आपका CRM उतना ही दमदार होता है, जितना दमदार डेटा तुम उसमें डालते हो। और सबसे बढ़िया डेटा अक्सर पब्लिक वेबसाइटों पर ही मिल जाता है—महंगे थर्ड-पार्टी डेटाबेस में नहीं।
web extractor टूल्स उस बिखरे हुए वेब डेटा को एकदम साफ-सुथरी स्प्रेडशीट में बदल देते हैं। अच्छे टूल्स ये काम मिनटों में कर देते हैं—बिना एक लाइन कोड लिखे।
मैंने इन टूल्स को रियल प्रोजेक्ट्स में घिसा है—लीड लिस्ट बनाना, कंपटीटर की प्राइसिंग ट्रैक करना, प्रोडक्ट कैटलॉग स्क्रैप करना। नीचे 12 ऐसे टूल्स हैं जो सच में काम आए, और मैंने इन्हें रियल बिज़नेस टास्क्स में परफॉर्मेंस के आधार पर रैंक किया है।
Web Extractors बिज़नेस के लिए ज़रूरी क्यों हैं
सच बताऊँ तो: वेब दुनिया का सबसे बड़ा (और सबसे अव्यवस्थित) डेटाबेस है। और 2026 में जो कंपनियाँ इस अव्यवस्था को इनसाइट में बदलना जानती हैं, वही गेम में आगे निकल रही हैं। के मुताबिक, डेटा-ड्रिवन कंपनियाँ अपने साथियों की तुलना में 5% ज़्यादा प्रोडक्टिव और 6% ज़्यादा प्रॉफिटेबल होती हैं। ये कोई छोटा-मोटा फर्क नहीं—ये सीधी-सी ठोस बढ़त है।
web extractor tools (जिन्हें कभी-कभी web page extractor या web extracting solutions भी कहा जाता है) इसी बढ़त का “सीक्रेट सॉस” हैं। ये सेल्स टीमों को पब्लिक डायरेक्टरी, सोशल मीडिया और कंपनी वेबसाइटों से डेटा निकालकर टार्गेटेड प्रॉस्पेक्ट लिस्ट बनाने देते हैं—पुरानी लीड शीट खरीदने या इंटर्न के कॉपी-पेस्ट मैराथन पर निर्भर रहने की टेंशन खत्म (). मार्केटिंग और ईकॉमर्स टीमें web extractors से कंपटीटर प्राइसिंग ट्रैक, स्टॉक लेवल मॉनिटर, और रियल-टाइम प्रोडक्ट बेंचमार्क करती हैं—उदाहरण के लिए John Lewis ने सिर्फ बेहतर प्राइसिंग के कारण web scraping से 4% सेल्स लिफ्ट का क्रेडिट दिया है ().
मुद्दा सिर्फ नंबरों का नहीं है। web extractors ढेर सारा समय बचाते हैं (एक यूज़र ने डेटा कलेक्शन ऑटोमेट करके “सैकड़ों घंटे” बचाने की बात कही) और मानवीय गलतियाँ घटाते हैं (). ऑपरेशंस टीमें अब ऐसे scrapers सेट करती हैं जो लगातार डेटा जुटाते रहते हैं—जो काम पहले इंटर्न्स को हफ्तों लगाकर करना पड़ता था—और कॉपी-पेस्ट जैसी बोरिंग मेहनत में जाने वाले घंटे वापस दिलाते हैं (). और AI-ड्रिवन extractors के साथ तो नॉन-टेक्निकल यूज़र्स भी वेबसाइट को स्ट्रक्चर्ड डेटा में बदलकर एनालिसिस कर सकते हैं ().
निष्कर्ष? अगर 2026 में तुम web extractor इस्तेमाल नहीं कर रहे, तो मुमकिन है कि तुम इनसाइट्स (और पैसा) टेबल पर छोड़ रहे हो।
हमने टॉप 12 Web Extractors कैसे चुने
इतने सारे web extracting tools में सही टूल चुनना आसान नहीं होता। मैंने दर्जनों ऑप्शन्स देखे, लेकिन इस लिस्ट में सिर्फ 12 आए। चयन के लिए मैंने ये बातें सबसे ऊपर रखीं:
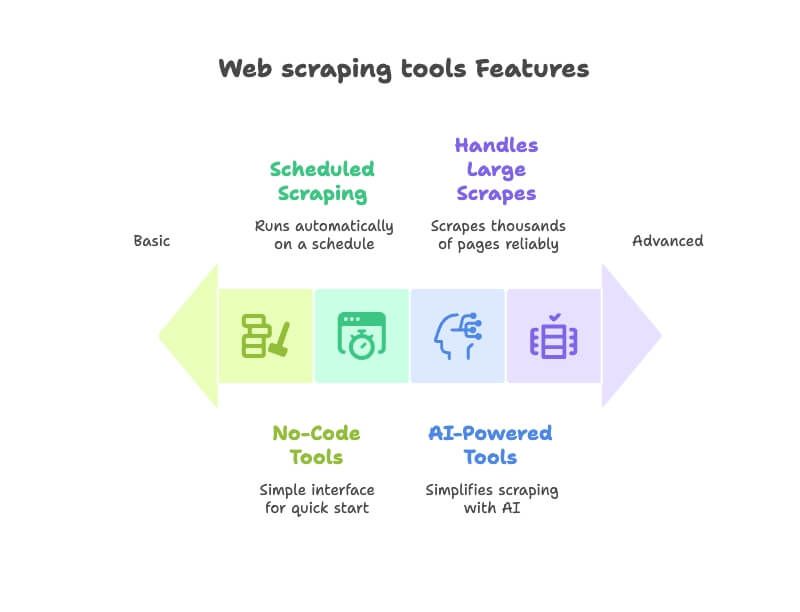
- इस्तेमाल में आसानी: क्या कोई नॉन-टेक यूज़र बिना कोड लिखे जल्दी शुरू कर सकता है? मैंने नो-कोड/लो-कोड और सहज UI वाले टूल्स को प्राथमिकता दी ().
- AI क्षमताएँ: ऐसे नेक्स्ट-जेन टूल्स जो AI से scraping आसान बनाते हैं—जैसे ऑटोमैटिक फील्ड डिटेक्शन, साइट नेविगेशन संभालना, या साधारण भाषा में जरूरत बताने पर काम करना ().
- ऑटोमेशन और शेड्यूलिंग: बेस्ट web extractors ऑटोपायलट पर चलते हैं। मैंने ऐसे टूल चुने जो recurring scrapes या वेबसाइट मॉनिटरिंग को शेड्यूल कर सकें ().
- डेटा एक्सपोर्ट और इंटीग्रेशन: क्या Excel, Google Sheets, Airtable या Notion में आसानी से एक्सपोर्ट हो जाता है? वर्कफ़्लो इंटीग्रेशन वाले टूल्स को एक्स्ट्रा पॉइंट्स मिले ().
- स्केलेबिलिटी और भरोसेमंदी: एक पेज हो या हजारों—टूल संभाल पाए। भरोसेमंदी के लिए यूज़र रिव्यूज़ भी देखे।
- बिज़नेस-केंद्रित यूज़ केस: मैंने उन टूल्स पर ज़ोर दिया जो सेल्स, मार्केटिंग, ईकॉमर्स और ऑपरेशंस टीमों में पॉपुलर हैं—सिर्फ डेवलपर्स तक सीमित नहीं।
कुछ टूल AI-पावर्ड नए खिलाड़ी हैं, कुछ इंडस्ट्री के क्लासिक्स। लेकिन सभी का लक्ष्य एक ही है: वेब को तुम्हारे बिज़नेस डेटाबेस में बदलना—बिना सिरदर्द के।
क्विक तुलना: Web Extractor Tools एक नज़र में
यहाँ उन 12 web extractor tools का एक स्नैपशॉट है जिनकी चर्चा आगे होगी—ताकि तुम जल्दी समझ सको कि कौन किसमें बेहतर है:
| टूल | AI ऑटोमेशन | इस्तेमाल में आसानी | सबसे अच्छा उपयोग |
|---|---|---|---|
| Thunderbit | हाँ – AI फील्ड सुझाता है और पेज अपने आप संभालता है | बहुत आसान (Chrome extension, बिना कोड) | नॉन-टेक यूज़र्स के लिए मिनटों में लीड्स, प्राइस आदि का तेज़ scraping। |
| Octoparse | सीमित (टेम्पलेट-आधारित, AI नहीं) | ज़्यादातर के लिए आसान (विज़ुअल ड्रैग-एंड-ड्रॉप) | लॉगिन/पेजिनेशन सहित कस्टम scraping वर्कफ़्लो—बिना कोड, लेकिन कंट्रोल के साथ। |
| Browse AI | आंशिक – पॉइंट-एंड-क्लिक “robots” | आसान (नो-कोड, क्लाउड-आधारित) | शेड्यूल पर डेटा मॉनिटरिंग (प्राइस, लिस्टिंग आदि), अलर्ट्स और इंटीग्रेशन के साथ। |
| WebScraper.io | नहीं (मैनुअल कॉन्फ़िगरेशन) | मध्यम (ब्राउज़र एक्सटेंशन + sitemap सेटअप) | मल्टी-लेवल साइट्स का विज़ुअल scraping—उन यूज़र्स के लिए जो स्टेप्स कॉन्फ़िगर कर सकते हैं। |
| ScraperAPI | लागू नहीं (API सर्विस; proxies API से संभालता है) | कोडिंग चाहिए (API इंटीग्रेशन) | टेक टीमों के लिए हाई-वॉल्यूम डेटा एक्सट्रैक्शन—बड़े स्केल पर proxies/CAPTCHA हैंडलिंग। |
| Data Miner | नहीं | बहुत आसान (ब्राउज़र एक्सटेंशन + वन-क्लिक टेम्पलेट्स) | टेबल/लिस्ट जैसी पेजों से जल्दी one-off डेटा निकालकर CSV/Excel में। |
| Simplescraper | नहीं (कुछ AI-असिस्टेड फीचर्स) | आसान (पॉइंट-एंड-क्लिक रेसिपी बिल्डर) | नो-कोड scraping + इंटीग्रेशन—Google Sheets, Airtable या API में डेटा भेजने के लिए बढ़िया। |
| Instant Data Scraper | हाँ – डेटा टेबल ऑटो-डिटेक्ट | बहुत आसान (बस क्लिक, सेटअप नहीं) | HTML टेबल/लिस्ट का तुरंत फ्री scraping—क्विक डेटा ग्रैब के लिए आदर्श। |
| ScrapeStorm | हाँ – AI पेज एलिमेंट्स पहचानता है | आसान (विज़ुअल UI; क्रॉस-प्लैटफ़ॉर्म ऐप) | बिना कोड बड़े/जटिल scraping प्रोजेक्ट्स, शेड्यूल्ड क्रॉल्स सहित। |
| Apify | कुछ – प्री-बिल्ट “actor” bots उपलब्ध | मध्यम (वेब UI; कोडिंग वैकल्पिक) | रेडीमेड या कस्टम स्क्रिप्ट्स के साथ स्केलेबल क्लाउड scraping और ऑटोमेशन। |
| ParseHub | नहीं (स्क्रिप्टलेस, पर मैनुअल सेटअप) | बेसिक के लिए आसान (विज़ुअल एडिटर; डेस्कटॉप ऐप) | डायनेमिक/कॉम्प्लेक्स साइट्स (AJAX) को नो-कोड इंटरफ़ेस से scrape करना। |
| OutWit Hub | नहीं | आसान (डेस्कटॉप GUI) | छोटे प्रोजेक्ट्स के लिए सरल, ऑफ़लाइन डेटा एक्सट्रैक्शन और कंटेंट आर्काइविंग। |
ज़्यादातर टूल्स फ्री टियर/ट्रायल और अलग-अलग सब्सक्रिप्शन प्लान देते हैं। यहाँ फोकस कीमत से ज़्यादा क्षमताओं और उपयोग मामलों पर है।
Thunderbit: हर किसी के लिए AI-पावर्ड Web Extractor

शुरुआत Thunderbit से करते हैं—हाँ, ये मेरा ही प्रोडक्ट है, लेकिन ज़रा बात सुनो। web extracting इंडस्ट्री “अपना scraper खुद कॉन्फ़िगर करो” से “AI को बस बता दो क्या चाहिए” की तरफ तेज़ी से शिफ्ट हो रही है। Thunderbit पहला टूल है (जिसे मैंने बनाने में मदद की) जो सच में एक “crawler” से ज़्यादा AI डेटा असिस्टेंट जैसा फील देता है।
में XPath, CSS selectors या regex जैसी चीज़ों में उलझने की जरूरत नहीं। तुम बस नॉर्मल भाषा में बता देते हो—जैसे “इस पेज से title, author और date निकालो”—और बाकी काम Thunderbit का AI कर देता है (). “AI Suggest Fields” पर क्लिक करो, Thunderbit पेज पढ़कर कॉलम सुझाता है, और subpages व pagination भी अपने आप संभाल लेता है ().
और ये सिर्फ डेटा उठाने तक सीमित नहीं। Thunderbit scraping के साथ-साथ डेटा साफ कर सकता है, ट्रांसफॉर्म कर सकता है, कैटेगराइज़ कर सकता है और जरूरत हो तो फील्ड्स का अनुवाद भी कर सकता है। फोन नंबर स्टैंडर्डाइज़ करने हैं, डिस्क्रिप्शन का सार चाहिए, या प्रोडक्ट नाम ट्रांसलेट करने हैं? बस एक छोटा निर्देश जोड़ दो—AI संभाल लेगा। और काम पूरा होने पर Excel, Google Sheets, Airtable या Notion में सीधे एक्सपोर्ट कर सकते हो ().
Thunderbit की सबसे बड़ी खासियत है ज़ीरो सेटअप, ज़ीरो लर्निंग कर्व। ये Chrome extension है—सेकंड्स में शुरू। न प्लगइन्स, न कॉन्फ़िगरेशन, न टेक्निकल जार्गन। इसी वजह से ये सेल्स, मार्केटिंग और ऑपरेशंस टीमों में फेवरेट बन गया है जिन्हें जल्दी रिज़ल्ट चाहिए (). फ्री टियर से तुम पूरा वर्कफ़्लो ट्राय कर सकते हो, और पेड प्लान्स भी ज़्यादातर टीमों के लिए पॉकेट-फ्रेंडली हैं।
अगर तुम देखना चाहते हो कि AI web extracting असल में कैसा लगता है, तो और ट्राय करो। हो सकता है तुम्हारा कॉपी-पेस्ट वाला ज़माना यहीं खत्म हो जाए।
Octoparse: कस्टम वर्कफ़्लो के लिए विज़ुअल Web Extractor
Octoparse विज़ुअल web scraping की दुनिया का एक क्लासिक टूल है। ये एक डेस्कटॉप ऐप है जिसमें पॉइंट-एंड-क्लिक इंटरफ़ेस मिलता है—तुम वेबपेज पर जाकर डेटा चुनते हो, और Octoparse बैकएंड में वर्कफ़्लो बना देता है (). लॉगिन, pagination, यहाँ तक कि फॉर्म सबमिशन ऑटोमेशन—सब बिना कोड के।
Octoparse की बड़ी ताकत है इसकी 500+ प्री-बिल्ट टेम्पलेट लाइब्रेरी (Amazon, Twitter, LinkedIn आदि) —अक्सर तुम टेम्पलेट लोड करके तुरंत एक्सट्रैक्शन शुरू कर सकते हो (). जटिल साइट्स के लिए मैनुअल मोड में जाकर हर स्टेप विज़ुअली सेट कर सकते हो। ये क्लिक/स्क्रॉल के बाद लोड होने वाला कंटेंट भी scrape कर सकता है, proxies सपोर्ट करता है और कठिन मामलों में CAPTCHA सॉल्विंग भी। स्केल पर चलाने और शेड्यूलिंग के लिए क्लाउड ऑप्शन भी है।
कमी? एडवांस्ड केस में थोड़ा सीखना पड़ता है। लेकिन जो नॉन-प्रोग्रामर या डेटा एनालिस्ट बिना कोड के कस्टम scraping वर्कफ़्लो चाहते हैं, उनके लिए Octoparse एक मजबूत विकल्प है ().
Browse AI: प्रीबिल्ट Robots के साथ ऑटोमेटेड Web Extracting
Browse AI का तरीका बड़ा दिलचस्प है: तुम जिस डेटा को चाहते हो, उस पर क्लिक करके एक “robot” ट्रेन करते हो, और वो समान पेजों पर वही डेटा निकालना सीख लेता है (). ये पूरी तरह क्लाउड-आधारित और नो-कोड है—स्क्रिप्ट/सर्वर की झंझट नहीं।
Browse AI की खासियत है इसका ऑटोमेशन और मॉनिटरिंग। तुम robots को नियमित रूप से चलने के लिए शेड्यूल कर सकते हो और डेटा बदलते ही अलर्ट पा सकते हो (जैसे कंपटीटर ने प्राइस घटाया या नई जॉब लिस्टिंग आई)। आम कामों के लिए प्रीबिल्ट robots की लाइब्रेरी भी है—जिसे तुम जरूरत के हिसाब से ट्यून कर सकते हो ().
ये Zapier और Make के जरिए हजारों ऐप्स से इंटीग्रेट होता है, और डेटा Google Sheets या API/webhooks से एक्सपोर्ट कर सकता है (). लगातार मॉनिटरिंग और recurring डेटा कलेक्शन के लिए ये बढ़िया फिट है—खासकर अगर तुम्हें hands-off अलर्ट्स और इंटीग्रेशन चाहिए।
WebScraper.io: ब्राउज़र-आधारित Web Page Extractor

WebScraper.io (अक्सर “Web Scraper” के नाम से) एक ब्राउज़र एक्सटेंशन है जो तुम्हें “sitemaps” बनाने देता है—यानी वेबसाइट पर कैसे नेविगेट करना है और क्या-क्या निकालना है, उसका विज़ुअल प्लान (). तुम डेटा के selectors और फॉलो करने वाले लिंक तय करते हो (जैसे “next” बटन क्लिक करके pagination, या हर प्रोडक्ट लिंक खोलकर डिटेल्स निकालना)।
सीखने में थोड़ा टाइम लगता है, लेकिन कोड नहीं लिखना पड़ता—बस एलिमेंट्स चुनो और एक्सट्रैक्शन एक्शन्स सेट करो। Web Scraper मल्टी-लेवल नेविगेशन, pagination और infinite scroll सपोर्ट करता है (हालाँकि स्टेप्स तुम्हें मैनुअली बताने होते हैं)। ये ब्राउज़र में चलता है, इसलिए लॉगिन के पीछे वाली साइट्स भी तुम खुद लॉगिन करके scrape कर सकते हो।
WebScraper.io उन “citizen data analysts” के लिए अच्छा है जो वेब पेज स्ट्रक्चर समझते हैं और एक फ्री, लचीला टूल चाहते हैं। अगर तुम अपने sitemaps सेट करने को तैयार हो, तो ये भरोसेमंद वर्कहॉर्स है।
ScraperAPI: डेवलपर्स और टीमों के लिए API-फर्स्ट Web Extractor
हर टीम को पॉइंट-एंड-क्लिक UI नहीं चाहिए—कभी-कभी तुम्हें बैकएंड सॉल्यूशन चाहिए जो वेब डेटा को सीधे तुम्हारे ऐप्स/डेटाबेस में भेज दे। ScraperAPI एक API-फर्स्ट web extractor है: तुम URL देते हो और ये raw HTML या एक्सट्रैक्टेड डेटा लौटाता है—और proxies, geo IP rotation, headless browsers, CAPTCHA जैसी मुश्किल चीज़ें खुद संभालता है ().
ScraperAPI के पास 50+ देशों में 40 मिलियन+ proxies का पूल है और ये हर महीने 36 बिलियन रिक्वेस्ट प्रोसेस करता है (). ये लार्ज-स्केल, ऑटोमेटेड scraping के लिए सबसे अच्छा है जहाँ reliability और anti-blocking अहम हैं। इसे इस्तेमाल करने के लिए कोडिंग स्किल चाहिए, लेकिन डेटा पाइपलाइन या प्रोडक्ट इंटीग्रेशन के लिए ये टॉप चॉइस है।
Data Miner: क्विक Web Page Extracting के लिए Chrome Extension

Data Miner एक Chrome extension है जो बिज़नेस यूज़र्स और रिसर्चर्स के लिए बनाया गया है जिन्हें जल्दी डेटा चाहिए। इसमें पॉइंट-एंड-क्लिक scraping और कॉमन पैटर्न (टेबल, लिस्ट, या कुछ साइट्स) के लिए प्री-बिल्ट “recipes” की लाइब्रेरी मिलती है ().
एक्सटेंशन इंस्टॉल करो, टार्गेट पेज खोलो, और Data Miner आइकन पर क्लिक करो। कोई recipe चुनो या पेज पर एलिमेंट्स सेलेक्ट करके अपनी बनाओ। ये one-off कामों या तुरंत डेटा जरूरत के लिए बढ़िया है—जैसे सेल्स रिप ऑनलाइन डायरेक्टरी से लीड्स निकाल रहा हो, या ईकॉमर्स मैनेजर कंपटीटर प्राइस कॉपी कर रहा हो।
ये सिंपल है, ब्राउज़र में ही रहता है, और ऑन-डिमांड, इंटरैक्टिव scraping के लिए परफेक्ट है।
Simplescraper: तुरंत नतीजों के लिए नो-कोड Web Extractor

Simplescraper अपने नाम जैसा ही है। ये एक नो-कोड Chrome extension (और वेब ऐप) है जिसमें तुम पेज पर डेटा विज़ुअली चुनकर एक्सट्रैक्शन की “recipe” बना सकते हो (). तुम लिंक फॉलो करके subpages scrape कर सकते हो, pagination संभाल सकते हो, और एक क्लिक में अपने scrape को API endpoint में भी बदल सकते हो।
Simplescraper की सबसे बड़ी ताकत है इसके इंटीग्रेशन विकल्प—तुम डेटा सीधे Google Sheets, Airtable या Zapier जैसे टूल्स में भेज सकते हो (). recurring jobs के लिए cloud scraping और scheduling भी है, और “AI Enhance” फीचर से GPT के जरिए डेटा साफ/एनालाइज़ किया जा सकता है।
अगर तुम्हें जल्दी रिज़ल्ट और आसान इंटीग्रेशन चाहिए, तो Simplescraper हल्के-फुल्के web scraping का Swiss Army knife है।
Instant Data Scraper: टेबल्स और लिस्ट्स के लिए तेज़ Web Extracting
कभी-कभी तुम्हें डेटा अभी चाहिए—बिना किसी सेटअप के। ऐसे में Instant Data Scraper (IDS) काम आता है। ये एक फ्री Chrome extension है जो एक क्लिक में tabular डेटा निकालने के लिए जाना जाता है (). एक्सटेंशन ऑन करते ही IDS पेज पर टेबल/लिस्ट ऑटो-डिटेक्ट कर लेता है। pagination और infinite scroll भी ये अपने आप क्लिक करके संभाल सकता है।
IDS 100% फ्री है—ना साइन-अप, ना कोडिंग, ना इंतज़ार। ये कैज़ुअल या अर्जेंट scraping के लिए परफेक्ट है—जैसे सेल्स रिप को तुरंत लीड लिस्ट चाहिए, या स्टूडेंट Wikipedia टेबल्स से डेटा निकाल रहा हो। अगर ये तुम्हारा डेटा पकड़ ले, तो सेकंड्स में काम हो जाता है।
ScrapeStorm: AI असिस्टेंस के साथ क्लाउड-आधारित Web Extractor
ScrapeStorm एक AI-पावर्ड web scraping टूल है जो विज़ुअल इंटरफ़ेस को मजबूत AI एल्गोरिद्म्स के साथ जोड़ता है (). तुम URL डालते हो और इसका AI डेटा फील्ड्स अपने आप पहचान लेता है—लिस्ट, टेबल, next-page बटन आदि।
ScrapeStorm क्रॉस-प्लैटफ़ॉर्म (Windows, Mac, Linux) सपोर्ट करता है और डेस्कटॉप व क्लाउड—दोनों मोड देता है। तुम टास्क शेड्यूल कर सकते हो, कई जॉब्स parallel चला सकते हो, और Excel/CSV/JSON में एक्सपोर्ट या डेटाबेस में अपलोड कर सकते हो (). ये ईकॉमर्स और मार्केट रिसर्च में खासा पॉपुलर है, और AI से इमेज/PDF से भी डेटा पार्स कर सकता है।
अगर तुम्हें बड़े या जटिल scraping प्रोजेक्ट्स के लिए स्मार्ट असिस्टेंट चाहिए, तो ScrapeStorm ज़रूर देखो।
Apify: Web Extractor मार्केटप्लेस और ऑटोमेशन प्लेटफ़ॉर्म

Apify सिर्फ scraper नहीं—ये एक web scraping और automation प्लेटफ़ॉर्म है। इसमें तुम “actors” चलाते हो, जो scraping या ब्राउज़र ऑटोमेशन के लिए स्क्रिप्ट्स होते हैं। Apify का असली कमाल है इसका प्री-बिल्ट actors का मार्केटप्लेस जो कॉमन कामों के लिए रेडी मिलता है (). किसी ईकॉमर्स साइट से सारे रिव्यूज़ निकालने हैं? बहुत चांस है उसके लिए actor पहले से मौजूद हो।
डेवलपर्स के लिए Apify Node.js या Python में अपने scrapers लिखकर क्लाउड पर डिप्लॉय करने देता है। ये स्केलेबल, ऑटोमेटेबल और API के जरिए इंटीग्रेटेबल है। Apify उन पावर यूज़र्स और संगठनों के लिए सबसे अच्छा है जो वेब डेटा को रणनीतिक संसाधन मानते हैं—जैसे ongoing बड़े स्केल का scraping या डेटा पाइपलाइन में इंटीग्रेशन।
ParseHub: जटिल साइट्स के लिए विज़ुअल Web Page Extractor

ParseHub एक डेस्कटॉप ऐप है (क्लाउड ऑप्शन के साथ) जो कॉम्प्लेक्स, डायनेमिक वेबसाइटों को संभालने के लिए जाना जाता है। तुम ब्राउज़र जैसी इंटरफ़ेस में साइट नेविगेट करते हो, डेटा पॉइंट्स पर क्लिक करते हो, और ParseHub तुम्हारा scraper बना देता है (). इसमें conditional logic, nested scraping, AJAX कंटेंट जैसी क्षमताएँ हैं।
जब दूसरे टूल्स किसी साइट को सही से scrape नहीं कर पाते, तब अक्सर ParseHub काम आता है। रिसर्चर्स, एनालिस्ट्स और छोटे बिज़नेस ओनर्स इसे tricky वेबसाइटों के लिए इस्तेमाल करते हैं। सीखने में समय लगता है, लेकिन अगर तुम्हारी साइट जटिल है और तुम कोड नहीं लिखना चाहते, तो ParseHub टॉप विकल्प है।
OutWit Hub: कंटेंट आर्काइविंग के लिए डेस्कटॉप Web Extractor

OutWit Hub थोड़ा old-school है, लेकिन ये एक डेस्कटॉप एप्लिकेशन है जो कई तरह के कंटेंट (लिंक्स, इमेज, ईमेल एड्रेस आदि) निकालकर व्यवस्थित करने में अच्छा है (). ये ब्राउज़र और स्प्रेडशीट का मिक्स जैसा लगता है—पेज खोलो और टेबल, लिस्ट, इमेज आदि निकालो।
ये कंटेंट आर्काइविंग या रिसर्च के लिए खास उपयोगी है—जैसे किसी फोरम के सारे पोस्ट scrape करना या फाइलों का कलेक्शन डाउनलोड करना। ये लोकल मशीन पर चलता है, इसलिए डेटा प्राइवेसी तुम्हारे कंट्रोल में रहती है। छोटे-मध्यम scraping कामों के लिए ये सीधा-सादा डेस्कटॉप विकल्प है।
आपकी जरूरत के लिए कौन सा Web Extractor सबसे बेहतर है?
12 टूल्स, हजारों यूज़ केस। तो चुनना कैसे है? ये रहा मेरा चीट शीट:
-
बिल्कुल शुरुआती या one-off क्विक टास्क्स के लिए:
बेसिक टेबल/लिस्ट के लिए Instant Data Scraper ट्राय करो (फ्री और तुरंत)। अगर तुम अक्सर समान पेज scrape करते हो, तो ज्यादा टेम्पलेट्स के साथ Data Miner भी आसान विकल्प है।
-
नॉन-टेक यूज़र्स जिन्हें ongoing scraping या इंटीग्रेशन चाहिए:
Thunderbit का AI-ड्रिवन वर्कफ़्लो सबसे सरल है—बिज़नेस यूज़र्स के लिए जो तेज़ और बार-बार रिज़ल्ट चाहते हैं। Browse AI लगातार मॉनिटरिंग और अलर्ट्स के लिए बढ़िया है। Simplescraper तब अच्छा है जब तुम scraped डेटा को Google Sheets या API के जरिए किसी इंटरनल ऐप में भेजना चाहते हो।
-
जटिल वेबसाइटें या बिना कोड कस्टम वर्कफ़्लो:
Octoparse या ParseHub जैसे विज़ुअल scrapers चुनो। Octoparse यूज़र-फ्रेंडली है और टेम्पलेट्स बहुत हैं। ParseHub बहुत जटिल डायनेमिक साइट्स संभालता है और ज्यादा कंट्रोल देता है। अगर तुम अपने sitemaps सेट करने को तैयार हो, तो WebScraper.io भी अच्छा है।
-
डेवलपर्स/डेटा इंजीनियर्स जिन्हें स्केल चाहिए:
ScraperAPI तुम्हारे सॉफ्टवेयर में web scraping embed करने या बड़े स्केल प्रोजेक्ट्स के लिए बना है। Apify तब परफेक्ट है जब तुम्हें स्केलेबल प्लेटफ़ॉर्म और रेडीमेड/कस्टम स्क्रिप्ट्स का मार्केटप्लेस चाहिए।
-
कंटेंट-हेवी एक्सट्रैक्शन या ऑफ़लाइन उपयोग:
OutWit Hub व्यवस्थित तरीके से कंटेंट कलेक्ट/आर्काइव करने के लिए अच्छा है—खासकर अगर तुम प्राइवेसी/कंट्रोल के लिए डेस्कटॉप टूल पसंद करते हो।
ईमानदारी से कहूँ तो कई टीमें काम के हिसाब से एक से ज़्यादा टूल इस्तेमाल करती हैं। तुम किसी आसान काम के लिए Instant Data Scraper से शुरू कर सकते हो, फिर बड़े प्रोजेक्ट के लिए Thunderbit या Octoparse पर जा सकते हो, और जब प्रोसेस को “इंडस्ट्रियल” बनाना हो तो ScraperAPI या Apify इस्तेमाल कर सकते हो। अच्छी बात ये है कि ज़्यादातर टूल्स में फ्री टियर/ट्रायल होता है—तो टेस्ट करके सही फिट चुन सकते हो।
निष्कर्ष: बिज़नेस टीमों के लिए Web Extracting का भविष्य
web extractor tools ने लंबा सफर तय किया है। 2026 में ये पूरी तरह mainstream हो चुके हैं। सबसे बड़ा ट्रेंड? Web scraping अब ज्यादा आसान, ज्यादा ऑटोमेटेड और रोज़मर्रा के वर्कफ़्लो में ज्यादा इंटीग्रेटेड हो रहा है (). AI-ड्रिवन scrapers की वजह से जटिल और डायनेमिक वेबसाइटें भी बिना स्पेशल स्किल्स के संभाली जा सकती हैं। एक डेटा इंजीनियर के शब्दों में: “जब AI web scraping टूल्स मार्केट में आए, तो मैं काम बहुत तेज़ और बड़े स्केल पर करने लगा... और AI के साथ [data cleaning] अपने आप वर्कफ़्लो में शामिल हो गई।”
एक और बड़ा बदलाव है scraping, monitoring और automation के बीच की सीमाओं का धुंधला होना। Browse AI और Thunderbit जैसे टूल्स सिर्फ डेटा निकालते नहीं—उसे अपडेट रखते हैं और एक्शन भी ट्रिगर कर सकते हैं (जैसे फॉर्म भरना या अलर्ट भेजना)। अपनाने की रफ्तार भी तेज़ है—एक बड़े प्लेटफ़ॉर्म ने एक साल में monthly active users में 140%+ उछाल देखा (). हर आकार की कंपनियाँ समझ रही हैं कि सार्वजनिक वेब डेटा तक पहुँच (नैतिक और कानूनी तरीके से) प्रतिस्पर्धी बने रहने के लिए जरूरी है।
बिज़नेस टीमों के लिए सीख ये है: सशक्तिकरण। तुम्हें डेवलपर का हफ्तों इंतज़ार नहीं करना, और न ही अंदाज़े पर फैसले लेने हैं। इस लिस्ट के टूल्स सेल्स, मार्केटिंग, ऑपरेशंस और उससे आगे के रियल-लाइफ यूज़ केस के लिए बने इंटरफ़ेस और फीचर्स के साथ वेब डेटा की ताकत तुम्हारे हाथ में देते हैं। और जिस तरह चीज़ें आगे बढ़ रही हैं, निकट भविष्य में और भी यूज़र-फ्रेंडली UI, ज्यादा स्मार्ट AI, और BI/analytics प्लेटफ़ॉर्म्स के साथ गहरी इंटीग्रेशन देखने को मिलेगी।
बस याद रखना: वेबसाइट की terms of service और robots.txt नियमों का सम्मान करो, और डेटा प्राइवेसी कानूनों के अनुरूप रहो। Ethical scraping इन प्रैक्टिसेज़ की टिकाऊपन के लिए जरूरी है।
तो चाहे तुम फ्री एक्सटेंशन से शुरुआत करो या एंटरप्राइज़-ग्रेड scraping सेटअप चलाओ—वेब की जानकारी को actionable insights में बदलने का इससे बेहतर समय नहीं रहा। web extractor क्रांति आ चुकी है—एक टूल चुनो, ट्राय करो, और जो वैल्यू सबके सामने छिपी है उसे अनलॉक करो। तुम्हारा डेटा-ड्रिवन भविष्य बस एक क्लिक दूर है।
FAQs
1. Web extractor क्या होता है और यह बिज़नेस के लिए क्यों जरूरी है?
Web extractor ऐसा टूल है जो वेबसाइटों से स्ट्रक्चर्ड डेटा अपने आप इकट्ठा करता है। यह इसलिए जरूरी है क्योंकि यह ऑनलाइन बिखरी जानकारी को actionable insights में बदल देता है—प्रोडक्टिविटी बढ़ाता है, प्रॉफिटेबिलिटी में मदद करता है और मैनुअल डेटा कलेक्शन खत्म करता है।
2. Web extractors कौन इस्तेमाल कर सकता है—क्या टेक्निकल स्किल्स चाहिए?
कई आधुनिक web extractors के लिए टेक्निकल स्किल्स जरूरी नहीं। Thunderbit, Browse AI और Instant Data Scraper जैसे टूल्स नॉन-टेक यूज़र्स के लिए बनाए गए हैं—सहज UI, AI ऑटोमेशन और नो-कोड वर्कफ़्लो के साथ।
3. सेल्स, मार्केटिंग और ऑपरेशंस टीमें web extractors से कैसे फायदा उठा सकती हैं?
सेल्स टीमें ऑनलाइन डायरेक्टरी से लीड लिस्ट बना सकती हैं, मार्केटिंग टीमें कंपटीटर प्राइसिंग मॉनिटर कर सकती हैं, और ऑपरेशंस टीमें डेटा कलेक्शन प्रोसेस ऑटोमेट कर सकती हैं। ये टूल्स समय बचाते हैं, गलतियाँ घटाते हैं और रणनीतिक फैसलों के लिए ताज़ा, भरोसेमंद इनसाइट्स देते हैं।
4. Web extractor टूल चुनते समय किन बातों पर ध्यान दें?
मुख्य फैक्टर्स: इस्तेमाल में आसानी, AI क्षमताएँ, ऑटोमेशन/शेड्यूलिंग, Google Sheets या Airtable जैसे टूल्स के साथ इंटीग्रेशन, स्केलेबिलिटी, और तुम्हारे बिज़नेस यूज़ केस से मेल (जैसे सेल्स लीड्स, प्राइस मॉनिटरिंग, कंटेंट आर्काइविंग)।
5. क्या फ्री या कम-खर्च वाले web extractor टूल्स उपलब्ध हैं?
हाँ, कई web extractors फ्री टियर या किफायती प्लान देते हैं। Instant Data Scraper बेसिक जरूरतों के लिए पूरी तरह फ्री है, जबकि Thunderbit, Simplescraper और Data Miner जैसे टूल्स अच्छे फ्री प्लान और जरूरत के हिसाब से अपग्रेड विकल्प देते हैं।
Web extracting, AI scraping, या वेबसाइटों को तुम्हारी टीम के अगले बड़े फायदे में बदलने के बारे में और जानना है? अधिक गाइड्स, टिप्स और रियल-वर्ल्ड स्टोरीज़ के लिए देखें।