
Google traite bien plus de — certaines estimations le situent plutôt autour de — et ce chiffre continue de grimper. Toutes ces données de recherche sont une vraie mine d’or pour les équipes SEO, les opérations commerciales, les analystes e-commerce et, de plus en plus, les agents IA qui ont besoin de preuves web en temps réel. Le problème ? Choisir une SERP API en 2026 ressemble moins à sélectionner un outil qu’à essayer de s’orienter dans un labyrinthe de pages tarifaires, de systèmes de crédits et de promesses floues autour du « JSON structuré ».
J’ai passé les dernières semaines à examiner en profondeur huit fournisseurs de SERP API — en testant les temps de réponse, en normalisant les tarifs à travers des modèles de facturation compliqués et en vérifiant quelles fonctionnalités SERP chacun convertit réellement en champs structurés. L’objectif : vous offrir une comparaison honnête, à périmètre égal, qu’aucun autre article ne propose. Nous passons en revue la vitesse, le coût réel à grande échelle, la couverture de parsing, l’aptitude aux agents IA et la fiabilité en production. Si vous avez déjà été agacé par le fait qu’« on compare des pages tarifaires, pas la dépense réelle » (une vraie citation d’un que j’ai trouvé), cet article est pour vous.
Pourquoi vous avez besoin d’une SERP API en 2026 (et pourquoi en choisir une est difficile)
Une SERP API est un service hébergé qui envoie une requête de recherche à un moteur de recherche et renvoie la page de résultats sous une forme lisible par machine — généralement du JSON. Au lieu de construire votre propre rotation de proxys, la gestion des CAPTCHA, le rendu du navigateur et les parsers, vous appelez un endpoint et récupérez des données structurées. Le concept est simple, le marché est compliqué.
Les cas d’usage vont bien au-delà du suivi de position :
- Les équipes SEO ont besoin des classements, de la propriété des extraits, des questions People Also Ask et de la visibilité des concurrents.
- Les équipes commerciales et GTM utilisent les SERP pour découvrir des entreprises, des pages d’avis, des annuaires et des signaux d’achat.
- Les équipes e-commerce surveillent Google Shopping, les annonces payantes et les prix des concurrents.
- Les développeurs IA alimentent des agents LLM, des pipelines RAG et des outils de workflow comme n8n et LangChain avec des données SERP.
Le devrait atteindre , avec une croissance annuelle composée d’environ 13,78 %. Les SERP API représentent une part importante de ce marché.
Voici la principale source de frustration : chaque fournisseur affirme proposer du « JSON structuré », mais les éléments SERP réellement analysés — PAA, panneaux de connaissances, packs locaux, annonces Shopping, extraits optimisés — varient énormément d’un service à l’autre. La tarification est tout aussi confuse. Certains facturent par recherche, d’autres par crédit, d’autres par résultat, et certains appliquent des tarifs différents selon le niveau de vitesse ou la géolocalisation. Un utilisateur Reddit l’a bien résumé : « SerpApi facture par recherche réussie, ScraperAPI fonctionne avec des crédits, et Serperdev paraît bon marché jusqu’à ce qu’on convertisse les crédits en charge de travail réelle. »
Cet article comble les lacunes que je n’ai trouvées nulle part ailleurs : une matrice de parsing montrant ce que chaque API renvoie réellement, des tarifs normalisés à 1K/10K/100K requêtes, l’adéquation aux agents IA et des données sur l’aptitude à la production.
Notre méthode de test : critères pour choisir la meilleure SERP API
J’ai évalué chaque fournisseur selon huit dimensions directement liées à ce qui compte vraiment pour les utilisateurs en production. La plupart des articles comparatifs n’en couvrent que deux ou trois de façon superficielle. Je voulais les huit, avec des preuves à l’appui.
Vitesse et temps de réponse. Je me suis appuyé sur des benchmarks tiers — notamment la — ainsi que sur la documentation des fournisseurs. La vitesse compte quand vous construisez des tableaux de bord en temps réel ou des agents IA qui appellent des outils et ne peuvent pas attendre 30 secondes pour une réponse.
Tarification à grande échelle (1K, 10K, 100K requêtes). J’ai normalisé les tarifs de chaque fournisseur en coût pour 1 000 requêtes réussies. C’est la seule façon de comparer équitablement les modèles à crédits, les abonnements et le paiement à l’usage.
Fonctionnalités SERP analysées (au-delà des résultats organiques). J’ai vérifié la documentation et des réponses d’exemple pour confirmer quels éléments SERP chaque API renvoie sous forme de champs structurés — et pas seulement en HTML brut.
Offre gratuite et disponibilité du paiement à l’usage. Un point d’entrée avec peu d’engagement compte. Si vous ne pouvez pas tester un fournisseur avec votre vraie charge de travail avant de vous engager pour des centaines de dollars, c’est un signal d’alerte.
Intégration IA et automatisation. En 2026, davantage d’équipes ont besoin que les SERP API alimentent des agents IA plutôt que des tableaux de bord. La stabilité du schéma, la propreté de la sortie et la conversion en Markdown comptent pour la consommation en aval par les LLM.
Prise en charge multi-moteurs. La plupart des articles se concentrent uniquement sur Google. J’ai vérifié quels fournisseurs prennent en charge Bing, Yandex, DuckDuckGo, Baidu et d’autres.
Limites de taux et aptitude à la production. Aucun article comparatif n’évalue systématiquement les limites de débit, les politiques de retry ou les SLA. Pourtant, les équipes qui montent à des milliers de requêtes par jour ont besoin de ces informations.
Facilité pour les développeurs. Qualité de la documentation, disponibilité des SDK et temps jusqu’au premier résultat.
1. Thunderbit
adopte une approche fondamentalement différente des SERP API traditionnelles. Au lieu de proposer des endpoints fixes qui analysent des éléments SERP prédéfinis, l’Extract API de Thunderbit vous permet de définir votre propre schéma JSON — et l’IA extrait exactement les champs que vous spécifiez depuis n’importe quelle page de résultats de moteur de recherche. Son Distill API transforme n’importe quelle URL en Markdown propre, prêt pour les LLM.
Cela signifie que Thunderbit fonctionne sur Google, Bing, Yandex, DuckDuckGo ou tout autre moteur de recherche — l’IA relit la page à chaque fois au lieu de s’appuyer sur des sélecteurs codés en dur. Les interfaces SERP changent sans arrêt. Vous n’attendez pas qu’un fournisseur mette à jour un parser.
Fonctionnalités clés
- Extract API : définissez un schéma JSON personnalisé (résultats organiques, questions PAA, entreprises du pack local, produits Shopping — ce dont vous avez besoin) et récupérez exactement ces champs sous forme de données structurées.
- Distill API : convertissez n’importe quelle page SERP en Markdown propre — idéal pour les pipelines RAG et la synthèse par LLM.
- Multi-moteur par conception : fonctionne sur n’importe quelle page de recherche accessible, pas seulement Google.
- Traitement par lots : traitez plusieurs URL en parallèle.
- Gestion anti-bot intégrée : résolution de CAPTCHA, rendu JS et rotation des proxys sont inclus.
- Limites de débit par offre : Free (10 requêtes/min, 2 en parallèle), Pro (100 requêtes/min, 10 en parallèle), Enterprise (1 000 requêtes/min, 50 en parallèle).
Tarifs
Modèle à crédits. Distill coûte 1 crédit par page ; Extract coûte 20 crédits par page. Des crédits gratuits sont disponibles pour tester. En raisonnant sur une offre annuelle, le coût marginal de Distill peut descendre à environ 0,80 USD par 1K pages, tandis qu’Extract tourne autour de 16 USD par 1K pages à pleine utilisation. La proposition de valeur d’Extract est que vous obtenez exactement le schéma dont votre système en aval a besoin — sans post-traitement.
Consultez les pour les offres à jour.
Idéal pour
Les workflows d’agents IA, les pipelines RAG, le scraping multi-moteur, les équipes qui ont besoin d’un schéma flexible plutôt que d’une sortie figée, et toute personne fatiguée d’attendre qu’un fournisseur ajoute la prise en charge d’une nouvelle fonctionnalité SERP.
2. SerpApi
est le vétéran du secteur — en activité depuis 2016 et doté de la plus large gamme d’endpoints spécifiques à Google. Il couvre Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos, et plus encore.
Fonctionnalités clés
- Endpoints dédiés pour différents produits Google, avec un géociblage mature (jusqu’au niveau de la ville).
- Analyse les PAA, panneaux de connaissances, local pack, annonces, résultats Shopping, extraits optimisés, answer boxes et recherches associées sous forme de champs structurés.
- Documentation bien tenue et bibliothèques clientes dans plusieurs langages.
Tarifs
. Offre Starter : 25 USD/mois pour 1 000 recherches (soit 25 USD par 1K). Offre Popular : 130 USD/mois pour 15 000 recherches (environ 8,67 USD par 1K). Big Data : 2 750 USD/mois pour 500 000 recherches (environ 5,50 USD par 1K). Pas d’option simple au paiement à l’usage — il s’agit de forfaits par abonnement.
Vitesse et fiabilité
Le benchmark de HasData indique un temps de réponse moyen d’environ 5,49 secondes — pas le plus rapide, mais stable. SerpApi annonce un SLA de disponibilité de 99,95 % sur les offres payantes, et les limites de requêtes simultanées varient selon l’offre.
Idéal pour
Les équipes qui ont besoin de la couverture la plus large des produits Google (Maps, Scholar, Shopping, Jobs) avec une grande précision et des schémas stables. Projets enterprise avec budget pour une tarification premium.
3. Serper
mise sur la vitesse et le coût. C’est un acteur plus récent, spécialisé dans le scraping rapide de SERP Google à un prix extrêmement compétitif, et il est devenu populaire dans les communautés n8n et LangChain pour les intégrations d’agents IA.
Fonctionnalités clés
- Sortie JSON propre pour Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents et Autocomplete.
- Mise en route minimale — vous pouvez obtenir des résultats en moins d’une minute.
- Assez simple pour être intégré nativement par les frameworks d’agents IA.
Tarifs
2 500 requêtes gratuites à l’inscription. Tarification d’entrée autour de 0,001 USD/recherche, tombant à environ 0,00075 USD en volume élevé. Adapté au paiement à l’usage. Point à noter : demander plus de 10 résultats par requête peut coûter 2 crédits (vérifiez le comportement actuel dans votre tableau de bord).
Vitesse et fiabilité
Parmi les plus rapides des benchmarks — HasData indique environ 2,87 secondes en moyenne. Le support est uniquement par e-mail, et l’équipe maintient un profil public relativement discret, ce qui en inquiète certains utilisateurs. À très forte concurrence, quelques avis signalent des problèmes de fiabilité. Pour la plupart des charges de travail, cependant, le service est solide.
Idéal pour
Les projets sensibles au budget, les startups, les intégrations d’agents IA qui ont besoin de données SERP Google rapides et peu coûteuses. Le suivi de position à grand volume lorsque le coût par requête est la contrainte principale.
4. Scrapingdog
est présent sur le marché depuis plus de 5 ans et apparaît régulièrement comme le plus rapide dans les benchmarks tiers. HasData l’a mesuré à avec un taux de réussite de 100 %.
Fonctionnalités clés
- L’API SERP Google renvoie les résultats organiques, les PAA, les extraits optimisés, les annonces et les résultats locaux sous forme de JSON structuré.
- Options disponibles en HTML brut et en JSON parsé.
- Documentation en plusieurs langues avec extraits de code pour la plupart des langages de programmation — la prise en main prend des minutes, pas des heures.
- Support 24/7.
Tarifs
. Les offres payantes commencent autour de 40 USD/mois. Le prix par appel démarre à environ 0,001 USD et baisse fortement à grand volume — certaines comparaisons citent des tarifs aussi bas que 0,000058 USD dans les niveaux supérieurs.
Vitesse et fiabilité
Les chiffres de vitesse sont vraiment impressionnants. Si votre workflow est sensible à la latence et que vous faites une extraction SERP Google à schéma fixe et à grand volume, Scrapingdog est difficile à battre sur le temps de réponse brut.
Idéal pour
Les outils SEO à grand volume et les trackers de position qui ont besoin d’une faible latence et d’un faible coût. Les équipes qui construisent des systèmes de production où chaque milliseconde du temps de réponse de l’API compte.
5. DataForSEO
n’est pas seulement une SERP API — c’est une suite complète d’API conçue pour les entreprises qui créent des produits SEO. Elle couvre les SERP, les mots-clés, les backlinks, les données d’entreprise, Google Ads, Trends, et plus encore.
Fonctionnalités clés
- Analyse SERP extrêmement complète — organique, payant, local pack, knowledge graph, PAA, extraits optimisés, Shopping, images, vidéos, top stories, et plus encore.
- Deux modes : Live (synchrone) pour les tableaux de bord en temps réel, et Standard (asynchrone) pour les workflows par lots où vous mettez les tâches en file d’attente puis récupérez les résultats plus tard.
- Multi-moteur : Google, Bing, Yahoo, Baidu, Naver, Seznam, et d’autres.
Tarifs
Modèle au paiement à l’usage, mais le coût varie selon l’endpoint, le moteur, l’appareil, la priorité et le mode. La tarification SERP varie généralement d’environ 0,0006 USD à 0,002 USD par tâche pour le Google organique, selon les paramètres standard vs live et la priorité. La documentation est dense — prévoyez du temps avec le calculateur de tarifs. .
Vitesse et fiabilité
Le mode asynchrone Standard peut être plus lent (environ 10 secondes) car les tâches sont mises en file d’attente. Les modes Live / haute vitesse coûtent plus cher, mais conviennent aux tableaux de bord en temps réel. Long historique, stabilité éprouvée et support enterprise disponibles.
Idéal pour
Les éditeurs SaaS qui construisent des plateformes SEO, des tableaux de bord de suivi de position et des outils de recherche de mots-clés. Les équipes à l’aise avec une documentation complexe et une infrastructure de niveau entreprise.
6. Bright Data
est le poids lourd du monde enterprise. Sa SERP API n’est qu’un produit parmi d’autres — proxys, datasets, Web Unlocker et outils de scraping. Sa proposition de valeur repose sur l’échelle, la fiabilité et l’infrastructure.
Fonctionnalités clés
- Endpoints dédiés pour Google Maps, Shopping et la recherche générale — ainsi qu’une prise en charge multi-moteur via une infrastructure proxy couvrant Bing, Yahoo, Yandex et DuckDuckGo.
- Taux de réussite annoncé de 100 % grâce à une technologie de déblocage intégrée.
- Là où Bright Data excelle vraiment : géociblage, concurrence simultanée et déblocage à l’échelle enterprise.
Tarifs
Orienté entreprise. Les prix publics montrent des options au paiement à l’usage et par abonnement, et de nombreuses comparaisons citent des engagements d’entrée autour de 499 USD/mois. Le coût par appel commence à environ 0,005 USD, mais baisse avec le volume. . Crédits d’essai disponibles (5 USD).
Vitesse et fiabilité
Les benchmarks montrent souvent entre 2 et 5,58 secondes. La raison d’acheter Bright Data n’est pas la latence médiane brute — c’est le SLA enterprise, le support dédié et une infrastructure capable de gérer des millions de requêtes simultanées sans dégradation. La recommande une montée en charge progressive.
Idéal pour
Les équipes enterprise qui collectent des millions de SERP par mois. Les organisations qui ont besoin de données Google Maps / entreprises locales à grande échelle. Les équipes qui utilisent déjà les produits proxy de Bright Data.
7. ScraperAPI
est une API de web scraping généraliste qui propose aussi des endpoints Google SERP structurés. C’est l’option « un seul outil pour tout » — facile à intégrer, avec un pool de proxy de plus de 40 millions d’IP.
Fonctionnalités clés
- Endpoints de données structurées pour Google Search, Shopping, News et Jobs.
- Anti-blocage et résolution de CAPTCHA basés sur le machine learning, avec rendu JavaScript inclus sans surcoût.
- Géociblage pour des résultats localisés.
Tarifs
Essai gratuit de 7 jours avec 5 000 crédits. Les offres payantes commencent autour de 49 USD/mois. Le piège : les appels SERP peuvent consommer un nombre de crédits différent des requêtes de scraping standard, donc il faut toujours normaliser par le nombre réel de requêtes SERP réussies délivrées. .
Vitesse et fiabilité
Voici la partie honnête : le benchmark de HasData rapporte un temps de réponse moyen d’environ 33,66 secondes pour les requêtes SERP. C’est nettement plus lent que les SERP API dédiées. Taux de réussite élevé (99,9 %), mais la latence le rend moins adapté aux applications temps réel. Mieux pour le traitement par lots.
Idéal pour
Les équipes qui ont besoin d’une solution générale de web scraping avec la SERP en complément. Les projets où la vitesse est moins critique que la fiabilité et la facilité de mise en place. Les développeurs qui utilisent déjà ScraperAPI pour d’autres tâches de scraping et souhaitent consolider leurs fournisseurs.
8. Apify
n’est pas une SERP API pure. C’est une plateforme de scraping et d’automatisation construite autour des « Actors » — des scripts réutilisables pour des tâches comme le scraping Google Search, l’extraction Maps et l’automatisation de workflows. Voyez-la comme une place de marché où vous choisissez (ou créez) le scraper qui correspond exactement à votre besoin.
Fonctionnalités clés
- Marketplace d’ préconstruits avec des niveaux de couverture fonctionnelle variables.
- Hautement personnalisable — créez des workflows de scraping sur mesure, enchaînez plusieurs actors, programmez les exécutions.
- Sortie JSON ; possibilité de parser des fonctionnalités SERP spécifiques via la configuration de l’actor.
- Très utile pour combiner l’extraction SERP avec d’autres tâches de scraping / automatisation.
Tarifs
Offre gratuite avec crédits mensuels de plateforme (valeur d’environ 5 USD, soit à peu près 1 400 résultats). Les offres payantes commencent autour de 49 USD/mois. Le coût au niveau de l’actor varie — certains facturent par résultat, d’autres par unité de calcul. Les comparaisons tierces situent souvent Apify autour de 0,003 USD/recherche à petite échelle. .
Vitesse et fiabilité
HasData indique environ 8,2 secondes en moyenne. L’architecture basée sur les actors ajoute une surcharge par rapport à des endpoints SERP dédiés. Mieux adapté aux workflows planifiés / par lots qu’aux requêtes en temps réel.
Idéal pour
Les équipes qui ont besoin de workflows de scraping + automatisation personnalisés, au-delà des seules données SERP. Les projets combinant extraction SERP et autres tâches de web scraping. Les développeurs qui veulent une flexibilité maximale plutôt que des endpoints préconstruits.
Matrice de parsing des fonctionnalités SERP : ce que chaque API renvoie réellement
C’est la comparaison que je n’ai trouvée nulle part ailleurs. Chaque fournisseur affirme proposer du « JSON structuré », mais les éléments SERP réellement analysés en tant que champs de premier niveau varient énormément. J’ai vérifié la documentation et les réponses d’exemple de chacun.
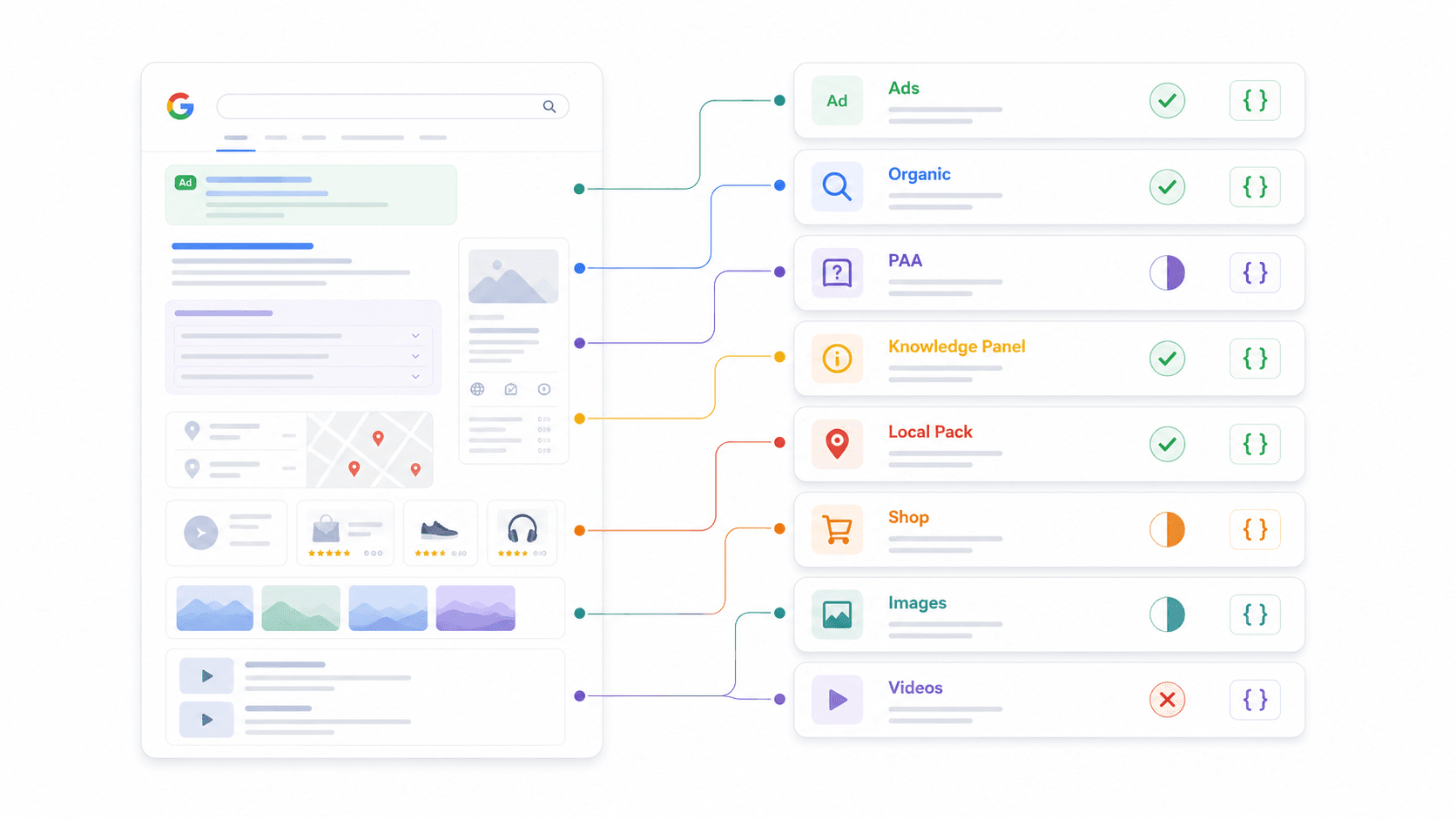
| Fonction SERP | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Résultats organiques | Schéma personnalisé | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Dépend de l’actor |
| People Also Ask | Schéma personnalisé | ✅ | ✅ | ✅ | ✅ | Partiel | Partiel | Dépend de l’actor |
| Panneau de connaissances | Schéma personnalisé | ✅ | Partiel | Partiel | ✅ | Partiel | Partiel | Dépend de l’actor |
| Pack local / Maps | Schéma personnalisé | ✅ | ✅ | Partiel | ✅ | ✅ | Partiel | Dépend de l’actor |
| Résultats Shopping | Schéma personnalisé | ✅ | ✅ | Partiel | ✅ | ✅ | ✅ | Dépend de l’actor |
| Extraits optimisés | Schéma personnalisé | ✅ | Partiel | ✅ | ✅ | Partiel | Partiel | Dépend de l’actor |
| Annonces (haut / bas) | Schéma personnalisé | ✅ | Partiel | ✅ | ✅ | Partiel | Partiel | Dépend de l’actor |
| Pack d’images | Schéma personnalisé | ✅ | ✅ | ✅ | ✅ | Partiel | Partiel | Dépend de l’actor |
| Résultats vidéo | Schéma personnalisé | ✅ | ✅ | Partiel | ✅ | Partiel | Partiel | Dépend de l’actor |
Ce que « Schéma personnalisé » signifie pour Thunderbit : au lieu de prédéfinir quelles fonctionnalités SERP il analyse, vous définissez votre propre schéma JSON pour extraire exactement les champs dont vous avez besoin. Vous voulez les questions PAA avec les résumés de réponses et des signaux d’intention commerciale ? Définissez ce schéma et l’IA vous le fournit. Cette flexibilité explique pourquoi Thunderbit fonctionne sur n’importe quel moteur de recherche — pas seulement Google.
Pourquoi cela compte pour votre workflow : si vous avez besoin de données PAA pour une stratégie de contenu, vérifiez que votre fournisseur les analyse réellement. Si vous suivez les annonces Shopping pour l’e-commerce, confirmez que les champs Shopping structurés existent. Ne supposez pas que « JSON structuré » signifie couverture complète.
Coût réel à grande échelle : comparaison du prix par requête
Les prix affichés sur les sites web ne racontent pas toute l’histoire. J’ai tout normalisé en coût pour 1 000 requêtes réussies sur trois niveaux de volume.
| Fournisseur | Coût pour 1K requêtes | Coût pour 10K requêtes | Coût pour 100K requêtes | Paiement à l’usage ? | Offre gratuite |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ~0,80–3,20 USD | ~8–32 USD | ~80–320 USD | Pack de crédits | Crédits gratuits |
| Thunderbit (Extract) | ~16–64 USD | ~160–640 USD | ~1 600–6 400 USD | Pack de crédits | Crédits gratuits |
| SerpApi | 25 USD (Starter) | ~87 USD (Popular) | ~550 USD (Big Data) | Non (abonnement) | 250/mois |
| Serper | ~1 USD | ~10 USD | ~75–100 USD | Oui | 2 500 requêtes |
| Scrapingdog | ~1 USD | ~10 USD ou moins | Peut descendre bien en dessous de 10 USD | Offre / crédits | 1 000 crédits |
| DataForSEO | ~0,60–2 USD | ~6–20 USD | ~60–200 USD | Oui | Crédits d’essai |
| Bright Data | ~0,50–5 USD+ | Selon devis | Meilleur en volume enterprise | Oui / offre | Crédits d’essai (5 USD) |
| ScraperAPI | Dépend des crédits | Dépend des crédits | Dépend des crédits | Offre / crédits | 5 000 crédits d’essai |
| Apify | ~3 USD (petite échelle) | Dépend de l’actor | Dépend de l’actor | Crédits plateforme | Crédits gratuits mensuels |
Coûts cachés à surveiller :
- La possible facturation de 2 crédits chez Serper pour plus de 10 résultats par requête.
- Les différences de prix de DataForSEO entre les modes standard et live / haute priorité.
- Les multiplicateurs de crédits de ScraperAPI pour SERP par rapport au scraping simple.
- Les engagements minimums enterprise de Bright Data.
Rapport qualité-prix par niveau :
- Projets secondaires (50 USD/mois) : Serper ou Scrapingdog pour du JSON SERP Google fixe.
- Équipes en croissance (10K–50K requêtes/mois) : Serper, Scrapingdog ou DataForSEO selon la profondeur de parsing.
- Entreprise (100K+ requêtes/mois) : DataForSEO, Bright Data ou SerpApi Big Data.
- Extraction orientée IA : Thunderbit, parce que le schéma correspond aux attentes de votre agent en aval sans post-traitement.
Meilleure SERP API pour les agents IA et les workflows LLM en 2026
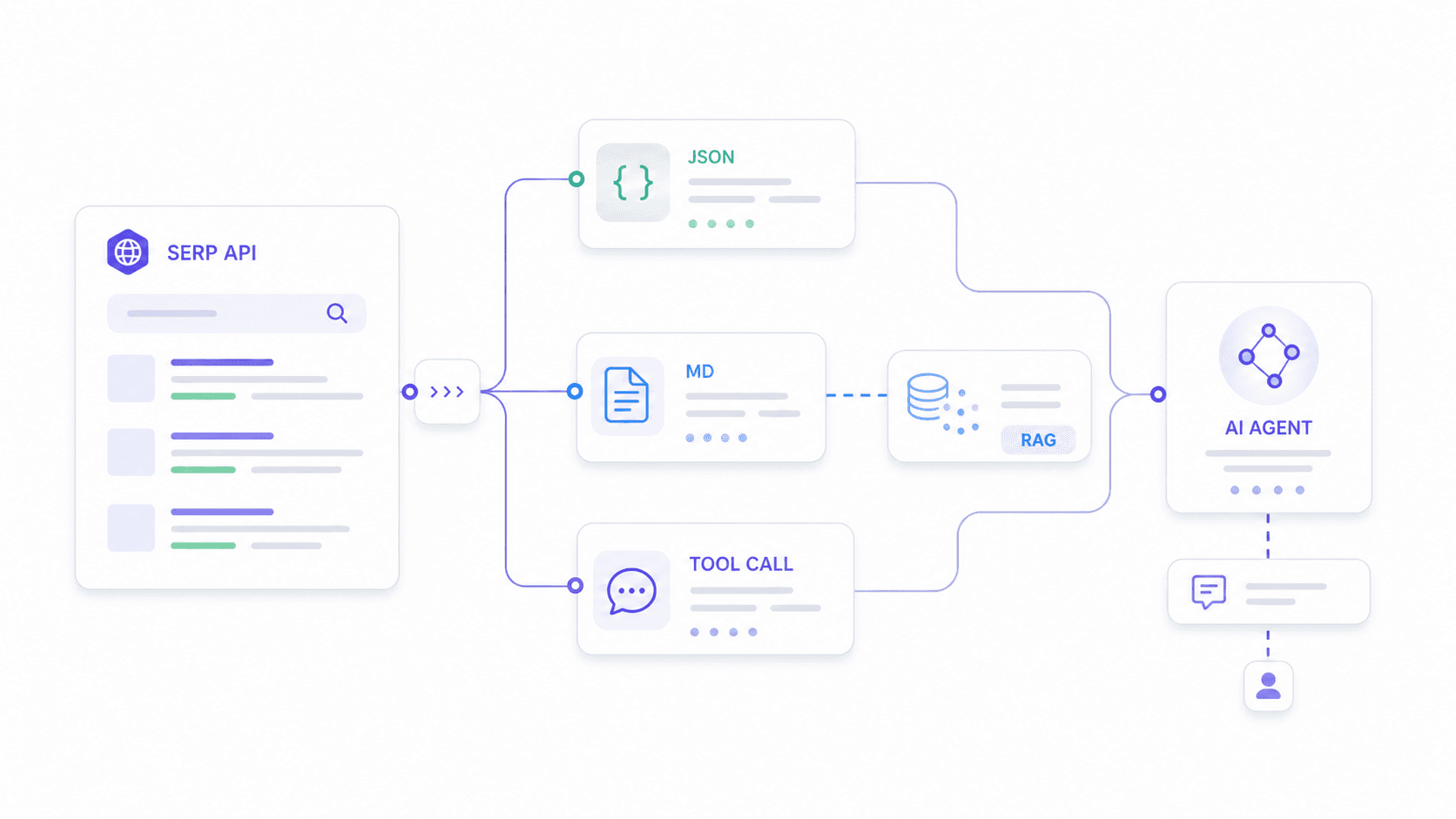
C’est le cas d’usage que personne d’autre ne couvre vraiment bien. J’ai trouvé au moins trois où des utilisateurs expliquent avoir essayé d’intégrer des SERP API à des workflows n8n et à des agents IA, l’un d’eux disant explicitement qu’il n’avait « pas encore réussi à le faire fonctionner correctement avec un agent IA ».
Les agents IA ont besoin de choses différentes de celles des tableaux de bord de suivi de position. Ils ont besoin de :
- JSON à schéma stable qui ne casse pas leur logique de parsing lorsque le fournisseur modifie son format de sortie.
- Champs de sortie personnalisés correspondant à ce qu’attend le modèle en aval — pas un export générique de tout.
- Markdown ou texte propre pour les pipelines d’embedding RAG.
- Une latence suffisamment faible pour l’appel d’outils en temps réel.
Comment chaque fournisseur s’intègre dans une pile d’agents IA
| Fournisseur | Adéquation aux agents IA | Pourquoi |
|---|---|---|
| Thunderbit | Excellente | Schéma JSON personnalisé (Extract API) + Markdown pour RAG (Distill API). Le plus flexible pour l’extraction spécifique aux agents. |
| Serper | Très bonne | JSON rapide et propre, populaire dans les communautés n8n / LangChain. Simple et peu coûteux pour les appels de recherche basiques. |
| SerpApi | Bonne | Schéma stable, excellente documentation. Fonctionne bien quand les agents ont besoin des verticales Google (Maps, Scholar, Shopping). |
| DataForSEO | Bonne | Le meilleur choix quand l’agent fait partie d’un pipeline de données SEO plus large. |
| Scrapingdog | Bonne | Rapide et peu coûteux ; schéma stable pour la SERP Google. |
| Bright Data | Bonne | Collecte de données fraîches à l’échelle enterprise, sur plusieurs moteurs et régions. |
| ScraperAPI | Modérée | Mieux quand l’agent a aussi besoin d’un crawling web généraliste. |
| Apify | Modérée à bonne | Flexible mais plus lent ; mieux pour les workflows batch planifiés. |
Exemple pratique avec Thunderbit : imaginez que votre agent IA doive analyser l’intention de recherche pour « meilleur CRM pour l’immobilier ». Vous définissez un schéma demandant les résultats organiques (titre, URL, extrait, position), les questions People Also Ask avec des résumés de réponses, et une classification de l’intention commerciale. L’Extract API de Thunderbit renvoie exactement cette structure — ni plus, ni moins. Votre agent ne gaspille pas de jetons à analyser des champs inutiles ou à nettoyer des artefacts HTML.
Pour les pipelines RAG, le Distill API de Thunderbit transforme la page SERP en Markdown propre, prêt à être vectorisé. La plupart des SERP API dédiées renvoient des schémas JSON fixes ; l’approche de Thunderbit permet aux développeurs d’adapter la sortie à ce qu’attend leur modèle en aval.
Matrice de décision par cas d’usage : si vous avez X, utilisez Y
Les utilisateurs sur les forums demandent sans cesse des recommandations précises, alignées sur leurs vrais workflows — pas des conseils génériques du type « ça dépend ». J’ai donc construit ceci.
| Votre cas d’usage | Meilleur choix | Second choix | Pourquoi |
|---|---|---|---|
| Suivi de position SEO (grand volume) | DataForSEO | Scrapingdog | Endpoints natifs SEO, tarification de masse, parsing complet |
| Google Maps / données d’entreprises locales | SerpApi | Bright Data | Endpoint Maps mature ; Bright Data convient au scraping local à l’échelle enterprise |
| Agent IA / automatisation n8n | Thunderbit | Serper | Schéma personnalisé + Markdown pour RAG ; Serper est rapide et peu coûteux pour les appels simples |
| MVP / projet secondaire à budget limité (<50 USD/mois) | Serper | Scrapingdog | Offres gratuites généreuses, paiement à l’usage, configuration minimale |
| Multi-moteur (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | Thunderbit fonctionne sur n’importe quel moteur via l’extraction IA ; DataForSEO propose des endpoints multi-moteurs |
| Agrégation d’avis Google | SerpApi | DataForSEO | Endpoints dédiés au parsing des avis |
| E-commerce / suivi Shopping | SerpApi | DataForSEO | Forte couverture Google Shopping et champs structurés |
| Workflows de scraping personnalisés | Apify | ScraperAPI | Flexibilité des actors ; ScraperAPI est simple pour le scraping général + SERP |
Guide rapide par profil :
- Équipe SEO : commencez par DataForSEO si vous construisez des tableaux de bord ; utilisez SerpApi si la couverture des verticales Google et la documentation comptent plus que le prix.
- Équipe commerciale : utilisez Thunderbit quand le workflow couvre SERP, pages d’annuaires et enrichissement ; utilisez Serper pour des requêtes simples de découverte de prospects.
- Développeur d’outils IA : Thunderbit pour les schémas personnalisés / RAG, Serper pour une recherche rapide et peu coûteuse, SerpApi pour des verticales Google robustes.
- Entrepreneur solo : commencez avec les offres gratuites de Serper, Scrapingdog, SerpApi et Thunderbit. Exécutez les mêmes 20 requêtes proches de la production avant de vous engager.
Limites de débit, fiabilité et aptitude à la production comparées
J’aurais aimé avoir cette section quand j’évaluais pour la première fois des fournisseurs pour des workflows de production. Les équipes qui montent à des milliers de requêtes par jour ont besoin de limites de débit prévisibles, de retries automatiques et de garanties de disponibilité — et aucun autre article comparatif ne les couvre systématiquement.
| Fournisseur | Limite de débit | Requêtes simultanées | Retry en cas d’échec | SLA / disponibilité |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | Intégré (anti-bot, CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | Intégré | — |
| Thunderbit Enterprise | 1 000 req/min | 50 | Intégré | Conditions personnalisées |
| SerpApi | Selon l’offre (recherches/heure) | Selon l’offre | Le fournisseur gère proxys/CAPTCHA | SLA 99,95 % |
| Serper | Selon le compte / l’offre | Peu publié publiquement | Retry manuel côté client recommandé | Pas de SLA public |
| Scrapingdog | Selon l’offre | Vérifiez les conditions de l’offre | Anti-blocage géré | Pas toujours public |
| DataForSEO | Documenté par endpoint / mode | Varie selon le mode | L’asynchrone prend en charge le polling / retry | Support enterprise |
| Bright Data | Documenté, montée progressive | À l’échelle enterprise | Déblocage intégré | SLA enterprise |
| ScraperAPI | Concurrence selon l’offre | Dépend des crédits | Gère retries / proxys | Options de support payant |
| Apify | Dépend de l’actor / de la mémoire / du calcul | Limites de la plateforme | Configuration au niveau de l’actor | Fiabilité de la plateforme |
Checklist de production avant de vous engager :
- Demandez si le fournisseur facture les requêtes échouées ou bloquées.
- Confirmez exactement la concurrence, le nombre de requêtes par minute et le comportement en rafale.
- Vérifiez si le géociblage, le mobile vs desktop et le rendu JS modifient la consommation de crédits.
- Conservez des réponses JSON d’exemple pour 20 à 50 requêtes réelles et comparez les noms de champs sur plusieurs jours pour vérifier la stabilité du schéma.
- Ajoutez des retries côté client et des budgets de timeout si les données SERP sont critiques pour votre activité.
Résumé rapide : comparaison des 8 SERP API
| Fournisseur | Vitesse moyenne | Coût par 1K | Offre gratuite | Couverture de parsing | Adéquation IA | Multi-moteur | Verdict |
|---|---|---|---|---|---|---|---|
| Thunderbit | Moyenne (extraction IA) | Faible (Distill) à premium (Extract) | Oui | Personnalisée (toute fonctionnalité) | Excellente | Excellente | Le meilleur pour une extraction SERP et un RAG personnalisés, nativement orientés IA |
| SerpApi | ~5,5 s | Premium | 250/mois | Excellente (fixe) | Bonne | Large couverture des verticales Google | La meilleure couverture Google mature |
| Serper | ~2–3 s | Très faible | 2 500 requêtes | Bonne | Très bonne | Principalement Google | La meilleure API rapide et bon marché pour les IA / MVP |
| Scrapingdog | ~1,25 s | Très faible à grande échelle | 1 000 crédits | Bonne | Bonne | Vérifier les moteurs | Le meilleur combo vitesse / coût |
| DataForSEO | Moyen à lent (standard) | Faible à modéré | Crédits d’essai | Excellente | Bonne | Excellente | La meilleure infrastructure pour une plateforme SEO |
| Bright Data | ~2–5,5 s | Enterprise | Essai (5 USD) | Bonne (selon le produit) | Bonne | Excellente | La meilleure collecte à l’échelle enterprise |
| ScraperAPI | ~33 s | Dépend des crédits | 5 000 crédits d’essai | Modérée | Modérée | Endpoints Google | Le meilleur choix si la SERP n’est qu’une partie d’un scraping plus large |
| Apify | ~8 s | Dépend de l’actor | Crédits mensuels | Dépend de l’actor | Modérée à bonne | Dépend de l’actor | Le meilleur pour les workflows d’automatisation personnalisés |
Comment Thunderbit s’intègre dans votre workflow SERP
Un peu de contexte sur la manière dont notre équipe a conçu l’API de Thunderbit. Le modèle SERP API traditionnel — endpoints fixes, champs de sortie prédéfinis, Google uniquement — fonctionne bien pour un suivi de position simple. Mais dès que vous avez besoin de quelque chose d’un peu différent (réponses PAA avec sentiment, résultats du pack local avec nombre d’avis, ou données Shopping formatées pour un schéma de base de données précis), vous devez soit faire du post-traitement, soit changer de fournisseur.
L’Extract API de Thunderbit inverse ce modèle. Vous indiquez ce que vous voulez via un schéma JSON, et l’IA détermine comment l’obtenir à partir de la page de recherche que vous lui donnez. Google aujourd’hui, Bing demain, un moteur de recherche vertical de niche la semaine prochaine — même API, même approche.
Le Distill API résout un autre problème : transformer des pages SERP désordonnées en Markdown propre, que les LLM peuvent réellement consommer sans s’étrangler sur les artefacts HTML, les éléments de navigation et les scripts de suivi. Si vous construisez un pipeline RAG qui a besoin de preuves de recherche fraîches, c’est le chemin le plus rapide de la « SERP en direct » au « contenu embarqué ».
Les deux endpoints incluent la gestion anti-bot, la résolution de CAPTCHA et le rendu JS d’origine. Vous ne payez pas plus pour cela — c’est inclus dans le coût en crédits.
Essayez-le vous-même : pour l’extraction dans le navigateur, ou utilisez l’API directement pour des workflows programmatiques. Notre propose des tutoriels si vous voulez le voir en action avant d’écrire du code.
Note sur la légalité
La question revient dans toutes les FAQ, alors voici la version courte : la légalité du scraping SERP dépend des faits et de la juridiction. L’affaire a établi que le scraping de données publiquement accessibles n’est pas nécessairement un crime informatique, mais cela ne donne pas une autorisation générale. Google au sujet du scraping SERP, ce qui montre qu’il existe une pression commerciale active autour de l’accès.
Conseil pratique : utilisez les API des fournisseurs conformément à leurs conditions, évitez de collecter des données personnelles sauf si c’est nécessaire, et demandez aux fournisseurs comment ils gèrent la conformité. Ne partez pas du principe que le scraping SERP est sans risque.
Conclusion
Aucun fournisseur ne gagne sur toutes les dimensions — le bon choix dépend de votre cas d’usage, de votre budget et de votre stack technique. Après avoir normalisé les tarifs, testé la vitesse, cartographié la couverture de parsing et évalué l’aptitude aux agents IA, voici mon cadre de décision :
- Besoin de flexibilité + compatibilité avec les agents IA ? → Thunderbit
- Besoin d’une large couverture des produits Google ? → SerpApi
- Besoin de vitesse + du coût le plus bas ? → Serper ou Scrapingdog
- Vous construisez une plateforme SEO ? → DataForSEO
- Besoin d’une échelle enterprise avec SLA ? → Bright Data ou DataForSEO
- Scraping général + SERP occasionnelle ? → ScraperAPI ou Apify
Commencez par les offres gratuites. Lancez 20 à 50 vraies requêtes correspondant à votre charge de travail de production. Comparez les réponses JSON. Vérifiez le coût réel après crédits et multiplicateurs. Puis engagez-vous.
Les prix changent souvent sur ce marché — cette comparaison a été normalisée à partir des pages publiques disponibles en mai 2026. Si vous lisez ceci plusieurs mois plus tard, revérifiez avant d’acheter.
Pour en savoir plus sur les approches de et leur comparaison avec les méthodes traditionnelles, nous avons beaucoup écrit sur le sujet. Et si vous évaluez le , l’extension Chrome de Thunderbit gère aussi cet aspect-là.
FAQ
1. Qu’est-ce qu’une SERP API et qui en a besoin ?
Une SERP API est un service qui envoie des requêtes de recherche à des moteurs comme Google, Bing ou Yandex et renvoie les résultats sous forme de données structurées (généralement du JSON). Les professionnels du SEO l’utilisent pour le suivi de position, les équipes commerciales pour la découverte de prospects, les équipes e-commerce pour la surveillance des prix et les développeurs IA pour alimenter des agents et des pipelines RAG avec des données de recherche en temps réel.
2. Combien coûte le scraping de 1 000 résultats de recherche Google via une API ?
Le coût varie fortement — d’environ 0,60 USD par 1K (DataForSEO au niveau standard) à environ 25 USD par 1K (offre Starter de SerpApi). Les remises de volume changent énormément d’un fournisseur à l’autre. Normalisez toujours en coût pour 1 000 requêtes réussies plutôt que de comparer les tarifs affichés.
3. Puis-je utiliser une SERP API avec des agents IA comme LangChain ou n8n ?
Oui. Serper est populaire dans la communauté n8n pour les appels de recherche simples. Thunderbit est le plus fort lorsque votre agent a besoin de schémas JSON personnalisés ou de Markdown pour le RAG. SerpApi fonctionne bien pour les agents qui ont besoin de données Google verticales stables (Maps, Scholar, Shopping).
4. Quelle SERP API a la meilleure offre gratuite pour tester ?
Serper offre 2 500 requêtes gratuites à l’inscription — la plus généreuse en volume pur. SerpApi donne 250/mois, Scrapingdog offre 1 000 crédits, ScraperAPI fournit 5 000 crédits d’essai (7 jours) et Thunderbit inclut des crédits gratuits pour le prototypage. Apify dispose de crédits de plateforme mensuels d’une valeur d’environ 5 USD.
5. Quelles fonctionnalités SERP dois-je vérifier avant d’acheter ?
Ne supposez pas que « JSON structuré » signifie couverture complète. Vérifiez si l’API renvoie des champs structurés pour : People Also Ask, Knowledge Panel, Local Pack / Maps, résultats Shopping, Featured Snippets, annonces (haut et bas), Image Pack et résultats vidéo. Utilisez la matrice de parsing de cet article comme liste de contrôle de départ, et testez avec de vraies requêtes avant de souscrire à une offre.
En savoir plus