

Temu tavoittaa nyt yli 416 miljoonaa kuukausittaista aktiivikäyttäjää yli 50 markkina-alueella. Sen valikoima ulottuu keittiövälineistä lemmikkitarvikkeisiin ja LED-valonauhoihin. Jos työskentelet verkkokaupan, dropshippingin tai kilpailija-analyysin parissa, olet varmasti joskus halunnut siirtää Temu-datan taulukkoon — ja huomannut sitten, ettei Temu todellakaan helpota sitä.
Olen käyttänyt paljon aikaa suojattujen verkkokauppasivustojen keruutyökalujen tutkimiseen ja testaamiseen. Temu on yksi vaikeimmista kohteista. Useimmat nettioppaat tarjoavat joko Python-opastuksen, joka hajoaa viikon sisällä, tai ohjaavat sinut yritystason API-rajapintoihin, jotka maksavat enemmän kuin kuukausittainen mainosbudjettisi.
Todellisuudessa useimmat liiketoimintakäyttäjät — dropshipperit, yksinyrittäjät, markkinointitiimit — haluavat vain siistin taulukon, jossa on tuotteiden nimet, hinnat, kuvat, arviot ja myyjätiedot. He eivät halua debugata Playwright-skriptejä kello kahdelta yöllä.
Tämä opas on rakennettu juuri tämän tarpeen ympärille: käytännöllinen, taitotason mukaan jäsennelty katsaus parhaisiin Temu-kerääjiin, jotka oikeasti toimivat vuonna 2026, sekä parhaisiin käytäntöihin, joilla raakaa keruuta muutetaan jatkuvaksi kilpailija-analyysiksi. Olitpa täysin aloittelija tai kehittäjä rakentamassa dataputkea, tästä löytyy sinulle sopiva osio.
Kokeile Thunderbitia Temu-keruuseen
Miksi Temu-dataa kannattaa kerätä? Tärkeimmät käyttötapaukset liiketoimintatiimeille
Temu-data ei ole vain kiinnostavaa — se on strategisesti hyödyllistä.
Alustasta on tullut hintojen määrittelyyn vaikuttava voima edullisten ja keskihintaisten tuotteiden segmenteissä. Vaikka et myisi Temussa, asiakkaasi vertaavat hintoja siihen, mitä siellä näkevät. Näin eri tiimit hyödyntävät Temu-dataa:
| Käyttötapaus | Tarvittava data | Miksi sillä on väliä |
|---|---|---|
| Dropshipping-tuotetutkimus | Otsikko, hinta, kuva, arvosana, arvostelujen määrä, myyty määrä, variantit | Löytää edullisia tuotteita, joilla on kysyntäsignaaleja vertailuun Amazonissa, Shopifyssa, AliExpressissä ja TikTok Shopissa |
| Kilpailijahinnoittelu | Nykyhinta, alkuperäishinta, alennus %, valuutta, toimitus, aikaleima | Rakentaa pohjan hinnoittelustrategialle ja kampanjasuunnittelulle |
| Tuotteen hankinta | Tekniset tiedot, kuvat, variantit, myyjä/kauppa, tuotetunnus, kategoria | Tunnistaa tuotetyypit ja toimittajamaiset listaukset, jotka kannattaa varmistaa tarkemmin |
| Markkinatrendien analyysi | Hakusana, kategoria, myyty määrä, arvostelujen määrä, arvosana | Näyttää, mitkä tuotteet ovat nousemassa eri kategorioissa |
| Markkinointi- ja luovatutkimus | Otsikko, kuva, arvostelujen määrä, arvosana, kuvaukset, kategoriatunnisteet | Paljastaa viestinnän, visuaaliset koukut, paketit ja väitteet, joita runsaan volyymin listauksissa käytetään |
| Varasto- ja saatavuusseuranta | Tuotteen URL, saatavuus, toimitusarvio, hinta, aikaleima | Taltioi loppuunmyynnit, paikallisen varaston muutokset ja hinnanliikkeet ajan myötä |
Hakusanalla "best Temu scrapers" etsivä yleisö jakautuu yleensä kolmeen ryhmään. Ei-tekniset käyttäjät haluavat Chrome-laajennuksen, joka tuottaa taulukon. Puolitekniset käyttäjät haluavat visuaalisen työkalun, jossa on valmiit mallit ja ajastus. Kehittäjät haluavat API:n, Playwright-skriptin ja välityspalvelustrategian.
Tämä artikkeli kattaa kaikki kolme — mutta se aloittaa suurimmasta ryhmästä: ihmisistä, jotka tarvitsevat dataa, eivät koodia.
Mikä erottaa parhaat Temu-kerääjät muista vuonna 2026
Kerääjä, joka selviää Amazonista tai Shopifysta, ei välttämättä selviä Temusta. Tämän artikkelin arviointikriteerit ovat:
- Luotettavuus Temussa — Palauttaako se oikeasti siistiä dataa, vai estyykö se, tuottaako tyhjiä rivejä tai rikkoutuuko asettelumuutoksen jälkeen?
- Käytön helppous — Voiko ei-tekninen liiketoimintakäyttäjä aloittaa ilman koodausta?
- Datan kattavuus — Tukeeko se alisivujen rikastamista (eli jokaisen tuotesivun avaamista teknisiä tietoja, variantteja ja myyjätietoja varten)?
- Ylläpitotaakka — Mukautuuko se, kun Temu muuttaa sivurakennettaan?
- Ajastus ja seuranta — Voiko sillä tehdä toistuvia keruita ja viedä datan elävään tietolähteeseen?
- Vientikohteet — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Kustannusten läpinäkyvyys — Paljonko realistinen Temu-keruuprosessi oikeasti maksaa kuukaudessa?
Yhteisön raportit Redditin r/webscrapingistä kuvaavat Temua johdonmukaisesti yhdeksi vaikeimmista verkkokauppasivustoista kerätä. Eräs käyttäjä kirjoitti, ettei "saa edes hintaa ostajana", kun taas toinen huomautti, että Temulla ja Shopeella on tiimit, jotka vahvistavat jatkuvasti anti-bot-mekanismeja. Temukohtaista epäonnistumisdataa ei ole julkisesti vertailtuna, mutta vuoden 2025 Imperva Bad Bot -raportti totesi, että automatisoitu liikenne ohitti ihmisten liikenteen, ja botit muodostivat 51 % kaikesta internetliikenteestä. Juuri sitä vastaan Temu puolustautuu.
Temun anti-bot-suojaukset: miksi useimmat kerääjät epäonnistuvat
Useimmat Temu-keruuta käsittelevät artikkelit käyttävät anti-bot-suojauksista vain yhden lauseen: "Temu käyttää anti-botia." Siitä ei ole hyötyä.
Jos valitset työkalua, sinun täytyy tietää, mitä suojauksia Temu käyttää ja mitkä työkalujen ominaisuudet kiertävät ne. Tässä käytännöllinen kartta:
| Temun suojaus | Mitä se tekee | Tarvittava työkalukyky | Esimerkkityökalut |
|---|---|---|---|
| Cloudflare WAF / selaintarkistukset | Estää automaattiset user-agentit, tunnistaa bottien sormenjäljet, näyttää challenge-sivuja | Pilvi-infrastruktuuri, jossa kiertävät residential-IP:t ja aidot selainsormenjäljet | Thunderbit (pilvikeruu), Bright Data, Oxylabs, ScraperAPI |
| Raskas JavaScript-renderöinti | Tuotetieto latautuu JS:n kautta; raaka HTML on tyhjä | Headless-selain tai täysi selainrenderöinti | Thunderbit (selainkeruutila), Playwright, Selenium, ParseHub, Apify browser actors |
| Dynaamiset CSS-valitsimet | Luokkien nimet vaihtuvat julkaisujen välillä ja rikkovat CSS-pohjaiset kerääjät | AI-pohjainen kenttien tunnistus (ei riippuvainen kiinteistä valitsimista) | Thunderbit (AI lukee sivun aina tuoreena), Bright Data AI scraper builder |
| Nopeusrajoitus | Hidastaa nopeasti peräkkäisiä pyyntöjä | Samanaikaiset pilvipyynnöt älykkäällä rajoituksella | Thunderbit (jopa 50 sivua kerrallaan pilven kautta), ScraperAPI, Bright Data |
| CAPTCHA-haasteet | Keskeyttää istunnot epäilyttävän toiminnan jälkeen | Sisäänrakennettu CAPTCHA-ratkaisu tai vähemmän laukaiseva strategia | Bright Data, Oxylabs, ScraperAPI premium/ultra-premium |
| Loputon vieritys / laiska lataus | Vain ensimmäiset tuotteet näkyvät ilman vuorovaikutusta | Älykäs vieritys, sivutuksen tunnistus, vuorovaikutuksen automaatio | Thunderbit pagination, Apify smart scrolling, Octoparse workflow builder |
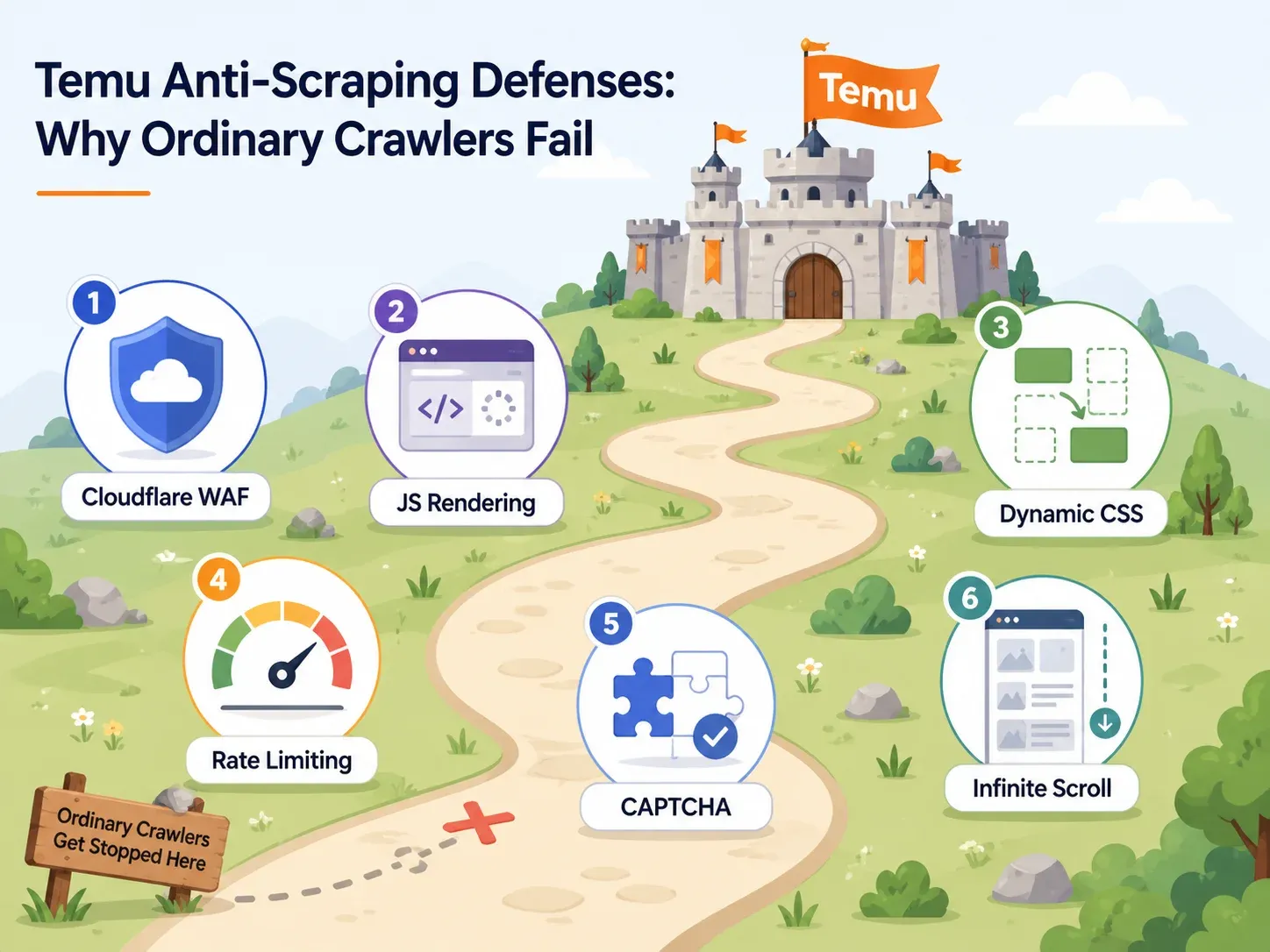
Cloudflare WAF ja IP-estot
Temun etuovi on Cloudflare-tyyppisten selaineheyden tarkistusten suojaama. Perus-HTTP-pyynnöt — sellaiset, joita yksinkertainen Python requests.get() tekee — haastetaan, palautetaan 403-virhe tai niillä näytetään puutteellista dataa.
Tämän tason keruuseen tarvitaan kiertäviä residential- tai mobiili-IP-osoitteita sekä aidot selainsormenjäljet. Cloudflaren vuoden 2025 Radar-yhteenveto kertoi, että ei-AI-botit aloittivat vuoden 2025 vastaten suunnilleen puolta HTML-sivupyyntöistä. Sellaista automaatiota vastaan Temu puolustautuu.
JavaScript-renderöinti ja dynaamiset valitsimet
Tässä useimmat aloittelevat kerääjät epäonnistuvat hiljaa.
Jos katsot Temun sivun lähdekoodia, löydät usein tyhjän kuoren — varsinaiset tuotekortit, hinnat ja kuvat injektoidaan JavaScriptillä sivun latauduttua. Kerääjä, joka lukee vain raakaa HTML:ää, ei palauta mitään hyödyllistä. Lisäksi Temun CSS-luokat ja DOM-rakenteet muuttuvat julkaisujen välillä. Kerääjä, joka nojaa kiinteään CSS-valitsimeen kuten .product-card__price, toimii tänään ja palauttaa huomenna tyhjiä sarakkeita.
AI-pohjaiset kerääjät (kuten Thunderbit) lukevat sivun semanttisesti joka kerta, joten ne eivät ole riippuvaisia siitä, että tietyt luokkanimet pysyvät samoina.
Nopeusrajoitus ja CAPTCHA-haasteet
Jos osut Temuun liian nopeasti tai liian monta kertaa samasta IP:stä, laukaise nopeusrajoitukset tai CAPTCHA-haasteet. Jotkin työkalut hoitavat tämän älykkäällä hidastuksella ja sisäänrakennetulla CAPTCHA-ratkaisulla. Toiset jättävät sen sinun vastuullesi — mikä ei-tekniselle käyttäjälle on käytännössä umpikuja.
Pilvikeruussa avain on samanaikaiset pyynnöt puhtaiden IP-osoitteiden yli automaattisella uudelleenyrityksellä.
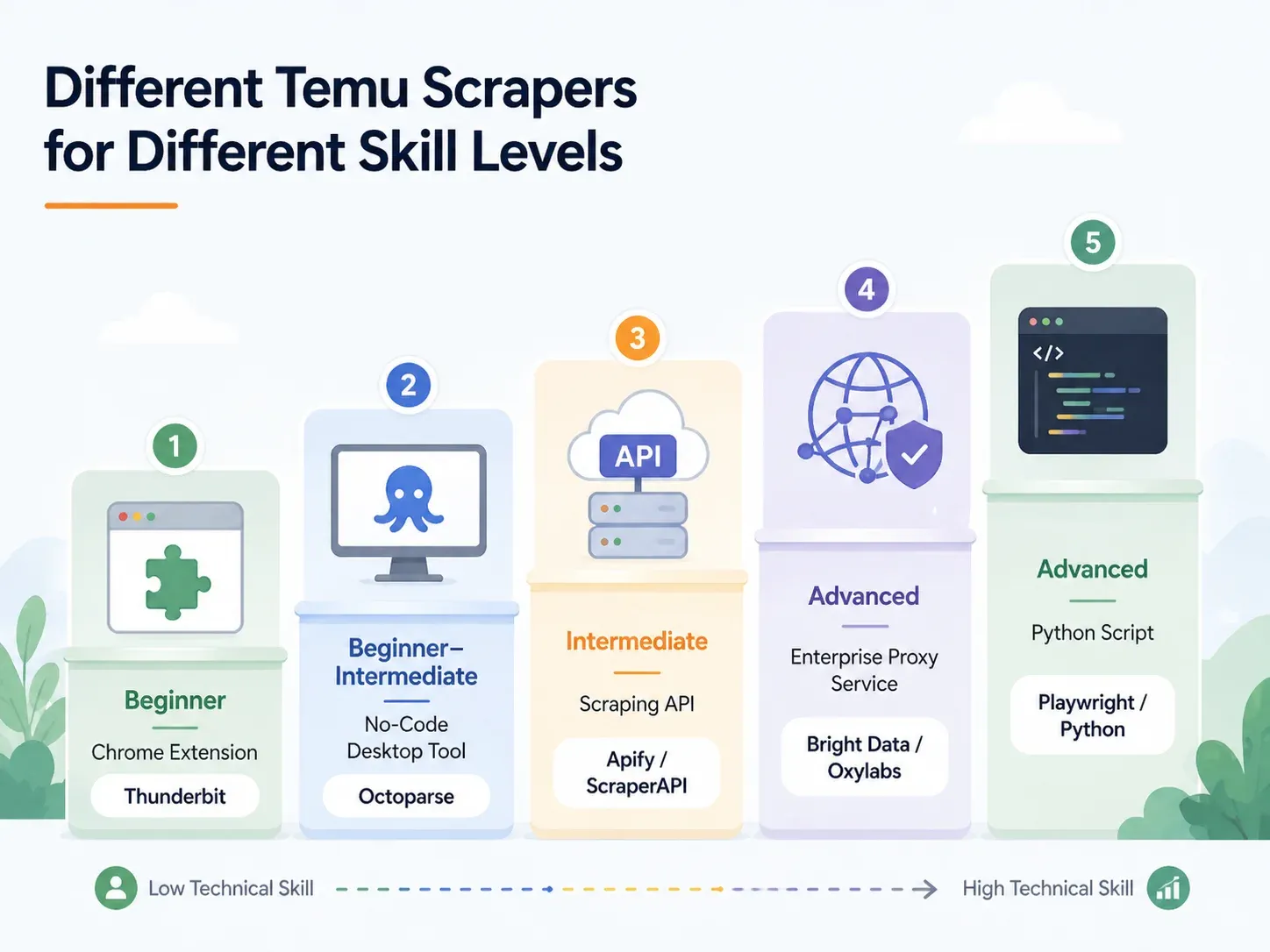
Parhaat Temu-kerääjät taitotason mukaan: täydellinen läpikäynti
Etsi oma rivisi ja siirry sinulle sopivaan osioon:
| Lähestymistapa | Taitotaso | Asennusaika | Anti-bot-käsittely | Paras käyttötarkoitus |
|---|---|---|---|---|
| AI Chrome -laajennus (esim. Thunderbit) | Aloittelija | < 2 min | Hoidetaan puolestasi (pilvi tai selain) | Dropshipperit, markkinoijat, verkkokaupan operointi |
| No-code-työpöytätyökalu (esim. Octoparse, ParseHub) | Aloittelija–keskitason | 10–60 min | Osittainen (proxy-asetus tarvitaan) | Säännöllinen keruu malleilla |
| Keruu-API/palvelu (esim. ScraperAPI, Apify) | Keskitaso | 15–45 min | Sisäänrakennettu | Kehittäjät, jotka integroivat datan putkiin |
| Hallittu proxy/yritystaso (esim. Bright Data, Oxylabs) | Edistynyt/yritys | Tunteja–päiviä | Täysi infrastruktuuri | Suurivolyymiset toimitukset varastoon |
| Oma Python-skripti (Playwright/Selenium) | Edistynyt | 1–4 h+ | Manuaalinen (proxy + CAPTCHA-asetus) | Täysi hallinta, erikoistapaukset |
Thunderbit: paras Temu-kerääjä ei-teknisille käyttäjille
Thunderbit on AI-pohjainen Chrome-laajennus, joka on rakennettu liiketoimintakäyttäjille — myyntitiimeille, verkkokauppaoperaattoreille, dropshippereille ja markkinoijille — jotka tarvitsevat jäsenneltyä dataa verkkosivuilta ilman koodausta. Työskentelen Thunderbit-tiimissä, joten tunnen tuotteen hyvin. Kerron suoraan, mitä se tekee ja mihin se sopii.
Perusprosessi on kaksivaiheinen: avaa Temu-sivu, klikkaa AI Suggest Fields, tarkista ehdotetut sarakkeet (tuotteen nimi, hinta, kuva, arvosana jne.) ja klikkaa sitten Scrape.
Thunderbitin AI lukee sivun rakenteen ja ehdottaa sarakenimet sekä tietotyypit automaattisesti. Se ei perustu kiinteisiin CSS-valitsimiin, joten kun Temu muuttaa luokkanimiä tai korttien asettelua, kerääjä mukautuu.
Tärkeimmät ominaisuudet Temua varten:
- Pilvikeruutila: Nopeampi julkisille sivuille, käsittelee jopa 50 sivua kerrallaan. Paras kategorisivuille, hakutuloksiin ja tuotelistauksiin, jotka eivät vaadi kirjautumista.
- Selainkeruutila: Käyttää nykyistä Chrome-istuntoasi, mukaan lukien evästeet, alueasetus ja kirjautumistila. Paras silloin, kun alue, pop-upit tai kirjautunut sisältö vaikuttavat siihen, mitä sivulla näkyy.
- Scrape Subpages: Kun olet kerännyt listaussivun, voit klikata "Scrape Subpages" ja vierailla jokaisella tuotesivulla lisätäksesi sarakkeita kuten koko kuvaus, variantit, myyjätiedot, toimitusarvio ja tekniset tiedot — ilman lisäasetuksia.
- Field AI Prompts: Luokittele, käännä tai muotoile dataa keruun aikana. Esimerkiksi: "Luokittele tämä tuote keittiövälineisiin, pienkoneisiin, säilytysratkaisuihin tai muuhun."
- Ajastettu keruu: Aseta luonnollisella kielellä aikataulu ("joka maanantai klo 9"), syötä URL-osoitteet ja Thunderbit suorittaa keruun pilvessä ja vie tulokset Google Sheetiin, Airtableen tai muuhun kohteeseen.
- Ilmaiset viennit: Excel, CSV, Google Sheets, Airtable, Notion, JSON — vientiä ei ole lukittu maksumuurin taakse. Kuvat viedään Airtableen ja Notioniin oikeina liitteinä.
Hinnoittelu: ilmainen taso sisältää jopa 6 sivua (tai 10 kokeilubonuksella); maksulliset paketit alkavat noin $15/kk (kuukausittain) tai $9/kk (vuosittain) hintaisista 500 krediitistä, jossa 1 krediitti = 1 tulosrivi.
Kerää Temu-dataa AI:lla Get Started Free
Rinnakkain: Thunderbit vs. Python-skripti samalla Temu-sivulla
Ero on selvä:
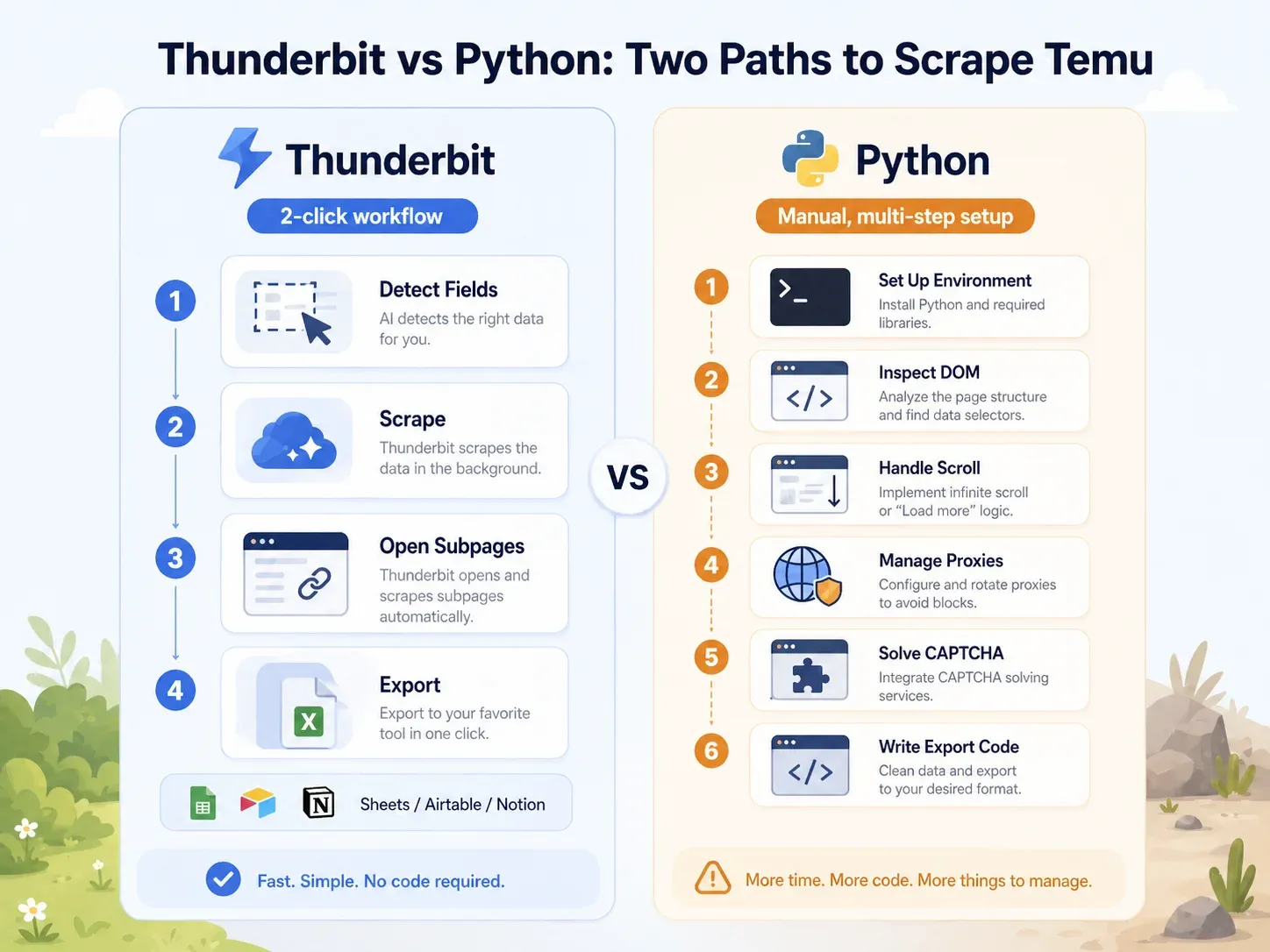
| Tehtävä | Thunderbit | Python (Playwright) |
|---|---|---|
| Avaa Temu-kategoriasivu | Avaa sivu Chromessa | Luo Python-ympäristö, asenna Playwright, asenna selaimet |
| Tunnista kentät | Klikkaa "AI Suggest Fields" | Tarkastele DOM:ia, verkkopyyntöjä, JSON-paketteja |
| Käsittele dynaaminen lataus | Selain-/pilvitila + sivutus | Kirjoita vieritys- ja odotuslogiikka, sieppaa pyynnöt |
| Käsittele estot | Kokeile pilvitilaa tai selaintilaa | Lisää proxyt, headerit, sormenjäljet, uudelleenyritykset, CAPTCHA |
| Poimi listauskentät | Klikkaa "Scrape" | Kirjoita valitsimet tai API-jäsennyslogiikka |
| Rikasta tuotesivuilla | Klikkaa "Scrape Subpages" | Rakenna erillinen PDP-kerääjä |
| Vienti | Klikkaa Sheets/Airtable/Notion/Excel | Kirjoita CSV/JSON/Sheets-integraatiokoodia |
| Tyypillinen asetus liiketoimintakäyttäjälle | Alle 2 minuuttia | Vähintään 1–4 tuntia; jatkuva ylläpito |
Minimaalinen Playwright-prototyyppi Temulle voisi näyttää tältä (pseudokoodia — ei tuotantovalmiina):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Tuotantokoodi tarvitsee silti valitsimet, proxyt, uudelleenyritykset,
# CAPTCHA-käsittelyn, PDP-keruun ja vientilogiiikan.
print(cards.count())
Siinä on yli 10 riviä ennen kuin olet poiminut ensimmäistäkään kenttää, etkä ole vielä koskenut proxeihin, CAPTCHAan, PDP-rikastukseen tai vientiin. Ei-tekniselle käyttäjälle Thunderbit tiivistää koko tämän työn muutamaan klikkaukseen. Kehittäjälle Python-reitti tarjoaa enemmän hallintaa — mutta paljon suuremmalla ylläpitokustannuksella.
Octoparse ja ParseHub: no-code-työpöytäkerääjät Temulle
Jos haluat enemmän hallintaa kuin Chrome-laajennus tarjoaa mutta et halua kirjoittaa koodia, Octoparse ja ParseHub ovat päävaihtoehdot.
Octoparse sisältää julkisen Temu Details Scraper -mallin. Sen esimerkkitulosteessa on tuotetunnukset, otsikot, hinnat, myyjä-/kauppatiedot, kuva-URL:t, alennukset, kauppa-URL:t ja yksityiskohtaiset tekniset tiedot. Se on oikea etu — voit aloittaa mallilla sen sijaan, että rakentaisit työnkulun tyhjästä. Octoparse tukee myös pilvipoimintaa, ajastusta ja visuaalista työnkulun rakentamista.
Temun osalta huomioitavaa:
- Anti-bot-lisäosat (residential-proxyt hintaan $3/GB, CAPTCHA-ratkaisu $1–$1.50 / tuhat) voivat kasvattaa kustannuksia nopeasti.
- Mallit voivat rikkoutua, kun Temu muuttaa asetteluaan. Saatat joutua päivittämään valitsimia tai odottamaan, että Octoparse ylläpitää mallia.
- Asennus vie 10–60 minuuttia sivun monimutkaisuudesta riippuen.
Octoparse-hinnoittelu: ilmainen suunnitelma 10 tehtävällä ja 50K kuukausittaisella dataviennillä; Standard noin $75/kk vuosilaskutuksella; Professional noin $108/kk vuosilaskutuksella. Lisäosat proxeille, CAPTCHAlle ja hallinnoiduille palveluille veloitetaan erikseen.
ParseHub on visuaalinen työpöytä-/verkkokerääjä, joka käsittelee dynaamisia sivuja hyvin (se käyttää täyttä Chromium-selainta). Maksulliset paketit alkavat kuitenkin $189/kk:sta, mikä on yksinyrittäjälle melko kallista. En löytänyt tutkimuksessani vahvaa julkista Temu-kohtaista mallia. ParseHub sopii paremmin tiimeille, jotka ovat jo valmiita rakentamaan visuaalisia keruuprojekteja.
| Työkalu | Vahvuudet Temussa | Heikkoudet Temussa | Hinnoittelu |
|---|---|---|---|
| Octoparse | Julkinen Temu-malli, visuaalinen työnkulku, pilvipoiminta, ajastus | Mallien ylläpito, anti-bot-lisäosat lisäävät kustannuksia | Ilmainen; noin $75/kk vuosittainen Standard; noin $108/kk vuosittainen Pro; lisäosat erikseen |
| ParseHub | Dynaamisten sivujen käsittely, projektityönkulun rakentaja, IP-vaihto maksullisilla tasoilla | Korkeampi aloitushinta, ei löytynyt julkista Temu-mallia | Maksulliset paketit alkaen $189/kk |
Keruu-API:t: ScraperAPI, Apify ja Bright Data Temulle
API-pohjaiset keruupalvelut hoitavat proxyt, renderöinnin ja anti-bot-logiikan, jotta kehittäjät voivat keskittyä datan jäsentämiseen ja tallentamiseen. Ne sopivat silloin, kun rakennat dataputkea etkä tee kertaluonteista taulukkovientiä.
ScraperAPI on kehittäjä-API proxyjen kierrätykseen ja renderöintiin. Sen hinnoittelusivulla mainitaan 7 päivän kokeilu 5 000 krediitillä, Hobby-taso $49/kk 100 000 krediitillä ja siitä ylöspäin korkeammat tasot. Temun kohdalla haaste on tämä: JavaScript-renderöinti ja premium-proxypoolit kuluttavat 10–75 krediittiä pyyntöä kohti tasosta riippuen. Tämä krediittikertymä tarkoittaa, että todellinen kustannus per rivi voi olla paljon suurempi kuin otsikkohinta.
Apify on alusta, jossa on markkinapaikka valmiille "actoreille" (kerääjille). Temu-actoreita on useita. Yksi yhteisön ylläpitämä Temu Scraper listaa pay-per-event-hinnoittelun noin $5 per 1 000 tuotetta ilmaisella tasolla. Toinen Temu Products Scraper listaa $4 per 1 000 tulosta. Riski: actorien laatu vaihtelee, ylläpito on yhteisöstä riippuvaista, ja jotkin actorit voivat olla vanhentuneita tai rikkoutua, kun Temu päivittyy. Tarkista aina "last modified" -päiväys ja käyttäjäarviot ennen sitoutumista.
Bright Data on yritystason vaihtoehto. Sen Temu-kerääjäsivu kertoo, että työt ajetaan Bright Datan infrastruktuurilla, jossa on proxyjen kierto, geo-targetointi, CAPTCHA-/unblocking-logiikka ja automaattinen skaalautuvuus. Tulosmuotoja ovat JSON, CSV, Parquet sekä suora toimitus S3:een, GCS:ään, Azure Blobiin, BigQueryyn ja Snowflakeen. Alan arviot kertovat, että Web Scraper API:n pay-as-you-go-hinta on noin $2.5 per 1 000 tietuetta, ja sitoutuneet paketit alkavat noin $499/kk:sta. Tehokas, mutta hinnoiteltu tiimeille, joilla on oikeaa budjettia.
Oxylabs:lla on myös oma Temu Scraper API -sivu. Paketit alkavat $49/kk:sta, ja tarjolla on jopa 2 000 tuloksen ilmainen kokeilu. Se on vahva vaihtoehto Bright Datalle kehitystiimeille, jotka haluavat jäsenneltyä Temu-dataa API:n kautta.
| API/alusta | Temu-kohtainen näyttö | Vahvuus | Heikkous | Paras käyttötarkoitus |
|---|---|---|---|---|
| ScraperAPI | Temu-kohtaista sivua ei löytynyt, mutta verkkokaupan anti-bot-ominaisuudet on dokumentoitu | Yksinkertainen endpoint, JS-renderöinti, premium-proxyt | Premium-ominaisuuksien krediittikertoimet; kehittäjän täytyy jäsentää data itse | Kehittäjäputket |
| Apify | Markkinapaikalla useita Temu-actoreita | Nopein kehittäjäpolku, jos actor sopii ja sitä ylläpidetään | Actorien laatu vaihtelee; osa vanhentuu | Kehittäjät, jotka haluavat actor-markkinapaikan ja ajastuksen |
| Bright Data | Oma Temu-kerääjäsivu | Yritystason infrastruktuuri, unblocking, varastotoimitus | Kallis; web-keruun käsitteet ovat silti tarpeen | Yritystason datatiimit |
| Oxylabs | Oma Temu Scraper API -sivu | Selkeä hinnoittelu per tulos, JS-käsittely, IP/CAPTCHA-väitteet | Kehittäjä-API-työnkulku | Kehitystiimit, jotka tarvitsevat Temu-API-pääsyn |
Räätälöidyt Python-skriptit (Playwright/Selenium): täysi hallinta, suuri työmäärä
Räätälöidyt Python-kerääjät tarjoavat maksimaalisen joustavuuden — siinä on niiden etu. Playwright on yleensä parempi lähtöpiste kuin Selenium Temulle, koska siinä on automaattinen odottaminen ja parempi tuki JavaScript-painotteisille sivuille.
Mutta kompromissi on raju.
Prototyyppi vie 1–4 tuntia. Tuotantokerääjä tarvitsee proxyjen kierrätyksen, realistiset selainsormenjäljet, CAPTCHA-strategian, uudelleenyritykset, skeeman validoinnin, tulostallennuksen, seurannan, hälytykset ja juridisen tarkistuksen.
Ja se rikkoutuu. Redditin keruuyhteisöt kuvaavat toistuvasti modernia verkkokauppakeruuta epävakaaksi silloin, kun sivustot käyttävät Cloudflarea, JavaScript-renderöintiä ja anti-bot-sormenjälkiä.
| Virhetila | Tyypillinen syy | Torjunta |
|---|---|---|
| Tyhjä HTML / tuotteet puuttuvat | JS lataa tuotekortit alkuperäisen HTML:n jälkeen | Käytä Playwrightia, odota verkkoa ja DOM:ia |
| Vain muutama ensimmäinen tuote | Loputon vieritys / laiska lataus | Vierityssilmukka, verkon hiljentymisen odotus, korttimäärän kynnysarvot |
| Hinnat puuttuvat tai ovat epäjohdonmukaisia | Alue-/istunto-/valuuttatila tai anti-bot-vastaus | Aseta locale, evästeet, maantieteellisesti kohdistettu proxy |
| 403 / challenge / CAPTCHA | IP:n maine, headless-sormenjälki, pyyntönopeus | Residential-proxyt, stealth-selain, alempi nopeus |
| Valitsimen rikkoutuminen | DOM-/luokkamuutokset, A/B-testit | Semanttinen poiminta tai API-jäsennys, jos saatavilla |
Räätälöidyt skriptit eivät ole "ilmainen" vaihtoehto. Ne siirtävät kustannuksen tilausmaksuista kehittäjäaikaan, proxy-laskuihin, CAPTCHA-kuluihin ja ylläpitoriskiin. Jos sinulla on talossa keruuinsinööri ja tarvitset poikkeuksellista logiikkaa, tämä on oikea polku. Kaikille muille se on käytännössä kallein vaihtoehto.
Parhaat käytännöt: alisivujen keruu täydellistä Temu-tuotedataa varten
Tämä on tämän artikkelin yksittäisesti vaikuttavin paras käytäntö — eikä melkein mikään muu opas käsittele sitä.
Temu-kategoria- tai hakusivu näyttää perustiedot: otsikon, pikkukuvan, hinnan, karkean arvosanan. Mutta ne kentät, jotka tekevät rivistä oikeasti käyttökelpoisen — yksityiskohtaiset kuvaukset, varianttilistat, täydelliset arvostelumäärät, toimitusarviot, myyjän nimet, tekniset taulukot — löytyvät tuotesivulta (PDP).
Jos keräät vain listaussivun, työskentelet vajaan aineiston kanssa.
Kaksivaiheinen työnkulku:
- Vaihe 1 — Kerää listaussivu (PLP): Poimi tuotteen nimi, hinta, pikkukuva ja arvosana Temun haku- tai kategorisivulta.
- Vaihe 2 — Rikasta alisivukeruulla: Vieraile jokaisen tuotteen PDP-sivulla ja lisää sarakkeita kuten koko kuvaus, arvostelujen määrä, varianttivaihtoehdot, toimitusaika ja myyjän tiedot.
Näin data näyttää ennen ja jälkeen:
| Kenttä | PLP:stä (vaihe 1) | Lisätty PDP:stä (vaihe 2) |
|---|---|---|
| Tuotteen otsikko | ✅ | — |
| Hinta | ✅ | ✅ (varmistettu / alennus %) |
| Pikkukuva | ✅ | — |
| Tähtiarvosana | ✅ | ✅ (arvostelujen määrällä) |
| Koko kuvaus | ❌ | ✅ |
| Variantit (koot, värit) | ❌ | ✅ |
| Myyjän nimi | ❌ | ✅ |
| Toimitusarvio | ❌ | ✅ |
| Yksityiskohtaiset tekniset tiedot | ❌ | ✅ |
Thunderbitissa tämä on yhden klikkauksen asia: alkuperäisen keruun jälkeen klikkaa "Scrape Subpages". AI vierailee jokaisessa tuotteen URL-osoitteessa ja lisää lisäsarakkeet — ei lisäasetuksia, ei erillistä spideriä, ei valitsimien ylläpitoa. Octoparse’n Temu Details -malli ja Apifyn Temu-actor tukevat myös PDP-tason kenttiä, mutta vaativat enemmän asennusta ja ylläpitoa. Pythonissa sinun pitäisi rakentaa erillinen PDP-kerääjä, ylläpitää sen valitsimia ja käsitellä sivutusta tuotesivuilla — merkittävä lisäinvestointi.
Parhaat käytännöt: aikataulutettu Temu-keruu jatkuvaa hinnan ja varaston seurantaa varten
Kertaluonteiset keruut ovat hyödyllisiä tuotteen löytämisessä. Kilpailija-analyysi vaatii toistuvaa tarkastelua.
Hinnat muuttuvat, tuotteet loppuvat varastosta, uusia tuotteita ilmestyy päivittäin ja alennusten syvyys vaihtelee kampanjoiden mukana. Viikoittainen tai päivittäinen keruu luo historiataulukon, johon tiimisi voi oikeasti tarttua.
Kolme automatisoimisen arvoista käyttötapaa:
- Hintaseuranta: Seuraa kilpailijan 50 suosituimman Temu-SKU:n hintoja viikoittain. Saat päivitetyt hinnat automaattisesti Google Sheetiin, jolloin vertailu omaan hinnoitteluusi on helppoa.
- Varasto- ja saatavuusseuranta: Huomaa, milloin trendituote loppuu varastosta, uusi variantti ilmestyy tai toimitusarvio muuttuu.
- Uusien tuotteiden / trendien havaitseminen: Ajoita päivittäinen keruu Temun "New Arrivals" -sivulle tai prioriteettikategoriaan. Lajittele myytyjen määrien tai arvostelujen perusteella, jotta löydät nousevat tuotteet ajoissa.
Thunderbitissa tämä tehdään kuvaamalla aikaväli luonnollisella kielellä ("joka maanantai klo 9"), syöttämällä kohde-URL-osoitteet ja klikkaamalla "Schedule". Keruu ajetaan pilvessä ja viedään valitsemaasi kohteeseen. Koska AI lukee sivun aina tuoreena, aikataulutetut keruut mukautuvat automaattisesti Temun asettelumuutoksiin — sinun ei tarvitse päivittää valitsimia, kun Temu suunnittelee tuotekortin uudelleen.
Vaihtoehto: tee cron-jobi, ylläpidä Python-skriptiä, määritä proxyjen kierto, rakenna vientiputki ja korjaa valitsimet aina kun Temu muuttaa asetteluaan. Ei-tekniselle tiimille se on käytännössä poissuljettu. Kehittäjälle se on jatkuvaa lisätyötä. Apify ja Bright Data tukevat myös ajastettuja ajoja, mutta teknisemmällä asennuksella ja korkeammilla aloituskustannuksilla.
Parhaat käytännöt: päästä päähän -Temu-dataprosessi (kerää → puhdista → vie → toimi)
Useimmat keruuoppaat päättyvät kohtaan "lataa CSV".
Mutta liiketoimintakäyttäjät tarvitsevat datan niihin työkaluihin, joissa he oikeasti toimivat — Google Sheets yhteistyöhön, Airtable tuotetietokantoihin, Notion tiimin koontinäyttöihin. Oikea paras käytäntö on päästä päähän -prosessi:
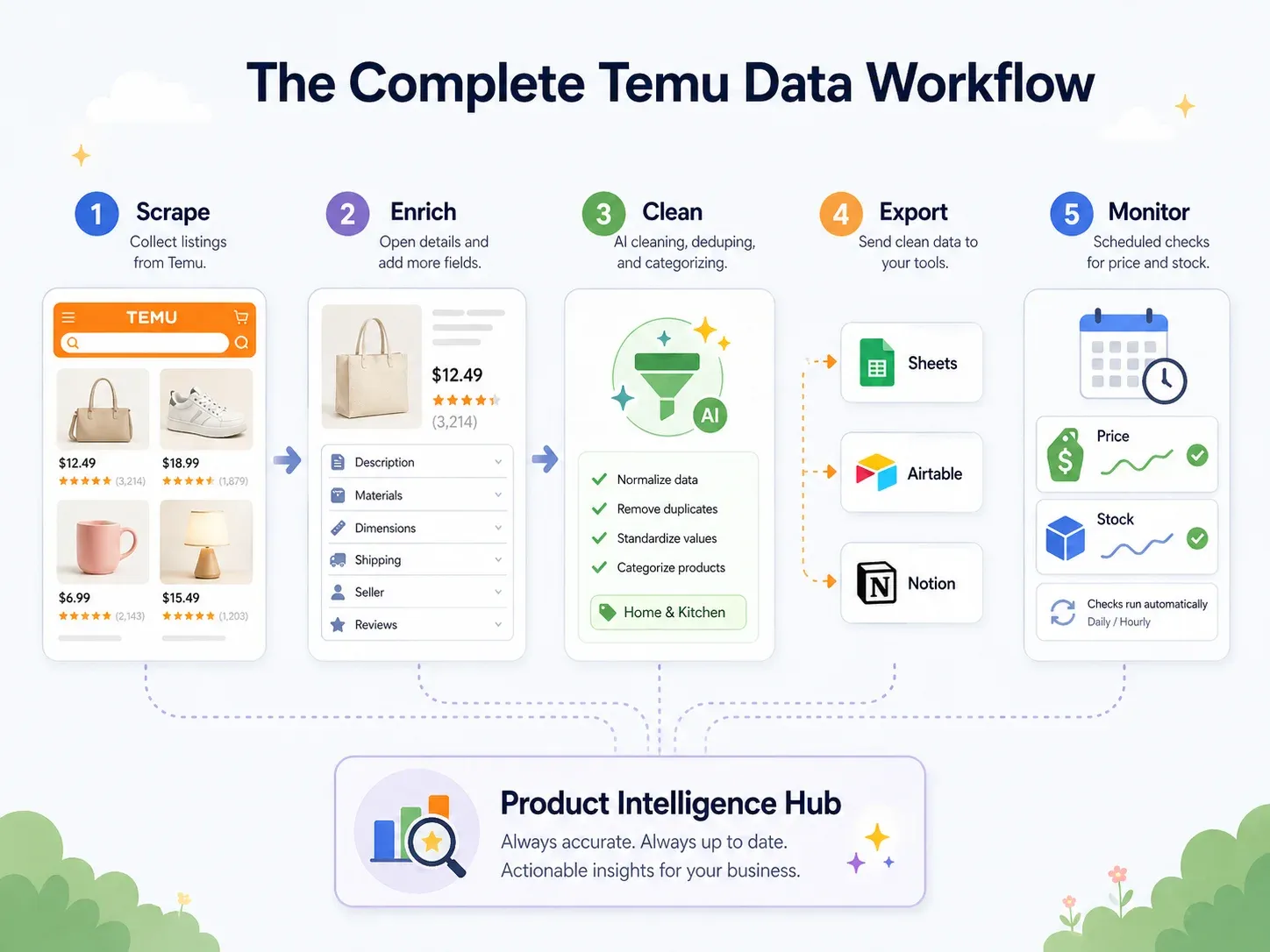
| Työvaihe | Mitä tapahtuu | Thunderbitin ominaisuus |
|---|---|---|
| Kerää | Poimi data Temu-sivuilta | AI Suggest Fields → Scrape (2 klikkausta) |
| Rikasta | Vieraile jokaisen tuotteen tuotesivulla | Scrape Subpages (1 klikkaus) |
| Puhdista ja merkitse | Luokittele tuotteet, normalisoi hinnat, käännä otsikot | Field AI Prompt — merkitse, muotoile, käännä keruun aikana |
| Vie | Siirrä data liiketoimintatyökaluihin | Ilmainen vienti Exceliin, Google Sheetiin, Airtableen, Notioniin; lataa CSV/JSON |
| Seuraa | Tarkkaile muutoksia ajan myötä | Scheduled Scraper luonnollisen kielen aikaväleillä |
Tässä konkreettinen esimerkki: keräät 200 Temu-keittiötuotetta. Keruun aikana Field AI Prompt luokittelee jokaisen tuotteen automaattisesti ryhmiin "Utensils / Small Appliances / Storage / Cleaning / Decor". Hinnat normalisoidaan numeerisiksi USD-arvoiksi. Kiinalaiset tuotet otsikot käännetään englanniksi. Data viedään suoraan Airtable-baseen tuotekuvat mukana (ei vain URL-osoitteina — oikeina kuvaliitteinä, kuten Thunderbitin kuvakeruuoppaassa kuvataan). Ajastettu keruu päivittää datan viikoittain.
Hyödyllisiä Field AI Prompt -ohjeita Temu-datalle:
- "Luokittele tämä tuote yhteen seuraavista: Kitchen Utensils, Small Appliances, Storage, Cleaning, Decor, Other. Palauta vain luokka."
- "Käännä tuotteen otsikko tiiviiksi englanniksi säilyttäen tuotemerkit, määrät, koot ja mallinumerot."
- "Normalisoi hinta numeroksi ilman valuuttasymboleja."
- "Merkitse kysyntä korkeaksi, keskitasoiseksi tai matalaksi arvosanan, arvostelujen määrän ja myytyjen määrän perusteella. Jos data puuttuu, palauta Unknown."
Tämä työnkulku muuttaa raakadatan eläväksi tuoteälyn tietokannaksi — ilman että kehittäjän täytyy rakentaa erillistä ETL-putkea.
Parhaat Temu-kerääjät vertailussa: rinnakkaistaulukko
| Työkalu | Taitotaso | Asennusaika | Anti-bot-käsittely | Alisivukeruu | Ajastus | Vientivaihtoehdot | Hinnoittelutaso | Paras käyttötarkoitus |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Aloittelija | Minuuteissa | Selaintila, pilvitila, AI-kenttätunnistus | Kyllä (Scrape Subpages) | Kyllä (luonnollisen kielen aikataulut) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Ilmainen 6 sivulle; maksullinen alkaen noin $9–15/kk 500 krediitille | Ei-tekniset verkkokauppatiimit, dropshipperit |
| Octoparse | Aloittelija–keskitason | 10–60 min | Pilvipoiminta, proxy/CAPTCHA-lisäosat | Kyllä (mallipohjaiset työnkulut) | Kyllä (maksulliset/pilvipaketit) | Excel, CSV, JSON, HTML, XML, tietokanta, Google Sheets | Ilmainen; noin $75/kk vuosittainen Standard; lisäosat erikseen | Käyttäjät, jotka haluavat visuaaliset työnkulut + Temu-mallin |
| ParseHub | Aloittelija–keskitason | 30–60 min | Dynaaminen renderöinti, maksullinen IP-vaihto | Kyllä (projektivirrat) | Maksulliset paketit | CSV/JSON, Dropbox/S3 maksullisilla | Maksullinen alkaen $189/kk | Tiimit, jotka rakentavat visuaalisia projekteja dynaamisille sivuille |
| ScraperAPI | Kehittäjä | Tunteja | Proxyjen kierto, JS-renderöinti, premium-poolit | Räätälöity koodilla | DataPipeline/ajastin | HTML/JSON/CSV | Kokeilu 5K krediittiä; Hobby $49/kk; korkeampia tasoja saatavilla | Kehittäjät, jotka rakentavat räätälöityjä Temu-putkia |
| Apify | Keskitaso | 10–30 min, jos actor sopii | Actor-kohtainen selain-/proxylogiikka | Actorista riippuva | Kyllä | JSON, CSV, Excel, API/datasetit | Ilmainen alusta; Temu-actorit noin $4–5/1K tuotetta | Kehittäjät/käyttäjät, jotka osaavat arvioida actorin laadun |
| Bright Data | Edistynyt/yritys | Tunteja–päiviä | Täysi proxy, CAPTCHA, unblocking, automaattinen skaalautuvuus | Räätälöity kerääjän/API:n kautta | Kyllä | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | noin $2.5/1K tietuetta PAYG; sitoutuneet alkaen noin $499/kk | Yritystason datatiimit, suurivolyyminen keruu |
| Oxylabs | Edistynyt | Tunteja | JS-käsittely, IP/CAPTCHA-väitteet | Räätälöity API:n kautta | Kyllä | JSON/API-tulos | Alkaen $49/kk; kokeilu jopa 2K tulokselle | Kehitystiimit, jotka tarvitsevat Temu-API-pääsyn |
| Oma Python (Playwright) | Edistynyt | 1–4 h+; jatkuva ylläpito | Manuaaliset proxyt, CAPTCHA, sormenjäljet | Täysin räätälöity | Cron/jono/manuaalinen | Räätälöity | Kehittäjäaika + proxy/CAPTCHA/hosting-kulut | Erikoistapaukset, tiimit joilla on keruuinsinöörejä |
Minkä Temu-kerääjän valitset? Nopeat suositukset
- Dropshipper, joka tarvitsee nopeaa tuotetutkimusta? Aloita Thunderbitin ilmaiselta tasolta. Se on nopein tie siitä, että "tarvitsen Temu-dataa", siihen että "minulla on taulukko." Jos se toimii kohdesivuillasi (ja sen pitäisi toimia useimmilla julkisilla kategoria- ja tuotesivuilla), olet valmis.
- Käyttäjä, joka haluaa visuaalista hallintaa ja uudelleenkäytettäviä malleja? Octoparsella on julkinen Temu Details -malli ja visuaalinen työnkulun rakentaja. Varaudu 10–30 minuutin asennukseen ja jonkin verran proxy/CAPTCHA-asetuksia.
- Kehittäjä, joka rakentaa dataputkea tai sisäistä työkalua? ScraperAPI tai Apify tarjoavat API-/actor-työnkulkuja, jotka integroituvat koodiin ja ajastettuihin töihin. Arvioi Apifyn actorit huolellisesti — tarkista ylläpitotila ja käyttäjäarviot.
- Yritystiimi, joka tarvitsee suurivolyymistä Temu-dataa ja toimituksen varastoon? Bright Data on infrastruktuurivalinta. Kallis, mutta se hoitaa skaalan, unblockingin ja toimituksen S3:een/BigQueryyn/Snowflakeen.
- Keruuinsinööri, joka tarvitsee erikoislogiikkaa? Räätälöity Playwright/Selenium antaa täyden hallinnan. Budjetoi vain jatkuva ylläpito, proxy-kulut ja CAPTCHA-käsittely.
Useimmille ei-teknisille liiketoimintakäyttäjille suosittelen testaamaan ensin Thunderbitin ilmaista tasoa. Välitön kysymys on aina: "saanko tästä juuri tästä Temu-sivusta tarvitsemani rivit?" — ja siihen voit vastata alle kahdessa minuutissa ilman, että käytät rahaa. Kehittäjille kannattaa ajaa onnistuneen rivin kustannusvertailu Apifyn, ScraperAPI:n ja pienen Playwright-prototyypin välillä ennen budjetin sitomista.
Kokeile Thunderbitia ilmaiseksi Temu-keruuseen
Usein kysytyt kysymykset Temu-keruusta
Onko Temun kerääminen laillista?
Se riippuu lainkäyttöalueesta, keräämästäsi datasta, käyttötavasta ja siitä, miten hyödynnät dataa. Temun käyttöehdot rajoittavat nimenomaisesti automaattista pääsyä, mukaan lukien sivujen tai datan crawlailu, kerääminen tai spideröinti. Yhdysvaltain tuomioistuimet ovat tarjonneet joissain tapauksissa myönteistä ennakkotapausta julkisesti saatavilla olevan datan käyttämiseen (yhdeksännen piirin hiQ v. LinkedIn -ratkaisu), mutta myöhemmät päätökset ovat myös vahvistaneet sopimusrikkomus- ja luvattoman tunkeutumisen vaatimuksia. Lyhyt vastaus: julkisesti saatavilla olevan tuotetiedon kerääminen tutkimukseen voi joissain tilanteissa olla puolustettavissa, mutta käyttöehdot, tietosuoja, tekijänoikeudet ja datan käyttötapa kaikki merkitsevät. Tämä ei ole oikeudellista neuvontaa — kysy neuvoa asianajajalta kaupallista käyttöä varten.
Kuinka usein Temu muuttaa sivustonsa rakennetta?
Julkista rytmiä ei ole dokumentoitu. Yhteisön raportit ja työkaluekosysteemi käsittelevät Temua dynaamisena, usein päivittyvänä kohteena. Oleta, että CSS-valitsimet voivat rikkoutua milloin tahansa, ja suosi AI-/semanttista poimintaa tai aktiivisesti ylläpidettyjä malleja kovakoodattujen valitsimien sijaan.
Voinko kerätä Temu-dataa joutumatta estetyksi?
Rajoitetuilla julkisilla sivuilla ja maltillisella tahdilla kyllä — erityisesti työkaluilla, joissa on aito selainrenderöinti, istuntotuki ja nopeudenrajoitus. Yhtäkään työkalua ei pidä pitää yleismaailmallisena takauksena. Pilvikeruu kiertävillä IP-osoitteilla toimii hyvin julkisilla katalogisivuilla; selainkeruu nykyisellä istunnollasi toimii paremmin, kun alue, kirjautuminen tai pop-upit vaikuttavat dataan.
Mitä dataa voin poimia Temun tuotesivuilta?
Yleisiä julkisia kenttiä ovat tuotteen otsikko, URL, nykyhinta, alkuperäishinta, alennusprosentti, kuva-URL:t, tähtiarvosana, arvostelujen määrä, myyty määrä, myyjän/kaupan nimi, toimitustiedot, kategoria, tekniset tiedot, variantit (värit, koot) ja keruun aikaleima. Täsmälliset kentät riippuvat sivutyypistä (lista vs. tuotesivu) ja alueesta.
Tarvitsenko proxyt Temun keräämiseen?
Pienessä, selaintilassa tehdystä manuaalimaisesta keruusta (muutama sivu kerrallaan) et välttämättä tarvitse. Pilvi-, ajastettu tai suurivolyyminen keruu vaatii yleensä proxyjä tai hallittua estonkiertoinfrastruktuuria. Työkalut kuten Thunderbit, Bright Data ja ScraperAPI sisällyttävät proxyhallinnan alustaansa, joten sinun ei tarvitse määrittää sitä erikseen.
Jos haluat syventyä aiheeseen lisää, katso oppaamme hintavertailun web-keruusta, parhaista verkkokaupan web-kerääjistä, datan keräämisestä verkkosivuilta Exceliin ja siitä, miten keräät dataa Google Sheetiin. Voit myös katsoa läpikäyntejä Thunderbitin YouTube-kanavalta.
Kokeile Thunderbitia Temu-keruuseen Get Started Free
Lue lisää




