El trimestre pasado, nuestro equipo de operaciones dedicaba 40 horas a la semana a copiar y pegar datos de la competencia en hojas de cálculo. Este trimestre, tarda 20 minutos.
¿La diferencia? Las herramientas automatizadas de raspado web. Han pasado de ser algo reservado para desarrolladores a una solución que cualquier vendedor o profesional de marketing puede poner en marcha en la pausa del almuerzo.
Llevo años creando SaaS y herramientas de automatización (y sí, cofundé ). La generación de herramientas de 2026 es la más sólida hasta la fecha: nativas de IA, autorreparables y de verdad útiles para personas sin conocimientos técnicos.
Aquí tienes 10 que he evaluado personalmente, comparadas por caso de uso y nivel de habilidad.
Por qué las herramientas automatizadas de raspado web son importantes para usuarios de negocio
Seamos sinceros: los días de copiar y pegar manualmente datos de sitios web ya quedaron atrás, salvo que disfrutes de las lesiones por esfuerzo repetitivo y de la angustia existencial. Las herramientas automatizadas de raspado web se han vuelto críticas para empresas de todos los tamaños. De hecho, , y el raspado web es una parte clave de esa estrategia.
Estas son las razones por las que estas herramientas son tan valiosas:
- Ahorra tiempo y reduce el trabajo manual: Los raspadores automatizados pueden procesar miles de registros en minutos, liberando a tu equipo para tareas de mayor valor. Un usuario de una herramienta informó haber ahorrado “cientos de horas” al automatizar la recopilación de datos ().
- Mejora la precisión de los datos: Se acabaron los errores tipográficos y los registros perdidos. La extracción automatizada significa datos más limpios y fiables.
- Facilita una toma de decisiones más rápida: Con flujos de datos en tiempo real, puedes vigilar a la competencia, seguir precios o crear listas de leads sin esperar al informe mensual del becario.
- Permite trabajar a equipos sin perfil técnico: Gracias a las herramientas sin código y basadas en IA, incluso quienes creen que “XPath” es una postura de yoga ya pueden crear flujos de datos web ().
No sorprende que , y que casi el 80% diga que su organización no podría operar con eficacia sin ellos. En 2026, si no automatizas la recopilación de datos, probablemente estés dejando dinero —e información— sobre la mesa.
Cómo elegimos las mejores herramientas automatizadas de raspado web
Con un mercado de software de raspado web que se prevé que , elegir la herramienta adecuada puede sentirse como comprar zapatos en una tienda con 10.000 opciones. Así es como hice la selección:
- Facilidad de uso: ¿Puede empezar rápido una persona sin experiencia en desarrollo? ¿La curva de aprendizaje es pronunciada?
- Capacidades de IA: ¿La herramienta usa IA para detectar automáticamente campos de datos, gestionar sitios dinámicos o permitirte describir lo que necesitas en lenguaje natural?
- Exportación e integración de datos: ¿Qué tan fácil es llevar los datos a Excel, Google Sheets, Airtable, Notion o tu CRM?
- Precio: ¿Hay prueba gratuita? ¿Los planes de pago son accesibles para particulares y pequeños equipos, o solo para empresas?
- Escalabilidad: ¿Puede manejar tanto trabajos pequeños puntuales como extracciones grandes y programadas?
- Usuario objetivo: ¿Está pensada para usuarios de negocio, desarrolladores o ambos?
- Ventajas únicas: ¿Qué hace que esta herramienta destaque frente a las demás?
He incluido herramientas para todos los niveles, desde “solo quiero una hoja de cálculo” hasta “quiero rastrear internet entero”. Vamos con la lista.
1. Thunderbit: la herramienta de raspado web con IA para todo el mundo
Déjame empezar por la herramienta que mejor conozco, porque mi equipo y yo la construimos precisamente para resolver los mismos problemas que he visto durante años en usuarios de negocio. no es el típico raspador de “arrastrar y soltar” ni el de “escribe tus propios selectores”. Es un asistente de datos impulsado por IA que te deja describir lo que quieres y hace el trabajo pesado: sin código, sin pelearte con XPath, sin lágrimas.
Por qué Thunderbit encabeza la lista
Thunderbit es lo más parecido que he visto a “convertir cualquier sitio web en una base de datos”. Así funciona:
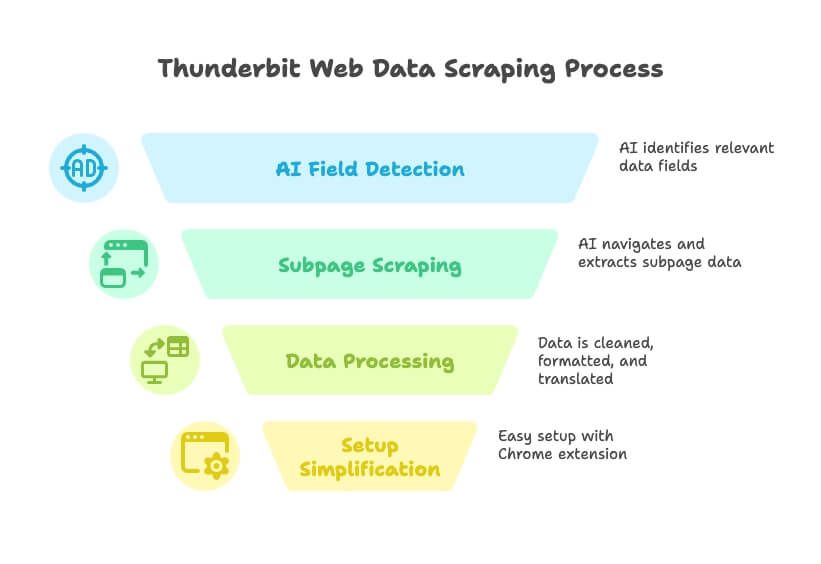
- Basado en lenguaje natural: Solo dile a Thunderbit qué datos necesitas (“quiero todos los nombres de empresa, correos electrónicos y números de teléfono de este directorio”) y la IA detectará automáticamente los campos relevantes.
- Sugerencia de campos con IA: Con un clic, Thunderbit lee la página y sugiere las mejores columnas para extraer; se acabaron las adivinanzas y el ensayo y error.
- Raspado de subpáginas y de varios niveles: ¿Necesitas detalles de la subpágina de cada ficha? Thunderbit puede navegar por ellas, obtener la información adicional y añadirla a tu tabla.
- Limpieza, traducción y clasificación de datos: Thunderbit no se limita a extraer datos en bruto; también puede limpiar, dar formato, traducir e incluso categorizar campos mientras raspa.
- Sin dolores de cabeza por la configuración: Instala la , haz clic en “Sugerir campos con IA” y estarás extrayendo datos en menos de un minuto.
- Prueba gratuita y bajo coste: Un nivel gratuito generoso (extrae hasta 6 páginas gratis), con planes de pago desde solo 9 $/mes. Eso es menos de lo que gasto en café en una semana.
Thunderbit está pensado para equipos de ventas, marketing y operaciones que necesitan datos rápido. Sin programación, sin complementos, sin formación. Es como tener un becario de datos que de verdad escucha y nunca se queja.
Funciones destacadas de Thunderbit
- Raspado impulsado por IA: La IA entiende la estructura de la página, se adapta a cambios de diseño e incluso gestiona automáticamente la paginación y las subpáginas ().
- Exportación instantánea de datos: Envía tus resultados directamente a Excel, Google Sheets, Airtable, Notion o descárgalos como CSV/JSON.
- Ejecución en la nube o local: Ejecuta raspados en la nube para ganar velocidad y escala, o en tu navegador si necesitas usar tu sesión de inicio.
- Raspado programado: Configura tareas recurrentes para mantener tus datos actualizados; perfecto para controlar precios o actualizar leads con regularidad.
- Sin mantenimiento: La IA de Thunderbit se adapta a los cambios en los sitios web, así que pasas menos tiempo arreglando raspadores rotos ().
¿Para quién es? Para cualquiera que quiera pasar de “necesito estos datos” a “aquí tienes tu hoja de cálculo” en minutos, especialmente usuarios sin perfil técnico. Con y una valoración de 4,9★, Thunderbit se está convirtiendo rápidamente en la opción preferida de los equipos de negocio que buscan resultados, no dolores de cabeza.
¿Quieres verlo en acción? Consulta el o explora más .
2. Clay: enriquecimiento automático de datos y raspado web
Clay es como la navaja suiza de los equipos de crecimiento. No es solo un raspador web: es una hoja de cálculo de automatización que se conecta a más de 50 fuentes de datos en vivo (piensa en Apollo, LinkedIn, Crunchbase) y usa IA integrada para enriquecer leads, redactar correos de prospección y puntuar prospectos.
- Automatización de flujos de trabajo: Cada fila es un lead, cada columna puede extraer datos o activar una acción. ¿Quieres extraer una lista de empresas, enriquecerla con perfiles de LinkedIn y enviar un correo personalizado? Clay lo hace.
- Integración de IA: Usa GPT-4 para escribir mensajes de apertura, resumir biografías y más.
- Integraciones: Se conecta de forma nativa con HubSpot, Salesforce, Gmail, Slack y más.
- Precio: Empieza en torno a 99 $/mes para el plan profesional, con prueba gratuita para usos ligeros.
Ideal para: ventas outbound, equipos de growth y marketers que quieren crear flujos personalizados de leads, combinando raspado, enriquecimiento y prospección en un solo lugar. Es potente, pero tiene cierta curva de aprendizaje si eres nuevo en las herramientas de automatización ().
3. Bardeen: herramienta de raspado web basada en navegador para automatizar flujos de trabajo
Bardeen es como tener un robot del navegador que puede extraer datos y automatizar tareas web repetitivas, todo desde una extensión de Chrome.
- Automatización sin código: Más de 500 “Playbooks” para raspar, rellenar formularios, mover datos entre apps y más.
- Constructor de comandos con IA: Describe tu tarea en lenguaje natural y Bardeen crea el flujo de trabajo.
- Integraciones: Funciona con Notion, Trello, Slack, Salesforce y más de 100 apps.
- Precio: Gratis para uso ligero (100 créditos de automatización al mes), con planes de pago desde 99 $/mes para equipos.
Ideal para: usuarios avanzados y equipos de go-to-market que quieren automatizar el raspado y las acciones de seguimiento en varias apps. Tiene mucha flexibilidad, pero los principiantes pueden encontrar la curva de aprendizaje algo pronunciada ().
4. Bright Data: herramientas automatizadas de raspado web de nivel empresarial
Bright Data (antes Luminati) es la maquinaria pesada del raspado web: piensa en redes globales de proxies, APIs avanzadas y la capacidad de rastrear miles de páginas al día.
- Escala empresarial: Más de 100 millones de IP, Web Scraper IDE y Web Unlocker para sortear medidas antibot.
- Personalizable: Crea extracciones complejas y de gran escala con alta fiabilidad.
- Precio: Desde 499 $/mes para Web Scraper IDE, con paquetes “micro” más pequeños disponibles.
Ideal para: grandes empresas, agregadores de datos y usuarios avanzados que necesitan soluciones robustas y escalables. Si vas a rastrear miles de páginas al día y necesitas evitar bloqueos de IP, Bright Data está hecho para ti ().
5. Octoparse: herramienta visual de raspado web para usuarios intermedios
Octoparse es una popular herramienta sin código con una interfaz visual de apuntar y hacer clic, perfecta para quienes quieren potencia sin programar.
- Interfaz de arrastrar y soltar: Haz clic en los elementos para definir qué extraer, gestionar inicios de sesión, paginación y más.
- Plantillas: Más de 500 plantillas listas para sitios comunes (Amazon, Twitter, etc.).
- Raspado en la nube: Ejecuta trabajos en los servidores de Octoparse, programa extracciones y usa rotación de IP.
- Precio: Plan gratuito con límites; los planes de pago empiezan en 119 $/mes.
Ideal para: personas sin perfil técnico y analistas de datos que quieren un raspador capaz sin escribir código. Muy útil para seguimiento de precios, catálogos de productos y proyectos de investigación ().
6. : plataforma de extracción de datos para empresas
es una de las veteranas del raspado web, ahora convertida en una plataforma integral de extracción de datos.
- Extracción de apuntar y hacer clic: Gestiona inicios de sesión, menús desplegables y elementos interactivos.
- Basada en la nube: Procesa miles de URL en paralelo, programa extracciones y accede a APIs.
- Enfoque empresarial: Se usa para seguimiento de precios, investigación de mercado y creación de conjuntos de datos para machine learning.
- Precio: Plan Starter a 199 $/mes, Standard a 599 $/mes y Advanced a 1.099 $/mes.
Ideal para: empresas medianas y grandes y equipos de datos que necesitan soluciones fiables y mantenidas para trabajos grandes. Probablemente excesiva para proyectos hobby, pero una potencia para necesidades a escala empresarial ().
7. Parsehub: herramienta flexible de raspado web con editor visual
Parsehub es una aplicación de escritorio (Windows, Mac, Linux) que te permite crear raspadores haciendo clic por la interfaz de un sitio web.
- Flujo visual: Selecciona elementos, configura reglas de extracción y gestiona inicios de sesión, menús desplegables y scroll infinito.
- Funciones en la nube: Ejecuta raspados en la nube, programa tareas y usa acceso API.
- Precio: Nivel gratuito para trabajos pequeños; planes de pago desde 149 $/mes.
Ideal para: investigadores, pequeñas empresas o personas que quieren más control que una extensión del navegador, pero aún no están listas para programar su propio raspador ().
8. Common Crawl: datos web abiertos para IA e investigación
Common Crawl no es una herramienta en el sentido tradicional: es un enorme conjunto de datos abiertos de rastreo web, actualizado mensualmente.
- Escala: ~400 TB de datos web, que cubren miles de millones de páginas.
- Gratis y abierto: No necesitas ejecutar tu propio crawler.
- Se requieren conocimientos técnicos: Vas a necesitar herramientas de big data y cierta soltura en ingeniería para filtrar y analizar los datos.
Ideal para: científicos de datos e ingenieros que construyen modelos de IA o hacen investigación a gran escala. Si necesitas texto web general o archivos históricos de largo plazo, es una mina de oro ().
9. Crawly: herramienta ligera de raspado web automatizado para startups
Crawly (de Diffbot) es un crawler basado en la nube e impulsado por IA que puede capturar datos de millones de sitios web y devolver resultados estructurados, sin necesidad de reglas de análisis.
- Extracción con IA: Usa visión por ordenador y NLP para identificar y extraer contenido.
- Acceso API: Consulta los datos recopilados e intégralos con herramientas de analítica o bases de datos.
- Precio: Nivel empresarial; contacta para conocer el precio.
Ideal para: startups y equipos con ciertos conocimientos técnicos que necesitan extracción inteligente de datos web a gran escala sin construir sus propios raspadores ().
10. Apify: herramienta de raspado web para desarrolladores con marketplace
Apify es una plataforma en la nube donde puedes crear tus propios raspadores (“Actors”) o usar una biblioteca de raspadores de la comunidad ya hechos.
- Flexibilidad para desarrolladores: Compatible con raspado basado en JavaScript/Python, Chrome sin interfaz, gestión de proxies y programación.
- Marketplace: Amplia biblioteca de raspadores listos para sitios comunes.
- Precio: Nivel gratuito con 5 $/mes en créditos; los planes de pago empiezan en 49 $/mes.
Ideal para: desarrolladores y analistas con perfil técnico que quieren control total y escalabilidad. Incluso quienes no programan pueden usar Actors preconstruidos para tareas comunes ().
Tabla comparativa de herramientas automatizadas de raspado web
| Herramienta | Facilidad de uso | Funciones de IA | Precio inicial | Usuario objetivo | Ventajas únicas |
|---|---|---|---|---|---|
| Thunderbit | ★★★★★ | Lenguaje natural, sugerencia de campos con IA, raspado de subpáginas | 9 $/mes | Usuarios de negocio sin perfil técnico | Configuración en 2 clics, sin código, exportación instantánea, prueba gratuita |
| Clay | ★★★★☆ | Enriquecimiento con IA, GPT-4 | 99 $/mes | Growth/ventas/operaciones | Hoja de cálculo de automatización, enriquecimiento, prospección |
| Bardeen | ★★★★☆ | Constructor de comandos con IA | 99 $/mes | Usuarios avanzados, equipos GTM | RPA en navegador, más de 500 playbooks, integraciones profundas |
| Bright Data | ★★☆☆☆ | Rotación de proxies, IA antibot | 499 $/mes | Empresas, desarrolladores | Escala, fiabilidad, proxies globales |
| Octoparse | ★★★★☆ | Detección visual con IA | 119 $/mes | Analistas, personas sin código | Arrastrar y soltar, plantillas, raspado en la nube |
| Import.io | ★★★☆☆ | Extractores interactivos | 199 $/mes | Empresas, equipos de datos | Concurrencia, programación, API, soporte |
| Parsehub | ★★★★☆ | Flujos visuales | 149 $/mes | Investigadores, pymes | Aplicación de escritorio, gestiona sitios dinámicos |
| Common Crawl | ★☆☆☆☆ | N/A (solo conjunto de datos) | Gratis | Científicos de datos, ingenieros | Conjunto de datos abierto masivo, archivos a escala web |
| Crawly | ★★☆☆☆ | Extracción con IA | Personalizado/empresarial | Startups, equipos técnicos | Impulsado por IA, sin reglas de análisis, acceso API |
| Apify | ★★★★☆ | Marketplace de Actors | 49 $/mes | Desarrolladores, analistas técnicos | Creación/marketplace, automatización en la nube, flexibilidad |
Cómo elegir la herramienta de raspado web adecuada para tus necesidades
Elegir la mejor herramienta automatizada de raspado web depende del tamaño de tu equipo, sus habilidades técnicas y tus objetivos de negocio. Aquí va mi guía rápida:
- Para usuarios sin perfil técnico (ventas, marketing, operaciones): Elige . Está pensado para ti: sin código, sin configuración, solo resultados. Perfecto para generación de leads, seguimiento de precios y proyectos de datos rápidos.
- Para equipos obsesionados con la automatización: Clay y Bardeen destacan si quieres combinar raspado con enriquecimiento, prospección o automatización de flujos de trabajo.
- Para empresas y desarrolladores: Bright Data, y Apify son tus mejores apuestas para proyectos de gran escala y altamente personalizables.
- Para investigadores y analistas: Octoparse y Parsehub ofrecen interfaces visuales y funciones potentes sin necesidad de programar.
- Para proyectos de IA y ciencia de datos: Common Crawl y Crawly proporcionan enormes conjuntos de datos y extracción con IA para quienes quieren construir o entrenar modelos.
Pregúntate: ¿quieres empezar en minutos o necesitas construir una solución personalizada de nivel empresarial? Si no lo tienes claro, empieza con una prueba gratuita; la mayoría de las herramientas la ofrecen.
El valor diferencial de Thunderbit: un asistente de IA para datos de negocio
Entre todas estas herramientas, Thunderbit destaca como la única que realmente actúa como un “asistente de IA” para el raspado web y la transformación de datos. No se trata solo de obtener datos: se trata de convertir sitios web desordenados en información limpia y estructurada sin barreras técnicas.
- Interfaz en lenguaje natural: Describe lo que necesitas en lenguaje sencillo y Thunderbit se encarga del resto.
- Automatización completa del flujo de trabajo: Desde la extracción hasta la limpieza, la traducción y la exportación, Thunderbit cubre todo el proceso.
- Perfecto para experimentar rápido: ¿Necesitas validar un nuevo mercado, crear una lista de leads o vigilar a la competencia? Thunderbit es el punto de partida más rápido y económico.
Es como tener un analista de datos integrado en tu navegador, uno que nunca pide un aumento ni se va de vacaciones.
Conclusión: empieza de forma más inteligente con la herramienta automatizada de raspado web adecuada
El panorama del raspado en 2026 es irreconocible comparado con el de hace dos años. Los raspadores con IA autorreparables, los flujos nativos de LLM y las herramientas sin código de verdad útiles han cambiado las reglas del juego. Tanto si eres un fundador en solitario, un equipo comercial con pocos recursos o un científico de datos en una gran empresa, hay una herramienta en esta lista que encaja con tus necesidades. La clave es alinear tu flujo de trabajo y tus habilidades con la plataforma adecuada, para dejar de pelearte con el código y empezar a desbloquear información.
Si estás listo para dejar atrás el copiar y pegar manual y empezar de forma más inteligente, y descubre lo fácil que puede ser el raspado web. O explora las otras opciones anteriores según tus objetivos. En cualquier caso, el futuro de los negocios impulsados por datos pertenece a quienes automatizan.
¿Tienes curiosidad por saber más? Visita para análisis en profundidad, tutoriales y consejos sobre cómo sacar el máximo partido a tus datos web. Feliz raspado, y recuerda: que tus datos estén siempre limpios y que tus raspadores nunca fallen (pero si lo hacen, deja que la IA se encargue).
Preguntas frecuentes
1. ¿Por qué son importantes las herramientas automatizadas de raspado web para los usuarios de negocio en 2026?
Las herramientas automatizadas de raspado web agilizan la recopilación de datos, ahorran tiempo y reducen el trabajo manual. Mejoran la precisión de los datos, facilitan la toma de decisiones en tiempo real y permiten a equipos sin perfil técnico extraer y usar datos web sin escribir código. Hoy son críticas para las funciones de ventas, marketing y operaciones.
2. ¿Qué hace que Thunderbit sea diferente de otras herramientas de raspado web?
Thunderbit usa IA para permitir que los usuarios describan qué datos quieren en lenguaje natural. Detecta automáticamente los campos de datos, gestiona subpáginas y paginación, y exporta resultados al instante a plataformas como Excel y Airtable. Está diseñado para usuarios sin perfil técnico y ofrece funciones potentes como limpieza de datos y raspado programado a un precio asequible.
3. ¿Qué herramienta es mejor para proyectos de raspado empresarial a gran escala?
Bright Data e son ideales para uso empresarial. Ofrecen funciones como rotación de proxies, medidas antibot, concurrencia a gran escala y acceso API, lo que las hace adecuadas para organizaciones que necesitan procesar miles de páginas web de forma fiable y a gran escala.
4. ¿Hay herramientas que combinen raspado con automatización y prospección?
Sí. Herramientas como Clay y Bardeen no solo extraen datos web, sino que también los integran en flujos de trabajo. Clay enriquece leads y automatiza la prospección, mientras que Bardeen permite automatizar tareas y flujos basados en navegador con playbooks impulsados por IA.
5. ¿Cuál es la mejor opción para usuarios sin formación técnica?
Thunderbit destaca para usuarios sin perfil técnico gracias a su interfaz en lenguaje natural, su configuración impulsada por IA y su facilidad de uso. No requiere programación ni configuración y es ideal para usuarios de negocio que necesitan datos rápidos y fiables sin complejidad técnica.