

Les données web sont partout, et elles sont devenues un actif stratégique à part entière pour les entreprises. Commerce, e-commerce, immobilier, veille concurrentielle : dans chacun de ces métiers, avoir la bonne information au bon moment change la donne. Reste un obstacle bien connu : personne n’a envie de recopier à la main des pages web entières dans un tableur. L’extraction de données web existe précisément pour éviter cette corvée, et elle est plus accessible qu’on ne l’imagine.
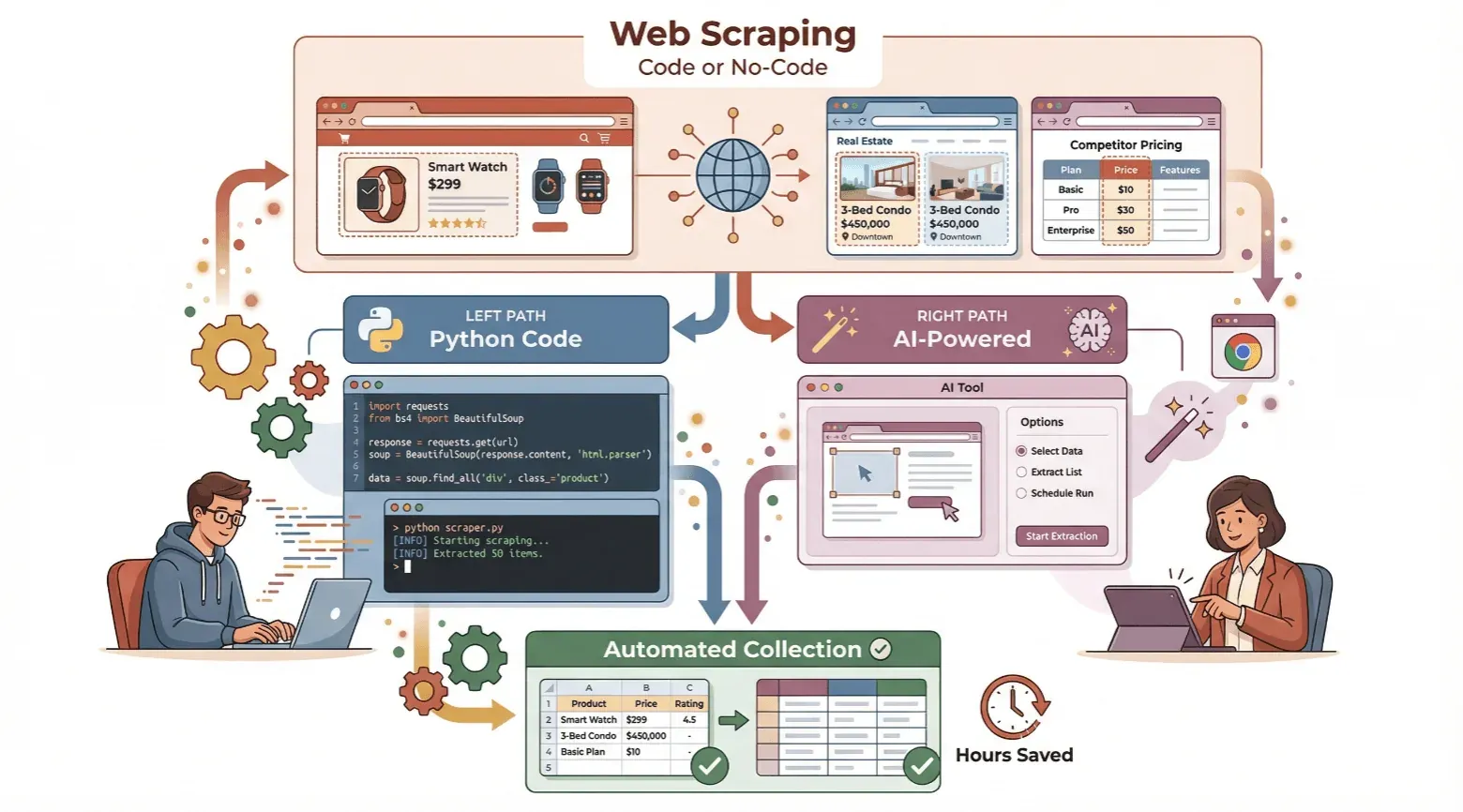
Ce guide détaille deux façons de créer un extracteur Web : coder le vôtre en Python si vous voulez comprendre les rouages, ou passer par un outil sans code piloté par l’IA comme Thunderbit si vous préférez aller droit au résultat. Nous verrons les fondamentaux, les deux méthodes pas à pas, puis comment trancher entre elles selon votre situation.
Un extracteur Web, concrètement, c’est quoi ?
Un extracteur Web est un outil — logiciel ou service — qui récupère automatiquement des informations depuis des sites web. Prenons un besoin banal : la liste de tous les cafés de votre ville, avec adresses et numéros de téléphone. Deux options s’offrent à vous. La première : cliquer de page en page et tout recopier à la main, jusqu’à la crampe. La seconde : confier ce travail à un extracteur.
L’extracteur agit comme un assistant qui lit les pages, y repère les éléments que vous visez — prix, noms de produits, coordonnées — et les range dans un tableur ou une base de données. Fini les allers-retours entre un onglet et Excel : la récupération, l’analyse et l’enregistrement se font en une seule opération, et en une fraction du temps.
Ce qui se joue en coulisses tient en trois temps :
- Requête : l’extracteur interroge une page et en télécharge le HTML brut.
- Analyse : il parcourt ce HTML pour isoler les données visées (le prix logé dans une balise
<span>, par exemple). - Extraction : il enregistre le résultat dans un format structuré — CSV, Excel, Google Sheets, etc.
Le copier-coller manuel, c’est vider une piscine à la petite cuillère. L’extraction web, c’est brancher la pompe.
Ce que l’extraction web apporte à une entreprise
L’extraction de données n’est plus réservée aux profils techniques ou aux data scientists : elle est devenue un réflexe pour quiconque a besoin d’informations fiables et actuelles. Près de 97 % des grandes organisations investissent aujourd’hui dans la décision fondée sur les données, et les projections de marché anticipent une croissance soutenue jusqu’à la fin de la décennie.
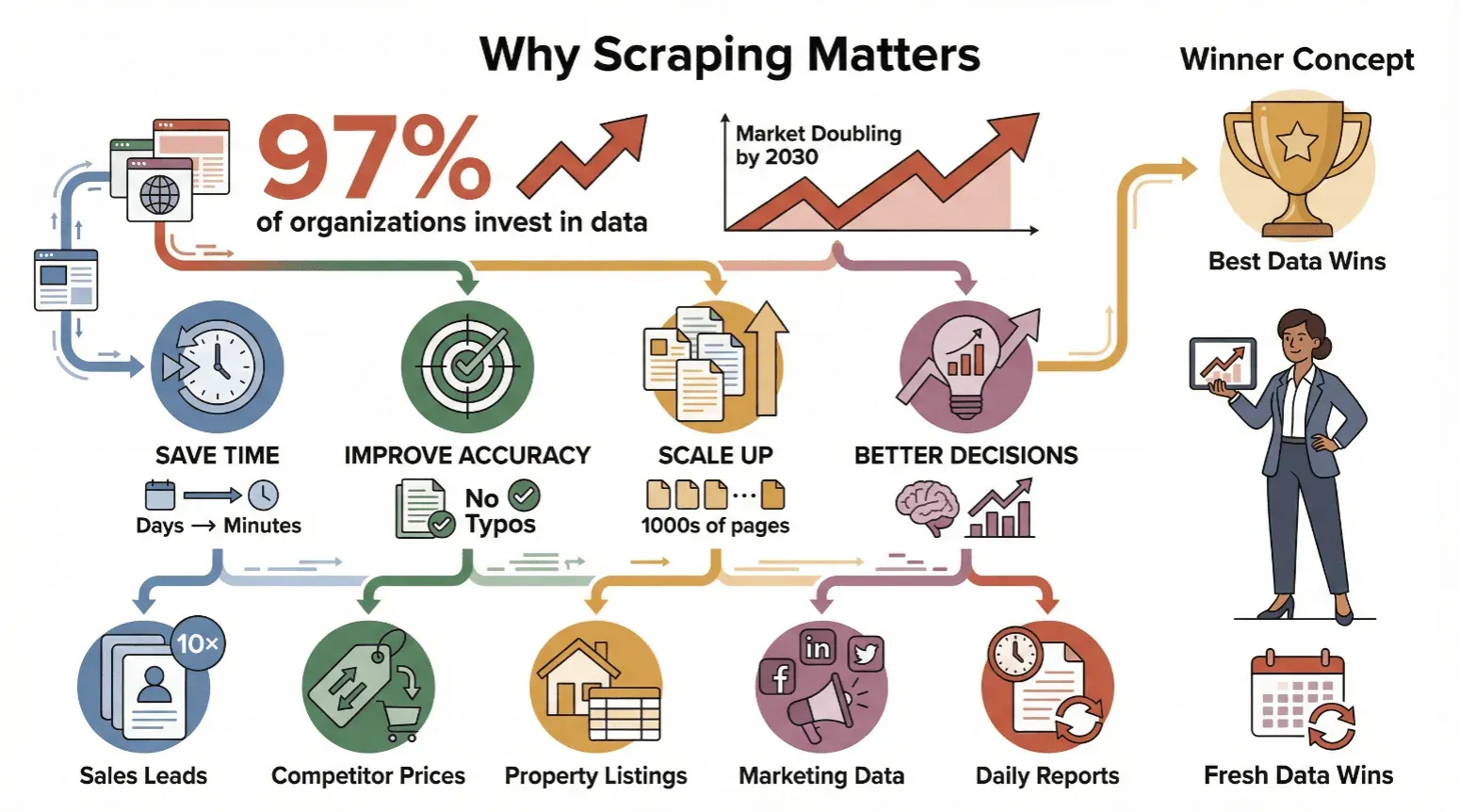
Ce qui pousse les entreprises de toutes tailles à s’y mettre :
- Le temps gagné : l’automatisation ramène des journées de travail manuel à quelques minutes.
- La fiabilité : un logiciel ne se fatigue pas et ne fait pas de fautes de frappe.
- Le passage à l’échelle : on extrait des milliers de pages, pas seulement une dizaine.
- De meilleures décisions : des données fraîches nourrissent des choix plus avisés — ajuster un prix, repérer un prospect, suivre une tendance.
Quelques cas d’usage concrets :
| Cas d’usage | Qui en bénéficie | Résultat habituel |
|---|---|---|
| Extraire des prospects commerciaux à partir d’annuaires | Équipes commerciales | 10× plus de prospects, des heures gagnées sur la prospection |
| Surveiller les prix des concurrents sur les sites e-commerce | Responsables e-commerce | Ajustements de prix en temps réel, protection des marges |
| Regrouper des annonces immobilières | Agences immobilières | Découverte plus rapide d’opportunités, données de marché à jour |
| Collecter des données marketing sur le web et les réseaux sociaux | Équipes marketing | Campagnes mieux ciblées, suivi des performances amélioré |
| Automatiser les rapports quotidiens de données web | Opérations, analystes | Coûts de main-d’œuvre réduits, moins d’erreurs, reporting constant et ponctuel |
Au fond, la règle est simple : celui qui dispose des données les plus complètes et les plus récentes garde l’avantage.
Coder son extracteur en Python : le parcours débutant
Vous voulez voir l’extraction de l’intérieur ? Python est un excellent terrain d’apprentissage. Même sans expérience de la programmation, quelques étapes suffisent pour un extracteur de base.
Préparer l’environnement
Installez d’abord Python sur votre machine. Récupérez la dernière version sur python.org et suivez la procédure adaptée à votre système, Windows ou Mac. Pendant l’installation, veillez à cocher « Add Python to PATH ».
Ouvrez ensuite votre terminal ou l’invite de commandes, et installez les bibliothèques requises :
pip install requests
pip install bs4
pip install pandas
requestssert à récupérer les pages web.bs4(Beautiful Soup) sert à analyser le HTML.pandassert à enregistrer les données en CSV ou Excel.
Repérer où se trouvent les données
Avant d’écrire la moindre ligne, il faut localiser vos données dans le HTML. Ouvrez le site visé dans Chrome, faites un clic droit sur l’élément qui vous intéresse — un intitulé de poste, par exemple — puis choisissez « Inspecter ». L’élément HTML correspondant se met en surbrillance ; ce sera peut-être une balise <a> avec une classe du type jobtitle. Notez ces balises et ces classes : elles diront à votre extracteur quoi chercher.
Écrire et lancer le script
Imaginons que vous cherchiez à récupérer des intitulés de poste et des noms d’entreprise sur une page d’offres d’emploi. Un script simple suffit :
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Remplacez par l’URL cible
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Trouver tous les intitulés de poste et noms d’entreprise (ajustez les sélecteurs si nécessaire)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Enregistrer en CSV
df = pd.DataFrame({'Intitulé du poste': titles, 'Entreprise': companies})
df.to_csv('jobs.csv', index=False)
print("Extraction terminée ! Données enregistrées dans jobs.csv")
- Adaptez l’URL et les noms de classe au site visé.
- Exécutez le script dans le terminal :
python yourscript.py - Ouvrez
jobs.csvpour consulter le résultat.
Un point d’attention : les sites plus complexes — pagination, contenu dynamique — imposent d’ajouter des boucles ou de passer par des outils comme Selenium. Mais pour de nombreuses pages statiques, cette approche fait le travail.
Sans une ligne de code : créer un extracteur avec Thunderbit
Et si vous ne vouliez pas toucher au code ? C’est le créneau de Thunderbit, un extracteur Web sans code, piloté par l’IA, conçu pour les utilisateurs métier. Sur des pages simples et bien structurées, vous passez de « il me faut ces données » à un tableur exploitable en quelques clics. Les sites plus retors — connexion obligatoire, défenses anti-bot, mises en page atypiques — demandent encore un peu de réglage, mais la marche à franchir reste sans commune mesure avec l’écriture d’un parseur maison.
Extraire des données depuis n’importe quel site grâce à l’IA Get Started Free
Le déroulé :
Étape 1 : installer l’extension Chrome Thunderbit
Rendez-vous sur la page de téléchargement de l’extension Chrome Thunderbit et ajoutez-la à votre navigateur. Créez un compte gratuit — la formule gratuite couvre quelques pages, de quoi faire vos premiers essais.
Étape 2 : ouvrir le site cible
Ouvrez dans Chrome la page à extraire. Connectez-vous si nécessaire, puis faites défiler pour déclencher le chargement du contenu dynamique.
Étape 3 : décrire les données recherchées
Cliquez sur l’icône Thunderbit pour ouvrir la barre latérale. Deux voies possibles :
- « Suggestion de champs par l’IA » : l’IA analyse la page et propose des colonnes (« Nom du produit », « Prix », « Image »…).
- Une requête en langage naturel, du type : « Extraire tous les titres de livres et leurs auteurs depuis cette page ».
L’IA recommande d’elle-même les champs et les types de données. Libre à vous de renommer, d’ajouter ou de supprimer des colonnes.
Étape 4 : lancer la première extraction
Vos champs définis, cliquez sur « Extraire ». Thunderbit collecte les données, gère la pagination le cas échéant et présente le tout dans un tableau lisible. Besoin de détails logés dans des sous-pages — des fiches produit individuelles, par exemple ? Cliquez sur « Extraire les sous-pages » : Thunderbit visite chaque lien et rapporte les informations complémentaires.
Étape 5 : vérifier et exporter
Relisez vos données dans le tableau Thunderbit. Une fois satisfait, cliquez sur « Exporter » et choisissez le format : Excel, CSV, Google Sheets, Airtable, Notion ou JSON. Les exports sont gratuits et illimités.
Rien de plus. Pas de code, pas de modèle à monter, pas de casse-tête.
Essayez gratuitement Thunderbit AI Web Scraper
Extracteur classique ou sans code : lequel choisir ?
Voici comment les deux approches se comparent :
| Solution | Temps de configuration | Compétences requises | Maintenance | Flexibilité | Options d’export |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Heures/jours | Programmation, bases du HTML | Élevée (se casse facilement) | Très élevée | CSV, Excel, JSON (via code) |
| Anciens outils sans code | 30 à 60 min | Quelques notions techniques | Moyenne (corrections manuelles) | Bonne pour les pages statiques | CSV, Excel |
| Thunderbit (IA sans code) | Minutes | Aucune (langage naturel) | Faible (l’IA s’adapte) | Élevée (sites dynamiques) | Excel, CSV, Sheets, Notion... |
Avec l’approche pilotée par l’IA, le temps passé à configurer et à réparer fond ; celui consacré à exploiter réellement les données augmente d’autant.
Les points de blocage des extracteurs classiques
Les extracteurs traditionnels butent sur quelques difficultés récurrentes. Voici comment Thunderbit les aborde :
- Refontes de site : un site qui change de mise en page peut faire casser votre code. L’IA de Thunderbit s’adapte automatiquement à la plupart de ces changements, ce qui vous épargne un nouveau tour de code.
- Défenses anti-bot : beaucoup de sites bloquent les scripts. Thunderbit peut travailler dans votre navigateur — en réutilisant votre session connectée — ou dans le cloud pour gagner en vitesse.
- Contenu dynamique : défilement infini, boutons « Charger plus »… autant de pièges pour les extracteurs basiques. Le défilement automatique et les éléments interactifs sont pris en charge par défaut.
- Données derrière une connexion : en mode navigateur, la règle est simple — si vous le voyez dans Chrome, vous pouvez l’extraire.
Autrement dit, Thunderbit est fait pour composer avec le désordre des sites web actuels, de sorte que vous n’ayez pas à le faire.
Aller plus loin : les fonctions avancées de Thunderbit
Thunderbit ne se contente pas de récupérer des données : il le fait vite, proprement, et les livre prêtes à l’emploi. Quelques fonctions qui font la différence :
Pagination automatique et sous-pages
Des centaines de produits répartis sur plusieurs pages ? Thunderbit détecte la pagination — boutons Suivant, défilement infini — et récupère l’ensemble en une passe. Pour descendre au niveau des sous-pages, cliquez sur « Extraire les sous-pages » : chaque lien est visité, chaque champ supplémentaire (informations vendeur, caractéristiques produit…) rapatrié.
Champs suggérés par l’IA et structuration
L’IA ne se borne pas à deviner des colonnes : elle tient compte du contexte. Elle nomme les colonnes, attribue les types de données (texte, nombre, image, email) et applique même des consignes sur mesure — « uniquement les prix supérieurs à 100 $ (environ 92 €) » ou « traduire les descriptions en anglais ». Vous pouvez ajouter des prompts pour catégoriser, résumer ou reformater au moment de l’extraction.
Modèles prêts à l’emploi
Pour les sites populaires — Amazon, Zillow, Google Maps, Instagram —, Thunderbit propose des modèles instantanés : vous choisissez le site, tous les champs sont déjà en place. Aucune configuration.
Planification et automatisation
Des données fraîches chaque jour ? Fixez un planning — « tous les lundis à 9 h » — et Thunderbit lance l’extraction seul, en actualisant votre Google Sheet ou votre base sans intervention de votre part.
Cloud ou navigateur, au choix
Exécutez vos extractions dans le navigateur — idéal pour les sites nécessitant une connexion ou très interactifs — ou dans le cloud, plus rapide sur les données publiques, jusqu’à 50 pages en simultané.
Qu’est-ce que l’extraction de données et comment la faire en 2025 Get Started Free
Cet éventail de fonctions avancées fait de Thunderbit un choix solide pour les équipes métier en quête d’un outil fiable, évolutif et rapide à prendre en main.
Guide pas à pas : créer un extracteur avec Thunderbit
Votre liste de contrôle pour démarrer sans attendre :
- Installez Thunderbit : ajoutez l’extension Chrome et créez votre compte.
- Ouvrez le site cible : connectez-vous si besoin, puis faites défiler pour charger le contenu.
- Ouvrez la barre latérale Thunderbit : cliquez sur l’icône de l’extension.
- Décrivez les données : « Suggestion de champs par l’IA » ou saisie de votre requête.
- Vérifiez les champs : renommez, ajoutez ou supprimez des colonnes.
- Cliquez sur « Extraire » : laissez Thunderbit faire le travail.
- (Facultatif) Sous-pages : pour plus de détail, cliquez sur « Extraire les sous-pages ».
- Contrôlez le résultat : vérifiez l’exactitude du tableau.
- Exportez : Excel, CSV, Google Sheets, Notion, Airtable ou JSON.
- Enregistrez / modèle / planifiez : conservez votre configuration ou programmez des extractions récurrentes.
En cas de souci :
- Données manquantes ? Reformulez votre requête ou ajoutez des consignes personnalisées.
- Contenu dynamique ? Vérifiez que vous êtes bien en mode navigateur.
- Limite de la formule gratuite atteinte ? Une montée en gamme débloque davantage de pages.
Voir les tarifs et les formules Thunderbit
Conclusion et points clés
Créer un extracteur Web n’est plus l’apanage des développeurs. Coder en Python ou déléguer le gros du travail à l’IA : dans les deux cas, les outils n’ont jamais été aussi abordables.
À retenir :
- L’extraction web fait gagner du temps, gagne en fiabilité et alimente des décisions fondées sur les données.
- Python convient pour apprendre et pour les projets sur mesure, mais il exige du code et de la maintenance.
- Thunderbit offre la voie rapide et sans code : vous décrivez ce que vous voulez, vous cliquez sur « Extraire ».
- Pagination automatique, extraction de sous-pages, champs suggérés par l’IA : autant d’atouts pour les équipes métier.
- Thunderbit s’essaie gratuitement et donne des résultats en quelques minutes.
Prêt à refermer le chapitre du copier-coller ? Téléchargez Thunderbit et jugez par vous-même. Pour aller plus loin, le blog Thunderbit regorge de tutoriels et d’astuces.
Essayez gratuitement Thunderbit AI Web Scraper Get Started Free
FAQ
1. Faut-il savoir coder pour créer un extracteur Web ?
Non. Le code (Python + Beautiful Soup) donne un contrôle total, mais un outil sans code comme Thunderbit permet à quiconque de bâtir de puissants extracteurs à partir de prompts en langage naturel et de quelques clics.
2. Quels types de données Thunderbit peut-il extraire ?
Texte, nombres, images, emails, numéros de téléphone et bien d’autres éléments, depuis à peu près n’importe quel site — listes paginées et sous-pages comprises. Des modèles couvrent en plus les sites les plus fréquentés.
3. Comment Thunderbit gère-t-il les sites qui changent de mise en page ?
Son IA s’adapte automatiquement à la plupart des refontes. Là où un extracteur classique casse à la moindre mise à jour, Thunderbit s’appuie sur une compréhension sémantique de la page et continue de fonctionner moyennant un minimum d’ajustements.
4. L’extraction de données web est-elle légale et sûre ?
Elle l’est dès lors que vous collectez des données publiquement accessibles et respectez les conditions d’utilisation du site. Thunderbit encourage un usage responsable et propose des fonctions pour vous aider à rester en conformité.
5. Peut-on planifier des extractions récurrentes et automatiser les exports ?
Oui. Vous programmez des extractions à l’intervalle voulu — quotidien, hebdomadaire… — et exportez les résultats directement vers Google Sheets, Notion, Airtable, Excel ou CSV, sans manipulation manuelle.
Prêt à automatiser votre collecte de données ? Essayez Thunderbit gratuitement et voyez à quel point l’extraction web peut être simple pour tout le monde.
En savoir plus
- Comment commencer à créer un extracteur Web : guide du débutant
- Comment extraire un site web : guide du débutant pour 2025
- Comment crawler des sites web : guide du débutant étape par étape
- Comment écrire un extracteur Web avec Python : du début à la fin
- Guide complet de l’extraction de données web en Python : étape par étape




