Te registras en ScraperAPI, ves “100,000 credits” en el plan Hobby y empiezas a extraer datos. Tres días después, tu panel muestra que ya se fue el 80% de esos créditos, y quizá apenas has rastreado unas 6,000 páginas. ¿Qué pasó? Lo que pasó es el sistema de multiplicadores de créditos, y es, sin duda, la parte más importante de ScraperAPI que casi ninguna reseña explica de verdad. He pasado semanas revisando la documentación de ScraperAPI, comparando precios reales de cinco proveedores competidores y leyendo todos los hilos de Reddit y reseñas de Capterra que pude encontrar. Esta es la reseña de ScraperAPI que me habría gustado tener cuando nuestro equipo empezó a evaluar APIs de scraping. Voy a mostrarte las matemáticas reales detrás de los créditos, dónde ScraperAPI destaca y dónde falla por completo, resumir lo que dicen los usuarios en G2, Capterra y Reddit, y —siendo honestos— ayudarte a decidir si realmente necesitas una API de scraping.
¿Qué es ScraperAPI y para quién está pensado?
ScraperAPI es una API de web scraping que se encarga de la infraestructura complicada detrás del scraping a gran escala: rotación de proxies en , resolución automática de CAPTCHA, renderizado de JavaScript e intentos automáticos de reintento. Solo envías una URL mediante una llamada API sencilla y te devuelve el HTML (o JSON ya procesado, si usas sus endpoints de datos estructurados). La empresa fue fundada en 2018 por Daniel Ni, tiene su sede en Las Vegas y hoy atiende a , incluidas Deloitte, Sony y Alibaba, procesando .
Su público principal son equipos de desarrollo y operaciones técnicas que construyen pipelines de scraping personalizados. Si no programas, ScraperAPI no está pensado para ti (más sobre eso después).
Funciones principales: rotación de proxies, renderizado de JavaScript, geotargeting, endpoints de datos estructurados para sitios populares y reintentos automáticos para solicitudes fallidas.
Pero aquí está lo que la mayoría de reseñas pasan por alto: las cifras de créditos que aparecen en la página de precios de ScraperAPI son muy engañosas si no entiendes cómo funcionan los multiplicadores. Así que empezaremos por ahí.
Cómo funciona realmente el sistema de créditos de ScraperAPI (la parte que la mayoría de reseñas omite)
ScraperAPI cobra con un sistema de créditos. La idea básica es simple: 1 solicitud API = 1 crédito. Excepto que casi nunca funciona así en la práctica. El costo real en créditos depende de dos cosas: el dominio que estás extrayendo y las funciones que activas. Y esos costos se acumulan de forma poco intuitiva.
La tabla de multiplicadores que todo usuario debería ver antes de registrarse

Antes incluso de activar un solo parámetro, el tipo de sitio web que estás rastreando determina tu costo base en créditos:
| Categoría de dominio | Créditos base por solicitud | Ejemplos |
|---|---|---|
| Sitios normales | 1 | Blogs, sitios de noticias, HTML simple |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (motores de búsqueda) | 25 | Google, Bing |
| Redes sociales | 30 |
Además, los parámetros añaden créditos extra:
| Parámetro | Créditos extra | Notas |
|---|---|---|
render=true (renderizado JS) | +10 | Todos los planes |
screenshot=true | +10 | Todos los planes |
premium=true (proxy premium) | +10 | Todos los planes |
ultra_premium=true | +30 | Solo planes de pago |
| Evitación antibots (Cloudflare, DataDome, PerimeterX) | +10 cada uno | Se detecta automáticamente; no lo eliges tú |
premium=true + render=true combinados | +25 | NO +20 |
ultra_premium=true + render=true combinados | +75 | NO +40 |
Esa última fila es la clave. Combinar funciones cuesta MÁS que sumar sus costos individuales. Un proxy premium (+10) más renderizado de JavaScript (+10) debería costar lógicamente +20 créditos extra, pero ScraperAPI cobra . Ultra premium (+30) más renderizado de JavaScript (+10) debería costar +40, pero en realidad son — casi el doble. Este apilamiento no lineal no está documentado de forma destacada, y es la principal razón por la que los usuarios sienten que los créditos desaparecen más rápido de lo esperado.
Parámetros que no consumen créditos extra: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Qué incluye realmente cada plan: del gratuito al Enterprise
Estos son los :
| Plan | Precio mensual | Anual (por mes) | Créditos API | Hilos concurrentes | Geotargeting |
|---|---|---|---|---|---|
| Gratis | $0 | — | 1,000 | 5 | No |
| Hobby | $49 | $44 | 100,000 | 20 | Solo EE. UU. y UE |
| Startup | $149 | $134 | 1,000,000 | 50 | Solo EE. UU. y UE |
| Business | $299 | $269 | 3,000,000 | 100 | Nivel país (más de 50 países) |
| Scaling | $475 | $427 | 5,000,000 | 200 | Nivel país |
| Enterprise | Personalizado | Personalizado | 5,000,000+ | 200+ | Nivel país |
Ahora bien, este es el costo efectivo por cada 1,000 solicitudes en cada nivel, teniendo en cuenta los multiplicadores:
| Plan | Estándar (1×) | Renderizado JS (10×) | E-commerce (5×) | SERP (25×) | Ultra premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
Un plan de $49 al mes anunciado como “100,000 credits” en realidad solo entrega 1,333 solicitudes reales cuando extraes sitios protegidos con ultra premium más renderizado de JavaScript. Eso equivale a — más caro que muchos servicios de scraping totalmente gestionados.
Por qué los créditos desaparecen más rápido de lo que imaginas
Hay tres cosas que sorprenden a los usuarios.
Primero: el precio por dominio es automático. No eliges pagar el multiplicador 5× de Amazon ni el 25× de Google. Se aplica en el momento en que ScraperAPI detecta el dominio. Lo mismo ocurre con los créditos de evasión antibot (+10 para Cloudflare, DataDome, PerimeterX), que se añaden automáticamente cuando se detectan.
Segundo: los créditos NO se acumulan. Los créditos no usados . No se arrastran al mes siguiente.
Y tercero —esto molesta bastante— Pay-As-You-Go solo está disponible en el plan Scaling ($475/mes) y superiores. Si estás en Hobby, Startup o Business y agotas los créditos a mitad de ciclo, simplemente te quedas bloqueado hasta el siguiente período de facturación. La única opción es subir de plan.
Un usuario en Reddit contó que le cotizaron $3,600 por 60 millones de créditos a 1 crédito por solicitud de Amazon, pero después de pagar se le aplicó un multiplicador de 5 créditos sin aviso previo. En la práctica, su plan de 60M solo equivalía a 12M solicitudes — un respecto a lo que esperaba.
La trampa de créditos de DataPipeline
La función no-code DataPipeline de ScraperAPI (scraping programado con entrega por webhook) usa una tabla de créditos aparte, bastante más cara. Una solicitud básica normal cuesta en la API estándar:
| Tipo de solicitud | API estándar | DataPipeline | Relación |
|---|---|---|---|
| Solicitud básica normal | 1 | 6 | 6× |
| E-commerce básica | 5 | 10 | 2× |
| SERP básica | 25 | 30 | 1.2× |
| Ultra premium + JS (normal) | 75 | 80 | 1.07× |
Los usuarios que configuran pipelines sin código esperando costos de crédito estándar descubren que están gastando 6× créditos en solicitudes básicas. Está documentado, pero hay que buscarlo bastante.
Costo real por solicitud: ScraperAPI frente a la competencia
El precio de portada no sirve de mucho si no se consideran los multiplicadores. Tomé los precios actuales de cinco proveedores y los normalicé en el rango de unos $300 al mes para tres escenarios comunes.
Scraping HTML básico (sin JS, sin proxy premium)
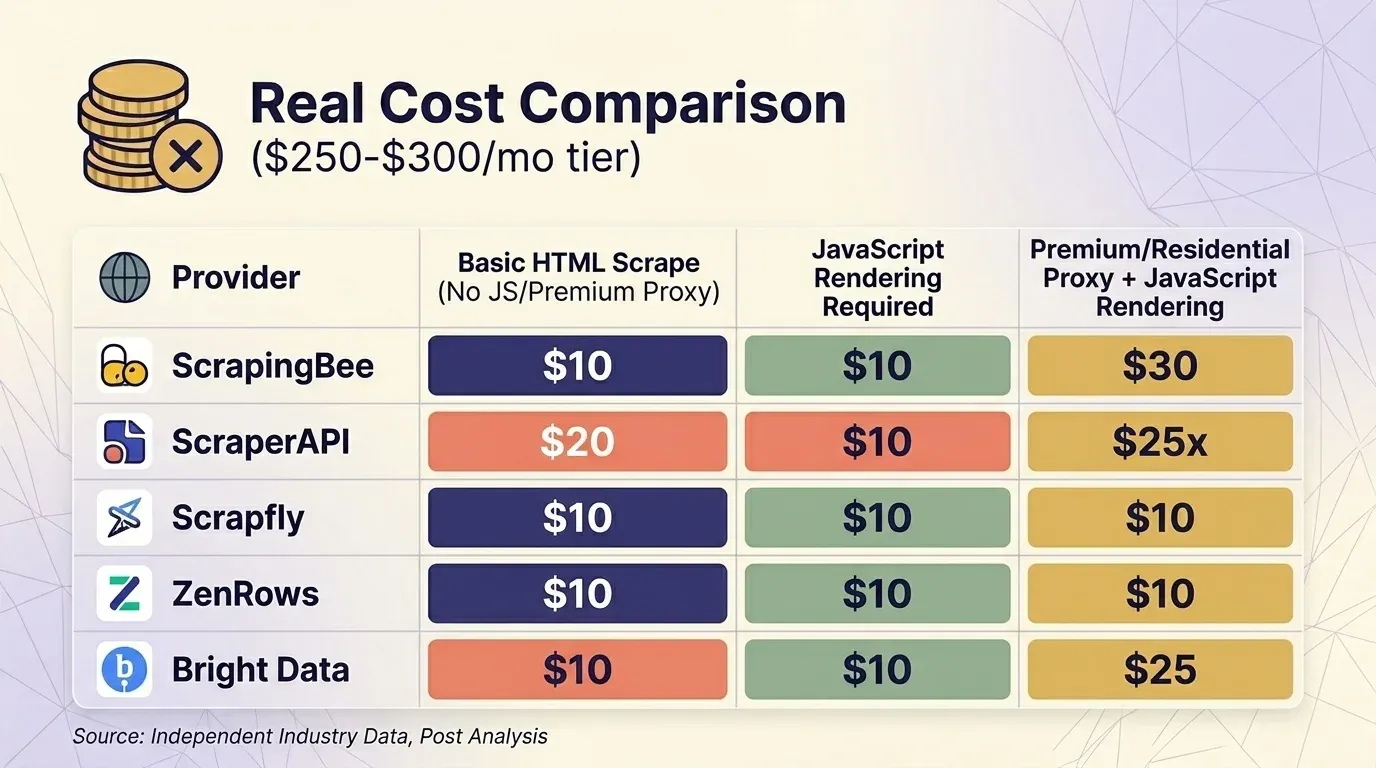
| Proveedor | Plan | Créditos por solicitud | Solicitudes reales | Costo por 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3,000,000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3,000,000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2,500,000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1,071,000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200,000 | $1.50 |
Requiere renderizado de JavaScript
| Proveedor | Plan | Créditos por solicitud | Solicitudes reales | Costo por 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (activado por defecto) | 600,000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416,667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300,000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214,000 | $1.40 |
| Bright Data | PAYG | tarifa plana | ~200,000 | $1.50 |
Proxy premium/residencial + renderizado de JavaScript (sitios protegidos)
| Proveedor | Plan | Créditos por solicitud | Solicitudes reales | Costo por 1K |
|---|---|---|---|---|
| Bright Data | PAYG | tarifa plana | ~200,000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120,000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120,000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80,645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42,857 | $7.00 |
El Web Unlocker de Bright Data es el único proveedor que : todas las solicitudes cuestan lo mismo con una tarifa fija. En el rango de unos $300, ScrapingBee y ScraperAPI compiten bien para scraping de sitios protegidos, mientras que ZenRows es el más caro.
Un dato importante sobre el comportamiento: ScrapingBee con un costo de 5×. Si comparas ScrapingBee y ScraperAPI cara a cara, asegúrate de que las configuraciones de renderizado sean equivalentes.
Un análisis independiente de Scrape.do encontró que ScraperAPI cuesta , “más que cualquier otro proveedor probado”, con un tiempo medio de respuesta de , lo que lo convierte en “uno de los proveedores más lentos disponibles”. Conviene saberlo antes de comprometerte.
Tasas de éxito por sitio: dónde brilla ScraperAPI y dónde sufre
Ninguna API de scraping funciona igual de bien en todos los sitios. Las pruebas independientes de Scrapeway (abril de 2026) muestran una historia claramente dividida.
Rendimiento por categoría de sitio
| Sitio objetivo | Tasa de éxito | Velocidad media | Costo por 1K (plan Business) |
|---|---|---|---|
| Zillow | 100% | 10.5s | $0.49 |
| Etsy | 99% | 4.8s | $4.90 |
| Amazon | 98% | 6.5s | $2.45 |
| 95% | 17.8s | $14.70 | |
| Walmart | 93% | 11.4s | $2.45 |
| Indeed | 90% | 15.8s | $4.90 |
| StockX | 84% | 3.9s | $4.90 |
| Realtor.com | 12% | 11.8s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Tasa de éxito promedio general: , ligeramente por encima del promedio de la industria, que es 58.2–59.5%. Tiempo medio de respuesta: 5.2–7.3 segundos, mejor que el promedio de la industria de 9.8 segundos.
Dónde funciona bien ScraperAPI
ScraperAPI es realmente fuerte en e-commerce (Amazon, Walmart, Etsy) y bienes raíces (Zillow). Los endpoints de datos estructurados para estos sitios devuelven JSON procesado con gran fiabilidad. Si tu caso principal es extraer páginas de productos de Amazon o SERPs de Google, ScraperAPI es una opción razonable.
Dónde se queda corto ScraperAPI
Las redes sociales son una zona muerta. Instagram, Twitter/X y Booking.com muestran una tasa de éxito del 0% en pruebas independientes. LinkedIn funciona al 95%, pero con 30 créditos por solicitud, el costo es elevado.
Los sitios con inicio de sesión están fuera de alcance. ScraperAPI admite persistencia de sesión mediante el parámetro session_number, pero . No puede manejar formularios, autenticación de dos factores ni flujos complejos de acceso.
Datos desactualizados en objetivos protegidos. ScraperAPI aplica una , lo que significa que, si rastreas datos sensibles al tiempo (precios, inventario), podrías recibir resultados de hasta 10 minutos de antigüedad.
En el benchmark de Proxyway de 2025, ScraperAPI tuvo la con 81.72%.
Resumen del rendimiento por categoría de sitio
| Categoría de sitio | Rendimiento de ScraperAPI | Problemas conocidos | Alternativa potencial |
|---|---|---|---|
| Amazon / e-commerce | ✅ Fuerte (endpoints SDP) | Muy costoso a escala | Plantillas de Thunderbit (1 clic, sin créditos por fila para la plantilla) |
| SERPs de Google | ✅ Fuerte | El geotargeting cuesta extra; peor éxito en Google en un benchmark | — |
| Bienes raíces (Zillow) | ✅ Excelente (100%) | — | — |
| Instagram / redes sociales | ❌ 0% de éxito | Fallo total | Playwright + proxies (hecho por ti) |
| SPA con mucho JS | ⚠️ Moderado | Requiere renderizado headless con costo de 10× | Scrapfly, ZenRows |
| Sitios que requieren login | ❌ Prohibido por los Términos | Sin soporte para sesión/autenticación | Browser Scraping de Thunderbit (usa tu sesión de login) |
| Booking.com / viajes | ❌ 0% de éxito | Fallo total | Bright Data |
Lo que dicen los usuarios reales: resumen de opiniones en G2, Capterra y Reddit
Recopilé comentarios de tres plataformas. Estas son las calificaciones actuales:
| Plataforma | Calificación | Reseñas |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Subcalificaciones de Capterra: Facilidad de uso 4.9/5, Atención al cliente 4.6/5, Funciones 4.5/5, Relación calidad-precio 4.5/5.
Resumen del sentimiento por tema
| Tema | Señales positivas | Señales negativas |
|---|---|---|
| Facilidad de configuración / documentación | "Super easy to set up. You can start scraping in minutes." — Latenode community; Capterra Ease of Use 4.9/5 | — |
| Transparencia de precios | "Affordable entry tier" (varias reseñas en Capterra) | "Breakdown of credit costs can be confusing" — John S., Founder, Capterra (Feb 2025); "Prices increased by 1000% and quality degraded" — CTO, Online Media, Capterra (Sep 2022) |
| Fiabilidad | "Works great for Amazon/Google" (G2, Capterra) | "ScraperAPI becomes shaky for heavy duty jobs" — emcarter, Latenode; "80% failure rate on some targets" (Reddit) |
| Soporte al cliente | "Responsive team" (Capterra) | Un usuario dijo que le cotizaron un precio y luego le cobraron 5× más sin aviso previo (Reddit) |
| Valor a lo largo del tiempo | Solo cobra por solicitudes exitosas (200/404) | "If you're running large-scale operations, the expenses can add up quickly" y construir infraestructura propia es "more cost-effective in the long run" — mikezhang, Latenode |
La conclusión: ScraperAPI es bien valorado por lo fácil que es empezar y funciona de forma fiable en objetivos populares y bien soportados. Las quejas se concentran en sorpresas con los precios (multiplicadores, subidas inesperadas) y en la fiabilidad para objetivos más difíciles.
Los endpoints de datos estructurados de ScraperAPI: ¿merecen los créditos premium?
ScraperAPI ofrece en 5 plataformas, devolviendo JSON procesado en lugar de HTML crudo:
- Amazon (3 endpoints): detalles de producto por ASIN, resultados de búsqueda, ofertas de competidores. Devuelve más de 18 campos, incluidos precios, valoraciones, descripciones, reseñas, BSR, imágenes e información del vendedor. Admite .
- Google (5 endpoints): (resultados orgánicos, knowledge graph, videos, preguntas relacionadas, paginación), Shopping, Maps, News y Jobs.
- Walmart (4 endpoints): producto, búsqueda, categoría y reseñas.
- eBay (2 endpoints): producto y búsqueda.
- Redfin (4 endpoints): búsqueda, detalles de agentes, propiedades en alquiler y propiedades en venta.
Los SDE están disponibles en todos los planes, incluido el Gratis. ScraperAPI afirma una para los dominios compatibles con SDE, aunque los benchmarks independientes muestran una realidad más matizada según el sitio.
Completitud de los datos
El SDE de Amazon es la oferta más fuerte de ScraperAPI. Devuelve un conjunto completo de campos: precio, reseñas, BSR, variantes, imágenes, información del vendedor y más. El SDE de Google SERP devuelve resultados orgánicos, anuncios, fragmentos destacados y People Also Ask. La completitud de datos es realmente buena para estas dos plataformas.
Eficiencia de créditos: SDE vs. análisis hecho por ti
En el plan Business ($299/mes, 3M créditos), extraer 10,000 productos de Amazon mediante el SDE cuesta 50,000 créditos (5 por cada uno), es decir, alrededor de $5 del valor del plan. Construir tu propio parser con una solicitud estándar (1 crédito cada una) costaría solo 10,000 créditos, pero tendrías que invertir tiempo de desarrollo en crear y mantener el parser.
Para equipos pequeños sin desarrolladores, los SDE ahorran tiempo real.
Para equipos con capacidad de ingeniería y scraping a escala, el sobreprecio de 5× en créditos es difícil de justificar.
Cómo se comparan los SDPs con las plantillas no-code de scraping
Esta comparación importa más de lo que la mayoría de reseñas deja ver. ofrece plantillas instantáneas para Amazon, Shopify, Zillow y que no requieren código y no tienen costo por fila para la plantilla en sí.
| Factor | ScraperAPI SDP (Amazon) | Plantilla de Amazon de Thunderbit |
|---|---|---|
| Tiempo de configuración | 30–60 min (código + integración API) | ~2 minutos (instala la extensión, abre Amazon, haz clic en la plantilla) |
| Costo por 1,000 productos (plan Business) | ~$5 (50,000 créditos a $0.10/crédito) | ~$16.50 (1,000 filas × 1 crédito a $0.0165/crédito en Pro) |
| Campos devueltos | Más de 18 (muy completo) | Nombre del producto, precio, valoración, reseñas, imágenes, URL y más |
| Opciones de exportación | JSON (requiere código para procesarlo) | Excel, CSV, Google Sheets, Airtable, Notion — 1 clic |
| Mantenimiento | ScraperAPI mantiene el SDP | El equipo de Thunderbit mantiene las plantillas |
| Nivel técnico | Se requiere Python/Node.js | Ninguno |
Para equipos de desarrollo que hacen scraping de Amazon en grandes volúmenes, el SDP de ScraperAPI es más rentable por producto a escala. Para usuarios de negocio que quieren datos de Amazon en una hoja de cálculo sin programar, Thunderbit es muchísimo más rápido de configurar y usar.
¿De verdad necesitas una API de scraping? La ruta no-code que muchas reseñas ignoran
Mucha gente que busca una “reseña de Scraper API” todavía no ha decidido usar una API en su flujo de trabajo. Primero está tratando de averiguar si la necesita.
Sorprendentemente, muchos no la necesitan. El mercado de APIs de web scraping es una industria de que crece a una tasa compuesta anual del 14–18%, pero ese crecimiento lo impulsan sobre todo equipos de ingeniería enterprise, no el gerente de ventas que necesita 500 leads de un sitio web.
API de scraping vs. herramienta no-code: marco de decisión lado a lado
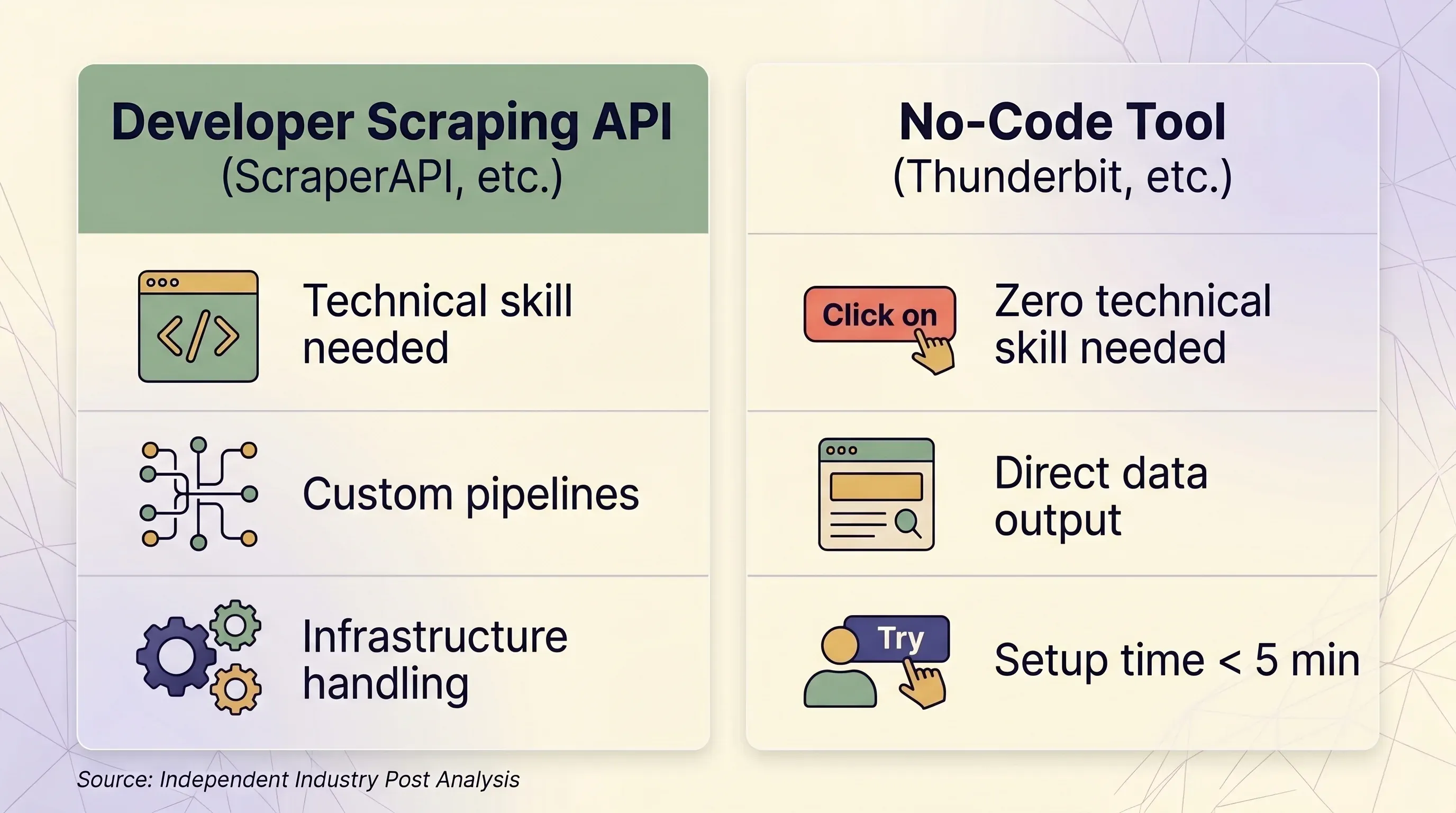
| Factor | API de scraping (ScraperAPI, etc.) | Herramienta no-code (Thunderbit, etc.) |
|---|---|---|
| Ideal para | Desarrolladores que construyen pipelines de datos a escala | Usuarios de negocio, marketers, equipos de ventas, investigadores |
| Conocimientos técnicos necesarios | Python/Node.js, conceptos HTTP, análisis de JSON | Ninguno — clics en el navegador |
| Tiempo de configuración | Mínimo 1–2 horas (código + pruebas + depuración) | Menos de 5 minutos |
| Manejo antibots | Proxies premium (10–75 créditos/solicitud) | Sesión real de navegador — evita el fingerprinting de forma natural |
| Sitios que requieren login | ❌ Prohibido por los Términos de ScraperAPI | ✅ Browser Scraping usa tu sesión existente |
| Escala (páginas/día) | 100K–3M+ solicitudes/mes | Uso puntual, normalmente menos de 1,000 páginas/día |
| Salida de datos | HTML crudo o JSON (requiere código para procesarlo) | Filas/columnas estructuradas — listas para usar |
| Exportación | JSON, CSV (mediante código) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON |
| Mantenimiento | Hay que actualizar selectores, lógica de reintento e infraestructura | Ninguno — la IA relee la estructura de la página cada vez |
| Unidad de precio | Créditos por solicitud (variable: 1–75 créditos/solicitud) | Créditos por fila (1 crédito = 1 fila, 2 para subpáginas) |
| Precio de entrada | $49/mes por 100K créditos | $9/mes por 5,000 créditos (anual) |
| Plan gratuito | 1,000 créditos/mes, 5 concurrentes | 6 páginas/mes, 30 créditos/página |
| Previsibilidad de precio | Baja — los multiplicadores generan costos sorpresa | Alta — 1 fila siempre = 1 crédito |
Cuándo sí tiene sentido una API de scraping
- Tienes un equipo de desarrollo o ingeniería
- Necesitas extraer 100K+ páginas al día de forma programática
- Necesitas personalización profunda de encabezados, sesiones y lógica de reintentos
- Tus objetivos están bien soportados (Amazon, Google, Walmart, Zillow)
Cuándo tiene más sentido una herramienta no-code como Thunderbit
- Trabajas en ventas, e-commerce, marketing o bienes raíces, no en ingeniería
- Necesitas datos de docenas de sitios distintos sin construir parsers para cada uno
- Quieres exportación directa a Excel, Google Sheets, Airtable o Notion
- Necesitas extraer sitios con login (el de Thunderbit usa tu sesión)
- Quieres que la IA lea la página desde cero cada vez, sin mantenimiento cuando el sitio cambia de diseño
- Necesitas scraping de subpáginas: Thunderbit puede visitar cada página de detalle y enriquecer filas automáticamente
El flujo de trabajo de la es realmente sencillo: instala la extensión, entra en cualquier página, haz clic en “AI Suggest Fields”, haz clic en “Scrape” y exporta. La IA detecta qué datos hay en la página y sugiere columnas; no necesitas escribir selectores ni código. Para saber más sobre cómo funciona, consulta nuestra .
sufrieron sobrecostos en la nube durante 2024, y las compañías que usan precios basados en consumo sin protección adecuada registran debido al impacto de facturación. La previsibilidad de un modelo de créditos por fila vale la pena si ya te has llevado sorpresas por costos variables de API.
Pros y contras de ScraperAPI de un vistazo
| Pros | Contras |
|---|---|
| Infraestructura de proxies sólida (más de 40M IP, más de 50 países) | Sistema de multiplicadores de créditos confuso: combinar funciones cuesta más que la suma |
| Excelente documentación y configuración inicial fácil (Facilidad de uso en Capterra: 4.9/5) | Los créditos NO se acumulan de un mes a otro |
| Fiable en Amazon, Google, Zillow y Etsy | 0% de éxito en Instagram, Twitter/X y Booking.com |
| Solo cobra por solicitudes exitosas (200/404) | Las respuestas 404 sí consumen créditos |
| 18 endpoints de datos estructurados con salida JSON procesada | Los sitios que requieren login están explícitamente prohibidos |
| Disponible en todos los planes, incluido el gratuito | Pay-As-You-Go solo en Scaling ($475/mes) y superiores |
| Política de reembolso de 7 días sin preguntas | Caché forzada de 10 minutos en objetivos difíciles: riesgo de datos antiguos |
| El crecimiento de ingresos del 30–35% anual sugiere desarrollo activo | DataPipeline puede costar hasta 6× los créditos de la API estándar |
| — | El geotargeting fuera de EE. UU. y la UE requiere el plan Business ($299/mes) |
| — | No hay alertas proactivas de uso: hay que revisar el panel manualmente |
Consejos prácticos para sacar el máximo partido a ScraperAPI (si decides usarlo)
Supervisa tu consumo de créditos a diario
El de ScraperAPI ofrece estadísticas de uso, incluida la latencia media, los dominios rastreados y métricas de concurrencia. Sin embargo, no hay alertas proactivas de uso — ni correo ni SMS cuando los créditos están por agotarse. Tienes que revisarlo manualmente. El historial de analíticas está limitado a 2 semanas en los planes Hobby/Startup y a 6 meses en Business o superiores.
Pon un recordatorio en el calendario para revisar el panel todos los días durante el primer mes. Necesitas desarrollar intuición sobre qué tan rápido se consumen los créditos en tus objetivos concretos.
Empieza con el plan gratuito para probar tus sitios objetivo
Usa los 1,000 créditos gratis (más una prueba de 7 días con 5,000 créditos) para medir las tasas de éxito en los sitios concretos que te interesan antes de comprometerte con un plan de pago. Documenta qué sitios necesitan renderizado de JavaScript o proxies premium para poder calcular costos mensuales realistas con multiplicadores.
Desactiva las funciones premium salvo que el objetivo las requiera
ScraperAPI NO activa automáticamente proxies premium ni renderizado de JavaScript: tienes que establecer explícitamente render=true, premium=true o ultra_premium=true. Pero el precio por dominio SÍ es automático: Amazon siempre cuesta 5 créditos, Google siempre 25 y LinkedIn siempre 30. Los créditos de bypass antibot (+10 para Cloudflare, DataDome, PerimeterX) también se añaden automáticamente cuando se detectan. Ten esto claro antes de lanzar un lote.
Usa los endpoints de datos estructurados para los sitios compatibles
Si vas a extraer Amazon o Google, los SDE ahorran tiempo de desarrollo incluso si cuestan más créditos. Para sitios no compatibles, evalúa si una sería más rápida y barata que construir un parser personalizado.
Ten un plan alternativo para objetivos poco fiables
Si la tasa de éxito de ScraperAPI en un sitio específico cae por debajo del 90%, considera enrutar esas solicitudes a otro proveedor o usar una herramienta basada en navegador. Para sitios que requieren login, ScraperAPI simplemente no funciona: necesitarás una herramienta como que opere dentro de tu sesión del navegador.
Conoce los puntos delicados
- Las respuestas 404 consumen créditos — ScraperAPI cobra tanto por códigos 200 como 404
- Las solicitudes canceladas se cobran si cancelas antes de que se complete la ventana de procesamiento de 70 segundos
- Caché forzada de 10 minutos en objetivos difíciles — podrías recibir datos antiguos
- Pay-As-You-Go solo está disponible en Scaling ($475/mes) y superiores — los planes inferiores se bloquean al agotar créditos
- El geotargeting fuera de EE. UU. y la UE requiere el plan Business ($299/mes)
Conclusiones clave: ¿es ScraperAPI la herramienta adecuada para ti?
Esto fue lo que concluí después de toda la investigación:
- ScraperAPI es una opción sólida para equipos de desarrollo que hacen scraping de alto volumen en objetivos bien soportados como Amazon, Google, Walmart y Zillow. Los endpoints de datos estructurados son realmente útiles, la infraestructura de proxies es grande y la documentación está por encima del promedio.
- El sistema de multiplicadores de créditos es el mayor riesgo. Si no entiendes cómo se acumulan los multiplicadores, gastarás de más. La diferencia entre los créditos anunciados y las solicitudes reales puede ser de 5 a 75×. Haz las cuentas para tu caso concreto antes de contratar un plan de pago.
- La fiabilidad depende del sitio. ScraperAPI rinde muy bien en e-commerce y bienes raíces, regular en portales de empleo y redes sociales, y es completamente inútil en Instagram, Twitter/X y Booking.com. No des por hecho un rendimiento uniforme.
- Para equipos no técnicos, ScraperAPI no es la herramienta adecuada. Si trabajas en ventas, marketing u operaciones y necesitas datos estructurados sin programar, una herramienta no-code como te lleva ahí en dos clics — con detección de campos por IA, exportación directa a hojas de cálculo, enriquecimiento de subpáginas y sin carga de mantenimiento. Mira la o ve tutoriales en el .
- Para desarrolladores con presupuesto limitado, prueba el plan gratuito de ScraperAPI en tus objetivos reales y luego compara el costo efectivo por solicitud con ScrapingBee, Scrapfly y Bright Data antes de decidir. La opción más barata depende por completo de tu caso de uso y de los requisitos de funciones.
¿Quieres ver cómo se traducen los números a tus necesidades de scraping? Empieza con el plan gratuito de ScraperAPI para probar tus sitios objetivo, o para ver hasta dónde te llevan dos clics. Para más información sobre , consulta nuestros planes.
Preguntas frecuentes
¿ScraperAPI es gratis?
Sí, ScraperAPI ofrece un plan gratuito con y una prueba de 7 días con 5,000 créditos. Sin embargo, los multiplicadores de créditos para renderizado de JavaScript, proxies premium o dominios de alto costo (Amazon = 5×, Google = 25×, LinkedIn = 30×) hacen que tu capacidad real pueda ser mucho menor que 1,000 solicitudes. En el plan gratuito, los proxies ultra premium no están disponibles.
¿Cuánto cuesta ScraperAPI por solicitud?
Depende muchísimo de las funciones activadas y del dominio objetivo. Una solicitud estándar a un sitio HTML sencillo cuesta 1 crédito. Una solicitud a Amazon cuesta 5 créditos. Una solicitud a Google SERP cuesta 25 créditos. Añadir renderizado de JavaScript suma 10 créditos. Combinar proxy ultra premium con renderizado de JavaScript cuesta 75 créditos por solicitud. En el plan Hobby ($49/mes, 100K créditos), eso va desde $0.00049 por solicitud (estándar) hasta $0.0368 por solicitud (ultra premium + JS). Consulta las tablas de costos anteriores para más detalles.
¿ScraperAPI sirve para extraer datos de Amazon?
El endpoint de Amazon Structured Data de ScraperAPI es una de sus funciones más fuertes, con una en benchmarks independientes y una salida JSON procesada muy completa (más de 18 campos). Sin embargo, cada solicitud a Amazon cuesta al menos 5 créditos, así que el gasto crece rápido a escala. Para equipos pequeños que quieren datos de Amazon en una hoja de cálculo sin programar, la ofrece una alternativa de 1 clic con exportación directa.
¿Cuáles son las mejores alternativas a ScraperAPI?
Para desarrolladores: (la más barata para HTML básico), (buena para renderizado de JavaScript), (la mejor para sitios protegidos — tarifa plana sin importar el renderizado) y . Para usuarios no técnicos: — una extensión de Chrome con IA y sin código, con exportación directa a Excel, Google Sheets, Airtable y Notion. Consulta nuestra para un análisis más profundo.
¿Puede ScraperAPI extraer sitios que requieren login?
ScraperAPI admite persistencia de sesión mediante el parámetro session_number (misma IP en varias solicitudes), pero . No puede manejar formularios, autenticación de dos factores ni flujos complejos de acceso. Para sitios con login, las herramientas basadas en navegador como —que usa tu sesión actual del navegador para extraer lo que puedes ver— son la opción más fiable.
Más información