Rekisteröidyt ScraperAPI:hin, näet Hobby-paketissasi “100,000 credits” ja alat scrapeta. Kolme päivää myöhemmin hallintapaneelissa näkyy, että 80 % krediiteistä on jo palanut — ja olet ehkä saanut talteen vain noin 6,000 sivua. Mitä ihmettä tapahtui? Syy löytyy krediittikerroinjärjestelmästä, ja se on yksittäisen tärkeä asia ScraperAPI:ssa, jota melkein mikään arvostelu ei oikeasti avaa. Olen käyttänyt viikkoja ScraperAPI:n dokumentaation penkomiseen, kerännyt oikeaa hinnoitteludataa viideltä kilpailijalta ja lukenut läpi jokaisen Reddit-ketjun sekä Capterra-arvostelun, jonka löysin. Tämä scraper api arvostelu on juuri sellainen, jonka olisin itse halunnut lukea, kun tiimimme alkoi ensimmäisen kerran arvioida scraping-rajapintoja. Käyn läpi krediittien todellisen matematiikan, näytän missä ScraperAPI toimii hyvin (ja missä se kosahtaa täysin), kokoan yhteen mitä oikeat käyttäjät sanovat G2:ssa, Capterrassa ja Redditissä — ja rehellisesti sanottuna autan sinua myös pohtimaan, tarvitsetko scraping-API:a lainkaan.
Mikä ScraperAPI on ja kenelle se on tehty?
ScraperAPI on web scraping -rajapinta, joka hoitaa ison mittakaavan scrapauksen hankalan taustainfrastruktuurin: proxyjen kierrätyksen välillä, automaattisen CAPTCHA-ratkaisun, JavaScript-renderöinnin ja automaattiset uudelleenyritykset. Lähetät sille URL-osoitteen yksinkertaisella API-kutsulla, ja se palauttaa HTML:n (tai rakenteistetun JSONin, jos käytät heidän structured data -päätepisteitään). Yrityksen perusti vuonna 2018 Daniel Ni, sen pääkonttori on Las Vegasissa, ja se palvelee nykyään mukaan lukien Deloitte, Sony ja Alibaba — käsitellen .
Ensisijainen kohderyhmä on kehittäjätiimit ja tekniset operatiiviset tiimit, jotka rakentavat omia scraping-putkia. Jos et kirjoita koodia, ScraperAPI ei ole sinua varten (palaamme tähän myöhemmin).
Ydintoiminnot: proxyjen kierrätys, JavaScript-renderöinti, geotargetointi, suosittujen sivustojen structured data -päätepisteet ja epäonnistuneiden pyyntöjen automaattiset uusintayritykset.
Mutta tässä on se, minkä useimmat arvostelut jättävät väliin: ScraperAPI:n hinnoittelusivulla näkyvät krediittimäärät ovat aika harhaanjohtavia, jos et ymmärrä, miten kertoimet toimivat. Aloitetaan siitä.
Miten ScraperAPI:n krediittijärjestelmä oikeasti toimii (se osa, jonka useimmat arvostelut jättävät väliin)
ScraperAPI laskuttaa krediittijärjestelmällä. Perusajatus on simppeli: 1 API-pyyntö = 1 krediitti. Mutta käytännössä näin ei melkein koskaan ole. Todellinen krediittikustannus riippuu kahdesta asiasta: scrapattavasta domainista ja käytössä olevista feature-lipuista. Ja nämä kulut kasaantuvat tavalla, joka ei ole lainkaan intuitiivinen.
Krediittikerrointaulukko, jonka jokaisen käyttäjän pitäisi nähdä ennen rekisteröitymistä

Jo ennen kuin otat käyttöön yhtäkään parametria, scrapattavan sivuston tyyppi määrittää peruskulun krediiteissä:
| Domain-kategoria | Peruskrediitit per pyyntö | Esimerkkejä |
|---|---|---|
| Tavalliset sivustot | 1 | Blogit, uutissivustot, yksinkertainen HTML |
| Verkkokaupat | 5 | Amazon, eBay, Walmart |
| SERP (hakukoneet) | 25 | Google, Bing |
| Sosiaalinen media | 30 |
Tämän päälle feature-liput lisäävät omat krediittinsä:
| Parametri | Lisäkrediitit | Huomioita |
|---|---|---|
render=true (JS-renderöinti) | +10 | Kaikki paketit |
screenshot=true | +10 | Kaikki paketit |
premium=true (premium-proxy) | +10 | Kaikki paketit |
ultra_premium=true | +30 | Vain maksulliset paketit |
| Anti-bot-bypass (Cloudflare, DataDome, PerimeterX) | +10 / kpl | Tunnistetaan automaattisesti — et valitse tätä itse |
premium=true + render=true yhdessä | +25 | EI +20 |
ultra_premium=true + render=true yhdessä | +75 | EI +40 |
Tuo viimeinen rivi on se varsinainen koukku. Ominaisuuksien yhdistäminen maksaa ENEMMÄN kuin yksittäisten kustannusten summa. Premium-proxy (+10) ja JavaScript-renderöinti (+10) pitäisi loogisesti maksaa +20 lisäkrediittiä, mutta ScraperAPI veloittaa . Ultra-premium (+30) ja JavaScript-renderöinti (+10) pitäisi maksaa +40, mutta todellisuudessa hinta on — melkein kaksinkertainen. Tätä epälineaarista kasautumista ei dokumentoida näkyvästi, ja se on tärkein syy siihen, miksi käyttäjät kokevat krediittien hupenevan odotettua nopeammin.
Parametrit, jotka eivät maksa lisäkrediittejä: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Mitä kukin paketti oikeasti tarjoaa: Free-paketista Enterpriseen
Tässä ovat ScraperAPI:n :
| Paketti | Kuukausihinta | Vuosihinta (kk) | API-krediitit | Samanaikaiset säikeet | Geotargetointi |
|---|---|---|---|---|---|
| Free | $0 | — | 1,000 | 5 | Ei |
| Hobby | $49 | $44 | 100,000 | 20 | Vain Yhdysvallat ja EU |
| Startup | $149 | $134 | 1,000,000 | 50 | Vain Yhdysvallat ja EU |
| Business | $299 | $269 | 3,000,000 | 100 | Maakohtainen (50+ maata) |
| Scaling | $475 | $427 | 5,000,000 | 200 | Maakohtainen |
| Enterprise | Räätälöity | Räätälöity | 5,000,000+ | 200+ | Maakohtainen |
Ja tässä on todellinen hinta per 1,000 pyyntöä eri tasoilla, kertoimet huomioituna:
| Paketti | Perus (1×) | JS-renderöinti (10×) | Verkkokauppa (5×) | SERP (25×) | Ultra-premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
$49/kuukausi -paketti, jota mainostetaan “100,000 credits” -pakettina, tuottaa vain 1,333 oikeaa pyyntöä, kun scrapataan suojattuja sivustoja ultra-premiumin ja JavaScript-renderöinnin yhdistelmällä. Se tekee — kalliimpaa kuin monet täysin hallinnoidut scraping-palvelut.
Miksi krediitit hupenevat nopeammin kuin odotat
Kolme asiaa yllättää käyttäjät toistuvasti.
Ensinnäkin: domain-pohjainen hinnoittelu on automaattista. Et valitse erikseen 5× Amazon-kerrointa tai 25× Google-kerrointa. Se lisätään heti, kun ScraperAPI tunnistaa domainin. Sama pätee anti-bot-bypass-krediitteihin (+10 Cloudflarelle, DataDomelle, PerimeterX:lle) — nämä lisätään automaattisesti, kun ne havaitaan.
Toiseksi: krediitit EIVÄT siirry seuraavalle kaudelle. Käyttämättömät krediitit . Niitä ei kerry talteen.
Ja kolmanneksi — tämä kirpaisee — Pay-As-You-Go on käytettävissä vain Scaling-paketista ($475/kk) ylöspäin. Jos olet Hobby-, Startup- tai Business-paketissa ja krediitit loppuvat kesken kauden, sinut katkaistaan yksinkertaisesti pois seuraavaan laskutusjaksoon asti. Ainoa vaihtoehtosi on päivittää seuraavalle tasolle.
Yksi Reddit-käyttäjä kertoi saaneensa tarjouksen 60 miljoonasta krediitistä hintaan $3,600, olettaen että Amazon-pyyntö maksaa 1 krediitin, mutta maksun jälkeen ilman ennakkovaroitusta sovellettiin 5-kertaista kerrointa. Heidän 60M-pakettinsa vastasi käytännössä vain 12M pyyntöä — eli verrattuna odotuksiin.
DataPipeline-krediittiloukku
ScraperAPI:n no-code DataPipeline -ominaisuus (aikataulutettu scraping webhook-toimituksella) käyttää erillistä, huomattavasti kalliimpaa krediittitaulukkoa. Tavallinen peruspyyntö maksaa standardi-API:ssa:
| Pyyntötyyppi | Standardi API | DataPipeline | Suhde |
|---|---|---|---|
| Perusnormaali pyyntö | 1 | 6 | 6× |
| Perus verkkokauppa | 5 | 10 | 2× |
| Perus SERP | 25 | 30 | 1.2× |
| Ultra-premium + JS (normaali) | 75 | 80 | 1.07× |
Käyttäjät, jotka rakentavat no-code-putkia odottaen standardia krediittikuluja, huomaavat polttavansa 6× enemmän krediittejä peruspyynnöissä. Tämä on kyllä dokumentoitu, mutta tiedon löytämiseksi täytyy oikeasti kaivaa.
Todellinen hinta per pyyntö: ScraperAPI vs. kilpailijat
Listahinta on merkityksetön, jos kertoimia ei huomioida. Keräsin ajantasaisen hinnoittelun viideltä toimijalta ja vertasin niitä noin $300/kk -tasolla kolmessa yleisessä käyttötapauksessa.
Perus HTML-scrape (ei JS:ää, ei premium-proxya)
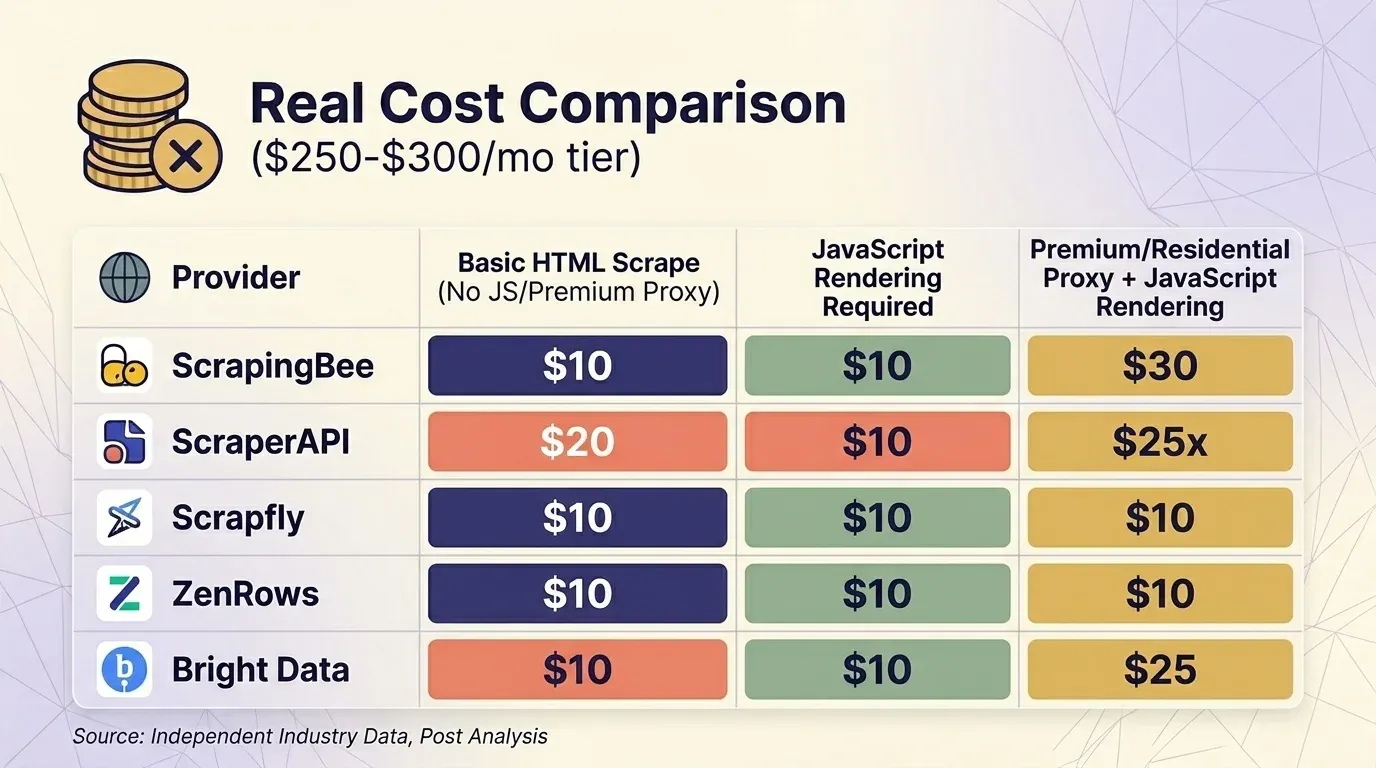
| Palvelu | Paketti | Krediittejä per pyyntö | Oikeita pyyntöjä | Hinta / 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200,000 | $1.50 |
JavaScript-renderöinti tarvitaan
| Palvelu | Paketti | Krediittejä per pyyntö | Oikeita pyyntöjä | Hinta / 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (oletuksena päällä) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | PAYG | kiinteä | ~200,000 | $1.50 |
Premium-/residential-proxy + JavaScript-renderöinti (suojatut sivustot)
| Palvelu | Paketti | Krediittejä per pyyntö | Oikeita pyyntöjä | Hinta / 1K |
|---|---|---|---|---|
| Bright Data | PAYG | kiinteä | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
Bright Datan Web Unlocker on ainoa palvelu, joka — kaikki pyynnöt maksavat saman kiinteän hinnan. Noin $300-tasolla ScrapingBee ja ScraperAPI ovat kilpailukykyisiä suojattujen sivustojen scrapauksessa, kun taas ZenRows on kallein.
Yksi tärkeä huomio käyttäytymisestä: ScrapingBee 5× kustannuksella. Jos vertaat ScrapingBee:tä ja ScraperAPI:a suoraan, varmista, että vertaat samoja renderöintiasetuksia.
Scrape.do:n riippumaton analyysi löysi, että ScraperAPI:n keskimääräinen hinta on — “enemmän kuin mikään muu testattu palvelu” — ja keskimääräinen vasteaika on , mikä tekee siitä “yhden hitaimmista saatavilla olevista palveluista.” Tämä on hyvä tietää ennen sitoutumista.
Sivustokohtaiset onnistumisprosentit: missä ScraperAPI loistaa ja missä se takkuilee
Yksikään scraping-API ei toimi yhtä hyvin kaikilla sivustoilla. Scrapewayn (huhtikuu 2026) riippumattomat vertailut kertovat aika kaksijakoisen tarinan.
Suorituskyky sivustokategorian mukaan
| Kohdesivusto | Onnistumisaste | Keskinopeus | Hinta / 1K (Business-paketti) |
|---|---|---|---|
| Zillow | 100% | 10.5 s | $0.49 |
| Etsy | 99% | 4.8 s | $4.90 |
| Amazon | 98% | 6.5 s | $2.45 |
| 95% | 17.8 s | $14.70 | |
| Walmart | 93% | 11.4 s | $2.45 |
| Indeed | 90% | 15.8 s | $4.90 |
| StockX | 84% | 3.9 s | $4.90 |
| Realtor.com | 12% | 11.8 s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Keskimääräinen onnistumisaste: , hieman yli alan keskiarvon 58.2–59.5 %. Keskimääräinen vasteaika: 5.2–7.3 sekuntia, mikä on parempi kuin alan 9.8 sekunnin keskiarvo.
Missä ScraperAPI toimii hyvin
ScraperAPI on aidosti vahva verkkokaupoissa (Amazon, Walmart, Etsy) ja asuntomarkkinassa (Zillow). Näiden sivustojen structured data -päätepisteet palauttavat parsittua JSONia erittäin luotettavasti. Jos pääkäyttötapauksesi on Amazon-tuotesivujen tai Google SERPien scrapetus, ScraperAPI on järkevä valinta.
Missä ScraperAPI jää jälkeen
Sosiaalinen media on kuollut alue. Instagram, Twitter/X ja Booking.com näyttävät kaikki 0 % onnistumisasteen riippumattomissa testeissä. LinkedIn toimii 95 %:n tasolla, mutta 30 krediitin hinta per pyyntö on kova.
Kirjautumista vaativat sivustot on nimenomaisesti rajattu pois. ScraperAPI tukee session säilyttämistä session_number-parametrilla, mutta se . Se ei pysty käsittelemään lomakkeiden täyttöä, kaksivaiheista tunnistautumista tai monimutkaisia kirjautumisprosesseja.
Vanhentunutta dataa suojatuilla kohteilla. ScraperAPI käyttää , eli jos keräät aikakriittistä dataa (hinnat, varastosaldot), saatat saada jopa 10 minuuttia vanhaa tietoa.
Proxywayn vuoden 2025 benchmarkissa ScraperAPI:lla oli : 81.72 %.
Sivustokategorian suorituskyvyn yhteenveto
| Sivustokategoria | ScraperAPI:n suorituskyky | Tiedossa olevat ongelmat | Mahdollinen vaihtoehto |
|---|---|---|---|
| Amazon / verkkokauppa | ✅ Vahva (SDP-päätepisteet) | Korkea krediittikulu skaalassa | Thunderbit templates (1 klikkaus, ei krediittejä per rivi templateille) |
| Google SERP | ✅ Vahva | Geotargetointi maksaa erikseen; yhdessä benchmarkissa heikoin Google-tulos | — |
| Asuntomarkkina (Zillow) | ✅ Erinomainen (100%) | — | — |
| Instagram / sosiaalinen media | ❌ 0 % onnistuminen | Täydellinen epäonnistuminen | Playwright + proxyt (itse rakennettu) |
| JS-painotteiset SPA-sovellukset | ⚠️ Kohtalainen | Vaatii 10× krediittikustannuksen headless-renderöinnistä | Scrapfly, ZenRows |
| Sivustot, jotka vaativat kirjautumisen | ❌ Kielletty käyttöehdoissa | Ei session/autentikointitukea | Thunderbit browser scraping (käyttää omaa kirjautumissessiotasi) |
| Booking.com / matkailu | ❌ 0 % onnistuminen | Täydellinen epäonnistuminen | Bright Data |
Mitä oikeat käyttäjät sanovat: yhteenveto G2-, Capterra- ja Reddit-palautteesta
Keräsin palautetta kolmelta alustalta. Tässä nykyiset arviot:
| Alusta | Arvio | Arvostelut |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterran ala-arviot: Käytön helppous 4.9/5, Asiakaspalvelu 4.6/5, Ominaisuudet 4.5/5, Vastinetta rahalle 4.5/5.
Teemakohtainen yhteenveto palautteesta
| Teema | Positiiviset signaalit | Negatiiviset signaalit |
|---|---|---|
| Käyttöönoton helppous / dokumentaatio | "Super easy to set up. You can start scraping in minutes." — Latenode community; Capterra Ease of Use 4.9/5 | — |
| Hinnoittelun läpinäkyvyys | "Affordable entry tier" (useita Capterra-arvosteluja) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (helmi 2025); "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (syys 2022) |
| Luotettavuus | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) |
| Asiakastuki | "Responsive team" (Capterra) | Käyttäjä kertoi saaneensa ensin yhden hinnan, mutta laskutuksen menneen 5× hinnalla ilman ennakkovaroitusta (Reddit) |
| Arvo ajan myötä | Laskuttaa vain onnistuneista (200/404) pyynnöistä | "If you're running large-scale operations, the expenses can add up quickly" ja oman infrastruktuurin rakentaminen on "more cost-effective in the long run" — mikezhang, Latenode |
Johtopäätös: ScraperAPI:tä pidetään yleisesti helppona ottaa käyttöön, ja se toimii luotettavasti suosituilla, hyvin tuetuilla kohteilla. Kritiikki keskittyy hinnoittelun yllätyksiin (kertoimet, odottamattomat korotukset) sekä vaikeampien kohteiden luotettavuuteen.
ScraperAPI:n structured data -päätepisteet: ovatko ne premium-krediittien arvoisia?
ScraperAPI tarjoaa viidellä alustalla, ja ne palauttavat parsitun JSONin raakan HTML:n sijaan:
- Amazon (3 päätepistettä): Tuotetiedot ASINin perusteella, hakutulokset, kilpailija-offerit. Palauttaa yli 18 kenttää, mukaan lukien hinnat, arviot, kuvaukset, arvostelut, BSR, kuvat ja myyjätiedot. Tukee .
- Google (5 päätepistettä): (orgaaniset tulokset, knowledge graph, videot, related questions, sivutus), Shopping, Maps, News, Jobs.
- Walmart (4 päätepistettä): Tuote, Haku, Kategoria, Arvostelut.
- eBay (2 päätepistettä): Tuote, Haku.
- Redfin (4 päätepistettä): Haku, agenttitiedot, vuokra-asunnot, myynnissä olevat kohteet.
SDE:t ovat saatavilla kaikissa paketeissa, myös Free-paketissa. ScraperAPI väittää tuetuille SDE-domainille — vaikka riippumattomat benchmarkit maalaavat hieman monisyisemmän kuvan sivustosta riippuen.
Datan kattavuus
Amazon SDP on ScraperAPI:n vahvin tuote. Se palauttaa laajan kenttäjoukon: hinta, arvostelut, BSR, variantit, kuvat, myyjätiedot ja paljon muuta. Google SERP SDP palauttaa orgaaniset tulokset, mainokset, featured snippetit ja People Also Ask -osion. Datan kattavuus on näillä kahdella alustalla aidosti hyvä.
Krediittitehokkuus: SDP vs. oma parsinta
Business-paketissa ($299/kk, 3M krediittiä) 10,000 Amazon-tuotteen scrapetus SDE:n kautta maksaa 50,000 krediittiä (5 krediittiä per tuote) — noin $5 arvosta pakettia. Oman parserin rakentaminen tavallisella pyynnöllä (1 krediitti per tuote) maksaisi vain 10,000 krediittiä, mutta käyttäisit kehittäjän aikaa parserin rakentamiseen ja ylläpitoon.
Pienille tiimeille ilman kehittäjiä SDE:t säästävät oikeasti aikaa.
Tiimeille, joilla on kehityskykyä ja jotka scrapettavat suuressa mittakaavassa, 5× krediittipreemio on vaikea perustella.
Miten SDP:t vertautuvat no-code scraper -templateihin
Tämä vertailu merkitsee enemmän kuin useimmat arvostelut antavat ymmärtää. tarjoaa valmiita scraper-templateja Amazonille, Shopifylle, Zillowille ja , eikä niiden käyttö vaadi koodia eikä templateen kuuluvaa per-rivi-krediittikustannusta.
| Tekijä | ScraperAPI SDP (Amazon) | Thunderbit Amazon Template |
|---|---|---|
| Käyttöönottoaika | 30–60 min (koodi + API-integraatio) | ~2 min (asenna laajennus, avaa Amazon, klikkaa templatea) |
| Kustannus / 1,000 tuotetta (Business-paketti) | ~$5 (50,000 krediittiä á $0.10/krediitti) | ~$16.50 (1,000 riviä × 1 krediitti á $0.0165/krediitti Pro-paketissa) |
| Palautettavat kentät | 18+ (laaja) | Tuotenimi, hinta, arvio, arvostelut, kuvat, URL ja muuta |
| Vientivaihtoehdot | JSON (vaatii koodia purkamiseen) | Excel, CSV, Google Sheets, Airtable, Notion — yhdellä klikkauksella |
| Ylläpito | ScraperAPI ylläpitää SDP:tä | Thunderbit-tiimi ylläpitää templateja |
| Tekninen osaaminen | Python/Node.js vaaditaan | Ei tarvita |
Kehittäjätiimeille, jotka ajavat suurivolyymista Amazon-scrapingia, ScraperAPI:n SDP on skaalassa kustannustehokkaampi tuotetta kohden. Liiketoimintakäyttäjille, jotka haluavat Amazon-datan taulukkoon ilman koodausta, Thunderbit on huomattavasti nopeampi ottaa käyttöön ja käyttää.
Tarvitsetko edes scraping-API:a? No-code-polku, jonka useimmat arvostelut ohittavat
Moni, joka hakee “Scraper API review” -aihetta, ei ole vielä sitoutunut API-pohjaiseen työnkulkuun. He yrittävät ensin ymmärtää, tarvitsevatko he sellaista lainkaan.
Yllättävän moni ei tarvitse. Web scraping -API-markkina on , joka kasvaa 14–18 % CAGR:llä, mutta kasvua vetävät pääasiassa enterprise-kehitystiimit — eivät myyntioperaatioiden managerit, jotka tarvitsevat 500 liidiä verkkosivustolta.
Scraping-API vs. no-code-työkalu: rinnakkainen päätösmalli
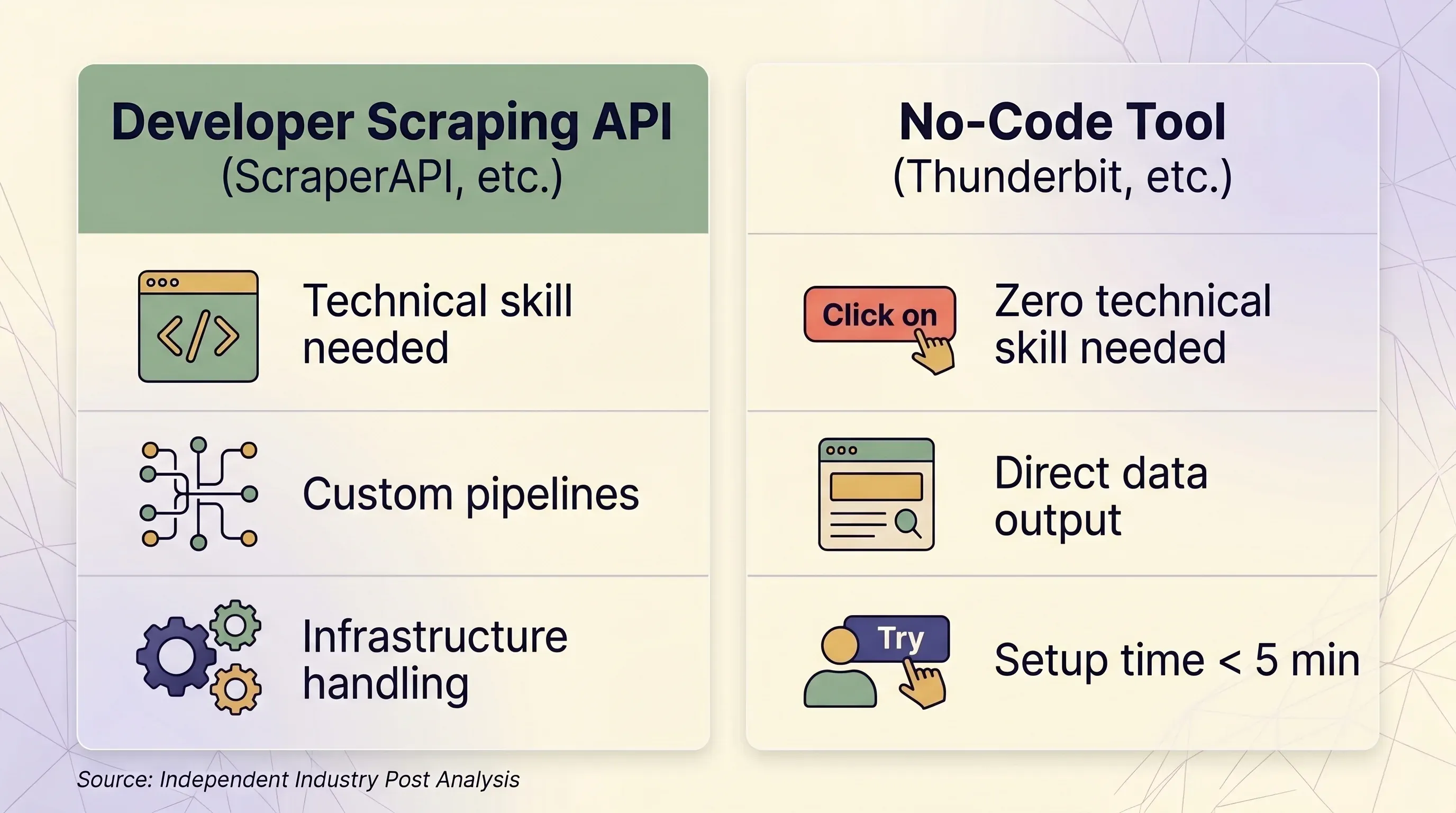
| Tekijä | Scraping-API (ScraperAPI jne.) | No-code-työkalu (Thunderbit jne.) | |---|---|---|---| | Paras käyttäjä | Kehittäjät, jotka rakentavat data-putkia skaalassa | Liiketoimintakäyttäjät, markkinoijat, myyntitiimit, tutkijat | | Tarvittava tekninen osaaminen | Python/Node.js, HTTP-käsitteet, JSON-parsinta | Ei mitään — klikkaile selaimessa | | Käyttöönottoaika | Vähintään 1–2 tuntia (koodi + testaus + debuggaus) | Alle 5 minuuttia | | Anti-bot-käsittely | Premium-proxyt (10–75 krediittiä/pyyntö) | Oikea selainistunto — ohittaa fingerprintingin luonnollisesti | | Kirjautumista vaativat sivustot | ❌ Kielletty ScraperAPI:n käyttöehdoissa | ✅ Browser Scraping käyttää olemassa olevaa istuntoasi | | Skaala (sivua/päivä) | 100K–3M+ pyyntöä/kk | Tarvittaessa, tyypillisesti alle 1,000 sivua/päivä | | Datan ulostulo | Raaka HTML tai JSON (vaatii parsintakoodin) | Jäsennellyt rivit/sarakkeet — valmiina käyttöön | | Vienti | JSON, CSV (koodin kautta) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Ylläpito | Selectorit, retry-logiikka ja infra on päivitettävä | Ei mitään — AI lukee sivun rakenteen uudelleen joka kerta | | Hinnoitteluyksikkö | Per pyyntö krediitteinä (vaihtelee: 1–75 krediittiä/pyyntö) | Per rivi -krediitit (1 krediitti = 1 rivi, 2 alasivuille) | | Aloitushinta | $49/kk 100K krediitillä | $9/kk 5,000 krediitistä (vuosilaskutus) | | Ilmainen taso | 1,000 krediittiä/kk, 5 samanaikaista | 6 sivua/kk, 30 krediittiä/sivu | | Hinnoittelun ennustettavuus | Matala — kertoimet aiheuttavat yllätyskuluja | Korkea — 1 rivi = aina 1 krediitti |
Milloin scraping-API on järkevä
- Sinulla on kehittäjä tai engineering-tiimi
- Sinun täytyy scrapeta 100K+ sivua päivässä ohjelmallisesti
- Tarvitset syvää räätälöintiä request-otsikoihin, sessioneihin ja retry-logiikkaan
- Kohdesivustosi ovat hyvin tuettuja (Amazon, Google, Walmart, Zillow)
Milloin no-code-työkalu kuten Thunderbit on järkevämpi
- Olet myynnissä, verkkokaupan operaatioissa, markkinoinnissa tai kiinteistöalalla — et engineeringissä
- Tarvitset dataa kymmeniltä eri sivustoilta ilman, että rakennat jokaiselle oman parserin
- Haluat suoran viennin Exceliin, Google Sheetiin, Airtableen tai Notioniin
- Tarvitset kirjautumisen vaativien sivustojen scrapauksen (Thunderbitin käyttää istuntoasi)
- Haluat, että AI lukee sivun joka kerta tuoreeltaan — ei koodin ylläpitotyötä, kun sivustot muuttavat ulkoasuaan
- Tarvitset alasivujen scrapauksen: Thunderbit voi käydä jokaisella detail-sivulla ja rikastaa rivit automaattisesti
-työnkulku on aidosti yksinkertainen: asenna laajennus, siirry mille tahansa sivulle, klikkaa “AI Suggest Fields”, klikkaa “Scrape” ja vie data ulos. AI päättelee, mitä dataa sivulla on, ja ehdottaa sarakkeet — sinun ei tarvitse kirjoittaa selectoreita tai koodia. Jos haluat lisää taustaa, katso meidän .
koki pilvikulujen ylityksiä vuonna 2024, ja yrityksillä, jotka käyttävät käyttöön perustuvaa hinnoittelua ilman kunnollisia suojia, on lasku-shokin vuoksi. Per-rivi-krediittimallin ennustettavuus on hyvä juttu, jos muuttuvat API-kulut ovat aiemmin polttaneet sormesi.
ScraperAPI:n plussat ja miinukset yhdellä silmäyksellä
| Plussat | Miinukset |
|---|---|
| Vahva proxy-infrastruktuuri (40M+ IP:tä, 50+ maata) | Sekava krediittikerroinjärjestelmä — ominaisuuksien yhdistäminen maksaa enemmän kuin summa |
| Erinomainen dokumentaatio ja helppo alkuun pääsy (Capterra Ease of Use: 4.9/5) | Krediitit EIVÄT siirry kuukaudesta toiseen |
| Luotettava Amazonissa, Googlessa, Zillowissa ja Etsyssä | 0 % onnistumisaste Instagramissa, Twitter/X:ssä ja Booking.comissa |
| Laskuttaa vain onnistuneista pyynnöistä (200/404) | 404-vastaukset kuluttavat silti krediittejä |
| 18 structured data -päätepistettä parsitulla JSON-ulostulolla | Kirjautumista vaativat sivustot on nimenomaisesti kielletty |
| Saatavilla kaikissa paketeissa, myös Free-paketissa | Pay-As-You-Go vain Scaling-paketissa ($475/kk) ja sitä ylemmissä |
| 7 päivän palautusoikeus ilman kyselyjä | 10 minuutin pakotettu välimuisti vaikeilla kohteilla — riski vanhasta datasta |
| 30–35 % vuotuinen liikevaihdon kasvu viittaa aktiiviseen kehitykseen | DataPipeline voi maksaa jopa 6× standardi-API:n krediitit |
| — | Geotargetointi US:n ja EU:n ulkopuolelle vaatii Business-paketin ($299/kk) |
| — | Ei ennakoivia käyttöilmoituksia — dashboard pitää tarkistaa itse |
Käytännön vinkit ScraperAPI:n hyödyntämiseen parhaalla tavalla (jos päätät käyttää sitä)
Seuraa krediittikulutusta päivittäin
ScraperAPI:n näyttää käyttötilastoja, kuten keskimääräisen viiveen, scrapattujen domainien määrän ja samanaikaisten yhteyksien metrikat. Mutta ennakoivia käyttövaroituksia ei ole — ei sähköpostia tai SMS:ää, kun krediitit ovat loppumassa. Sinun täytyy tarkistaa asia itse. Analytiikan historia rajoittuu 2 viikkoon Hobby/Startup-paketeissa ja 6 kuukauteen Business+-paketeissa.
Laita kalenterimuistutus tarkistamaan dashboard joka päivä ensimmäisen kuukauden aikana. Sinun täytyy oppia, kuinka nopeasti krediitit palavat juuri sinun kohteissasi.
Aloita ilmaisella tasolla ja testaa omat kohteesi
Käytä 1,000 ilmaista krediittiä (sekä 7 päivän kokeilua 5,000 krediitillä) testataksesi onnistumisasteita omilla kohdesivuillasi ennen kuin sitoudut maksulliseen pakettiin. Kirjaa ylös, mitkä sivustot tarvitsevat JavaScript-renderöintiä tai premium-proxyjä, jotta voit arvioida realistiset kuukausikulut kertoimet huomioiden.
Kytke premium-ominaisuudet pois, ellei kohde niitä vaadi
ScraperAPI EI ota premium-proxyjä tai JavaScript-renderöintiä automaattisesti käyttöön — sinun täytyy asettaa render=true, premium=true tai ultra_premium=true itse. Mutta domain-pohjainen hinnoittelu ON automaattista: Amazon maksaa aina 5 krediittiä, Google aina 25, LinkedIn aina 30. Anti-bot-bypass-krediitit (+10 Cloudflarelle, DataDomelle, PerimeterX:lle) lisätään myös automaattisesti, kun ne havaitaan. Tiedä tämä ennen massapyyntöjen ajamista.
Käytä structured data -päätepisteitä tuetuilla sivustoilla
Jos scrapaat Amazonia tai Googlea, SDE:t säästävät kehitysaikaa, vaikka ne maksaisivat enemmän krediittejä. Tuettomille sivustoille kannattaa arvioida, olisiko nopeampi ja halvempi kuin oman parserin rakentaminen.
Pidä varasuunnitelma epäluotettaville kohteille
Jos ScraperAPI:n onnistumisaste tietyllä sivustolla on alle 90 %, harkitse pyyntöjen ohjaamista toisen palveluntarjoajan kautta tai selainpohjaisen työkalun käyttöä. Kirjautumista vaativilla sivustoilla ScraperAPI ei yksinkertaisesti toimi — tarvitset työkalun kuten , joka toimii selaussessiosi sisällä.
Tunne sudenkuopat
- 404-vastaukset kuluttavat krediittejä — ScraperAPI veloittaa sekä 200- että 404-statuskoodeista
- Perutut pyynnöt laskutetaan, jos peruutat ne ennen kuin 70 sekunnin käsittelyikkuna päättyy
- 10 minuutin pakotettu välimuisti vaikeilla kohteilla — saatat saada vanhaa dataa
- Pay-As-You-Go on vain Scaling-paketissa ($475/kk) ja sitä ylemmissä — alempien tasojen käyttäjät katkaistaan, kun krediitit loppuvat
- Geotargetointi US:n ja EU:n ulkopuolelle vaatii Business-paketin ($299/kk)
Keskeiset huomiot: onko ScraperAPI oikea työkalu sinulle?
Tähän päädyin kaiken tutkimuksen jälkeen:
- ScraperAPI on vahva valinta kehittäjätiimeille, jotka scrapettavat suuria volyymejä ja hyvin tuettuja kohteita kuten Amazonia, Googlea, Walmartia ja Zillowia. Structured data -päätepisteet ovat aidosti hyödyllisiä, proxy-infrastruktuuri on laaja ja dokumentaatio on keskimääräistä parempaa.
- Krediittikerroinjärjestelmä on suurin riski. Jos et ymmärrä, miten kertoimet kasaantuvat, kulutat helposti liikaa. Ero mainostettujen krediittien ja oikeiden pyyntöjen välillä voi olla 5–75×. Laske oma käyttötapauksesi ennen kuin sitoudut maksulliseen pakettiin.
- Luotettavuus riippuu sivustosta. ScraperAPI on erinomainen verkkokaupassa ja kiinteistöalalla, keskinkertainen työpaikkasivustoilla ja sosiaalisessa mediassa, ja täysin hyödytön Instagramissa, Twitter/X:ssä ja Booking.comissa. Älä oleta tasaista suorituskykyä.
- Ei-teknisille tiimeille ScraperAPI on väärä työkalu. Jos työskentelet myynnissä, markkinoinnissa tai operaatioissa ja tarvitset jäsenneltyä dataa ilman koodausta, no-code-työkalu kuten vie sinut maaliin kahdella klikkauksella — AI-pohjaisella kenttätunnistuksella, suoralla taulukko-viennillä, alasivujen rikastuksella ja ilman ylläpitokuormaa. Katso tai katso tutoriaaleja .
- Budjetilla työskenteleville kehittäjille testaa ScraperAPI:n ilmainen taso omilla kohteillasi ja vertaa sitten todellisia per pyyntö -kuluja ScrapingBeehen, Scrapflyhin ja Bright Dataan ennen valintaa. Halvin vaihtoehto riippuu täysin käyttötapauksestasi ja ominaisuusvaatimuksistasi.
Haluatko nähdä, miten numerot toimivat juuri sinun scraping-tarpeissasi? Aloita ScraperAPI:n ilmaisesta tasosta ja testaa kohdesivustosi, tai ja katso, kuinka pitkälle kaksi klikkausta riittää. Lisätietoa saat tutustumalla paketteihimme.
Usein kysytyt kysymykset
Onko ScraperAPI ilmainen?
Kyllä, ScraperAPI tarjoaa ilmaisen tason, jossa on sekä 7 päivän kokeilun 5,000 krediitillä. JavaScript-renderöinnin, premium-proxyjen tai kalliiden domainien (Amazon = 5×, Google = 25×, LinkedIn = 30×) krediittikertoimet tarkoittavat kuitenkin, että todellinen kapasiteetti voi olla paljon alle 1,000 pyyntöä. Ilmaisella tasolla ultra-premium-proxyt eivät ole käytettävissä.
Kuinka paljon ScraperAPI maksaa per pyyntö?
Se riippuu voimakkaasti feature-lipuista ja kohde-domainista. Tavallinen pyyntö yksinkertaiseen HTML-sivustoon maksaa 1 krediitin. Amazon-pyyntö maksaa 5 krediittiä. Google SERP -pyyntö maksaa 25 krediittiä. JavaScript-renderöinti lisää 10 krediittiä. Ultra-premium-proxyn ja JavaScript-renderöinnin yhdistelmä maksaa 75 krediittiä per pyyntö. Hobby-paketissa ($49/kk, 100K krediittiä) hinta voi olla mitä tahansa $0.00049 per pyyntö (tavallinen) ja $0.0368 per pyyntö (ultra-premium + JS) välillä. Katso tarkat kulutaulukot yllä.
Onko ScraperAPI hyvä Amazonin scrapaukseen?
ScraperAPI:n Amazon Structured Data -päätepiste on yksi sen vahvimmista ominaisuuksista, ja sillä on riippumattomissa testeissä sekä laaja, parsittu JSON-ulostulo (18+ kenttää). Jokainen Amazon-pyyntö maksaa kuitenkin vähintään 5 krediittiä, joten kulut kasvavat skaalassa. Pienemmille tiimeille, jotka haluavat Amazon-dataa taulukkoon ilman koodausta, tarjoaa 1 klikkauksen vaihtoehdon suoralla viennillä.
Mitkä ovat parhaat ScraperAPI-vaihtoehdot?
Kehittäjille: (halvin perus-HTML:ssä), (hyvä JavaScript-renderöinti), (paras suojatuille sivustoille — kiinteä hinta riippumatta renderöinnistä) ja . Ei-teknisille käyttäjille: — no-code, AI-pohjainen Chrome-laajennus, jossa on suora vienti Exceliin, Google Sheetiin, Airtableen ja Notioniin. Katso syvempää analyysiä varten.
Voiko ScraperAPI scrapeta sivustoja, jotka vaativat kirjautumisen?
ScraperAPI tukee session säilyttämistä session_number-parametrin kautta (sama IP useilla pyynnöillä), mutta se . Se ei pysty käsittelemään lomakkeiden täyttöä, kaksivaiheista tunnistautumista tai monimutkaisia auth-flow’ita. Kirjautumista vaativille sivustoille selainpohjaiset työkalut kuten — joka käyttää olemassa olevaa selainistuntoasi siihen, mitä voit nähdä — ovat luotettavampi vaihtoehto.
Lisätietoa