
La semana pasada me tiré 40 minutos depurando un script de Python que iba perfecto en tres sitios de prueba, hasta que caí en cuenta de que el cuarto estaba detrás de Cloudflare. El scraper se quedaba pegado en una página de "Checking your browser…" y solo devolvía HTML de desafío. ¿Te suena?
Si ya te topaste con ese muro, no eres el único. ya usan Cloudflare, incluyendo de internet. Eso convierte a Cloudflare en la barrera más común para cualquiera que quiera recopilar datos web, ya sea para generación de leads, seguimiento de precios, investigación inmobiliaria o análisis de la competencia.
El problema es que la mayoría de las guías ponen todas las técnicas de bypass en una lista plana, sin decirte cuál deberías probar primero según tu caso. Esta guía va por otro camino: un árbol de decisión ordenado por prioridad, estimaciones honestas de fiabilidad y una ruta sin código que la mayoría de artículos ignora por completo.
- Dificultad: Principiante a intermedio (según el método que uses)
- Tiempo estimado: ~10–30 minutos para la ruta sin código; varía para los métodos con código
- Lo que necesitarás: navegador Chrome (para la ruta sin código), opcionalmente Python 3.9+ (para métodos con código) y una URL objetivo
¿Qué es la protección de Cloudflare y por qué bloquea tu scraper?
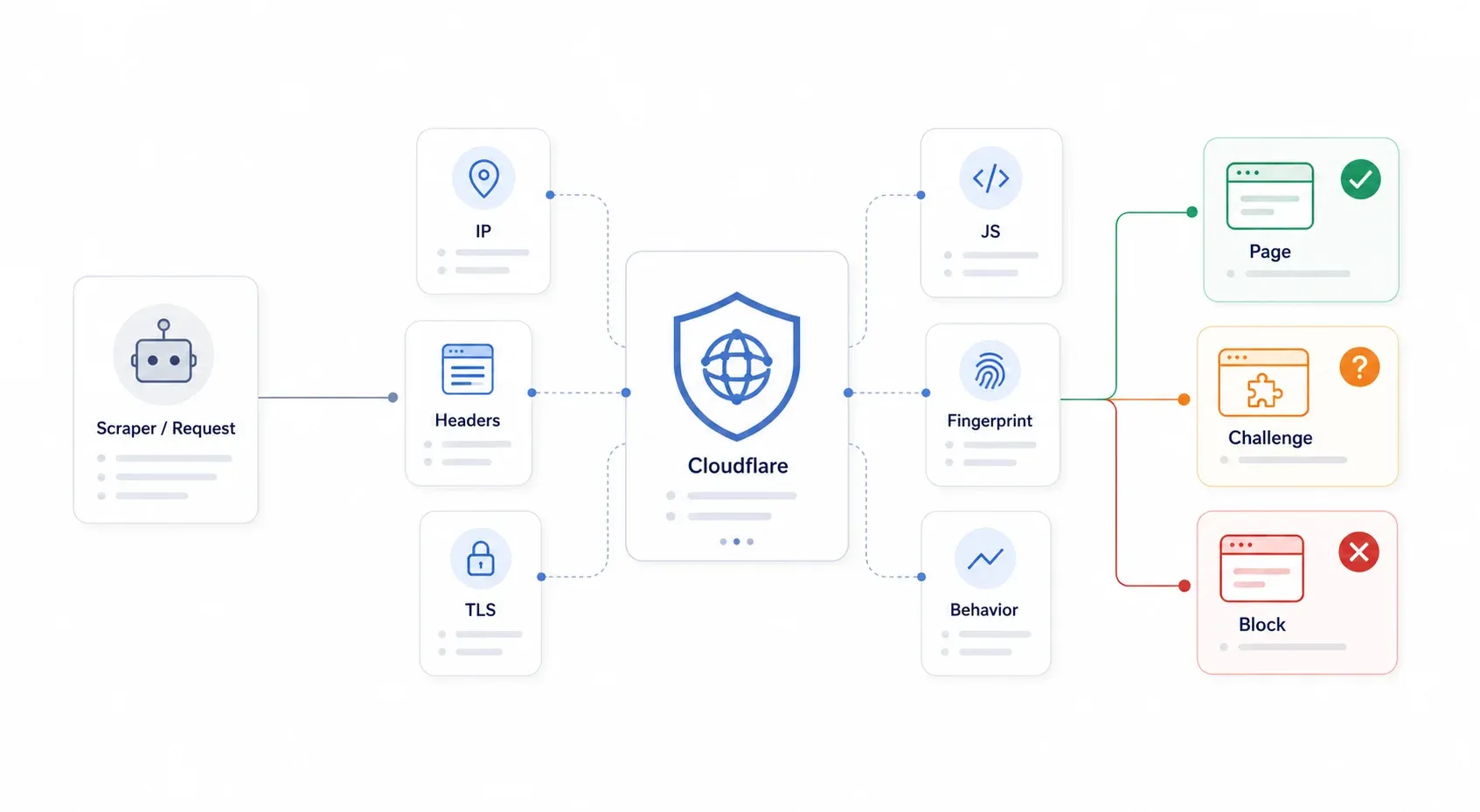
Cloudflare funciona como un proxy inverso que se coloca entre los visitantes y el servidor de origen del sitio. Cada solicitud pasa primero por el borde de Cloudflare, y Cloudflare decide si muestra la página, lanza un desafío al visitante o lo bloquea directamente. Lo importante aquí es esto: Cloudflare no necesita saber que tu scraper es malicioso. Solo necesita clasificar tu solicitud como suficientemente automatizada o sospechosa.
El sistema de de Cloudflare usa un enfoque por capas: no es una sola cerradura, sino un control de seguridad completo. Revisa la reputación de la IP, los encabezados HTTP, las huellas TLS, la ejecución de JavaScript, el fingerprinting del navegador y los patrones de comportamiento. Cuando tu biblioteca Python requests envía un GET a una página protegida por Cloudflare, falla en varias capas a la vez: handshake TLS incorrecto, sin ejecución de JavaScript, sin cookies y sin huella de navegador. Por eso el simple spoofing de headers dejó de funcionar hace años.
Los síntomas más comunes son: 403 Forbidden, 503 con "Checking your browser…", 1020 Access Denied, bucles infinitos de desafío, widgets de Turnstile que nunca se resuelven y páginas HTML de desafío cuando tú esperabas JSON.
Detección pasiva: lo que Cloudflare revisa antes de que cargue la página
Antes incluso de que veas una página, la capa pasiva de Cloudflare ya ha puntuado tu solicitud:
- Reputación de IP: Las IPs de centros de datos, rangos alojados en la nube y salidas de proxies conocidos suelen marcarse. Las IPs residenciales y de operadores móviles tienen . En 2026, los reportes de la comunidad describen de forma consistente que la navegación residencial local pasa, mientras que entornos Docker o VPS son bloqueados.
- Análisis de headers HTTP: Cloudflare compara tu User-Agent, Accept-Language, el orden de los encabezados y la versión HTTP. Un desajuste —por ejemplo, decir que eres Chrome 136 mientras tu handshake TLS grita "Python"— delata la automatización.
- Fingerprinting TLS (JA3/JA4): Durante el handshake TLS, tu cliente revela un patrón de suites de cifrado admitidas, extensiones y preferencias de protocolo. comprime eso en un identificador. Un Chrome real y un script de Python
requestsdejan huellas muy distintas. - Fingerprinting HTTP/2: Los navegadores y las librerías HTTP difieren en los frames SETTINGS de HTTP/2, el orden de los pseudo-headers y el comportamiento de prioridad. El trabajo de de Cloudflare va más allá de la identidad de una sola solicitud y sigue patrones entre solicitudes a lo largo del tiempo.
- AI Labyrinth: Esta es la trampa más nueva de Cloudflare. En lugar de bloquear crawlers sospechosos, los que parecen plausibles pero consumen recursos del rastreador. Puede que tu scraper ni siquiera se dé cuenta de que cayó en la trampa.
Detección activa: desafíos que se ejecutan en tu navegador
Cuando los controles pasivos no son concluyentes, Cloudflare escala a desafíos activos:
- Desafíos de JavaScript: El clásico intersticial "Checking your browser…". Las de Cloudflare ejecutan scripts invisibles para identificar solicitudes automatizadas.
- Turnstile: La alternativa de Cloudflare al CAPTCHA. Los incluyen Managed, Non-Interactive e Invisible. Analiza movimientos del ratón, entorno del navegador, huella TLS y más, sin necesidad de mostrar siempre un rompecabezas visible.
- Fingerprinting de Canvas y WebGL: Estas comprobaciones detectan navegadores headless que renderizan de forma distinta a los reales.
- Señales de comportamiento: Tiempos entre solicitudes, patrones de scroll y secuencias de clics. Un scraper que carga 50 páginas en 3 segundos sin mover el ratón no se parece en nada a una persona.
La conclusión práctica: si Cloudflare ya escaló a un desafío activo, los clientes HTTP simples como requests, httpx o incluso curl_cffi no bastan. Necesitas algo que ejecute un navegador real.
Niveles de protección de Cloudflare: por qué el mismo script funciona en un sitio pero falla en otro
Esto es justo lo que la mayoría de guías de bypass se salta. La protección de Cloudflare no es uniforme. Un sitio en el plan gratuito de Cloudflare con "Security Level: Medium" plantea un reto totalmente distinto al de un sitio Enterprise con Bot Management y Turnstile activados. El mismo script que pasa sin problema en uno puede chocar de frente con un muro en el otro.
| Nivel de Cloudflare | Defensas típicas | Dificultad de bypass | Lo que suele funcionar |
|---|---|---|---|
| Plan gratuito (seguridad baja) | Bot Fight Mode, reglas WAF básicas, reputación de IP | ⭐ Baja | Descubrimiento de API interna, curl_cffi con headers correctos, sesión real de navegador |
| Plan Pro (medio) | Super Bot Fight Mode, Managed Challenge, detecciones de JavaScript | ⭐⭐ Media | Sesión real de navegador, automatización stealth, proxies residenciales |
| Business | WAF más fuerte, Bot Analytics, desafíos más estrictos en rutas clave | ⭐⭐⭐ Media–Alta | Extracción desde sesión del navegador, persistencia de sesión, proxies residenciales/móviles, APIs de scraping de pago |
| Enterprise / Bot Management | Bot scores, campos JA3/JA4, reglas por endpoint, Turnstile, AI Labyrinth | ⭐⭐⭐⭐ Alta | API interna (si existe), herramientas con sesión real de usuario, APIs de scraping de nivel proveedor |
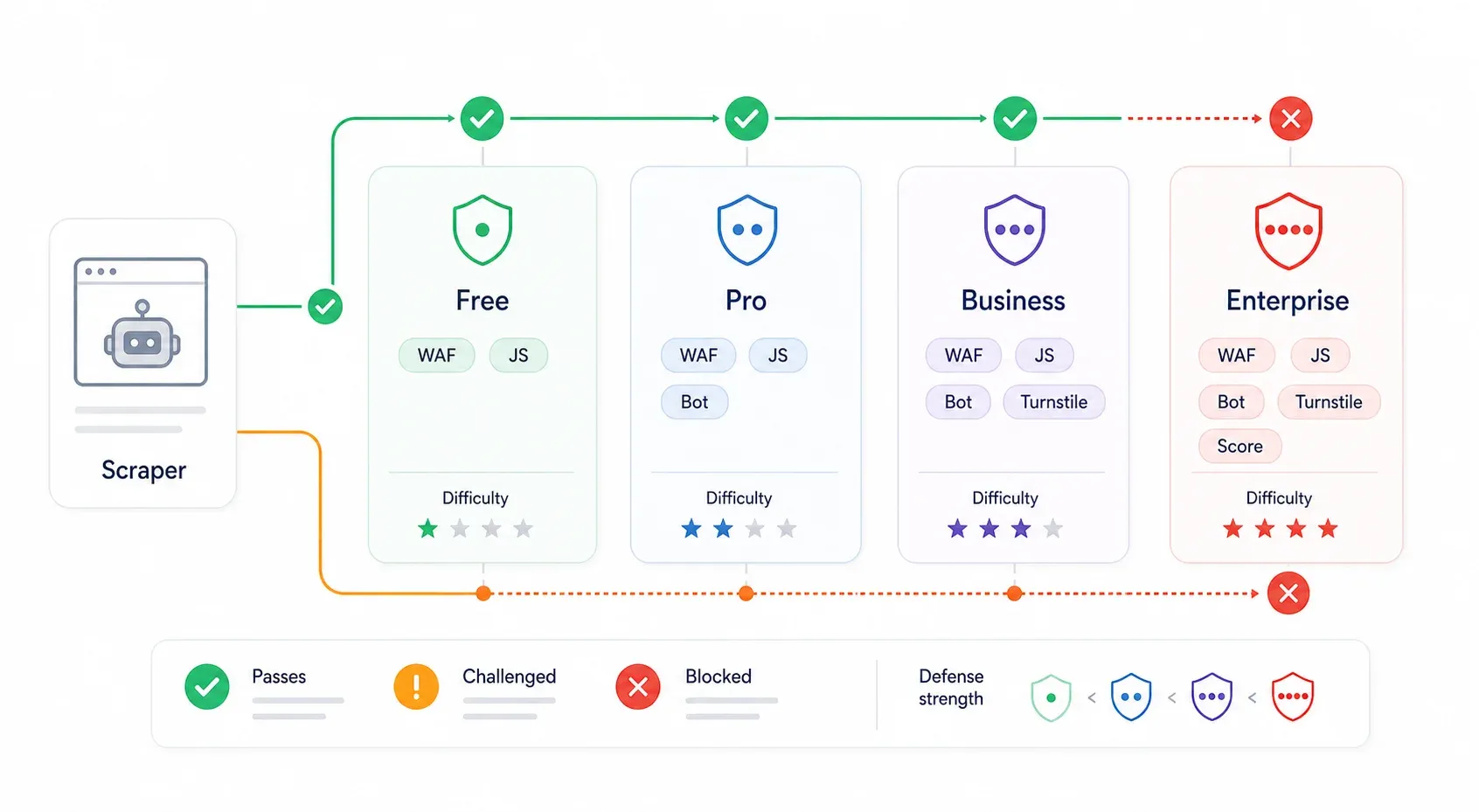
muestra Free a $0, Pro a $20/mes, Business a $200/mes y Enterprise con precio personalizado. es el interruptor sencillo del plan Free; añade más controles para Pro/Business; y Bot Management en Enterprise incorpora bot scores granulares y reglas específicas por endpoint.
Cómo identificar más o menos el nivel al que te enfrentas: un 403 con bloqueo de marca Cloudflare y sin script de desafío suele significar rechazo por WAF o fingerprint. Un cf-turnstile div o un script challenges.cloudflare.com/turnstile/v0/api.js indica Turnstile. Un intersticial de "Checking your browser" apunta a un Managed Challenge. Los fallos en rutas específicas después de cargar correctamente la página de inicio suelen indicar reglas de WAF o Bot Management específicas para ese endpoint.
Identifica el nivel de protección antes de elegir tu enfoque. Te ahorrará horas de depuración.
El árbol de decisión de "prueba esto primero" para evitar Cloudflare
En vez de ir probando métodos al azar, sigue un enfoque por prioridad. Empieza por lo más fácil y fiable, y sube de nivel solo cuando haga falta:
| Paso | Prueba esto primero | Por qué | Si falla → |
|---|---|---|---|
| 1 | Busca una API interna/no documentada | Evita Cloudflare por completo; es lo más rápido y fiable | Paso 2 |
| 2 | Usa una herramienta sin código con renderizado de navegador integrado (por ejemplo, Thunderbit) | Sin configuración, gestiona desafíos JS automáticamente | Paso 3 |
| 3 | Suplantación de huella TLS (curl_cffi) | Rápido, ligero, sin necesidad de navegador | Paso 4 |
| 4 | Automatización stealth del navegador (SeleniumBase UC / Puppeteer stealth) | Gestiona desafíos JS + fingerprinting | Paso 5 |
| 5 | FlareSolverr + Docker | Open source, apto para servidor | Paso 6 |
| 6 | API de scraping de pago (ScrapingBee, ZenRows, Scrapfly, etc.) | Externaliza por completo la carrera armamentística | — |
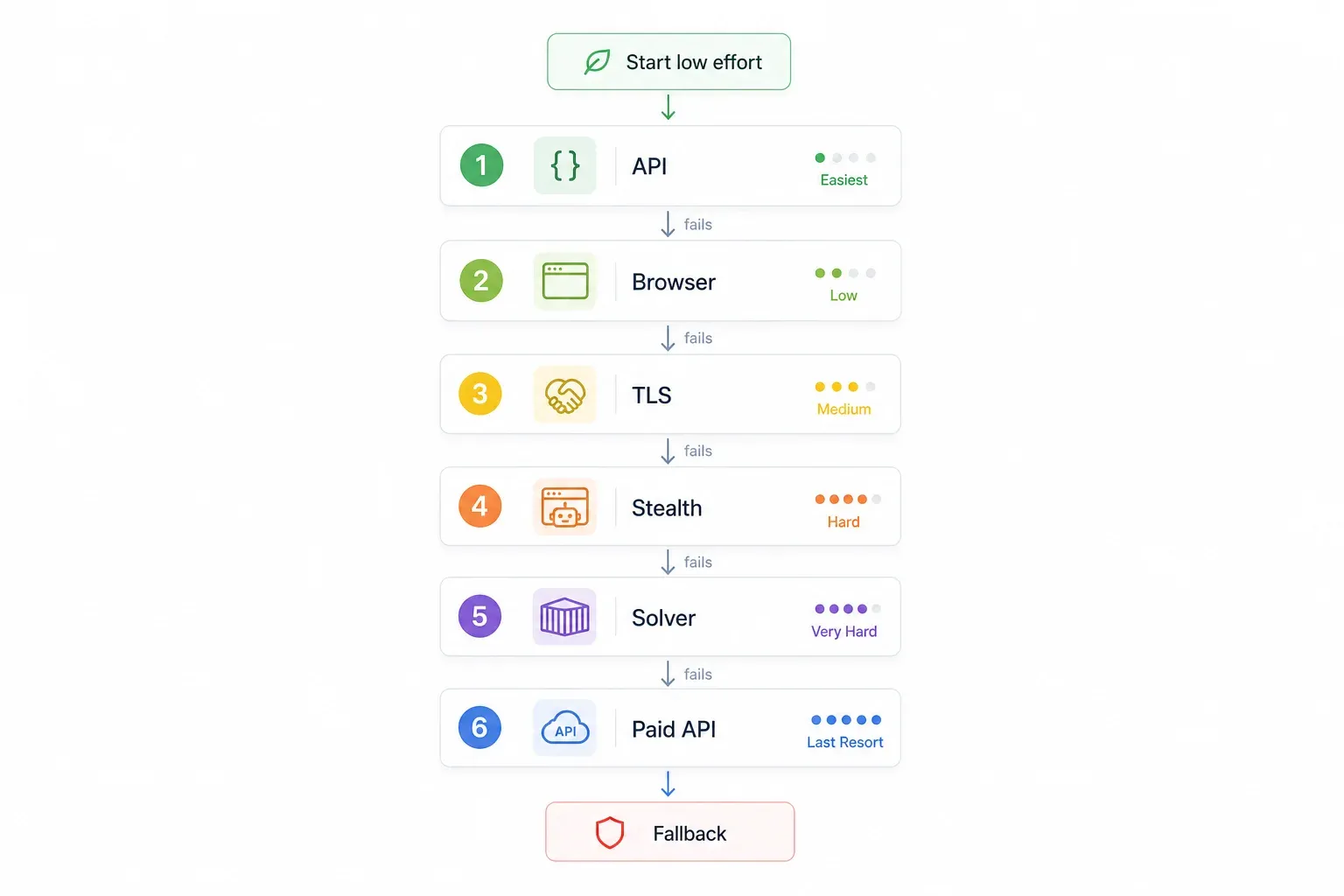
La lógica es simple: primero lo gratis y de bajo esfuerzo, y al final lo más complejo y caro. Salta directamente al paso que encaje con tu caso.
Un afirmó que curl_cffi superó 16 de 20 dominios probados (80%), FlareSolverr cubrió aproximadamente 55–70%, y los agregadores de proxies de pago alcanzaron alrededor de un 97% de éxito promedio, pero el mismo hilo advierte que esos números cambian conforme Cloudflare se actualiza. Toma todas las tasas de éxito como orientativas, no garantizadas.
Paso 1: evita la pelea — encuentra la API interna detrás de Cloudflare
Cuatro hilos distintos de foros que he visto recomiendan encontrar la API interna del sitio en lugar de pelear directamente con Cloudflare. Y, sinceramente, este es el movimiento más inteligente para empezar. Si el sitio tiene una API interna, te saltas Cloudflare por completo: sin trucos, sin spoofing de huellas, sin plugins stealth.
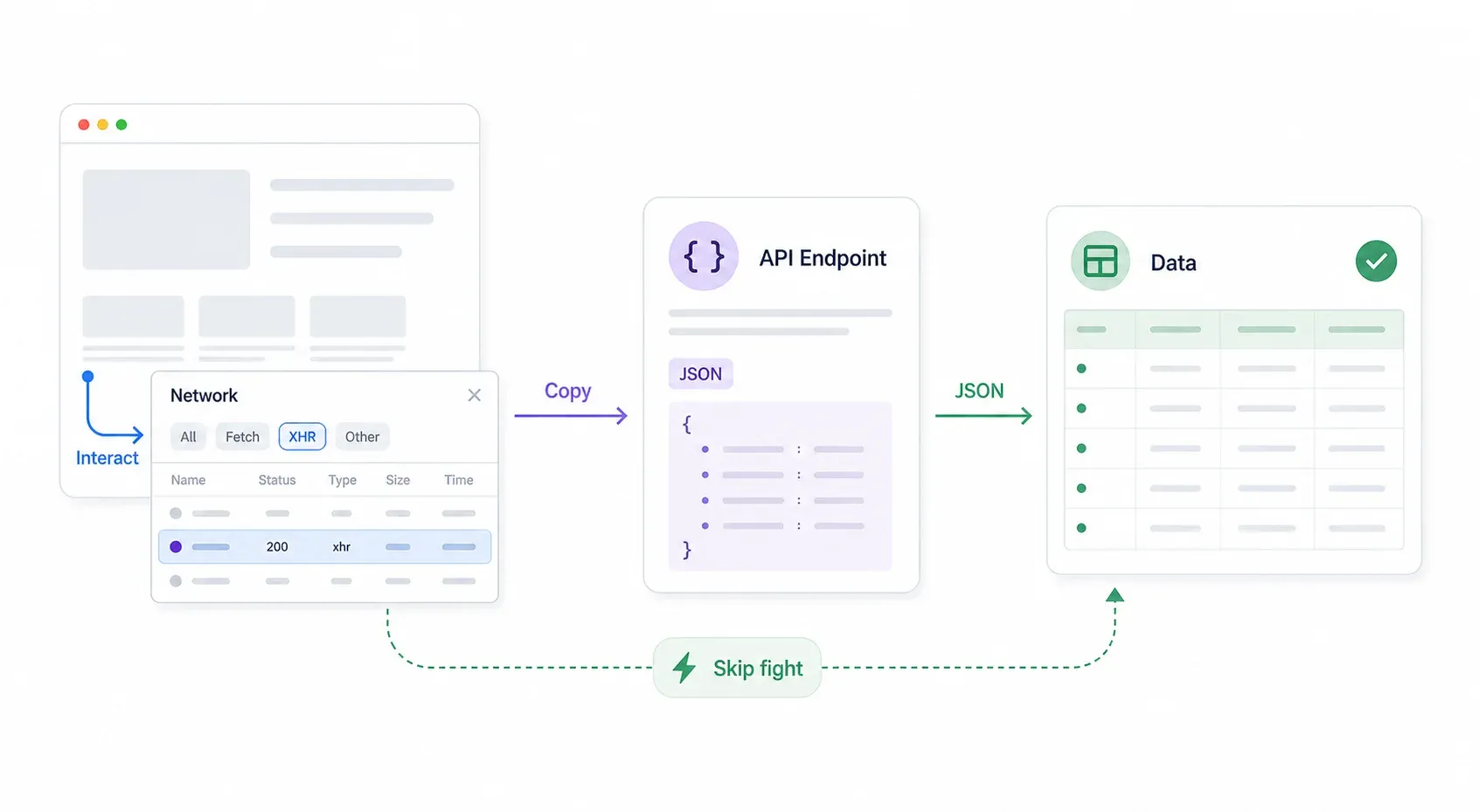
Este es el enfoque sistemático:
- Abre Chrome DevTools → ve a la pestaña Network → filtra por XHR/Fetch.
- Interactúa con la página: busca, filtra, pagina, desplázate. Observa si aparecen respuestas JSON en la pestaña Network.
- Inspecciona la URL y los headers de la solicitud. A menudo el endpoint de API no tiene la misma protección de Cloudflare o la tiene más débil que la página frontal.
- Haz clic derecho en la solicitud → Copy → Copy as cURL. Pégalo en tu terminal o en Postman y pruébalo.
- Replica la solicitud en Python (con
requestsocurl_cffi) usando los mismos headers, cookies y parámetros de consulta.
Si la API devuelve JSON estructurado, quizá ni siquiera necesites un scraper tradicional. Un describió exactamente este caso: un usuario bloqueado por Cloudflare a pesar de usar curl_cffi descubrió que la única vía viable era interceptar directamente la respuesta de la API.
Consejo práctico: una vez que el copy as cURL funcione, empieza a quitar headers innecesarios. Puede que sean necesarios headers como sec-ch-ua, cookies, tokens CSRF y referer; normalmente los controles de caché del navegador no lo son. Mantén la huella TLS coherente con el User-Agent si pasas de cURL en navegador a código.
Limitaciones: no todos los sitios tienen una API accesible. Algunas APIs requieren autenticación, tokens CSRF, parámetros firmados o cookies ligadas a la sesión. Pero cuando funciona, este es el método con una tasa de éxito cercana al 99% y sin mantenimiento.
Paso 2: la ruta sin código — evita Cloudflare con una extensión del navegador (Thunderbit)
Todas las guías de la competencia asumen que el lector escribe Python o JavaScript. Pero esta keyword también atrae a equipos comerciales que arman listas de leads, a operaciones de ecommerce que monitorean precios de la competencia y a analistas inmobiliarios que extraen datos de propiedades. Esa gente no quiere montar contenedores Docker.
Una extensión de Chrome como maneja de forma natural muchas comprobaciones de Cloudflare porque se ejecuta dentro de tu sesión real de navegador. Hereda la huella TLS auténtica de Chrome, tus cookies, tu estado de inicio de sesión y tus señales de comportamiento, justo lo que Cloudflare considera confiable. Sin plugins stealth, sin xvfb-run, sin comandos de terminal.
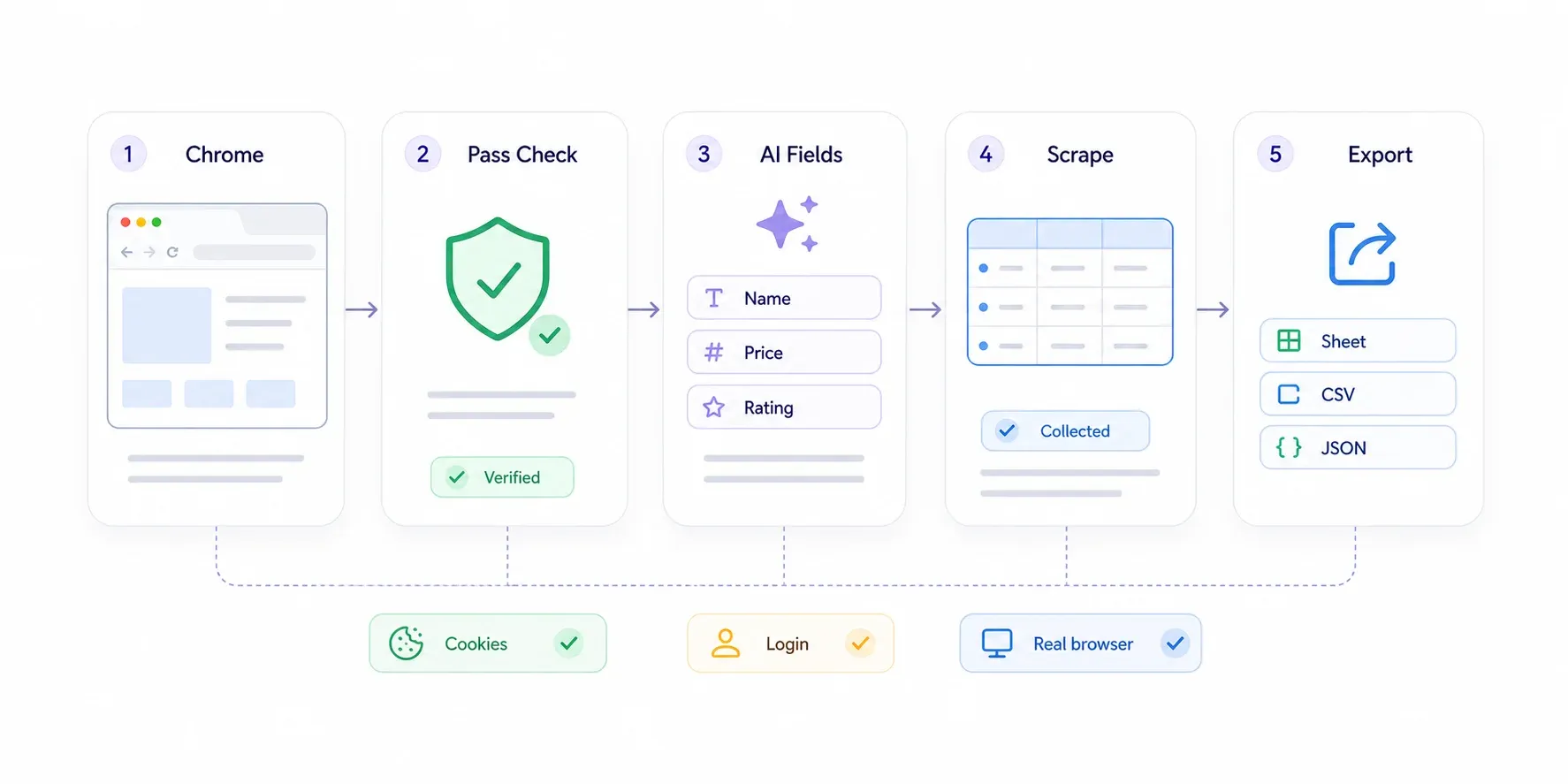
Guía paso a paso
- Instala la desde Chrome Web Store.
- Abre en Chrome la página protegida por Cloudflare. Si Cloudflare te lanza un desafío, resuélvelo como un usuario normal: marca la casilla de Turnstile o espera a que desaparezca la página "Checking your browser". Estás en un navegador real y eres una persona real; Cloudflare te dejará pasar.
- Haz clic en "AI Suggest Fields" en la barra lateral de Thunderbit. La IA analiza la página y propone columnas como "Product Name", "Price", "Rating" o cualquier otra relevante.
- Revisa los campos sugeridos. Quita lo que no necesites y añade campos personalizados describiendo en lenguaje natural lo que quieres.
- Haz clic en "Scrape". Thunderbit extrae los datos de la página visible.
- Exporta a Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Para sitios paginados, Thunderbit maneja tanto la paginación por clic como el scroll infinito. Para páginas de detalle (por ejemplo, si tienes una lista de enlaces de productos y quieres extraer las especificaciones de cada página individual), usa : Thunderbit visita cada página enlazada y enriquece tu tabla.
Por experiencia, este flujo tarda unos 5–10 minutos desde la instalación hasta tener la hoja exportada para un dataset típico de 50–100 filas.
Cuándo funciona mejor el scraping basado en navegador (y cuándo no)
Quiero ser claro con las limitaciones. El scraping basado en navegador depende de la velocidad de tu sesión. Es ideal para tareas de escala moderada: desde cientos hasta unos pocos miles de páginas. Si necesitas rastrear millones de páginas de forma programada, te convendrán más métodos basados en código o en API.
La opción de Cloud Scraping de Thunderbit puede acelerar el proceso al raspar hasta 50 páginas a la vez en sitios de acceso público. Y para flujos de trabajo de desarrollador o a mayor escala, la de Thunderbit maneja renderizado de JavaScript, protección anti-bot y rotación de proxies con procesamiento por lotes de hasta .
Pero para usuarios de negocio que extraen leads, precios o listados inmobiliarios a una escala razonable, este suele ser el único método que necesitan. Sin código, sin proxies, sin mantenimiento.
Paso 3: suplantación de huella TLS con curl_cffi (enfoque ligero con código)
Si te manejas bien con Python y la ruta sin código no encaja con tu flujo, es la opción de código más ligera. Es un binding de Python sobre libcurl que puede imitar la huella TLS de navegadores reales. A diferencia de requests o httpx, tu handshake TLS parece venir de Chrome o Safari.
A partir de 2026, los incluyen chrome136, safari184 y muchos perfiles históricos. La biblioteca tuvo una , así que sigue manteniéndose activamente.
Cuándo usarlo: sitios con protección Cloudflare de nivel Free o Pro que dependen principalmente de fingerprinting pasivo, sin desafío JavaScript activo ni Turnstile.
Ejemplo básico:
1from curl_cffi import requests
2url = "https://example.com/products"
3resp = requests.get(
4 url,
5 impersonate="chrome136",
6 headers={
7 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 },
10 timeout=30,
11)
12print(resp.status_code)
13print(resp.text[:500])Algo que suele confundir a la gente: mantén el User-Agent coherente con el objetivo de impersonación. Si estás suplantando Chrome 136, no mandes una cadena de User-Agent de Chrome 120. La discrepancia es una señal.
Limitaciones: curl_cffi no ejecuta JavaScript. Si el sitio muestra un desafío de "Checking your browser" o un widget de Turnstile, este método falla. Tampoco sirve para sitios que requieren estado de sesión basado en cookies procedente de un desafío en navegador. Piensa en él como un primer intento rápido y barato para protecciones solo pasivas.
Alternativas de la misma familia: tls-client y curl-impersonate ofrecen capacidades similares de impersonación TLS.
Paso 4: automatización stealth del navegador (Puppeteer Stealth y SeleniumBase UC)
El spoofing de TLS no basta cuando el sitio exige ejecución de JavaScript, desafíos activos o Turnstile. Ahí necesitas un navegador completo. Dos opciones principales:
- SeleniumBase UC Mode (Python): la como una forma de que la automatización parezca más humana y evite servicios anti-bot. Incluye ejemplos de manejo de Cloudflare Turnstile.
- Puppeteer con
puppeteer-extra-plugin-stealth(Node.js): sigue siendo muy usado, pero . Los reportes de la comunidad describen fallos por flags de detección CDP (Chrome DevTools Protocol) y perfiles de navegador desalineados.
Ambas herramientas lanzan un navegador Chromium real, pero parchean señales detectables de automatización: navigator.webdriver, metadatos de WebGL, listas de plugins y más.
Consejos de configuración que de verdad importan:
- Usa modo visible (no headless). La documentación de SeleniumBase advierte que UC Mode es detectable en modo headless. En servidores Linux, usa una pantalla virtual.
- Aleatoriza el tamaño del viewport y el User-Agent, pero mantén coherencia entre ambos y con la geolocalización de tu proxy.
- Añade retrasos realistas entre acciones. Un intervalo de 200 ms entre cargas de página grita "bot".
- Conserva cookies y perfiles del navegador después de superar el desafío inicial. No resuelvas el desafío en cada solicitud.
- Combínalo con proxies residenciales para una mejor reputación de IP.
El riesgo de este enfoque es el mantenimiento. Las pilas de automatización de navegador se rompen cuando Chrome se actualiza, Cloudflare añade una nueva señal, un plugin stealth se queda atrás o el objetivo introduce un Turnstile específico por ruta. Un encontró que muchas configuraciones stealth fallan las pruebas de fingerprinting por combinaciones tipo "franken-fingerprint": zona horaria, idioma y geografía del proxy desalineados.
Este método es potente, pero caro de operar. Reserva tiempo para arreglos continuos.
Rotación de proxies: por qué la IP importa tanto como las huellas
Incluso con un stealth perfecto del navegador, si envías demasiadas solicitudes desde una sola IP, activarás límites de tasa. Cloudflare confía mucho más en IPs residenciales y móviles que en IPs de centro de datos.
- Proxies residenciales: en volúmenes de entrada en 2026. Más confiables, pero más caros.
- Proxies de centro de datos: más baratos, pero .
- Estrategia de rotación: rota por sesión, no por solicitud. La rotación por solicitud rompe cookies ligadas a la sesión y
cf_clearance. Mantén IP, cookies y huella coherentes dentro de una misma sesión.
No existe un "tamaño mínimo de pool de proxies" mágico. Un scraping de leads de bajo volumen puede funcionar con unas pocas sesiones residenciales persistentes; un monitor de precios de alto volumen puede necesitar cientos de salidas más lógica de reintento.
Paso 5: FlareSolverr — el servidor open source para evitar Cloudflare
es un servidor proxy open source que usa Chromium con undetected-chromedriver dentro de un contenedor Docker para resolver desafíos de Cloudflare y devolver cookies/headers para reutilización. Tuvo un , así que sigue manteniéndose activamente.
Cuándo usarlo: pipelines de scraping del lado del servidor donde necesitas un servicio persistente para resolver desafíos; por ejemplo, un job automático que se ejecuta cada noche y necesita cookies cf_clearance nuevas.
Cómo funciona: tu scraper envía una URL a la API de FlareSolverr. FlareSolverr abre la página en un navegador, intenta resolver el desafío y devuelve el HTML junto con las cookies. Luego puedes reutilizar esas cookies en tu cliente HTTP normal para solicitudes posteriores.
Resumen de configuración: Docker Compose, levantar el contenedor y enviar solicitudes POST al endpoint API local. .
Limitaciones que quiero dejar claras:
- No puede resolver de forma fiable desafíos interactivos de Turnstile ni Bot Management de nivel Enterprise.
- y muestran comportamiento inconsistente: fallos en detección de desafíos, timeouts de Turnstile y caídas de página.
- Requiere infraestructura Docker y mantenimiento continuo.
- Consume muchos recursos: cada resolución lanza un contexto de navegador.
Fiabilidad estimada: 60–80% en objetivos con protección media. Más baja para Enterprise, más alta para páginas de desafío más simples. Si FlareSolverr no alcanza, toca considerar APIs de pago.
Paso 6: APIs de scraping de pago que se encargan de Cloudflare por ti
A veces las cuentas salen solas: mantener tu propia infraestructura stealth cuesta más en horas de ingeniería que una suscripción. Las APIs de scraping de pago externalizan toda la carrera armamentística a un proveedor dedicado: tú envías una URL y ellos se encargan del fingerprinting, los proxies, la resolución de desafíos y los reintentos.
Cómo compararlas:
| Proveedor | Compatibilidad con Cloudflare | Renderizado JS | Proxies residenciales | Salida estructurada | Modelo de precios |
|---|---|---|---|---|---|
| ScrapingBee | Sí | Sí | Sí | Solo HTML | Créditos por solicitud |
| ZenRows | Sí (afirma >99% de éxito) | Sí | Sí (premium) | HTML, algo de parsing | CPM con multiplicadores |
| Scrapfly | Sí (incluye CF, Akamai, DataDome) | Sí | Sí | HTML, algo de parsing | Basado en créditos |
| Browserless | Sí | Sí (Chrome headless) | Sí (incluidos) | HTML, capturas de pantalla | Basado en unidades |
| Thunderbit API | Sí | Sí | Sí | JSON/CSV estructurado con esquema de IA | Plan gratuito + planes de pago |
Cuándo tiene sentido: scraping de alto volumen, requisitos de fiabilidad de nivel enterprise o cuando tu equipo no quiere mantener infraestructura de scraping. Rango de coste: aproximadamente $30–$500+/mes para usos pequeños o medianos, escalando más en volúmenes enterprise.
Vale la pena mencionar Thunderbit API por separado porque devuelve datos estructurados, no solo HTML crudo. Su puede procesar hasta 50 URLs por solicitud y devolver JSON/CSV basado en un esquema impulsado por IA, útil si necesitas datos limpios y listos para análisis en lugar de HTML para parsear tú mismo.
Tabla honesta de fiabilidad: qué funciona de verdad y qué se rompe
He estado siguiendo reportes de la comunidad, issues de GitHub y afirmaciones de proveedores durante 2025–2026. Lo que sigue es una comparación franca. Son estimaciones orientativas, no benchmarks de laboratorio:
| Método | Tasa de éxito estimada | Carga de mantenimiento | Se rompe cuando… | Rango de coste |
|---|---|---|---|---|
| API interna (si existe) | ~90–99% | Baja | La API cambia, se añade autenticación o los tokens pasan a estar firmados | Gratis |
| Extensión del navegador (Thunderbit) | ~85–95% (sesión real) | Baja (la IA se adapta a cambios de layout) | El sitio requiere un flujo de autenticación especial o Turnstile agresivo por acción | Plan gratuito disponible |
curl_cffi / spoofing TLS | ~70–85% | Media (actualizaciones de fingerprint) | Cloudflare cambia los checks JA3, o se requiere un desafío JS activo | Gratis |
| Puppeteer + plugin stealth | ~70–90% | Alta (los plugins se quedan atrás) | Detección CDP, nuevas señales de fingerprint, detección de headless | Gratis + coste de proxy |
| FlareSolverr | ~60–80% | Alta (Docker, deriva de dependencias) | Protección de nivel Enterprise, interacción con Turnstile | Gratis + coste de infraestructura |
| API de scraping de pago | ~85–95% | Baja (la mantiene el proveedor) | El proveedor no se ha actualizado o se supera el presupuesto | ~$30–500+/mes |
La columna más importante no es la tasa de éxito, sino "Se rompe cuando". Todos los métodos tienen un modo de fallo. La mejor estrategia es elegir el método de menor esfuerzo que funcione para tu objetivo y tener un plan de respaldo.
No existe una solución permanente. Cloudflare se actualiza constantemente. La carrera armamentística es real.
Consejos para pasar más desapercibido ante Cloudflare, uses el método que uses
Independientemente del método que elijas, algunos hábitos te ayudan a permanecer fuera del radar de Cloudflare por más tiempo:
- Respeta los límites de tasa. Añade retrasos realistas entre solicitudes: mínimo 2–5 segundos para una navegación parecida a la humana. Atacar un sitio a velocidad de máquina es la forma más rápida de ser bloqueado.
- Mantén coherente tu fingerprint. User-Agent, huella TLS, versión del navegador, zona horaria, configuración regional y geografía de la IP deben contar la misma historia. Un User-Agent de Chrome 136 desde una IP alemana, con locale
en-USy un handshake TLS de Python es una contradicción. - Reutiliza cookies y sesiones después de superar un desafío. No resuelvas el desafío en cada solicitud.
- No cambies de IP a mitad de sesión. Cloudflare rastrea la continuidad de la sesión.
- Usa IPs residenciales o móviles cuando el caso de uso y el presupuesto lo justifiquen.
- Vigila bloqueos suaves: HTML de desafío donde esperabas JSON, tablas vacías, redirecciones a login o páginas que sospechosamente parecen honeypots de .
- Evita las horas punta de tráfico cuando los operadores del sitio pueden endurecer las reglas del WAF.
- Diseña rutas de respaldo: primero API, segundo sesión de navegador, tercero proveedor de pago.
Para los usuarios de Thunderbit en particular, la IA se adapta automáticamente a los cambios de layout de la página, así que dedicas menos tiempo a mantener selectores CSS y más a usar realmente los datos.
Una nota rápida sobre consideraciones legales y éticas
No es el foco de este artículo, pero es demasiado importante como para saltárselo.
El scraping de datos públicos tiene : el razonamiento CFAA en hiQ v. LinkedIn sobrevivió al retorno desde la Corte Suprema, aunque las partes llegaron a un acuerdo en 2022 y el panorama completo es matizado. Más recientemente, en 2025 por el supuesto scraping de comentarios de usuarios, y más adelante ese mismo año.
En la UE, el RGPD se aplica siempre que haya datos personales, y la añade obligaciones específicas sobre .
Reglas prácticas:
- Comprueba siempre los Términos de Servicio del sitio.
- La protección de Cloudflare es una señal de que el propietario quiere controlar el acceso automatizado; respeta esa intención.
- Evita recopilar datos personales sin una base legítima.
- Para flujos comerciales o de alto volumen, prioriza APIs oficiales, datos con licencia o permiso por escrito cuando estén disponibles.
- En caso de duda, consulta con un abogado para tu caso de uso y jurisdicción específicos.
Thunderbit está diseñado para casos de uso empresariales legítimos —generación de leads, monitorización de precios, investigación de mercado— usando datos públicamente accesibles.
Cierre: qué probar primero y qué probar después
El mayor ahorro de tiempo de todo este artículo no es una herramienta ni un fragmento de código: es identificar el nivel de protección antes de empezar. Solo eso evita horas de depurar un método que nunca iba a funcionar.
Empieza por aquí:
- Busca una API interna (es gratis, rápida y suele pasarse por alto).
- Si eres un usuario de negocio que no programa, prueba la : tu sesión real de navegador es tu mejor ventaja frente a Cloudflare.
- Si eres desarrollador y el objetivo usa solo fingerprinting pasivo, prueba
curl_cffi. - Sube a navegadores stealth, FlareSolverr o APIs de pago solo cuando fallen los métodos más simples.
No existe un único método permanente. Combina la herramienta adecuada para tu escala con un plan de respaldo y pasarás mucho menos tiempo mirando páginas 403.
Si quieres profundizar más, hemos escrito sobre , y en el blog de Thunderbit. Y si quieres ver la extensión en acción, visita el para ver tutoriales paso a paso.
Preguntas frecuentes
1. ¿Se puede evitar Cloudflare por completo?
Ningún método garantiza un 100% de éxito, especialmente frente a Bot Management de nivel Enterprise con Turnstile, fingerprinting JA4 y AI Labyrinth. Los enfoques más fiables combinan huellas de navegador reales con una buena reputación de IP. Encontrar una API interna es lo más cercano a un bypass "completo", porque evita Cloudflare por completo, pero no todos los sitios tienen una.
2. ¿Es legal evitar Cloudflare al hacer scraping?
Depende de tu jurisdicción, de los Términos de Servicio del sitio y de qué datos estés recopilando. El scraping de datos públicos tiene jurisprudencia favorable en EE. UU. en algunos contextos (hiQ v. LinkedIn), pero eludir controles técnicos de acceso, violar los TOS o recopilar datos personales sin una base legítima puede generar riesgo legal. Para flujos comerciales, prioriza APIs oficiales o datos con licencia cuando estén disponibles, y consulta a un abogado si no estás seguro.
3. ¿Cuál es la forma más fácil de evitar Cloudflare sin código?
Las extensiones de navegador como , que se ejecutan dentro de tu sesión real de Chrome, gestionan los desafíos de Cloudflare automáticamente: interactúas con el sitio como un usuario normal y luego dejas que la extensión extraiga y exporte los datos. Sin Python, sin Docker y sin configurar proxies.
4. ¿Por qué mi scraper funciona en algunos sitios con Cloudflare pero no en otros?
El nivel de protección de Cloudflare varía muchísimo según el plan (Free, Pro, Business, Enterprise) y la configuración. Un método que funciona contra desafíos JS básicos en un sitio del plan Free puede fallar frente a Turnstile o Bot Management completo en un sitio Enterprise. Identifica siempre primero el nivel de protección —si ves un simple check de JavaScript, un Managed Challenge o un widget de Turnstile— antes de elegir el enfoque de bypass.
5. ¿Cada cuánto se rompen los métodos para evitar Cloudflare?
Los métodos basados en código, como los plugins stealth y el spoofing TLS, pueden degradarse cada pocas semanas o meses en objetivos difíciles, conforme Cloudflare actualiza su detección. Las APIs de pago y las herramientas con sesión real de navegador suelen ser más resistentes porque se adaptan en la capa de infraestructura o de sesión del usuario. Las APIs internas rara vez se rompen, salvo que el sitio rediseñe su backend o cambie su modelo de autenticación. La estrategia más segura a largo plazo es tener varias vías de respaldo en lugar de depender de un solo método.
Más información