
वेब डेटा बिक्री, मार्केटिंग और ऑप्स के लिए डिफ़ॉल्ट इनपुट बन चुका है। अगर आप अभी भी कॉपी-पेस्ट कर रहे हैं, तो आप पीछे रह जा रहे हैं।
लेकिन “मुफ़्त” स्क्रैपिंग टूल्स के साथ दिक्कत यह है: ज़्यादातर सच में मुफ़्त नहीं होते। वे सीमित ट्रायल होते हैं, या फिर जिन सुविधाओं की आपको असल में ज़रूरत है, उन्हें पेवॉल के पीछे बंद कर देते हैं।
मैंने 12 टूल्स का मूल्यांकन किया ताकि पता चल सके कि कौन-से फ्री टियर पर असली काम करने देते हैं। मैंने Google Maps लिस्टिंग, लॉगिन के पीछे वाले डायनेमिक पेज, और PDF स्क्रैप किए। कुछ ने कमाल किया। कुछ ने मेरा दोपहर का समय बर्बाद किया।
यह रहा ईमानदार विश्लेषण — और शुरुआत उन टूल्स से, जिन्हें मैं सच में सुझाऊँगा।
मुफ़्त स्क्रैपर पहले से कहीं ज़्यादा ज़रूरी क्यों हैं
सीधी बात: 2026 में वेब स्क्रैपिंग सिर्फ हैकर्स या डेटा साइंटिस्ट्स के लिए नहीं रह गई है। यह आधुनिक व्यवसायों की एक बुनियादी ज़रूरत बन चुकी है, और आँकड़े भी यही दिखाते हैं। वेब स्क्रैपिंग सॉफ़्टवेयर बाज़ार तक पहुँच गया, और 2032 तक इसके दोगुने से भी ज़्यादा होने की राह पर है। क्यों? क्योंकि बिक्री टीमों से लेकर रियल एस्टेट एजेंटों तक, हर कोई आगे निकलने के लिए वेब डेटा का इस्तेमाल कर रहा है।
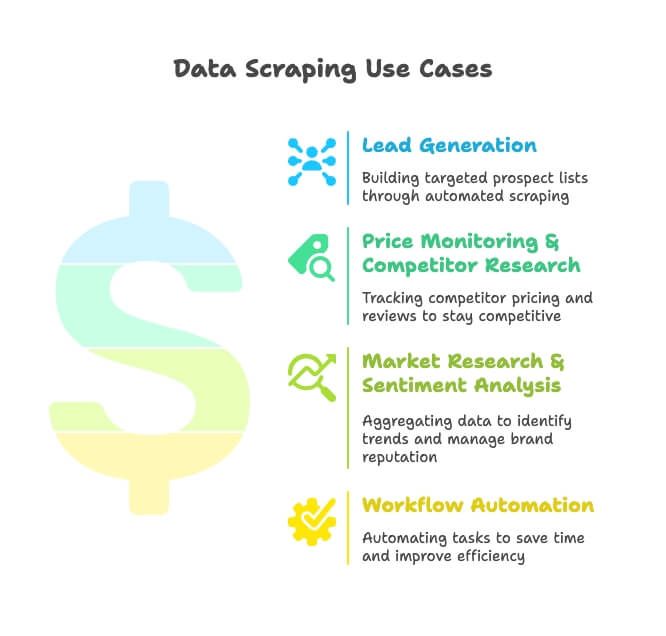
- लीड जनरेशन: सेल्स टीमें डायरेक्टरी, Google Maps और सोशल मीडिया से लक्षित संभावित ग्राहकों की सूचियाँ बनाती हैं—अब मैन्युअल खोज की ज़रूरत नहीं।
- प्राइस मॉनिटरिंग और प्रतिस्पर्धी शोध: ईकॉमर्स और रिटेल टीमें प्रतिस्पर्धियों के SKU, कीमतों और समीक्षाओं पर नज़र रखती हैं ताकि वे तेज़ बनी रहें (और हाँ, 82% ई-कॉमर्स कंपनियाँ इसी वजह से स्क्रैपिंग कर रही हैं)।
- मार्केट रिसर्च और सेंटिमेंट एनालिसिस: मार्केटर्स समीक्षाएँ, खबरें और सोशल चर्चाएँ इकट्ठा करके ट्रेंड्स पहचानते हैं और ब्रांड प्रतिष्ठा संभालते हैं।
- वर्कफ़्लो ऑटोमेशन: ऑपरेशंस टीमें इन्वेंट्री चेक से लेकर शेड्यूल्ड रिपोर्टिंग तक सब कुछ ऑटोमेट करती हैं, और हर हफ़्ते घंटों की बचत करती हैं।
और एक मज़ेदार आँकड़ा: AI-संचालित वेब स्क्रैपर इस्तेमाल करने वाली कंपनियाँ मैन्युअल तरीकों की तुलना में बचा रही हैं। यह सिर्फ थोड़ा-सा समय नहीं है—यही फर्क है कि आप 6 बजे घर जाएँ या 9 बजे।
हमने टॉप मुफ़्त डेटा स्क्रैपर टूल्स कैसे चुने
मैंने बहुत सारी “सर्वश्रेष्ठ वेब स्क्रैपर” सूचियाँ देखी हैं जो बस मार्केटिंग कॉपी दोहरा देती हैं। यहाँ ऐसा नहीं है। इस सूची के लिए, मैंने इन बातों पर ध्यान दिया:
- वास्तविक फ्री प्लान की उपयोगिता: क्या फ्री टियर आपको असली काम करने देता है, या बस एक झलक देता है?
- उपयोग में आसानी: क्या बिना कोडिंग के भी कोई कुछ मिनटों में परिणाम पा सकता है, या आपको Regex में पीएचडी चाहिए?
- समर्थित वेबसाइट प्रकार: स्टैटिक, डायनेमिक, पेजिनेटेड, लॉगिन-आवश्यक, PDF, सोशल मीडिया—क्या टूल असली दुनिया के हालात संभाल सकता है?
- डेटा एक्सपोर्ट विकल्प: क्या आप डेटा को बिना झंझट Excel, Google Sheets, Notion या Airtable में ले जा सकते हैं?
- अतिरिक्त सुविधाएँ: AI-संचालित एक्सट्रैक्शन, शेड्यूलिंग, टेम्पलेट्स, पोस्ट-प्रोसेसिंग, इंटीग्रेशन।
- यूज़र टाइप फ़िट: क्या यह टूल बिज़नेस यूज़र्स, एनालिस्ट्स या डेवलपर्स के लिए है?
मैंने हर टूल के दस्तावेज़ भी खंगाले, उनका ऑनबोर्डिंग टेस्ट किया, और उनके फ्री प्लान की सीमाओं की तुलना की—क्योंकि “मुफ़्त” हमेशा उतना मुफ़्त नहीं होता जितना सुनाई देता है।
एक नज़र में: 12 मुफ़्त डेटा स्क्रैपर की तुलना
यहाँ साथ-साथ तुलना दी गई है, ताकि आप अपनी ज़रूरत के हिसाब से सही टूल जल्दी चुन सकें।
| टूल | प्लेटफ़ॉर्म | फ्री प्लान सीमाएँ | किसके लिए सबसे अच्छा | एक्सपोर्ट फ़ॉर्मैट | विशेष सुविधाएँ |
|---|---|---|---|---|---|
| Thunderbit | Chrome एक्सटेंशन | 6 पेज/माह | बिना कोड वाले, बिज़नेस | Excel, CSV | AI प्रॉम्प्ट, PDF/इमेज स्क्रैपिंग, सबपेज क्रॉल |
| Browse AI | क्लाउड | 50 क्रेडिट/माह | नो-कोड यूज़र्स | CSV, Sheets | पॉइंट-एंड-क्लिक रोबोट, शेड्यूलिंग |
| Octoparse | डेस्कटॉप | 10 टास्क, 50k पंक्तियाँ/माह | नो-कोड, अर्ध-तकनीकी | CSV, Excel, JSON | विज़ुअल वर्कफ़्लो, डायनेमिक साइट सपोर्ट |
| ParseHub | डेस्कटॉप | 5 प्रोजेक्ट, 200 पेज/रन | नो-कोड, अर्ध-तकनीकी | CSV, Excel, JSON | विज़ुअल, डायनेमिक साइट सपोर्ट |
| Webscraper.io | Chrome एक्सटेंशन | स्थानीय उपयोग असीमित | नो-कोड, सरल काम | CSV, XLSX | साइटमैप-आधारित, समुदाय टेम्पलेट |
| Apify | क्लाउड | $5 क्रेडिट/माह | टीम, अर्ध-तकनीकी, डेवलपर | CSV, JSON, Sheets | Actor मार्केटप्लेस, शेड्यूलिंग, API |
| Scrapy | Python लाइब्रेरी | असीमित (ओपन सोर्स) | डेवलपर | CSV, JSON, DB | पूरा कोड नियंत्रण, स्केलेबल |
| Puppeteer | Node.js लाइब्रेरी | असीमित (ओपन सोर्स) | डेवलपर | कस्टम (कोड) | हेडलेस ब्राउज़र, डायनेमिक JS सपोर्ट |
| Selenium | बहु-भाषा | असीमित (ओपन सोर्स) | डेवलपर | कस्टम (कोड) | ब्राउज़र ऑटोमेशन, मल्टी-ब्राउज़र सपोर्ट |
| Zyte | क्लाउड | 1 स्पाइडर, 1 घंटा/जॉब, 7-दिन रिटेंशन | डेवलपर, ऑप्स टीमें | CSV, JSON | होस्टेड Scrapy, प्रॉक्सी प्रबंधन |
| SerpAPI | API | 100 खोजें/माह | डेवलपर, एनालिस्ट | JSON | सर्च इंजन API, एंटी-ब्लॉकिंग |
| Diffbot | API | 10,000 क्रेडिट/माह | डेवलपर, AI प्रोजेक्ट्स | JSON | AI एक्सट्रैक्शन, नॉलेज ग्राफ |
Thunderbit: AI-संचालित, उपयोग में आसान डेटा स्क्रैपिंग के लिए हमारी शीर्ष पसंद
चलिए बात करते हैं कि मेरी सूची में सबसे ऊपर क्यों है। मैं यह सिर्फ इसलिए नहीं कह रहा कि मैं टीम का हिस्सा हूँ—मेरा सच में मानना है कि Thunderbit एक ऐसे AI इंटर्न के सबसे करीब है जो सच में सुनता है (और कॉफ़ी ब्रेक भी नहीं माँगता)।
Thunderbit आपका सामान्य “टूल सीखो, फिर स्क्रैप करो” अनुभव नहीं है। यह ज़्यादा एक स्मार्ट असिस्टेंट को निर्देश देने जैसा है: आप बताते हैं कि क्या चाहिए (“इस पेज से सारे प्रोडक्ट नाम, कीमतें और लिंक निकालो”), और बाकी काम Thunderbit का AI कर देता है। न XPath की झंझट, न CSS selectors की, न Regex की सिरदर्दी। और अगर आप सबपेज स्क्रैप करना चाहते हैं (जैसे प्रोडक्ट डिटेल पेज या कंपनी कॉन्टैक्ट लिंक), तो Thunderbit अपने-आप क्लिक करके आपकी टेबल को समृद्ध कर सकता है—फिर से, बस एक बटन क्लिक करके।
लेकिन Thunderbit को अलग जो चीज़ बनाती है, वह है स्क्रैपिंग के बाद की प्रक्रिया। क्या आपको डेटा का सारांश बनाना है, अनुवाद करना है, वर्गीकृत करना है, या साफ़ करना है? Thunderbit का बिल्ट-इन AI पोस्ट-प्रोसेसिंग आपका काम कर देता है। आपको सिर्फ रॉ डेटा नहीं मिलता—आपको संरचित, उपयोगी जानकारी मिलती है, जो आपके CRM, स्प्रेडशीट या अगले बड़े प्रोजेक्ट के लिए तैयार होती है।
फ्री प्लान: Thunderbit का मुफ़्त ट्रायल आपको 6 पेज तक (या ट्रायल बूस्ट के साथ 10) स्क्रैप करने देता है, जिसमें PDF, इमेज और यहाँ तक कि सोशल मीडिया टेम्पलेट भी शामिल हैं। आप Excel या CSV में मुफ़्त एक्सपोर्ट कर सकते हैं, और ईमेल/फोन/इमेज एक्सट्रैक्शन जैसी सुविधाएँ आज़मा सकते हैं। बड़े कामों के लिए, पेड प्लान ज़्यादा पेज, Google Sheets/Notion/Airtable में डायरेक्ट एक्सपोर्ट, शेड्यूल्ड स्क्रैपिंग, और Amazon, Google Maps, Instagram जैसी लोकप्रिय साइट्स के लिए तुरंत टेम्पलेट्स अनलॉक करते हैं।
अगर आप Thunderbit को काम करते देखना चाहते हैं, तो देखें या हमारे पर जल्दी शुरू करने वाले वीडियो देखें।
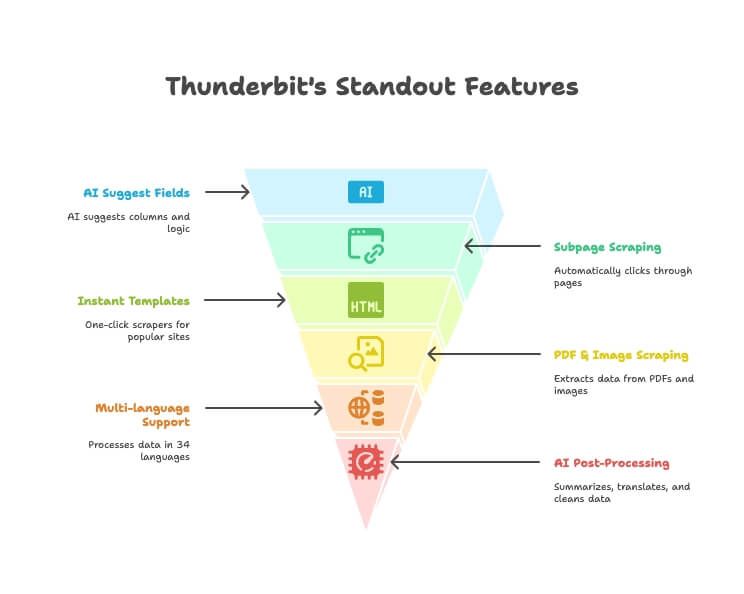
Thunderbit की प्रमुख विशेषताएँ
- AI फ़ील्ड सुझाव: बस बताएँ कि आपको कौन-सा डेटा चाहिए, और Thunderbit का AI सही कॉलम और एक्सट्रैक्शन लॉजिक सुझाता है।
- सबपेज स्क्रैपिंग: डिटेल पेज या लिंक पर अपने-आप क्लिक करके मुख्य टेबल को समृद्ध करता है—कोई मैन्युअल सेटअप नहीं।
- तुरंत टेम्पलेट्स: Amazon, Google Maps, Instagram और कई अन्य के लिए एक-क्लिक स्क्रैपर।
- PDF और इमेज स्क्रैपिंग: AI की मदद से PDF और इमेज से टेबल और डेटा निकालें—अतिरिक्त टूल की ज़रूरत नहीं।
- बहुभाषी सपोर्ट: 34 भाषाओं में डेटा स्क्रैप और प्रोसेस करें।
- डायरेक्ट एक्सपोर्ट: अपना डेटा सीधे Excel, Google Sheets, Notion या Airtable में भेजें (पेड प्लान)।
- AI पोस्ट-प्रोसेसिंग: स्क्रैप करते समय ही डेटा का सारांश, अनुवाद, वर्गीकरण और सफ़ाई करें।
- मुफ़्त ईमेल/फोन/इमेज एक्सट्रैक्शन: किसी भी साइट से संपर्क जानकारी या इमेज एक क्लिक में निकालें।
Thunderbit “सिर्फ डेटा स्क्रैप करने” और “ऐसा डेटा पाने” के बीच की दूरी कम करता है, जिसे आप सच में इस्तेमाल कर सकें। बिज़नेस यूज़र्स के लिए यह सचमुच एक AI डेटा असिस्टेंट के सबसे करीब है जो मैंने देखा है।
बाकी 12 में से सर्वश्रेष्ठ: मुफ़्त डेटा स्क्रैपर टूल्स की समीक्षा
अब बाकी टूल्स को देखते हैं, और उन्हें इस आधार पर बाँटते हैं कि वे किनके लिए सबसे अच्छे हैं।
बिना कोड और बिज़नेस यूज़र्स के लिए
Thunderbit
ऊपर पहले ही कवर कर चुके हैं। बिना कोड वालों के लिए सबसे आसान शुरुआत, AI सुविधाओं और तुरंत तैयार टेम्पलेट्स के साथ।
Webscraper.io
- प्लेटफ़ॉर्म: Chrome एक्सटेंशन
- किसके लिए सबसे अच्छा: सरल, स्टैटिक साइट्स; वे लोग जिन्हें थोड़ा ट्रायल-एंड-एरर आपत्तिजनक नहीं लगता।
- मुख्य सुविधाएँ: साइटमैप-आधारित स्क्रैपिंग, पेजिनेशन सपोर्ट, CSV/XLSX एक्सपोर्ट।
- फ्री प्लान: स्थानीय उपयोग असीमित, लेकिन क्लाउड रन या शेड्यूलिंग नहीं। सिर्फ़ मैन्युअल ऑपरेशन।
- सीमाएँ: लॉगिन, PDF, या जटिल डायनेमिक सामग्री के लिए बिल्ट-इन हैंडलिंग नहीं। सिर्फ समुदाय सहायता।
ParseHub
- प्लेटफ़ॉर्म: डेस्कटॉप ऐप (Windows, Mac, Linux)
- किसके लिए सबसे अच्छा: बिना कोड वाले और अर्ध-तकनीकी यूज़र्स, जो सीखने में समय लगाने को तैयार हों।
- मुख्य सुविधाएँ: विज़ुअल वर्कफ़्लो बिल्डर, डायनेमिक साइट, AJAX, लॉगिन, पेजिनेशन सपोर्ट।
- फ्री प्लान: 5 सार्वजनिक प्रोजेक्ट, प्रति रन 200 पेज, सिर्फ़ मैन्युअल रन।
- सीमाएँ: फ्री प्लान में प्रोजेक्ट सार्वजनिक रहते हैं (संवेदनशील डेटा के साथ सावधानी रखें), शेड्यूलिंग नहीं, एक्सट्रैक्शन स्पीड धीमी।
Octoparse
- प्लेटफ़ॉर्म: डेस्कटॉप ऐप (Windows/Mac), क्लाउड (पेड)
- किसके लिए सबसे अच्छा: बिना कोड वाले और एनालिस्ट, जिन्हें ताकत और लचीलापन दोनों चाहिए।
- मुख्य सुविधाएँ: विज़ुअल पॉइंट-एंड-क्लिक, डायनेमिक कंटेंट सपोर्ट, लोकप्रिय साइट्स के लिए टेम्पलेट्स।
- फ्री प्लान: 10 टास्क, 50,000 पंक्तियों तक/माह, सिर्फ़ डेस्कटॉप (क्लाउड/शेड्यूलिंग नहीं)।
- सीमाएँ: फ्री टियर में API, IP रोटेशन या शेड्यूलिंग नहीं। जटिल साइट्स के लिए सीखने की रफ्तार तेज़ हो सकती है।
Browse AI
- प्लेटफ़ॉर्म: क्लाउड
- किसके लिए सबसे अच्छा: नो-कोड यूज़र्स जो सरल स्क्रैपिंग और मॉनिटरिंग को ऑटोमेट करना चाहते हैं।
- मुख्य सुविधाएँ: पॉइंट-एंड-क्लिक रोबोट रिकॉर्डर, शेड्यूलिंग, इंटीग्रेशन (Sheets, Zapier)।
- फ्री प्लान: 50 क्रेडिट/माह, 1 वेबसाइट, अधिकतम 5 रोबोट।
- सीमाएँ: सीमित वॉल्यूम, जटिल साइट्स के लिए कुछ शुरुआती सीखने की ज़रूरत।
डेवलपर्स और तकनीकी यूज़र्स के लिए
Scrapy
- प्लेटफ़ॉर्म: Python लाइब्रेरी (ओपन सोर्स)
- किसके लिए सबसे अच्छा: डेवलपर जो पूरा नियंत्रण और स्केलेबिलिटी चाहते हैं।
- मुख्य सुविधाएँ: अत्यधिक कस्टमाइज़ेबल, बड़े क्रॉल सपोर्ट, middleware, pipelines।
- फ्री प्लान: असीमित (ओपन सोर्स)।
- सीमाएँ: GUI नहीं, Python कोडिंग चाहिए। बिना कोड वालों के लिए नहीं।
Puppeteer
- प्लेटफ़ॉर्म: Node.js लाइब्रेरी (ओपन सोर्स)
- किसके लिए सबसे अच्छा: डायनेमिक, JavaScript-भारी साइट्स स्क्रैप करने वाले डेवलपर।
- मुख्य सुविधाएँ: हेडलेस ब्राउज़र ऑटोमेशन, नेविगेशन और एक्सट्रैक्शन पर पूरा नियंत्रण।
- फ्री प्लान: असीमित (ओपन सोर्स)।
- सीमाएँ: JavaScript कोडिंग चाहिए, GUI नहीं।
Selenium
- प्लेटफ़ॉर्म: बहु-भाषा (Python, Java, आदि), ओपन सोर्स
- किसके लिए सबसे अच्छा: ब्राउज़र को स्क्रैपिंग या टेस्टिंग के लिए ऑटोमेट करने वाले डेवलपर।
- मुख्य सुविधाएँ: मल्टी-ब्राउज़र सपोर्ट, क्लिक, स्क्रॉल, लॉगिन ऑटोमेट करता है।
- फ्री प्लान: असीमित (ओपन सोर्स)।
- सीमाएँ: हेडलेस लाइब्रेरी की तुलना में धीमा, स्क्रिप्टिंग चाहिए।
Zyte (Scrapy Cloud)
- प्लेटफ़ॉर्म: क्लाउड
- किसके लिए सबसे अच्छा: स्केल पर Scrapy spiders तैनात करने वाले डेवलपर और ऑप्स टीमें।
- मुख्य सुविधाएँ: होस्टेड Scrapy, प्रॉक्सी प्रबंधन, जॉब शेड्यूलिंग।
- फ्री प्लान: 1 एक साथ चलने वाला spider, 1 घंटा/जॉब, 7-दिन डेटा रिटेंशन।
- सीमाएँ: फ्री प्लान में उन्नत शेड्यूलिंग नहीं, Scrapy ज्ञान चाहिए।
टीम और एंटरप्राइज़ उपयोग के लिए
Apify
- प्लेटफ़ॉर्म: क्लाउड
- किसके लिए सबसे अच्छा: टीमें, अर्ध-तकनीकी यूज़र्स, और डेवलपर जो तैयार या कस्टम स्क्रैपर चाहते हैं।
- मुख्य सुविधाएँ: Actor मार्केटप्लेस (पहले से बने बॉट), शेड्यूलिंग, API, इंटीग्रेशन।
- फ्री प्लान: $5 क्रेडिट/माह (छोटे कामों के लिए काफ़ी), 7-दिन डेटा रिटेंशन।
- सीमाएँ: कुछ सीखने की ज़रूरत, उपयोग क्रेडिट से सीमित।
SerpAPI
- प्लेटफ़ॉर्म: API
- किसके लिए सबसे अच्छा: सर्च इंजन डेटा (Google, Bing, YouTube) की ज़रूरत वाले डेवलपर और एनालिस्ट।
- मुख्य सुविधाएँ: सर्च API, एंटी-ब्लॉकिंग, संरचित JSON आउटपुट।
- फ्री प्लान: 100 खोजें/माह।
- सीमाएँ: मनचाही वेबसाइटों के लिए नहीं, सिर्फ़ API उपयोग।
Diffbot
- प्लेटफ़ॉर्म: API
- किसके लिए सबसे अच्छा: स्केल पर संरचित वेब डेटा की ज़रूरत वाले डेवलपर, AI/ML टीमें, और एंटरप्राइज़।
- मुख्य सुविधाएँ: AI-संचालित एक्सट्रैक्शन, नॉलेज ग्राफ, आर्टिकल/प्रोडक्ट API।
- फ्री प्लान: 10,000 क्रेडिट/माह।
- सीमाएँ: सिर्फ़ API, तकनीकी कौशल चाहिए, रेट-लिमिटेड थ्रूपुट।
फ्री प्लान सीमाएँ: हर डेटा स्क्रैपर के लिए “मुफ़्त” का असली मतलब
सच बोलें—“मुफ़्त” का मतलब कुछ भी हो सकता है: शौक़ीन उपयोगकर्ताओं के लिए असीमित से लेकर “बस आपको फँसाने भर का” तक। यहाँ असल में क्या मिलता है, उसका विवरण है:
| टूल | प्रति माह पेज/पंक्तियाँ | एक्सपोर्ट फ़ॉर्मैट | शेड्यूलिंग | API एक्सेस | उल्लेखनीय फ्री सीमाएँ |
|---|---|---|---|---|---|
| Thunderbit | 6 पेज | Excel, CSV | नहीं | नहीं | AI फ़ील्ड सुझाव सीमित, फ्री में सीधे Sheets/Notion एक्सपोर्ट नहीं |
| Browse AI | 50 क्रेडिट | CSV, Sheets | हाँ | हाँ | 1 वेबसाइट, 5 रोबोट, 15-दिन रिटेंशन |
| Octoparse | 50,000 पंक्तियाँ | CSV, Excel, JSON | नहीं | नहीं | सिर्फ़ डेस्कटॉप, क्लाउड/शेड्यूलिंग नहीं |
| ParseHub | 200 पेज/रन | CSV, Excel, JSON | नहीं | नहीं | 5 सार्वजनिक प्रोजेक्ट, धीमी स्पीड |
| Webscraper.io | स्थानीय उपयोग असीमित | CSV, XLSX | नहीं | नहीं | मैन्युअल रन, क्लाउड नहीं |
| Apify | $5 क्रेडिट (~छोटा) | CSV, JSON, Sheets | हाँ | हाँ | 7-दिन रिटेंशन, क्रेडिट सीमा |
| Scrapy | असीमित | CSV, JSON, DB | नहीं | लागू नहीं | कोडिंग ज़रूरी |
| Puppeteer | असीमित | कस्टम (कोड) | नहीं | लागू नहीं | कोडिंग ज़रूरी |
| Selenium | असीमित | कस्टम (कोड) | नहीं | लागू नहीं | कोडिंग ज़रूरी |
| Zyte | 1 spider, 1 घंटा/जॉब | CSV, JSON | सीमित | हाँ | 7-दिन रिटेंशन, 1 एक साथ चलने वाला जॉब |
| SerpAPI | 100 खोजें | JSON | नहीं | हाँ | सिर्फ़ सर्च API |
| Diffbot | 10,000 क्रेडिट | JSON | नहीं | हाँ | सिर्फ़ API, रेट-लिमिटेड |
निचोड़: असली प्रोजेक्ट्स के लिए, Thunderbit, Browse AI, और Apify बिज़नेस यूज़र्स को सबसे उपयोगी मुफ़्त ट्रायल देते हैं। लगातार या बड़े पैमाने की स्क्रैपिंग के लिए आप जल्दी सीमाएँ छू लेंगे और फिर अपग्रेड करना पड़ेगा या ओपन-सोर्स/कोड-आधारित समाधान पर जाना होगा।
आपकी ज़रूरत के लिए कौन-सा डेटा स्क्रैपर टूल सबसे अच्छा है? (यूज़र टाइप गाइड)
यहाँ एक त्वरित गाइड है, जो आपकी भूमिका और तकनीक के साथ सहजता के आधार पर सही टूल चुनने में मदद करेगी:
| यूज़र टाइप | सर्वश्रेष्ठ टूल (मुफ़्त) | क्यों |
|---|---|---|
| बिना कोड वाला (सेल्स/मार्केटिंग) | Thunderbit, Browse AI, Webscraper.io | सीखने में सबसे तेज़, पॉइंट-एंड-क्लिक, AI मदद |
| अर्ध-तकनीकी (ऑप्स/एनालिस्ट) | Octoparse, ParseHub, Apify, Zyte | ज़्यादा ताकत, जटिल साइट्स संभाल सकते हैं, कुछ स्क्रिप्टिंग संभव |
| डेवलपर/इंजीनियर | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | पूरा नियंत्रण, असीमित, API-प्रथम |
| टीम/एंटरप्राइज़ | Apify, Zyte | सहयोग, शेड्यूलिंग, इंटीग्रेशन |
वास्तविक वेब स्क्रैपिंग परिदृश्य: टूल्स की अनुकूलता की तुलना
आइए देखें कि पाँच आम स्क्रैपिंग परिदृश्यों में ये टूल्स कैसे टिकते हैं:
| परिदृश्य | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| पेजिनेटेड लिस्टिंग्स | आसान | आसान | मध्यम | मध्यम | मध्यम | आसान | आसान | आसान | आसान | आसान | लागू नहीं | मध्यम |
| Google Maps लिस्टिंग्स | आसान* | कठिन | मध्यम | मध्यम | कठिन | आसान | कठिन | कठिन | कठिन | कठिन | आसान | लागू नहीं |
| लॉगिन-आवश्यक पेज | आसान | मध्यम | मध्यम | मध्यम | मैन्युअल | मध्यम | आसान | आसान | आसान | आसान | लागू नहीं | लागू नहीं |
| PDF डेटा एक्सट्रैक्शन | आसान | नहीं | नहीं | नहीं | नहीं | मध्यम | कठिन | कठिन | कठिन | कठिन | नहीं | सीमित |
| सोशल मीडिया कंटेंट | आसान* | आंशिक | कठिन | कठिन | कठिन | आसान | कठिन | कठिन | कठिन | कठिन | YouTube | सीमित |
- Thunderbit और Apify, Google Maps और सोशल मीडिया स्क्रैपिंग के लिए पहले से बने टेम्पलेट/Actor देते हैं, जिससे ये परिदृश्य गैर-तकनीकी यूज़र्स के लिए बहुत आसान हो जाते हैं।
प्लगइन बनाम डेस्कटॉप बनाम क्लाउड: सबसे अच्छा वेब स्क्रैपर अनुभव क्या है?
- Chrome एक्सटेंशन (Thunderbit, Webscraper.io):
- फायदे: जल्दी शुरू होते हैं, आपके ब्राउज़र में चलते हैं, सेटअप बहुत कम चाहिए।
- नुकसान: मैन्युअल ऑपरेशन, साइट बदलने पर प्रभावित हो सकते हैं, ऑटोमेशन सीमित।
- Thunderbit की बढ़त: AI संरचना बदलाव, सबपेज नेविगेशन, और PDF/इमेज स्क्रैपिंग तक संभालता है—इसे पारंपरिक एक्सटेंशनों से कहीं ज़्यादा मज़बूत बनाता है।
- डेस्कटॉप ऐप्स (Octoparse, ParseHub):
- फायदे: शक्तिशाली, विज़ुअल वर्कफ़्लो, डायनेमिक साइट और लॉगिन संभालते हैं।
- नुकसान: सीखने की रफ़्तार तेज़, फ्री प्लान में क्लाउड ऑटोमेशन नहीं, OS पर निर्भर।
- क्लाउड प्लेटफ़ॉर्म (Browse AI, Apify, Zyte):
- फायदे: शेड्यूलिंग, टीम सहयोग, स्केलेबल, इंटीग्रेशन।
- नुकसान: फ्री प्लान अक्सर क्रेडिट से सीमित, कुछ सेटअप चाहिए, API ज्ञान भी लग सकता है।
- ओपन-सोर्स लाइब्रेरी (Scrapy, Puppeteer, Selenium):
- फायदे: असीमित, कस्टमाइज़ेबल, डेवलपर्स के लिए आदर्श।
- नुकसान: कोडिंग ज़रूरी, बिज़नेस यूज़र्स के लिए नहीं।
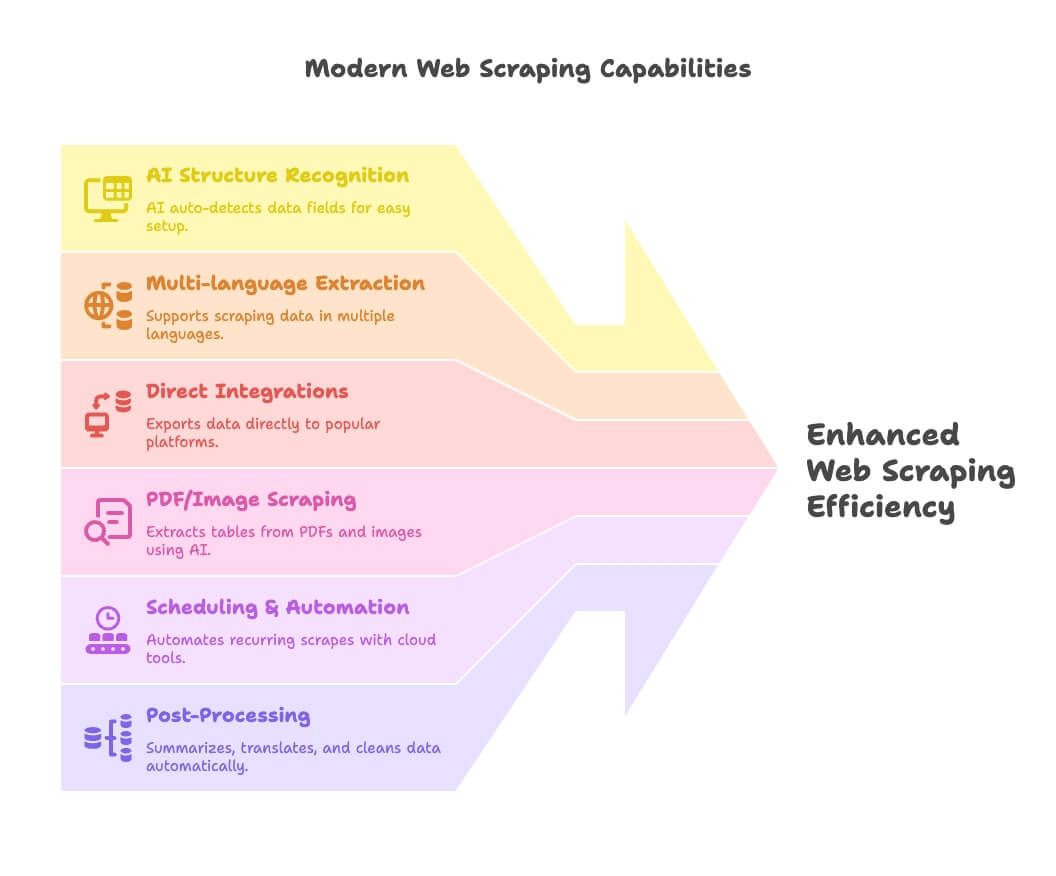
2026 वेब स्क्रैपिंग ट्रेंड्स: आधुनिक टूल्स को क्या अलग बनाता है
2026 में वेब स्क्रैपिंग का केंद्र AI, ऑटोमेशन और इंटीग्रेशन है। नए क्या है, देखिए:
- AI संरचना पहचान: Thunderbit जैसे टूल AI से डेटा फ़ील्ड अपने-आप पहचान लेते हैं, जिससे बिना कोड वालों के लिए सेटअप बहुत आसान हो जाता है।
- बहुभाषी एक्सट्रैक्शन: Thunderbit और अन्य टूल दर्जनों भाषाओं में डेटा स्क्रैप और प्रोसेस कर सकते हैं।
- डायरेक्ट इंटीग्रेशन: स्क्रैप किया गया डेटा सीधे Google Sheets, Notion या Airtable में एक्सपोर्ट करें—अब CSV से जूझने की ज़रूरत नहीं।
- PDF/इमेज स्क्रैपिंग: Thunderbit यहाँ आगे है; AI की मदद से PDF और इमेज से टेबल निकालने देता है।
- शेड्यूलिंग और ऑटोमेशन: क्लाउड टूल (Apify, Browse AI) आपको बार-बार होने वाले स्क्रैप को सेट करके भूल जाने देते हैं।
- पोस्ट-प्रोसेसिंग: स्क्रैप करते समय ही सारांश, अनुवाद, वर्गीकरण और सफ़ाई करें—अब गंदी स्प्रेडशीट नहीं।
Thunderbit, Apify, और SerpAPI इन ट्रेंड्स के सबसे आगे हैं, लेकिन Thunderbit इस वजह से अलग दिखता है कि वह AI-संचालित स्क्रैपिंग को सिर्फ डेवलपर्स नहीं, बल्कि हर किसी के लिए सुलभ बनाता है।
स्क्रैपिंग से आगे: डेटा प्रोसेसिंग और वैल्यू-ऐड सुविधाएँ
सिर्फ डेटा लेना ही सब कुछ नहीं है—उसे उपयोगी बनाना भी ज़रूरी है। पोस्ट-प्रोसेसिंग के मामले में टॉप टूल्स की स्थिति यह है:
| टूल | सफ़ाई | अनुवाद | वर्गीकरण | सारांश | नोट्स |
|---|---|---|---|---|---|
| Thunderbit | हाँ | हाँ | हाँ | हाँ | बिल्ट-इन AI पोस्ट-प्रोसेसिंग |
| Apify | आंशिक | आंशिक | आंशिक | आंशिक | इस्तेमाल किए गए actor पर निर्भर |
| Browse AI | नहीं | नहीं | नहीं | नहीं | सिर्फ़ रॉ डेटा |
| Octoparse | आंशिक | नहीं | आंशिक | नहीं | कुछ फ़ील्ड प्रोसेसिंग |
| ParseHub | आंशिक | नहीं | आंशिक | नहीं | कुछ फ़ील्ड प्रोसेसिंग |
| Webscraper.io | नहीं | नहीं | नहीं | नहीं | सिर्फ़ रॉ डेटा |
| Scrapy | हाँ* | हाँ* | हाँ* | हाँ* | अगर डेवलपर ने कोड किया हो |
| Puppeteer | हाँ* | हाँ* | हाँ* | हाँ* | अगर डेवलपर ने कोड किया हो |
| Selenium | हाँ* | हाँ* | हाँ* | हाँ* | अगर डेवलपर ने कोड किया हो |
| Zyte | आंशिक | नहीं | आंशिक | नहीं | कुछ ऑटो-एक्सट्रैक्शन सुविधाएँ |
| SerpAPI | नहीं | नहीं | नहीं | नहीं | सिर्फ़ संरचित सर्च डेटा |
| Diffbot | हाँ | हाँ | हाँ | हाँ | AI-संचालित, लेकिन सिर्फ़ API |
- प्रोसेसिंग लॉजिक डेवलपर को लागू करना होता है।
Thunderbit ही ऐसा टूल है, जो गैर-तकनीकी यूज़र्स को रॉ वेब डेटा से सीधे काम के, संरचित इनसाइट्स तक एक ही वर्कफ़्लो में ले जाता है।
समुदाय, सपोर्ट, और सीखने के संसाधन: तेज़ी से दक्ष कैसे बनें
दस्तावेज़ और ऑनबोर्डिंग बहुत महत्वपूर्ण होते हैं। टूल्स की तुलना यहाँ है:
| टूल | दस्तावेज़ और ट्यूटोरियल | समुदाय | टेम्पलेट्स | सीखने की रफ़्तार |
|---|---|---|---|---|
| Thunderbit | उत्कृष्ट | बढ़ता हुआ | हाँ | बहुत कम |
| Browse AI | अच्छा | अच्छा | हाँ | कम |
| Octoparse | उत्कृष्ट | बड़ा | हाँ | मध्यम |
| ParseHub | उत्कृष्ट | बड़ा | हाँ | मध्यम |
| Webscraper.io | अच्छा | फ़ोरम | हाँ | मध्यम |
| Apify | उत्कृष्ट | बड़ा | हाँ | मध्यम-उच्च |
| Scrapy | उत्कृष्ट | बहुत बड़ा | लागू नहीं | उच्च |
| Puppeteer | अच्छा | बड़ा | लागू नहीं | उच्च |
| Selenium | अच्छा | बहुत बड़ा | लागू नहीं | उच्च |
| Zyte | अच्छा | बड़ा | हाँ | मध्यम-उच्च |
| SerpAPI | अच्छा | मध्यम | लागू नहीं | उच्च |
| Diffbot | अच्छा | मध्यम | लागू नहीं | उच्च |
Thunderbit और Browse AI शुरुआती लोगों के लिए सबसे आसान हैं। Octoparse और ParseHub के संसाधन शानदार हैं, लेकिन धैर्य ज़्यादा चाहिए। Apify और डेवलपर टूल्स सीखने में कठिन हैं, लेकिन दस्तावेज़ अच्छी तरह से लिखे गए हैं।
निष्कर्ष: 2026 के लिए सही मुफ़्त डेटा स्क्रैपर चुनना
निष्कर्ष यह है: सभी “मुफ़्त” डेटा स्क्रैपर टूल्स एक जैसे उपयोगी नहीं होते, और आपकी पसंद आपकी भूमिका, तकनीकी सहजता और वास्तविक स्क्रैपिंग ज़रूरतों पर निर्भर होनी चाहिए।
- अगर आप बिज़नेस यूज़र या बिना कोड वाले हैं और तेज़ी से डेटा पाना चाहते हैं—खासतौर पर मुश्किल साइट्स, PDFs या इमेज से—तो Thunderbit सबसे अच्छी शुरुआत है। इसका AI-आधारित तरीका, प्राकृतिक भाषा प्रॉम्प्ट, और पोस्ट-प्रोसेसिंग सुविधाएँ इसे एक असली AI डेटा असिस्टेंट के सबसे करीब बनाती हैं। को मुफ़्त में आज़माएँ और देखें कि “मुझे यह डेटा चाहिए” से “यह रही मेरी स्प्रेडशीट” तक आप कितनी जल्दी पहुँच सकते हैं।
- अगर आप डेवलपर हैं या असीमित, कस्टमाइज़ेबल स्क्रैपिंग चाहते हैं, तो Scrapy, Puppeteer और Selenium जैसे ओपन-सोर्स टूल्स आपकी सबसे अच्छी पसंद हैं।
- टीमों और अर्ध-तकनीकी यूज़र्स के लिए, Apify और Zyte स्केलेबल, सहयोगी समाधान देते हैं, जिनमें छोटे कामों के लिए उदार फ्री टियर है।
आपका वर्कफ़्लो चाहे जैसा भी हो, उस टूल से शुरुआत करें जो आपकी स्किल और ज़रूरतों से मेल खाता हो। और याद रखिए: 2026 में वेब डेटा की ताकत इस्तेमाल करने के लिए आपको कोडर होने की ज़रूरत नहीं है—बस सही असिस्टेंट चाहिए (और शायद तब थोड़ा हास्य भी, जब रोबोट आपसे तेज़ निकल जाएँ)।
और गहराई में जाना चाहते हैं? पर और गाइड्स और तुलना देखें, जिनमें शामिल हैं: