

Oletko koskaan saanut esimieheltäsi nipun PDF-tiedostoja ja saanut tehtäväksi poimia niistä dataa täysin oikeassa ja täsmällisessä muodossa? Kun tämän tekee käsin, ylitöiden riski kasvaa nopeasti. Tiedon poimiminen PDF-tiedostoista voi olla todella työlästä, sillä toisin kuin verkkodata, PDF:issä muotoilu on usein epäyhtenäistä. Joissakin PDF:issä on taulukoita, toiset ovat pelkkiä kuvia tai skannattuja asiakirjoja, jolloin suora poiminta on hankalaa.
Poimi dataa miltä tahansa verkkosivustolta AI:n avulla Get Started Free
Jos esimerkiksi haluat poimia sähköpostiosoitteita PDF:stä, osa niistä saattaa olla kuvamuodossa, kun taas osa on piilotettu monimutkaisiin merkistökoodeihin. Ota tämä esimerkki: {john.doe,jane.doe}@example.com. Se tarkoittaa itse asiassa kahta erillistä sähköpostia: john.doe@example.com ja jane.doe@example.com. Sitten on vielä {first.last}@example.com, jossa korvaat sanat "first" ja "last" kirjoittajan etu- ja sukunimellä. Perinteiset tekstintunnistustyökalut eivät yksinkertaisesti riitä tähän. Siinä kohtaa apuun tulee kätevä työkalu, PDF Scraper, joka pelastaa päivän.
Mikä on PDF Scraper
PDF Scraper on kätevä työkalu, joka poimii dataa automaattisesti PDF-tiedostoista ja muuntaa sisällön, kuten taulukot ja tekstin, tarvitsemaasi muotoon, esimerkiksi Excel, CSV tai JSON. Yksinkertaisesti sanottuna se muuttaa työlään kopiointi- ja liittämisurakan yhden klikkauksen ratkaisuksi.
Kuvittele, että sinulla on pino laskuja, sopimuksia, akateemisia artikkeleita tai jopa skannattuja PDF:iä, joiden puhtaaksikirjoittaminen käsin veisi tunteja. PDF Scraperilla lataat vain tiedoston, ja sekunneissa data on poimittu talteen. Se säästää aikaa ja vaivaa sekä parantaa tarkkuutta. Voit sanoa hyvästit manuaaliselle tietojen syöttämiselle.
Jos PDF sisältää useita datatyyppejä, kuten taulukoita, linkkejä ja kuvia, anna AI PDF Scraperin hoitaa homma. AI PDF Scraperit hyödyntävät suuria kielimalleja (LLM), jotka pystyvät käsittelemään tekstiä, kuvia ja taulukoita samanaikaisesti ja tuottavat vaikuttavia tuloksia.
AI PDF Scraperin edut eivät rajoitu tehokkuuteen ja tarkkuuteen; sen mukautuvuus tekee siitä huolettoman valinnan. Olipa kyse skannatuista asiakirjoista, kuvista tai monikielisistä PDF-tiedostoista, AI hoitaa kaiken vaivatta. Saatavilla on monia hyviä AI-työkaluja, kuten Thunderbit, ChatGPT ja ChatPDF, joilla kaikilla on omat vahvuutensa erilaisiin tarpeisiin. Tarvitsetpa nopeaa tiedonpoimintaa tai monimutkaisten asiakirjojen analysointia, oikean työkalun valinta voi tehdä työstäsi helpompaa ja tehokkaampaa.
Kokeile itse: poimi dataa PDF:istä AI:n avulla
Kokeile! Voit klikata, tutkia ja ajaa työnkulun samalla kun katsot.
Miten valita oikea PDF Scraper
PDF Scraperin valitseminen on kuin auton ostamista; paras on se, joka sopii juuri sinun tarpeisiisi. Tässä muutama asia, jotka kannattaa ottaa huomioon:
| Ominaisuus | Kuvaus |
|---|---|
| Tarkkuus ja vakaus | Tarkista, poimiiko työkalu tiedot tarkasti, erityisesti kriittiset tiedot. |
| Tulostusformaatit | Varmista, että työkalu tukee tarvitsemiasi tulostusformaatteja, kuten Excel, CSV tai JSON. |
| Integraatio muiden työkalujen kanssa | Jos sinun täytyy yhdistää työkalu yrityksesi järjestelmiin, tarkista, tukeeko se sujuvaa integraatiota. |
| Käyttäjäystävällinen käyttöliittymä | Helppokäyttöinen työkalu sopii paremmin tavallisille käyttäjille, kun taas monimutkaisemmat työkalut voivat sopia teknisille tiimeille. |
Eri työkaluilla on omat vahvuutensa, ja oikean valinta voi parantaa tuottavuuttasi merkittävästi. Tässä on kolme suosittua PDF Scraperia, joista jokaisella on omat ominaisuutensa erilaisiin tarpeisiin:
| Työkalu | Hyödyt | Haitat |
|---|---|---|
| Thunderbit | Nopea poiminta; helppokäyttöinen selainlaajennuksena; erinomainen tiimityöhön | Rajallinen datankäsittelyn skaala |
| ChatPDF | Helppokäyttöinen, keskusteleva Q&A yhdestä PDF:stä | Ei natiivia CSV/Excel/JSON-vientiä — vastaukset jäävät chattiin |
| ChatGPT | Joustava monimutkaisen semantiikan kanssa, laaja käyttökohteiden kirjo | Vaatii joka kerta manuaalisen promptin syöttämisen |
Näin pääset alkuun AI PDF Scraperilla
Thunderbit
Haluatko poimia dataa PDF:istä nopeasti ilman, että käytät liikaa aikaa ja vaivaa? Thunderbit on juuri sinulle sopiva työkalu. Se on helppokäyttöinen, ja yhdellä klikkauksella saat kaiken hoidettua. Seuraa näitä vaiheita, niin muutat monimutkaisen PDF-datan helposti tarvitsemaasi muotoon ja tehostat työtäsi huomattavasti:
-
Lisää Thunderbit Chromeen ja rekisteröidy:
Siirry Thunderbitin viralliselle verkkosivustolle ja lisää Thunderbit -laajennus Chrome-selaimeesi. Rekisteröidy Google-tililläsi tai toisella sähköpostiosoitteella.

-
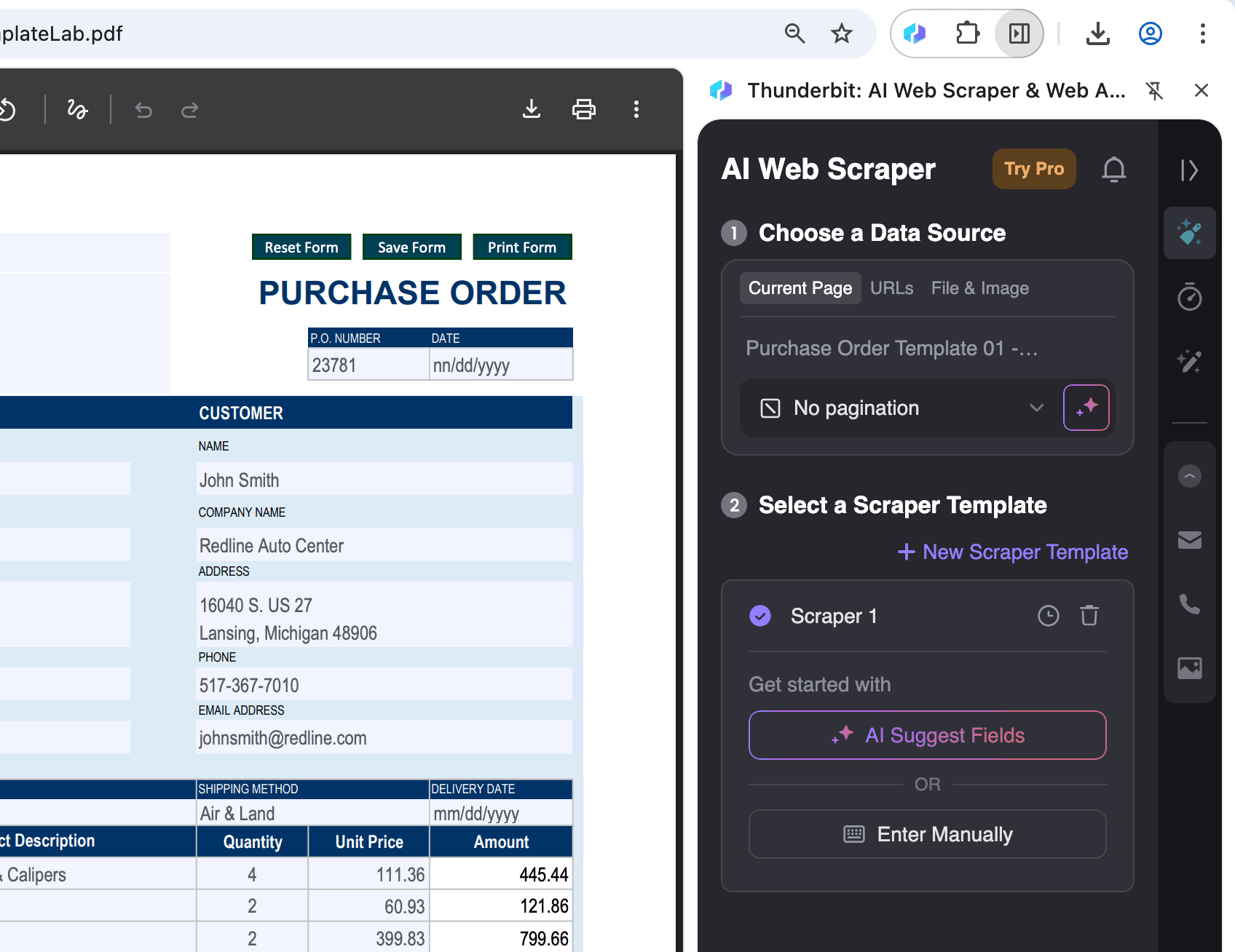
Avaa PDF Chromessa:
Avaa PDF-tiedosto, josta haluat poimia dataa, Chromessa ja napsauta Thunderbit-kuvaketta oikeassa yläkulmassa.
-
Valitse tulostusmuoto ja vie tiedot:
Kun olet valinnut AI Suggest Columns -toiminnon, voit suodattaa tai muokata dataa tarpeen mukaan. Valitse sitten haluamasi vientimuoto (CSV, Google Sheets, Airtable tai Notion) ja napsauta Scrape viedäksesi datan.
 Viedyn datan voi yhdistää suoraan Notioniin, Airtableen tai Google Sheetsiin helppoa tiimityötä varten.
Viedyn datan voi yhdistää suoraan Notioniin, Airtableen tai Google Sheetsiin helppoa tiimityötä varten.
Thunderbit on selkeä PDF-datan poimintatyökalu, jonka avulla voit nopeasti poimia tarvitsemasi tiedot PDF-tiedostoista ja muuntaa ne käyttökelpoiseen muotoon. Olipa kyse henkilökohtaisesta käytöstä tai tiimityöstä, Thunderbit voi parantaa tuottavuuttasi merkittävästi ja tehdä tiedonpoiminnasta helpompaa ja sujuvampaa.
ChatPDF
Jos sinun täytyy käsitellä PDF:iä massana ja haluat poimia vain tiettyjä avaintietoja koko datan sijaan, ChatPDF on erinomainen apuri. Se mahdollistaa tiedon poiminnan keskustelunomaisesti, joten se sopii hyvin aloittelijoille.
Näin poimit PDF-dataa ChatPDF:n avulla:
- Vieraile ChatPDF:n verkkosivustolla: Avaa ChatPDF -sivusto tai siihen liittyvä alusta.
- Lataa PDF-tiedostot: Napsauta "Upload File" -painiketta ja vedä tai valitse PDF-asiakirja, jota haluat analysoida. Se tukee monenlaisia tiedostotyyppejä, kuten sopimuksia, artikkeleita tai talousraportteja.
- Analysoi PDF: Kun tiedosto on ladattu, ChatPDF purkaa sen sisällön automaattisesti ja luo jäsennellyn asiakirjayhteenvedon. Sen jälkeen voit tarkastella poimittuja avaintietoja.
- Kysy vuorovaikutteisesti: Käytä syöttökenttää ja kysy esimerkiksi "Mikä on tämän raportin johtopäätös?" tai "Mikä on laskuun kirjattu kokonaissumma?" ChatPDF poimii relevantin sisällön kysymyksesi perusteella.
- Kopioi vastaukset ulos: ChatPDF palauttaa vastaukset chat-ikkunaan. Kopioi vastaus taulukkolaskentaan, dokumenttiin tai omaan taulukkoosi — jos tarvitset hyvin jäsennellyn lopputuloksen (siisti CSV/JSON ja yhtenäiset sarakkeet useista tiedostoista), Thunderbit tai ChatGPT kiinteällä promptilla on parempi vaihtoehto.
ChatPDF tarjoaa vuorovaikutteisen käyttökokemuksen, joten se sopii erityisen hyvin asiakirjojen tietojen nopeaan paikantamiseen, kuten keskeisten yksityiskohtien löytämiseen tai asiakirjan sisällön tiivistämiseen.
ChatGPT
ChatGPT on erinomainen monimutkaisen semanttisen datan käsittelyssä, kuten lakiasiakirjojen ehtojen jäsentämisessä. Työkalu on erittäin joustava, joten voit räätälöidä promptit poimiaksesi tiettyä dataa tai analysoidaksesi sisältöä. Sinun täytyy kuitenkin käyttää samaa promptia toistuvasti samanlaisiin tehtäviin, ja se vaatii hyvää promptien laatimisen ymmärrystä.
Tässä on valmiiksi kirjoitettu prompti, jota voit muokata tarpeisiisi (muista korvata sarakkeet haluamallasi tiedolla):
Olet nyt PDF Scraper; tehtäväsi on, kun sinulle annetaan PDF, poimia sen sisältö käyttäjän antamien sarakkeiden perusteella. Tulosteesi tulee olla CSV-tiedosto.
Tässä ovat sarakkeet:
1. Nimi
2. Sähköposti
3. Puhelinnumero
4. ...
- Rekisteröidy tai kirjaudu sisään: Avaa ChatGPT -sivusto ja luo tili. Jos sinulla on jo tili, kirjaudu vain sisään.
- Lataa PDF ja syötä kysely: Kirjoita kyselysi suoraan syöttökenttään; mitä tarkempi, sen parempi. Esimerkiksi: "Tämä PDF-asiakirja sisältää kolme kaaviota, vie ne taulukoina."
- Tarkista ja säädä tuloksia: Tarkista, vastaako vastaus odotuksiasi. Tarvittaessa tarkenna tuloksia esittämällä jatkokysymyksiä tai muokkaamalla promptia.
- Vie data Excel- tai CSV-muodossa: Jos ChatGPT:n poimima data on sitä, mitä haluat, kirjoita syöttökenttään: "Vie tämä data Excel- tai CSV-muodossa."
- Tallenna tulokset: Napsauta ChatGPT:n tarjoamaa tiedostolinkkiä ladataksesi tiedoston.
AI PDF Scraperin todelliset käyttötapaukset
AI PDF Scraper on työssäsi kuin monipuolinen apulainen, olipa kyse laskuista, sopimuksista, talousraporteista tai ostotilauksista. Tässä muutamia käytännön tilanteita, joissa se loistaa:
Laskujen ja kuittien käsittely
Käsittele yrityksen laskut ja kuitit erissä ja poimi keskeiset tiedot, kuten summat ja päivämäärät, luokittelua ja arkistointia varten.
- Käynnistä Thunderbit, napsauta AI Web Scraper ja sitten Bulk Pages
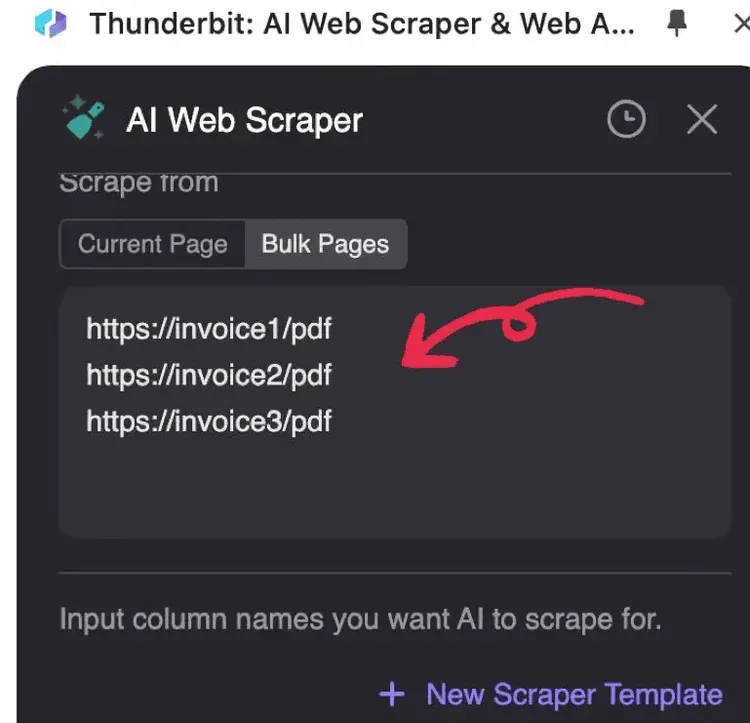
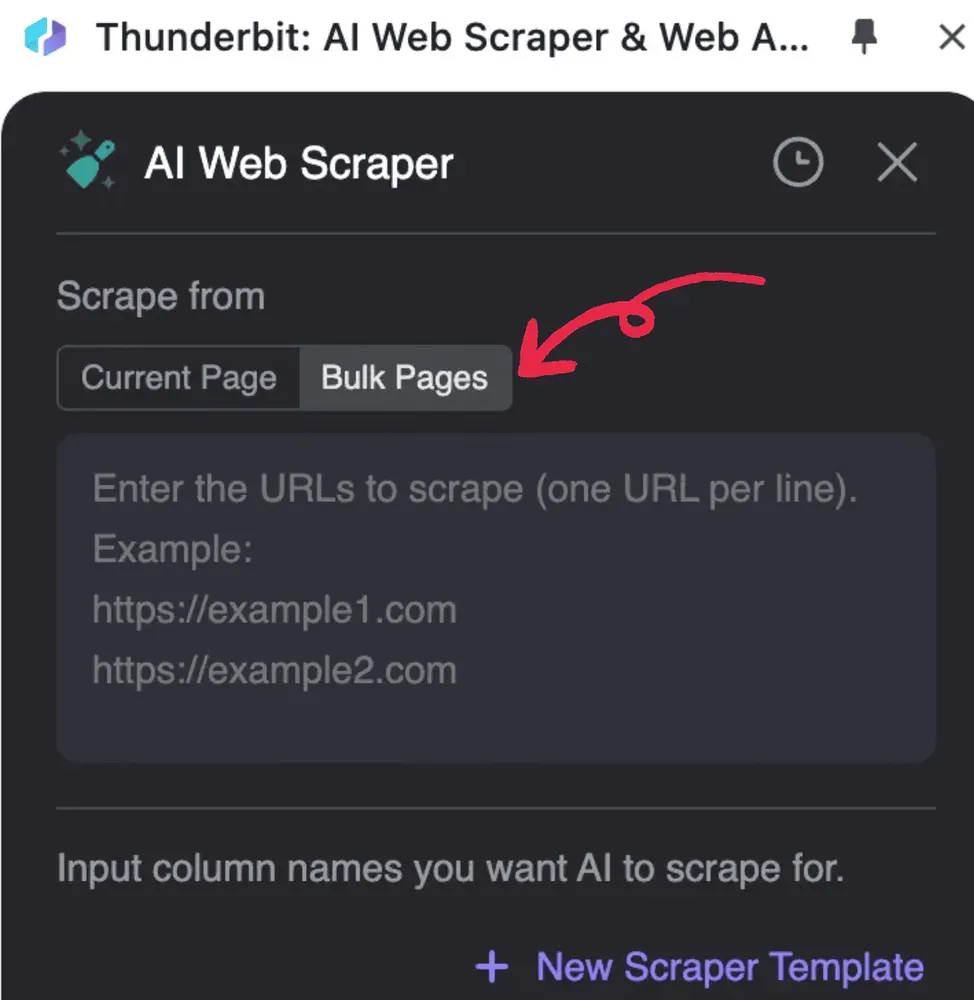 2. Syötä käsiteltävät PDF-URL-osoitteet, yksi URL per rivi
2. Syötä käsiteltävät PDF-URL-osoitteet, yksi URL per rivi
 3. Napsauta AI Suggest Columns (AI lukee PDF:n ja ehdottaa, miten data kannattaa jäsentää)
4. Napsauta Scrape ja vie data
3. Napsauta AI Suggest Columns (AI lukee PDF:n ja ehdottaa, miten data kannattaa jäsentää)
4. Napsauta Scrape ja vie data
Ostotilausten käsittely
Tunnista ostotilauksista automaattisesti tuotteet, määrät ja yksikköhinnat, luo standardoituja tietueita ja poimi dataa PDF:istä, mikä säästää manuaaliseen käsittelyyn kuluvaa aikaa.
- Avaa ostotilaus Chromessa ja käynnistä Thunderbit
- Napsauta AI Web Scraper, sitten AI Suggest Columns
- Tarkista luotu luettelo ja napsauta Scrape
- Napsauta Download CSV
Taloustietojen poiminta
Poimi talousraporteista dataa yhdellä klikkauksella, kuten katteet ja myyntiluvut, jolloin työläs manuaalinen läpikäynti jää pois.
- Avaa talousraportti Chromessa ja käynnistä Thunderbit
- Napsauta Summarize
- Luo automaattisesti yhteenveto keskeisistä tiedoista, mukaan lukien teksti ja taulukon sisältö
Etkö ole tyytyväinen automaattisesti luotuun yhteenvetoon? Voit syöttää haluamasi projektitiedot myös käsin.
- Avaa talousraportti Chromessa ja käynnistä Thunderbit
- Napsauta AI Web Scraper, syötä haluamasi kohteet, kuten nettotulos, myynti jne.
- Napsauta Scrape, tuloste taulukoksi
Oikeudellisten asiakirjojen analyysi
Kamppailetko sopimusten ehtojen kanssa? AI-työkalut löytävät nopeasti maksuehdot, sopimusrikkomuslausekkeet, sopimuksen keston ja muut keskeiset kohdat. Poimi ne yhdellä klikkauksella ja luo tiivis yhteenveto tai luettelo ehdoista, mikä säästää aikaa ja varmistaa, ettei yksikään yksityiskohta jää huomaamatta.
Sama pätee kuin talousraporttien keskeisten tietojen poiminnassa: voit avata PDF:n ja napsauttaa Summarize nähdäksesi maksuehdot, sopimusrikkomuslausekkeet, sopimuksen keston ja muut keskeiset tiedot yhdellä klikkauksella.
Usein kysytyt kysymykset
-
Voinko poimia dataa useista PDF-tiedostoista kerralla?
Kyllä, kehittyneet PDF-poimintatyökalut mahdollistavat datan poimimisen useista PDF:istä samanaikaisesti. Tämä eräkäsittely nopeuttaa työnkulkua merkittävästi verrattuna manuaalisiin menetelmiin.
-
Onko PDF Scraper ilmainen?
Kyllä, useita ilmaisia PDF Scraper -työkaluja on saatavilla. Monet verkkotyökalut, kuten Thunderbit ja ChatPDF, tarjoavat ilmaisia sivu- ja datapoimintoja. Vaikka jotkin edistyneet ominaisuudet voivat olla maksullisia, peruspoiminta on yleensä ilmaista.
-
Tarvitaanko PDF Scraperin käyttöön ohjelmointiosaamista?
Ei, monet AI PDF Scraperit, kuten Thunderbit, on suunniteltu käyttäjille, joilla ei ole ohjelmointitaitoja. Ne tarjoavat käyttäjäystävälliset käyttöliittymät, joiden avulla voit ladata tiedostoja ja poimia dataa vain muutamalla klikkauksella.
-
Mitä asiakirjatyyppejä PDF Scraperilla voi käsitellä?
PDF Scraperit voivat käsitellä erilaisia asiakirjatyyppejä, kuten laskuja, sopimuksia, talousraportteja, akateemisia artikkeleita ja muuta PDF-tiedostoissa olevaa jäsenneltyä tai puolijäsenneltyä sisältöä.
-
Ovatko tietoni turvassa PDF Scraperia käyttäessäni?
Luotettavat PDF-poimintatyökalut asettavat käyttäjien turvallisuuden etusijalle ja noudattavat usein GDPR:n kaltaisia säädöksiä. Ne tallentavat tietosi tyypillisesti salatuille palvelimille eivätkä pääse niihin käsiksi ilman lupaasi.
-
Onko PDF:stä muita tapoja poimia dataa?
PDF-tiedostoista voi poimia dataa monin tavoin myös käsin syöttämisen ja Python-skriptaamisen lisäksi. Näihin kuuluvat PDF-muuntimet, joilla tiedostoja voi muuntaa esimerkiksi Excel- tai CSV-muotoon, erikoistuneet PDF-datan poimintatyökalut, kuten Tabula ja Excalibur, jäsennellyille asiakirjoille, AI-pohjaiset ratkaisut, joissa käytetään optista tekstintunnistusta (OCR) sekä natiiveille että skannatuille PDF:ille, sekä avoimen lähdekoodin työkalut, kuten Extractous ja PymuPDF4llm, jotka on suunniteltu tehokkaaseen tiedonpoimintaan. Jokaisella menetelmällä on omat etunsa ja haittansa, joten valinta riippuu käyttäjän erityistarpeista ja teknisestä osaamisesta.
Lue lisää
- Kuinka poimia dataa miltä tahansa verkkosivustolta AI:n avulla
- 5 parasta työkalua PDF:ien datan poimintaan AI:n avulla
- Kuinka käyttää ChatGPT:tä PDF:istä poimintaan
- Ilmainen PDF-yhteenvedon tekijä verkossa
Kokeile AI Web Scraperia Get Started Free




