La web crece a un ritmo que, la verdad, cuesta hasta imaginar. Cada día se publican miles de millones de páginas nuevas, productos, reseñas y conjuntos de datos, impulsando desde la investigación de mercado hasta el entrenamiento de IA y tu próxima compra en Amazon. Como alguien que ha pasado años en SaaS y automatización, he visto de primera mano cómo los datos correctos pueden marcar la diferencia entre el éxito y el fracaso de una decisión empresarial. Pero aquí está el problema: recopilar, actualizar y entender todo ese contenido web se vuelve cada vez más difícil, no más fácil. Los scrapers web tradicionales ya no alcanzan el ritmo, y las empresas necesitan una forma más inteligente y rápida de convertir internet en información útil. Ahí es donde entra el cloud crawler: una herramienta que está cambiando, casi sin hacer ruido, la forma en que las organizaciones descubren y aprovechan los datos web a gran escala.
Entonces, ¿qué es exactamente un cloud crawler? ¿En qué se diferencia de los web scrapers que ya conoces? ¿Y por qué equipos que van desde ventas hasta operaciones están apostando por esta tecnología para seguir siendo competitivos en un mundo impulsado por los datos? Vamos a ponerlo claro, quitar la jerga y ver cómo los cloud crawlers —especialmente la solución de Thunderbit— están cambiando las reglas del juego para las empresas modernas.
¿Qué es un cloud crawler? El siguiente paso en el descubrimiento de datos
Vamos a dejarlo claro: un cloud crawler no es simplemente un web scraper que vive en la nube. Se parece más a un motor de descubrimiento de datos: un sistema inteligente basado en la nube, diseñado para encontrar, extraer y analizar automáticamente grandes volúmenes de datos en internet. Mientras que un web scraper tradicional toma información de unas pocas páginas (muchas veces de una en una y normalmente desde un solo dispositivo), un cloud crawler juega en otra liga. Funciona en potentes centros de datos en la nube, recorriendo miles —o incluso millones— de páginas al mismo tiempo, y puede procesarlo todo: texto, imágenes, PDFs y mucho más, sin importar lo compleja o extensa que sea la web objetivo.
Piénsalo así: si un web scraper es como un bibliotecario copiando fragmentos de un libro, un cloud crawler es como un equipo de superordenadores escaneando todos los libros de la biblioteca a la vez, etiquetando, organizando y analizando el contenido sobre la marcha. ¿El resultado? Las empresas consiguen datos más ricos, más frescos y más útiles para tomar decisiones, sin los cuellos de botella del hardware local ni el trabajo manual (, ).
Cloud crawler vs. web scraper tradicional: ¿cuál es la diferencia real?
Si alguna vez has usado un web scraper, ya conoces lo básico: lo apuntas a una página, defines lo que quieres y dejas que extraiga los datos. Pero conforme la web se hace más grande y más compleja, el enfoque de siempre empieza a quedarse corto. Así se comparan los cloud crawlers y los web scrapers tradicionales:
| Característica/Aspecto | Web Scraper Tradicional | Cloud Crawler |
|---|---|---|
| Implementación | Se ejecuta en tu dispositivo local o en un servidor | Se ejecuta en la nube (centros de datos remotos) |
| Escala | Limitado por la potencia de tu equipo | Procesamiento masivamente paralelo: miles de páginas a la vez |
| Velocidad | Más lento, especialmente en trabajos grandes | Procesamiento por lotes de alta velocidad |
| Mantenimiento | Requiere actualizaciones frecuentes y se rompe con cambios en el sitio | Basado en la nube, se actualiza automáticamente y es menos frágil |
| Tipos de datos | Normalmente texto, a veces imágenes | Texto, imágenes, PDFs, diseños complejos |
| Acceso | Depende de tu dispositivo o red | Accesible desde cualquier lugar y cualquier dispositivo |
| Programación | Manual o automatización básica | Programación avanzada, tareas recurrentes |
| Ideal para | Proyectos pequeños, sitios sencillos | Necesidades de datos complejas, frecuentes o a gran escala |
Los cloud crawlers están pensados para la web moderna, donde los datos están por todos lados y la velocidad y la escala no son negociables (, ).
Cómo los cloud crawlers disparan la eficiencia de la recopilación de datos
Aquí es donde la cosa se pone buena. Los cloud crawlers aprovechan la potencia de la computación en la nube para procesar miles de páginas web en paralelo. Eso significa que puedes extraer un catálogo completo de ecommerce, monitorizar precios de la competencia en decenas de sitios o recopilar anuncios inmobiliarios de todos los grandes portales, todo en una fracción del tiempo que te llevaría con un scraper tradicional.
¿Por qué importa esto? Porque en sectores como ecommerce, finanzas e inmobiliaria, tener datos frescos lo es todo. Los precios, el inventario y las tendencias del mercado pueden cambiar minuto a minuto. Esperar horas —o días— a que termine un scraper local simplemente no es una opción. Los cloud crawlers no están limitados por la RAM de tu portátil ni por el Wi‑Fi de la oficina: escalan según lo que necesites, para que puedas afrontar trabajos enormes sin despeinarte (, ).
Los sectores que más se benefician de esta eficiencia incluyen:
- Ecommerce: seguimiento de precios, agregación de catálogos de productos, análisis de reseñas
- Inmobiliaria: recopilación de anuncios, seguimiento de tendencias del mercado, comparación de propiedades
- Finanzas: análisis de noticias y sentimiento, monitorización de acciones y cripto, seguimiento regulatorio
- Ventas y marketing: generación de leads, investigación de la competencia, detección de tendencias
Y, siendo sinceros, eso es solo la punta del iceberg. Si necesitas datos web a gran escala, un cloud crawler se convierte en un aliado de primera.
La solución cloud crawler de Thunderbit: rápida, flexible y potente
Déjame ponerme el sombrero de Thunderbit un momento (aunque, la verdad, nunca me lo quito del todo). El modo de scraping en la nube de es nuestra respuesta al reto moderno de los datos: un cloud crawler diseñado para usuarios de negocio que quieren resultados, no complicaciones.
Esto es lo que hace destacar al cloud crawler de Thunderbit:
- Scraping por lotes a alta velocidad: extrae hasta 50 páginas a la vez, con servidores en la nube en EE. UU., la UE y Asia para un alcance global. Se acabó esperar a que tu portátil procese una lista interminable.
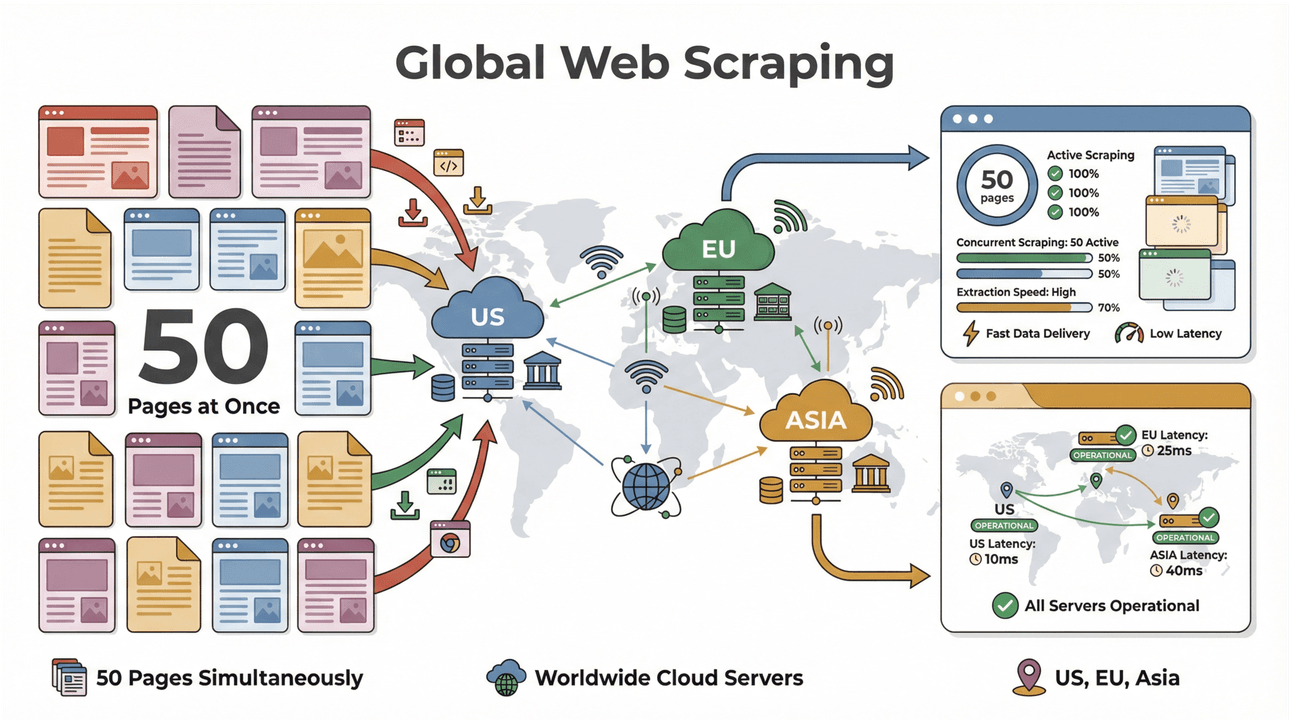
- Compatibilidad con páginas complejas: la IA de Thunderbit puede con todo, desde sitios de ecommerce dinámicos hasta PDFs complicados e incluso extracción de imágenes. Si está en la web, Thunderbit probablemente puede extraerlo ().
- Rastreo de subpáginas: ¿Necesitas enriquecer tus datos con detalles de subpáginas, como especificaciones de productos o biografías de autores? La IA de Thunderbit puede entrar en cada subpágina y fusionar los resultados en tu conjunto de datos principal ().
- Estructuración inteligente de datos: usa “AI Suggest Fields” para que Thunderbit lea el sitio y te recomiende las mejores columnas, sin necesidad de código ni plantillas.
- Exportación a cualquier lugar: envía tus datos directamente a Excel, Google Sheets, Airtable o Notion. O descárgalos en CSV/JSON, según te convenga más en tu flujo de trabajo ().
- Sin mantenimiento: la IA de Thunderbit se adapta a los cambios del sitio web, así que no tendrás que estar arreglando scrapers rotos todo el tiempo ().
Y sí, puedes probar todo esto con un , así que no hace falta que me creas solo porque lo diga yo.
Implementación de cloud crawler: nube vs. local, ¿cuál te conviene?
Una de las mayores ventajas de los cloud crawlers es la flexibilidad de implementación. Con un crawler tradicional (local), dependes de un dispositivo concreto, una red específica y, muchas veces, de bastantes dolores de cabeza para configurarlo. Si tu ordenador se suspende o se cae internet, el scraping se detiene. Y escalar significa comprar más hardware o ejecutar varios scripts.
Los cloud crawlers cambian el enfoque por completo:
- No hace falta hardware especial: todo el trabajo pesado ocurre en la nube. Puedes lanzar scrapes masivos desde un Chromebook, un Mac o incluso tu teléfono.
- Acceso desde cualquier lugar: ¿viajando? ¿trabajando en remoto? No pasa nada: tu cloud crawler siempre está disponible.
- Escalado sencillo: ¿necesitas extraer 10.000 páginas en lugar de 100? Solo amplías el trabajo, sin depender de IT.
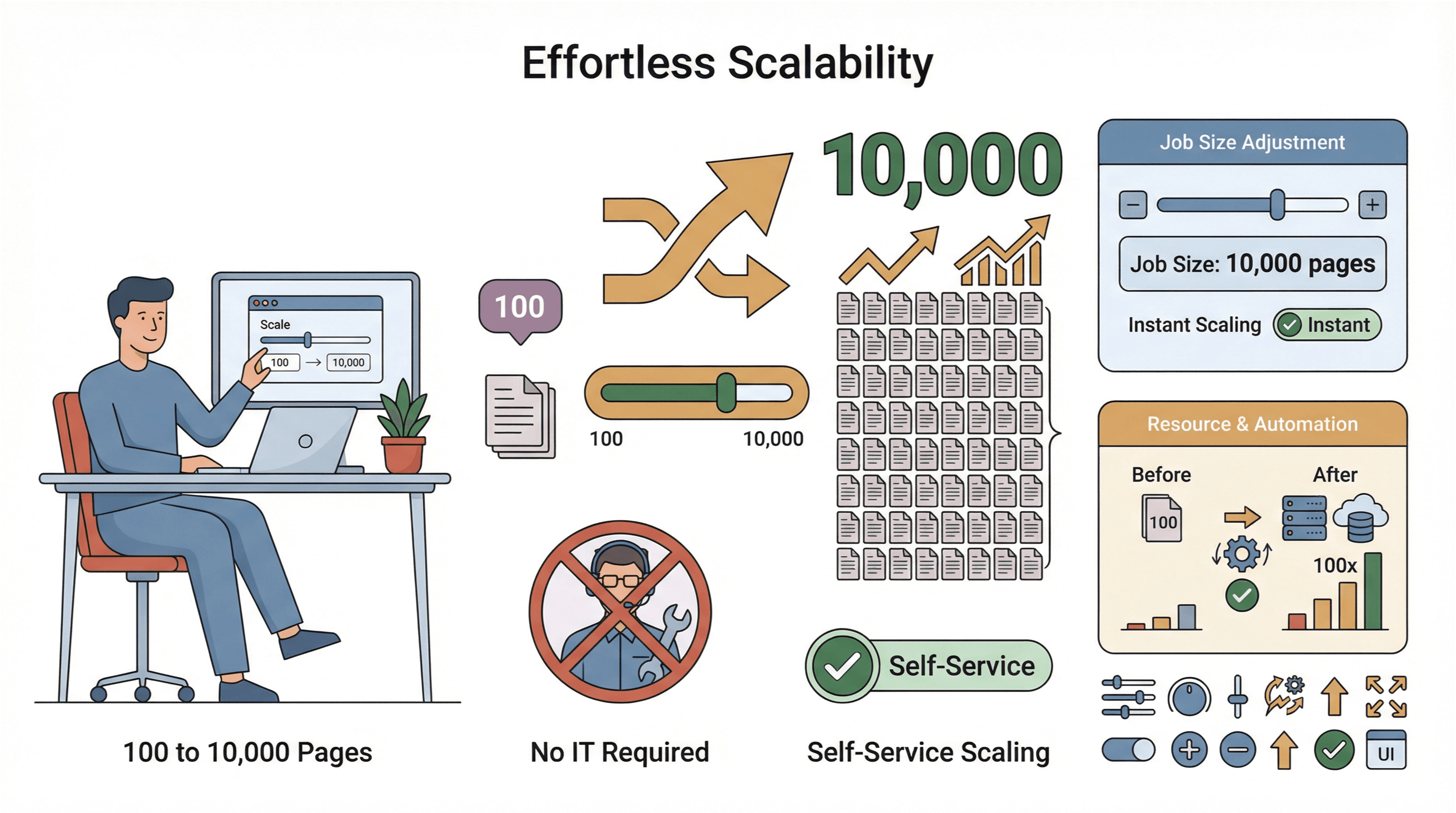
- Recopilación global de datos: con servidores en la nube en varias regiones, puedes acceder a contenido con restricciones geográficas y manejar mejor el cumplimiento ().
Por supuesto, la seguridad y el cumplimiento normativo siempre van primero. Los mejores cloud crawlers (incluido Thunderbit) usan conexiones cifradas, respetan los términos de los sitios web y ofrecen funciones para ayudarte a manejar datos sensibles de forma responsable.
Impacto real: cómo los cloud crawlers están transformando las estrategias basadas en datos
Vamos a lo práctico. ¿Por qué las empresas están migrando a los cloud crawlers? Porque están viendo resultados reales y medibles:
- Análisis de mercado en tiempo real: los minoristas usan cloud crawlers para monitorizar precios e inventario de la competencia en tiempo real, lo que permite precios dinámicos y respuestas más rápidas a los cambios del mercado ().
- Predicción de tendencias de consumo: las marcas agregan reseñas, publicaciones en redes sociales y conversaciones en foros para detectar tendencias emergentes y ajustar campañas sobre la marcha.
- Ventas y generación de leads: los equipos comerciales crean listas de leads actualizadas desde directorios, sitios de eventos e incluso PDFs, alimentando los CRM con contactos frescos y cualificados ().
- Operaciones y cumplimiento: las entidades financieras usan cloud crawlers para seguir actualizaciones regulatorias, noticias y presentaciones en múltiples jurisdicciones, reduciendo riesgos y adelantándose a los cambios.
El patrón común es clarísimo: los cloud crawlers permiten a los equipos moverse más rápido, tomar decisiones más inteligentes y dejar atrás a competidores que siguen atascados en el carril lento.
Funciones clave que debes buscar en un cloud crawler
No todos los cloud crawlers son iguales. Si estás comparando opciones, estas son las funciones que más importan (y donde Thunderbit destaca):
- Escalabilidad: ¿puede manejar miles de páginas a la vez? ¿Se ralentiza cuando sube la carga?
- Facilidad de uso: ¿la interfaz es amigable para usuarios no técnicos? ¿Puedes configurar un scraping en unos pocos clics?
- Compatibilidad con múltiples tipos de datos: texto, imágenes, PDFs, subpáginas, ¿lo soporta todo?
- Integraciones: ¿exporta a tus herramientas favoritas (Excel, Sheets, Notion, Airtable)?
- Programación: ¿puedes automatizar tareas recurrentes para tener datos siempre frescos?
- Asistencia con IA: ¿ofrece sugerencias inteligentes de campos, enriquecimiento de datos y adaptación automática a cambios del sitio?
- Seguridad y cumplimiento: ¿están protegidos tus datos y credenciales? ¿Ayuda a cumplir con las leyes de privacidad?
Thunderbit cumple con todos estos puntos, lo que lo convierte en una de las mejores opciones para equipos que quieren potencia sin dolores de cabeza.
Cómo empezar: usar un cloud crawler en tu negocio
¿Listo para empezar? Así es como un usuario de negocio típico puede arrancar con un cloud crawler como Thunderbit:
- Instala la : configuración rápida, sin necesidad de IT.
- Elige tu objetivo: abre el sitio web, listado o documento que quieras extraer.
- Haz clic en “AI Suggest Fields”: deja que la IA de Thunderbit analice la página y te recomiende las mejores columnas para extraer.
- Personaliza según necesites: añade, elimina o renombra campos para ajustarlos a tu caso.
- Selecciona el modo de scraping en la nube: para trabajos grandes o sitios complejos, cambia a modo cloud para obtener la máxima velocidad.
- Lanza el scraping: Thunderbit procesará hasta 50 páginas a la vez en la nube.
- Revisa y exporta: previsualiza los resultados y luego expórtalos a Excel, Google Sheets, Notion o Airtable.
- Programa tareas recurrentes: para necesidades continuas, configura scrapes programados; tus datos se actualizarán automáticamente ().
Consejo: empieza con una tarea pequeña para familiarizarte con la herramienta y luego sube la carga cuando te sientas cómodo. Y no dudes en usar el soporte o la documentación de Thunderbit: están para echarte una mano.
El futuro de la recopilación de datos: ¿qué viene para los cloud crawlers?
La revolución de los cloud crawlers apenas está empezando. Esto es lo que sigo de cerca para los próximos años:
- Extracción de IA más inteligente: los cloud crawlers cada vez entienden mejor el contexto, las relaciones e incluso el sentimiento, lo que hace que los datos que recopilan sean más valiosos ().
- Compatibilidad con nuevos tipos de datos: se espera una mejor gestión de vídeo, audio y contenido interactivo, no solo texto e imágenes estáticas.
- Automatización más profunda: desde la programación automática hasta alertas en tiempo real, los cloud crawlers serán cada vez más autónomos para los usuarios de negocio.
- Cumplimiento reforzado: a medida que evolucionen las leyes de privacidad, los cloud crawlers incorporarán más herramientas para ayudar a los equipos a mantenerse dentro de la normativa.
- Integración con herramientas de BI e IA: canales directos desde cloud crawlers hacia plataformas de analítica, dashboards y machine learning.
En resumen, los cloud crawlers están llamados a convertirse en la columna vertebral de la estrategia digital empresarial, impulsando desde lanzamientos de productos hasta previsiones apoyadas por IA ().
Conclusión: por qué los cloud crawlers son esenciales para las empresas modernas
En resumen: la web está explotando en cantidad de datos, y las formas antiguas de recopilarlos ya no dan la talla. Los cloud crawlers son la siguiente evolución: ofrecen velocidad, escala e inteligencia que los scrapers tradicionales simplemente no pueden igualar. Herramientas como hacen posible que cualquier equipo, técnico o no, aproveche todo el potencial de los datos web, impulsando decisiones más inteligentes, respuestas más rápidas y una ventaja competitiva real.
Si estás listo para dejar atrás el scraping manual y los procesos lentos, ahora es el momento de descubrir lo que un cloud crawler puede hacer por tu negocio. Prueba el modo de scraping en la nube de Thunderbit y comprueba lo fácil —y potente— que puede ser el descubrimiento de datos moderno. Y si quieres profundizar, visita el para encontrar más guías, consejos y ejemplos reales.
Preguntas frecuentes
1. ¿Qué es un cloud crawler en términos sencillos?
Un cloud crawler es una herramienta basada en la nube que descubre, extrae y analiza automáticamente grandes cantidades de datos de la web. A diferencia de los scrapers tradicionales que se ejecutan en tu dispositivo local, los cloud crawlers funcionan en potentes centros de datos, lo que permite una escala y velocidad enormes.
2. ¿En qué se diferencia un cloud crawler de un web scraper normal?
Los cloud crawlers se ejecutan en la nube, manejan miles de páginas a la vez, admiten tipos de datos complejos como imágenes y PDFs, y no requieren mantenimiento ni hardware local. Los scrapers tradicionales están limitados por la potencia de tu equipo y son mejores para trabajos más pequeños y sencillos.
3. ¿Cuáles son las principales ventajas de usar un cloud crawler?
Los cloud crawlers ofrecen recopilación de datos a gran velocidad y escala, compatibilidad con sitios web complejos, acceso sencillo desde cualquier lugar y funciones avanzadas como programación y extracción con IA. Son ideales para empresas que necesitan datos frescos y accionables con rapidez.
4. ¿Cómo funciona el cloud crawler de Thunderbit para usuarios de negocio?
El cloud crawler de Thunderbit te permite configurar un scraping en solo unos clics, sin necesidad de programar. Puedes extraer datos de sitios web, PDFs e imágenes, enriquecerlos con IA y exportarlos directamente a Excel, Google Sheets, Notion o Airtable. Está pensado para usuarios no técnicos que buscan resultados, no complejidad.
5. ¿El cloud crawling es seguro y cumple con las leyes de privacidad de datos?
Sí, los principales cloud crawlers como Thunderbit usan conexiones cifradas y buenas prácticas de seguridad. Asegúrate siempre de extraer solo datos de acceso público y de respetar los términos de uso de los sitios web y las normativas de privacidad.
¿Listo para ver lo que puede hacer un cloud crawler? y empieza hoy mismo a explorar el mundo de la recopilación de datos a gran escala impulsada por la nube.
Más información