client का cache list performance कैसे बेहतर बनाता है?
Apollo cache पहले से fetch किए गए डेटा को स्टोर करता है, जिससे repeated queries पर तुरंत response मिल सकता है। सही normalization और fetch policies (जैसे cache-and-network) list views को काफी तेज़ कर देती हैं और server load भी घटाती हैं।
4. Thunderbit न्यूज़ scraping और Apollo integration में कैसे मदद करता है?
Thunderbit एक no-code AI web scraper है जो किसी भी वेबसाइट से structured news data निकाल सकता है। तुम इससे news extraction ऑटोमेट कर सकते हो और फिर उस डेटा को database या GraphQL API में feed करके Apollo Client के साथ इस्तेमाल कर सकते हो।
5. Apollo list query performance को monitor और troubleshoot करने के लिए कौन से tools उपयोगी हैं?
से तुम real time में queries, cache state और performance inspect कर सकते हो। इसे New Relic या Uptrends जैसे observability dashboards के साथ जोड़कर latency और error rates ट्रैक करो, और बेहतर results के लिए query design को iterate करते रहो।
web scraping, automation और real-time data workflows पर और tips चाहिए? deep dives, tutorials और AI-powered productivity के नए अपडेट्स के लिए देखो।
और जानें