
האינטרנט גדל בקצב שקשה ממש לתפוס. מדי יום מתפרסמים מיליארדי עמודים חדשים, מוצרים, ביקורות ומאגרי נתונים — והכול מזין תחומים כמו מחקר שוק, אימון AI ואפילו את מסע הקניות הבא שלכם ב-Amazon. כמי שעוסק כבר שנים ב-SaaS ובאוטומציה, ראיתי מקרוב איך הנתונים הנכונים יכולים להכריע עסקה או החלטה עסקית. אבל כאן בדיוק העניין: לאסוף, לעדכן ולעבד את כל נתוני האינטרנט האלה נהיה קשה יותר, לא פשוט יותר. Web Scraper-ים מסורתיים מתקשים לעמוד בקצב, ועסקים מחפשים דרך חכמה ומהירה יותר להפוך את הרשת לתובנות מעשיות. כאן נכנס לתמונה ה-Cloud Crawler — כלי שמוביל בשקט מהפכה באופן שבו ארגונים מגלים ומנצלים נתוני רשת בקנה מידה גדול.
אז מה זה בעצם Cloud Crawler? במה הוא שונה מ-Web Scraper-ים שכבר אולי מוכרים לכם? ולמה צוותים ממכירות ועד תפעול מהמרים על הטכנולוגיה הזו כדי להישאר צעד אחד לפני כולם בעולם מבוסס-נתונים? בואו נצלול פנימה, נפשט את המונחים, ונראה איך Cloud Crawler-ים (ובמיוחד הפתרון של Thunderbit) משנים את כללי המשחק עבור עסקים מודרניים.
מהו Cloud Crawler? הצעד הבא בגילוי נתונים
בואו נפרק את זה: Cloud Crawler הוא לא סתם Web Scraper שפועל בענן. הוא יותר כמו מנוע לגילוי נתונים — מערכת חכמה מבוססת-ענן שנועדה לאתר, לחלץ ולנתח אוטומטית מאגרי נתונים עצומים מכל רחבי האינטרנט. בעוד Web Scraper מסורתי שולף מידע מכמה עמודים בודדים (לעיתים אחד-אחד, ובדרך כלל ממכשיר יחיד), Cloud Crawler עובד ברמה אחרת לגמרי. הוא רץ במרכזי נתונים חזקים בענן, סורק אלפי ואפילו מיליוני עמודים במקביל, ויכול לעבד הכול מטקסט ועד תמונות ו-PDF — לא משנה כמה מורכב או רחב האתר היעד.
אפשר לחשוב על זה כך: אם Web Scraper הוא כמו ספרן יחיד שמעתיק קטעים מתוך ספר, Cloud Crawler הוא צוות של מחשבי-על שסורקים את כל הספרייה בבת אחת, תוך כדי תיוג, ארגון וניתוח התוכן. התוצאה? עסקים מקבלים נתונים עשירים, עדכניים ושימושיים יותר — בלי צווארי בקבוק של חומרה מקומית או עבודה ידנית (, ).
Cloud Crawler לעומת Web Scraper מסורתי: מה באמת ההבדל?
אם אי פעם השתמשתם ב-Web Scraper, אתם מכירים את העיקרון: מצביעים על עמוד, מגדירים מה רוצים, ונותנים לכלי למשוך את הנתונים. אבל ככל שהאינטרנט נעשה גדול ומורכב יותר, הגישה הישנה מתחילה להראות את המגבלות שלה. כך נראית ההשוואה בין Cloud Crawler-ים ל-Web Scraper-ים מסורתיים:
| מאפיין/היבט | Web Scraper מסורתי | Cloud Crawler |
|---|---|---|
| פריסה | פועל על המכשיר או השרת המקומיים שלך | רץ בענן (מרכזי נתונים מרוחקים) |
| קנה מידה | מוגבל לעוצמת המחשב שלך | עיבוד מקבילי עצום — אלפי עמודים בבת אחת |
| מהירות | איטי יותר, במיוחד בעבודות גדולות | עיבוד אצווה מהיר |
| תחזוקה | דורש עדכונים תכופים, נשבר כשאתר משתנה | מבוסס ענן, מתעדכן אוטומטית, פחות שביר |
| סוגי נתונים | בדרך כלל טקסט, לפעמים תמונות | טקסט, תמונות, PDF, פריסות מורכבות |
| גישה | קשור למכשיר/רשת שלך | נגיש מכל מקום ומכל מכשיר |
| תזמון | ידני או אוטומציה בסיסית | תזמון מתקדם, משימות חוזרות |
| מתאים במיוחד ל | פרויקטים קטנים, אתרים פשוטים | צרכי נתונים רחבי היקף, תכופים או מורכבים |
Cloud Crawler-ים בנויים עבור הרשת המודרנית — עולם שבו הנתונים נמצאים בכל מקום, ומהירות וקנה מידה הם לא מותרות אלא הכרח (, ).
איך Cloud Crawler-ים משדרגים את יעילות איסוף הנתונים
כאן הדברים נעשים באמת מעניינים. Cloud Crawler-ים משתמשים בכוח של מחשוב ענן כדי לעבד אלפי עמודי אינטרנט במקביל. המשמעות היא שאפשר לחלץ קטלוג מלא של חנות אונליין, לעקוב אחרי מחירי מתחרים בעשרות אתרים, או לאסוף רישומי נדל״ן מכל הפורטלים הגדולים — והכול בזמן קצר בהרבה ממה שיידרש עם Scraper מסורתי.
למה זה חשוב? כי בתחומים כמו מסחר אלקטרוני, פיננסים ונדל״ן, הטריות של הנתונים היא הכול. מחירים, מלאי ומגמות שוק יכולים להשתנות מדקה לדקה. לחכות שעות או ימים עד ש-Scraper מקומי יסיים פשוט לא באמת אפשרי. Cloud Crawler-ים לא מוגבלים לזיכרון ה-RAM של המחשב הנייד או ל-Wi‑Fi של המשרד — הם מתרחבים לפי הצורך, כך שאפשר להתמודד גם עם משימות ענק בלי להזיע (, ).
הענפים שמרוויחים במיוחד מהיעילות הזו כוללים:
- מסחר אלקטרוני: מעקב מחירים, איסוף קטלוג מוצרים, ניתוח ביקורות
- נדל״ן: איסוף מודעות, מעקב אחרי מגמות שוק, השוואת נכסים
- פיננסים: ניתוח חדשות וסנטימנט, מעקב מניות/קריפטו, ניטור רגולציה
- מכירות ושיווק: יצירת לידים, מחקר מתחרים, זיהוי מגמות
ובכנות, זו רק ההתחלה. אם אתם צריכים נתוני רשת בקנה מידה גדול, Cloud Crawler הוא החבר החדש הכי טוב שלכם.
פתרון ה-Cloud Crawler של Thunderbit: מהיר, גמיש וחזק
תנו לי רגע לחבוש את הכובע של Thunderbit (טוב, האמת היא שאני כמעט אף פעם לא מוריד אותו). מצב ה-Cloud Scraping של הוא התשובה שלנו לאתגר הנתונים המודרני — Cloud Crawler שנבנה עבור משתמשים עסקיים שרוצים תוצאות, לא כאבי ראש.
זה מה שמבדיל את ה-Cloud Crawler של Thunderbit:
- חילוץ אצווה מהיר במיוחד: סריקה של עד 50 עמודים בו-זמנית, עם שרתים בענן בארה״ב, באיחוד האירופי ובאסיה להגעה גלובלית. אין יותר המתנה שהמחשב הנייד יזחול דרך רשימה ארוכה.
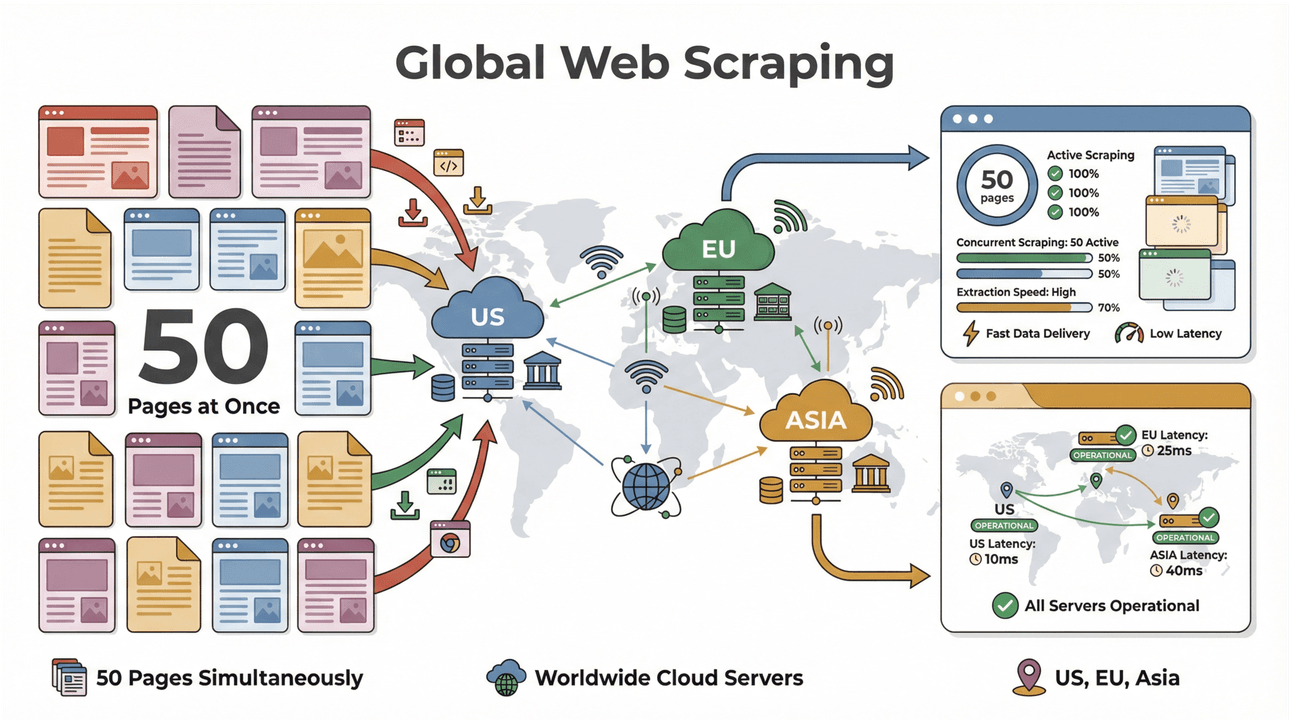
- תמיכה בעמודים מורכבים: ה-AI של Thunderbit יודע להתמודד עם אתרי Ecommerce דינמיים, PDF-ים מאתגרים ואפילו חילוץ תמונות. אם זה נמצא ברשת, סביר להניח ש-Thunderbit יכול לחלץ אותו ().
- סריקת עמודי משנה: צריכים להעשיר את המידע שלכם בפרטים מעמודי משנה (כמו מפרטי מוצר או ביוגרפיות של כותבים)? ה-AI של Thunderbit יכול לבקר בכל עמוד משנה ולמזג את התוצאות למאגר הראשי ().
- מבנה נתונים חכם: השתמשו ב-"AI Suggest Fields" כדי לאפשר ל-Thunderbit לקרוא את האתר ולהמליץ על העמודות הטובות ביותר — בלי קוד ובלי בניית תבניות.
- ייצוא לכל מקום: שלחו את הנתונים ישירות ל-Excel, Google Sheets, Airtable או Notion. או פשוט הורידו כ-CSV/JSON — מה שמתאים לזרימת העבודה שלכם ().
- בלי תחזוקה: ה-AI של Thunderbit מסתגל לשינויים באתר, כך שלא תצטרכו כל הזמן לתקן Scraper-ים שבורים ().
וכן, אפשר לנסות את כל זה גם עם — אז לא תצטרכו להאמין לי רק על סמך המילה שלי.
פריסת Cloud Crawler: ענן מול מקומי — מה מתאים לכם?
אחד היתרונות הגדולים ביותר של Cloud Crawler-ים הוא גמישות הפריסה. עם Crawler מסורתי (מקומי), אתם תלויים במכשיר מסוים, ברשת מסוימת, ולעיתים גם בהרבה כאב ראש של התקנה. אם המחשב נכנס למצב שינה או האינטרנט נופל, הסריקה נעצרת. כדי להתרחב צריך לקנות חומרה נוספת או להריץ כמה סקריפטים במקביל.
Cloud Crawler-ים הופכים את התמונה:
- אין צורך בחומרה מיוחדת: כל העבודה הכבדה נעשית בענן. אפשר להפעיל סריקות ענק מ-Chromebook, Mac או אפילו מהטלפון.
- גישה מכל מקום: נוסעים? עובדים מרחוק? אין בעיה — ה-Cloud Crawler שלכם זמין תמיד.
- הרחבה קלה: צריכים לסרוק 10,000 עמודים במקום 100? פשוט מגדילים את גודל המשימה — בלי מעורבות של IT.
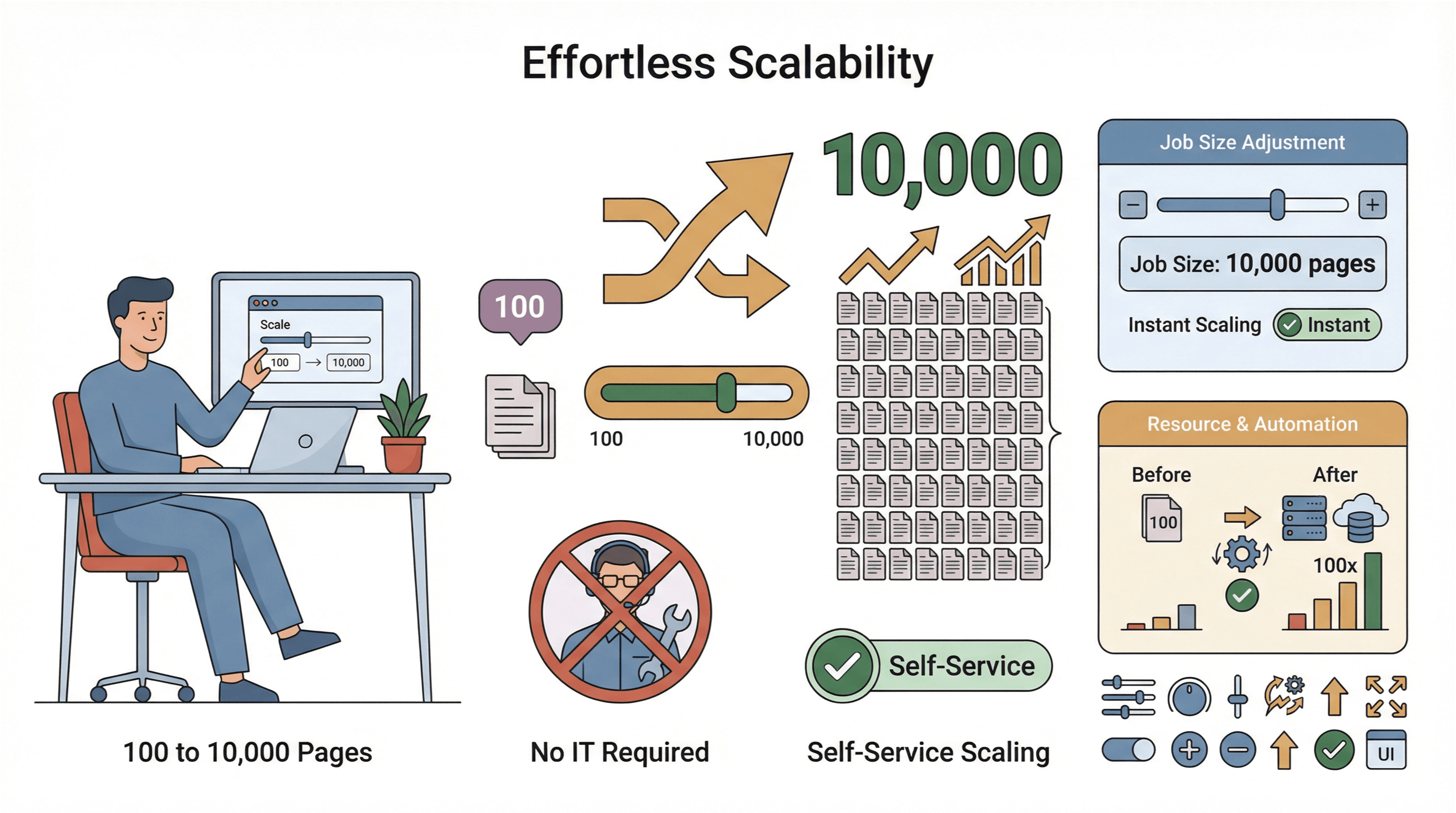
- איסוף נתונים גלובלי: עם שרתים בענן באזורים שונים, אפשר לגשת לתוכן עם הגבלות גיאוגרפיות ולנהל תאימות בקלות רבה יותר ().
כמובן, אבטחה ותאימות תמיד נמצאות בראש סדר העדיפויות. Cloud Crawler-ים מובילים (כולל Thunderbit) משתמשים בחיבורים מוצפנים, מכבדים את תנאי האתרים, ומציעים יכולות שמסייעות לנהל מידע רגיש בצורה אחראית.
השפעה בעולם האמיתי: איך Cloud Crawler-ים משנים אסטרטגיות מבוססות-נתונים
בואו נדבר מעשי. למה עסקים עוברים ל-Cloud Crawler-ים? כי הם רואים השפעה אמיתית ומדידה:
- ניתוח שוק בזמן אמת: קמעונאים משתמשים ב-Cloud Crawler-ים כדי לעקוב בזמן אמת אחרי מחירי מתחרים ומלאי, ולתמוך בתמחור דינמי ובתגובות מהירות לשינויים בשוק ().
- חיזוי מגמות צרכניות: מותגים מאגדים ביקורות, פוסטים מרשתות חברתיות ודיונים בפורומים כדי לזהות טרנדים מתפתחים ולהתאים קמפיינים תוך כדי תנועה.
- מכירות ויצירת לידים: צוותי מכירות בונים רשימות לידים מעודכנות מספריות, מאתרי אירועים ואפילו מ-PDF — ומזינים את ה-CRM באנשי קשר טריים ורלוונטיים ().
- תפעול וציות: גופים פיננסיים משתמשים ב-Cloud Crawler-ים כדי לנטר עדכוני רגולציה, חדשות והגשות מסמכים בין תחומי שיפוט שונים — וכך מצמצמים סיכון ונשארים עם היד על הדופק.
החוט המקשר בין הכול? Cloud Crawler-ים מאפשרים לצוותים לנוע מהר יותר, לקבל החלטות חכמות יותר ולהקדים מתחרים שעדיין תקועים במסלול האיטי.
תכונות מרכזיות שכדאי לחפש ב-Cloud Crawler
לא כל Cloud Crawler נולד שווה. אם אתם בודקים אפשרויות, הנה התכונות החשובות ביותר — ושם Thunderbit באמת בולט:
- יכולת קנה מידה: האם הוא יכול להתמודד עם אלפי עמודים בבת אחת? האם הוא מאט כשעומס העבודה גדל?
- קלות שימוש: האם הממשק נוח גם למשתמשים לא טכניים? האם אפשר להגדיר סריקה בכמה קליקים?
- תמיכה בכמה סוגי נתונים: טקסט, תמונות, PDF-ים, עמודי משנה — האם הוא יודע להתמודד עם הכול?
- אינטגרציות: האם הוא מייצא לכלים שאתם כבר אוהבים (Excel, Sheets, Notion, Airtable)?
- תזמון: האם אפשר להגדיר משימות חוזרות כדי לקבל נתונים תמיד מעודכנים?
- סיוע מבוסס AI: האם יש המלצות חכמות על שדות, העשרת נתונים והתאמה אוטומטית לשינויים באתר?
- אבטחה ותאימות: האם הנתונים והפרטים שלכם מוגנים? האם הכלי מסייע לעמוד בחוקי פרטיות?
Thunderbit עונה על כל הסעיפים האלה, ולכן הוא בחירה מצוינת לצוותים שרוצים כוח בלי סבל.
איך להתחיל: איך להשתמש ב-Cloud Crawler לעסק שלכם
מוכנים להתחיל? כך משתמש עסקי טיפוסי יכול להתחיל לעבוד עם Cloud Crawler כמו Thunderbit:
- התקינו את : התקנה מהירה, בלי צורך ב-IT.
- בחרו את היעד: פתחו את האתר, הרשימה או המסמך שתרצו לחלץ ממנו נתונים.
- לחצו על "AI Suggest Fields": תנו ל-AI של Thunderbit לסרוק את העמוד ולהציע את העמודות הטובות ביותר לחילוץ.
- התאימו לפי הצורך: הוסיפו, הסירו או שנו שמות של שדות בהתאם לצרכים שלכם.
- בחרו מצב Cloud Scraping: למשימות גדולות או אתרים מורכבים, עברו למצב ענן למהירות מקסימלית.
- הפעילו את הסריקה: Thunderbit יעבד עד 50 עמודים בו-זמנית בענן.
- בדקו וייצאו: צפו בתוצאות, ואז ייצאו ל-Excel, Google Sheets, Notion או Airtable.
- תזמנו משימות חוזרות: לצרכים מתמשכים, הגדירו סריקות מתוזמנות — והנתונים יתעדכנו אוטומטית ().
טיפ קטן: התחילו ממשימה קטנה כדי להתרגל, ואז הגדילו בהדרגה כשאתם מרגישים בנוח. ואל תהססו להיעזר בתמיכה או בתיעוד של Thunderbit — הם שם כדי לעזור.
עתיד איסוף הנתונים: מה צפוי ל-Cloud Crawler-ים?
מהפכת ה-Cloud Crawler-ים רק בתחילתה. הנה מה שאני עוקב אחריו בשנים הקרובות:
- חילוץ AI חכם יותר: Cloud Crawler-ים נעשים טובים יותר בהבנת הקשר, קשרים ואפילו סנטימנט — מה שהופך את הנתונים שהם אוספים ליקרים יותר ().
- תמיכה בסוגי נתונים חדשים: צפויה תמיכה טובה יותר בווידאו, אודיו ותוכן אינטראקטיבי — לא רק בטקסט ובתמונות סטטיים.
- אוטומציה עמוקה יותר: מתזמון אוטומטי ועד התראות בזמן אמת, Cloud Crawler-ים יהפכו לעוד יותר “ידיים חופשיות” עבור משתמשים עסקיים.
- תאימות משופרת: ככל שחוקי הפרטיות מתפתחים, Cloud Crawler-ים יטמיעו יותר כלים שיעזרו לצוותים להישאר בצד הנכון של התקנות.
- אינטגרציה עם כלי BI ו-AI: צינורות ישירים מ-Cloud Crawler-ים לפלטפורמות אנליטיקה, דשבורדים ולמידת מכונה.
בקיצור, Cloud Crawler-ים עומדים להפוך לעמוד השדרה של אסטרטגיית העסקים הדיגיטלית — ולהזין הכול מהשקות מוצרים ועד תחזיות מבוססות-AI ().
סיכום: למה Cloud Crawler-ים חיוניים לעסקים מודרניים
לסיכום: האינטרנט מתפוצץ מכמות נתונים, והדרכים הישנות לאיסוף שלהם פשוט כבר לא עומדות בקצב. Cloud Crawler-ים הם האבולוציה הבאה — עם מהירות, קנה מידה ואינטליגנציה ש-Web Scraper-ים מסורתיים לא מסוגלים להשתוות אליהם. כלים כמו מאפשרים לכל צוות, טכני או לא, למצות את מלוא הפוטנציאל של נתוני הרשת — ולחזק קבלת החלטות חכמה יותר, תגובה מהירה יותר ויתרון תחרותי אמיתי.
אם אתם מוכנים להשאיר מאחור את הסריקה הידנית והנתונים האיטיים, עכשיו הזמן לבדוק מה Cloud Crawler יכול לעשות עבור העסק שלכם. נסו את מצב ה-Cloud Scraping של Thunderbit, ותגלו עד כמה גילוי נתונים מודרני יכול להיות פשוט — ובעיקר חזק. ואם אתם רוצים להעמיק, היכנסו ל- כדי למצוא עוד מדריכים, טיפים ודוגמאות מהעולם האמיתי.
שאלות נפוצות
1. מה זה Cloud Crawler במילים פשוטות?
Cloud Crawler הוא כלי מבוסס-ענן שמגלה, מחלץ ומנתח אוטומטית כמויות גדולות של נתונים מהאינטרנט. בניגוד ל-Scraper-ים מסורתיים שרצים על המכשיר המקומי, Cloud Crawler-ים פועלים במרכזי נתונים חזקים, מה שמאפשר קנה מידה ומהירות עצומים.
2. במה Cloud Crawler שונה מ-Web Scraper רגיל?
Cloud Crawler-ים רצים בענן, מטפלים באלפי עמודים בו-זמנית, תומכים בסוגי נתונים מורכבים כמו תמונות ו-PDF-ים, ולא דורשים תחזוקה או חומרה מקומית. Web Scraper-ים מסורתיים מוגבלים לעוצמת המכשיר שלכם ומתאימים בעיקר למשימות קטנות ופשוטות.
3. מהם היתרונות העיקריים של שימוש ב-Cloud Crawler?
Cloud Crawler-ים מציעים איסוף נתונים מהיר ובקנה מידה גדול, תמיכה באתרים מורכבים, גישה קלה מכל מקום, ותכונות מתקדמות כמו תזמון וחילוץ מבוסס AI. הם אידיאליים לעסקים שצריכים נתונים עדכניים ושימושיים במהירות.
4. איך ה-Cloud Crawler של Thunderbit עובד עבור משתמשים עסקיים?
ה-Cloud Crawler של Thunderbit מאפשר להגדיר סריקה בכמה קליקים בלבד — בלי צורך בקוד. אפשר לחלץ נתונים מאתרים, PDF-ים ותמונות, להעשיר אותם באמצעות AI, ולייצא ישירות ל-Excel, Google Sheets, Notion או Airtable. הוא נבנה עבור משתמשים לא טכניים שרוצים תוצאות, לא מורכבות.
5. האם Cloud Crawling מאובטח ותואם לחוקי פרטיות?
כן, Cloud Crawler-ים מובילים כמו Thunderbit משתמשים בחיבורים מוצפנים ובשיטות עבודה מומלצות לאבטחת מידע. חשוב תמיד לחלץ רק מידע ציבורי ולהקפיד על תנאי השימוש של האתר ועל רגולציית הפרטיות.
מוכנים לראות מה Cloud Crawler יכול לעשות? והתחילו לחקור היום את עולם איסוף הנתונים מבוסס-הענן בקנה מידה גדול.
מידע נוסף