
वेब डेटा हर दिन 폭발적으로 बढ़ रहा है—और उसके साथ उसे मैनेज करने का प्रेशर भी। मैंने खुद देखा है कि सेल्स और ऑपरेशंस टीमें असल फैसले लेने के बजाय स्प्रेडशीट्स “ठीक-ठाक” करने और वेबसाइटों से कॉपी‑पेस्ट में ही घंटों खपा देती हैं। Salesforce के मुताबिक, सेल्स रिप्स अब अपना लगा रहे हैं, और Asana बताता है कि । मतलब मैन्युअल डेटा कलेक्शन में ढेरों घंटे स्वाहा—वही घंटे डील क्लोज़ करने या कैंपेन लॉन्च करने में लग सकते थे।
पर अच्छी खबर ये है: web scraping अब पूरी तरह मेनस्ट्रीम हो चुका है, और इसकी पावर यूज़ करने के लिए तुम्हें डेवलपर होना ज़रूरी नहीं। Ruby लंबे समय से वेब डेटा एक्सट्रैक्शन ऑटोमेट करने के लिए पसंदीदा भाषा रही है, लेकिन जब तुम इसे जैसे मॉडर्न AI web scrapers के साथ जोड़ते हो, तो दोनों दुनिया का बेस्ट मिल जाता है—कोडर्स के लिए flexibility, और बाकी सबके लिए नो‑कोड सादगी। तुम मार्केटर हो, ईकॉमर्स मैनेजर हो, या बस अंतहीन कॉपी‑पेस्ट से तंग—यह गाइड तुम्हें Ruby और AI के साथ web scraping में प्रो बनना सिखाएगी—वो भी बिना कोड लिखे।
Ruby के साथ Web Scraping क्या है? ऑटोमेटेड डेटा की ओर आपका प्रवेश द्वार
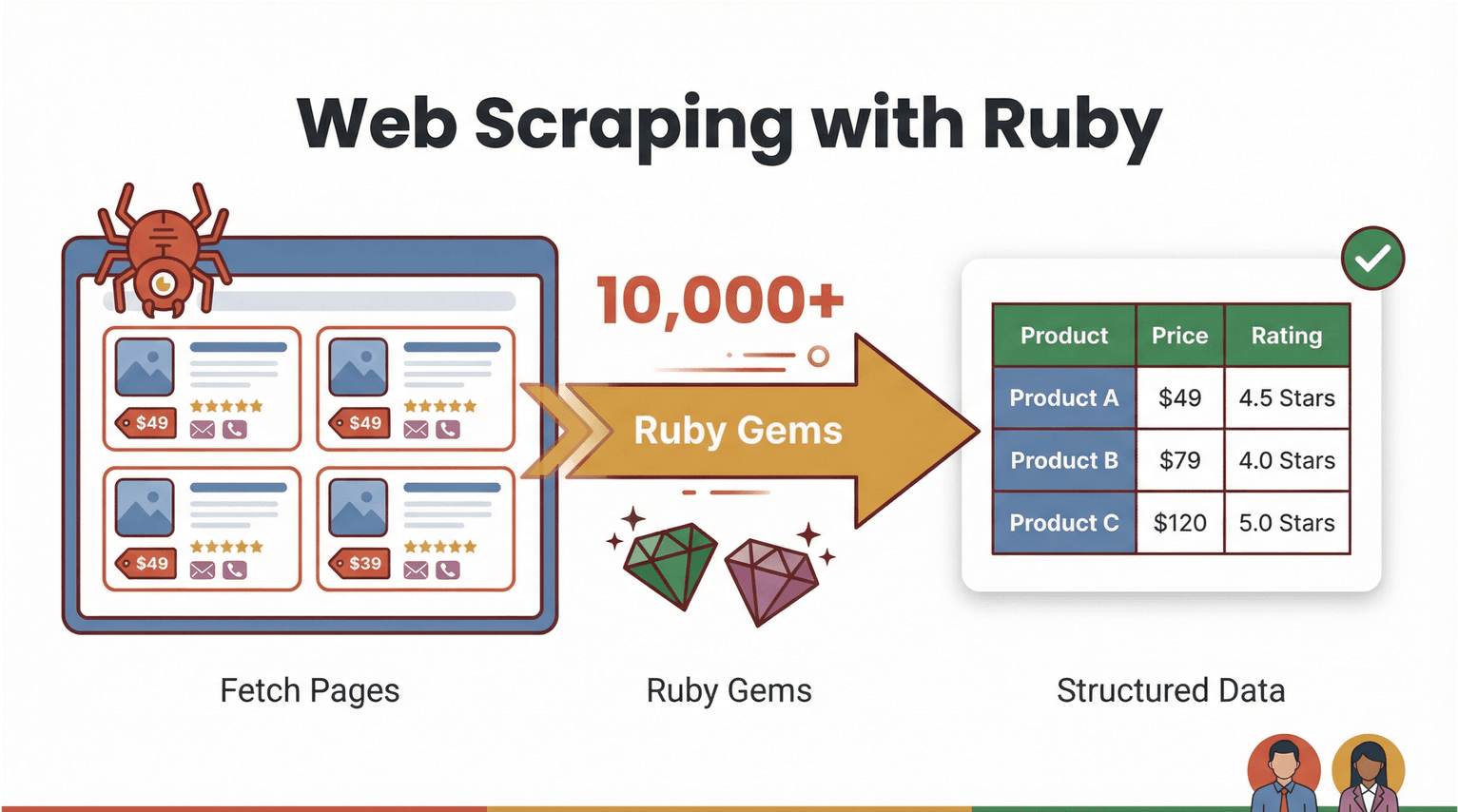
चलो पहले बेसिक्स क्लियर करें। Web scraping का मतलब है सॉफ्टवेयर की मदद से वेब पेज को लाना और उसमें से खास जानकारी—जैसे प्रोडक्ट प्राइस, कॉन्टैक्ट डिटेल्स, या रिव्यू—निकालकर उसे एक स्ट्रक्चर्ड फॉर्मेट (जैसे CSV या Excel) में बदल देना। ruby के साथ web scraping पावरफुल भी है और सीखने में भी फ्रेंडली। Ruby अपनी पढ़ने‑लायक सिंटैक्स और “gems” (लाइब्रेरीज़) के बड़े इकोसिस्टम के लिए जानी जाती है, जो ऑटोमेशन को काफी आसान बना देता है ().
तो “ruby के साथ web scraping” असल में दिखता कैसा है? मान लो तुम्हें किसी ईकॉमर्स साइट से सारे प्रोडक्ट नाम और कीमतें निकालनी हैं। Ruby में तुम एक स्क्रिप्ट लिख सकते हो जो:
- वेब पेज डाउनलोड करे (जैसे जैसी लाइब्रेरी से)
- HTML पार्स करके ज़रूरी डेटा ढूंढे (जैसे से)
- उसे स्प्रेडशीट या डेटाबेस में एक्सपोर्ट कर दे
लेकिन असली गेम‑चेंजर ये है: हर बार कोड लिखना ज़रूरी नहीं। AI‑पावर्ड, no code web scraper जैसे अब भारी काम खुद संभाल लेते हैं—वेब पेज पढ़ना, फील्ड्स पहचानना, और बस कुछ क्लिक में साफ‑सुथरी डेटा टेबल एक्सपोर्ट करना। Ruby कस्टम वर्कफ़्लोज़ के लिए अब भी शानदार “automation glue” है, लेकिन AI web scrapers बिज़नेस यूज़र्स के लिए दरवाज़ा और भी चौड़ा कर रहे हैं।
बिज़नेस टीमों के लिए Ruby के साथ Web Scraping क्यों मायने रखता है

सच बताऊँ तो कोई भी दिनभर डेटा कॉपी‑पेस्ट में नहीं फँसना चाहता। ऑटोमेटेड वेब डेटा एक्सट्रैक्शन की डिमांड तेज़ी से बढ़ रही है—और वजह भी एकदम साफ है। Ruby (और AI टूल्स) के साथ web scraping बिज़नेस ऑपरेशंस को इस तरह बदल रहा है:
- Lead Generation: डायरेक्टरीज़ या LinkedIn से कॉन्टैक्ट जानकारी झटपट निकालकर सेल्स पाइपलाइन तैयार करो।
- Competitor Price Monitoring: सैकड़ों ईकॉमर्स SKUs पर प्राइस बदलाव ट्रैक करो—मैन्युअल चेकिंग को bye-bye।
- Product Catalog Building: अपने स्टोर/मार्केटप्लेस के लिए प्रोडक्ट डिटेल्स और इमेजेज़ एक जगह समेटो।
- Market Research: ट्रेंड एनालिसिस के लिए रिव्यू, रेटिंग्स या न्यूज़ आर्टिकल्स कलेक्ट करो।
ROI एकदम साफ है: जो टीमें वेब डेटा कलेक्शन ऑटोमेट करती हैं, वे हर हफ्ते कई घंटे बचाती हैं, गलतियाँ घटाती हैं, और ज़्यादा ताज़ा व भरोसेमंद डेटा पाती हैं। मैन्युफैक्चरिंग में, उदाहरण के लिए, , जबकि सिर्फ दो साल में डेटा वॉल्यूम दोगुना हो चुका है। ऑटोमेशन के लिए यह बड़ा मौका है।
यहाँ एक त्वरित सारांश है कि Ruby और AI टूल्स के साथ web scraping कैसे वैल्यू देता है:
| Use Case | Manual Pain Point | Benefit of Automation | Typical Outcome |
|---|---|---|---|
| Lead Generation | Copying emails one by one | Scrape thousands in minutes | 10x more leads, less grunt work |
| Price Monitoring | Daily site checks | Scheduled, automated price pulls | Real-time pricing intelligence |
| Catalog Building | Manual data entry | Bulk extraction & formatting | Faster launches, fewer errors |
| Market Research | Reading reviews by hand | Scrape and analyze at scale | Deeper, fresher insights |
और ये सिर्फ स्पीड की बात नहीं—ऑटोमेशन का मतलब है कम गलतियाँ और ज़्यादा कंसिस्टेंट डेटा, जो तब बेहद जरूरी हो जाता है जब ।
Web Scraping के विकल्प: Ruby Scripts बनाम AI Web Scraper टूल्स
तो फिर—तुम अपनी Ruby स्क्रिप्ट लिखोगे या AI‑पावर्ड, no code web scraper यूज़ करोगे? चलो दोनों ऑप्शन्स को ठीक से समझते हैं।
Ruby Scripting: पूरा कंट्रोल, लेकिन मेंटेनेंस ज़्यादा
Ruby के इकोसिस्टम में लगभग हर scraping जरूरत के लिए gems मिल जाते हैं:
- : HTML और XML पार्स करने के लिए सबसे पॉपुलर।
- : वेब पेज और APIs फेच करने के लिए।
- : cookies, forms और navigation वाले साइट्स के लिए।
- / : असली ब्राउज़र ऑटोमेशन के लिए (JavaScript‑heavy साइट्स पर बढ़िया)।
Ruby scripts के साथ तुम्हें पूरी आज़ादी मिलती है—कस्टम लॉजिक, डेटा क्लीनिंग, और अपने सिस्टम्स के साथ इंटीग्रेशन। लेकिन मेंटेनेंस भी तुम्हारी जिम्मेदारी है: वेबसाइट का लेआउट बदला तो स्क्रिप्ट टूट सकती है। और अगर कोडिंग में कम्फर्टेबल नहीं हो, तो सीखने में टाइम लगेगा।
AI Web Scrapers और No-Code टूल्स: तेज़, आसान, और बदलावों के साथ एडैप्टिव
जैसे मॉडर्न no code web scraper पूरा तरीका ही बदल देते हैं। कोड लिखने के बजाय तुम:
- Chrome extension खोलते हो
- “AI Suggest Fields” पर क्लिक करके AI को तय करने देते हो कि क्या निकालना है
- “Scrape” दबाते हो और डेटा एक्सपोर्ट कर लेते हो
Thunderbit का AI बदलते वेब लेआउट के साथ एडैप्ट करता है, subpages (जैसे प्रोडक्ट डिटेल पेज) संभालता है, और Excel, Google Sheets, Airtable, या Notion में सीधे एक्सपोर्ट करता है। बिज़नेस यूज़र्स के लिए यह बिना झंझट के रिज़ल्ट देता है।
यह रहा एक साइड‑बाय‑साइड कंपैरिजन:
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Ruby Scripting | Full control, custom logic, flexible | Steeper learning curve, maintenance | Developers, advanced users |
| AI Web Scraper | No-code, fast setup, adapts to changes | Less granular control, some limits | Business users, ops teams |
ट्रेंड साफ है: जैसे‑जैसे वेबसाइटें ज्यादा कॉम्प्लेक्स (और डिफेंसिव) हो रही हैं, AI web scrapers ज़्यादातर बिज़नेस वर्कफ़्लोज़ के लिए पसंदीदा विकल्प बनते जा रहे हैं।
शुरुआत करें: Ruby Web Scraping Environment सेटअप करना
अगर तुम Ruby scripting ट्राय करना चाहते हो, तो पहले environment सेट कर लेते हैं। अच्छी बात ये है कि Ruby इंस्टॉल करना आसान है और Windows, macOS, और Linux—तीनों पर चलता है।
Step 1: Ruby इंस्टॉल करें
- Windows: डाउनलोड करो और निर्देशों के अनुसार इंस्टॉल करो। Nokogiri जैसे gems के लिए native extensions बनाने हेतु MSYS2 शामिल करना मत भूलना।
- macOS/Linux: version management के लिए इस्तेमाल करो। Terminal में:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(लेटेस्ट stable version के लिए देख लो।)
Step 2: Bundler और जरूरी Gems इंस्टॉल करें
Bundler dependencies मैनेज करने में मदद करता है:
1gem install bundlerअपने प्रोजेक्ट के लिए Gemfile बनाओ:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'फिर चलाओ:
1bundle installइससे तुम्हारा environment कंसिस्टेंट रहता है और scraping के लिए रेडी हो जाता है।
Step 3: सेटअप टेस्ट करें
IRB (Ruby का interactive shell) में ये ट्राय करो:
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONअगर version number दिख जाए, तो सब सेट है।
Step-by-Step: अपना पहला Ruby Web Scraper बनाइए
अब एक रियल उदाहरण देखते हैं— से प्रोडक्ट डेटा निकालना। ये साइट scraping प्रैक्टिस के लिए ही बनाई गई है।
यहाँ एक सिंपल Ruby स्क्रिप्ट है जो book titles, prices, और stock status निकालती है:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#{BASE_URL}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #{rows.length} rows to books.csv"ये स्क्रिप्ट हर पेज फेच करती है, HTML पार्स करती है, डेटा निकालती है, और CSV में लिख देती है। तुम books.csv को Excel या Google Sheets में खोल सकते हो।
Common pitfalls:
- अगर missing gems की errors आएँ, तो Gemfile चेक करो और
bundle installचलाओ। - जिन साइट्स में डेटा JavaScript से लोड होता है, वहाँ Selenium या Watir जैसे browser automation टूल की जरूरत पड़ेगी।
Thunderbit के साथ Ruby Scraping को और पावरफुल बनाइए: AI Web Scraper का इस्तेमाल
अब देखते हैं कि तुम्हारे scraping को कैसे नेक्स्ट लेवल पर ले जा सकता है—बिना कोड के।
Thunderbit एक है, जो सिर्फ दो क्लिक में किसी भी वेबसाइट से structured data निकाल देता है। तरीका ये है:
- जिस पेज से डेटा चाहिए, वहाँ Thunderbit extension खोलो।
- “AI Suggest Fields” पर क्लिक करो। Thunderbit का AI पेज स्कैन करके सबसे अच्छे कॉलम सुझाता है (जैसे “Product Name,” “Price,” “Stock”).
- “Scrape” पर क्लिक करो। Thunderbit डेटा निकालता है, pagination संभालता है, और जरूरत हो तो subpages भी फॉलो करता है।
- डेटा एक्सपोर्ट करो—सीधे Excel, Google Sheets, Airtable, या Notion में।
Thunderbit की खास बात ये है कि ये कॉम्प्लेक्स और डायनेमिक वेब पेज भी संभाल लेता है—ना brittle selectors, ना कोड। और अगर तुम वर्कफ़्लो मिक्स करना चाहो, तो Thunderbit से डेटा निकालकर Ruby स्क्रिप्ट से आगे प्रोसेस/एनरिच भी कर सकते हो।
Pro tip: ईकॉमर्स और रियल एस्टेट टीमों के लिए Thunderbit का subpage scraping फीचर बहुत काम का है। पहले प्रोडक्ट लिंक की लिस्ट स्क्रैप करो, फिर Thunderbit को हर लिंक पर जाकर specs, images, या reviews निकालने दो—अपने आप dataset और rich हो जाएगा।
रियल-वर्ल्ड उदाहरण: Ruby और Thunderbit से Ecommerce प्रोडक्ट व प्राइस डेटा स्क्रैप करना
अब इसे एक प्रैक्टिकल वर्कफ़्लो में जोड़ते हैं—खासकर ईकॉमर्स टीमों के लिए।
Scenario: तुम्हें सैकड़ों SKUs पर competitor prices और product details मॉनिटर करनी हैं।
Step 1: Thunderbit से Main Product List स्क्रैप करो
- competitor की product listing page खोलो।
- Thunderbit लॉन्च करो, “AI Suggest Fields” क्लिक करो (जैसे Product Name, Price, URL)।
- “Scrape” करो और CSV में एक्सपोर्ट कर दो।
Step 2: Subpage Scraping से डेटा एनरिच करो
- Thunderbit में “Scrape Subpages” फीचर से हर प्रोडक्ट के detail page पर जाओ और extra फील्ड्स निकालो (जैसे description, stock, images)।
- enriched table एक्सपोर्ट कर लो।
Step 3: Ruby से प्रोसेस/एनालिसिस करो
- Ruby स्क्रिप्ट से डेटा को और साफ करो, ट्रांसफॉर्म करो, या एनालाइज़ करो। जैसे:
- prices को standard currency में कन्वर्ट करना
- out-of-stock items हटाना
- summary statistics बनाना
यहाँ in-stock products फ़िल्टर करने का एक सिंपल Ruby snippet है:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endResult:
तुम raw web pages से सीधे एक साफ, actionable data table तक पहुँच जाते हो—जो pricing analysis, inventory planning, या marketing campaigns के लिए तैयार है। और ये सब तुमने scraping code की एक भी लाइन लिखे बिना कर लिया।
No-Code? कोई दिक्कत नहीं: हर किसी के लिए Web Data Extraction ऑटोमेट करें
Thunderbit की सबसे बढ़िया बात ये है कि ये non-technical यूज़र्स को भी empower करता है। Ruby, HTML, या CSS जानने की जरूरत नहीं—बस extension खोलो, AI को काम करने दो, और डेटा एक्सपोर्ट कर लो।
Learning curve: Ruby scripts में तुम्हें प्रोग्रामिंग और वेब स्ट्रक्चर की बेसिक्स सीखनी पड़ती हैं। Thunderbit में सेटअप मिनटों में हो जाता है, दिनों में नहीं।
Integration: Thunderbit सीधे उन टूल्स में एक्सपोर्ट करता है जिन्हें बिज़नेस टीमें रोज़ यूज़ करती हैं—Excel, Google Sheets, Airtable, Notion। तुम ongoing monitoring के लिए recurring scrapes शेड्यूल भी कर सकते हो।
User feedback: मैंने मार्केटिंग टीमों, sales ops, और ईकॉमर्स मैनेजर्स को Thunderbit से lead lists बनाने से लेकर price tracking तक सब कुछ ऑटोमेट करते देखा है—IT को कॉल किए बिना।
Best Practices: स्केलेबल ऑटोमेशन के लिए Ruby और AI Web Scraper को साथ इस्तेमाल करें
एक मजबूत और स्केलेबल scraping workflow बनाना है? ये मेरी टॉप टिप्स हैं:
- Website changes संभालें: Thunderbit जैसे AI web scrapers अपने आप एडैप्ट कर लेते हैं, लेकिन Ruby scripts में साइट बदलने पर selectors अपडेट करने पड़ सकते हैं।
- Scrapes शेड्यूल करें: नियमित डेटा pulls के लिए Thunderbit का scheduling फीचर यूज़ करो। Ruby में cron job या task scheduler सेट करो।
- Batch processing: बड़े datasets के लिए scraping को batches में बाँटो ताकि block होने या सिस्टम overload का रिस्क कम हो।
- Data formatting: analysis से पहले डेटा को साफ और validate करो—Thunderbit structured export देता है, लेकिन custom Ruby scripts में extra checks लग सकते हैं।
- Compliance: सिर्फ publicly available डेटा स्क्रैप करो,
robots.txtका सम्मान करो, और privacy laws का ध्यान रखो (खासकर EU में—). - Fallback strategies: अगर कोई साइट बहुत कॉम्प्लेक्स हो जाए या scraping ब्लॉक करे, तो official APIs या alternative data sources देखो।
कब क्या इस्तेमाल करें?
- जब तुम्हें पूरा कंट्रोल, कस्टम लॉजिक, या internal systems के साथ integration चाहिए—Ruby scripts चुनो।
- जब तुम्हें स्पीड, आसान इस्तेमाल, और बदलावों के साथ adaptability चाहिए—Thunderbit चुनो (खासकर one-off या recurring बिज़नेस टास्क्स के लिए)।
- Advanced workflows के लिए दोनों मिलाओ: extraction Thunderbit से, और enrichment/QA/integration Ruby से।
निष्कर्ष और मुख्य बातें
ruby के साथ web scraping हमेशा से डेटा कलेक्शन ऑटोमेट करने की एक सुपरपावर रही है—लेकिन अब Thunderbit जैसे AI web scrapers के साथ ये ताकत हर किसी के लिए accessible हो गई है। तुम डेवलपर हो और flexibility चाहिए, या बिज़नेस यूज़र हो और बस रिज़ल्ट—तुम web data extraction ऑटोमेट कर सकते हो, मैन्युअल काम के घंटे बचा सकते हो, और बेहतर व तेज़ फैसले ले सकते हो।
यहाँ मुख्य takeaways:
- Ruby web scraping और automation के लिए शानदार टूल है—खासकर Nokogiri और HTTParty जैसे gems के साथ।
- Thunderbit जैसे AI web scrapers non-coders के लिए data extraction आसान बनाते हैं, “AI Suggest Fields” और subpage scraping जैसी सुविधाओं के साथ।
- Ruby + Thunderbit साथ में इस्तेमाल करने पर दोनों का बेस्ट मिलता है: तेज़, नो‑कोड extraction और साथ में कस्टम automation/analysis।
- Sales, marketing, और ecommerce टीमों के लिए web data collection ऑटोमेट करना एक स्मार्ट गेम प्लान है—कम मेहनत, ज्यादा accuracy, और नए insights।
शुरू करने के लिए तैयार हो? , एक सिंपल Ruby स्क्रिप्ट ट्राय करो, और देखो तुम कितना समय बचा सकते हो। और अगर तुम और गहराई में जाना चाहो, तो पर और गाइड्स, टिप्स, और real-world examples मिलेंगे।
FAQs
1. क्या Thunderbit से web scraping करने के लिए मुझे कोडिंग आनी चाहिए?
नहीं। Thunderbit non-technical यूज़र्स के लिए बनाया गया है। बस extension खोलो, “AI Suggest Fields” पर क्लिक करो, और बाकी काम AI पर छोड़ दो। तुम डेटा को Excel, Google Sheets, Airtable, या Notion में एक्सपोर्ट कर सकते हो—बिना कोड के।
2. Web scraping के लिए Ruby इस्तेमाल करने के मुख्य फायदे क्या हैं?
Ruby में Nokogiri और HTTParty जैसी पावरफुल लाइब्रेरीज़ हैं, जो flexible और कस्टम scraping workflows बनाने में मदद करती हैं। यह उन डेवलपर्स के लिए बढ़िया है जिन्हें पूरा कंट्रोल, कस्टम लॉजिक, और दूसरे सिस्टम्स के साथ integration चाहिए।
3. Thunderbit का “AI Suggest Fields” फीचर कैसे काम करता है?
Thunderbit का AI वेब पेज स्कैन करता है, सबसे प्रासंगिक डेटा फील्ड्स (जैसे product names, prices, emails) पहचानता है, और तुम्हारे लिए एक structured table सुझाता है। Scrape करने से पहले तुम जरूरत के अनुसार कॉलम बदल भी सकते हो।
4. क्या advanced workflows के लिए मैं Thunderbit को Ruby scripts के साथ जोड़ सकता/सकती हूँ?
बिल्कुल। कई टीमें Thunderbit से डेटा निकालती हैं (खासकर complex या dynamic साइट्स से), और फिर Ruby scripts से उसे आगे प्रोसेस या एनालाइज़ करती हैं। यह hybrid तरीका custom reporting या data enrichment के लिए बहुत उपयोगी है।
5. क्या बिज़नेस इस्तेमाल के लिए web scraping कानूनी और सुरक्षित है?
जब तुम publicly available डेटा कलेक्ट करते हो और वेबसाइट की terms of service व privacy laws का पालन करते हो, तब web scraping आम तौर पर कानूनी है। हमेशा robots.txt चेक करो और बिना उचित सहमति के personal data स्क्रैप करने से बचो—खासकर EU यूज़र्स के लिए GDPR के तहत।
जानना चाहते हो कि web scraping तुम्हारे वर्कफ़्लो को कैसे बदल सकता है? Thunderbit का free tier ट्राय करो या आज ही Ruby स्क्रिप्ट के साथ प्रयोग शुरू करो। और अगर कहीं अटक जाओ, तो और पर ढेरों tutorials और tips मिलेंगे—जो तुम्हें web data automation में माहिर बनने में मदद करेंगे, बिना कोड के।
Learn More