
पिछले हफ्ते, हमारे एक यूज़र ने हमें मैसेज किया: "मुझे शुक्रवार तक 14 प्रतिस्पर्धी Shopify स्टोर्स से कीमतें, विवरण, और वेरिएंट डेटा चाहिए।" यह लगभग 4,000 प्रोडक्ट पेज बनते हैं। कॉपी-पेस्ट? बिल्कुल नहीं।
अगर आपने कभी Shopify स्टोर से प्रोडक्ट डेटा निकालने की कोशिश की है — कीमतें, इमेज, विवरण, वेरिएंट, रिव्यू — तो आप जानते होंगे कि यह कितना झंझट वाला काम है। 2026 तक हैं, और उनमें से किसी में भी "बाहरी लोगों के लिए एक्सपोर्ट" बटन नहीं होता। वहीं, कहते हैं कि वे प्रतिस्पर्धियों की कीमतों पर सक्रिय रूप से नज़र रखते हैं, और ईकॉमर्स सेवा प्रदाता बताते हैं कि वेरिएंट और इमेज के साथ एक भी प्रोडक्ट मैन्युअली अपलोड करने में लग सकते हैं। इसे कुछ सौ प्रोडक्ट्स से गुणा करिए, और आपका पूरा हफ़्ता चला गया।
इसीलिए Shopify स्क्रैपर Chrome एक्सटेंशन ईकॉमर्स टूलकिट का एक ज़रूरी हिस्सा बन गए हैं — प्रतिस्पर्धी रिसर्च, ड्रॉपशिपिंग खोज, कैटलॉग माइग्रेशन, और बहुत कुछ के लिए। लेकिन ज़्यादातर "बेस्ट स्क्रैपर" लेख सिर्फ फीचर्स की लिस्ट देते हैं, यह नहीं दिखाते कि असली Shopify स्टोर्स पर चलाने पर क्या होता है। यह लेख अलग है। मैंने आठ एक्सटेंशनों को असली स्टोरफ्रंट्स पर टेस्ट किया, वास्तविक एंटी-बॉट दीवारों से टकराया, और जाना कि कौन-से टूल आपको ज़रूरी गहरा प्रोडक्ट डेटा देते हैं — और कौन-से सिर्फ ऊपर-ऊपर की जानकारी तक सीमित रह जाते हैं।
ईकॉमर्स टीमों को Shopify स्क्रैपर Chrome एक्सटेंशन की ज़रूरत क्यों होती है
Shopify स्टोर्स में व्यावसायिक रूप से काम आने वाला प्रोडक्ट डेटा बहुत होता है। लेकिन बाहरी व्यक्ति होने के नाते आपको CSV डाउनलोड नहीं मिलता। आपको सिर्फ एक स्टोरफ्रंट दिखता है। उस स्टोरफ्रंट को काम की जानकारी में बदलने के लिए आपको एक स्क्रैपर चाहिए — और उपयोग सिर्फ "प्रोडक्ट नामों की सूची चाहिए" तक सीमित नहीं है।
असल सवाल यह है: आपको किस काम के लिए कौन-सा डेटा चाहिए? नीचे सबसे आम ईकॉमर्स उपयोग मामलों और उनसे जुड़े डेटा फ़ील्ड्स का मैप दिया गया है:
प्रतिस्पर्धी कीमतों पर रिसर्च
आपको चाहिए: प्रोडक्ट शीर्षक, कीमतें, compare-at-prices, और वेरिएंट-स्तर की कीमतें। यह dynamic pricing strategy की बुनियाद है — यानी सिर्फ यह नहीं कि प्रतिस्पर्धी कितना चार्ज करता है, बल्कि यह भी कि वह अलग-अलग साइज़ या रंगों पर छूट, बंडल, और मूल्य निर्धारण कैसे करता है।
ड्रॉपशिपिंग प्रोडक्ट खोज
आपको चाहिए: शीर्षक, सभी इमेज (सिर्फ thumbnails नहीं), पूरी descriptions, और publish dates। सबसे नई publish date के अनुसार sorting करने से आप ट्रेंडिंग या हाल ही में लॉन्च हुए प्रोडक्ट्स को बाज़ार में saturate होने से पहले पकड़ सकते हैं।
अपने स्टोर में कैटलॉग इम्पोर्ट
आपको चाहिए: शीर्षक, body HTML, सभी इमेज, वेरिएंट, SKU, और कीमतें — आदर्श रूप से में। हर टूल यह साफ़-सुथरे ढंग से नहीं देता।
बिक्री गति का अनुमान
आपको चाहिए: प्रोडक्ट शीर्षक और inventory quantities, जिन्हें समय के साथ ट्रैक किया जाए। शेड्यूल के अनुसार inventory level स्नैपशॉट लेकर आप अनुमान लगा सकते हैं कि प्रतिस्पर्धी प्रोडक्ट कितनी तेज़ी से बेच रहा है — यह भले अनुमानित हो, लेकिन उपयोगी proxy होता है जब सीधे बिक्री डेटा उपलब्ध न हो।
लीड जनरेशन (स्टोर मालिकों को ढूँढना)
आपको चाहिए: स्टोर नाम, संपर्क ईमेल, फ़ोन नंबर, और कभी-कभी स्टोर द्वारा उपयोग किए जाने वाले ऐप्स या tech stack। बिक्री टीमें इसका उपयोग niche या technology के आधार पर segmented outreach lists बनाने के लिए करती हैं।
यह रहा एक तेज़ संदर्भ:
| उपयोग मामला | ज़रूरी प्रमुख डेटा फ़ील्ड्स | अनुशंसित वर्कफ़्लो |
|---|---|---|
| प्रतिस्पर्धी कीमत रिसर्च | शीर्षक, कीमत, compare-at-price, वेरिएंट कीमतें | लिस्टिंग पेज स्क्रैप करें + वेरिएंट्स के लिए सबपेज enrichment |
| ड्रॉपशिपिंग प्रोडक्ट खोज | शीर्षक, कीमत, इमेज (सभी), विवरण, publish date | सबपेज स्क्रैप + सबसे नई publish date के अनुसार sort |
| अपने स्टोर में कैटलॉग इम्पोर्ट | शीर्षक, body HTML, इमेज, वेरिएंट, SKU, कीमत | पूरा सबपेज स्क्रैप → Shopify-import CSV में एक्सपोर्ट |
| बिक्री अनुमान | शीर्षक, inventory quantity (समय के साथ) | शेड्यूल्ड स्क्रैपिंग → Google Sheets tracking |
| लीड जनरेशन (स्टोर मालिक) | स्टोर नाम, ईमेल, फ़ोन, उपयोग किए गए ऐप्स | स्टोर संपर्क पेज स्क्रैप करें + email/phone extractors |
मैंने इन 8 Shopify स्क्रैपर Chrome एक्सटेंशनों का मूल्यांकन कैसे किया
मैंने सभी आठ एक्सटेंशन इंस्टॉल किए और उन्हें उन्हीं असली Shopify स्टोर्स पर चलाया — जिनमें public stores, Cloudflare-protected stores, और ऐसे स्टोर्स थे जिनमें products.json disabled था। मैं सिर्फ feature lists नहीं देख रहा था। मैं जानना चाहता था कि जब आप live Shopify collection page पर "scrape" दबाते हैं, तो असल में क्या होता है।
मैंने ये आठ मानदंड इस्तेमाल किए, और हर एक Shopify के लिए खास तौर पर क्यों मायने रखता है:
| मानदंड | Shopify स्क्रैपिंग में इसका महत्व |
|---|---|
| सेटअप की आसानी | क्या कोई non-technical dropshipper 5 मिनट के भीतर स्क्रैपिंग शुरू कर सकता है? |
| निकाले गए डेटा फ़ील्ड्स | क्या यह title, price, images, descriptions, variants, और reviews निकालता है — या सिर्फ सतही डेटा? |
| सबपेज enrichment | क्या यह listing page स्क्रैप करके फिर हर product page पर जाकर पूरी जानकारी जोड़ सकता है? |
| Pagination handling | क्या यह प्रोडक्ट्स के पहले पेज के आगे भी स्क्रैप कर सकता है (pagination click या infinite scroll)? |
| एंटी-बॉट मजबूती | क्या यह Cloudflare Turnstiles या Shopify की bot protection को बिना टूटे संभाल सकता है? |
| एक्सपोर्ट फ़ॉर्मैट | CSV, Excel, Google Sheets, Airtable, Notion, Shopify-import-ready CSV? |
| Scheduled/recurring scraping | क्या यह कीमतों या inventory बदलावों को समय के साथ अपने आप मॉनिटर कर सकता है? |
| मूल्य पारदर्शिता | फ्री टियर सीमाएँ, credit system, flat-fee — और आपको वास्तव में क्या मिलता है |
अब इस framework के साथ, देखते हैं हर टूल ने कैसा प्रदर्शन किया।
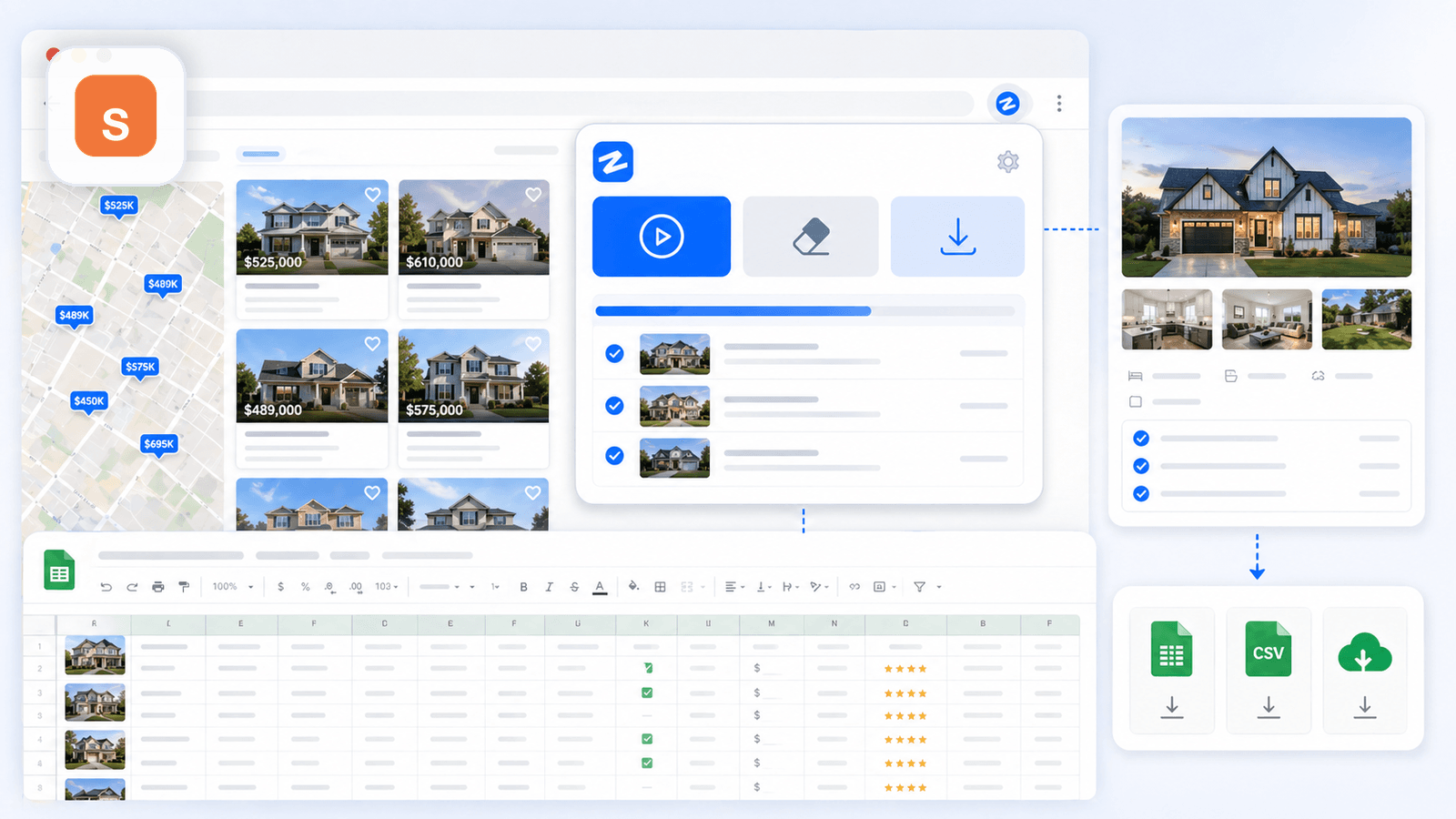
1. Thunderbit — नॉन-कोडर्स के लिए बनाया गया AI-संचालित Shopify स्क्रैपर
वह टूल है जिसे हमने Thunderbit में खास तौर पर business users के लिए बनाया है, जो बिना कोड लिखे, CSS selectors configure किए बिना, या setup पर 20 मिनट लगाए बिना गहरा प्रोडक्ट डेटा चाहते हैं। Shopify स्टोर पर workflow सचमुच दो क्लिक का है: collection page खोलिए, "AI Suggest Fields" पर क्लिक कीजिए, और AI पेज पढ़कर columns सुझा देता है (title, price, image, आदि)। फिर "Scrape" पर क्लिक कीजिए, और listing page तैयार।
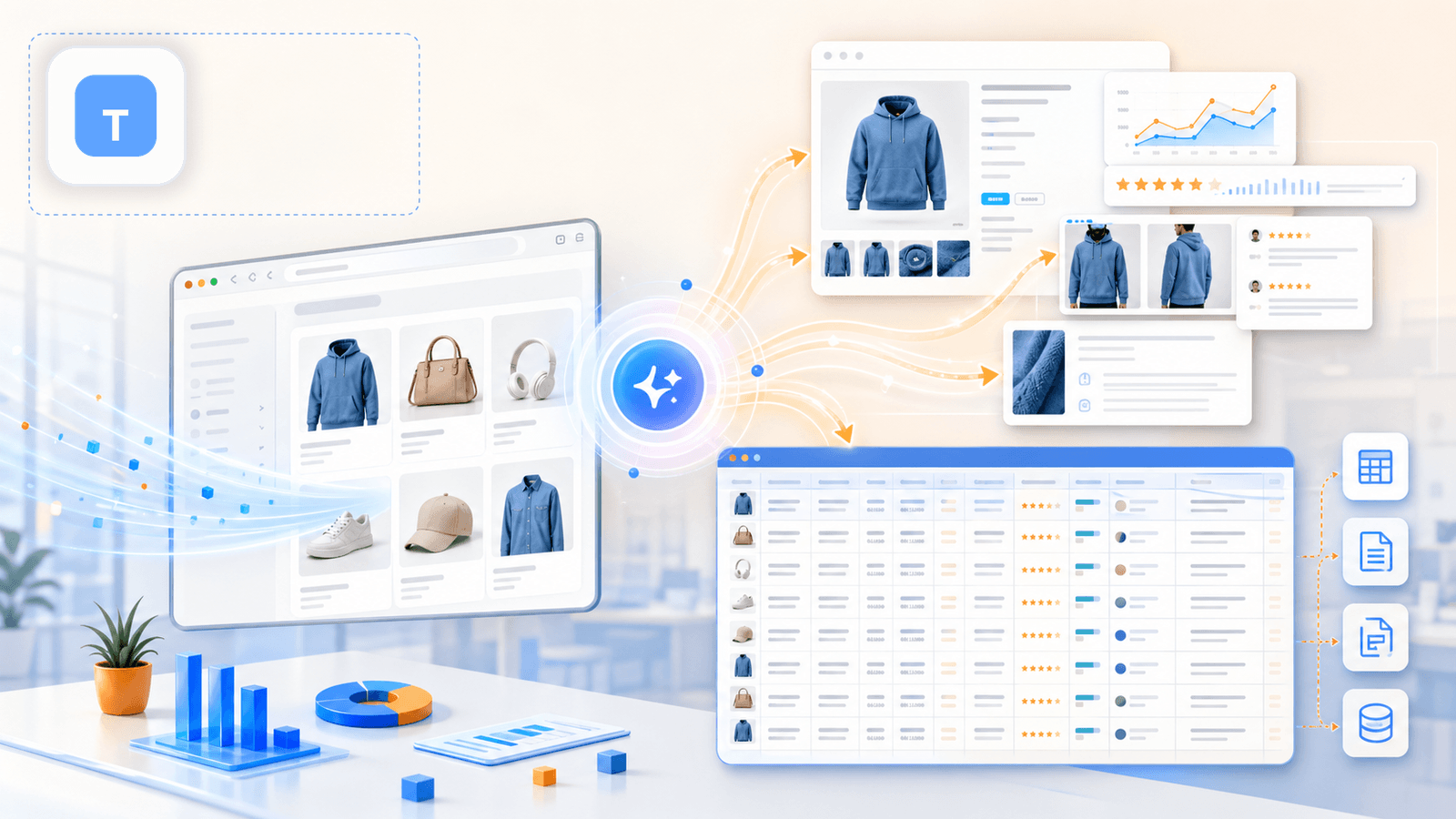
लेकिन असली फर्क — और वह चीज़ जिसे ज़्यादातर प्रतिस्पर्धी लेख नज़रअंदाज़ करते हैं — यह है कि इसके बाद क्या होता है।
सबपेज enrichment: वह फीचर जो सब कुछ बदल देता है
Listing page स्क्रैप करने के बाद, आप "Scrape Subpages" पर क्लिक करते हैं। Thunderbit का AI हर individual product URL पर जाता है और detail-page data को आपकी मूल table में जोड़ देता है: पूरी descriptions, सभी gallery images, variant options, SKUs, review counts, और भी बहुत कुछ। यही वह चरण है जो एक साधारण spreadsheet को काम के competitive-research dataset में बदल देता है।
मैं नीचे एक अलग सेक्शन में यह गहराई से बताऊँगा कि यह क्यों ज़रूरी है (और before/after comparison भी दिखाऊँगा)।
Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- AI Suggest Fields Shopify पेज को पढ़कर सही column structure अपने आप बना देता है — CSS selectors की ज़रूरत नहीं, मैन्युअल setup नहीं
- Subpage scraping listing pages से छूट जाने वाले data gaps भर देता है (पूरी descriptions, variant options, image galleries, reviews)
- Cloud scraping mode public stores पर तेज़ bulk extraction के लिए; browser scraping mode Cloudflare-protected या login-required stores के लिए
- Pagination handling (click-based और infinite scroll)
- Scheduled scraping ongoing price/inventory monitoring के लिए — शेड्यूल को साधारण अंग्रेज़ी में बताइए (जैसे, "हर सोमवार सुबह 9 बजे")
- मुफ़्त email और phone extractors lead gen use cases के लिए
- Excel, Google Sheets, Airtable, Notion, CSV, JSON में export — Shopify-import-friendly formats सहित
- Field AI Prompt आपको हर column के लिए custom instructions जोड़ने देता है (जैसे, "3 product types में categorize करें" या "description को English में translate करें")
कहाँ कमज़ोर पड़ता है
- Credit-based pricing का मतलब है कि बहुत बड़े पैमाने पर scraping (दसियों हज़ार प्रोडक्ट्स) के लिए paid plan चाहिए
- बहुत ही सरल pages पर template-based scrapers की तुलना में AI processing में कुछ सेकंड अतिरिक्त लगते हैं
मूल्य निर्धारण
- Free tier: 6 pages (या free trial के साथ 10 तक), सभी exports मुफ्त
- Starter: , 500 credits/month
- Professional tiers: $38/month (3,000 credits) से लेकर $249/month (20,000 credits) तक
- Credit rules: web scraping के लिए 1 output row = 1 credit; subpage scraping के लिए 1 output row = 2 credits; exports हमेशा free हैं
Best for: non-technical ecommerce teams जिन्हें minimal setup के साथ सबसे गहरा Shopify product data चाहिए — और जो समय के साथ competitors को monitor करना चाहते हैं।
2. Instant Data Scraper — बिना कॉन्फ़िगरेशन वाला auto-detect विकल्प
Instant Data Scraper एक free Chrome extension है जो heuristic algorithms का उपयोग करके web pages पर tabular data auto-detect करता है। इसमें कोई configuration नहीं होती — Shopify collection page खोलिए, extension icon पर क्लिक कीजिए, और यह product data को table में detect करके दिखाने की कोशिश करता है।
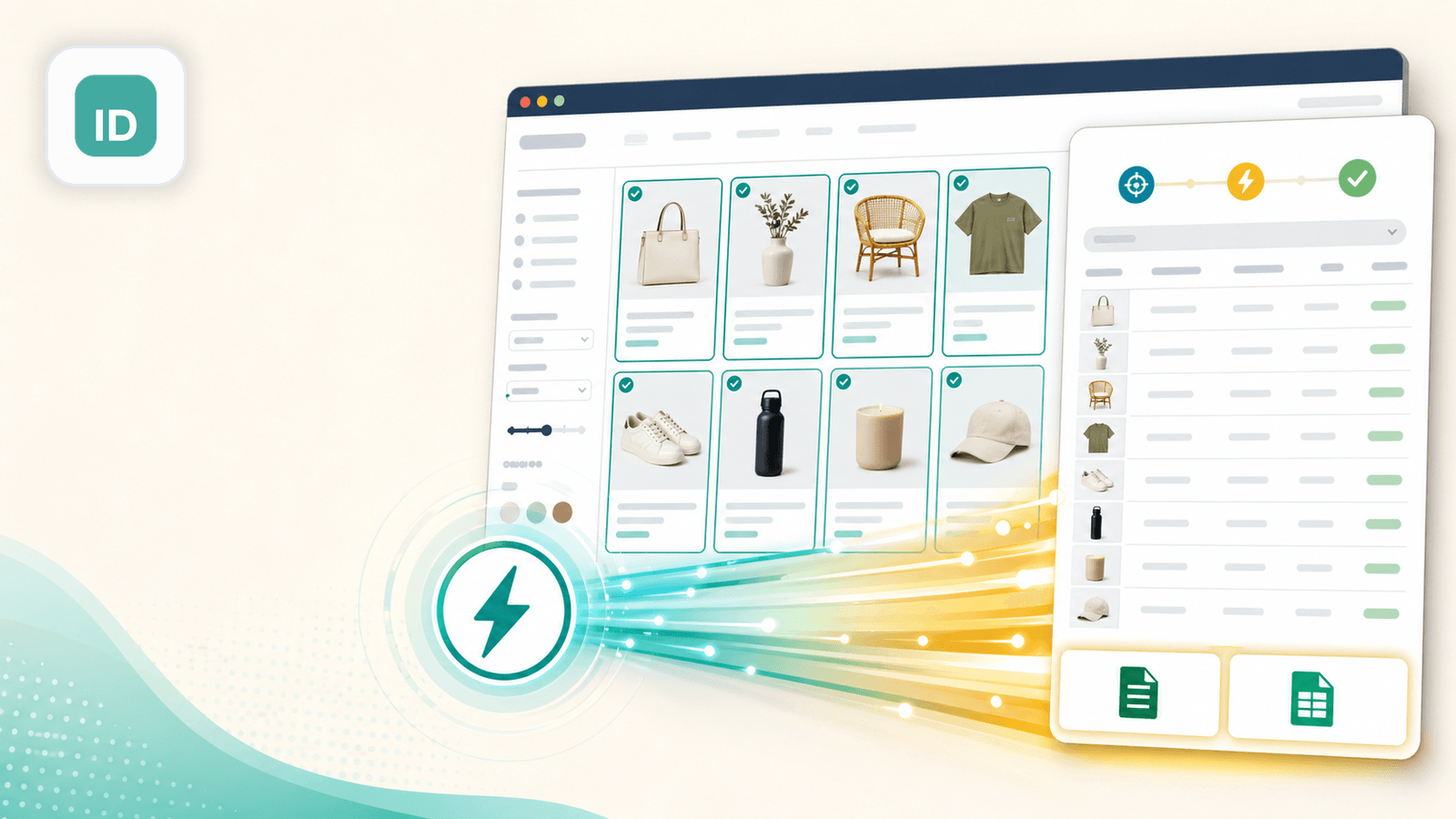
मेरे परीक्षण में, यह standard Shopify Dawn-theme collection pages पर अच्छी तरह चला, और कुछ ही सेकंड में titles, prices, और thumbnail image URLs पकड़ लिए। लेकिन non-standard layouts वाले स्टोर्स पर यह कभी-कभी products की जगह navigation links या footer content उठा लेता था — output को ध्यान से देखना पड़ता है।
Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- पूरी तरह मुफ़्त, कोई usage limit नहीं
- Auto-detection के कारण zero setup time — जल्दी, एक बार के exports के लिए बढ़िया
- Pagination सपोर्ट करता है ("next page" अपने आप click कर सकता है)
- CSV और XLSX में export
कहाँ कमज़ोर पड़ता है
- Non-standard layouts वाले Shopify स्टोर्स पर auto-detection कभी सही, कभी गलत
- कोई subpage enrichment नहीं: listing page पर जो है वही मिलता है (title, price, thumbnail), लेकिन पूरी descriptions, variants, या reviews नहीं
- डेटा को साफ़ करने, label करने, या transform करने के लिए कोई AI नहीं
- कोई scheduling नहीं, कोई cloud scraping नहीं
- Google Sheets, Airtable, या Notion में direct export नहीं
मूल्य निर्धारण
- पूरी तरह मुफ़्त
Best for: कोई भी व्यक्ति जिसे standard Shopify store से visible listing-page data का तेज़, मुफ़्त, बिना setup वाला export चाहिए।
3. Web Scraper — विज़ुअल sitemap builder
Web Scraper (webscraper.io) क्लासिक point-and-click Chrome extension है जो "sitemaps" बनाने के लिए इस्तेमाल होती है — यानी scraping recipes, जहाँ आप पेज पर elements चुनते हैं और scraping flow define करते हैं। Shopify पर, आप product titles, prices, images पर क्लिक करके sitemap बनाते हैं, और pagination तथा link-following rules तय करते हैं।
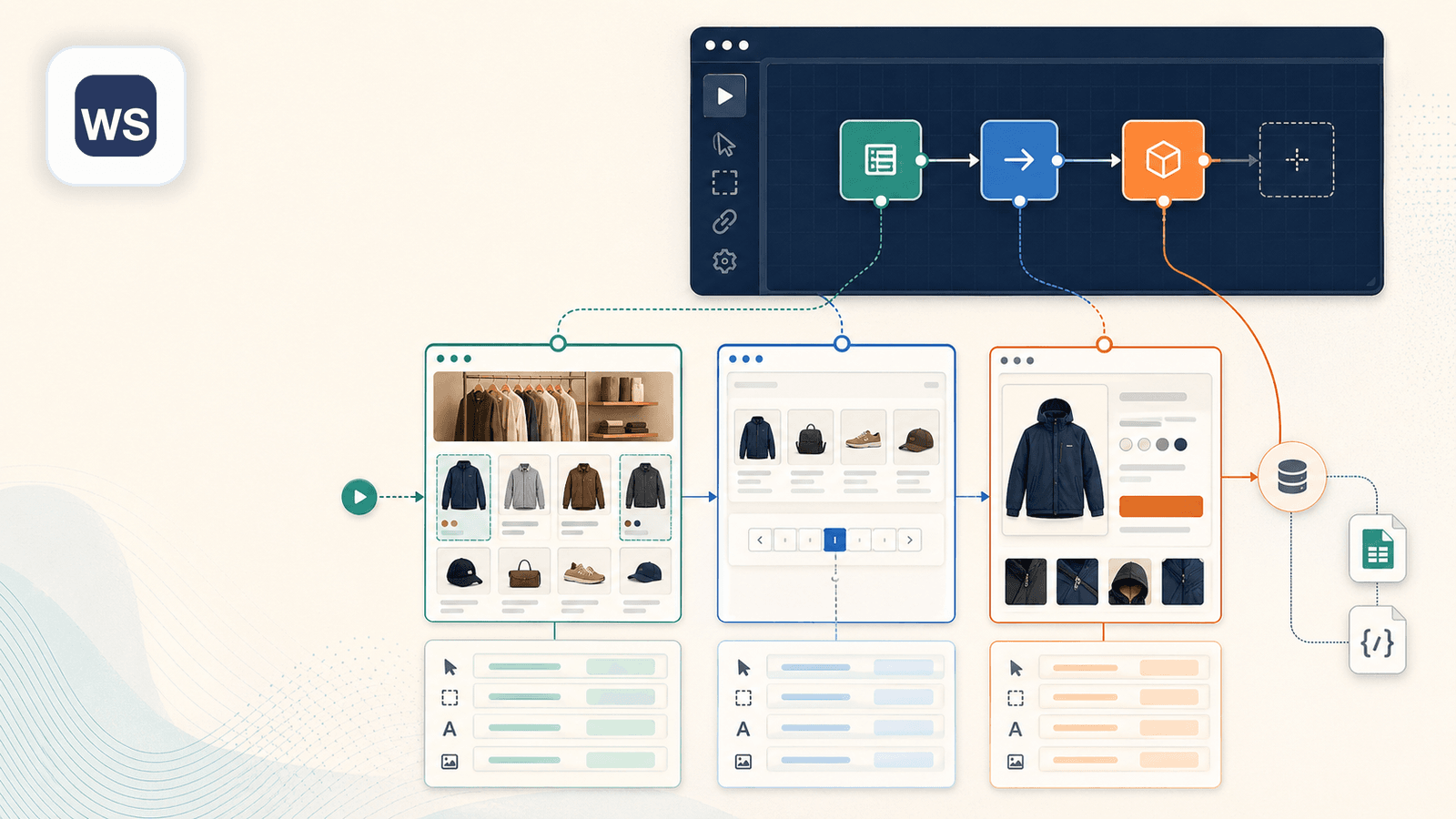
Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- Visual selector builder auto-detect tools की तुलना में ज़्यादा नियंत्रण देता है
- Subpages (product detail pages) के links follow कर सकता है — लेकिन इसके लिए sitemap में parent-child selectors मैन्युअल रूप से configure करने पड़ते हैं
- Proper setup के साथ pagination संभालता है
- Free browser-based scraping; paid cloud scraping plans उपलब्ध (from $50/month)
- CSV में export; cloud plans Google Sheets और अन्य formats सपोर्ट करते हैं
कहाँ कमज़ोर पड़ता है
- Setup में ज़्यादा समय लगता है: नए Shopify store के लिए parent-child selectors वाला sitemap बनाने में मुझे लगभग 15 मिनट लगे
- Subpage scraping के लिए चाहिए — यह one-click enrichment नहीं है
- Shopify stores का layout या CSS classes बदलने पर sitemaps टूट सकते हैं
- Learning curve AI-powered alternatives की तुलना में अधिक है
मूल्य निर्धारण
- Browser extension: मुफ़्त
- Cloud plans: Project $50/month, Professional $100/month, Scale $200/month से शुरू
Best for: technical users जो अपनी scraping flow पर granular control चाहते हैं और recipe खुद बनाना पसंद करते हैं।
4. Data Miner — recipe-आधारित स्क्रैपर
Data Miner (dataminer.io) "recipes" के आसपास बना है — pre-built या custom scraping templates जिन्हें आप किसी पेज पर लागू करते हैं। इसमें public recipe library है, इसलिए आपको किसी दूसरे user द्वारा साझा किया गया Shopify template मिल सकता है, या आप पेज पर elements चुनकर अपना खुद का बना सकते हैं।
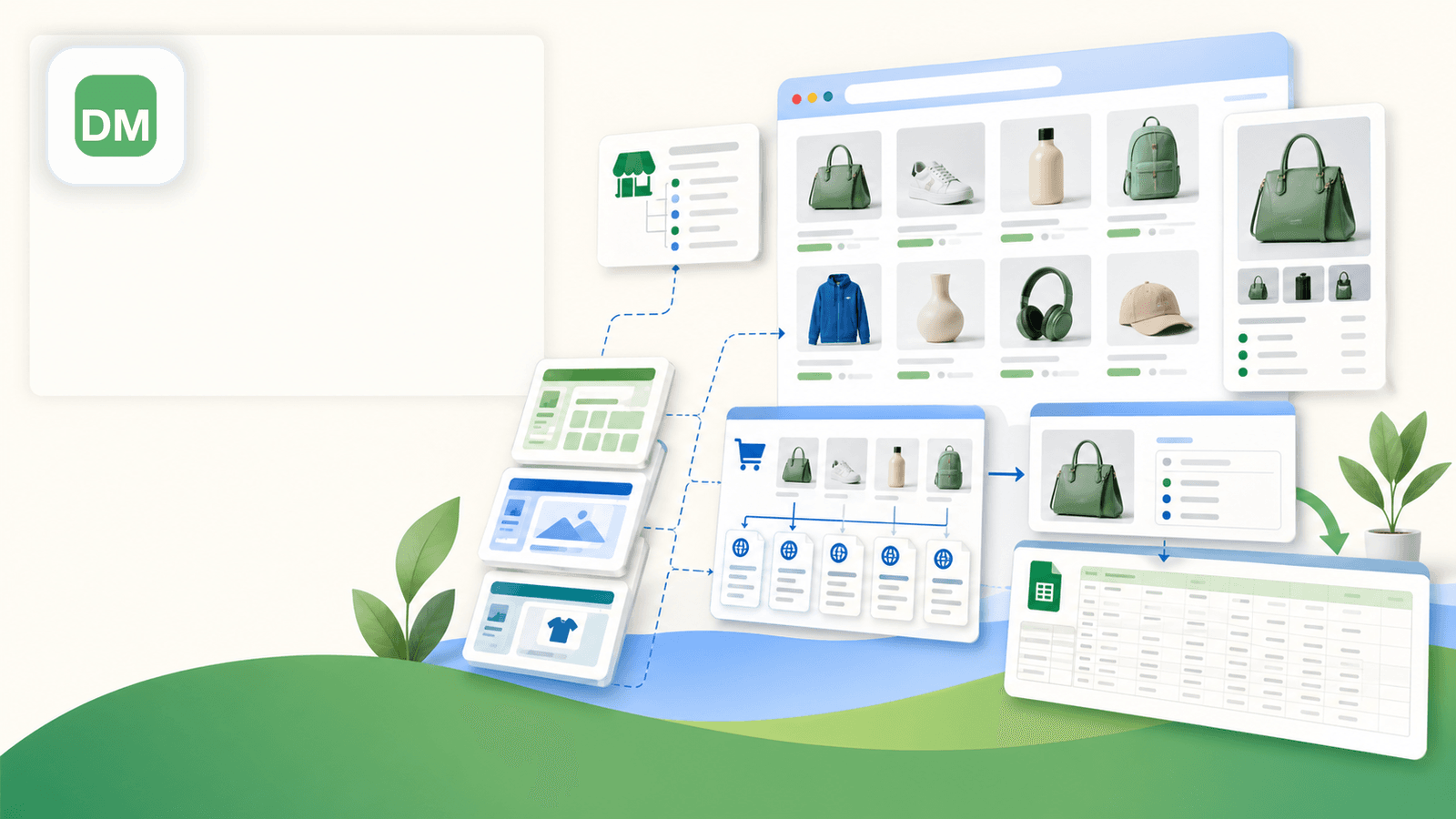
Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- Recipe library में अन्य users द्वारा साझा किए गए pre-built Shopify templates हो सकते हैं
- Custom scraping configurations के लिए visual recipe builder
- Recipe configuration के साथ pagination संभालता है
- CSV, Excel, Google Sheets, और TSV में export
- List pages के बाद detail pages पर जाने के लिए crawl workflows
कहाँ कमज़ोर पड़ता है
- Free tier 500 pages/month तक सीमित है
- Recipes CSS-selector-based हैं, इसलिए store layouts बदलने पर टूट जाती हैं
- AI-powered field suggestion या data transformation नहीं
- Built-in one-click subpage enrichment workflow नहीं — detail pages के लिए अलग crawl recipe चाहिए
- Scheduled crawls मौजूद हैं, लेकिन scheduling का अनुभव सबसे आसान नहीं है
मूल्य निर्धारण
- Free: 500 pages/month
- Solo: $19.99/month
- Small Business: $49/month
- Business: $99/month
- Business Plus: $200/month
Best for: वे users जिन्हें templates के साथ काम करना पसंद है और जो common sites पर setup तेज़ करने के लिए recipe library चाहते हैं।
5. Simplescraper — हल्का-फुल्का extractor
Simplescraper (simplescraper.io) एक minimalist Chrome extension और cloud-based scraper है जो simplicity पर ज़ोर देता है। आप Shopify page पर data elements पर क्लिक करते हैं, Simplescraper CSS selectors generate करता है, और matching data extract करता है।
Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- साफ़, minimal interface — सीखने में तेज़
- Scheduled और bulk jobs के लिए cloud scraping उपलब्ध
- Developers के लिए API access, जो scraped data को workflows में जोड़ना चाहते हैं
- CSV, JSON, Google Sheets, Airtable, और webhooks के ज़रिए export
- Detail pages के links follow करने के लिए deep scraping concept
- Session-sensitive stores के लिए login-capable workflows
कहाँ कमज़ोर पड़ता है
- Manual selector-based approach — fields auto-detect करने के लिए AI नहीं
- Subpage scraping के लिए अतिरिक्त configuration चाहिए
- Web Scraper या Data Miner की तुलना में community छोटी और pre-built templates कम
- Free tier: 100 credits (1 JS-rendered page = 2 credits)
- Official site पर paid tier pricing peers की तुलना में कम पारदर्शी है
मूल्य निर्धारण
- Free: 100 credits
- Paid plans: third-party sources के अनुसार Plus लगभग ~$39/month, Pro ~$70/month, Premium ~$150/month (G2 pricing data के अनुसार)
Best for: वे users जिन्हें अच्छा integration वाला हल्का modern cloud scraper चाहिए और AI-powered field detection की ज़रूरत नहीं है।
6. Octoparse — desktop-powered Chrome extension
Octoparse (octoparse.com) मुख्यतः एक desktop application है, जिसके साथ एक companion Chrome extension भी आता है। यह visual workflow builder और लोकप्रिय sites के लिए pre-built templates दोनों देता है, जिनमें Shopify-specific scraping tutorial भी शामिल है।

Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- आम scraping tasks के लिए pre-built Shopify templates
- शक्तिशाली desktop app, जिसमें advanced features हैं: IP rotation, scheduled scraping, cloud extraction
- Pagination, infinite scroll, और AJAX-loaded content को अच्छी तरह संभालता है
- इस सूची में सबसे मज़बूत documented anti-bot handling, जिसमें automatic CAPTCHA handling भी शामिल है
- CSV, Excel, JSON, HTML, XML, databases, और Google Sheets में export
कहाँ कमज़ोर पड़ता है
- सिर्फ Chrome extension अपने आप में सीमित है — ज़्यादातर power features के लिए desktop app चाहिए
- Desktop app का visual workflow builder सीखने में कठिन है
- Free tier सीमित है; सार्थक उपयोग के लिए paid plan चाहिए
- Pure Chrome extension tools की तुलना में setup भारी है — 5 मिनट वाले quick scrape के लिए आदर्श नहीं
- Desktop app केवल Windows/Mac पर है (सिर्फ browser-based नहीं)
मूल्य निर्धारण
- Free plan उपलब्ध
- Basic: $39/month
- Standard: लगभग $83/month (monthly), लगभग $75/month (annual)
- Professional: लगभग $299/month (monthly), लगभग $208/month (annual)
- Enterprise: custom
Best for: वे teams जिन्हें IP rotation, anti-bot handling, और recurring cloud jobs के साथ enterprise-scale scraping चाहिए — और जिन्हें desktop app से दिक्कत नहीं।
7. Bardeen — automation-first स्क्रैपर
Bardeen (bardeen.ai) एक browser automation platform है जो web scraping को workflow automation के साथ जोड़ता है। Users "playbooks" बनाते हैं जो data scrape कर सकते हैं और फिर उसे दूसरे apps में भेज सकते हैं — इसे ऐसे समझिए: "अगर मैं यह scrape करूँ, तो इसे अपने CRM में push कर दूँ।"

Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- Scraping से आगे workflow automation: Shopify data scrape करें → enrich करें → एक ही playbook में CRM या spreadsheet में push करें
- 100+ apps के साथ integration (Google Sheets, Airtable, Notion, HubSpot, Slack, आदि)
- डेटा extraction और classification के लिए AI-powered features
- Browser में चलता है — desktop app की ज़रूरत नहीं
- शेड्यूलिंग के लिए time/date-based automations
कहाँ कमज़ोर पड़ता है
- यह मुख्यतः automation tool है, dedicated scraper नहीं — इसकी scraping capabilities specialized tools जितनी गहरी नहीं
- Playbook बनाना उन users के लिए उलझन भरा हो सकता है जिन्हें सिर्फ product list निकालनी है
- Free tier 100 credits तक सीमित
- Subpage enrichment और pagination handling dedicated scraping tools जितने सहज नहीं
- यदि downstream automation नहीं चाहिए, तो यह ज़रूरत से ज़्यादा भारी समाधान है
मूल्य निर्धारण
- Free: 100 credits
- Basic: $10/month, 100 credits/month
- Premium: $50/month, 1,000 credits/month (~$40/month annually)
- Enterprise: custom
- Credit model: scraper row पर 1 credit, enrichment row पर 3 credits
Best for: वे teams जो Shopify data scrape करके उसे तुरंत downstream apps (CRMs, spreadsheets, Slack) में एक automated workflow के ज़रिए भेजना चाहते हैं।
8. Listly — list-to-spreadsheet कन्वर्टर
Listly (listly.io) खास तौर पर web page lists और tables को spreadsheet-ready data में बदलने के लिए बनाया गया है। Shopify collection page पर extension क्लिक कीजिए, और Listly product list detect करके उसे spreadsheet के रूप में export करने की कोशिश करता है।

Shopify स्क्रैपिंग के लिए प्रमुख ताकतें
- बेहद सरल interface — one-click list extraction के लिए बनाया गया
- दोहराए जाने वाले list structures (जैसे product grids) को पहचानने में अच्छा
- सीधे Excel और Google Sheets में export
- Group scraping feature, जिससे एक साथ कई URLs प्रोसेस किए जा सकते हैं
- Business plans पर scheduling उपलब्ध
कहाँ कमज़ोर पड़ता है
- सिर्फ वही निकालता है जो पेज पर auto-detect होता है — custom field configuration नहीं
- Subpage enrichment नहीं — सिर्फ listing-page-level data export करता है
- Non-standard Shopify themes या भारी JavaScript rendering वाले stores पर संघर्ष करता है
- Free tier बहुत सीमित है (10 URLs/month)
- प्रतिस्पर्धियों की तुलना में export विकल्प सीमित हैं (मुख्यतः Excel और Sheets)
मूल्य निर्धारण
- Free: 10 URLs/month, basic 1-page extraction, Excel download, Google Sheet export
- Light: $30/month ($187.20/year annually)
- Business: $90/month ($993.60/year annually) — advanced extraction, group extraction, scheduling, auto-scroll/click, API beta जोड़ता है
Best for: वे users जिन्हें Shopify collection page से spreadsheet तक जाने का सबसे सरल रास्ता चाहिए — और जिन्हें गहरा प्रोडक्ट डेटा नहीं चाहिए।
सभी 8 Shopify स्क्रैपर Chrome एक्सटेंशनों की तुलना
यहाँ पूरा side-by-side दिया गया है। मैंने हर सेल में सिर्फ box tick करने के बजाय विशिष्ट जानकारी देने की कोशिश की है — क्योंकि "pagination सपोर्ट करता है" का मतलब टूल के हिसाब से बहुत अलग हो सकता है।
| टूल | सेटअप की आसानी | डेटा फ़ील्ड्स | सबपेज enrichment | Pagination | एंटी-बॉट हैंडलिंग | एक्सपोर्ट फ़ॉर्मैट | Scheduling | Free Tier / मूल्य |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | बहुत आसान (AI-led, 2 क्लिक) | non-technical users के लिए सबसे मज़बूत (AI सभी प्रासंगिक फ़ील्ड सुझाता है) | हाँ — one-click enrichment | हाँ (click + infinite scroll) | public के लिए cloud, protected के लिए browser | Sheets, Airtable, Notion, CSV, JSON, Excel | हाँ (साधारण अंग्रेज़ी scheduling) | 6 pages मुफ़्त; paid $15/mo से |
| Instant Data Scraper | बेहद आसान (zero config) | सिर्फ listing-level डेटा के लिए अच्छा | नहीं | हाँ (next page auto-detect) | सिर्फ browser, anti-bot story नहीं | CSV, XLSX | नहीं | मुफ़्त |
| Web Scraper | मध्यम-कठिन (manual sitemap) | sitemap ठीक से बने तो लचीला | हाँ, लेकिन link selectors के ज़रिए manual | हाँ (sitemap config के साथ) | स्थानीय browser; cloud plans पर proxy rotation | स्थानीय रूप से CSV; cloud पर व्यापक | cloud plans पर हाँ | मुफ़्त extension; cloud $50/mo से |
| Data Miner | मध्यम (recipe-based) | recipe मौजूद हो या बनाया जाए तो अच्छा | हाँ, लेकिन multi-step crawl setup | हाँ (recipe config) | ज़्यादातर browser-side | CSV, Excel, Sheets, TSV | automated crawls मौजूद | 500 pages/mo मुफ़्त; paid $19.99/mo से |
| Simplescraper | आसान-मध्यम (selector-based) | हल्की extraction के लिए मज़बूत | Deep scraping मौजूद है, लेकिन one-click नहीं | हाँ (infinite scroll सपोर्टेड) | proxy rotation और login-friendly | CSV, JSON, Sheets, Airtable, webhooks | हाँ | 100 credits मुफ़्त; paid tiers उपलब्ध |
| Octoparse | कठिन (desktop app) | configure होने पर बहुत मज़बूत | हाँ, workflows या templates के ज़रिए | हाँ (AJAX, infinite scroll) | सबसे मज़बूत anti-bot (IP rotation, CAPTCHA) | CSV, Excel, JSON, HTML, XML, DBs, Sheets | Standard+ पर हाँ | मुफ़्त; Basic $39/mo; cloud लगभग $83/mo से |
| Bardeen | मध्यम (playbook builder) | automation से जुड़ा हो तो अच्छा | workflow logic में संभव, Shopify-first नहीं | संभव | browser में चलता है, anti-bot core नहीं | CSV, Sheets, Airtable, Notion | automations के ज़रिए हाँ | 100 credits मुफ़्त; Basic $10/mo; Premium $50/mo |
| Listly | बेहद आसान (one-click list detect) | visible list rows के लिए सबसे अच्छा | नहीं | detected list structure तक सीमित | न्यूनतम | Business पर Excel, Sheets, CSV/JSON API | Business पर हाँ | 10 URLs/mo मुफ़्त; Light $30/mo; Business $90/mo |
प्राथमिकता के अनुसार तेज़ निष्कर्ष
अगर आपको minimal setup के साथ सबसे गहरा Shopify product data चाहिए, तो Thunderbit का AI + subpage enrichment सबसे मज़बूत संयोजन है। अगर आपको पूरी तरह मुफ़्त, जल्दी-फुर्तीला export चाहिए, तो साधारण pages के लिए Instant Data Scraper काम करता है। अगर आप पूरा नियंत्रण चाहते हैं और recipe बनाने में दिक्कत नहीं, तो Web Scraper या Octoparse वह ताक़त देते हैं। और अगर आपका असली लक्ष्य scrape → automate → CRM में push है, तो Bardeen देखने लायक workflow platform है।
सिर्फ listing page स्क्रैप करना आधा काम है: subpage enrichment workflow
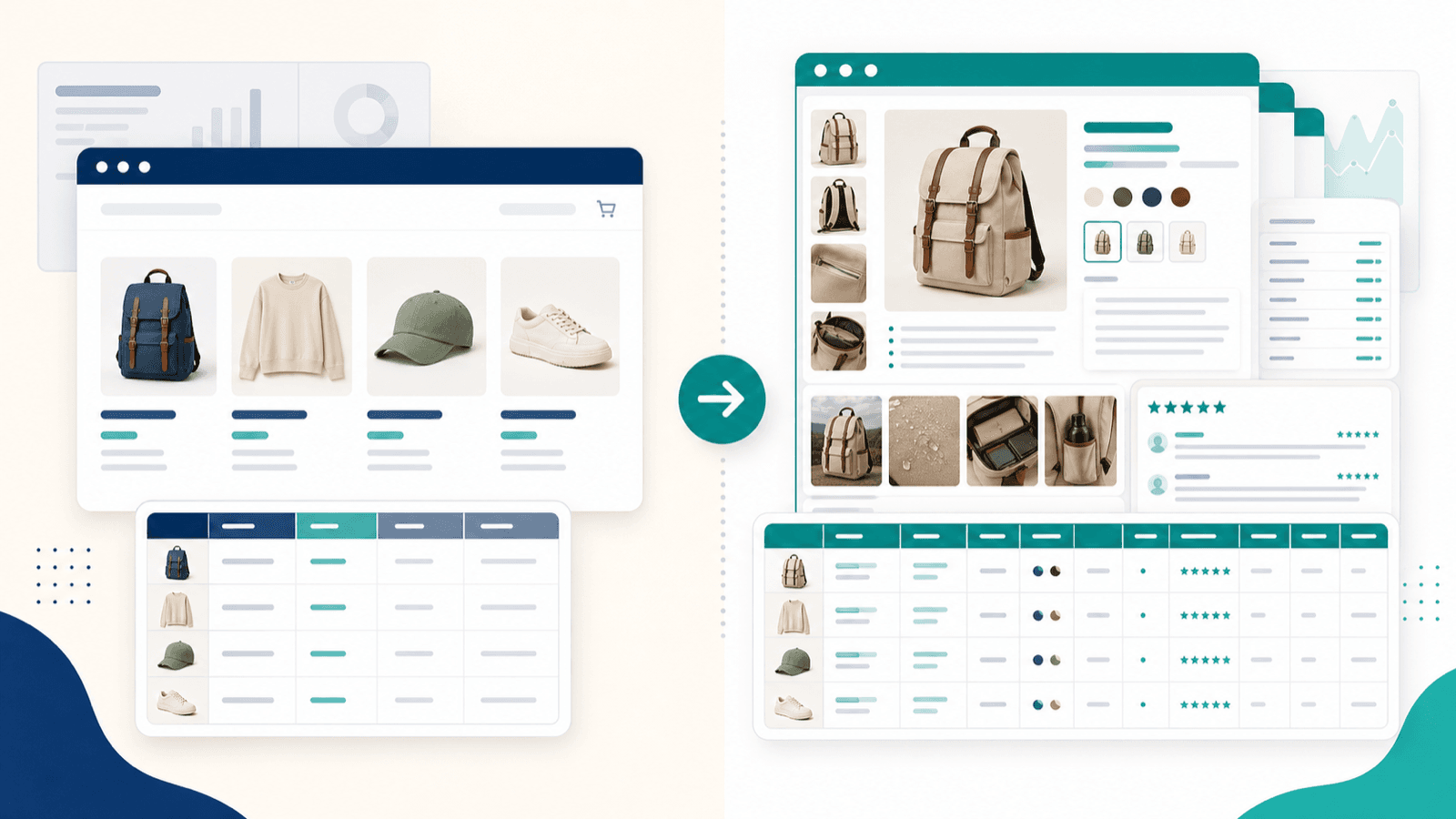
यह वह हिस्सा है जिसे मैं चाहता हूँ कि हर दूसरा Shopify scraper लेख शामिल करे — क्योंकि यही प्रतिस्पर्धी कंटेंट में सबसे बड़ा gap है, और ईकॉमर्स users से सुनने वाली #1 निराशा भी यही है।
जब आप Shopify collection page (listing page) स्क्रैप करते हैं, तो आपको surface-level data मिलता है: शीर्षक, कीमतें, thumbnails, शायद एक truncated description। लेकिन competitor analysis, catalog import, या dropshipping research के लिए असली ज़रूरी फ़ील्ड individual product detail pages पर होते हैं।
Listing page से आपको क्या मिलता है बनाम subpage enrichment के बाद
| डेटा फ़ील्ड | सिर्फ listing page से | Subpage enrichment के बाद |
|---|---|---|
| प्रोडक्ट शीर्षक | ✅ | ✅ |
| कीमत | ✅ | ✅ |
| Thumbnail image | ✅ | ✅ + सभी gallery images |
| छोटी description | ⚠️ Truncated | ✅ पूरी HTML description |
| Variants (size, color) | ❌ | ✅ |
| SKU / Inventory | ❌ | ✅ |
| Reviews / Ratings | ❌ | ✅ |
यह बहुत बड़ा अंतर है।
Listing-page-only export आपको एक shallow spreadsheet देता है। Subpage-enriched export आपको काम का competitive-research dataset देता है।
Thunderbit में subpage scraping कैसे काम करता है (स्टेप बाय स्टेप)
- Shopify store के collection/listing page पर जाएँ
- "AI Suggest Fields" पर क्लिक करें — Thunderbit पेज पढ़कर columns सुझाता है (title, price, image, link, आदि)
- Listing-page data निकालने के लिए "Scrape" पर क्लिक करें
- "Scrape Subpages" पर क्लिक करें — AI हर product URL पर जाता है और detail-page data (पूरी description, सभी images, variants, reviews) मूल table में जोड़ देता है
- Enriched table को Excel, Google Sheets, Airtable, Notion, या CSV में export करें
पूरी प्रक्रिया आम collection के लिए कुछ मिनट लेती है, और अंत में आपके पास ऐसा dataset होता है जिसे मैन्युअली जोड़ने में घंटों लग जाते।
कौन-से अन्य टूल subpage enrichment सपोर्ट करते हैं?
- Web Scraper: हाँ, लेकिन link selectors और child sitemaps के साथ manual sitemap configuration चाहिए — प्रति स्टोर 15-20 मिनट की setup अपेक्षित
- Octoparse: हाँ, workflow builder या templates के ज़रिए — शक्तिशाली, लेकिन setup भारी
- Data Miner: हाँ, multi-step crawl workflows के ज़रिए — one-click नहीं
- Simplescraper: Deep scraping concept मौजूद है, लेकिन कम turnkey
- Instant Data Scraper, Listly, Bardeen: Shopify के लिए documented one-click subpage enrichment नहीं
"20 मिनट की manual setup के साथ links follow कर सकता है" और "one-click enrichment" के बीच का अंतर scraper engineers के लिए बने टूल और ecommerce operators के लिए बने टूल का अंतर है।
जब Shopify का products.json काम नहीं करता — और क्यों Chrome extensions आपका backup plan हैं
अगर आपने दूसरे Shopify scraping guides पढ़े हैं, तो आपने शायद /products.json trick देखी होगी: बस Shopify store URL में /products.json जोड़ दीजिए और आपको JSON format में structured product data मिल जाता है। यह एक असली endpoint है, और जब काम करता है, तो बहुत उपयोगी है।
products.json कैसे काम करता है
Shopify stores /products.json पर एक expose करते हैं जो structured product data लौटाता है। आप ?page=2&limit=250 के साथ paginate कर सकते हैं (एक page पर अधिकतम 250 products)।
आमतौर पर लौटने वाले fields में शामिल हैं: title, body_html, vendor, product_type, tags, published_at, variants (price, compare_at_price, sku, available के साथ), और images।
products.json क्या नहीं देता
- Review data या rating counts नहीं
- Rendered pages की तुलना में description formatting सीमित
- Custom metafields अक्सर शामिल नहीं होते
- Variant-level images असंगत हो सकती हैं
- Rendered merchandising content, badges, या social proof नहीं
products.json कब टूटता है
मैंने 27 अप्रैल 2026 को आठ असली Shopify storefronts पर direct HTTP checks चलाए। नतीजे काफ़ी बताने वाले थे:
| स्टोर | परिणाम |
|---|---|
| kith.com | ✅ काम किया — साफ़ JSON |
| colourpop.com | ✅ काम किया |
| allbirds.com | ✅ काम किया |
| brooklinen.com | ✅ काम किया |
| negativeunderwear.com | ✅ काम किया |
| gymshark.com | ❌ ब्लॉक — JSON की जगह 403 HTML |
| mvmt.com | ⚠️ आंशिक रूप से disabled — 200 HTML page, JSON नहीं |
| fashionnova.com | ❌ Disabled — 404 |
आठ में से पाँच ने साफ़ JSON लौटाया। तीन ने नहीं।
Forum users भी यही बताते हैं: "किसी वजह से, कुछ Shopify stores अपने products.json को expose नहीं करते।" Password-protected stores, custom API setups वाले stores, और Cloudflare-protected domains — ये सभी pattern तोड़ सकते हैं।
Chrome extension fallback
जब products.json उपलब्ध नहीं होता, तो Chrome extension scraper सीधे rendered page (DOM) से data निकालता है। यही browser-based scrapers का core value proposition है: वे वही देखते और निकालते हैं जो आप browser में देखते हैं, API उपलब्ध हो या नहीं। इसलिए Chrome extensions एक भरोसेमंद Plan B हैं — और अक्सर तब Plan A भी, जब आपको reviews, merchandising content, या full image galleries जैसे rendered-page data चाहिए।
एंटी-बॉट सुरक्षा: Shopify स्टोर्स स्क्रैप करते समय असल में क्या होता है
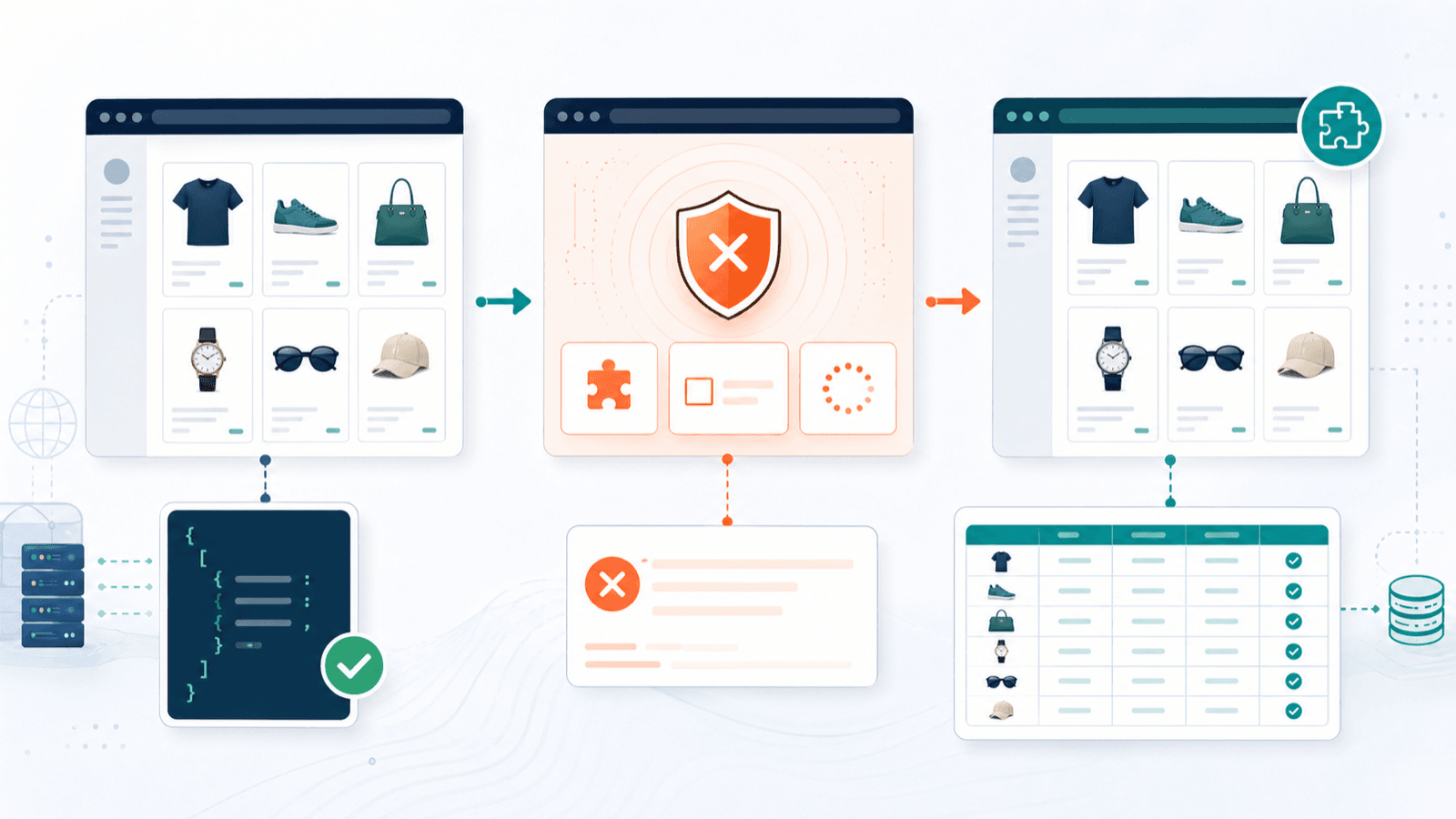
ज़्यादातर Shopify scraper लेख मान लेते हैं कि हर स्टोर पूरी तरह खुला है। ऐसा नहीं है। के अनुसार 99.2% Shopify stores Cloudflare infrastructure का उपयोग करते हैं। इसका मतलब यह नहीं कि हर स्टोर आक्रामक रूप से scrapers को ब्लॉक करता है, लेकिन यह ज़रूर है कि blocking का infrastructure हर जगह मौजूद है।
व्यावहारिक रूप से, स्थिति कुछ ऐसी दिखती है:
स्क्रैप करने में आसान
- ऐसे public stores जिन पर aggressive Cloudflare protection नहीं है
- जिन स्टोर्स में products.json enabled है
- Standard Shopify themes वाले stores (consistent DOM structure)
स्क्रैप करने में कठिन
- Cloudflare-protected stores (CAPTCHA challenges, Turnstiles)
- Login-required या password-gated stores
- Shopify Plus stores जिनमें custom security layers हैं
- Aggressive rate limiting वाले stores
हर टूल एंटी-बॉट परिदृश्यों को कैसे संभालता है
| परिदृश्य | सबसे अच्छा तरीका | जो टूल इसे संभालते हैं |
|---|---|---|
| Public store, कोई anti-bot नहीं | Cloud scraping (तेज़) | Thunderbit (cloud mode), Instant Data Scraper, अधिकांश अन्य |
| Cloudflare-protected store | Browser-based scraping (आपके session का उपयोग) | Thunderbit (browser mode), Web Scraper, Octoparse |
| Login-required / private store | आपके logged-in session के साथ browser scraping | Thunderbit (browser mode), Web Scraper, Simplescraper |
| products.json disabled | Rendered page से DOM-based extraction | सभी Chrome extensions (यही उनकी ताकत है) |
Thunderbit के dual cloud/browser scraping modes यहाँ वाकई काम आते हैं। Cloud mode public stores की bulk scraping के लिए तेज़ है। Browser mode आपके असली Chrome session का उपयोग करता है जब anti-bot protection की ज़रूरत होती है। यही flexibility मुझे gymshark.com पर काम आई, जहाँ cloud requests block हो गईं लेकिन browser mode ठीक चला।
Scheduled Shopify scraping: समय के साथ कीमतें और inventory मॉनिटर करें
एक बार की scraping उपयोगी है। लेकिन ईकॉमर्स ops teams को आमतौर पर लगातार competitor intelligence चाहिए — सिर्फ एक snapshot नहीं। कीमतों में बदलाव, inventory उतार-चढ़ाव, नए प्रोडक्ट लॉन्च: ये लगातार होते रहते हैं। एक forum user ने सीधे कहा: "उनका current inventory level और समय के साथ घटता हुआ snapshot देखना ज़्यादा मददगार है।"
फिर भी लगभग कोई भी प्रतिस्पर्धी लेख scheduled या recurring scraping का ज़िक्र नहीं करता। यह एक साफ़ blind spot है।
Scheduled Shopify monitoring कैसे काम करती है
- किसी competitor की collection या product pages की recurring scrape सेट करें
- हर run पर data Google Sheets (या Airtable) में export होता है, जिससे price और inventory data की time-series बनती है
- डेटा का उपयोग करें: price drops/increases, stockouts, नए प्रोडक्ट जोड़ना, seasonal patterns ट्रैक करने के लिए
Thunderbit के साथ scheduled scraping सेटअप करना
Thunderbit इसे बेहद आसान बना देता है।
आप शेड्यूल को साधारण अंग्रेज़ी में लिखते हैं (जैसे, "हर सोमवार सुबह 9 बजे"), Shopify store URLs डालते हैं, और "Schedule" पर क्लिक करते हैं। Thunderbit scrape अपने आप चलाता है और चुनी हुई destination पर export कर देता है। कोई cron jobs नहीं, कोई code नहीं, कोई third-party scheduler नहीं।
सभी 8 टूल्स में scheduling सपोर्ट
| टूल | Scheduling? |
|---|---|
| Thunderbit | हाँ — साधारण अंग्रेज़ी scheduling |
| Instant Data Scraper | नहीं |
| Web Scraper | हाँ — cloud plans पर |
| Data Miner | automated crawls मौजूद हैं, लेकिन सबसे आसान scheduling नहीं |
| Simplescraper | हाँ |
| Octoparse | हाँ — Standard और उससे ऊपर |
| Bardeen | हाँ — time/date automations के ज़रिए |
| Listly | हाँ — Business plan पर |
अगर ongoing competitor monitoring आपके workflow का हिस्सा है, तो यह एक प्रमुख differentiator है। ज़्यादातर free-tier Chrome extensions यह सुविधा बिल्कुल नहीं देते।
आपकी ज़रूरत के लिए कौन-सा Shopify scraper Chrome extension सही है?

सामान्य "जो पसंद हो उसे चुनो" वाले निष्कर्ष के बजाय, यहाँ specific use cases के अनुसार एक decision matrix है:
| उपयोग मामला | सबसे अच्छी सिफारिश | क्यों |
|---|---|---|
| प्रतिस्पर्धी मूल्य रिसर्च | Thunderbit | Listing + subpage enrichment + scheduling = पूरा pricing workflow |
| तेज़ एक-बार का export | Instant Data Scraper | जब सिर्फ visible list data चाहिए, तब सबसे तेज़ मुफ़्त रास्ता |
| अपने Shopify स्टोर में कैटलॉग इम्पोर्ट | Thunderbit | पूरा subpage data + Shopify-import-friendly CSV/Excel export |
| लगातार price/inventory monitoring | Thunderbit या Octoparse | सबसे आसान no-code scheduling बनाम सबसे मज़बूत enterprise-style scheduling |
| लीड जनरेशन (स्टोर मालिक संपर्क) | Thunderbit | built-in email/phone extractors + structured export |
| जटिल multi-step automations | Bardeen | एक ही workflow में scrape, enrich, और downstream apps में push |
| technical users जो पूरा नियंत्रण चाहते हैं | Web Scraper या Octoparse | selectors, flow, और extraction logic पर सबसे अच्छा manual control |
समापन
2026 में Shopify scraping का सवाल यह नहीं है कि आप प्रोडक्ट डेटा निकाल सकते हैं या नहीं — सवाल यह है कि आपका workflow कितना गहरा, कितना तेज़, और कितना repeatable है। इस क्षेत्र के ज़्यादातर लेख listing page पर रुक जाते हैं। असली मूल्य subpage enrichment, scheduled monitoring, और उन एंटी-बॉट चुनौतियों को संभालने में है जो असली Shopify stores सामने रखते हैं।
अगर आप देखना चाहते हैं कि यह व्यवहार में कैसा दिखता है — collection page से कुछ ही क्लिक में fully enriched dataset तक — तो आज़माइए। और अगर Thunderbit बिल्कुल सही fit न हो, तो Instant Data Scraper साधारण jobs के लिए एक मज़बूत मुफ़्त शुरुआत है, जबकि Web Scraper और Octoparse उन technical users के लिए अच्छे विकल्प हैं जो अधिक नियंत्रण चाहते हैं।
हैप्पी स्क्रैपिंग — और आपकी product data हमेशा पूरी, structured, और variant-rich रहे।
FAQs
1. क्या Shopify स्टोर्स से डेटा स्क्रैप करना कानूनी है?
Shopify स्टोर्स पर सार्वजनिक रूप से उपलब्ध product data आम तौर पर किसी भी साइट विज़िटर के लिए सुलभ होता है। फिर भी, वैधता आपके क्षेत्राधिकार, स्टोर की Terms of Service, और आप डेटा का क्या उपयोग करते हैं — इस पर निर्भर करती है। प्रतिस्पर्धी analysis के लिए सार्वजनिक कीमतें स्क्रैप करना आम प्रथा है; लेकिन सामग्री को wholesale कॉपी करके पुनर्प्रकाशित करना अधिक जोखिम भरा है। यह कानूनी सलाह नहीं है — अपनी स्थिति के लिए किसी पेशेवर से सलाह लें।
2. क्या मैं login या password वाले Shopify stores स्क्रैप कर सकता हूँ?
हाँ, लेकिन आपको browser-based scraper चाहिए जो आपके logged-in Chrome session का उपयोग करे। Cloud scrapers आम तौर पर login-gated pages तक नहीं पहुँच पाते। Thunderbit का browser mode, Web Scraper (local), और Simplescraper के login workflows सभी इस स्थिति को सपोर्ट करते हैं।
3. मैं एक बार में Shopify store से कितने products scrape कर सकता हूँ?
यह टूल और plan पर निर्भर करता है। Shopify का products.json endpoint पर paginate करता है। Thunderbit का cloud mode एक बार में 50 pages तक process करता है। अधिकांश tools के free tiers pages, rows, या credits पर cap लगाते हैं — इसलिए बड़े काम से पहले अपने plan limits जाँच लें।
4. Shopify के लिए cloud scraping और browser scraping में क्या अंतर है?
Cloud scraping remote servers पर चलता है — यह तेज़ है और बिना anti-bot protection वाले public stores के लिए बेहतर है। Browser scraping आपका local Chrome session उपयोग करता है, इसलिए यह Cloudflare-protected, login-required, या region-sensitive stores को संभाल सकता है। Thunderbit दोनों modes देता है, और चुनाव आमतौर पर इस पर निर्भर करता है कि store remote requests block करता है या नहीं।
5. क्या मैं scraped Shopify data सीधे Google Sheets या Airtable में export कर सकता हूँ?
हाँ, लेकिन सभी टूल ऐसा नहीं करते। Thunderbit Google Sheets, Airtable, Notion, Excel, CSV, और JSON में export करता है — वह भी मुफ्त। Data Miner और Listly Google Sheets सपोर्ट करते हैं। Simplescraper Sheets और Airtable सपोर्ट करता है। Octoparse premium tiers पर Google Sheets सपोर्ट करता है। Bardeen Sheets, Airtable, और Notion के साथ integrate करता है। Instant Data Scraper सिर्फ CSV और XLSX में export करता है, direct Sheets integration नहीं देता।
और जानें