

La web rebosa de datos, y el apetito por extraerlos crece a toda velocidad. Eso sí, si buscas una sola cifra sobre el tamaño del mercado, verás estimaciones que varían muchísimo según si el analista incluye software, servicios, proxies o los tres. La lectura honesta es que el web scraping ya se ha instalado en ese rincón aburrido, pero imprescindible, de la pila de datos.
Tanto si eres analista de negocio, especialista en marketing o simplemente una persona curiosa que está empezando, la capacidad de extraer datos de un sitio web se está convirtiendo rápidamente en una habilidad clave. Y, si eres como yo, seguramente querrás saltarte la rutina infinita de copiar y pegar e ir directo a lo bueno: información útil, hojas de cálculo limpias y, quizá, un poco de magia de automatización.
Ahí es donde entra Python. Es la navaja suiza del mundo de los datos: lo bastante sencillo para principiantes, pero lo bastante potente para todo, desde extraer una sola página hasta rastrear miles. En este tutorial práctico, te guiaré por los conceptos básicos del web scraping con Python, te mostraré cómo abordar sitios dinámicos e incluso te presentaré Thunderbit, nuestro raspador web sin código impulsado por IA que hace que la extracción de datos sea tan fácil como pedir comida a domicilio. Tanto si vienes a aprender código como si solo quieres un atajo, estás en el lugar adecuado.
¿Qué es el Web Scraping y por qué usar Python para extraer datos de un sitio web?
Extrae datos de cualquier sitio web con IA Get Started Free
El web scraping es el proceso automatizado de extraer información de sitios web y convertirla en un formato estructurado —piensa en hojas de cálculo, CSV o bases de datos— para análisis o uso empresarial (PromptCloud). En lugar de copiar y pegar datos manualmente, un raspador imita lo que haría una persona, pero a una velocidad y escala muchísimo mayores.
¿Por qué es tan valioso? Porque en el mundo empresarial actual, la toma de decisiones basada en datos es la norma. Cuanto más grande es tu empresa, más decisiones intentas respaldar con números reales y no con intuiciones; y muchos de esos números empiezan su vida en la página web de otra persona.
Imagina poder monitorizar a diario los precios de la competencia, agrupar anuncios inmobiliarios o crear una lista personalizada de prospectos, todo ello sin despeinarte.
Entonces, ¿por qué Python? Estas son las razones por las que es el lenguaje preferido para el web scraping:
- Legibilidad y simplicidad: la sintaxis de Python es limpia y amigable para principiantes, lo que facilita escribir y entender scripts de scraping (PromptCloud).
- Ecosistema rico: bibliotecas como
requests,BeautifulSoup,ScrapyySeleniumhacen que extraer, analizar y automatizar acciones del navegador sea pan comido. - Apoyo de la comunidad: como Python se mantiene constantemente entre los lenguajes de programación más populares del mundo, tienes infinidad de tutoriales, foros y ejemplos de código a tu disposición.
- Escalabilidad: Python puede manejar desde scripts sencillos de uso único hasta rastreadores a gran escala.
En resumen: Python es tu pase de entrada al mundo de los datos web, tanto si eres un principiante total como un analista con experiencia.
Primeros pasos: conceptos básicos del tutorial de web scraping con Python
Antes de entrar en el código, desglosamos el flujo básico para extraer datos de un sitio web con Python:
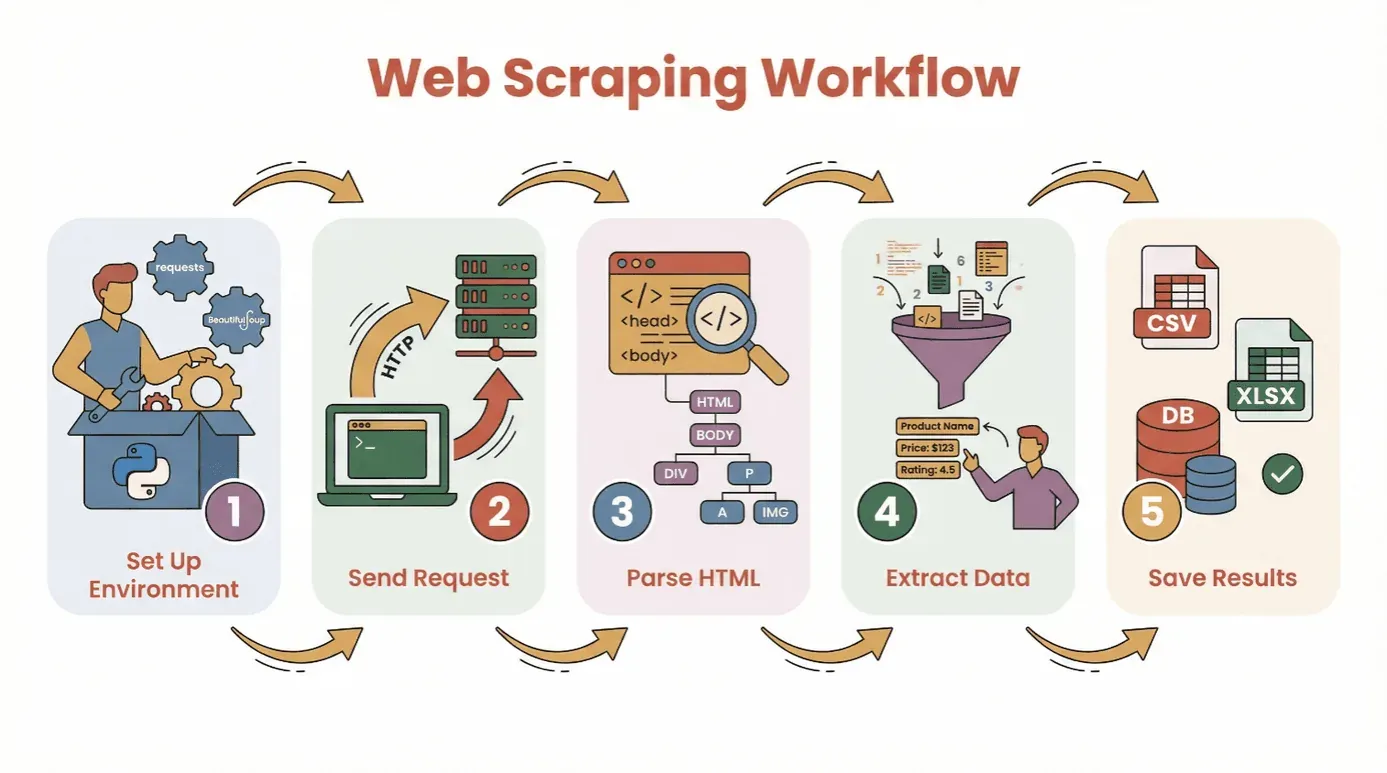
- Configura tu entorno: instala Python y las bibliotecas necesarias (
requests,BeautifulSoup, etc.). - Envía una solicitud: usa Python para obtener el contenido HTML de la página objetivo.
- Analiza el HTML: usa un parser para navegar por la estructura de la página.
- Extrae los datos: localiza y saca la información que necesitas.
- Guarda los resultados: almacena tus datos en un archivo CSV, Excel o una base de datos para analizarlos.
No necesitas ser un mago del código para empezar. Si sabes instalar Python y ejecutar un script, ya llevas la mitad del camino hecho. Si eres principiante absoluto, te recomiendo usar un entorno virtual o un notebook de Jupyter, aunque también puedes usar cualquier editor de texto básico.
Bibliotecas esenciales:
requests— para obtener páginas webBeautifulSoup— para analizar HTMLpandas— para guardar y limpiar datos (opcional, pero muy recomendable)
Cómo elegir la biblioteca adecuada de web scraping en Python: ¿BeautifulSoup, Scrapy o Selenium?
No todas las herramientas de scraping en Python son iguales. Aquí tienes un resumen rápido de las tres opciones más populares:
| Herramienta | Ideal para | Fortalezas | Desventajas |
|---|---|---|---|
| BeautifulSoup | Páginas simples y estáticas; principiantes | Fácil de usar, poca configuración, documentación excelente | No es ideal para rastreos grandes ni contenido dinámico |
| Scrapy | Rastreo a gran escala y de varias páginas | Rápido, asíncrono, con pipelines integrados; gestiona rastreo y almacenamiento de datos | Curva de aprendizaje más pronunciada, excesivo para trabajos pequeños, no ejecuta JavaScript |
| Selenium | Sitios dinámicos o con mucho JavaScript, automatización | Puede renderizar JS, simular acciones de usuario, admite inicios de sesión y clics | Más lento, consume más recursos y su configuración es más compleja |
BeautifulSoup: la opción ideal para analizar HTML simple
BeautifulSoup es perfecto para principiantes y proyectos pequeños. Te permite analizar HTML y extraer elementos con solo unas pocas líneas de código. Si tu sitio objetivo es mayormente estático (sin cargas sofisticadas de JavaScript), BeautifulSoup + requests es todo lo que necesitas.
Ejemplo:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Cuándo usarlo: extracciones puntuales, blogs sencillos, páginas de producto o directorios.
Scrapy: para rastreos estructurados o a gran escala
Scrapy es un framework completo para rastrear sitios web enteros o procesar miles de páginas. Es asíncrono (es decir, rápido), admite pipelines para limpiar y guardar datos, y puede seguir enlaces automáticamente.
Ejemplo:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Cuándo usarlo: proyectos grandes, rastreos programados o cuando necesites velocidad y estructura.
Selenium: para sitios dinámicos y con mucho JavaScript
Selenium controla un navegador real, como Chrome o Firefox, así que puede trabajar con sitios que cargan datos con JavaScript, requieren inicio de sesión o necesitan que hagas clic en botones.
Ejemplo:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Cuándo usarlo: redes sociales, sitios financieros, scroll infinito o cualquier cosa que parezca vacía cuando ves el código fuente.
Paso a paso: cómo extraer datos de un sitio web usando Python (tutorial para principiantes)
Vamos a recorrer un ejemplo real usando requests y BeautifulSoup. Rastrearemos un sitio sencillo de libros para obtener títulos, autores y precios.
Paso 1: configurar tu entorno de Python
Primero, instala las bibliotecas que vas a necesitar:
pip install requests beautifulsoup4 pandas
Después, impórtalas en tu script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Paso 2: enviar una solicitud al sitio web
Obtén el contenido HTML:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"No se pudo recuperar la página: {response.status_code}")
Paso 3: analizar el contenido HTML
Crea un objeto BeautifulSoup:
soup = BeautifulSoup(html, 'html.parser')
Encuentra todos los contenedores de libros:
books = soup.find_all('article', class_='product_pod')
print(f"Se encontraron {len(books)} libros en esta página.")
Paso 4: extraer los datos que necesitas
Recorre cada libro y extrae los detalles:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Título": title, "Precio": price})
Paso 5: guardar los datos para analizarlos
Convierte los datos en un DataFrame y guárdalos:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
¡Ahora ya tienes un archivo CSV limpio listo para analizar!
Consejos para solucionar problemas:
- Si obtienes resultados vacíos, comprueba si los datos se cargan con JavaScript (consulta la siguiente sección).
- Inspecciona siempre la estructura HTML con las herramientas de desarrollador de tu navegador.
- Gestiona los datos faltantes con
get_text(strip=True)y comprobaciones condicionales.
Cómo superar el contenido dinámico: extraer datos de sitios web renderizados con JavaScript
A los sitios web modernos les encanta JavaScript. A veces, los datos que quieres no están en el HTML inicial: se cargan después de que la página aparece. Si tu raspador no devuelve nada, quizá estés ante contenido dinámico.
Cómo gestionarlo:
- Selenium: simula un navegador real, espera a que el contenido cargue y puede hacer clic en botones o desplazarse.
- Playwright/Puppeteer: más avanzados, pero con una idea similar (navegadores sin interfaz).
Guía rápida de Selenium:
- Instala Selenium y un controlador del navegador, por ejemplo ChromeDriver.
- Usa esperas explícitas para dar tiempo a que el contenido cargue.
- Extrae el HTML renderizado y analízalo con BeautifulSoup si hace falta.
Ejemplo:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Extraer los datos como antes
driver.quit()
¿Cuándo necesitas Selenium?
- Si
requests.get()devuelve HTML sin datos, pero sí los ves en tu navegador. - Si el sitio usa scroll infinito, ventanas emergentes o requiere inicio de sesión.
Simplificar el web scraping con IA: usar Thunderbit para extraer datos de un sitio web
Prueba Thunderbit AI Web Scraper Extrae datos de cualquier sitio web en 2 clics, sin necesidad de código. Get Started Free
Seamos sinceros: a veces solo quieres los datos, no el código. Ahí es donde entra Thunderbit. Thunderbit es una extensión de Chrome impulsada por IA que te permite extraer datos de cualquier sitio web con unos pocos clics, sin necesidad de Python.
Cómo funciona Thunderbit:
- Instala la extensión de Chrome de Thunderbit.
- Abre el sitio web objetivo.
- Haz clic en el icono de Thunderbit y pulsa “AI Suggest Fields”. La IA de Thunderbit escanea la página y recomienda qué datos extraer (por ejemplo, nombres de productos, precios, correos electrónicos).
- Ajusta los campos si es necesario y luego haz clic en “Scrape”.
- Exporta los datos directamente a Excel, Google Sheets, Notion o Airtable.
Por qué Thunderbit destaca:
- No requiere código. Incluso mi madre puede usarlo (y eso que aún me llama por problemas con el Wi‑Fi).
- Gestiona subpáginas y paginación. ¿Necesitas extraer detalles de productos de varias páginas? Thunderbit puede ir clicando y combinar los datos por ti.
- Instrucciones en lenguaje natural. Solo dile lo que quieres (“extrae todos los títulos y precios de los productos”) y deja que la IA lo resuelva.
- Plantillas instantáneas para sitios populares. Amazon, Zillow, LinkedIn y más: un clic y listo.
- Exportación gratuita de datos. Descarga en CSV, Excel o envíalo directamente a tus herramientas favoritas.
Thunderbit cuenta con la confianza de más de 100.000 usuarios en todo el mundo. Hay un plan gratuito que puedes probar sin pagar nada: consulta la página de precios para ver el límite actual de páginas, ya que los límites han cambiado un par de veces. Para usuarios de negocio es un ahorro de tiempo; para quienes trabajan con Python, es una forma útil de acotar el trabajo antes de decidir si merece la pena escribir su propio raspador.
Pruébalo gratis: no necesitas código
Después del scraping: limpiar y analizar datos con Pandas y NumPy
Extraer los datos es solo el primer paso. Los datos web en bruto suelen venir desordenados: duplicados, valores faltantes, formatos extraños. Ahí es donde brillan las bibliotecas pandas y NumPy de Python.
Tareas comunes de limpieza:
- Eliminar duplicados:
df.drop_duplicates(inplace=True) - Gestionar valores faltantes:
df.fillna('Unknown')odf.dropna() - Convertir tipos de datos:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Analizar fechas:
df['Date'] = pd.to_datetime(df['Date']) - Filtrar valores atípicos:
df = df[df['Price'] > 0]
Análisis básico:
- Estadísticas resumidas:
df.describe() - Agrupar por categoría:
df.groupby('Category')['Price'].mean() - Gráficos rápidos:
df['Price'].hist()odf.groupby('Category')['Price'].mean().plot(kind='bar')
Para matemáticas más avanzadas o operaciones rápidas con arrays, NumPy es tu aliado. Pero, para la mayoría de los usuarios de negocio, pandas cubre el 95 % de lo que necesitas.
Recursos: si eres nuevo en pandas, consulta la guía 10 Minutes to pandas.
Mejores prácticas y consejos para tener éxito con el web scraping en Python
El web scraping es poderoso, pero también conlleva responsabilidades. Aquí tienes mi lista de comprobación para hacer scraping como un profesional —y no acabar bloqueado ni demandado—:
- Respeta robots.txt y los Términos de servicio. Comprueba siempre si el sitio permite hacer scraping (PromptCloud).
- No sobrecargues los servidores. Añade pausas entre solicitudes (
time.sleep(2)) y raspa a una velocidad parecida a la humana. - Usa encabezados realistas. Configura una cadena User-Agent para imitar a un navegador.
- Maneja los errores con elegancia. Usa bloques try/except y vuelve a intentar las solicitudes fallidas.
- Rota proxies si hace falta. Para scraping a gran escala, considera usar pools de proxies para evitar bloqueos de IP.
- Sé ético y legal. No extraigas datos personales ni contenido detrás de inicios de sesión sin permiso.
- Documenta tu proceso. Guarda notas sobre qué extrajiste, de dónde y cuándo.
- Usa APIs oficiales cuando estén disponibles. A veces hay una mejor opción que raspar HTML.
Para más consejos, consulta la Guía definitiva de web scraping.
Conclusión y puntos clave
El web scraping con Python es un superpoder para cualquiera que quiera convertir el caos de la web en datos estructurados y accionables. Ya sea que uses código (requests, BeautifulSoup, Scrapy o Selenium) o una herramienta sin código como Thunderbit, tienes todo lo necesario para extraer datos de un sitio web y desbloquear nuevas ideas.
Recuerda:
- Empieza por lo simple: extrae una sola página antes de lanzarte a proyectos grandes.
- Elige la herramienta adecuada para lo que necesitas (BeautifulSoup para lo básico, Scrapy para escalar, Selenium para sitios dinámicos, Thunderbit para no-code).
- Limpia y analiza tus datos con pandas y NumPy.
- Haz scraping siempre de forma responsable y ética.
¿Listo para probarlo por tu cuenta? Empieza con un proyecto pequeño: quizá extraer los titulares de hoy o una lista de productos, y comprueba lo rápido que puedes pasar de una página web en bruto a una hoja de cálculo limpia. Y si quieres saltarte el código, descarga Thunderbit y deja que la IA haga el trabajo pesado.
Para más tutoriales, consejos y sabiduría sobre web scraping, visita el blog de Thunderbit.
Lee más tutoriales de web scraping
Preguntas frecuentes
1. ¿Qué es el web scraping y por qué Python es tan popular para esto?
El web scraping es la extracción automatizada de datos de sitios web. Python es popular para el web scraping por su sintaxis legible, sus potentes bibliotecas (como BeautifulSoup, Scrapy y Selenium) y el gran apoyo de su comunidad (PromptCloud).
2. ¿Qué biblioteca de Python debería usar para web scraping?
Usa BeautifulSoup para páginas simples y estáticas; Scrapy para rastreos a gran escala o de varias páginas; y Selenium para sitios dinámicos o con mucho JavaScript. Cada una tiene sus propias fortalezas según lo que necesites (IPRoyal).
3. ¿Cómo gestiono sitios web que cargan datos con JavaScript?
Para contenido renderizado con JavaScript, usa Selenium (o Playwright) para simular un navegador y espera a que el contenido cargue antes de extraer los datos. A veces, puedes encontrar un endpoint de API subyacente inspeccionando el tráfico de red.
4. ¿Qué es Thunderbit y cómo simplifica el web scraping?
Thunderbit es una extensión de Chrome impulsada por IA que te permite extraer datos de cualquier sitio web sin programar. Usa IA para sugerir campos, gestionar subpáginas y paginación, y exporta los datos directamente a Excel, Google Sheets, Notion o Airtable.
5. ¿Cómo puedo limpiar y analizar datos extraídos en Python?
Usa pandas para eliminar duplicados, gestionar valores faltantes, convertir tipos de datos y hacer análisis. NumPy es ideal para operaciones numéricas. Para visualización, pandas se integra con Matplotlib para crear gráficos rápidos (10 Minutes to pandas).
¡Feliz scraping! Y que tus datos estén siempre limpios, estructurados y listos para la acción.
Prueba AI Web Scraper Get Started Free
Más información




