
पिछली तिमाही में, हमारी ऑप्स टीम हर हफ्ते 40 घंटे प्रतियोगी डेटा को स्प्रेडशीट में कॉपी-पेस्ट करने में लगा रही थी। इस तिमाही में, यह काम 20 मिनट में हो जाता है।
फर्क? स्वचालित वेब स्क्रैपिंग टूल्स। अब ये सिर्फ डेवलपर्स तक सीमित नहीं रहे; कोई भी सेल्स रिप्रेज़ेंटेटिव या मार्केटर इन्हें लंच के दौरान सेट कर सकता है।
मैं सालों से SaaS और ऑटोमेशन टूल्स बना रहा हूँ (और हाँ, मैंने की सह-स्थापना भी की है)। 2026 की फसल अब तक की सबसे मजबूत है — AI-native, self-healing, और गैर-तकनीकी लोगों के लिए सच में उपयोगी।
यहाँ 10 टूल हैं जिन्हें मैंने खुद इस्तेमाल करके आंका है, उनके उपयोग-केस और कौशल-स्तर के हिसाब से तुलना की गई है।
व्यापार उपयोगकर्ताओं के लिए स्वचालित वेब स्क्रैपिंग टूल्स क्यों ज़रूरी हैं
साफ़ बात है: वेबसाइटों से डेटा को मैन्युअल रूप से कॉपी और पेस्ट करने के दिन अब खत्म हो चुके हैं (जब तक कि आपको repetitive stress injury और existential dread पसंद न हो)। स्वचालित वेब स्क्रैपिंग टूल्स हर आकार के व्यवसायों के लिए अब बेहद ज़रूरी हो गए हैं। वास्तव में, , और वेब स्क्रैपिंग उस रणनीति का अहम हिस्सा है।
ये टूल्स इतने मूल्यवान क्यों हैं:
- समय बचाएँ और मैन्युअल काम कम करें: स्वचालित स्क्रैपर्स कुछ ही मिनटों में हज़ारों रिकॉर्ड प्रोसेस कर सकते हैं, जिससे आपकी टीम ज़्यादा महत्वपूर्ण कामों पर ध्यान दे सकती है। एक टूल यूज़र ने बताया कि डेटा कलेक्शन ऑटोमेट करके उसने “सैकड़ों घंटे” बचाए ()।
- डेटा की सटीकता बेहतर करें: अब टाइपो या छूटी हुई एंट्रीज़ की चिंता नहीं। ऑटोमेटेड एक्सट्रैक्शन का मतलब है ज़्यादा साफ़ और भरोसेमंद डेटा।
- तेज़ निर्णय-निर्माण में मदद करें: रियल-टाइम डेटा फ़ीड्स के साथ आप प्रतिस्पर्धियों पर नज़र रख सकते हैं, कीमतों को ट्रैक कर सकते हैं, या हर महीने की इंटर्न रिपोर्ट का इंतज़ार किए बिना लीड लिस्ट बना सकते हैं।
- गैर-तकनीकी टीमों को सक्षम करें: नो-कोड और AI-चालित टूल्स की वजह से, यहाँ तक कि वे लोग भी जो सोचते हैं कि “XPath” कोई योगासन है, अब वेब डेटा पाइपलाइन बना सकते हैं ()।
यह हैरानी की बात नहीं है कि , और लगभग 80% कहते हैं कि उनका संगठन इसके बिना प्रभावी ढंग से काम नहीं कर सकता। 2026 में, अगर आप अपना डेटा कलेक्शन ऑटोमेट नहीं कर रहे हैं, तो आप शायद पैसा — और इनसाइट्स — मेज़ पर छोड़ रहे हैं।
हमने सबसे अच्छे स्वचालित वेब स्क्रैपिंग टूल्स कैसे चुने
वेब स्क्रैपिंग सॉफ़्टवेयर बाज़ार के का अनुमान है, इसलिए सही टूल चुनना ऐसा लग सकता है जैसे 10,000 विकल्पों वाले स्टोर में जूते खरीदना। मैंने इसे ऐसे फ़िल्टर किया:
- उपयोग में आसानी: क्या कोई गैर-डेवलपर जल्दी शुरुआत कर सकता है? क्या सीखने की प्रक्रिया कठिन है?
- AI क्षमताएँ: क्या टूल AI का उपयोग करके डेटा फ़ील्ड्स अपने-आप पहचानता है, डायनेमिक साइट्स को संभालता है, या आपको अपनी ज़रूरतें साधारण अंग्रेज़ी में बताने देता है?
- डेटा एक्सपोर्ट और इंटीग्रेशन: आप अपने डेटा को Excel, Google Sheets, Airtable, Notion, या अपने CRM में कितनी आसानी से ला सकते हैं?
- मूल्य निर्धारण: क्या फ्री ट्रायल मिलता है? क्या पेड प्लान व्यक्तिगत उपयोगकर्ताओं और छोटी टीमों के लिए किफ़ायती हैं, या सिर्फ़ एंटरप्राइज़ के लिए?
- स्केलेबिलिटी: क्या टूल छोटे एकबारगी काम और बड़े, शेड्यूल्ड एक्सट्रैक्शन — दोनों संभाल सकता है?
- लक्षित उपयोगकर्ता: क्या यह बिज़नेस यूज़र्स, डेवलपर्स, या दोनों के लिए बना है?
- विशिष्ट ताकतें: यह टूल भीड़ से अलग क्या करता है?
मैंने हर कौशल-स्तर के लिए टूल शामिल किए हैं — “मुझे बस एक स्प्रेडशीट चाहिए” से लेकर “मुझे पूरा इंटरनेट क्रॉल करना है” तक। चलिए सूची में आगे बढ़ते हैं।
1. Thunderbit: हर किसी के लिए AI-संचालित वेब स्क्रैपर टूल
मैं उस टूल से शुरुआत करता हूँ जिसे मैं सबसे अच्छी तरह जानता हूँ — क्योंकि, ठीक है, मेरी टीम और मैंने इसे ठीक उन्हीं परेशानियों को हल करने के लिए बनाया था जिनका सामना मैंने सालों से बिज़नेस यूज़र्स में देखा है। आपका आम “drag-and-drop” या “खुद selector लिखो” स्क्रैपर नहीं है। यह एक AI-संचालित डेटा असिस्टेंट है जो आपको बताने देता है कि आपको क्या चाहिए, और फिर बाकी भारी काम खुद करता है — कोई कोड नहीं, XPath से कोई झंझट नहीं, कोई आँसू नहीं।
Thunderbit सूची में सबसे ऊपर क्यों है
Thunderbit अब तक मैंने जो देखा है, उसमें “किसी भी वेबसाइट को डेटाबेस में बदलने” के सबसे करीब है। यह ऐसे काम करता है:
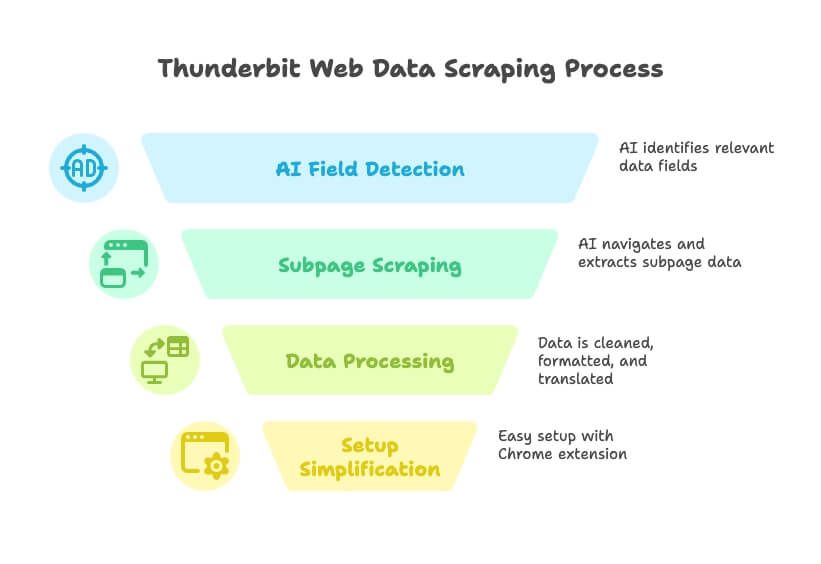
- प्राकृतिक भाषा-आधारित: बस Thunderbit को बताइए कि आपको कौन-सा डेटा चाहिए (“मुझे इस डायरेक्टरी से सभी कंपनी नाम, ईमेल, और फ़ोन नंबर चाहिए”), और AI प्रासंगिक फ़ील्ड्स अपने-आप पहचान लेगा।
- AI फ़ील्ड्स सुझाता है: एक क्लिक में Thunderbit पेज पढ़ता है और निकालने के लिए सबसे अच्छे कॉलम सुझाता है — अब अंदाज़ा लगाने या ट्रायल-एंड-एरर की ज़रूरत नहीं।
- सबपेज और मल्टी-लेवल स्क्रैपिंग: क्या हर लिस्टिंग के सबपेज से विवरण चाहिए? Thunderbit क्लिक करके आगे बढ़ सकता है, अतिरिक्त जानकारी ले सकता है, और उसे आपकी टेबल में जोड़ सकता है।
- डेटा सफ़ाई, अनुवाद, और वर्गीकरण: Thunderbit सिर्फ़ कच्चा डेटा नहीं निकालता — यह स्क्रैप करते समय डेटा को साफ़, फ़ॉर्मैट, अनुवाद, और यहाँ तक कि वर्गीकृत भी कर सकता है।
- सेटअप की कोई झंझट नहीं: इंस्टॉल करें, “AI Suggest Fields” पर क्लिक करें, और एक मिनट से भी कम समय में स्क्रैपिंग शुरू करें।
- फ्री ट्रायल और कम लागत: उदार फ्री टियर (6 पेज तक मुफ़्त स्क्रैप कर सकते हैं), और पेड प्लान सिर्फ़ $9/महीना से शुरू होते हैं। यह उस कॉफ़ी से भी कम है जो मैं एक हफ्ते में पी जाता हूँ।
Thunderbit उन सेल्स, मार्केटिंग, और ऑपरेशंस टीमों के लिए बना है जिन्हें तेज़ी से डेटा चाहिए। कोडिंग नहीं, प्लगइन्स नहीं, ट्रेनिंग की ज़रूरत नहीं। यह ऐसा है जैसे आपके पास एक डेटा इंटर्न हो जो सचमुच सुनता हो और कभी शिकायत न करता हो।
Thunderbit की सबसे खास विशेषताएँ
- AI-चालित स्क्रैपिंग: AI पेज की संरचना समझता है, लेआउट बदलने पर खुद को ढाल लेता है, और pagination तथा सबपेज को भी अपने-आप संभालता है ()।
- तुरंत डेटा एक्सपोर्ट: अपने परिणाम सीधे Excel, Google Sheets, Airtable, Notion में भेजें, या CSV/JSON के रूप में डाउनलोड करें।
- क्लाउड या लोकल रन: गति और स्केल के लिए क्लाउड में स्क्रैप चलाएँ, या अगर आपको अपना लॉगिन/सेशन इस्तेमाल करना है तो ब्राउज़र में चलाएँ।
- शेड्यूल्ड स्क्रैपिंग: डेटा को ताज़ा रखने के लिए आवर्ती जॉब्स सेट करें — कीमतों की निगरानी या नियमित लीड अपडेट के लिए बिल्कुल सही।
- मेंटेनेंस-फ्री: Thunderbit का AI वेबसाइट बदलावों के अनुसार ढल जाता है, इसलिए आप टूटे हुए स्क्रैपर्स ठीक करने में कम समय लगाते हैं ()।
यह किसके लिए है? जो कोई भी “मुझे यह डेटा चाहिए” से “यह रहा आपकी स्प्रेडशीट” तक कुछ मिनटों में पहुँचना चाहता है — खासकर गैर-तकनीकी उपयोगकर्ता। और 4.9★ रेटिंग के साथ, Thunderbit तेज़ी से उन बिज़नेस टीमों की पहली पसंद बन रहा है जो नतीजे चाहती हैं, झंझट नहीं।
इसे काम करते देखना चाहते हैं? देखें या और पढ़ें।
2. Clay: ऑटोमेटेड डेटा एनरिचमेंट और वेब स्क्रैपिंग का मेल
Clay ग्रोथ टीमों के लिए Swiss Army knife जैसा है। यह सिर्फ़ वेब स्क्रैपर नहीं है — यह एक ऑटोमेशन स्प्रेडशीट है जो 50+ लाइव डेटा स्रोतों (जैसे Apollo, LinkedIn, Crunchbase) से जुड़ती है और एम्बेडेड AI का उपयोग करके लीड्स को समृद्ध करती है, आउटरीच ईमेल लिखती है, और संभावनाओं को स्कोर करती है।
- वर्कफ़्लो ऑटोमेशन: हर row एक लीड है, हर column डेटा खींच सकता है या कोई action ट्रिगर कर सकता है। कंपनी सूची स्क्रैप करनी है, LinkedIn प्रोफ़ाइल्स से समृद्ध करना है, और पर्सनलाइज़्ड ईमेल भेजना है? Clay आपके साथ है।
- AI इंटीग्रेशन: आइसब्रेकर्स लिखने, बायो संक्षेप करने, और भी बहुत कुछ के लिए GPT-4 का उपयोग करता है।
- इंटीग्रेशन: HubSpot, Salesforce, Gmail, Slack, और बहुत से अन्य ऐप्स से सीधे जुड़ता है।
- मूल्य निर्धारण: प्रोफ़ेशनल प्लान लगभग $99/महीना से शुरू होता है, और हल्के उपयोग के लिए फ्री ट्रायल भी है।
सबसे अच्छा किसके लिए: आउटबाउंड सेल्स, ग्रोथ हैकर्स, और मार्केटर्स जो कस्टम लीड पाइपलाइन बनाना चाहते हैं — स्क्रैपिंग, एनरिचमेंट, और आउटरीच को एक ही जगह जोड़कर। यह शक्तिशाली है, लेकिन अगर आप ऑटोमेशन टूल्स में नए हैं तो सीखने की प्रक्रिया थोड़ी कठिन हो सकती है ()।
3. Bardeen: वर्कफ़्लो ऑटोमेशन के लिए ब्राउज़र-आधारित वेब स्क्रैपर टूल
Bardeen ऐसा है जैसे आपके पास एक ब्राउज़र रोबोट हो जो Chrome extension से ही डेटा स्क्रैप कर सकता है और दोहराए जाने वाले वेब कार्यों को ऑटोमेट कर सकता है।
- नो-कोड ऑटोमेशन: स्क्रैपिंग, फ़ॉर्म भरने, ऐप्स के बीच डेटा मूव करने, और बहुत कुछ के लिए 500+ “Playbooks”।
- AI कमांड बिल्डर: अपना काम साधारण अंग्रेज़ी में बताइए, और Bardeen वर्कफ़्लो बना देता है।
- इंटीग्रेशन: Notion, Trello, Slack, Salesforce, और 100+ अन्य ऐप्स के साथ काम करता है।
- मूल्य निर्धारण: हल्के उपयोग के लिए मुफ़्त (100 automation credits/महीना), और टीमों के लिए पेड प्लान $99/महीना से शुरू होते हैं।
सबसे अच्छा किसके लिए: पावर यूज़र्स और go-to-market टीमें जो कई ऐप्स में स्क्रैपिंग और फ़ॉलो-अप क्रियाओं को ऑटोमेट करना चाहती हैं। इसमें बहुत लचीलापन है, लेकिन शुरुआती उपयोगकर्ताओं को सीखने की प्रक्रिया थोड़ी कठिन लग सकती है ()।
4. Bright Data: एंटरप्राइज़-स्तरीय स्वचालित वेब स्क्रैपिंग टूल्स
Bright Data (पहले Luminati) वेब स्क्रैपिंग की भारी मशीनरी है — यानी global proxy networks, advanced APIs, और रोज़ हज़ारों पेज क्रॉल करने की क्षमता।
- एंटरप्राइज़-स्केल: 100 मिलियन से अधिक IPs, Web Scraper IDE, anti-bot उपायों को बायपास करने के लिए Web Unlocker।
- कस्टमाइज़ेबल: उच्च विश्वसनीयता के साथ जटिल, बड़े पैमाने के एक्सट्रैक्शन बनाइए।
- मूल्य निर्धारण: Web Scraper IDE के लिए $499/महीना से शुरू, साथ में छोटे “micro” पैकेज उपलब्ध।
सबसे अच्छा किसके लिए: बड़े एंटरप्राइज़, डेटा एग्रीगेटर्स, और उन्नत उपयोगकर्ता जिन्हें मज़बूत, स्केलेबल समाधान चाहिए। अगर आप रोज़ हज़ारों पेज क्रॉल कर रहे हैं और IP blocks से बचना चाहते हैं, तो Bright Data आपके लिए बना है ()।
5. Octoparse: मध्य-स्तर उपयोगकर्ताओं के लिए विज़ुअल वेब स्क्रैपर टूल
Octoparse एक लोकप्रिय नो-कोड टूल है, जिसका visual, point-and-click interface है — प्रोग्रामिंग के बिना ताकत चाहने वाले उपयोगकर्ताओं के लिए बिल्कुल सही।
- Drag-and-drop UI: निकालने के लिए क्या चाहिए, यह तय करने हेतु एलिमेंट्स पर क्लिक करें; लॉगिन, pagination, और बहुत कुछ संभालें।
- टेम्पलेट्स: आम साइट्स (Amazon, Twitter, आदि) के लिए 500+ तैयार टेम्पलेट्स।
- क्लाउड स्क्रैपिंग: Octoparse के सर्वरों पर जॉब्स चलाएँ, एक्सट्रैक्शन शेड्यूल करें, और IP rotation का उपयोग करें।
- मूल्य निर्धारण: सीमाओं के साथ मुफ़्त प्लान; पेड प्लान $119/महीना से शुरू।
सबसे अच्छा किसके लिए: गैर-प्रोग्रामर और डेटा एनालिस्ट्स जो कोड लिखे बिना सक्षम स्क्रैपर चाहते हैं। कीमतों की निगरानी, प्रोडक्ट लिस्टिंग, और रिसर्च प्रोजेक्ट्स के लिए बढ़िया ()।
6. : व्यवसायों के लिए डेटा स्क्रैपिंग प्लेटफ़ॉर्म
वेब स्क्रैपिंग के पुराने दिग्गजों में से एक है, जो अब एक पूर्ण-स्तरीय डेटा एक्सट्रैक्शन प्लेटफ़ॉर्म में विकसित हो चुका है।
- Point-and-click extraction: लॉगिन, ड्रॉपडाउन, और इंटरैक्टिव एलिमेंट्स संभालता है।
- क्लाउड-आधारित: हज़ारों URLs को एक साथ प्रोसेस करें, एक्सट्रैक्शन शेड्यूल करें, और APIs का उपयोग करें।
- एंटरप्राइज़ फ़ोकस: कीमतों की निगरानी, मार्केट रिसर्च, और मशीन लर्निंग डेटासेट बनाने के लिए इस्तेमाल किया जाता है।
- मूल्य निर्धारण: Starter प्लान $199/महीना, Standard $599/महीना, Advanced $1,099/महीना।
सबसे अच्छा किसके लिए: मध्यम से बड़े एंटरप्राइज़ और डेटा टीमें जिन्हें बड़े कामों के लिए भरोसेमंद, मेंटेन किए गए समाधान चाहिए। यह शौकिया प्रोजेक्ट्स के लिए शायद ज़रूरत से ज़्यादा हो सकता है, लेकिन व्यवसाय-स्तरीय ज़रूरतों के लिए यह एक ताकतवर विकल्प है ()।
7. Parsehub: विज़ुअल एडिटर वाला लचीला वेब स्क्रैपर टूल
Parsehub एक desktop app (Windows, Mac, Linux) है जो आपको वेबसाइट के interface पर क्लिक करके स्क्रैपर बनाने देता है।
- विज़ुअल वर्कफ़्लो: एलिमेंट्स चुनें, एक्सट्रैक्शन नियम सेट करें, और लॉगिन, ड्रॉपडाउन, तथा infinite scroll संभालें।
- क्लाउड फ़ीचर्स: क्लाउड में स्क्रैप चलाएँ, जॉब्स शेड्यूल करें, और API एक्सेस का उपयोग करें।
- मूल्य निर्धारण: छोटे कामों के लिए मुफ़्त टियर; पेड प्लान $149/महीना से शुरू।
सबसे अच्छा किसके लिए: शोधकर्ता, छोटे व्यवसाय, या ऐसे व्यक्ति जो browser extension से ज़्यादा नियंत्रण चाहते हैं, लेकिन अपना स्क्रैपर खुद कोड करने के लिए तैयार नहीं हैं ()।
8. Common Crawl: AI और शोध के लिए खुला वेब डेटा
Common Crawl पारंपरिक अर्थों में कोई टूल नहीं है — यह वेब क्रॉल डेटा का एक विशाल खुला डेटासेट है, जो हर महीने अपडेट होता है।
- स्केल: लगभग 400 TB वेब डेटा, जिसमें अरबों वेब पेज शामिल हैं।
- मुफ़्त और खुला: अपना क्रॉलर चलाने की ज़रूरत नहीं।
- तकनीकी कौशल आवश्यक: डेटा को फ़िल्टर और पार्स करने के लिए बिग डेटा टूल्स और कुछ इंजीनियरिंग कौशल चाहिए।
सबसे अच्छा किसके लिए: AI मॉडल बनाने या बड़े पैमाने पर शोध करने वाले डेटा साइंटिस्ट्स और इंजीनियर्स। अगर आपको सामान्य वेब टेक्स्ट या लंबे समय का आर्काइव चाहिए, तो यह खज़ाना है ()।
9. Crawly: स्टार्टअप्स के लिए हल्का स्वचालित वेब स्क्रैपिंग टूल
Crawly (Diffbot द्वारा) एक क्लाउड-आधारित, AI-संचालित crawler है जो लाखों वेबसाइटों से डेटा कैप्चर कर सकता है और संरचित परिणाम लौटा सकता है — parsing rules की ज़रूरत नहीं।
- AI एक्सट्रैक्शन: सामग्री की पहचान और निष्कर्षण के लिए machine vision और NLP का उपयोग करता है।
- API एक्सेस: इकट्ठे डेटा को क्वेरी करें और analytics या databases के साथ इंटीग्रेट करें।
- मूल्य निर्धारण: एंटरप्राइज़-स्तर; कीमत के लिए संपर्क करें।
सबसे अच्छा किसके लिए: स्टार्टअप्स और कुछ तकनीकी कौशल वाली टीमें जिन्हें अपने स्क्रैपर खुद बनाए बिना बड़े पैमाने पर, intelligent web data extraction चाहिए ()।
10. Apify: मार्केटप्लेस वाला डेवलपर-फ्रेंडली वेब स्क्रैपर टूल
Apify एक cloud platform है जहाँ आप अपने खुद के स्क्रैपर्स (“Actors”) बना सकते हैं या पहले से बने community scrapers की लाइब्रेरी का उपयोग कर सकते हैं।
- डेवलपर लचीलापन: JavaScript/Python-आधारित scraping, headless Chrome, proxy management, और scheduling का समर्थन करता है।
- मार्केटप्लेस: आम साइट्स के लिए तैयार स्क्रैपर्स की बड़ी लाइब्रेरी।
- मूल्य निर्धारण: $5/महीना क्रेडिट के साथ मुफ़्त टियर; पेड प्लान $49/महीना से शुरू।
सबसे अच्छा किसके लिए: डेवलपर्स और तकनीक-समझ रखने वाले एनालिस्ट्स जो पूरा नियंत्रण और स्केलेबिलिटी चाहते हैं। गैर-कोडर्स भी आम कामों के लिए तैयार Actors का उपयोग कर सकते हैं ()।
स्वचालित वेब स्क्रैपिंग टूल्स तुलना तालिका
| टूल | उपयोग में आसानी | AI सुविधाएँ | मूल्य (प्रारंभिक) | लक्षित उपयोगकर्ता | विशिष्ट ताकतें |
|---|---|---|---|---|---|
| Thunderbit | ★★★★★ | प्राकृतिक भाषा, AI फ़ील्ड्स सुझाएँ, सबपेज स्क्रैपिंग | $9/माह | गैर-तकनीकी बिज़नेस यूज़र्स | 2-क्लिक सेटअप, कोई कोड नहीं, तुरंत एक्सपोर्ट, फ्री ट्रायल |
| Clay | ★★★★☆ | AI एनरिचमेंट, GPT-4 | $99/माह | ग्रोथ/सेल्स ऑप्स | ऑटोमेशन स्प्रेडशीट, एनरिचमेंट, आउटरीच |
| Bardeen | ★★★★☆ | AI कमांड बिल्डर | $99/माह | पावर यूज़र्स, GTM टीमें | ब्राउज़र RPA, 500+ प्लेबुक्स, गहरे इंटीग्रेशन |
| Bright Data | ★★☆☆☆ | प्रॉक्सी रोटेशन, anti-bot AI | $499/माह | एंटरप्राइज़, डेवलपर्स | स्केल, विश्वसनीयता, global proxies |
| Octoparse | ★★★★☆ | विज़ुअल AI डिटेक्शन | $119/माह | एनालिस्ट्स, non-coders | drag-and-drop, टेम्पलेट्स, क्लाउड स्क्रैपिंग |
| Import.io | ★★★☆☆ | इंटरैक्टिव एक्सट्रैक्टर्स | $199/माह | एंटरप्राइज़, डेटा टीमें | concurrency, scheduling, API, सपोर्ट |
| Parsehub | ★★★★☆ | विज़ुअल वर्कफ़्लोज़ | $149/माह | शोधकर्ता, SMBs | desktop app, डायनेमिक साइट्स संभालता है |
| Common Crawl | ★☆☆☆☆ | लागू नहीं (सिर्फ़ डेटासेट) | मुफ़्त | डेटा साइंटिस्ट्स, इंजीनियर्स | विशाल खुला डेटासेट, web-scale archives |
| Crawly | ★★☆☆☆ | AI एक्सट्रैक्शन | कस्टम/एंटरप्राइज़ | स्टार्टअप्स, तकनीकी टीमें | AI-संचालित, parsing rules नहीं, API एक्सेस |
| Apify | ★★★★☆ | Actor marketplace | $49/माह | डेवलपर्स, तकनीकी एनालिस्ट्स | build/marketplace, cloud automation, लचीलापन |
आपकी ज़रूरतों के लिए सही वेब स्क्रैपर टूल कैसे चुनें
सबसे अच्छा स्वचालित वेब स्क्रैपिंग टूल चुनना आपकी टीम के आकार, तकनीकी कौशल, और व्यावसायिक लक्ष्यों पर निर्भर करता है। यहाँ मेरी त्वरित गाइड है:
- गैर-तकनीकी उपयोगकर्ताओं के लिए (सेल्स, मार्केटिंग, ऑप्स): चुनें। यह आपके लिए बना है — कोई कोड नहीं, कोई सेटअप नहीं, बस नतीजे। लीड जनरेशन, कीमतों की निगरानी, और त्वरित डेटा प्रोजेक्ट्स के लिए बिल्कुल सही।
- ऑटोमेशन-प्रेमी टीमों के लिए: अगर आप स्क्रैपिंग को एनरिचमेंट, आउटरीच, या वर्कफ़्लो ऑटोमेशन के साथ जोड़ना चाहते हैं, तो Clay और Bardeen बेहतरीन हैं।
- एंटरप्राइज़ और डेवलपर्स के लिए: Bright Data, , और Apify बड़े पैमाने के, अत्यधिक कस्टमाइज़ेबल प्रोजेक्ट्स के लिए आपके सबसे अच्छे विकल्प हैं।
- शोधकर्ताओं और एनालिस्ट्स के लिए: Octoparse और Parsehub कोड लिखे बिना विज़ुअल इंटरफ़ेस और शक्तिशाली सुविधाएँ देते हैं।
- AI और डेटा साइंस प्रोजेक्ट्स के लिए: Common Crawl और Crawly उन लोगों के लिए विशाल डेटासेट और AI-संचालित एक्सट्रैक्शन देते हैं जो मॉडल बनाना या ट्रेन करना चाहते हैं।
खुद से पूछें: क्या आप कुछ मिनटों में शुरुआत करना चाहते हैं, या आपको कस्टम, एंटरप्राइज़-ग्रेड समाधान बनाना है? अगर निश्चित नहीं हैं, तो फ्री ट्रायल से शुरू करें — ज़्यादातर टूल्स यह सुविधा देते हैं।
Thunderbit का अनोखा मूल्य: व्यावसायिक डेटा के लिए AI असिस्टेंट
इन सभी टूल्स में से Thunderbit एकमात्र ऐसा है जो सचमुच वेब स्क्रैपिंग और डेटा ट्रांसफ़ॉर्मेशन के लिए “AI असिस्टेंट” की तरह काम करता है। यह सिर्फ़ डेटा खींचने के बारे में नहीं है — यह मुश्किल, बिखरी हुई वेबसाइटों को बिना किसी तकनीकी बाधा के साफ़, संरचित इनसाइट्स में बदलने के बारे में है।
- प्राकृतिक भाषा इंटरफ़ेस: अपनी ज़रूरतें साधारण अंग्रेज़ी में बताइए, और बाकी Thunderbit संभाल लेता है।
- पूर्ण वर्कफ़्लो ऑटोमेशन: एक्सट्रैक्शन से लेकर सफ़ाई, अनुवाद, और एक्सपोर्ट तक — Thunderbit पूरी प्रक्रिया कवर करता है।
- तेज़ प्रयोगों के लिए बिल्कुल सही: नया बाज़ार सत्यापित करना है, लीड लिस्ट बनानी है, या प्रतिस्पर्धियों पर नज़र रखनी है? Thunderbit सबसे तेज़, सबसे कम लागत वाला शुरुआती बिंदु है।
यह ऐसा है जैसे आपका ब्राउज़र एक डेटा एनालिस्ट के साथ आता हो — जो कभी वेतन नहीं मांगता और कभी छुट्टी नहीं लेता।
निष्कर्ष: सही स्वचालित वेब स्क्रैपिंग टूल के साथ स्मार्ट शुरुआत करें
2026 में स्क्रैपिंग का परिदृश्य दो साल पहले की तुलना में पहचान में नहीं आता। self-healing AI स्क्रैपर्स, LLM-native पाइपलाइन्स, और सच में उपयोगी नो-कोड टूल्स ने खेल बदल दिया है। चाहे आप एक solo founder हों, एक चुस्त sales team, या एक enterprise data scientist — इस सूची में आपकी ज़रूरत के हिसाब से एक टूल मौजूद है। मुख्य बात है अपने वर्कफ़्लो और कौशल को सही प्लेटफ़ॉर्म से मिलाना — ताकि आप कोड से जूझना बंद करें और इनसाइट्स निकालना शुरू करें।
अगर आप मैन्युअल copy-paste छोड़कर स्मार्ट शुरुआत करने के लिए तैयार हैं, तो और देखें कि वेब स्क्रैपिंग कितनी आसान हो सकती है। या, ऊपर दिए गए अपने लक्ष्यों के आधार पर अन्य विकल्पों को एक्सप्लोर करें। किसी भी तरह, डेटा-चालित व्यवसाय का भविष्य उन्हीं का है जो ऑटोमेट करते हैं।
और जानना चाहते हैं? देखें — गहराई से समझाने वाले लेख, ट्यूटोरियल्स, और अपने वेब डेटा से अधिकतम लाभ लेने के टिप्स के लिए। हैप्पी स्क्रैपिंग — और याद रखिए, आपका डेटा हमेशा साफ़ रहे और आपके स्क्रैपर्स कभी टूटें नहीं (और अगर टूटें भी, तो AI को संभालने दें)।
अक्सर पूछे जाने वाले प्रश्न
1. 2026 में व्यापार उपयोगकर्ताओं के लिए स्वचालित वेब स्क्रैपिंग टूल्स क्यों ज़रूरी हैं?
स्वचालित वेब स्क्रैपिंग टूल्स डेटा कलेक्शन को सुव्यवस्थित करते हैं, समय बचाते हैं, और मैन्युअल काम कम करते हैं। ये डेटा की सटीकता बढ़ाते हैं, रियल-टाइम निर्णय-निर्माण में मदद करते हैं, और गैर-तकनीकी टीमों को बिना कोड लिखे वेब डेटा निकालने और उपयोग करने में सक्षम बनाते हैं। अब ये टूल्स सेल्स, मार्केटिंग, और ऑपरेशंस फ़ंक्शन्स के लिए अत्यंत महत्वपूर्ण हैं।
2. Thunderbit को अन्य वेब स्क्रैपिंग टूल्स से अलग क्या बनाता है?
Thunderbit AI का उपयोग करता है ताकि यूज़र्स अपनी ज़रूरत का डेटा साधारण अंग्रेज़ी में बता सकें। यह डेटा फ़ील्ड्स को अपने-आप पहचानता है, सबपेज और pagination को संभालता है, और परिणाम Excel तथा Airtable जैसे प्लेटफ़ॉर्म्स पर तुरंत एक्सपोर्ट करता है। यह गैर-तकनीकी उपयोगकर्ताओं के लिए डिज़ाइन किया गया है और डेटा सफ़ाई तथा शेड्यूल्ड स्क्रैपिंग जैसी शक्तिशाली सुविधाएँ कम कीमत पर देता है।
3. बड़े पैमाने के एंटरप्राइज़ स्क्रैपिंग प्रोजेक्ट्स के लिए कौन-सा टूल सबसे अच्छा है?
Bright Data और एंटरप्राइज़ उपयोग के लिए आदर्श हैं। वे proxy rotation, anti-bot उपाय, बड़े पैमाने पर concurrency, और API एक्सेस जैसी सुविधाएँ देते हैं, जिससे वे उन संगठनों के लिए उपयुक्त हैं जिन्हें हज़ारों वेब पेज भरोसेमंद ढंग से और बड़े पैमाने पर प्रोसेस करने की ज़रूरत है।
4. क्या ऐसे टूल्स हैं जो स्क्रैपिंग को ऑटोमेशन और आउटरीच के साथ जोड़ते हैं?
हाँ, Clay और Bardeen जैसे टूल्स न केवल वेब डेटा स्क्रैप करते हैं बल्कि उसे वर्कफ़्लो में भी जोड़ते हैं। Clay लीड्स को समृद्ध करता है और आउटरीच ऑटोमेट करता है, जबकि Bardeen यूज़र्स को AI-चालित प्लेबुक्स के साथ ब्राउज़र-आधारित कार्यों और वर्कफ़्लोज़ को ऑटोमेट करने देता है।
5. बिना तकनीकी पृष्ठभूमि वाले उपयोगकर्ताओं के लिए सबसे अच्छा विकल्प क्या है?
Thunderbit अपने प्राकृतिक भाषा इंटरफ़ेस, AI-चालित सेटअप, और उपयोग में आसानी के कारण गैर-तकनीकी उपयोगकर्ताओं के लिए सबसे अलग है। इसमें किसी कोडिंग या सेटअप की आवश्यकता नहीं होती और यह उन बिज़नेस यूज़र्स के लिए आदर्श है जिन्हें तकनीकी जटिलता के बिना तेज़, भरोसेमंद डेटा चाहिए।