
2015 में वेब से डेटा निकालना मतलब—किसी डेवलपर से Python स्क्रिप्ट बनवाने की गुज़ारिश करना या पूरा वीकेंड XPath सीखने में लगा देना। 2026 में तुम बस लिखते हो, “इस पेज से सारे प्रोडक्ट नाम और कीमतें निकालो”—और AI बाकी सब खुद कर देता है।
यह बदलाव सच में बिजली की रफ्तार से हुआ। आज वेब स्क्रैपिंग पर निर्भर हैं। 2024 में यह मार्केट से आगे निकल चुका था और 2030 तक इसके दोगुना होने की रफ्तार है।
सबसे बड़ा कारण? AI वेब क्रॉलर। ये लेआउट बदलने पर भी खुद को ढाल लेते हैं। ये सिर्फ HTML टैग नहीं, पेज का मतलब समझते हैं। और सबसे बढ़िया बात—जो लोग कभी कोड नहीं लिखते, उनके लिए भी ये काम करते हैं।
मैंने महीनों लगाकर 15 टूल्स टेस्ट किए हैं। नीचे वही निचोड़ है—और यह भी कि Thunderbit (हाँ, वही कंपनी जिसे मैंने co-found किया) इस लिस्ट में #1 क्यों रहा।
AI कैसे वेब पेज स्क्रैपिंग को बदल रहा है: Web Scraper टूल्स का नया दौर
साफ़-साफ़ कहें तो पारंपरिक वेब स्क्रैपिंग आम बिज़नेस यूज़र के लिए बनी ही नहीं थी। सब कुछ कोड, सेलेक्टर्स और इस उम्मीद पर टिका रहता था कि वेबसाइट ने लेआउट बदला तो स्क्रिप्ट टूटेगी नहीं। लेकिन AI और LLMs ने पूरा गेम ही पलट दिया है।
कैसे?
- नेचुरल लैंग्वेज निर्देश: कोड में उलझने की जगह तुम बस बता देते हो कि चाहिए क्या। जैसे टूल तुम्हारी साधारण अंग्रेज़ी/भाषा को समझकर एक्सट्रैक्शन सेट कर देते हैं ().
- एडैप्टिव लर्निंग: AI Web Scraper वेबसाइट के कर लेते हैं, जिससे मेंटेनेंस का झंझट काफी कम हो जाता है।
- डायनेमिक कंटेंट हैंडलिंग: आज की साइट्स JavaScript और infinite scroll पर चलती हैं। AI टूल्स इन एलिमेंट्स के साथ इंटरैक्ट करके वह डेटा भी पकड़ लेते हैं जो पुराने स्क्रैपर अक्सर मिस कर देते थे।
- AI पार्सिंग के साथ स्ट्रक्चर्ड आउटपुट: LLM-बेस्ड स्क्रैपर सच में हैं और साफ़-सुथरा, स्ट्रक्चर्ड डेटा देते हैं।
- ऑटोमैटिक एंटी-बॉट बायपास: AI स्क्रैपर कर सकते हैं और proxies/headless browsers से IP ब्लॉक से बचते हैं।
- इंटीग्रेटेड डेटा वर्कफ़्लो: अच्छे टूल सिर्फ डेटा नहीं निकालते—उसे वहीं पहुंचाते हैं जहाँ तुम्हें चाहिए, जैसे Google Sheets, Airtable, Notion आदि में एक क्लिक एक्सपोर्ट ().
नतीजा यह है कि वेब स्क्रैपिंग अब point-and-click (या चैट जैसी) प्रक्रिया बन गई है—जिससे sales, marketing और operations टीमें भी सीधे वेब डेटा इस्तेमाल कर सकती हैं, सिर्फ डेवलपर्स नहीं।
2026 में ध्यान देने लायक 15 AI वेब क्रॉलर
अब 15 टॉप AI वेब क्रॉलर को विस्तार से देखते हैं—Thunderbit से शुरुआत करते हुए। हर टूल के core features, किसके लिए है, pricing, और क्या खास है—सब बताऊँगा। और हाँ, जहाँ कोई टूल कमजोर है, वहाँ भी बिल्कुल साफ़-साफ़ कहूँगा।
1. Thunderbit: हर किसी के लिए AI Web Scraper
मैं मानता हूँ, यहाँ मेरी थोड़ी bias हो सकती है—लेकिन Thunderbit वही AI Web Scraper है जो काश मुझे सालों पहले मिल जाता। यह इस लिस्ट में #1 क्यों है:
- नेचुरल लैंग्वेज एक्सट्रैक्शन: तुम Thunderbit से “चैट” करते हो। बस लिखो—“इस पेज से सारे प्रोडक्ट नाम और कीमतें स्क्रैप करो”—और AI बाकी कर देता है (). न कोड, न सेलेक्टर्स, न सिरदर्द।
- सबपेज और मल्टी-लेवल क्रॉलिंग: Thunderbit कर सकता है। जैसे—पहले प्रोडक्ट लिस्ट, फिर हर प्रोडक्ट के डिटेल पेज से जानकारी—एक ही रन में।
- तुरंत स्ट्रक्चर्ड आउटपुट: AI करता है—ज़रूरी फील्ड सुझाता है, फॉर्मैट नॉर्मलाइज़ करता है, और टेक्स्ट को summarize/categorize भी कर सकता है।
- कई तरह के सोर्स सपोर्ट: Thunderbit सिर्फ HTML तक सीमित नहीं—built-in OCR और vision AI से PDFs और images से भी डेटा निकाल सकता है ().
- बिज़नेस इंटीग्रेशन: Google Sheets, Airtable, Notion या Excel में one-click export (). Scrapes schedule करो और डेटा सीधे टीम वर्कफ़्लो में भेजो।
- प्री-बिल्ट टेम्पलेट्स: Amazon, LinkedIn, Zillow जैसी साइट्स के लिए Thunderbit में मिलते हैं—एक क्लिक में एक्सट्रैक्शन।
- यूज़र-फ्रेंडली: इंटरफ़ेस point-and-click है, और असिस्टेंट काफी सहज है। कई यूज़र्स मिनटों में सेटअप कर लेते हैं।

Thunderbit पर भरोसा करते हैं—Accenture, Grammarly और Puma जैसी टीमों सहित। Sales टीमें इसे में, रियल एस्टेट प्रोफेशनल्स प्रॉपर्टी लिस्टिंग्स जोड़ने में, और मार्केटर्स competitors मॉनिटर करने में इस्तेमाल करते हैं—बिना एक लाइन कोड लिखे।
Pricing: एक है (100 steps/month तक), और paid plans $14.99/month से शुरू होते हैं। Pro plans भी individuals और small teams के लिए किफायती हैं।
Thunderbit मुझे “वेब को डेटाबेस में बदलने” के सबसे करीब लगा—और यह सिर्फ इंजीनियर्स के लिए नहीं, हर किसी के लिए बना है।
2. Crawl4AI
किसके लिए: डेवलपर्स और टेक्निकल टीमें जो custom pipelines बनाती हैं।
Crawl4AI एक open-source, Python-बेस्ड फ्रेमवर्क है जो speed और large-scale crawling के लिए optimized है, और बनाया गया है। यह बहुत तेज़ है, dynamic content के लिए headless browsers सपोर्ट करता है, और scraped data को AI workflows में feed करने लायक structure कर सकता है।
- Best for: डेवलपर्स जिन्हें powerful और customizable crawling engine चाहिए।
- Pricing: Free (MIT license). तुम्हें खुद host/run करना होगा।
3. ScrapeGraphAI
किसके लिए: डेवलपर्स और analysts जो AI agents या complex data pipelines बनाते हैं।
ScrapeGraphAI एक prompt-driven, open-source Python library है जो LLMs की मदद से वेबसाइट को structured data “graphs” में बदलती है। तुम ऐसे prompts लिख सकते हो—“पहले 5 पेज से सारे प्रोडक्ट नाम, कीमतें और ratings निकालो”—और यह तुम्हारे लिए scraping workflow बना देती है ().
- Best for: टेक-सेवी यूज़र्स जिन्हें flexible, prompt-based scraping चाहिए।
- Pricing: Open-source library free; cloud API $20/month से।
4. Firecrawl
किसके लिए: डेवलपर्स जो AI agents या बड़े data pipelines बना रहे हैं।
Firecrawl एक AI-केंद्रित crawling platform और API है जो पूरी वेबसाइट को “LLM-ready” डेटा में बदल देता है (). यह Markdown या JSON आउटपुट देता है, dynamic content संभालता है, और LangChain/LlamaIndex जैसे frameworks के साथ integrate होता है।
- Best for: डेवलपर्स जिन्हें live web data AI models में feed करना हो।
- Pricing: Open-source core free; cloud plans $19/month से।
5. Browse AI
किसके लिए: बिज़नेस यूज़र्स, growth hackers, और analysts।
Browse AI एक no-code प्लेटफ़ॉर्म है जिसमें मिलता है। तुम क्लिक करके “robot” को ट्रेन करते हो कि कौन सा डेटा चाहिए, और AI आगे के scrapes में पैटर्न पहचान लेता है। यह logins, infinite scroll संभालता है और साइट बदलावों को monitor भी कर सकता है।
- Best for: non-technical यूज़र्स जो data collection और monitoring automate करना चाहते हैं।
- Pricing: Free plan (50 credits/month); paid $19/month से।
6. LLM Scraper
किसके लिए: डेवलपर्स जो parsing का काम AI से करवाना चाहते हैं।
LLM Scraper एक open-source JavaScript/TypeScript library है जिसमें तुम करते हो और LLM किसी भी webpage से उसी schema में डेटा निकाल देता है। यह Playwright पर बना है, कई LLM providers सपोर्ट करता है, और reusable code भी generate कर सकता है।
- Best for: डेवलपर्स जो LLMs से किसी भी webpage को structured data में बदलना चाहते हैं।
- Pricing: Free (MIT license).
7. Reader (Jina Reader)
किसके लिए: डेवलपर्स जो LLM apps, chatbots या summarizers बना रहे हैं।
Jina Reader एक API है जो webpages (और PDFs/images) से निकालकर LLM-ready Markdown या JSON लौटाता है। यह custom AI model से powered है और images के captions भी बना सकता है।
- Best for: LLMs/Q&A सिस्टम के लिए साफ़, readable content लाना।
- Pricing: Free API (basic use के लिए key नहीं चाहिए)।
8. Bright Data
किसके लिए: enterprises और प्रोफेशनल यूज़र्स जिन्हें scale, compliance और reliability चाहिए।
Bright Data वेब डेटा इंडस्ट्री का बड़ा नाम है—massive proxy network और के साथ। इसमें ready-made scrapers, general Web Scraper API और “LLM-ready” data feeds मिलते हैं।
- Best for: बड़े पैमाने पर भरोसेमंद web data चाहिए वाली organizations।
- Pricing: usage-based, premium. Free trials उपलब्ध।
9. Octoparse
किसके लिए: non-technical से लेकर semi-technical यूज़र्स।
Octoparse एक established no-code टूल है जिसमें और AI auto-detect मिलता है। यह logins, infinite scroll संभालता है और कई formats में export कर सकता है।
- Best for: analysts, small business owners, researchers।
- Pricing: Free tier; paid $119/month से।
10. Apify
किसके लिए: डेवलपर्स और टेक टीमें जिन्हें custom scraping/automation चाहिए।
Apify एक cloud platform है जहाँ scraping scripts (“actors”) चलाए जाते हैं और इसमें भी है। यह scalable है, AI के साथ integrate होता है और proxy management सपोर्ट करता है।
- Best for: डेवलपर्स जो cloud में custom scripts चलाना चाहते हैं।
- Pricing: Free tier; usage-based paid $49/month से।
11. Zyte (Scrapy Cloud)
किसके लिए: डेवलपर्स और कंपनियाँ जिन्हें enterprise-grade scraping चाहिए।
Zyte, Scrapy के पीछे की कंपनी है, और cloud platform के साथ देती है। यह scheduling, proxies और large-scale projects संभालता है।
- Best for: dev teams जो long-term scraping projects चलाती हैं।
- Pricing: Free trials से लेकर custom enterprise plans तक।
12. Webscraper.io
किसके लिए: beginners, journalists, researchers।
एक है जो point-and-click data extraction देता है। Local use के लिए simple और free है, और बड़े कामों के लिए cloud service भी है।
- Best for: जल्दी होने वाले, one-off scraping tasks।
- Pricing: Free extension; cloud plans ~ $50/month से।
13. ParseHub
किसके लिए: non-technical यूज़र्स जिन्हें basic tools से ज़्यादा power चाहिए।
ParseHub एक desktop app है जिसमें dynamic content (maps, forms सहित) स्क्रैप करने के लिए visual workflow मिलता है। यह cloud में projects चला सकता है और API भी देता है।
- Best for: digital marketers, analysts, journalists।
- Pricing: Free tier (200 pages/run); paid $189/month से।
14. Diffbot
किसके लिए: enterprises और AI कंपनियाँ जिन्हें बड़े पैमाने पर structured web data चाहिए।
Diffbot computer vision और NLP से करता है। यह articles/products के लिए APIs और एक बड़ा knowledge graph भी देता है।
- Best for: market intelligence, finance, AI training data।
- Pricing: premium, ~ $299/month से।
15. DataMiner
किसके लिए: non-technical यूज़र्स—खासकर sales, marketing और journalism में।
DataMiner एक है जो जल्दी point-and-click extraction करता है। इसमें pre-built “recipes” की लाइब्रेरी है और Google Sheets में direct export भी।
- Best for: tables/lists को spreadsheets में export जैसे quick tasks।
- Pricing: Free tier (500 pages/day); Pro ~ $19/month से।
टॉप AI Web Scraper टूल्स की तुलना: आपके लिए कौन सा सही है?
यहाँ एक high-level तुलना है ताकि तुम जल्दी decide कर सको:
| Tool | AI/LLM Usage | Ease of Use | Output/Integration | Ideal For | Pricing |
|---|---|---|---|---|---|
| Thunderbit | Natural language UI; AI suggests fields | Easiest (no-code chat) | Sheets, Airtable, Notion exports | Non-tech teams | Free tier; Pro ~$30/mo |
| Crawl4AI | AI-ready crawling; integrate LLMs | Hard (code Python) | Library/CLI; integrate via code | Devs needing fast AI data pipelines | Free |
| ScrapeGraphAI | LLM prompt pipelines for scraping | Medium (some coding or API) | API/SDK; JSON output | Devs/analysts building AI agents | Free OSS; API $20+/mo |
| Firecrawl | Crawls to LLM-ready Markdown/JSON | Medium (API/SDK use) | SDKs (Py, Node, etc.); LangChain integ | Devs integrating live web data to AI | Free + paid cloud |
| Browse AI | AI-assisted point & click | Easy (no-code) | 7000+ app integrations (Zapier) | Non-tech users automating web monitoring | Free 50 runs; Paid $19+/mo |
| LLM Scraper | Uses LLMs to parse page to schema | Hard (code TS/JS) | Code library; JSON output | Devs wanting AI to do parsing | Free (use own LLM API) |
| Reader (Jina) | AI model extracts text/JSON | Easy (simple API call) | REST API returns Markdown/JSON | Devs adding web search/content to LLMs | Free API |
| Bright Data | AI-enhanced scraping APIs; large proxy network | Hard (API, technical) | APIs/SDKs; data streams or datasets | Enterprise scale | Usage-based |
| Octoparse | AI auto-detect lists | Moderate (no-code app) | CSV/Excel, API for results | Semi-technical users | Free limited; $59–$166/mo |
| Apify | Some AI features (Actors, AI tutorials) | Hard (code scripts) | Comprehensive API; integrates with LangChain | Devs needing custom scraping in cloud | Free tier; pay-as-you-go |
| Zyte (Scrapy) | ML-based auto extraction; Scrapy framework | Hard (code Python) | API, Scrapy Cloud UI; JSON/CSV | Dev teams, long-term projects | Custom pricing |
| Webscraper.io | No AI (manual templates) | Easy (browser extension) | CSV download, Cloud API | Beginners, quick one-off scrapes | Free extension; Cloud ~$50/mo |
| ParseHub | No explicit LLM; visual builder | Moderate (no-code app) | JSON/CSV; API for cloud runs | Non-devs scraping complex sites | Free 200 pages; Paid $189+/mo |
| Diffbot | AI vision/NLP for any page; knowledge graph | Easy (just API calls) | APIs (Article/Prod/...) + Knowledge Graph query | Enterprise, structured web data | Starts ~$299/mo |
| DataMiner | No LLM; community recipes | Easiest (browser UI) | Excel/CSV export; Google Sheets | Non-tech users scraping to spreadsheets | Free limited; Pro ~$19/mo |
टूल कैटेगरीज़: डेवलपर-ग्रेड पावर से लेकर बिज़नेस-फ्रेंडली Web Scraper तक
इस लिस्ट को समझने के लिए इन्हें कुछ कैटेगरी में बाँटते हैं:
1. Developer & Open-Source Powerhouses
- Examples: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Strengths: बहुत flexible, scalable और customizable। custom pipelines या AI models के साथ integration के लिए बढ़िया।
- Trade-offs: coding skills और ज्यादा configuration चाहिए।
- Use cases: custom data pipeline बनाना, complex sites स्क्रैप करना, internal systems से जोड़ना।
2. AI-Integrated Scraping Agents
- Examples: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Strengths: scraping और data understanding के बीच की दूरी कम करते हैं। natural language interfaces इन्हें accessible बनाते हैं।
- Trade-offs: कुछ टूल अभी evolve हो रहे हैं; बहुत granular control हमेशा नहीं मिलता।
- Use cases: जल्दी datasets/answers, autonomous agents बनाना, live data LLMs को देना।
3. No-Code/Low-Code बिज़नेस-फ्रेंडली स्क्रैपर
- Examples: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Strengths: यूज़र-फ्रेंडली, कम या बिना कोड के काम, नियमित बिज़नेस टास्क के लिए अच्छे।
- Trade-offs: बहुत complex sites या massive scale पर सीमाएँ आ सकती हैं।
- Use cases: lead generation, competitor monitoring, research projects, one-off data pulls।
4. Enterprise डेटा प्लेटफ़ॉर्म और सर्विसेज
- Examples: Bright Data, Diffbot, Zyte
- Strengths: full-stack solutions, managed services, compliance और scale पर reliability।
- Trade-offs: लागत ज्यादा, onboarding भी ज्यादा।
- Use cases: बड़े पैमाने पर always-on data pipelines, market intelligence, AI training data।
अपनी वेब पेज स्क्रैपिंग ज़रूरत के लिए सही AI वेब क्रॉलर कैसे चुनें
सही टूल चुनना भारी लग सकता है, इसलिए यह step-by-step गाइड देखो:
- लक्ष्य और डेटा ज़रूरतें तय करो: कौन सी साइट्स? कौन सा डेटा? कितनी बार? कितना? और उसका उपयोग क्या होगा?
- अपनी टेक्निकल क्षमता समझो: कोडिंग नहीं आती? Thunderbit, Browse AI, या Octoparse। थोड़ा scripting? LLM Scraper या DataMiner। मजबूत dev skills? Crawl4AI, Apify, या Zyte।
- फ्रीक्वेंसी और स्केल देखो: one-off काम? free tools। recurring? scheduling फीचर देखो। बड़े पैमाने पर? enterprise tools या open-source को scale पर चलाओ।
- बजट और pricing model: testing के लिए free plans अच्छे हैं। subscription बनाम usage-based तुम्हारी जरूरत पर निर्भर है।
- Trial और PoC: अपने असली डेटा पर 2-3 टूल्स टेस्ट करो। ज्यादातर में free tier होता है।
- Maintenance और support: साइट बदलने पर कौन ठीक करेगा? no-code AI tools छोटे बदलाव खुद संभाल सकते हैं; open-source में तुम/कम्युनिटी पर निर्भरता रहती है।
- Scenarios के हिसाब से टूल चुनो: sales leads? Thunderbit या Browse AI। tweets/quick research? DataMiner या । news articles for AI model? Jina Reader या Zyte। comparison site build? Apify या Zyte।
- Backup प्लान रखो: कभी-कभी किसी खास साइट पर एक टूल काम नहीं करता—fallback रखना समझदारी है।
“सही” टूल वही है जो कम friction में, तुम्हारे बजट के भीतर, तुम्हें जरूरी डेटा दिला दे। कई बार best answer एक से ज्यादा टूल्स का कॉम्बिनेशन होता है।
Thunderbit बनाम पारंपरिक Web Scraper टूल्स: इसे अलग क्या बनाता है?
Thunderbit की खासियतें:
- Natural language interface: न कोड, न point-and-click की कसरत—बस बताओ क्या चाहिए ().
- Zero configuration & template suggestions: pagination, subpages auto-detect करता है और common sites के लिए templates भी suggest करता है ().
- AI-powered data cleaning & enrichment: scrape करते-करते summarize, categorize, translate और enrich कर सकता है ().
- कम maintenance: छोटे site changes पर भी AI resilient रहता है, breakage कम होता है।
- Business tool integration: Google Sheets, Airtable, Notion में direct export—CSV झंझट खत्म ().
- Speed to value: idea से data तक मिनटों में, दिनों में नहीं।
- Learning curve: अगर तुम web browse कर सकते हो और जरूरत बता सकते हो, तो Thunderbit चला सकते हो।
- Adaptability: websites, PDFs, images—सब एक ही टूल से।
Thunderbit सिर्फ scraper नहीं—यह एक data assistant है जो sales, marketing, ecommerce या real estate—हर workflow में फिट हो जाता है।
AI Web Scraper टूल्स के साथ वेब पेज स्क्रैपिंग की best practices
AI Web Scraper से बेहतर नतीजे पाने के लिए ये टिप्स अपनाओ:
- डेटा जरूरतें साफ़ लिखो: कौन से fields, कितने pages, और कौन सा format चाहिए।
- AI suggestions का फायदा लो: field detection और AI suggestions से वह डेटा भी पकड़ो जो छूट सकता है ().
- छोटे से शुरू करो और validate करो: पहले sample पर चलाओ, output चेक करो, फिर refine करो।
- Dynamic content संभालो: pagination, infinite scroll जैसी interactions का support जरूरी है।
- Website policies का सम्मान करो: robots.txt देखो, sensitive data से बचो, rate limits मानो।
- Automation के लिए integrate करो: exports/webhooks से डेटा सीधे workflow में डालो।
- Data quality बनाए रखो: sanity checks, post-processing और error monitoring करो।
- Prompts छोटे और स्पष्ट रखो: AI tools में specific instructions बेहतर output देती हैं।
- Community से सीखो: forums/communities में tips और troubleshooting मिलती है।
- Updated रहो: AI tools तेजी से बदलते हैं—नई features पर नजर रखो।
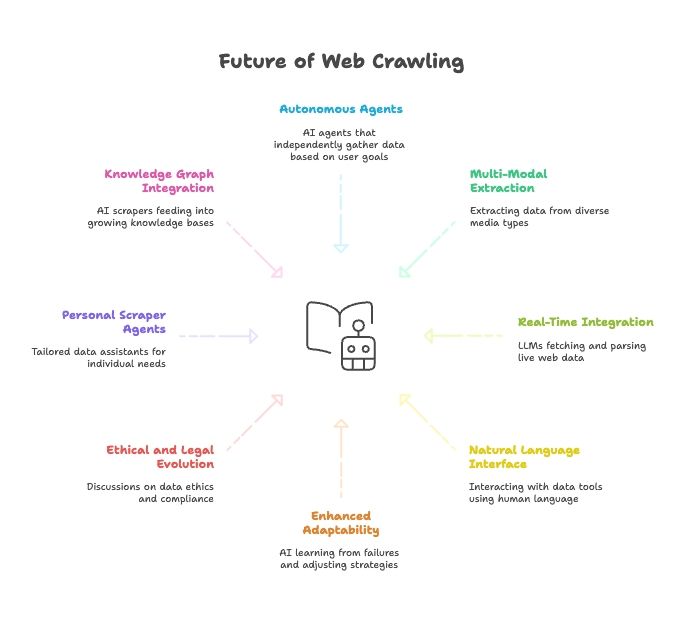
वेब स्क्रैपिंग का भविष्य: AI, LLMs और नेचुरल लैंग्वेज Web Scraper एजेंट्स
आगे देखते हुए, AI और वेब क्रॉलिंग का मेल और तेज़ होगा:
- पूरी तरह autonomous scraper agents: तुम सिर्फ end goal बताओगे, agent खुद तय करेगा डेटा कैसे लाना है।
- Multi-modal extraction: text के साथ images, PDFs और videos से भी डेटा निकलेगा।
- AI models के साथ real-time integration: LLMs में live web data fetch/parse करने के modules built-in होंगे।
- Natural language everywhere: डेटा टूल्स से बातचीत इंसानों जैसी होगी—डेटा कलेक्शन सबके लिए आसान।
- बेहतर adaptability: AI scrapers failures से सीखकर strategies खुद बदलेंगे।
- Ethical/legal बदलाव: data ethics, compliance और fair use पर चर्चा बढ़ेगी।
- Personal scraper agents: तुम्हारी जरूरत के हिसाब से news, jobs आदि जुटाने वाला personal assistant।
- Knowledge graphs के साथ integration: scrapers लगातार knowledge bases को feed करेंगे, जिससे AI और स्मार्ट बनेगा।
निष्कर्ष: वेब स्क्रैपिंग का भविष्य AI के भविष्य से जुड़ा है—टूल्स हर दिन ज्यादा स्मार्ट, ज्यादा autonomous और ज्यादा accessible हो रहे हैं।
निष्कर्ष: सही AI वेब क्रॉलर से बिज़नेस वैल्यू अनलॉक करें
AI की वजह से वेब क्रॉलिंग एक niche technical skill से निकलकर core business capability बन गई है। 2026 में जिन 15 टूल्स को मैंने कवर किया, वे developer-grade powerhouses से लेकर business-friendly assistants तक—आज की best possibilities दिखाते हैं।
असल बात यह है: सही टूल चुनने से web data से मिलने वाली वैल्यू कई गुना बढ़ सकती है। non-technical teams के लिए Thunderbit वेब को structured, analysis-ready database में बदलने का सबसे आसान तरीका है—न कोड, न झंझट, बस नतीजे।
तो चाहे तुम leads जुटा रहे हो, competitors मॉनिटर कर रहे हो, या next-gen AI model को डेटा दे रहे हो—अपनी जरूरतें समझो, कुछ टूल्स ट्राय करो, और जो फिट बैठे उसे चुनो। और अगर तुम आज ही web scraping का भविष्य देखना चाहते हो, तो । तुम्हें चाहिए insights—बस एक prompt की दूरी पर हैं।
और पढ़ना है? deep dives, tutorials और AI-powered data extraction की नई अपडेट्स के लिए देखें।
Further Reading:
FAQs
1. AI web crawler क्या होता है और यह traditional web scrapers से कैसे अलग है?
AI web crawler natural language processing और machine learning की मदद से वेब डेटा को समझकर निकालता और structure करता है। Traditional scrapers में manual coding और XPath selectors चाहिए होते हैं, जबकि AI tools dynamic content संभाल सकते हैं, layout changes के साथ adapt होते हैं, और plain English में दिए निर्देश समझ लेते हैं।
2. Thunderbit जैसे AI web scraping tools किसे इस्तेमाल करने चाहिए?
Thunderbit non-technical और technical—दोनों तरह के यूज़र्स के लिए बना है। यह sales, marketing, operations, research और ecommerce प्रोफेशनल्स के लिए ideal है जो websites, PDFs या images से structured data निकालना चाहते हैं—बिना कोड लिखे।
3. Thunderbit को दूसरे AI web crawlers से अलग कौन से features बनाते हैं?
Thunderbit में natural language interface, multi-level crawling, automatic data structuring, OCR support, और Google Sheets/Airtable जैसी platforms पर seamless exports मिलते हैं। साथ ही यह AI-powered field suggestions और popular sites के लिए pre-built templates भी देता है।
4. क्या 2026 में AI web scraping के लिए free options मौजूद हैं?
हाँ। Thunderbit, Browse AI और DataMiner जैसे कई टूल limited usage के साथ free plans देते हैं। डेवलपर्स के लिए Crawl4AI और ScrapeGraphAI जैसे open-source विकल्प बिना लागत के full functionality देते हैं—हालाँकि technical setup करना पड़ता है।
5. अपनी जरूरत के लिए सही AI web crawler कैसे चुनूँ?
सबसे पहले अपने data goals, technical ability, budget और scale requirements तय करो। अगर तुम्हें no-code और आसान solution चाहिए, तो Thunderbit या Browse AI अच्छे विकल्प हैं। बड़े पैमाने या custom जरूरतों के लिए Apify या Bright Data ज्यादा उपयुक्त हैं।