

La web rebosa de datos y, en 2026, la carrera por convertir ese caos en oro para los negocios es más intensa que nunca. He visto a equipos de ventas, ecommerce y operaciones transformar por completo sus flujos de trabajo al automatizar lo que antes eran horas de copiar y pegar de forma agotadora. Hoy en día, si no usas software de extracción de datos web, no solo te estás quedando atrás: probablemente sigues atrapado en el purgatorio de las hojas de cálculo mientras tus competidores ya se toman su segundo café.
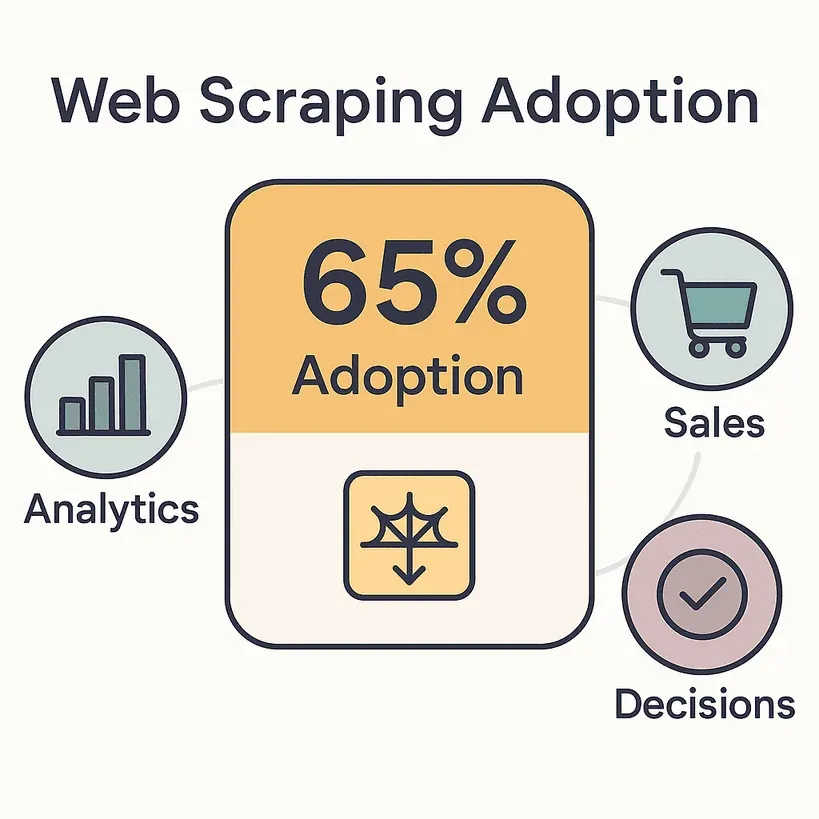
Esta es la realidad: el 65 % de las empresas ya usa herramientas de raspado web para impulsar analítica, ventas y toma de decisiones. El mercado global de extracción de datos web ya vale más de 1.000 millones de dólares, y se prevé que se duplique para 2030. Los representantes de ventas dedican hasta el 70 % de su tiempo a tareas que no venden, como introducir datos e investigar. Es muchísimo tiempo que podría invertirse en cerrar acuerdos de verdad, o al menos en disfrutar de la pausa para comer.

Entonces, ¿cuál es el mejor software de extracción de datos web para 2026? He investigado a fondo las cinco herramientas principales que están cambiando las reglas del juego para equipos de todos los tamaños y perfiles técnicos. Tanto si eres una persona sin conocimientos de programación que solo quiere hacer clic y listo, como si eres desarrollador y buscas la máxima flexibilidad, aquí hay algo para ti.
¿Qué hace que un software de extracción de datos web sea el mejor?
Qué es la extracción de datos y cómo hacerla en 2025 Get Started Free
Seamos sinceros: no todos los raspadores web son iguales. El mejor software de extracción de datos web en 2026 destaca por hacer que la extracción de datos sea rápida, fiable y accesible para todo el mundo, no solo para quienes sueñan en Python.
Estos son los criterios clave que yo busco, y los que más importan a los usuarios de negocio:
- Facilidad de uso: ¿Puede una persona sin conocimientos técnicos configurar una extracción en minutos? Las interfaces sin código y con IA son imprescindibles para la mayoría de los equipos.
- Flexibilidad de fuentes de datos: ¿Admite páginas web, PDFs, imágenes y contenido dinámico, como scroll infinito o AJAX? Cuantas más fuentes, mejor.
- Automatización y programación: ¿Puedes programar extracciones recurrentes, gestionar paginación y automatizar la navegación por subpáginas? La automatización marca la diferencia entre “lo configuro y me olvido” y “lo configuro y tengo que vigilarlo”.
- Integración y exportación: ¿Exporta directamente a Excel, Google Sheets, Notion, Airtable o mediante API? Cuanto menos trabajo manual, más contento estará tu equipo.
- Conocimientos técnicos necesarios: ¿Es realmente sin código o necesitas repasar regex? Las mejores herramientas se adaptan tanto a quienes no programan como a usuarios avanzados.
- Escalabilidad: ¿Puede extraer datos de cientos o miles de páginas sin inmutarse?
- Soporte y comunidad: ¿Tiene buena documentación, soporte ágil y una base de usuarios activa?
Estos criterios no son solo “nice to have”: son lo que separa a las herramientas que te ahorran horas de las que te hacen perder días. En 2026, con casi la mitad del tráfico de internet procedente de bots, contar con el raspador adecuado es una ventaja competitiva.
Ahora sí, vamos con las cinco mejores.
Los 5 mejores programas de extracción de datos web en 2026
- Thunderbit para extracción sin código, con IA y de múltiples fuentes
- Import.io para canalizaciones de datos integradas de nivel empresarial
- Scrapy para flexibilidad de código abierto impulsada por desarrolladores
- Octoparse para extracción visual sin código con programación
- ParseHub para extracción de datos sencilla, con clics, para tareas del día a día
1. Thunderbit: el software de extracción de datos web más fácil y potenciado por IA
Extrae datos de cualquier sitio web usando IA Get Started Free
Thunderbit es mi recomendación de referencia para cualquiera que quiera extraer datos web sin escribir ni una sola línea de código. Y sí, tengo cierto sesgo: ayudé a crearlo. Pero escúchame: Thunderbit está pensado para usuarios de negocio que quieren resultados, no dolores de cabeza.
¿Qué hace que Thunderbit destaque?
- Sugerir campos con IA: Solo tienes que hacer clic en “Sugerir campos con IA” y la IA de Thunderbit lee la página, recomienda qué extraer y configura el raspador por ti. Sin selectores, sin plantillas, sin drama.
- Extracción de múltiples fuentes: No solo extrae páginas web, también PDFs e imágenes. Thunderbit puede extraer texto, enlaces, correos electrónicos, números de teléfono e imágenes, todo en dos clics.
- Automatización de subpáginas y paginación: ¿Necesitas obtener detalles de cada producto o perfil? La extracción de subpáginas de Thunderbit sigue enlaces, recoge información adicional y la integra en tu tabla. Además, gestiona el scroll infinito y la paginación como un campeón.
- Extracción por lotes y programada: Pega una lista de URLs, programa tareas recurrentes y deja que Thunderbit haga el trabajo pesado, ya sea para vigilar precios a diario o actualizar leads cada semana.
- Exportación instantánea: Exporta directamente a Excel, Google Sheets, Airtable, Notion, CSV o JSON. Se acabaron las maratones de copiar y pegar.
- Prompts de IA personalizados: ¿Quieres clasificar, traducir o etiquetar datos mientras los extraes? Añade una instrucción personalizada y la IA de Thunderbit se encargará.
- Modo nube o navegador: Ejecuta las extracciones en la nube para ir más rápido (50 páginas a la vez) o en local para sitios que requieren inicio de sesión.
Thunderbit cuenta con la confianza de más de 30.000 usuarios en todo el mundo, desde equipos de ventas hasta agentes inmobiliarios y tiendas ecommerce independientes. El plan gratuito permite extraer hasta 6 páginas (o 10 con el impulso de prueba), y solo pagas por lo que usas: un crédito por cada fila de salida.
Por qué me encanta: Thunderbit es la única herramienta que he visto con la que una persona sin perfil técnico puede pasar de “necesito estos datos” a “aquí tienes mi hoja de cálculo” en menos de cinco minutos. La interfaz es realmente amigable (nos obsesionamos con ello), y la IA se adapta a los cambios del sitio web para que no estés corrigiendo raspadores rotos constantemente.
Ideal para: ventas, ecommerce, operaciones y cualquiera que quiera extracción sin código y con IA, sin mantenimiento.
Prueba la extensión de Chrome de Thunderbit
Consulta el blog de Thunderbit para ver más guías.
2. Import.io: extracción e integración de datos web de nivel empresarial
Import.io es el campeón de los pesos pesados para las empresas que necesitan datos web a gran escala y además integrarlos directamente en sus sistemas de negocio.
¿Qué diferencia a Import.io?
- Canalizaciones listas para empresa: Import.io no es solo un raspador; es una plataforma completa de integración de datos web. Piensa en “datos como servicio” con flujos continuos y automatizados.
- IA autorreparable: Si un sitio web cambia, la IA de Import.io intenta reasignar los campos automáticamente, para que tus canalizaciones no se rompan de la noche a la mañana.
- Automatización robusta: Programa extracciones por hora, a diario o con intervalos personalizados. Recibe alertas si algo falla o si los datos tienen un aspecto extraño.
- Flujos interactivos: Gestiona sitios con inicios de sesión, formularios o navegación en varios pasos. Import.io puede grabar y reproducir secuencias complejas.
- Cumplimiento y gobernanza: Detección automatizada de PII, enmascaramiento y registros de auditoría, algo crucial para sectores regulados.
- API e integración: Envía datos directamente a Google Sheets, Excel, Tableau, Power BI, bases de datos o tus propias apps mediante API.
Import.io cuenta con la confianza de marcas como Unilever, Volvo y RedHat. Es la opción habitual para casos de uso como la monitorización de precios en miles de sitios ecommerce, la inteligencia de mercado o la alimentación de modelos de IA/ML con datos web actualizados.
Precio: Import.io es una solución premium, con planes de autoservicio desde unos 299 USD al mes. Hay una prueba gratuita, pero no un plan gratuito permanente. Si los datos web son críticos para el negocio, el retorno de inversión está ahí.
Ideal para: empresas y organizaciones centradas en datos que necesitan fiabilidad, escala, cumplimiento e integración profunda.
3. Scrapy: framework de código abierto para desarrolladores
Scrapy es la potencia de código abierto para desarrolladores que quieren máxima flexibilidad y control. Si tú, o tu equipo, sabéis programar en Python, Scrapy es la navaja suiza del raspado web.
Por qué a los desarrolladores les encanta Scrapy:
- Personalización total: Escribe spiders (scripts) para rastrear, analizar y procesar datos exactamente como quieras. Gestiona flujos de varias páginas, lógica personalizada y limpieza de datos compleja.
- Asíncrono y rápido: La arquitectura de Scrapy está pensada para la velocidad y la escala: extrae cientos de páginas por minuto, o millones con rastreadores distribuidos.
- Extensible: Un ecosistema enorme de complementos y middleware para proxies, navegadores sin cabeza (Splash/Playwright) e integraciones.
- Gratis y de código abierto: Sin licencias. Ejecútalo en tu propio hardware o en la nube y escala todo lo que necesites.
- Soporte de la comunidad: Más de 55.000 estrellas en GitHub y una base de usuarios gigantesca. Si te atascas, probablemente alguien ya lo resolvió.
Limitaciones: Scrapy requiere conocimientos de Python y soltura con la línea de comandos. No tiene interfaz de clics; aquí manda el código. Pero para proyectos personalizados, datos de entrenamiento para IA o rastreos masivos, no hay nada mejor.
Ideal para: organizaciones con desarrolladores internos, canalizaciones de datos personalizadas o necesidades de extracción complejas y a gran escala.
4. Octoparse: extracción visual de datos web simplificada
Octoparse es uno de los favoritos entre quienes no programan pero quieren una extracción potente con una interfaz visual de apuntar y hacer clic.
Por qué Octoparse es tan popular:
- Constructor visual de flujos de trabajo: Haz clic en los elementos dentro de un navegador integrado y Octoparse detecta los patrones automáticamente. Sin código: solo haz clic y extrae.
- Gestiona contenido dinámico: Extrae datos de AJAX, scroll infinito y sitios protegidos con inicio de sesión. Simula clics, desplazamientos y envíos de formularios.
- Extracción en la nube y programación: Ejecuta tareas en la nube (más rápido y en paralelo) y programa trabajos recurrentes para tener datos siempre frescos.
- Plantillas prediseñadas: Cientos de plantillas para sitios populares (Amazon, Twitter, Zillow, etc.) te permiten empezar a extraer al instante.
- Exportación y API: Descarga resultados como CSV, Excel o JSON, o extrae datos mediante API. Integra con Google Sheets o bases de datos.
A menudo se describe Octoparse como “súper fácil de usar, incluso para principiantes”. El plan gratuito es limitado, pero los planes de pago (desde unos 83 USD al mes) desbloquean ejecuciones en la nube, programación y más velocidad.
Ideal para: usuarios sin perfil técnico, marketers, investigadores y equipos pequeños que necesitan recopilación de datos regular y automatizada sin programar.
5. ParseHub: extracción de datos fácil de usar para tareas cotidianas
ParseHub es otro favorito sin código, especialmente para pequeñas empresas y freelancers que quieren automatizar tareas de datos del día a día.
Qué hace brillar a ParseHub:
- Simplicidad de apuntar y hacer clic: Selecciona datos haciendo clic sobre elementos en una vista del navegador. Crea flujos de trabajo de forma visual, sin necesidad de programar.
- Gestiona sitios con JS y contenido dinámico: Extrae páginas con mucho JavaScript, scroll infinito y navegación en varios pasos.
- Ejecuciones en la nube y en local: Ejecuta extracciones en tu escritorio o en la nube. Programa trabajos recurrentes y accede a los resultados mediante API (en planes superiores).
- Opciones de exportación: Descarga datos como CSV, Excel o JSON. Acceso a API para automatización.
- Multiplataforma: Disponible en Windows, Mac y Linux.
El plan gratuito de ParseHub es limitado (200 páginas por ejecución), pero los planes de pago (desde unos 189 USD al mes) desbloquean más potencia, velocidad y acceso a la API.
Ideal para: pequeñas empresas, freelancers y equipos con necesidades de extracción sencillas que quieren una herramienta fiable y visual.
Tabla comparativa: los mejores programas de extracción de datos web de un vistazo
| Herramienta | Facilidad de uso | Fuentes de datos | Automatización y programación | Integración y exportación | Conocimientos técnicos | Precio |
|---|---|---|---|---|---|---|
| Thunderbit | Sin código, impulsado por IA | Web, PDF, imágenes | Subpáginas, paginación, programado, por lotes | Excel, Sheets, Notion, Airtable, CSV, JSON | Ninguno | Freemium (pago por fila) |
| Import.io | Interfaz de clics | Web (estático/dinámico, inicio de sesión) | Autorreparación, programado, alertas | API, herramientas BI, Sheets, Excel, BD | Bajo–medio | 299 USD+/mes |
| Scrapy | Requiere código | Web, APIs, (JS mediante complementos) | Automatización completa mediante código | Cualquiera (mediante código) | Desarrolladores Python | Gratis (código abierto) |
| Octoparse | Visual, sin código | Web (dinámico, inicio de sesión) | Programación en la nube, plantillas | CSV, Excel, JSON, API | Ninguno | 83 USD+/mes |
| ParseHub | Visual, sin código | Web (JS, dinámico) | Nube/local, programado | CSV, Excel, JSON, API | Ninguno | 189 USD+/mes |
Cómo elegir el mejor software de extracción de datos web para tu negocio
¿No sabes qué herramienta te conviene? Aquí va mi chuleta:
- Usuarios sin perfil técnico, resultados rápidos: elige Thunderbit o Octoparse. Thunderbit es imbatible para extracción instantánea potenciada por IA y soporte de múltiples fuentes (web, PDF, imágenes). Octoparse es excelente para extracciones visuales y programadas.
- Integración empresarial, cumplimiento y escala: Import.io es tu mejor apuesta. Está diseñado para canalizaciones de datos continuas, fiables y con integración profunda.
- Desarrolladores, proyectos personalizados o rastreos masivos: Scrapy es el camino. Necesitarás soltura con Python, pero ganarás flexibilidad ilimitada.
- Pequeñas empresas, freelancers o tareas cotidianas: ParseHub es una opción sólida y fácil de usar para extracción con clics y automatización moderada.
Consejos para elegir la herramienta adecuada:
- Ajusta la herramienta a los conocimientos técnicos de tu equipo y a tus necesidades de datos.
- Ten en cuenta la complejidad de los sitios que necesitas extraer (¿contenido dinámico? ¿inicios de sesión?).
- Piensa en cómo vas a usar los datos: ¿necesitas exportación directa a Sheets o integración profunda por API?
- Empieza con una prueba gratuita o un plan freemium para probar tareas reales.
- No subestimes el valor de un buen soporte y una buena documentación.
Empieza a extraer datos con Thunderbit
Conclusión: desbloquear valor empresarial con el mejor software de extracción de datos web
Los datos web son el combustible de las decisiones empresariales más inteligentes en 2026. El software adecuado de extracción de datos web puede ahorrarte horas, reducir errores y darle a tu equipo una ventaja real, ya sea que estés creando listas de leads, vigilando a la competencia o alimentando tu motor de analítica.
En resumen:
- Thunderbit es el raspador sin código más fácil y potenciado por IA para usuarios de negocio.
- Import.io es la solución de nivel empresarial para canalizaciones de datos continuas e integradas.
- Scrapy es el kit de herramientas de código abierto para desarrolladores que quieren control total.
- Octoparse y ParseHub hacen que la extracción visual sin código sea accesible para todo el mundo.
La mayoría de estas herramientas ofrecen pruebas gratuitas o planes freemium, así que pruébalas. Automatiza lo aburrido, desbloquea nuevos insights y deja que tu equipo se concentre en lo que realmente importa.
Feliz extracción, y que tus datos estén siempre frescos, estructurados y listos para actuar.
Preguntas frecuentes
1. ¿Para qué se utiliza el software de extracción de datos web?
El software de extracción de datos web automatiza el proceso de extraer información de sitios web, PDFs e imágenes. Se usa para generar leads, monitorizar precios, investigar mercados, agregar contenido y mucho más.
2. ¿Es legal la extracción de datos web?
El raspado web es legal cuando se recopilan datos de acceso público y se respetan los términos de servicio y las leyes de privacidad del sitio. Revisa siempre las políticas del sitio y usa los datos de forma responsable.
3. ¿Necesito saber programar para usar software de extracción de datos web?
¡No necesariamente! Herramientas como Thunderbit, Octoparse y ParseHub están pensadas para quienes no programan. Para proyectos más complejos o personalizados, pueden hacer falta herramientas para desarrolladores como Scrapy.
4. ¿Cómo exporto los datos extraídos a Excel o Google Sheets?
La mayoría de los raspadores modernos (Thunderbit, Octoparse, ParseHub) ofrecen exportación con un clic a Excel, Google Sheets, CSV o incluso integración directa con Notion y Airtable.
5. ¿El software de extracción de datos web puede gestionar sitios dinámicos o inicios de sesión?
Sí: herramientas de primer nivel como Import.io, Octoparse y ParseHub pueden gestionar contenido dinámico (AJAX, scroll infinito) y sitios protegidos con inicio de sesión. Thunderbit también admite la extracción de páginas dinámicas y subpáginas.
¿Quieres ver cómo es el raspado web moderno? Descarga la extensión de Chrome de Thunderbit o explora el blog de Thunderbit para más consejos, tutoriales y análisis profundos sobre el mundo de la extracción de datos con IA.
Prueba el Raspador Web IA Get Started Free




