
आइए सच बोलें—Amazon असल में पूरे इंटरनेट के लिए मॉल, सुपरमार्केट और इलेक्ट्रॉनिक्स स्टोर, सब कुछ एक साथ है। अगर आप सेल्स, ई-कॉमर्स या ऑपरेशंस में हैं, तो आप पहले से जानते हैं कि Amazon पर जो होता है, वह Amazon तक ही सीमित नहीं रहता—वह आपकी प्राइसिंग, इन्वेंटरी और यहाँ तक कि आपके अगले बड़े प्रोडक्ट लॉन्च तक को प्रभावित करता है। लेकिन दिक्कत यह है: प्रोडक्ट डिटेल्स, कीमतें, रेटिंग्स और रिव्यूज़ की वह सारी उपयोगी जानकारी एक ऐसे वेब इंटरफ़ेस के पीछे बंद है, जो खरीदारों के लिए बना है, डेटा-भूखी टीमों के लिए नहीं। तो फिर, 1999 की तरह अपना पूरा वीकेंड कॉपी-पेस्ट में लगाए बिना, आप वह डेटा हाथ कैसे लगाएँ?
यहीं वेब स्क्रैपिंग काम आती है। इस गाइड में, मैं आपको Amazon प्रोडक्ट डेटा निकालने के दो तरीके दिखाऊँगा: पहला, क्लासिक “कमर कसो और Python में कोड लिखो” वाला तरीका, और दूसरा, बिना कोड वाले वेब स्क्रैपर जैसे के साथ “AI से भारी काम कराओ” वाला आधुनिक तरीका। मैं आपको असली Python कोड के साथ (सारी बारीकियाँ और वर्कअराउंड्स सहित) समझाऊँगा, फिर दिखाऊँगा कि Thunderbit सिर्फ़ कुछ क्लिक में वही डेटा कैसे दिला सकता है—बिना किसी कोडिंग के। चाहे आप डेवलपर हों, बिज़नेस एनालिस्ट हों, या बस मैनुअल डेटा एंट्री से तंग आ चुके हों, यह गाइड आपके काम आएगी।
Amazon प्रोडक्ट डेटा क्यों निकालें? (amazon scraper python, web scraping with python)
Amazon सिर्फ़ दुनिया का सबसे बड़ा ऑनलाइन रिटेलर नहीं है—यह प्रतिस्पर्धी जानकारी के लिए दुनिया का सबसे बड़ा खुला बाज़ार भी है। और के साथ, Amazon उन सभी के लिए सोने की खान है जो यह चाहते हैं:

- कीमतों पर नज़र रखें (और अपनी कीमतें रीयल टाइम में समायोजित करें)
- प्रतिद्वंद्वियों का विश्लेषण करें (उनके नए लॉन्च, रेटिंग्स और रिव्यूज़ ट्रैक करें)
- लीड्स जनरेट करें (सेलर्स, सप्लायर्स, या संभावित पार्टनर्स खोजें)
- डिमांड का अनुमान लगाएँ (स्टॉक लेवल और सेल्स रैंक देखकर)
- मार्केट ट्रेंड्स पहचानें (रिव्यूज़ और सर्च रिज़ल्ट्स का विश्लेषण करके)
और यह सिर्फ़ थ्योरी नहीं है—असली बिज़नेस असली ROI देख रहे हैं। उदाहरण के लिए, एक इलेक्ट्रॉनिक्स रिटेलर ने स्क्रैप किए गए Amazon प्राइसिंग डेटा का इस्तेमाल कर , जबकि एक अन्य ब्रांड ने प्रतिस्पर्धी प्राइस ट्रैकिंग ऑटोमेट करने के बाद देखी।
यहाँ उपयोग के मामलों और आप जिस ROI की उम्मीद कर सकते हैं, उसका एक छोटा-सा टेबल है:
| उपयोग का मामला | कौन उपयोग करता है | सामान्य ROI / लाभ |
|---|---|---|
| प्राइस मॉनिटरिंग | ई-कॉमर्स, ऑप्स | 15%+ प्रॉफिट मार्जिन बढ़ोतरी, 4% बिक्री उछाल, 30% कम एनालिस्ट समय |
| प्रतिस्पर्धी विश्लेषण | सेल्स, प्रोडक्ट, ऑप्स | तेज़ प्राइस समायोजन, बेहतर प्रतिस्पर्धात्मकता |
| मार्केट रिसर्च (रिव्यूज़) | प्रोडक्ट, मार्केटिंग | तेज़ प्रोडक्ट इटरेशन, बेहतर विज्ञापन कॉपी, SEO इनसाइट्स |
| लीड जनरेशन | सेल्स | 3,000+ लीड्स/माह, प्रति प्रतिनिधि प्रति सप्ताह 8+ घंटे की बचत |
| इन्वेंटरी और डिमांड फोरकास्ट | ऑप्स, सप्लाई चेन | अतिरिक्त स्टॉक में 20% कमी, स्टॉक-आउट कम |
| ट्रेंड पहचान | मार्केटिंग, एग्जीक्यूटिव्स | गर्म प्रोडक्ट्स और कैटेगरीज की जल्दी पहचान |
और सबसे अहम बात: ने अब डेटा एनालिटिक्स से मापने योग्य मूल्य मिलने की रिपोर्ट दी है। अगर आप Amazon स्क्रैप नहीं कर रहे, तो आप इनसाइट्स (और पैसे) टेबल पर छोड़ रहे हैं।
अवलोकन: Amazon Scraper Python बनाम No Code Web Scraper टूल्स
ब्राउज़र से Amazon डेटा निकालकर स्प्रेडशीट या डैशबोर्ड में लाने के दो मुख्य तरीके हैं:
-
Amazon Scraper Python (web scraping with python):
Python लाइब्रेरीज़ जैसे Requests और BeautifulSoup का उपयोग करके अपना स्क्रिप्ट लिखें। इससे आपको पूरा नियंत्रण मिलता है, लेकिन आपको कोडिंग, एंटी-बॉट उपायों, और Amazon की साइट बदलने पर स्क्रिप्ट मेंटेन करने की समझ होनी चाहिए।
-
No Code Web Scraper टूल्स (जैसे Thunderbit):
ऐसा टूल इस्तेमाल करें जिसमें आप पॉइंट, क्लिक और डेटा एक्सट्रैक्ट कर सकें—कोई प्रोग्रामिंग नहीं चाहिए। जैसे आधुनिक टूल्स तो AI का उपयोग करके यह भी तय कर लेते हैं कि कौन-सा डेटा निकालना है, सबपेज और पेजिनेशन संभालते हैं, और सीधे Excel या Google Sheets में एक्सपोर्ट कर देते हैं।
इनकी तुलना कुछ यूँ है:
| मानदंड | Python Scraper | No Code (Thunderbit) |
|---|---|---|
| सेटअप समय | अधिक (इंस्टॉल, कोड, डिबग) | कम (एक्सटेंशन इंस्टॉल) |
| ज़रूरी कौशल | कोडिंग आवश्यक | कुछ नहीं (पॉइंट & क्लिक) |
| लचीलापन | असीमित | आम उपयोग मामलों के लिए उच्च |
| मेंटेनेंस | आप कोड ठीक करते हैं | टूल खुद अपडेट होता है |
| एंटी-बॉट हैंडलिंग | प्रॉक्सी, हेडर्स आप संभालते हैं | बिल्ट-इन, आपके लिए संभाला जाता है |
| स्केलेबिलिटी | मैनुअल (थ्रेड्स, प्रॉक्सी) | क्लाउड स्क्रैपिंग, समानांतर प्रोसेसिंग |
| डेटा एक्सपोर्ट | कस्टम (CSV, Excel, DB) | Excel, Sheets में एक क्लिक |
| लागत | मुफ़्त (आपका समय + प्रॉक्सी) | फ्रीमियम, स्केल के लिए भुगतान |
| सबसे अच्छा किसके लिए | डेवलपर्स, कस्टम ज़रूरतें | बिज़नेस यूज़र्स, तेज़ परिणाम |
अगले हिस्सों में, मैं आपको दोनों तरीकों से लेकर चलूँगा—पहले, Python में Amazon स्क्रैपर कैसे बनाना है (असली कोड के साथ), फिर Thunderbit के AI वेब स्क्रैपर से वही काम कैसे करना है।
Amazon Scraper Python शुरू करने के लिए: ज़रूरी चीज़ें और सेटअप
कोड में कूदने से पहले, चलिए आपका एनवायरनमेंट सेट कर लेते हैं।
आपको चाहिए:
- Python 3.x ( से डाउनलोड करें)
- एक कोड एडिटर (मुझे VS Code पसंद है, लेकिन कोई भी चलेगा)
- निम्नलिखित लाइब्रेरीज़:
requests(HTTP requests के लिए)beautifulsoup4(HTML parsing के लिए)lxml(तेज़ HTML parser)pandas(डेटा टेबल्स/एक्सपोर्ट के लिए)re(regular expressions, बिल्ट-इन)
लाइब्रेरीज़ इंस्टॉल करें:
1pip install requests beautifulsoup4 lxml pandasप्रोजेक्ट सेटअप:
- अपने प्रोजेक्ट के लिए एक नया फ़ोल्डर बनाएँ।
- एडिटर खोलें, एक नई Python फ़ाइल बनाएँ (जैसे,
amazon_scraper.py)। - अब आप तैयार हैं!
चरण-दर-चरण: Amazon प्रोडक्ट डेटा के लिए Python से वेब स्क्रैपिंग
चलिए एक Amazon प्रोडक्ट पेज स्क्रैप करते हैं। (चिंता मत करें, थोड़ी देर में हम कई प्रोडक्ट्स और पेजेज़ स्क्रैप करने पर भी आएँगे।)
1. Requests भेजना और HTML फ़ेच करना
सबसे पहले, चलिए किसी प्रोडक्ट पेज का HTML लेते हैं। (URL की जगह कोई भी Amazon प्रोडक्ट डाल सकते हैं।)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)ध्यान दें: यह बेसिक request Amazon द्वारा ब्लॉक हो सकती है। आपको प्रोडक्ट पेज की बजाय 503 error या CAPTCHA दिख सकता है। क्यों? क्योंकि Amazon जानता है कि आप असली ब्राउज़र नहीं हैं।
Amazon के एंटी-बॉट उपायों को कैसे संभालें
Amazon को बॉट्स पसंद नहीं हैं। ब्लॉक होने से बचने के लिए आपको यह करना होगा:
- User-Agent header सेट करें (Chrome या Firefox जैसा दिखाएँ)
- User-Agents घुमाएँ (हर बार वही उपयोग न करें)
- Requests की गति कम रखें (रैंडम देरी जोड़ें)
- Proxies इस्तेमाल करें (बड़े पैमाने की स्क्रैपिंग के लिए)
हेडर्स सेट करने का तरीका:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)थोड़ा और स्मार्ट बनना है? User-Agents की एक सूची रखें और हर request के लिए उन्हें घुमाएँ। बड़े काम के लिए आपको proxy service चाहिए होगी (ऐसी बहुत मिल जाएँगी), लेकिन छोटे पैमाने की स्क्रैपिंग के लिए headers और delays आमतौर पर काफी होते हैं।
मुख्य प्रोडक्ट फ़ील्ड्स निकालना
एक बार HTML मिल जाए, तो उसे BeautifulSoup से parse करने का समय है।
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")अब ज़रूरी चीज़ें निकालते हैं:
प्रोडक्ट शीर्षक
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else Noneकीमत
Amazon की कीमत कुछ अलग जगहों पर हो सकती है। ये तरीके आज़माएँ:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textरेटिंग और रिव्यू काउंट
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # उदाहरण: "1,554 ratings"मुख्य इमेज URL
Amazon कभी-कभी हाई-रेज़ इमेजेज़ को HTML के अंदर JSON में छिपा देता है। यहाँ एक तेज़ regex तरीका है:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else Noneया फिर मुख्य image tag पकड़ें:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else Noneप्रोडक्ट विवरण
ब्रांड, वज़न और आयाम जैसी specs आमतौर पर एक टेबल में होती हैं:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueया अगर Amazon “detailBullets” फ़ॉर्मेट इस्तेमाल कर रहा हो:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()अपने परिणाम प्रिंट करें:
1print("शीर्षक:", product_title)
2print("कीमत:", price)
3print("रेटिंग:", rating, "आधार पर", reviews_count, "रिव्यूज़")
4print("मुख्य इमेज URL:", main_image_url)
5print("विवरण:", details)कई प्रोडक्ट्स स्क्रैप करना और पेजिनेशन संभालना
एक प्रोडक्ट ठीक है, लेकिन शायद आपको पूरी सूची चाहिए। यहाँ बताया गया है कि search results और कई पेज कैसे स्क्रैप करें।
Search Page से प्रोडक्ट लिंक निकालना
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)पेजिनेशन संभालना
Amazon के search URLs में &page=2, &page=3, आदि होते हैं।
1for page in range(1, 6): # पहले 5 पेज स्क्रैप करें
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... ऊपर की तरह प्रोडक्ट लिंक निकालें ...प्रोडक्ट पेजेज़ के अंदर लूप करें और CSV में एक्सपोर्ट करें
अपने प्रोडक्ट डेटा को dictionaries की एक सूची में जमा करें, फिर pandas का उपयोग करें:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # dicts की सूची
3df.to_csv("amazon_products.csv", index=False)या Excel में:
1df.to_excel("amazon_products.xlsx", index=False)Amazon Scraper Python प्रोजेक्ट्स के लिए सर्वोत्तम अभ्यास
सच कहें तो—Amazon अपनी साइट लगातार बदलता रहता है और scrapers से लड़ता भी रहता है। अपने प्रोजेक्ट को चलाते रहने के लिए यह करें:
- Headers और User-Agents घुमाएँ (
fake-useragentजैसी लाइब्रेरी इस्तेमाल करें) - बड़े पैमाने की स्क्रैपिंग के लिए proxies उपयोग करें
- Requests की गति कम रखें (requests के बीच रैंडम
time.sleep()) - Errors को सही तरह संभालें (503 पर retry करें, block होने पर back off करें)
- Flexible parsing logic लिखें (हर फ़ील्ड के लिए कई selectors देखें)
- HTML बदलावों पर नज़र रखें (अगर स्क्रिप्ट अचानक हर जगह
Noneलौटाने लगे, तो पेज जाँचें) - robots.txt का सम्मान करें (Amazon कई सेक्शंस में scraping की अनुमति नहीं देता—ज़िम्मेदारी से स्क्रैप करें)
- जैसे-जैसे डेटा आए, उसे साफ़ करें (currency symbols, commas, whitespace हटाएँ)
- कम्युनिटी से जुड़े रहें (forums, Stack Overflow, Reddit का r/webscraping)
अपने स्क्रैपर को मेंटेन करने की चेकलिस्ट:
- [ ] User-Agents और headers घुमाएँ
- [ ] स्केल पर स्क्रैप कर रहे हों तो proxies इस्तेमाल करें
- [ ] रैंडम delays जोड़ें
- [ ] आसान अपडेट के लिए कोड को modular बनाएँ
- [ ] bans या CAPTCHAs पर नज़र रखें
- [ ] डेटा नियमित रूप से एक्सपोर्ट करें
- [ ] अपने selectors और logic का दस्तावेज़ बनाएँ
और गहराई से जानना हो, तो मेरी देखिए।
बिना कोड वाला विकल्प: Thunderbit AI Web Scraper से Amazon स्क्रैप करना
ठीक है, आपने Python वाला तरीका देख लिया। लेकिन अगर आप कोड नहीं लिखना चाहते—या बस दो क्लिक में डेटा निकालकर अपनी ज़िंदगी आगे बढ़ाना चाहते हैं? वहीं काम आता है।
Thunderbit एक AI वेब स्क्रैपर Chrome Extension है, जो आपको बिना कोडिंग के Amazon प्रोडक्ट डेटा (और लगभग किसी भी वेबसाइट का डेटा) निकालने देता है। मुझे यह इसलिए पसंद है:
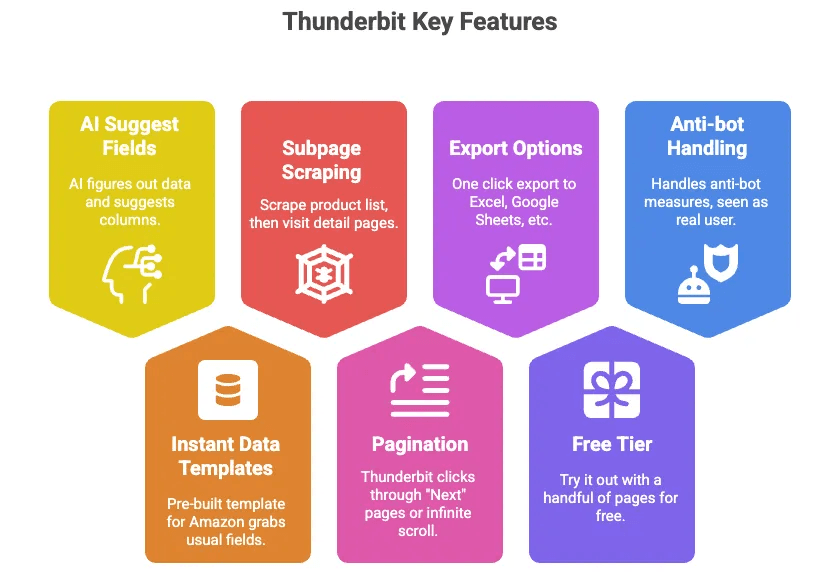
- AI Suggest Fields: बस एक बटन क्लिक करें, और Thunderbit का AI समझ लेता है कि पेज पर कौन-सा डेटा है और कॉलम सुझाता है (जैसे Title, Price, Rating आदि)।
- तैयार-निर्मित डेटा टेम्पलेट्स: Amazon के लिए एक पहले से बना टेम्पलेट है जो आम तौर पर ज़रूरी सारे फ़ील्ड्स खींच लेता है—सेटअप की ज़रूरत नहीं।
- सबपेज स्क्रैपिंग: प्रोडक्ट्स की सूची स्क्रैप करें, फिर Thunderbit को हर प्रोडक्ट के डिटेल पेज पर जाकर और जानकारी निकालने दें।
- पेजिनेशन: Thunderbit आपके लिए “Next” पेजों या infinite scroll पर क्लिक कर सकता है।
- Excel, Google Sheets, Airtable, Notion में एक्सपोर्ट: एक क्लिक में आपका डेटा इस्तेमाल करने लायक तैयार।
- फ़्री टियर: कुछ पेजों तक इसे मुफ़्त में आज़माएँ।
- एंटी-बॉट चीज़ों को आपके लिए संभालता है: क्योंकि यह आपके ब्राउज़र में (या क्लाउड में) चलता है, Amazon इसे असली यूज़र जैसा देखता है।
चरण-दर-चरण: Amazon प्रोडक्ट डेटा स्क्रैप करने के लिए Thunderbit का उपयोग
यह कितना आसान है:
-
Thunderbit इंस्टॉल करें:
डाउनलोड करें और साइन इन करें।
-
Amazon खोलें:
जिस Amazon पेज को आप स्क्रैप करना चाहते हैं, वहाँ जाएँ (search results, product detail, जो भी हो)।
-
“AI Suggest Fields” क्लिक करें या Template उपयोग करें:
Thunderbit निकालने के लिए कॉलम सुझाएगा (या आप Amazon Product template चुन सकते हैं)।
-
कॉलम्स की समीक्षा करें:
चाहें तो कॉलम समायोजित करें (फ़ील्ड जोड़ें/हटाएँ, नाम बदलें, आदि)।
-
“Scrape” पर क्लिक करें:
Thunderbit पेज से डेटा निकालता है और उसे टेबल में दिखाता है।
-
सबपेज और पेजिनेशन संभालें:
अगर आपने सूची स्क्रैप की है, तो “Scrape Subpages” क्लिक करके हर प्रोडक्ट के डिटेल पेज पर जाएँ और और जानकारी निकालें। Thunderbit “Next” पेजों पर अपने-आप क्लिक भी कर सकता है।
-
अपना डेटा एक्सपोर्ट करें:
“Export to Excel” या “Export to Google Sheets” क्लिक करें। हो गया।
-
(वैकल्पिक) स्क्रैपिंग शेड्यूल करें:
क्या यह डेटा आपको रोज़ चाहिए? इसे ऑटोमेट करने के लिए Thunderbit का scheduler इस्तेमाल करें।
बस इतना ही। कोई कोड नहीं, कोई डिबगिंग नहीं, कोई proxies नहीं, कोई सिरदर्द नहीं। विज़ुअल walkthrough के लिए या देखिए।
Amazon Scraper Python बनाम No Code Web Scraper: आमने-सामने तुलना
आइए सब कुछ एक साथ रखते हैं:
| मानदंड | Python Scraper | Thunderbit (No Code) |
|---|---|---|
| सेटअप समय | अधिक (इंस्टॉल, कोड, डिबग) | कम (एक्सटेंशन इंस्टॉल) |
| ज़रूरी कौशल | कोडिंग आवश्यक | कुछ नहीं (पॉइंट & क्लिक) |
| लचीलापन | असीमित | आम उपयोग मामलों के लिए उच्च |
| मेंटेनेंस | आप कोड ठीक करते हैं | टूल खुद अपडेट होता है |
| एंटी-बॉट हैंडलिंग | आप प्रॉक्सी, हेडर्स संभालते हैं | बिल्ट-इन, आपके लिए संभाला जाता है |
| स्केलेबिलिटी | मैनुअल (थ्रेड्स, प्रॉक्सी) | क्लाउड स्क्रैपिंग, समानांतर प्रोसेसिंग |
| डेटा एक्सपोर्ट | कस्टम (CSV, Excel, DB) | Excel, Sheets में एक क्लिक |
| लागत | मुफ़्त (आपका समय + प्रॉक्सी) | फ्रीमियम, स्केल के लिए भुगतान |
| सबसे अच्छा किसके लिए | डेवलपर्स, कस्टम ज़रूरतें | बिज़नेस यूज़र्स, तेज़ परिणाम |
अगर आप ऐसे डेवलपर हैं जिसे चीज़ों को ट्यून करना पसंद है और बहुत कस्टम समाधान चाहिए, तो Python आपका दोस्त है। अगर आप गति, सरलता और ज़ीरो कोड चाहते हैं, तो Thunderbit सही रास्ता है।
Amazon डेटा के लिए Python, No Code, या AI Web Scraper कब चुनें
Python चुनें अगर:
- आपको कस्टम लॉजिक चाहिए या स्क्रैपिंग को अपने backend systems में इंटीग्रेट करना है
- आप बड़े पैमाने पर स्क्रैप कर रहे हैं (दसियों हज़ार प्रोडक्ट्स)
- आप समझना चाहते हैं कि स्क्रैपिंग अंदर से कैसे काम करती है
Thunderbit (no code, AI web scraper) चुनें अगर:
- आपको बिना कोडिंग के तेज़ डेटा चाहिए
- आप बिज़नेस यूज़र, एनालिस्ट या मार्केटर हैं
- आपको अपनी टीम को खुद डेटा निकालने में सक्षम बनाना है
- आप proxies, एंटी-बॉट उपायों और मेंटेनेंस की झंझट से बचना चाहते हैं
दोनों का उपयोग करें अगर:
- आप Thunderbit से जल्दी prototype बनाना चाहते हैं, फिर production के लिए custom Python solution तैयार करना चाहते हैं
- आप डेटा कलेक्शन के लिए Thunderbit और डेटा क्लीनिंग/एनालिसिस के लिए Python इस्तेमाल करना चाहते हैं
ज़्यादातर बिज़नेस यूज़र्स के लिए, Thunderbit आपकी Amazon scraping ज़रूरतों का 90% बहुत कम समय में पूरा कर देगा। बाकी 10%—बहुत कस्टम, बड़े पैमाने वाले, या गहराई से इंटीग्रेटेड काम—के लिए Python अब भी सबसे आगे है।
निष्कर्ष और मुख्य सीख
Amazon प्रोडक्ट डेटा स्क्रैप करना किसी भी सेल्स, ई-कॉमर्स, या ऑपरेशंस टीम के लिए एक सुपरपावर है। चाहे आप कीमतों पर नज़र रख रहे हों, प्रतिस्पर्धियों का विश्लेषण कर रहे हों, या बस अपनी टीम को अंतहीन कॉपी-पेस्ट से बचाना चाहते हों—आपके लिए एक समाधान मौजूद है।
- Python scraping आपको पूरा नियंत्रण देती है, लेकिन इसमें सीखने की एक प्रक्रिया और लगातार मेंटेनेंस होता है।
- Thunderbit जैसे no code web scrapers Amazon डेटा एक्सट्रैक्शन को सभी के लिए सुलभ बनाते हैं—कोडिंग नहीं, सिरदर्द नहीं, बस नतीजे।
- सबसे अच्छा तरीका? वही टूल चुनें जो आपकी स्किल, आपकी टाइमलाइन और आपके बिज़नेस लक्ष्यों से मेल खाता हो।
अगर जिज्ञासा है, तो Thunderbit आज़माकर देखिए—शुरू करने के लिए यह मुफ़्त है, और आप हैरान रह जाएँगे कि ज़रूरी डेटा कितनी जल्दी मिल सकता है। और अगर आप डेवलपर हैं, तो मिक्स एंड मैच करने से न डरें: कभी-कभी बनाने का सबसे तेज़ तरीका होता है AI से उबाऊ हिस्से करवा लेना।
FAQs
1. कोई बिज़नेस Amazon प्रोडक्ट डेटा क्यों स्क्रैप करना चाहेगा?
Amazon को स्क्रैप करके बिज़नेस कीमतों पर नज़र रख सकते हैं, प्रतिस्पर्धियों का विश्लेषण कर सकते हैं, प्रोडक्ट रिसर्च के लिए रिव्यूज़ जुटा सकते हैं, डिमांड का अनुमान लगा सकते हैं, और सेल्स लीड्स जनरेट कर सकते हैं। Amazon पर 600 मिलियन से ज़्यादा प्रोडक्ट्स और लगभग 2 मिलियन सेलर्स होने के कारण, यह प्रतिस्पर्धी जानकारी का समृद्ध स्रोत है।
2. Amazon स्क्रैप करने के लिए Python और Thunderbit जैसे no-code टूल्स में मुख्य अंतर क्या हैं?
Python scrapers अधिकतम लचीलापन देते हैं, लेकिन इसके लिए कोडिंग स्किल, सेटअप समय, और लगातार मेंटेनेंस चाहिए। Thunderbit, एक no-code AI वेब स्क्रैपर, उपयोगकर्ताओं को Chrome extension के जरिए तुरंत Amazon डेटा निकालने देता है—कोडिंग नहीं चाहिए, साथ में बिल्ट-इन एंटी-बॉट हैंडलिंग और Excel या Sheets में एक्सपोर्ट विकल्प भी हैं।
3. क्या Amazon से डेटा स्क्रैप करना कानूनी है?
Amazon की terms of service सामान्यतः scraping को प्रतिबंधित करती हैं, और वे सक्रिय रूप से anti-bot measures लागू करते हैं। फिर भी, कई व्यवसाय सार्वजनिक रूप से उपलब्ध डेटा को जिम्मेदारी से स्क्रैप करते हैं—जैसे rate limits का सम्मान करना और अत्यधिक requests से बचना।
4. वेब स्क्रैपिंग टूल्स से Amazon से किस तरह का डेटा निकाला जा सकता है?
आम डेटा फ़ील्ड्स में प्रोडक्ट शीर्षक, कीमतें, रेटिंग्स, रिव्यू काउंट, इमेजेज़, प्रोडक्ट स्पेसिफिकेशन्स, उपलब्धता, और यहाँ तक कि सेलर जानकारी भी शामिल है। Thunderbit सबपेज स्क्रैपिंग और पेजिनेशन भी सपोर्ट करता है ताकि कई listings और पेजों से डेटा लिया जा सके।
5. मुझे Python scraping कब चुननी चाहिए और कब Thunderbit जैसे टूल को?
अगर आपको पूरा नियंत्रण, कस्टम लॉजिक, या scraping को backend systems में इंटीग्रेट करने की योजना है, तो Python चुनें। अगर आप बिना कोडिंग के तेज़ परिणाम चाहते हैं, आसानी से scale करना चाहते हैं, या कम-मेंटेनेंस समाधान की तलाश में बिज़नेस यूज़र हैं, तो Thunderbit चुनें।
और गहराई में जाना चाहते हैं? ये संसाधन देखें:
खुश होकर scraping करें—और आपकी स्प्रेडशीट्स हमेशा अप-टू-डेट रहें।