दुनियाभर के ऑफिसों में एक शांत-सी क्रांति चल रही है—और इसमें न तो पिंग-पोंग टेबल हैं, न ही नल पर कोम्बुचा। असली बदलाव है “easy web extract” का उभार: यानी अब सिर्फ डेवलपर्स नहीं, बल्कि कोई भी इंसान मिनटों में वेब से काम का डेटा निकाल सकता है—दिनों में नहीं। अगर तुमने कभी किसी वेबसाइट को देखते हुए सोचा है कि काश ये सारे नाम, कीमतें या ईमेल बस उठाकर सीधे स्प्रेडशीट में डाल पाता/पाती, तो भरोसा रखो—तुम अकेले नहीं हो। सच बताऊँ तो मैंने सेल्स, मार्केटिंग और ऑपरेशंस टीमों के लोगों से बात की है—और सबका सवाल एक ही रहता है: “ये अब भी इतना मुश्किल क्यों है?”
हकीकत यह है कि आसान वेब स्क्रैपिंग तरीकों की डिमांड तेज़ी से बढ़ रही है। के मुताबिक, अब 65% संगठन कम-से-कम एक बिज़नेस फ़ंक्शन में जनरेटिव AI का इस्तेमाल कर रहे हैं, और वेब डेटा एक्सट्रैक्शन बहुत तेज़ी से सबसे ज़्यादा चाही जाने वाली उपयोगिताओं में शामिल हो रहा है। वेब स्क्रैपिंग मार्केट के तक पहुँचने का अनुमान है, और बिज़नेस यूज़र्स—खासकर जिनका टेक्निकल बैकग्राउंड नहीं है—ऐसे टूल्स की मांग को आगे बढ़ा रहे हैं जो डेटा निकालना कॉपी-पेस्ट जितना आसान बना दें। लेकिन “easy web extract” का असल मतलब क्या है, और तुम इसे अपने वर्कफ़्लो को सरल बनाने के लिए कैसे इस्तेमाल कर सकते हो? चलो इसे समझते हैं।
नॉन-टेक्निकल यूज़र्स के लिए Easy Web Extract: बिना कोड, बिना सिरदर्द
सबसे पहले बेसिक्स: “easy web extract” क्या है? आसान भाषा में कहें तो यह वेब के बिखरे हुए और लगातार बदलते डेटा को साफ़-सुथरी, व्यवस्थित टेबल्स में बदलने का तरीका है—वो भी बिना एक लाइन कोड लिखे। नॉन-टेक्निकल बिज़नेस यूज़र्स के लिए यह सच में गेम-चेंजर है। अब न IT टीम के पीछे भागना, न Python स्क्रिप्ट्स में उलझना, और न ही वेबसाइट का लेआउट रातों-रात बदल जाए तो हाथ खड़े कर देना।
अभी यह इतना ज़रूरी क्यों हो गया है? क्योंकि वेब पहले से कहीं ज़्यादा डायनेमिक हो चुका है। बहुत-सी साइट्स infinite scroll, पॉप-अप्स और भारी-भरकम JavaScript का इस्तेमाल करती हैं, जिससे पुराने तरीके के स्क्रेपर्स बार-बार फेल हो जाते हैं। दूसरी तरफ, बिज़नेस टीमों पर तेज़ी से इनसाइट्स देने का दबाव भी पहले से ज्यादा है। में 98% संगठन कहते हैं कि पब्लिक वेब डेटा उनके ऑपरेशंस के लिए महत्वपूर्ण या बहुत महत्वपूर्ण है, और आधे से ज्यादा इसे रोज़ इस्तेमाल करते हैं।
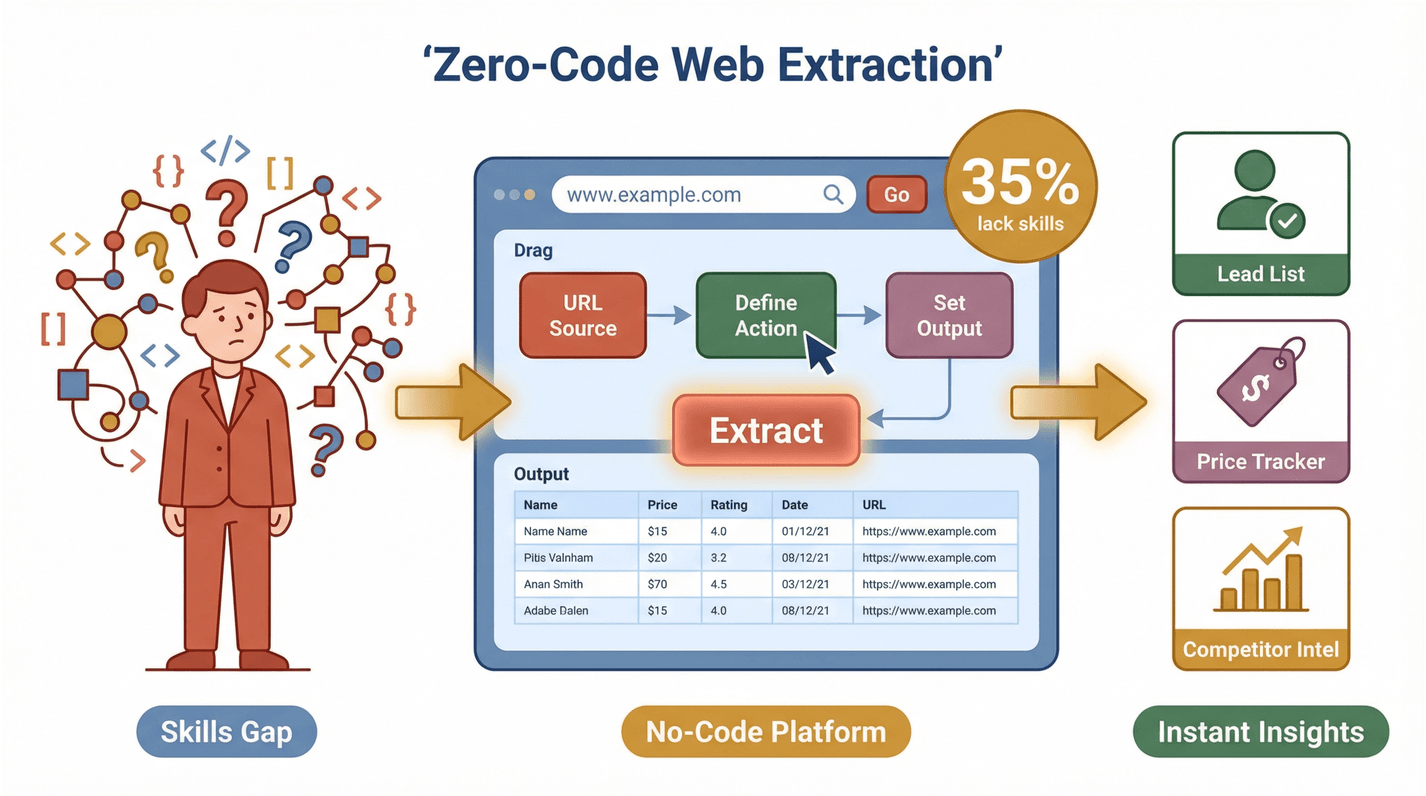
लेकिन ट्विस्ट यह है: इन टीमों में से ज़्यादातर टेक्निकल नहीं होतीं। एक हालिया सर्वे में पाया गया कि 35% संगठनों के पास वेब डेटा एक्सट्रैक्शन के लिए सही स्किल्स नहीं हैं, और 33% के पास सही टूल्स नहीं हैं। यही वजह है कि ज़ीरो-कोड सॉल्यूशंस के लिए बड़ा मौका बनता है। जब कोई भी वेब डेटा निकालकर इस्तेमाल कर सके, तो प्रोडक्टिविटी का नया लेवल खुलता है—चाहे तुम लीड लिस्ट बना रहे हो, competitors को ट्रैक कर रहे हो, या कीमतों की निगरानी कर रहे हो।
No-Code/Low-Code मूवमेंट: यह क्यों मायने रखता है
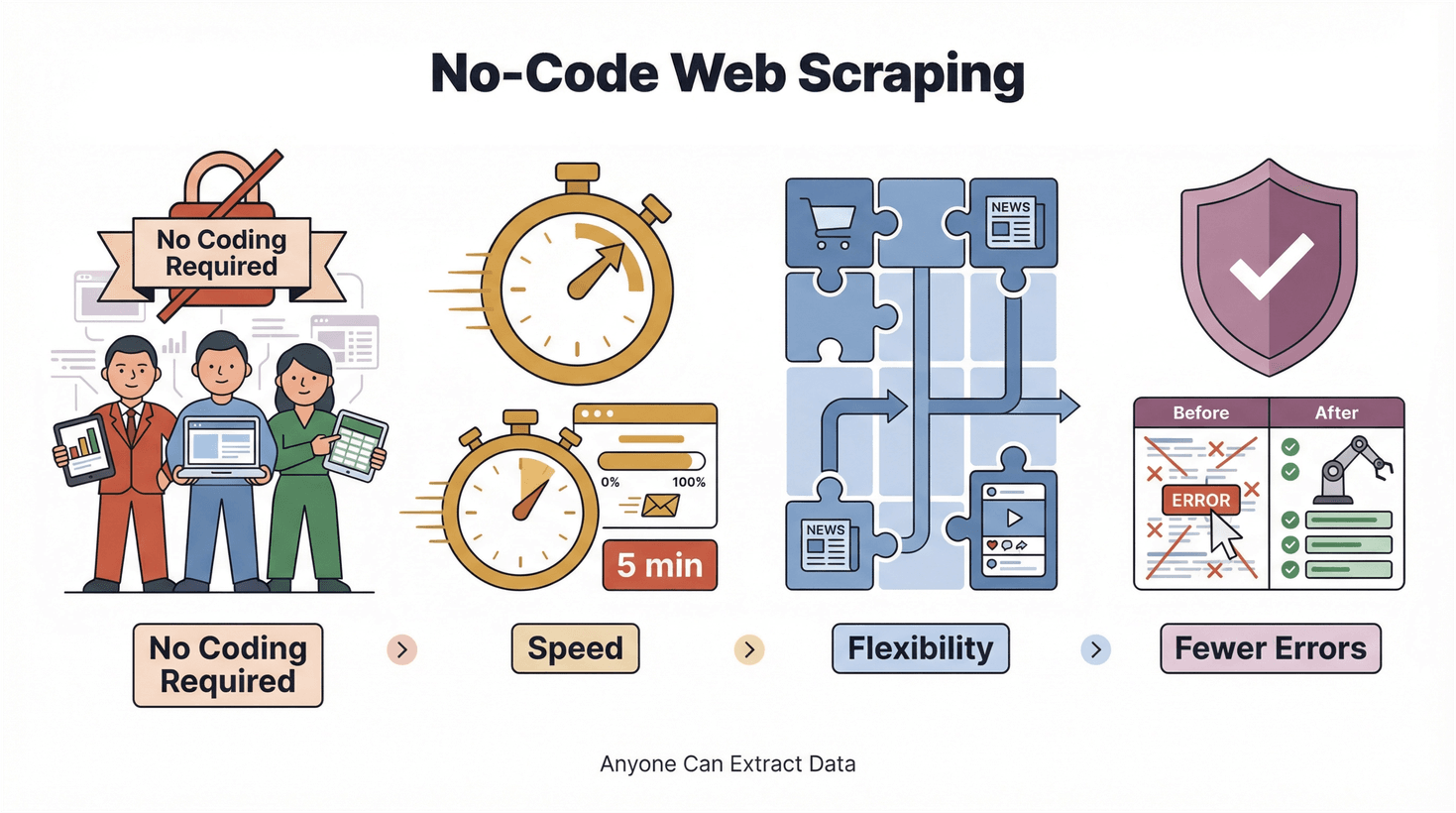
No-code और low-code टूल्स का उभार टेक्नोलॉजी को सबके लिए सुलभ बनाने की दिशा में है। यह सिर्फ Silicon Valley का buzzword नहीं—काम करने के तरीके में असली बदलाव है। वेब स्क्रैपिंग की दुनिया में इसका मतलब है:
- कोडिंग की जरूरत नहीं: डेटा कोई भी निकाल सकता है, सिर्फ इंजीनियर्स नहीं।
- तेज़ी: मिनटों में नतीजे, दिनों में नहीं।
- लचीलापन: नई साइट्स और नए डेटा की जरूरतों के अनुसार तुरंत ढलना।
- कम गलतियाँ: ऑटोमेशन से कॉपी-पेस्ट की चूकें घटती हैं।
और सबसे अच्छी बात? इसमें शामिल होने के लिए तुम्हें टेक-गुरु बनने की जरूरत नहीं।
पारंपरिक Web Scraper टूल्स इतने झुंझलाहट भरे क्यों होते हैं
ईमानदारी से कहें तो पारंपरिक वेब स्क्रैपिंग टूल्स अक्सर ऐसे लगते हैं जैसे डेवलपर्स ने डेवलपर्स के लिए बनाए हों—बिज़नेस यूज़र्स के लिए नहीं। मैंने यह कई बार देखा है: टीम किसी नए प्रोजेक्ट को लेकर एक्साइटेड होती है, और फिर जैसे ही टूल CSS selectors, XPath या regular expressions मांगता है—सबकी आँखें बुझ जाती हैं और “चलो अगली तिमाही देखते हैं” वाले ईमेल शुरू हो जाते हैं।
आमतौर पर दिक्कतें यहाँ आती हैं:
- कोडिंग जरूरी: कई पुराने टूल्स में स्क्रिप्ट लिखनी पड़ती है या जटिल टेम्पलेट्स सेट करने पड़ते हैं।
- सेटअप का झंझट: हर फ़ील्ड मैप करना, लॉगिन फ्लो संभालना, और ब्लॉक होने से बचने के लिए प्रॉक्सी सेट करना।
- नाज़ुक लॉजिक: वेबसाइट का लेआउट बदला और स्क्रैपर टूट गया। फिर तुम अपने असली काम की जगह डिबगिंग करते रह जाते हो।
- मेंटेनेंस का बोझ: साइट अपडेट होते ही फिर से शुरुआत।
इसीलिए के अनुसार, वेब स्क्रैपिंग की सबसे बड़ी तकनीकी चुनौतियाँ हैं IP ब्लॉक/बैन (56%), डायनेमिक कंटेंट (55%), और CAPTCHAs (52%)। बड़े और अनुभवी टीमें भी इससे जूझती हैं।
वहीं बिज़नेस यूज़र्स को बस एक सरल, भरोसेमंद तरीका चाहिए—ताकि डेटा स्प्रेडशीट या CRM में आसानी से पहुँच जाए। यहीं easy web extract और सरल वेब स्क्रैपिंग तरीके काम आते हैं।
Thunderbit कैसे Easy Web Extract को संभव बनाता है
यहीं मैं सबसे ज्यादा उत्साहित होता/होती हूँ—क्योंकि यही समस्या हम में हल करना चाहते थे। हमारा लक्ष्य है वेब स्क्रैपिंग को इतना आसान बनाना कि कोई भी कर सके—चाहे उसका टेक्निकल बैकग्राउंड हो या नहीं।
Thunderbit एक है, जो वेब एक्सट्रैक्शन को दो क्लिक की प्रक्रिया बना देता है। यह ऐसे काम करता है:
- बताइए आपको क्या चाहिए: साधारण भाषा में Thunderbit को बताइए कि कौन-सा डेटा चाहिए। जैसे, “इस पेज से सभी प्रोडक्ट नाम और कीमतें निकालो।”
- “AI Suggest Fields” पर क्लिक करें: Thunderbit का AI पेज पढ़कर सबसे उपयुक्त कॉलम सुझाता है—जैसे “Name,” “Price,” “Email,” या “Image।”
- “Scrape” पर क्लिक करें: बाकी काम Thunderbit कर देता है—pagination, subpages, और जरूरत हो तो logged-in कंटेंट भी।
बस इतना ही। न कोड, न टेम्पलेट्स, न सेटअप का सिरदर्द। इंटरफ़ेस खास तौर पर बिज़नेस यूज़र्स—सेल्स, मार्केटिंग, ईकॉमर्स, रियल एस्टेट—के लिए बनाया गया है, जिन्हें बस नतीजे चाहिए।
Thunderbit का AI-ड्रिवन वर्कफ़्लो: मेहनत कम, समझदारी ज्यादा
असली कमाल AI में है। Thunderbit सिर्फ अंदाज़ा नहीं लगाता—यह पेज को पढ़ता है, संदर्भ समझता है, और डेटा को अपने-आप स्ट्रक्चर कर देता है। अगर तुम एडवांस जाना चाहो, तो हर फ़ील्ड के लिए कस्टम निर्देश जोड़ सकते हो (जैसे “इस कॉलम को कैटेगराइज़ करो” या “इसे English में ट्रांसलेट करो”), लेकिन ज्यादातर यूज़र्स बस क्लिक करके आगे बढ़ जाते हैं।
इस AI-ड्रिवन तरीके के फायदे:
- कम गलतियाँ: AI अलग-अलग लेआउट के अनुसार ढल जाता है, इसलिए वेबसाइट बदलने पर भी परिणाम स्थिर रहते हैं।
- तेज़ सेटअप: टेम्पलेट बनाने या स्क्रिप्ट लिखने की जरूरत नहीं।
- काम का डेटा: Thunderbit स्क्रैप करते समय डेटा को लेबल, कैटेगराइज़ और even enrich भी कर सकता है।
और गहराई से जानने के लिए या हमारा वाला ब्लॉग पोस्ट देखें। तुम पर और गाइड्स भी देख सकते हो, जैसे और ।
सरल वेब स्क्रैपिंग तरीकों के लिए Thunderbit की खास खूबियाँ
Thunderbit को अलग बनाता है सिर्फ AI नहीं—बल्कि पूरा वर्कफ़्लो, जो असली बिज़नेस जरूरतों के हिसाब से डिज़ाइन किया गया है। कुछ फीचर्स जिन्हें यूज़र्स सबसे ज्यादा पसंद करते हैं:
- ऑटोमैटिक pagination: मल्टी-पेज साइट्स और infinite scroll को बिना सेटअप संभालता है।
- Subpage scraping: ज्यादा डिटेल चाहिए? Thunderbit हर subpage (जैसे प्रोडक्ट डिटेल्स या LinkedIn प्रोफाइल) पर जाकर डेटा अपने-आप जोड़ देता है।
- कहीं भी एक्सपोर्ट: डेटा सीधे Excel, Google Sheets, Airtable, Notion में भेजें या CSV/JSON डाउनलोड करें। कॉपी-पेस्ट की मैराथन खत्म।
- Logged-in पेजों पर भी काम: जिन साइट्स में लॉगिन चाहिए, वहाँ भी स्क्रैप करें—Thunderbit आपके ब्राउज़र में चलता है, इसलिए वही देखता है जो आप देखते हैं।
- AI-आधारित लेबलिंग और कैटेगराइज़ेशन: एक्सट्रैक्शन के साथ ही डेटा को क्लासिफाई/टैग/ट्रांसलेट करने के निर्देश जोड़ें।
- Scheduled scraping: नियमित जॉब्स सेट करें ताकि डेटा हमेशा ताज़ा रहे—प्राइस मॉनिटरिंग या लीड ट्रैकिंग के लिए बढ़िया।
और हाँ, यह सब एक ऐसे टूल में मिलता है जिस पर दुनिया भर में भरोसा करते हैं।
ऑटोमैटिक Pagination और Subpage Extraction
वेब स्क्रैपिंग में सबसे बड़ा सिरदर्द paginated लिस्ट्स या nested detail pages को संभालना होता है। Thunderbit के साथ तुम्हें चिंता नहीं करनी पड़ती। AI pagination को पहचान लेता है (चाहे “Next” बटन हो या infinite scroll) और subpages के लिंक भी अपने-आप फॉलो कर लेता है। यानी तुम एक ही बार में सैकड़ों या हजारों रिकॉर्ड निकाल सकते हो—बिना मैनुअल क्लिकिंग के।
उदाहरण के लिए, अगर तुम Amazon पर प्रोडक्ट्स की लिस्ट स्क्रैप कर रहे हो, तो Thunderbit कई पेजों के सारे प्रोडक्ट्स निकाल सकता है, फिर हर प्रोडक्ट पेज में जाकर reviews, ratings या seller info भी खींच सकता है। यह ऐसा है जैसे तुम्हारे पास एक थकान-रहित असिस्टेंट हो जो कभी बोर नहीं होता।
मल्टी-फ़ॉर्मेट एक्सपोर्ट और CRM इंटीग्रेशन
डेटा तभी काम का है जब तुम उसे इस्तेमाल कर सको। Thunderbit तुम्हें वही फ़ॉर्मेट देता है जो तुम्हारी टीम चाहती है—Excel, Google Sheets, Airtable, Notion, या CSV/JSON। तुम डेटा को सीधे अपने CRM या वर्कफ़्लो टूल्स में भी भेज सकते हो, ताकि सेल्स और ऑप्स टीमों के पास हमेशा लेटेस्ट जानकारी रहे।
यह डायरेक्ट इंटीग्रेशन बहुत समय बचाता है। गंदे एक्सपोर्ट्स साफ़ करने या कॉलम री-फ़ॉर्मेट करने की जरूरत नहीं—Thunderbit का AI यह सब संभाल लेता है।
Easy Web Extract के रियल-वर्ल्ड उपयोग
तो easy web extract का सबसे बड़ा असर कहाँ दिखता है? Thunderbit यूज़र्स से मिले कुछ वास्तविक उदाहरण:
सेल्स के लिए लीड एक्सट्रैक्शन
सेल्स टीमों के लिए लीड लिस्ट ही सब कुछ है। Thunderbit के साथ तुम LinkedIn, Google Maps या बिज़नेस डायरेक्टरीज़ से मिनटों में कॉन्टैक्ट जानकारी निकाल सकते हो। बस पेज खोलो, “AI Suggest Fields” पर क्लिक करो, और Thunderbit नाम, ईमेल, फोन नंबर और कंपनी डिटेल्स को तैयार स्प्रेडशीट में डाल दे।
एक सेल्स मैनेजर ने बताया कि पहले वे हर हफ्ते घंटों कॉपी-पेस्ट में लगाते थे। अब Thunderbit से वे बहुत कम समय में टार्गेटेड लिस्ट बना लेते हैं—और टीम डेटा एंट्री की जगह आउटरीच पर फोकस करती है।
ईकॉमर्स और मार्केट मॉनिटरिंग
ईकॉमर्स टीमें Thunderbit का इस्तेमाल Amazon, Shopify और अन्य प्लेटफ़ॉर्म्स पर प्रतिस्पर्धियों के SKUs, कीमतें और रिव्यू ट्रैक करने के लिए करती हैं। प्राइस चेंज या नए प्रोडक्ट लॉन्च मॉनिटर करने हैं? Scheduled scrape सेट करो और हर सुबह ताज़ा डेटा अपने Google Sheet में पाओ।
यहाँ subpage scraping खास तौर पर काम आता है—तुम प्रोडक्ट डिटेल्स, इमेजेज और ग्राहक रिव्यू तक बिना मेहनत निकाल सकते हो।
रियल एस्टेट डेटा कलेक्शन
रियल एस्टेट प्रोफेशनल्स Zillow या Realtor.com जैसी साइट्स से प्रॉपर्टी लिस्टिंग्स, कीमतें और एजेंट जानकारी जुटाने के लिए Thunderbit का उपयोग करते हैं। AI pagination और subpages संभाल लेता है, जिससे तुम्हें मार्केट का पूरा और अपडेटेड व्यू मिलता है—एनालिसिस या क्लाइंट रिपोर्ट्स के लिए परफेक्ट।
एक रियल एस्टेट एनालिस्ट ने साझा किया कि जो काम पहले पूरा दोपहर ले लेता था, अब कुछ क्लिक में हो जाता है। यही है सरल वेब स्क्रैपिंग तरीकों की ताकत।
पारंपरिक बनाम सरल वेब स्क्रैपिंग तरीकों की तुलना
आइए इसे एक साइड-बाय-साइड तुलना में देखें:
| फ़ीचर | पारंपरिक स्क्रेपर्स | Easy Web Extract (Thunderbit) |
|---|---|---|
| कोडिंग की जरूरत | हाँ (स्क्रिप्ट्स, selectors) | नहीं (AI + प्राकृतिक भाषा) |
| सेटअप समय | ज्यादा (टेम्पलेट्स, कॉन्फ़िग) | कम (2 क्लिक) |
| मेंटेनेंस | बार-बार (साइट बदलते ही टूटता) | न्यूनतम (AI ढल जाता है) |
| pagination संभालना | मैनुअल सेटअप | ऑटोमैटिक |
| subpage extraction | जटिल लॉजिक | 1 क्लिक |
| एक्सपोर्ट फ़ॉर्मेट्स | अक्सर सीमित | Excel, Sheets, Airtable, Notion, CSV, JSON |
| logged-in पेजों पर काम | कभी-कभी (कॉन्फ़िग के साथ) | हाँ (ब्राउज़र-आधारित) |
| डेटा लेबलिंग/कैटेगराइज़ेशन | मैनुअल पोस्ट-प्रोसेसिंग | AI-आधारित, बिल्ट-इन |
| scheduling/monitoring | कभी-कभी (एडवांस) | हाँ (आसान सेटअप) |
अंतर साफ़ है। Thunderbit के साथ कोई भी वेब डेटा निकाल सकता है, व्यवस्थित कर सकता है और इस्तेमाल कर सकता है—बिना टेक्निकल स्किल्स के।
Easy Web Extract और सरल वेब स्क्रैपिंग तरीकों के भविष्य के ट्रेंड्स
आगे देखते हुए, easy web extract का भविष्य काफी उज्ज्वल है। AI लगातार स्मार्ट हो रहा है, और ज़ीरो-कोड टूल्स की मांग तेज़ी से बढ़ रही है। के अनुसार, अब 78% संगठन कम-से-कम एक फ़ंक्शन में AI का उपयोग कर रहे हैं, और agentic systems—ऐसे AI टूल्स जो मल्टी-स्टेप वेब वर्कफ़्लो संभाल सकते हैं—तेजी से बढ़ रहे हैं।
बिज़नेस यूज़र्स के लिए इसका मतलब: ज्यादा ताकत, कम झंझट। AI के बेहतर होने के साथ हम देखेंगे:
- और स्मार्ट फ़ील्ड डिटेक्शन: AI जटिल डेटा और रिश्तों को बेहतर समझेगा।
- बेहतर इंटीग्रेशन: ज्यादा बिज़नेस टूल्स और प्लेटफ़ॉर्म्स से डायरेक्ट कनेक्शन।
- ज्यादा भरोसेमंदी: कम टूट-फूट, ज्यादा स्थिर परिणाम—डायनेमिक या प्रोटेक्टेड साइट्स पर भी।
- ज्यादा सुलभता: वेब एक्सट्रैक्शन हर किसी के लिए एक सामान्य स्किल बन जाएगा, सिर्फ टेक लोगों के लिए नहीं।
और हाँ, Thunderbit इस मूवमेंट के बिल्कुल अग्रिम मोर्चे पर है।
निष्कर्ष और मुख्य बातें
वेब दुनिया का सबसे बड़ा डेटाबेस है—लेकिन हाल तक इसे सिर्फ कोडर्स ही इस्तेमाल कर पाते थे। अब यह तेजी से बदल रहा है। easy web extract और सरल वेब स्क्रैपिंग तरीकों के साथ, कोई भी मिनटों में वेबसाइट्स को actionable डेटा में बदल सकता है।
यहाँ मेरी सीख (और जो मैं चाहता/चाहती हूँ कि तुम साथ ले जाओ):
- ज़ीरो-कोड वेब एक्सट्रैक्शन अब स्थायी है: Thunderbit जैसे टूल्स किसी को भी वेब डेटा जुटाने और इस्तेमाल करने देते हैं—बिना टेक्निकल स्किल्स के।
- AI ही असली ताकत है: फ़ील्ड चयन, pagination, subpage extraction और डेटा लेबलिंग को ऑटोमेट करके AI-आधारित स्क्रेपर्स समय बचाते हैं और गलतियाँ घटाते हैं।
- बिज़नेस असर वास्तविक है: सेल्स, ईकॉमर्स और रियल एस्टेट टीमें पहले से ज्यादा प्रोडक्टिविटी, ताज़ा डेटा और बेहतर निर्णय देख रही हैं।
- आगे और भी बेहतर होगा: जैसे-जैसे AI और no-code टूल्स विकसित होंगे, वेब डेटा एक्सट्रैक्शन ईमेल भेजने जितना सामान्य हो जाएगा।
अगर तुम मैनुअल कॉपी-पेस्ट से थक चुके हो, टूटते स्क्रेपर्स से परेशान हो, या बस जानना चाहते हो कि क्या संभव है—तो आज़माओ। तुम करके मुफ़्त में डेटा निकालना शुरू कर सकते हो—बिना सेटअप, बिना कोड, बिना झंझट।
और अगर तुम और गहराई में जाना चाहते हो, तो पर और गाइड्स, टिप्स और रियल-वर्ल्ड उदाहरण देखें।
FAQs
1. “easy web extract” क्या है और यह किसके लिए है?
Easy web extract का मतलब है ज़ीरो-कोड, AI-आधारित वेब स्क्रैपिंग तरीके, जिनसे कोई भी—खासकर नॉन-टेक्निकल बिज़नेस यूज़र्स—वेबसाइट्स से स्ट्रक्चर्ड डेटा जल्दी और आसानी से निकाल सकता है। यह सेल्स, मार्केटिंग, ईकॉमर्स और ऑपरेशंस टीमों के लिए आदर्श है, जिन्हें टेक्निकल झंझट के बिना actionable डेटा चाहिए।
2. Thunderbit पारंपरिक वेब स्क्रैपिंग टूल्स से कैसे अलग है?
Thunderbit AI की मदद से फ़ील्ड चयन, pagination और subpage extraction को ऑटोमेट करता है। पारंपरिक स्क्रेपर्स में जहाँ कोडिंग या जटिल टेम्पलेट्स की जरूरत होती है, वहीं Thunderbit में तुम साधारण भाषा में जरूरत बताकर सिर्फ दो क्लिक में डेटा निकाल सकते हो।
3. क्या Thunderbit डायनेमिक या मल्टी-पेज वेबसाइट्स संभाल सकता है?
हाँ। Thunderbit pagination (infinite scroll सहित) को अपने-आप पहचानकर संभालता है और गहरे डेटा के लिए subpages के लिंक भी फॉलो कर सकता है—वो भी न्यूनतम सेटअप के साथ।
4. Thunderbit किन एक्सपोर्ट विकल्पों को सपोर्ट करता है?
Thunderbit डेटा को सीधे Excel, Google Sheets, Airtable, Notion, CSV या JSON में एक्सपोर्ट करने देता है। तुम इसे CRMs और अन्य वर्कफ़्लो टूल्स के साथ भी इंटीग्रेट कर सकते हो ताकि बिज़नेस प्रोसेस सहज रहें।
5. क्या Thunderbit जैसे easy web extract टूल्स का उपयोग सुरक्षित और नैतिक है?
Thunderbit जिम्मेदार और नैतिक वेब स्क्रैपिंग को प्रोत्साहित करता है। हमेशा वेबसाइट की terms of service का सम्मान करो, बिना सहमति के व्यक्तिगत डेटा स्क्रैप करने से बचो, और सेवा में बाधा न आए इसके लिए rate limiting का उपयोग करो। बेस्ट प्रैक्टिसेज के लिए देखें।
वेब डेटा की ताकत खोलने के लिए तैयार हो? आज ही Thunderbit आज़माओ और देखो कि easy web extract तुम्हारे वर्कफ़्लो को कितना बदल सकता है।
और जानें