
वेब स्क्रैपिंग के लिए कौन-सी प्रोग्रामिंग भाषा चुननी चाहिए? सच बोलूँ तो इसका जवाब तुम्हारे प्रोजेक्ट पर टिका है—और मैंने खुद डेवलपर्स को गलत भाषा चुनकर बीच रास्ते में “아… छोड़ो यार” कहते हुए हार मानते देखा है।
वेब स्क्रैपिंग सॉफ्टवेयर मार्केट 2024 में . सही भाषा चुनोगे तो रिज़ल्ट जल्दी आएंगे और मेंटेनेंस कम होगा। गलत भाषा का मतलब: स्क्रैपर बार-बार टूटेंगे और वीकेंड पूरा “멘붕” में चला जाएगा।
मैं कई सालों से ऑटोमेशन टूल्स बना रहा हूँ। यहाँ वेब स्क्रैपिंग के लिए इस्तेमाल की गई 7 भाषाएँ हैं—कोड स्निपेट्स, एकदम ईमानदार फायदे-नुकसान, और यह भी कि कब कोडिंग छोड़कर सीधे इस्तेमाल करना ज़्यादा समझदारी है।
हमने वेब स्क्रैपिंग के लिए “बेस्ट भाषा” कैसे चुनी
वेब स्क्रैपिंग में हर प्रोग्रामिंग भाषा एक जैसी नहीं होती। कुछ अहम बातों पर ही प्रोजेक्ट उड़ान भरता है (या सीधा क्रैश हो जाता है):
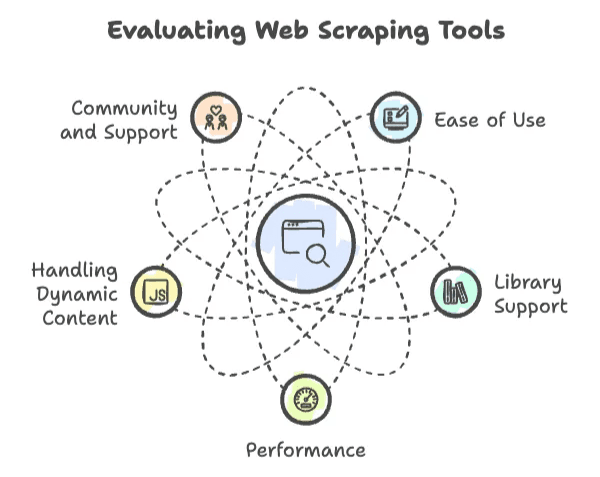
- इस्तेमाल में आसानी: शुरुआत कितनी जल्दी हो जाती है? सिंटैक्स दोस्ताना है या “Hello, World” प्रिंट करने के लिए भी कंप्यूटर साइंस में PhD चाहिए?
- लाइब्रेरी सपोर्ट: HTTP रिक्वेस्ट, HTML पार्सिंग और डायनेमिक कंटेंट संभालने के लिए मजबूत लाइब्रेरीज़ हैं या हर चीज़ खुद बनानी पड़ेगी?
- परफॉर्मेंस: क्या यह लाखों पेज स्क्रैप कर सकती है, या कुछ सौ के बाद ही दम तोड़ देती है?
- डायनेमिक कंटेंट हैंडलिंग: आजकल वेबसाइट्स JavaScript पर चलती हैं—क्या आपकी भाषा उसके साथ चल पाएगी?
- कम्युनिटी और सपोर्ट: जब आप अटकेंगे (और अटकेंगे), तो मदद के लिए कम्युनिटी मौजूद है?
इन्हीं मानकों—और ढेर सारी देर-रात टेस्टिंग—के आधार पर, मैं इन 7 भाषाओं को कवर कर रहा हूँ:
- Python: शुरुआती और प्रो—दोनों की पहली पसंद।
- JavaScript & Node.js: डायनेमिक कंटेंट का बादशाह।
- Ruby: साफ-सुथरा सिंटैक्स, जल्दी स्क्रिप्ट्स।
- PHP: सर्वर-साइड पर सीधा-सादा तरीका।
- C++: जब आपको कच्ची स्पीड चाहिए।
- Java: एंटरप्राइज़-रेडी और स्केलेबल।
- Go (Golang): तेज़ और कॉन्करेंट।
और अगर तुम सोच रहे हो, “Shuai, मुझे बिल्कुल कोड नहीं लिखना,” तो अंत में Thunderbit वाला हिस्सा ज़रूर देखना।
Python Web Scraping: शुरुआती लोगों के लिए सबसे ताकतवर विकल्प
सबसे लोकप्रिय विकल्प से शुरू करते हैं: Python। अगर तुम डेटा वालों से भरे कमरे में पूछो, “वेब स्क्रैपिंग के लिए सबसे अच्छी भाषा कौन-सी है?”—तो जवाब Python ऐसे गूंजेगा जैसे Taylor Swift कॉन्सर्ट में कोरस।
Python क्यों?
- शुरुआती-फ्रेंडली सिंटैक्स: Python कोड पढ़ते हुए अक्सर लगता है जैसे तुम अंग्रेज़ी पढ़ रहे हो—काफी “깔끔”।
- लाइब्रेरी सपोर्ट बेमिसाल: HTML पार्सिंग के लिए , बड़े पैमाने पर क्रॉलिंग के लिए , HTTP के लिए , और ब्राउज़र ऑटोमेशन के लिए —Python में सब कुछ मिल जाता है।
- बहुत बड़ी कम्युनिटी: सिर्फ वेब स्क्रैपिंग पर ही मौजूद हैं।
Python सैंपल कोड: पेज टाइटल स्क्रैप करना
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")ताकत:
- तेज़ डेवलपमेंट और प्रोटोटाइपिंग।
- ट्यूटोरियल्स और Q&A की भरमार।
- डेटा एनालिसिस के लिए शानदार—Python से स्क्रैप करें, pandas से एनालाइज़ करें, matplotlib से विज़ुअलाइज़ करें।
कमियाँ:
- बहुत बड़े कामों में compiled भाषाओं से धीमी।
- बहुत ज़्यादा डायनेमिक साइट्स पर काम थोड़ा भारी लग सकता है (हालाँकि Selenium और Playwright मदद करते हैं)।
- “बिजली की रफ्तार” से लाखों पेज स्क्रैप करने के लिए आदर्श नहीं।
निष्कर्ष:
अगर तुम स्क्रैपिंग में नए हो या जल्दी काम निपटाना चाहते हो, तो वेब स्क्रैपिंग के लिए Python सबसे बढ़िया भाषा है—बस। .
JavaScript & Node.js: डायनेमिक वेबसाइट्स को आसानी से स्क्रैप करें
अगर Python Swiss Army knife है, तो JavaScript (और Node.js) पावर ड्रिल है—खासकर उन मॉडर्न वेबसाइट्स के लिए जो JavaScript पर भारी निर्भर हैं। एकदम “찐” डायनेमिक साइट्स वाला गेम।
JavaScript/Node.js क्यों?
- डायनेमिक कंटेंट के लिए नैचुरल फिट: यह ब्राउज़र की दुनिया की भाषा है, इसलिए React/Angular/Vue जैसी साइट्स पर भी वही देख सकता है जो यूज़र देखता है।
- Async डिफ़ॉल्ट: Node.js एक साथ सैकड़ों रिक्वेस्ट संभाल सकता है—काफी “빠르게”।
- वेब डेवलपर्स के लिए परिचित: अगर तुमने वेबसाइट बनाई है, तो JavaScript पहले से थोड़ी-बहुत आती ही होगी।
मुख्य लाइब्रेरीज़:
- : Headless Chrome ऑटोमेशन।
- : मल्टी-ब्राउज़र ऑटोमेशन।
- : Node के लिए jQuery-जैसी HTML पार्सिंग।
Node.js सैंपल कोड: Puppeteer से पेज टाइटल स्क्रैप करना
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();ताकत:
- JavaScript से रेंडर होने वाला कंटेंट सीधे संभालता है।
- infinite scroll, pop-ups और इंटरैक्टिव साइट्स स्क्रैप करने में बढ़िया।
- बड़े पैमाने पर concurrent scraping के लिए प्रभावी।
कमियाँ:
- शुरुआती लोगों के लिए async प्रोग्रामिंग थोड़ा उलझाऊ हो सकता है—कभी-कभी “헷갈려” वाला फील।
- बहुत सारे headless browsers साथ चलाने पर मेमोरी खपत बढ़ जाती है।
- Python की तुलना में डेटा एनालिसिस टूल्स कम।
JavaScript/Node.js कब सबसे अच्छा विकल्प है?
जब तुम्हारी टारगेट साइट डायनेमिक हो या तुम्हें ब्राउज़र एक्शन्स ऑटोमेट करने हों। .
Ruby: साफ-सुथरे सिंटैक्स के साथ जल्दी स्क्रैपिंग स्क्रिप्ट्स
Ruby सिर्फ Rails और “सुंदर कोड” तक सीमित नहीं है। वेब स्क्रैपिंग के लिए भी यह एक अच्छा विकल्प है—खासकर अगर तुम्हें ऐसा कोड पसंद है जो पढ़ने में कविता जैसा लगे, एकदम “감성” वाला।
Ruby क्यों?
- पढ़ने में आसान, एक्सप्रेसिव सिंटैक्स: Ruby में स्क्रैपर लिखना कई बार किराने की लिस्ट जितना सीधा लगता है।
- प्रोटोटाइपिंग के लिए बढ़िया: जल्दी लिखो, जल्दी बदलो।
- मुख्य लाइब्रेरीज़: पार्सिंग के लिए , नेविगेशन ऑटोमेशन के लिए ।
Ruby सैंपल कोड: पेज टाइटल स्क्रैप करना
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"ताकत:
- बेहद readable और concise।
- छोटे प्रोजेक्ट्स, one-off scripts, या Ruby यूज़र्स के लिए शानदार।
कमियाँ:
- बड़े कामों में Python/Node.js से धीमी।
- स्क्रैपिंग के लिए लाइब्रेरीज़ और कम्युनिटी सपोर्ट अपेक्षाकृत कम।
- JavaScript-heavy साइट्स के लिए आदर्श नहीं (हालाँकि Watir या Selenium इस्तेमाल कर सकते हैं)।
किसके लिए सही:
अगर तुम Rubyist हो या जल्दी एक स्क्रिप्ट बनानी है, Ruby मज़ेदार है। बहुत बड़े और डायनेमिक स्क्रैपिंग के लिए दूसरे विकल्प देखो।
PHP: सर्वर-साइड पर वेब डेटा निकालने का सरल तरीका
PHP भले ही पुराने वेब का “क्लासिक” लगे, लेकिन आज भी काम का है—खासकर जब तुम सर्वर पर ही स्क्रैपिंग करना चाहते हो। मतलब, “그냥 된다” वाली प्रैक्टिकलिटी।
PHP क्यों?
- हर जगह चलता है: ज़्यादातर वेब सर्वर्स पर PHP पहले से मौजूद होता है।
- वेब ऐप्स के साथ इंटीग्रेशन आसान: स्क्रैप भी करो और उसी साइट पर दिखा भी दो।
- मुख्य लाइब्रेरीज़: HTTP के लिए , रिक्वेस्ट्स के लिए , headless ब्राउज़र ऑटोमेशन के लिए ।
PHP सैंपल कोड: पेज टाइटल स्क्रैप करना
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>ताकत:
- वेब सर्वर पर डिप्लॉय करना आसान।
- वेब वर्कफ़्लो के हिस्से के रूप में स्क्रैपिंग के लिए अच्छा।
- सरल सर्वर-साइड स्क्रैपिंग टास्क्स में तेज़।
कमियाँ:
- एडवांस्ड स्क्रैपिंग के लिए लाइब्रेरी सपोर्ट सीमित।
- हाई कॉन्करेंसी या बड़े स्केल के लिए डिज़ाइन नहीं।
- JavaScript-heavy साइट्स संभालना मुश्किल (हालाँकि Panther मदद करता है)।
किसके लिए सही:
अगर तुम्हारा स्टैक पहले से PHP है, या तुम साइट पर ही डेटा स्क्रैप करके दिखाना चाहते हो, तो PHP एक व्यावहारिक विकल्प है। .
C++: बड़े पैमाने पर हाई-परफॉर्मेंस वेब स्क्रैपिंग
C++ प्रोग्रामिंग भाषाओं की muscle car है। अगर तुम्हें कच्ची स्पीड और पूरा कंट्रोल चाहिए—और तुम थोड़ी “हाथ से मेहनत” से नहीं डरते—तो C++ बहुत आगे ले जा सकती है। बस तैयार रहो: कभी-कभी “빡세다” भी लगेगा।
C++ क्यों?
- बेहद तेज़: CPU-bound कामों में कई भाषाओं से आगे।
- बारीक कंट्रोल: मेमोरी, थ्रेड्स और परफॉर्मेंस ट्यूनिंग पर पकड़।
- मुख्य लाइब्रेरीज़: HTTP के लिए , पार्सिंग के लिए ।
C++ सैंपल कोड: पेज टाइटल स्क्रैप करना
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}ताकत:
- बहुत बड़े स्क्रैपिंग जॉब्स में बेजोड़ स्पीड।
- हाई-परफॉर्मेंस सिस्टम्स में स्क्रैपिंग इंटीग्रेट करने के लिए अच्छा।
कमियाँ:
- सीखने की ढलान तेज़ (कॉफी साथ रखें)।
- मैनुअल मेमोरी मैनेजमेंट।
- हाई-लेवल लाइब्रेरीज़ कम; डायनेमिक कंटेंट के लिए आदर्श नहीं।
किसके लिए सही:
जब तुम्हें लाखों पेज स्क्रैप करने हों या परफॉर्मेंस ही सबसे बड़ा लक्ष्य हो। वरना स्क्रैपिंग से ज़्यादा समय डिबगिंग में जा सकता है।
Java: एंटरप्राइज़-ग्रेड वेब स्क्रैपिंग
Java एंटरप्राइज़ दुनिया का भरोसेमंद वर्कहॉर्स है। अगर तुम्हें ऐसा सिस्टम बनाना है जो लंबे समय तक चले, बहुत डेटा संभाले, और “कठिन हालात” में भी टिके—तो Java काम आती है। एकदम “든든”।
Java क्यों?
- मजबूत और स्केलेबल: बड़े और लंबे समय तक चलने वाले स्क्रैपिंग प्रोजेक्ट्स के लिए बढ़िया।
- Strong typing और error handling: प्रोडक्शन में कम सरप्राइज़।
- मुख्य लाइब्रेरीज़: पार्सिंग के लिए , ब्राउज़र ऑटोमेशन के लिए , HTTP के लिए ।
Java सैंपल कोड: पेज टाइटल स्क्रैप करना
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}ताकत:
- अच्छी परफॉर्मेंस और कॉन्करेंसी।
- बड़े, मेंटेनेबल कोडबेस के लिए बेहतरीन।
- डायनेमिक कंटेंट के लिए भी ठीक सपोर्ट (Selenium या HtmlUnit के जरिए)।
कमियाँ:
- सिंटैक्स verbose; scripting भाषाओं की तुलना में सेटअप ज़्यादा।
- छोटे, one-off scripts के लिए ओवरकिल।
किसके लिए सही:
एंटरप्राइज़-स्केल स्क्रैपिंग, या जब तुम्हें बहुत भरोसेमंद और स्केलेबल सिस्टम चाहिए।
Go (Golang): तेज़ और कॉन्करेंट वेब स्क्रैपिंग
Go नया खिलाड़ी है, लेकिन हाई-स्पीड और कॉन्करेंट स्क्रैपिंग में तेजी से लोकप्रिय हो रहा है—काफी “핫”।
Go क्यों?
- Compiled स्पीड: लगभग C++ जितनी तेज़।
- Built-in concurrency: Goroutines से parallel scraping आसान हो जाती है।
- मुख्य लाइब्रेरीज़: स्क्रैपिंग के लिए , पार्सिंग के लिए ।
Go सैंपल कोड: पेज टाइटल स्क्रैप करना
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}ताकत:
- बड़े स्केल पर बेहद तेज़ और efficient।
- डिप्लॉयमेंट आसान (single binary)।
- concurrent crawling के लिए शानदार।
कमियाँ:
- Python/Node.js जितनी बड़ी कम्युनिटी नहीं।
- हाई-लेवल स्क्रैपिंग लाइब्रेरीज़ कम।
- JavaScript-heavy साइट्स के लिए अतिरिक्त सेटअप चाहिए (Chromedp या Selenium)।
किसके लिए सही:
जब तुम्हें स्केल पर स्क्रैप करना हो, या Python की स्पीड कम पड़ रही हो। .
वेब स्क्रैपिंग के लिए बेस्ट प्रोग्रामिंग भाषाओं की तुलना
अब सब कुछ एक साथ देखते हैं। 2026 में वेब स्क्रैपिंग के लिए सही भाषा चुनने में मदद के लिए यह side-by-side तुलना देखें:
| Language/Tool | Ease of Use | Performance | Library Support | Dynamic Content Handling | Best Use Case |
|---|---|---|---|---|---|
| Python | बहुत अधिक | मध्यम | उत्कृष्ट | अच्छा (Selenium/Playwright) | जनरल-पर्पज़, शुरुआती, डेटा एनालिसिस |
| JavaScript/Node.js | मध्यम | उच्च | मजबूत | उत्कृष्ट (native) | डायनेमिक साइट्स, async scraping, वेब डेवलपर्स |
| Ruby | उच्च | मध्यम | ठीक-ठाक | सीमित (Watir) | जल्दी स्क्रिप्ट्स, प्रोटोटाइपिंग |
| PHP | मध्यम | मध्यम | औसत | सीमित (Panther) | सर्वर-साइड, वेब ऐप इंटीग्रेशन |
| C++ | कम | बहुत अधिक | सीमित | बहुत सीमित | परफॉर्मेंस-क्रिटिकल, बहुत बड़ा स्केल |
| Java | मध्यम | उच्च | अच्छा | अच्छा (Selenium/HtmlUnit) | एंटरप्राइज़, लंबे समय तक चलने वाली सर्विसेज |
| Go (Golang) | मध्यम | बहुत अधिक | बढ़ता हुआ | मध्यम (Chromedp) | हाई-स्पीड, कॉन्करेंट स्क्रैपिंग |
कब कोडिंग छोड़ दें: नो-कोड वेब स्क्रैपिंग के लिए Thunderbit
सच बताऊँ तो कई बार तुम्हें बस डेटा चाहिए होता है—बिना कोडिंग, डिबगिंग, या “ये selector क्यों नहीं चल रहा” वाली टेंशन के। ऐसे में काम आता है—एकदम “꿀” जैसा।
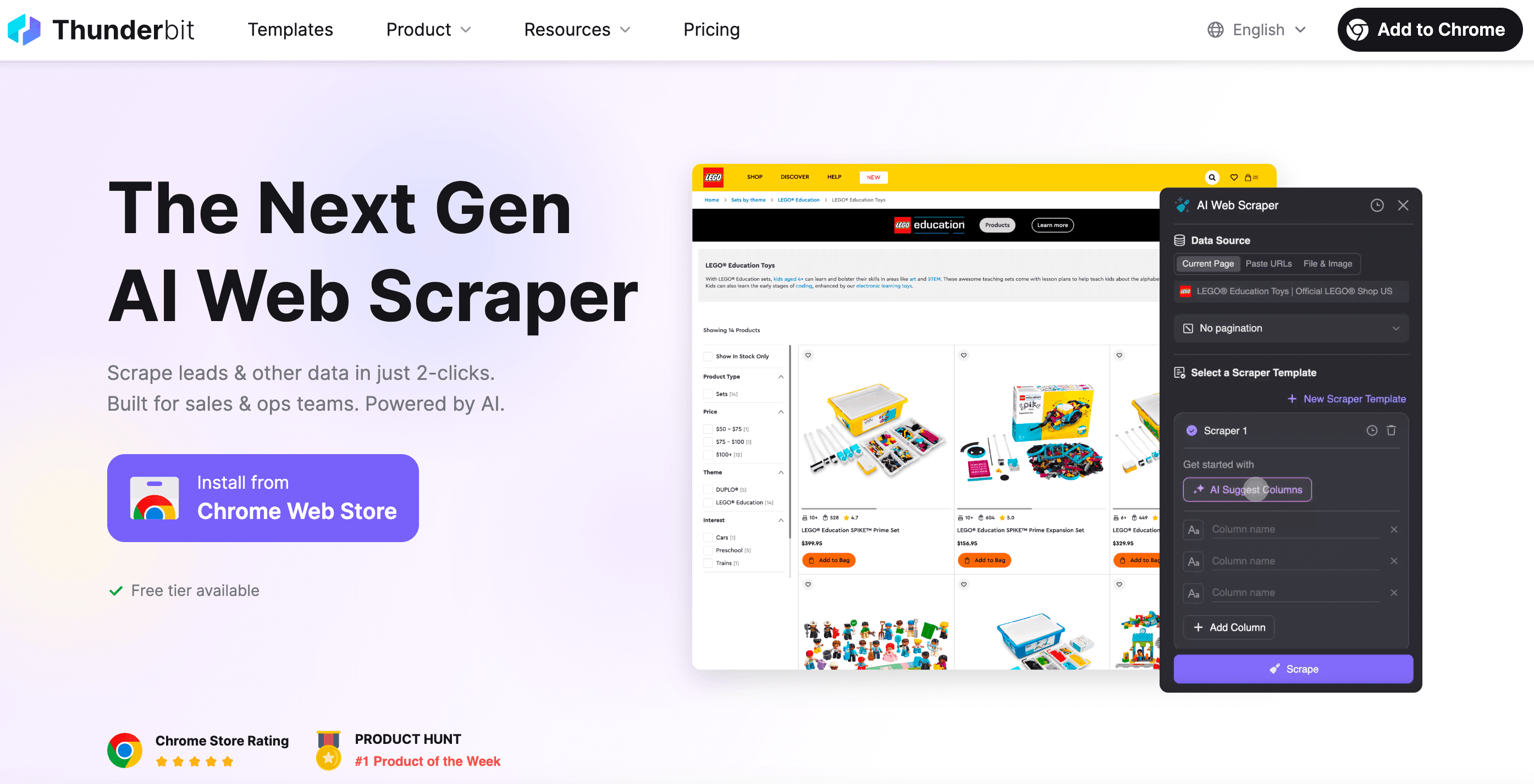
Thunderbit के co-founder के तौर पर मेरा लक्ष्य था वेब स्क्रैपिंग को इतना आसान बनाना जितना takeout ऑर्डर करना। Thunderbit को अलग क्या बनाता है:
- 2-क्लिक सेटअप: बस “AI Suggest Fields” और “Scrape” पर क्लिक करें। HTTP requests, proxies या anti-bot जुगाड़ में समय नहीं जाता।
- स्मार्ट टेम्पलेट्स: एक scraper template कई तरह के पेज लेआउट के साथ खुद को ढाल लेता है। साइट बदलते ही स्क्रैपर फिर से लिखने की जरूरत नहीं।
- ब्राउज़र और क्लाउड स्क्रैपिंग: ब्राउज़र में स्क्रैप करें (logged-in साइट्स के लिए बढ़िया) या क्लाउड में (पब्लिक डेटा के लिए सुपर फास्ट)।
- डायनेमिक कंटेंट भी संभाले: Thunderbit का AI असली ब्राउज़र कंट्रोल करता है—इसलिए infinite scroll, pop-ups, logins वगैरह भी हो जाते हैं।
- कहीं भी एक्सपोर्ट: Excel, Google Sheets, Airtable, Notion में डाउनलोड करें या सीधे clipboard में कॉपी करें।
- मेंटेनेंस लगभग शून्य: साइट बदले तो बस AI suggestion फिर से चला दें—रात भर डिबगिंग नहीं।
- शेड्यूलिंग और ऑटोमेशन: स्क्रैपर्स को शेड्यूल पर चलाएँ—ना cron jobs, ना सर्वर सेटअप।
- स्पेशलाइज़्ड एक्सट्रैक्टर्स: emails, phone numbers या images चाहिए? Thunderbit में इनके लिए one-click extractors भी हैं।
सबसे अच्छी बात: तुम्हें एक लाइन भी कोड जानने की जरूरत नहीं। Thunderbit बिज़नेस यूज़र्स, मार्केटर्स, सेल्स टीम्स, रियल एस्टेट प्रोफेशनल्स—हर उस व्यक्ति के लिए है जिसे जल्दी और साफ-सुथरा डेटा चाहिए।
Thunderbit को लाइव देखना है? या डेमो के लिए हमारा देखें।
निष्कर्ष: 2026 में वेब स्क्रैपिंग के लिए सही भाषा कैसे चुनें
2026 में वेब स्क्रैपिंग पहले से कहीं ज़्यादा आसान भी है और ताकतवर भी। ऑटोमेशन की दुनिया में सालों काम करने के बाद मेरी सीख:
- Python अब भी वेब स्क्रैपिंग के लिए सबसे बढ़िया है, अगर तुम जल्दी शुरुआत करना चाहते हो और तुम्हारे पास सीखने/मदद के ढेर सारे संसाधन चाहिए।
- JavaScript/Node.js डायनेमिक, JavaScript-heavy साइट्स के लिए सबसे मजबूत विकल्प है।
- Ruby और PHP जल्दी स्क्रिप्ट्स और वेब इंटीग्रेशन के लिए अच्छे हैं—खासकर अगर तुम इन्हें पहले से इस्तेमाल करते हो।
- C++ और Go तब काम आते हैं जब स्पीड और स्केल सबसे ज़रूरी हों।
- Java एंटरप्राइज़ और लंबे समय वाले प्रोजेक्ट्स के लिए भरोसेमंद विकल्प है।
- और अगर तुम कोडिंग पूरी तरह छोड़ना चाहते हो? तुम्हारा सीक्रेट हथियार है।
शुरू करने से पहले खुद से पूछो:
- मेरा प्रोजेक्ट कितना बड़ा है?
- क्या मुझे डायनेमिक कंटेंट संभालना है?
- मेरा टेक्निकल कम्फर्ट लेवल क्या है?
- मुझे सिस्टम बनाना है, या बस डेटा चाहिए?
ऊपर दिए गए किसी कोड स्निपेट को ट्राय करो, या अपने अगले प्रोजेक्ट के लिए Thunderbit इस्तेमाल करके देखो। और अगर तुम और गहराई में जाना चाहते हो, तो गाइड्स, टिप्स और रियल-वर्ल्ड स्क्रैपिंग स्टोरीज़ के लिए हमारा देखें।
स्क्रैपिंग मुबारक—और तुम्हारा डेटा हमेशा साफ, स्ट्रक्चर्ड, और बस एक क्लिक दूर रहे।
P.S. अगर कभी तुम रात 2 बजे वेब स्क्रैपिंग के rabbit hole में फँस जाओ, तो याद रखना: Thunderbit हमेशा है। या कॉफी। या दोनों।
FAQs
1. 2026 में वेब स्क्रैपिंग के लिए सबसे अच्छी प्रोग्रामिंग भाषा कौन-सी है?
Python आज भी सबसे ऊपर है—क्योंकि इसका सिंटैक्स पढ़ने में आसान है, BeautifulSoup, Scrapy और Selenium जैसी ताकतवर लाइब्रेरीज़ मिलती हैं, और कम्युनिटी बहुत बड़ी है। यह शुरुआती और प्रो—दोनों के लिए बढ़िया है, खासकर जब स्क्रैपिंग के साथ डेटा एनालिसिस भी करना हो।
2. JavaScript-heavy वेबसाइट्स स्क्रैप करने के लिए कौन-सी भाषा सबसे अच्छी है?
डायनेमिक साइट्स के लिए JavaScript (Node.js) सबसे अच्छा विकल्प है। Puppeteer और Playwright जैसे टूल्स तुम्हें पूरा ब्राउज़र कंट्रोल देते हैं, जिससे React, Vue या Angular से लोड होने वाले कंटेंट के साथ भी इंटरैक्ट किया जा सकता है।
3. क्या वेब स्क्रैपिंग के लिए कोई नो-कोड विकल्प है?
हाँ— एक नो-कोड AI Web Scraper है जो डायनेमिक कंटेंट से लेकर शेड्यूलिंग तक सब संभालता है। बस “AI Suggest Fields” पर क्लिक करो और स्क्रैपिंग शुरू करो। यह सेल्स, मार्केटिंग या ऑप्स टीम्स के लिए परफेक्ट है जिन्हें जल्दी स्ट्रक्चर्ड डेटा चाहिए।
Learn More: