

"Puedes tener datos sin información, pero no puedes tener información sin datos." — Daniel Keys Moran*
Más de 1.500 millones de sitios web pueblan internet, con unos 2 millones de publicaciones nuevas cada día. Detrás de esa cifra se esconde un filón para la toma de decisiones, pero con un problema serio: cerca del 80% de esa información no está estructurada. Sin un procesamiento previo, no sirve de mucho. Aquí es donde las herramientas de web scraping marcan la diferencia — son la vía más directa para convertir ese caos en datos aprovechables.
Si nunca has trabajado con web scraping, conceptos como componentes web o HTML pueden sonar intimidantes. Pero en 2026, con la irrupción de la IA, la barrera técnica ha bajado drásticamente. Las herramientas actuales permiten recopilar y estructurar datos sin tocar una línea de código.
Las mejores herramientas y software de web scraping
- Thunderbit para extraer datos web con IA de forma sencilla y con resultados de calidad
- Browse AI para monitorizar cambios en tiempo real y extracciones masivas
- Bardeen AI para automatización sin código con integraciones amplias
- Web Scraper para scraping visual dirigido a usuarios con experiencia
- Octoparse para scraping sin código con evasión de bloqueos de IP y detección de bots
- Diffbot para extracción avanzada de datos por API con IA y grafos de conocimiento
Prueba la IA para hacer web scraping
Haz clic, explora y ejecuta el flujo de trabajo mientras lo ves.
¿Cómo funciona el web scraping?
El web scraping consiste en extraer datos de páginas web de forma automatizada. Le das instrucciones a una herramienta y esta se encarga de recoger texto, imágenes o cualquier dato que necesites, volcándolo en una tabla ordenada. Es útil para todo: desde rastrear precios en tiendas online hasta recopilar datos de investigación o montar una hoja de cálculo en Excel o Google Sheets.
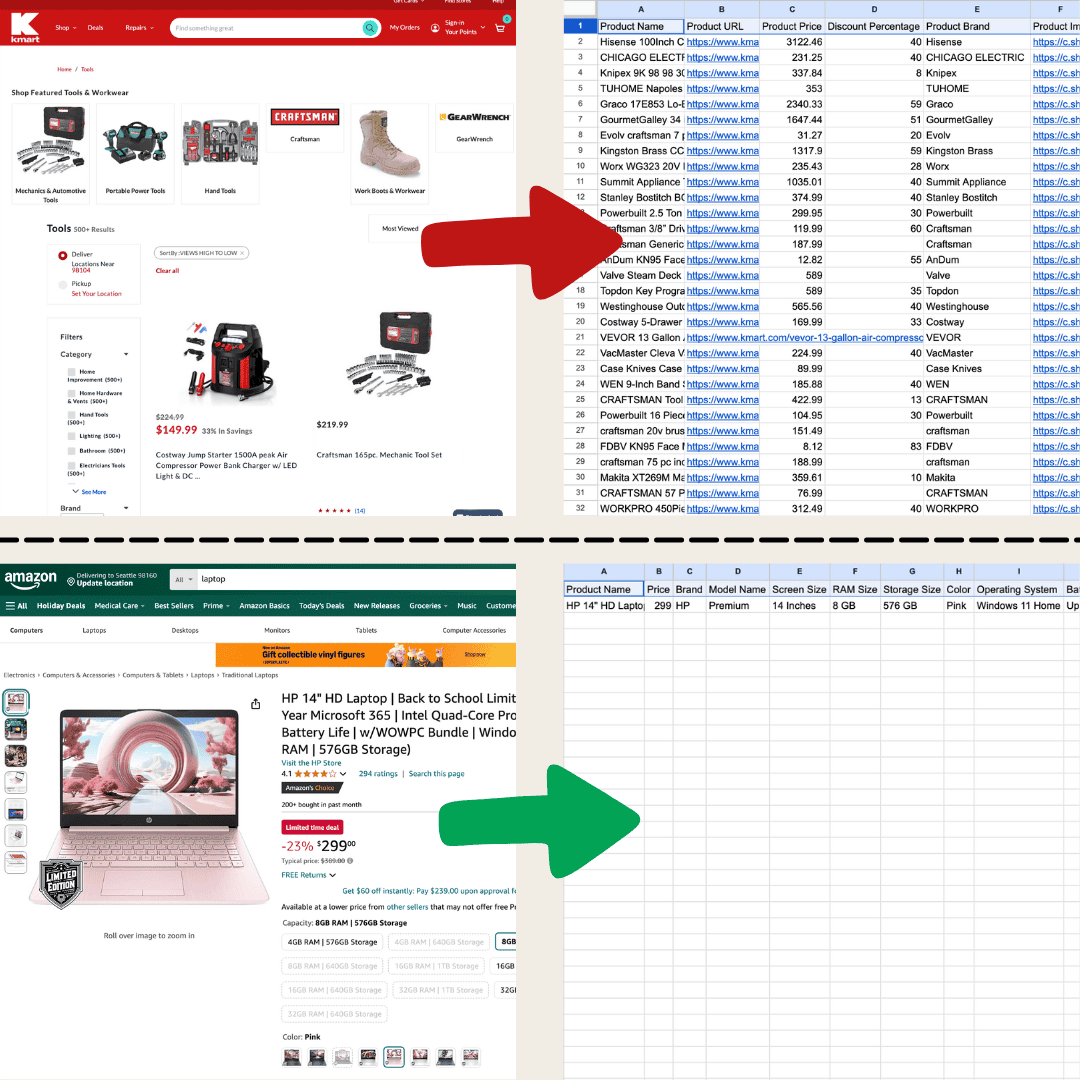 Hice esto con Thunderbit usando el Raspador Web IA.
Hice esto con Thunderbit usando el Raspador Web IA.
Existen varias formas de abordar el proceso. La más rudimentaria es copiar y pegar a mano, pero con volúmenes grandes resulta inviable. Por eso la mayoría recurre a uno de estos tres caminos: raspadores web tradicionales, raspadores web IA o código personalizado.
Los raspadores web tradicionales operan con reglas fijas sobre qué datos capturar según la estructura HTML de la página. Por ejemplo, puedes configurarlos para extraer nombres de productos o precios a partir de etiquetas concretas. Funcionan bien en sitios estables, pero cualquier cambio en el diseño obliga a revisar y ajustar el raspador.
 Un raspador tradicional exige un tiempo de aprendizaje considerable y probablemente decenas de clics para completar la configuración.
Un raspador tradicional exige un tiempo de aprendizaje considerable y probablemente decenas de clics para completar la configuración.
Extrae datos de cualquier sitio web con IA Get Started Free
Los raspadores web IA funcionan de forma distinta: la IA analiza el contenido de la página y extrae la información según lo que le pidas. Puede encargarse de la extracción, la traducción y el resumen en un solo paso. Gracias al procesamiento de lenguaje natural, interpretan la estructura del sitio y se adaptan a los cambios sin que tengas que reconfigurar nada. Si la web reorganiza sus secciones, un raspador IA puede ajustarse solo. Por eso son la mejor opción para sitios que cambian con frecuencia o tienen estructuras complejas.
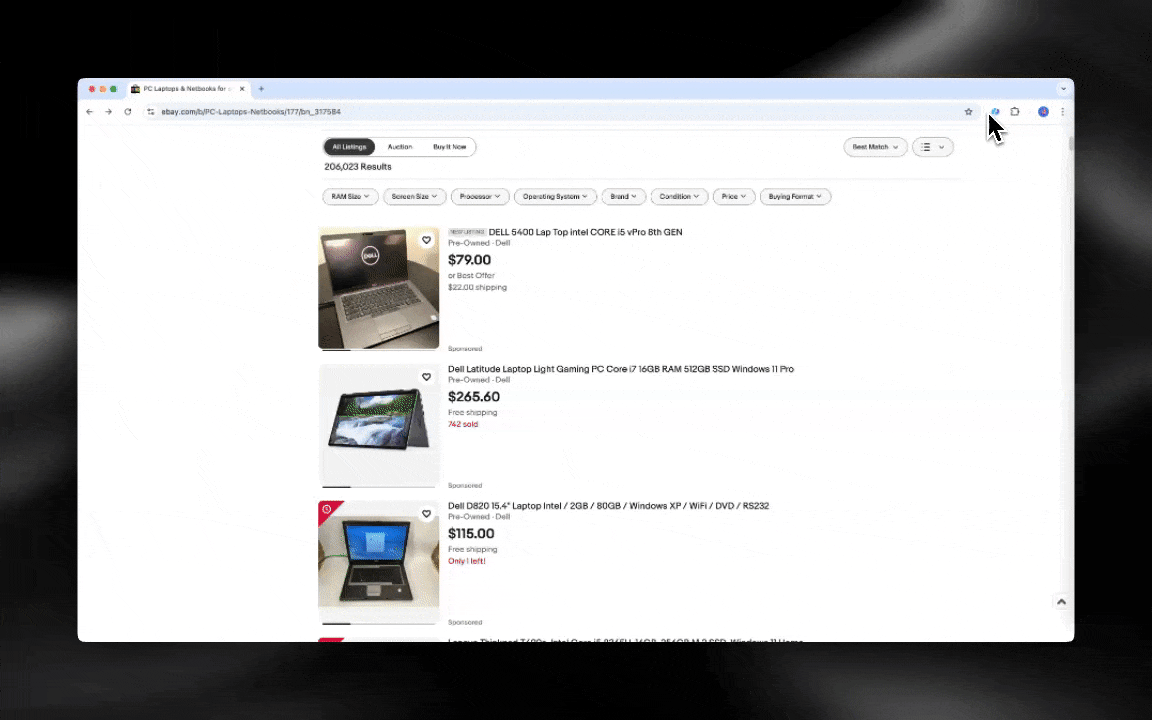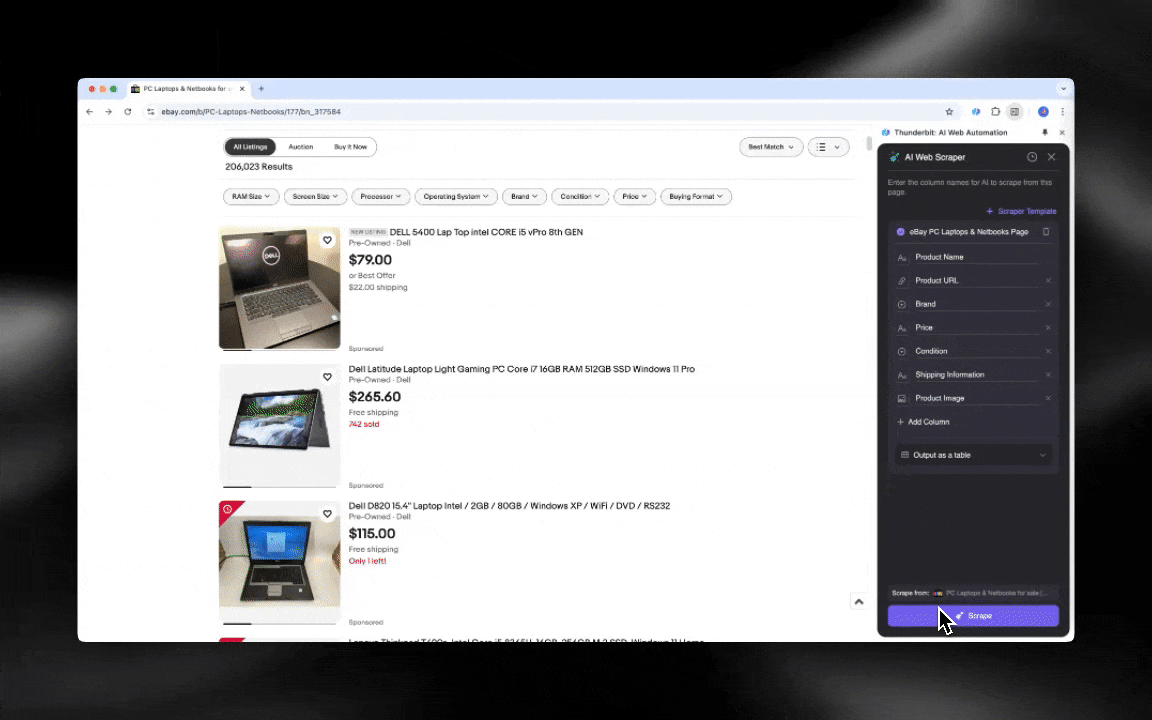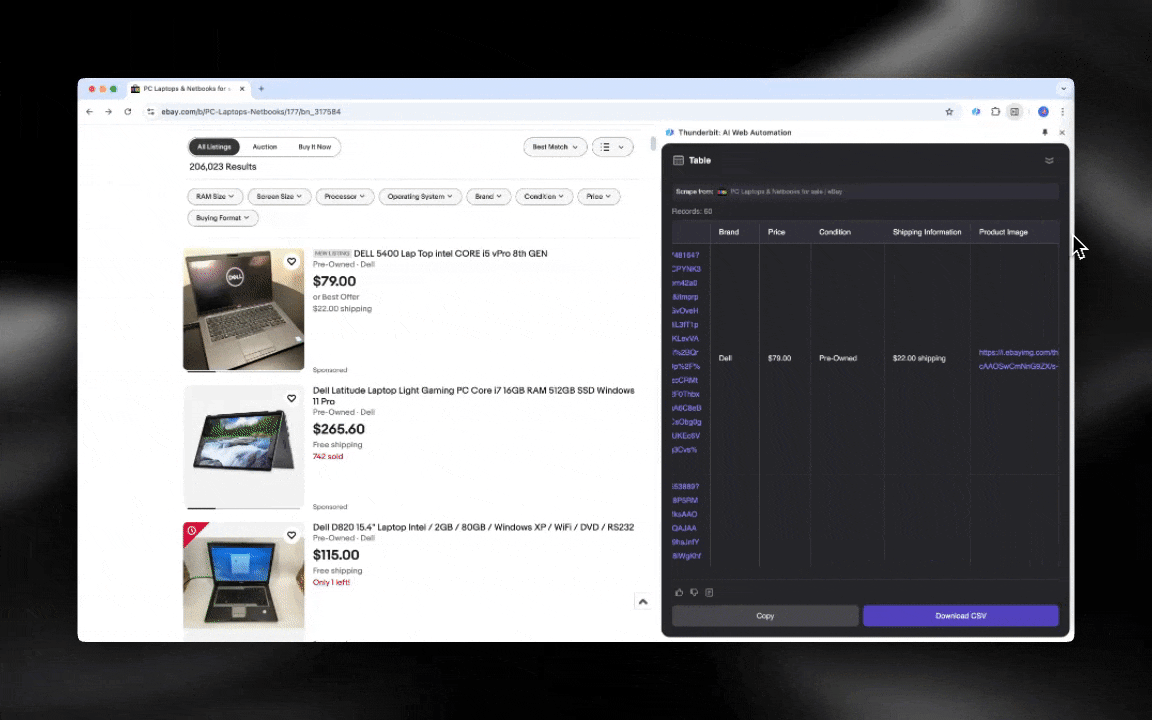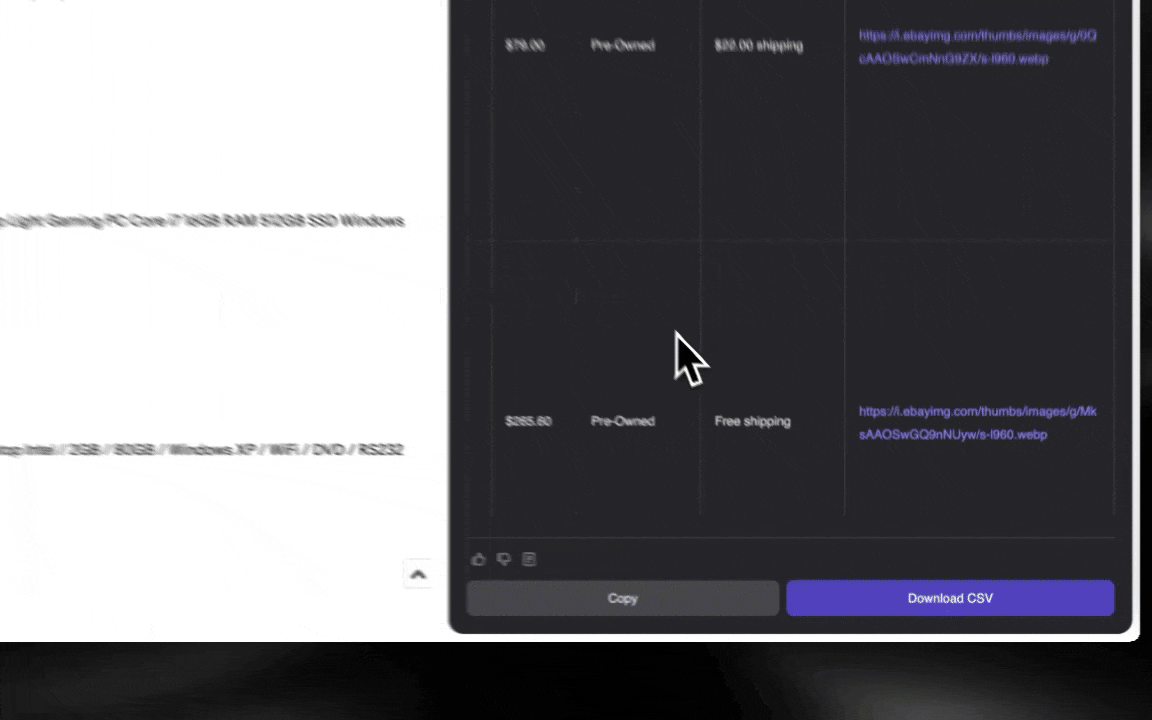 El Raspador Web IA es fácil de usar desde el primer momento y te da datos detallados en pocos clics.
El Raspador Web IA es fácil de usar desde el primer momento y te da datos detallados en pocos clics.
¿Cuál te conviene más? Depende del caso. Si manejas código o necesitas volúmenes enormes de un sitio conocido, los raspadores tradicionales pueden ser eficientes. Pero si estás empezando o quieres algo que se adapte a las actualizaciones del sitio, los raspadores IA suelen ser la opción más práctica. La tabla siguiente detalla los escenarios más habituales.
| Escenario | Mejor opción |
|---|---|
| Scraping ligero en páginas como directorios, tiendas en línea o cualquier sitio con listados | Raspador Web IA |
| La página tiene menos de 200 filas de datos y crear un raspador con uno tradicional lleva demasiado tiempo | Raspador Web IA |
| Los datos que necesitas extraer deben tener un formato concreto para subirlos a otro sitio. Por ejemplo: extraer información de contacto para subirla a HubSpot. | Raspador Web IA |
| Sitios de uso masivo, como decenas de miles de páginas de productos de Amazon o listados inmobiliarios de Zillow. | Raspador Web tradicional |
Las mejores herramientas y software de web scraping de un vistazo
| Herramienta | Precio | Funciones clave | Ventajas | Desventajas |
|---|---|---|---|---|
| Thunderbit | Desde 9 $/mes, con plan gratuito disponible | Raspador web IA, detecta y formatea datos automáticamente, admite varios formatos, exportación con un clic, interfaz fácil de usar. | Sin código, compatibilidad con IA, integraciones con apps como Google Sheets | El scraping a gran escala puede ser lento, y las funciones avanzadas pueden costar más |
| Browse AI | Desde 48,75 $/mes, con plan gratuito disponible | Interfaz sin código, monitorización en tiempo real, extracción masiva de datos, integración de flujos de trabajo. | Fácil de usar, se integra con Google Sheets y Zapier | Las páginas complejas necesitan configuración extra, el scraping masivo puede provocar tiempos de espera |
| Bardeen AI | Desde 60 $/mes, con plan gratuito disponible | Automatización sin código, se integra con más de 130 apps, MagicBox convierte tareas en flujos de trabajo. | Amplias integraciones, escalable para empresas | Curva de aprendizaje pronunciada para nuevos usuarios, configuración que lleva tiempo |
| Web Scraper | Gratis para uso local, 50 $/mes para la nube | Creación visual de tareas, admite sitios dinámicos (AJAX/JavaScript), scraping en la nube. | Funciona muy bien en sitios dinámicos | Requiere conocimientos técnicos para una configuración óptima |
| Octoparse | Desde 119 $/mes, con plan gratuito disponible | Scraping sin código, detección automática de elementos de la página, scraping en la nube con tareas programadas, biblioteca de plantillas para sitios comunes. | Funciones potentes para sitios dinámicos, gestiona restricciones | Los sitios complejos requieren aprendizaje |
| Diffbot | Desde 299 $/mes | API de extracción de datos, API sin reglas, NLP para texto no estructurado, amplio grafo de conocimiento. | Potente extracción con IA, amplia integración por API, scraping a gran escala | Curva de aprendizaje para usuarios no técnicos, tiempo de configuración |
El mejor raspador web en la era de la IA
Thunderbit
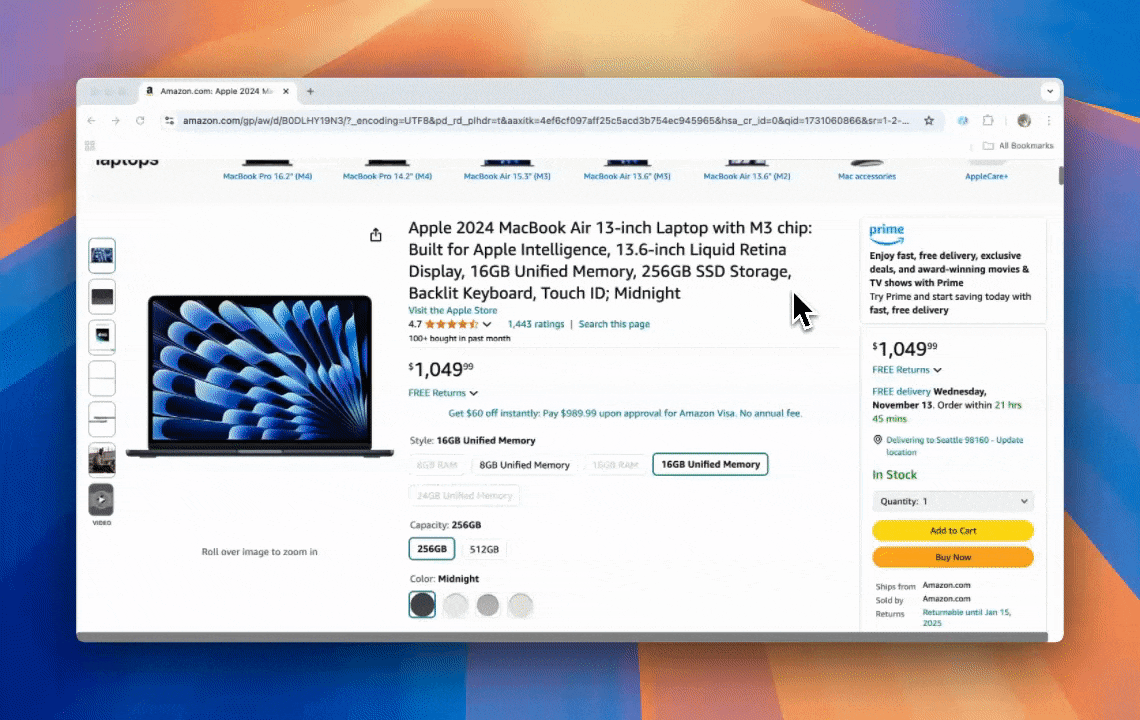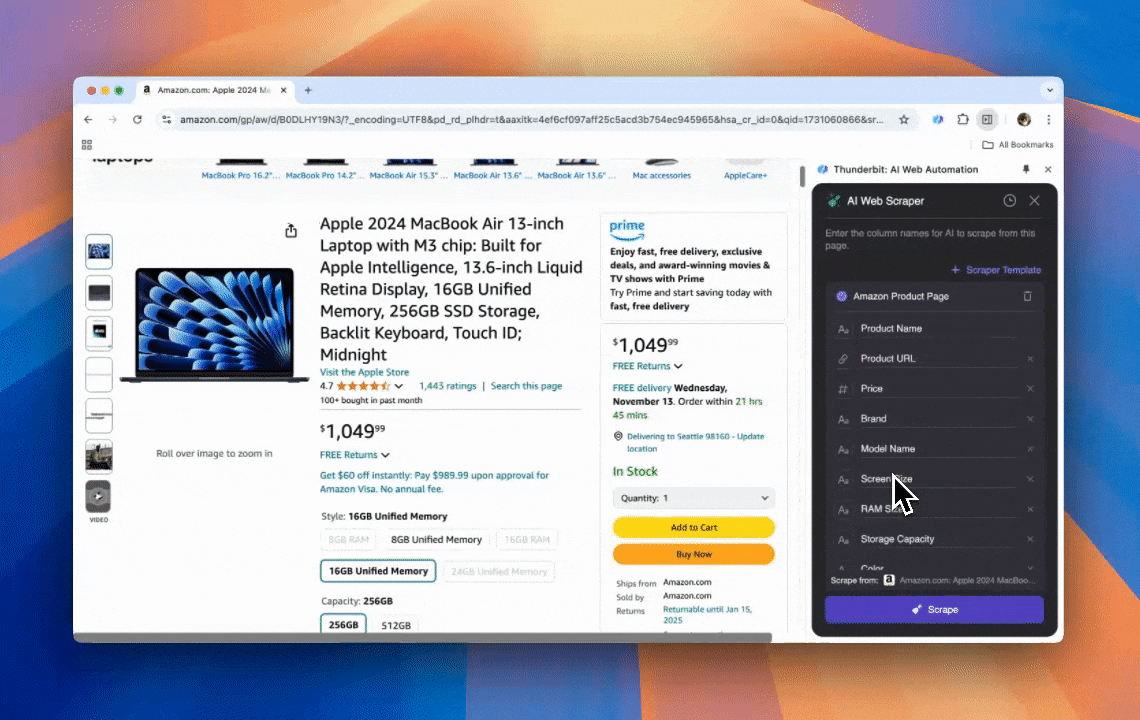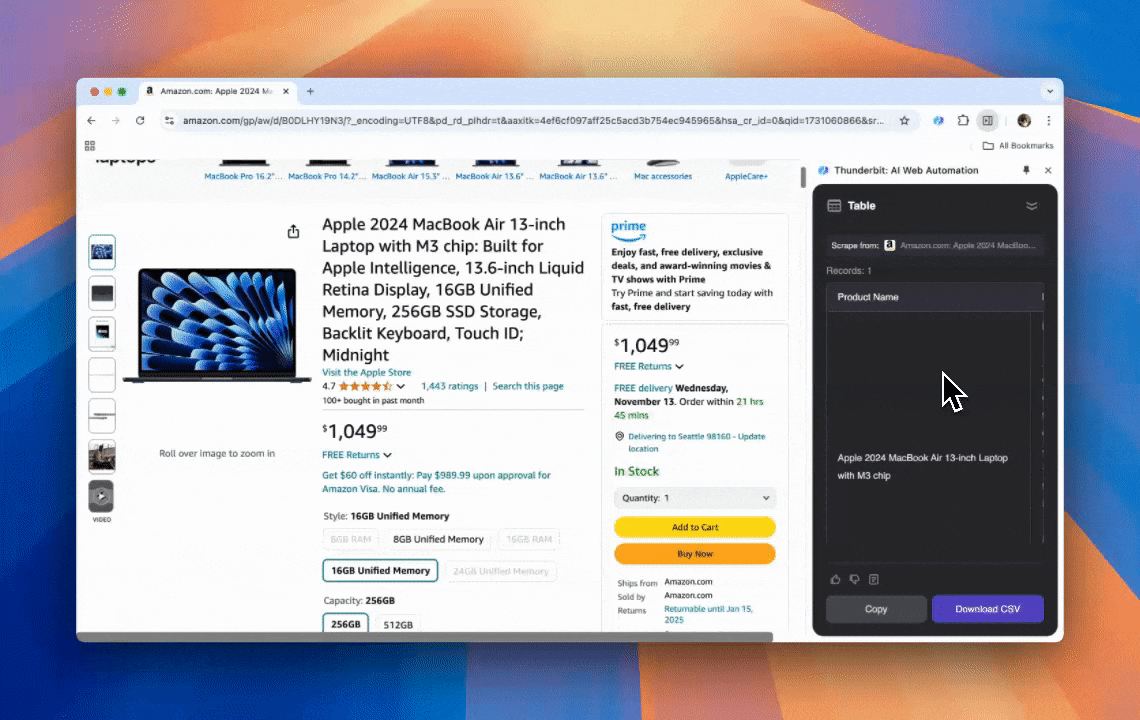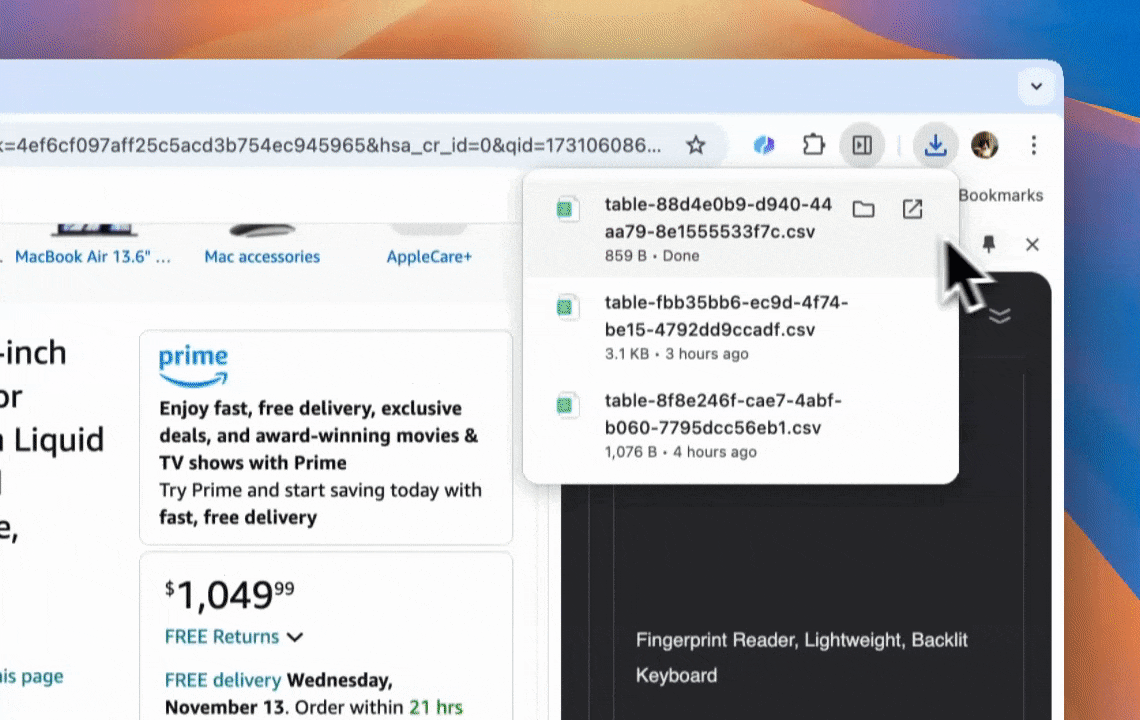
Thunderbit es una herramienta de automatización web con IA que permite extraer y organizar datos sin necesidad de programar. A través de su extensión de Chrome, el Raspador Web IA simplifica todo el proceso: los usuarios obtienen datos web sin tener que interactuar manualmente con los elementos de la página ni montar raspadores distintos para cada diseño.
Funciones clave
- Flexibilidad con IA: el Raspador Web IA detecta y formatea los datos automáticamente, sin necesidad de selectores CSS.
- Experiencia de scraping directa: solo tienes que pulsar "AI suggest column" y luego "Scrape" en la página objetivo. Nada más.
- Varios formatos de datos: extrae URLs, imágenes y muestra los resultados en múltiples formatos.
- Procesamiento automatizado: la IA reformatea los datos sobre la marcha — resúmenes, categorización y traducción incluidos.
- Exportación sencilla: envía datos a Google Sheets, Airtable o Notion con un clic.
- Interfaz intuitiva: accesible para cualquier nivel de experiencia.
Precio
Thunderbit tiene planes desde 9 $/mes por 5.000 créditos, hasta 199 $ por 240.000 créditos. Con el plan anual, recibes todos los créditos por adelantado.
Ventajas:
- La IA simplifica tanto la extracción como el procesamiento de datos.
- Sin código, accesible para cualquier perfil.
- Ideal para scraping ligero: directorios, tiendas online, listados.
- Exportación directa a las apps más populares.
Desventajas:
- Las extracciones a gran escala pueden tardar más para garantizar la precisión.
- Algunas funciones avanzadas requieren suscripción de pago.
¿Quieres saber más? Empieza por instalar Thunderbit, o descubre cómo extraer sitios web de forma sencilla con Thunderbit.
Mejor raspador web para monitorización de datos y extracción masiva
Browse AI
Browse AI es una herramienta de scraping sin código pensada para extraer y monitorizar datos sin escribir una sola línea de código. Incorpora algunas funciones de IA, aunque no alcanza el nivel de un scraping completamente basado en inteligencia artificial. Aun así, facilita mucho el arranque para la mayoría de usuarios.
Funciones clave
- Interfaz sin código: permite crear flujos de trabajo personalizados con unos pocos clics.
- Monitorización en tiempo real: emplea bots para rastrear cambios en una página web y entregar información actualizada.
- Extracción masiva: gestiona hasta 50.000 registros en una sola ejecución.
- Integración de flujos de trabajo: conecta varios bots para un procesamiento de datos más elaborado.
Precio
Desde 48,75 $/mes con 2.000 créditos incluidos. El plan gratuito ofrece 50 créditos al mes para probar las funciones básicas.
Ventajas:
- Integraciones con Google Sheets y Zapier.
- Los bots preconfigurados simplifican las tareas habituales de extracción.
Desventajas:
- Puede exigir configuración adicional para páginas complejas.
- La velocidad del scraping masivo varía y puede provocar tiempos de espera.
Mejor raspador web para integración de flujos de trabajo
Bardeen AI
Bardeen AI es una herramienta de automatización sin código diseñada para conectar distintas aplicaciones y agilizar flujos de trabajo. Usa IA para crear automatizaciones personalizadas, aunque no tiene la adaptabilidad de una herramienta de scraping con IA completa.
Funciones clave
- Automatización sin código: crea flujos de trabajo con clics.
- MagicBox: describe tareas en lenguaje natural y Bardeen AI las convierte en flujos automatizados.
- Amplias integraciones: se conecta con más de 130 apps, entre ellas Google Sheets, Slack y LinkedIn.
Precio
Desde 60 $/mes con 1.500 créditos (unas 1.500 filas de datos). El plan gratuito incluye 100 créditos al mes para probar las funciones básicas.
Ventajas:
- Las integraciones disponibles cubren necesidades empresariales muy variadas.
- Escalable para empresas de cualquier tamaño.
Desventajas:
- Los nuevos usuarios pueden necesitar tiempo para dominar la plataforma.
- La configuración inicial lleva su tiempo.
Mejor raspador web visual para personas con experiencia
Web Scraper
Sí, la herramienta se llama literalmente "Web Scraper". Es una extensión popular para Chrome y Firefox que permite extraer datos sin programar, con un enfoque visual para configurar las tareas de scraping. Eso sí, dominarla exige dedicarle unas horas a los tutoriales. Si prefieres algo más directo, el Raspador Web IA es una alternativa más ágil.
Funciones clave
- Creación visual: configura tareas de scraping seleccionando elementos en la página.
- Compatibilidad con sitios dinámicos: gestiona solicitudes AJAX y JavaScript.
- Scraping en la nube: programa tareas periódicas a través de Web Scraper Cloud.
Precio
Gratis para uso local; los planes de pago arrancan en 50 $/mes para funciones en la nube.
Ventajas:
- Gran rendimiento en sitios dinámicos.
- Gratis para uso local.
Desventajas:
- Requiere conocimientos técnicos para sacarle el máximo partido.
- Necesita pruebas detalladas antes de aplicar cambios.
Mejor raspador web para evitar el bloqueo de IP y la detección de bots
Octoparse
Octoparse es un software versátil dirigido a usuarios técnicos que necesitan recopilar y monitorizar datos web a gran escala sin código. A diferencia de otras herramientas, no depende del navegador del usuario: utiliza servidores en la nube para la extracción, lo que le permite ofrecer métodos para sortear bloqueos de IP y parte de la detección antibots de los sitios web.
Funciones clave
- Sin código: crea tareas de scraping sin escribir código, accesible para distintos perfiles técnicos.
- Detección automática inteligente: identifica los datos de la página y localiza los elementos disponibles para extraer, simplificando la configuración.
- Scraping en la nube: extracción 24/7 con tareas programadas para una recuperación flexible de datos.
- Biblioteca de plantillas: cientos de plantillas predefinidas para acceder a datos de sitios populares sin una configuración compleja.
Precio
Desde 119 $/mes con 100 tareas incluidas. El plan gratuito ofrece 10 tareas al mes para probar las funciones básicas.
Ventajas:
- Funciones potentes para scraping en sitios dinámicos con buena adaptabilidad.
- Ofrece soluciones para gestionar restricciones de scraping y contenido dinámico.
Desventajas:
- Las estructuras web complejas pueden requerir más tiempo de configuración.
- Los nuevos usuarios necesitan un período de adaptación.
Mejor raspador web para una API avanzada de extracción de datos con IA
Diffbot
Diffbot es una herramienta avanzada de extracción de datos que emplea IA para transformar contenido web no estructurado en datos estructurados. Gracias a sus APIs y su grafo de conocimiento, permite extraer, analizar y gestionar información de la web a escala, adaptándose a múltiples sectores y aplicaciones.
Funciones clave
- API de extracción sin reglas: basta con proporcionar una URL para que la extracción sea automática, sin definir reglas por cada sitio web.
- API de procesamiento de lenguaje natural: extrae entidades estructuradas, relaciones y sentimiento a partir de texto no estructurado, facilitando la creación de grafos de conocimiento propios.
- Grafo de conocimiento: uno de los más amplios del mercado, que conecta datos de entidades — personas y organizaciones incluidas.
Precio
Desde 299 $/mes con 250.000 créditos (equivalentes a unas 250.000 extracciones de páginas web basadas en API).
Ventajas:
- Extracción de datos sin reglas con alta adaptabilidad.
- Amplias opciones de integración por API con sistemas existentes.
- Preparado para scraping a gran escala en entornos empresariales.
Desventajas:
- La configuración inicial puede requerir un tiempo de aprendizaje para perfiles no técnicos.
- Su uso implica programar un programa que llame a la API.
¿Para qué puedes usar los raspadores?
Si estás empezando con el web scraping, aquí van algunos casos de uso habituales. Muchos equipos utilizan raspadores para obtener listados de productos de Amazon, extraer datos inmobiliarios de Zillow o recopilar información de empresas en Google Maps. Pero eso apenas es la superficie: con el Raspador Web IA de Thunderbit puedes recopilar datos de prácticamente cualquier sitio web, automatizando tareas y ahorrando tiempo en el día a día. Ya sea para investigación, seguimiento de precios o construcción de bases de datos, el web scraping abre un abanico enorme de posibilidades para poner los datos de internet a trabajar a tu favor.
Preguntas frecuentes
-
¿Es legal el web scraping?
El web scraping suele ser legal, pero hay que respetar los términos de servicio del sitio web y la naturaleza de los datos a los que se accede. Consulta siempre las políticas aplicables y cumple con la normativa vigente.
-
¿Necesito saber programar para usar herramientas de web scraping?
La mayoría de las herramientas de esta lista no requieren conocimientos de programación. Dicho esto, herramientas como Octoparse y Web Scraper pueden sacar más partido si el usuario entiende lo básico de estructuras web y tiene cierta mentalidad técnica.
-
¿Existen herramientas gratuitas de web scraping?
Sí. Herramientas como BeautifulSoup, Scrapy y Web Scraper son gratuitas, y varias de las opciones listadas ofrecen planes gratuitos con funciones limitadas.
-
¿Cuáles son los retos más habituales del web scraping?
Los problemas más frecuentes incluyen el manejo de contenido dinámico, CAPTCHAs, bloqueos de IP y estructuras HTML complejas. Las herramientas y técnicas avanzadas pueden resolver estos obstáculos con eficacia.
Más información:
Usa la IA para trabajar sin esfuerzo. Get Started Free




