Le web, c’est une vraie mine d’or de données – tellement que le marché mondial des logiciels d’extracteur web devrait atteindre . Que tu sois analyste, marketeur ou juste curieux, savoir extraire des données d’un site web est devenu un vrai atout. Et franchement, qui a envie de passer des heures à faire du copier-coller ? L’objectif, c’est d’aller droit au but : obtenir des analyses utiles, des tableaux bien rangés, et pourquoi pas, automatiser tout ça.
C’est là que Python fait toute la différence. C’est un peu le couteau suisse de la data : facile à prendre en main pour les débutants, mais aussi assez costaud pour gérer tout, de la simple page à l’exploration de milliers de sites. Dans ce tutoriel web scraping, je t’emmène pas à pas : des bases du scraping avec Python, à la gestion des sites dynamiques, jusqu’à , notre extracteur web IA sans code qui rend l’extraction de données aussi simple que commander un tteokbokki sur une appli de livraison. Que tu veuilles apprendre à coder ou aller à l’essentiel, tu es au bon endroit.
Qu’est-ce que le Web Scraping et pourquoi utiliser Python pour extraire des données ?
Le web scraping, c’est tout simplement le fait d’extraire automatiquement des infos de sites web pour les transformer en données structurées – genre des tableaux, des fichiers CSV ou des bases de données – pour analyser ou bosser dessus (). Plutôt que de faire du copier-coller à la main, un extracteur web fait le boulot à ta place, mais en mille fois plus rapide et efficace.
Pourquoi c’est si précieux ? Parce qu’aujourd’hui, prendre des décisions grâce à la data, c’est la base. s’appuient sur la donnée (souvent extraite du web) pour piloter leur stratégie, surveiller la concurrence ou trouver de nouveaux clients. Imagine : tu peux suivre les prix de tes concurrents, rassembler toutes les annonces immobilières du coin ou te faire une liste de prospects sur-mesure… sans te fatiguer.
Mais pourquoi Python ? Voilà pourquoi c’est LA référence pour le web scraping :
- Lisibilité & simplicité : Python, c’est clair, facile à lire et à écrire, parfait pour créer des scripts d’extraction ().
- Écosystème ultra-riche : Des bibliothèques comme
requests,BeautifulSoup,ScrapyouSeleniumrendent la récupération, l’analyse et l’automatisation super accessibles. - Communauté énorme : Python, c’est , donc tu trouves des tutos, des forums et des exemples partout.
- Scalabilité : Python s’adapte aussi bien aux petits scripts qu’aux robots d’extraction XXL.
En bref : Python, c’est ton passeport pour exploiter la data du web, que tu sois débutant ou déjà expert.
Premiers Pas : Les Bases du Web Scraping en Python
Avant de te lancer dans le code, voilà le parcours classique pour extraire des données d’un site avec Python :
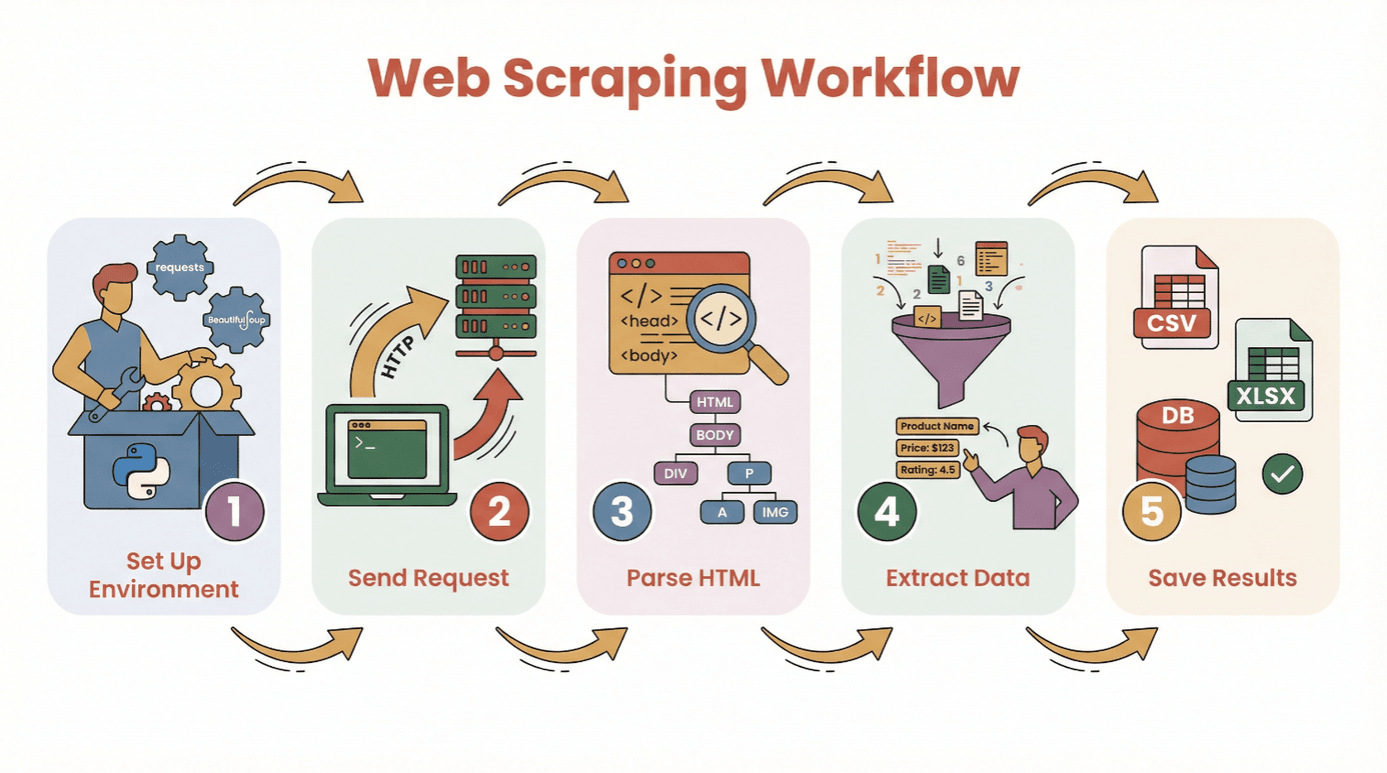
- Préparer l’environnement : Installer Python et les bibliothèques utiles (
requests,BeautifulSoup, etc.). - Envoyer une requête : Utiliser Python pour choper le contenu HTML de la page.
- Analyser le HTML : Parcourir la structure de la page avec un parseur.
- Extraire les données : Repérer et récupérer les infos qui t’intéressent.
- Sauvegarder les résultats : Stocker tout ça dans un CSV, un Excel ou une base de données pour l’analyse.
Pas besoin d’être un crack en code pour commencer. Si tu sais installer Python et lancer un script, t’as déjà fait la moitié du chemin. Pour les vrais débutants, un ou un notebook Jupyter, c’est top, mais un simple éditeur de texte fait aussi l’affaire.
Bibliothèques incontournables :
requests— pour récupérer les pages webBeautifulSoup— pour analyser le HTMLpandas— pour nettoyer et sauvegarder les données (optionnel mais super pratique)
Choisir la Bonne Bibliothèque Python : BeautifulSoup, Scrapy ou Selenium ?
Tous les outils Python ne se valent pas pour le web scraping. Petit tour d’horizon des trois stars du domaine :
| Outil | Idéal pour | Points forts | Limites |
|---|---|---|---|
| BeautifulSoup | Pages simples et statiques ; débutants | Facile à prendre en main, peu de configuration, excellente documentation | Peu adapté aux gros volumes ou contenus dynamiques |
| Scrapy | Exploration à grande échelle, multi-pages | Rapide, asynchrone, pipelines intégrés, gère le crawling et le stockage | Courbe d’apprentissage, trop complexe pour les petits besoins, pas de JS |
| Selenium | Sites dynamiques/JavaScript, automatisation | Gère le JS, simule les actions utilisateur, supporte les connexions | Plus lent, gourmand en ressources, configuration plus complexe |
BeautifulSoup : L’Indispensable pour l’Analyse HTML Simple
BeautifulSoup est parfait pour les débutants et les petits projets. Il permet d’analyser le HTML et d’extraire des éléments en quelques lignes. Si ton site cible est statique (pas de JavaScript qui charge du contenu), BeautifulSoup + requests suffisent largement.
Exemple :
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)À utiliser pour : extractions ponctuelles, blogs, pages produits ou annuaires simples.
Scrapy : Pour l’Extraction à Grande Échelle
Scrapy est un framework complet pour explorer des sites entiers ou gérer des milliers de pages. Il est asynchrone (donc rapide), propose des pipelines pour nettoyer/sauvegarder les données et suit automatiquement les liens.
Exemple :
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }À privilégier pour : gros projets, crawls planifiés, ou quand la rapidité et la structure sont clés.
Selenium : Pour les Sites Dynamiques et JavaScript
Selenium pilote un vrai navigateur (Chrome, Firefox…), ce qui permet de gérer les sites qui chargent leurs données en JavaScript, nécessitent une connexion ou des interactions (clics, scroll…).
Exemple :
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()À utiliser pour : réseaux sociaux, sites boursiers, scroll infini, ou toute page vide en « affichage du code source ».
Tutoriel Pas à Pas : Extraire des Données d’un Site avec Python (Débutant)
Prenons un exemple concret avec requests et BeautifulSoup. On va extraire les titres, auteurs et prix d’un site de livres.
Étape 1 : Préparer l’Environnement Python
D’abord, installe les bibliothèques nécessaires :
1pip install requests beautifulsoup4 pandasPuis, importe-les dans ton script :
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdÉtape 2 : Envoyer une Requête au Site
Récupère le contenu HTML :
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Échec de la récupération : \{response.status_code\}")Étape 3 : Analyser le Contenu HTML
Crée un objet BeautifulSoup :
1soup = BeautifulSoup(html, 'html.parser')Trouve tous les conteneurs de livres :
1books = soup.find_all('article', class_='product_pod')
2print(f"{len(books)} livres trouvés sur cette page.")Étape 4 : Extraire les Données Souhaitées
Boucle sur chaque livre pour récupérer les infos :
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Titre": title, "Prix": price})Étape 5 : Sauvegarder les Données pour l’Analyse
Transforme en DataFrame et sauvegarde :
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)Et voilà, tu obtiens un fichier CSV tout propre, prêt à être analysé !
Astuces de Dépannage :
- Si tu obtiens des résultats vides, vérifie si les données sont chargées en JavaScript (voir section suivante).
- Inspecte toujours la structure HTML avec les outils développeur de ton navigateur.
- Gère les données manquantes avec
get_text(strip=True)et des conditions.
Gérer le Contenu Dynamique : Extraire des Données de Sites JavaScript
Les sites modernes raffolent du JavaScript. Parfois, les données n’apparaissent pas dans le HTML de base, mais sont chargées après. Si ton extracteur ne trouve rien, c’est sûrement du contenu dynamique.
Comment s’en sortir ?
- Selenium : Simule un vrai navigateur, attend le chargement, peut cliquer ou scroller.
- Playwright/Puppeteer : Plus avancés, mais même principe (navigateurs sans interface).
Mini-guide Selenium :
- Installe Selenium et un driver (ex : ChromeDriver).
- Utilise des « waits » explicites pour attendre le chargement.
- Récupère le HTML rendu et analyse-le avec BeautifulSoup si besoin.
Exemple :
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# Extraction comme précédemment
13driver.quit()Quand utiliser Selenium ?
- Si
requests.get()te renvoie du HTML vide, mais que tu vois les données dans le navigateur. - Si le site utilise le scroll infini, des pop-ups ou demande une connexion.
Simplifier le Web Scraping avec l’IA : Utiliser Thunderbit pour Extraire des Données
Soyons clairs : parfois, on veut juste les données, pas se prendre la tête avec le code. C’est là que entre en scène. Thunderbit, c’est une extension Chrome boostée à l’IA qui te permet d’extraire des données de n’importe quel site en quelques clics – zéro ligne de Python à écrire.
Comment ça marche Thunderbit ?
- Installe l’.
- Ouvre le site que tu veux scraper.
- Clique sur l’icône Thunderbit et choisis « Suggérer les champs IA ». L’IA analyse la page et te propose les données à extraire (ex : noms de produits, prix, emails).
- Ajuste les champs si besoin, puis clique sur « Extraire ».
- Exporte tes données direct vers Excel, Google Sheets, Notion ou Airtable.
Pourquoi Thunderbit, c’est top :
- Aucune compétence technique requise. Même ta grand-mère peut l’utiliser (et elle galère encore avec le Wi-Fi !).
- Gère les sous-pages et la pagination. Besoin d’extraire des infos sur plusieurs pages ? Thunderbit clique et fusionne tout pour toi.
- Instructions en langage naturel. Dis juste ce que tu veux (« extraire tous les titres et prix ») et l’IA s’occupe du reste.
- Modèles instantanés pour les sites connus. Amazon, Zillow, LinkedIn… un clic et c’est plié.
- Export gratuit des données. Télécharge en CSV, Excel ou envoie direct vers tes outils préférés.
Thunderbit, c’est déjà plus de , et la version gratuite te permet d’extraire jusqu’à 6 pages (ou 10 avec l’essai boosté). Pour les pros, c’est un gain de temps énorme – et pour les geeks, un super moyen de prototyper avant de coder en Python.
Après l’Extraction : Nettoyer et Analyser les Données avec Pandas et NumPy
Extraire les données, c’est que la première étape. Les données brutes du web sont souvent en vrac : doublons, valeurs manquantes, formats bizarres… C’est là que pandas et NumPy deviennent tes meilleurs alliés.
Tâches de nettoyage classiques :
- Supprimer les doublons :
df.drop_duplicates(inplace=True) - Gérer les valeurs manquantes :
df.fillna('Inconnu')oudf.dropna() - Convertir les types de données :
df['Prix'] = df['Prix'].str.replace('€','').astype(float) - Analyser les dates :
df['Date'] = pd.to_datetime(df['Date']) - Filtrer les valeurs aberrantes :
df = df[df['Prix'] > 0]
Analyses de base :
- Statistiques descriptives :
df.describe() - Regrouper par catégorie :
df.groupby('Catégorie')['Prix'].mean() - Visualisations rapides :
df['Prix'].hist()oudf.groupby('Catégorie')['Prix'].mean().plot(kind='bar')
Pour les calculs plus costauds ou les gros tableaux, NumPy est là. Mais pour la plupart des besoins, pandas suffit largement.
Ressources : Si tu débutes avec pandas, check le guide .
Bonnes Pratiques et Conseils pour un Web Scraping Réussi en Python
Le web scraping, c’est puissant, mais il faut le faire proprement. Voici ma checklist pour scraper comme un pro (sans te faire bloquer ou avoir des soucis) :
- Respecte le robots.txt et les CGU. Vérifie toujours si le site autorise l’extraction ().
- N’inonde pas les serveurs. Ajoute des pauses entre les requêtes (
time.sleep(2)) et imite un comportement humain. - Utilise des headers réalistes. Mets un User-Agent pour simuler un vrai navigateur.
- Gère les erreurs proprement. Utilise try/except et relance les requêtes qui plantent.
- Alterner les proxies si besoin. Pour les gros volumes, utilise des pools de proxies pour éviter les blocages IP.
- Sois éthique et légal. N’extrais pas de données perso ou de contenus protégés sans autorisation.
- Documente ta démarche. Note ce que tu as extrait, où et quand.
- Privilégie les API officielles si elles existent. Parfois, c’est plus simple que d’analyser du HTML.
Pour plus de conseils, va voir le .
Conclusion & Points Clés à Retenir
Le web scraping avec Python, c’est un vrai super-pouvoir pour transformer le bazar du web en données propres et exploitables. Que tu utilises le code (requests, BeautifulSoup, Scrapy, Selenium) ou un outil sans code comme , tu as tout ce qu’il faut pour extraire des données et découvrir de nouveaux insights.
À retenir :
- Commence simple – teste sur une page avant de viser plus grand.
- Choisis l’outil adapté (BeautifulSoup pour le basique, Scrapy pour l’échelle, Selenium pour le dynamique, Thunderbit pour le sans-code).
- Nettoie et analyse tes données avec pandas et NumPy.
- Pratique toujours un scraping responsable et éthique.
Prêt à te lancer ? Essaie sur un petit projet – genre extraire les titres d’actus du jour ou une liste de produits – et tu verras à quelle vitesse tu passes d’une page web brute à un tableau exploitable. Et si tu veux aller à l’essentiel, et laisse l’IA bosser pour toi.
Pour plus de tutoriels, d’astuces et de conseils sur le web scraping, passe sur le .
FAQ
1. Qu’est-ce que le web scraping et pourquoi Python est-il si populaire ?
Le web scraping, c’est l’extraction automatisée de données depuis des sites web. Python cartonne grâce à sa syntaxe claire, ses bibliothèques puissantes (BeautifulSoup, Scrapy, Selenium) et sa communauté ultra-active ().
2. Quelle bibliothèque Python choisir pour le web scraping ?
BeautifulSoup pour les pages simples et statiques ; Scrapy pour les extractions à grande échelle ou multi-pages ; Selenium pour les sites dynamiques ou blindés de JavaScript. Chaque outil a ses avantages selon tes besoins ().
3. Comment gérer les sites qui chargent les données en JavaScript ?
Pour le contenu généré par JavaScript, utilise Selenium (ou Playwright) pour simuler un navigateur et attendre le chargement avant d’extraire les données. Parfois, tu peux aussi trouver une API cachée en inspectant le trafic réseau.
4. Qu’est-ce que Thunderbit et comment simplifie-t-il le web scraping ?
est une extension Chrome boostée à l’IA qui te permet d’extraire des données de n’importe quel site sans coder. L’IA suggère les champs, gère la pagination et exporte direct vers Excel, Google Sheets, Notion ou Airtable.
5. Comment nettoyer et analyser les données extraites en Python ?
Utilise pandas pour supprimer les doublons, gérer les valeurs manquantes, convertir les types et analyser les données. NumPy est top pour les calculs numériques. Pour la visualisation, pandas s’intègre à Matplotlib pour des graphiques rapides ().
Bon scraping – que tes données soient toujours clean, structurées et prêtes à l’emploi !
En savoir plus