Firecrawl se ha convertido en una de las API de web scraping más comentadas en el mundo de los desarrolladores de IA: , respaldo de Y Combinator y una lista de clientes que incluye Shopify, Zapier y Apple. Pero, después de revisar a fondo la documentación de precios, las quejas de usuarios, los benchmarks independientes y los modelos de coste reales, la historia que cuentan los titulares y la experiencia real están bastante alejadas.
Esta reseña de Firecrawl no es otra lista de funciones. Si te has registrado, has hecho unas cuantas pruebas de extracción y ahora te preguntas “¿cuánto me costará esto de verdad a escala?” — o si intentas averiguar si Firecrawl es la herramienta adecuada para tu equipo desde el principio — estás en el lugar correcto. Voy a repasar los costes reales (incluida la trampa de la doble facturación que la mayoría de reseñas pasa por alto), en qué destaca Firecrawl de verdad, en qué se queda corto (especialmente en sitios protegidos por bots) y cuándo conviene más una herramienta totalmente distinta, incluidas opciones sin código como . Mi objetivo: ahorrarte la sorpresa en el extracto de la tarjeta.
¿Qué es Firecrawl y para quién está pensado?
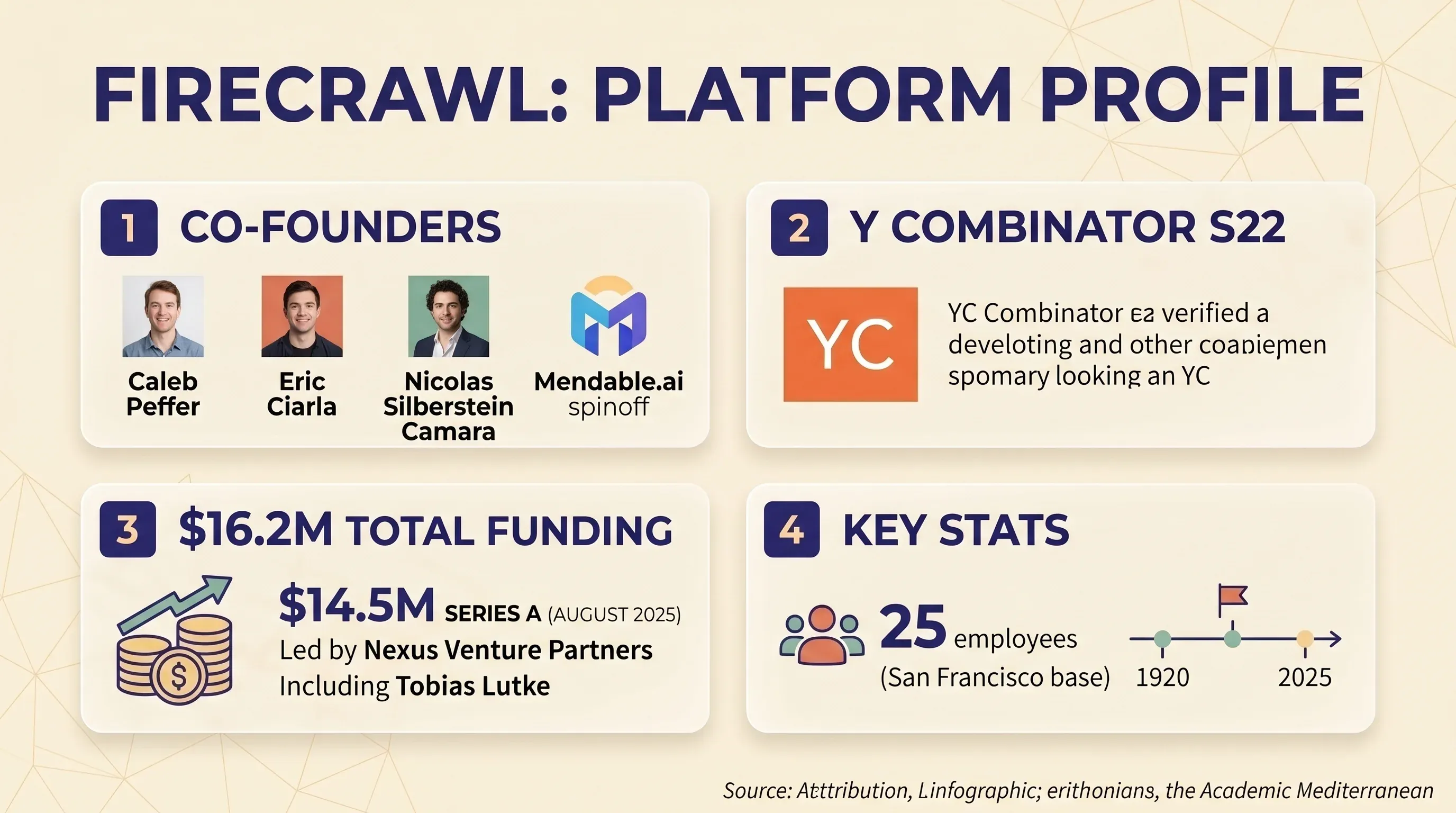
Firecrawl es una plataforma de scraping y rastreo web centrada en API que convierte sitios web en Markdown limpio o JSON estructurado. Está pensada sobre todo para desarrolladores que crean aplicaciones de IA y LLM: pipelines RAG, bases de conocimiento para chatbots y flujos de trabajo con agentes de IA. La empresa fue fundada por Caleb Peffer, Eric Ciarla y Nicolas Silberstein Camara como una derivación de Mendable.ai. Pasaron por y levantaron una en agosto de 2025, liderada por Nexus Venture Partners, con participación del CEO de Shopify, Tobias Lutke. Financiación total: 16,2 millones de dólares. El equipo está formado por 25 personas y tiene su sede en San Francisco.
Firecrawl ofrece cuatro modos principales, además de dos añadidos más recientes:
| Modo | Qué hace |
|---|---|
| Scrape | Convierte una sola URL en Markdown, JSON o captura de pantalla |
| Crawl | Rastrea una URL y todas sus subpáginas |
| Map | Descubre todas las URLs de un sitio en segundos (hasta 100.000 URLs) |
| Search | Búsqueda web con recuperación completa del contenido de la página |
| Extract | Extracción estructurada con IA mediante prompts o esquemas |
| Agent (Vista previa de investigación) | Investigación web autónoma sin especificar URLs |
Quiero ser claro desde el principio: Firecrawl es una herramienta para desarrolladores. Requiere llamadas a la API, conocimientos de programación y configuración técnica. Si eres un usuario de negocio que quiere obtener datos de una web sin escribir código, Firecrawl no está pensado para ti (hablaré de alternativas más adelante). Pero para equipos de desarrollo que construyen aplicaciones de IA, la propuesta es muy atractiva: datos web limpios, listos para LLM, con muy poca fricción de infraestructura.
Reseña de Firecrawl: niveles de precios de un vistazo
En apariencia, los precios de Firecrawl parecen sencillos. Esto es lo que aparece en :
| Plan | Precio mensual | Créditos/mes | Concurrencia | Precio anual |
|---|---|---|---|---|
| Gratis | 0 $ | 500 (únicos, no mensuales) | 2 | — |
| Hobby | 19 $/mes | 3.000 | 10 | 16 $/mes facturados anualmente |
| Standard | 99 $/mes | 100.000 | 50 | 83 $/mes facturados anualmente |
| Growth | 399 $/mes | 500.000 | 100 | 333 $/mes facturados anualmente |
| Scale | 749 $/mes | 1.000.000 | 1.000 | 599 $/mes facturados anualmente |
Hay un par de cosas que saltan a la vista de inmediato. Los 500 créditos del plan gratuito son únicos, no mensuales; muchos usuarios no se dan cuenta hasta que los agotan en una sola sesión de prueba. Y esos niveles parecen simples, pero el coste real depende mucho de las funciones que uses. El precio publicado es solo el punto de partida. ¿La factura real? De eso trata la siguiente sección.
El coste real de Firecrawl: calculadora de créditos para tu caso de uso
El precio es el mayor punto de dolor entre los usuarios reales de Firecrawl: “es condenadamente caro”, “tendría que estar en el plan de 99 $/mes para mi nivel de uso” y “escandalosamente caro” son citas reales de hilos de Hacker News y Reddit. ¿La razón? Hay un sistema de doble cobro que la mayoría de reseñas de Firecrawl ignora por completo.
Aquí está la trampa: los planes de créditos de Firecrawl cubren Scrape, Crawl, Map y Search. Pero Extract — la extracción estructurada con IA, que es uno de los grandes atractivos de Firecrawl — funciona con una suscripción de tokens completamente aparte.
| Plan de Extract | Precio mensual | Tokens/año | Tokens/mes (aprox.) |
|---|---|---|---|
| Starter | 89 $/mes | 18 M | ~1,5 M |
| Standard | 189 $/mes | 48 M | ~4 M |
| Growth | 389 $/mes | 108 M | ~9 M |
| Pro | 719 $/mes | 192 M | ~16 M |
Así que una startup en el plan de créditos Standard (99 $/mes) que además necesita extracción paga 99 + 89 = 188 $/mes como mínimo — antes de que entren en juego multiplicadores de créditos. Esa es la trampa de la doble facturación que pilla a mucha gente por sorpresa.
Multiplicadores ocultos de créditos que la mayoría pasa por alto
El titular de “1 crédito por página” es engañoso. Esto es lo que cuestan realmente las funciones:
| Función | Coste en créditos | Multiplicador efectivo |
|---|---|---|
| Scrape/Crawl básico | 1 crédito/página | 1x |
| Search | 2 créditos/10 resultados | 2x por conjunto de resultados |
| Extracción JSON (vía Scrape) | +4 créditos/página | 5x en total |
| Enhanced Mode | +4 créditos/página | 5x en total |
| JSON + Enhanced Mode | +8 créditos/página | 9x en total |
| Interacciones con el navegador | 2 créditos/minuto | Variable |
| Modo Agent (spark-1-mini) | Dinámico, ~100–500/consulta | 100–500x |
| Modo Agent (spark-1-pro) | Dinámico, ~200–1.500+/consulta | 200–1.500x |
Y hay algunos detalles más que importan: los créditos no se acumulan de un mes a otro. Las solicitudes fallidas también consumen créditos (los usuarios reportan un desperdicio del 20–30 % en sitios inestables). El modo Agent no tiene estimador de coste previo: defines un parámetro maxCredits, pero en la práctica estás adivinando. Los 500 créditos vitalicios del plan gratuito equivalen a unas 56 páginas si activas la extracción. Eso no es una prueba; es un aperitivo.
Tabla de coste mensual de ejemplo por perfil de usuario
| Perfil de usuario | Páginas mensuales | Funciones usadas | Consumo estimado de créditos | Coste mensual estimado |
|---|---|---|---|---|
| Aficionado / proyecto paralelo | 500 | Scrape + Crawl básicos | ~500 créditos | 19 $/mes (plan Hobby) |
| Aficionado + extracción JSON | 500 | Scrape + Extract | ~2.500 créditos + 89 $ de Extract | 108 $/mes |
| Startup / app de IA | 5.000 | Scrape + Extract + Search | ~30.000 créditos + 89 $ de Extract | 188 $/mes (Standard + Extract) |
| Empresa / canal de datos | 50.000 | Stack completo + Agent | ~250.000–450.000 créditos + 389 $ de Extract | 788–1.138 $/mes |
Un desarrollador de Hacker News que pagaba 190 $ al mes dijo que la experiencia era “cara y daba sensación de estar a medio hacer” y sustituyó Firecrawl por 2.700 líneas de código Elixir a medida. Es una señal bastante fuerte.
Firecrawl autohospedado: qué es realmente gratis y qué es solo para la nube
“¿Puedo simplemente autohospedar Firecrawl gratis?” es una de las preguntas más habituales que veo. La respuesta es: más o menos, pero probablemente no de la forma que esperas.
Firecrawl tiene un núcleo open source (licencia AGPL-3.0), pero varias funciones importantes son exclusivas de la nube. Aquí va el desglose definitivo:
| Capacidad | Autohospedado (gratis) | Nube (de pago) |
|---|---|---|
| Scrape/Crawl básico a Markdown | ✅ | ✅ |
| Map (descubrimiento de URLs) | ✅ | ✅ |
| Extract con IA/LLM | ⚠️ (aportas tus propias claves de LLM) | ✅ (gestionado) |
| Modo Agent | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Antibot / rotación de proxies (Fire-engine) | ❌ (usa tu IP estática) | ✅ |
| Procesamiento por lotes | ❌ | ✅ |
| Panel / analíticas | ❌ | ✅ |
| Infraestructura gestionada | ❌ (requiere Docker + PostgreSQL + Redis) | ✅ |
Fire-engine, el sistema propietario de anti-bot de Firecrawl, . Los usuarios autohospedados no obtienen ninguna capacidad anti-bot y deben aportar sus propios proxies.
Para quién sigue teniendo sentido autohospedar
Autohospedar funciona si eres un desarrollador que quiere un pipeline básico de rastreo a Markdown y te sientes cómodo gestionando Docker Compose con más de 5 servicios. Requisitos mínimos: 4 GB de RAM, 2 núcleos de CPU, además de claves de API de LLM para la extracción (0,01–0,10 $/página) y servicios de proxy si los necesitas. En total, los costes del autohospedaje rondan 90–340 $/mes — lo que a menudo es comparable a los planes en la nube a volumen moderado.
Por qué frustra a los usuarios la versión autohospedada
Los comentarios reales de usuarios pintan un panorama duro. Varios hilos de Reddit y GitHub describen que la versión autohospedada se va degradando con el tiempo a medida que las funciones pasan a ser exclusivas de la nube. Un usuario lo resumió sin rodeos: la empresa “intenta empujar a todos los usuarios a pagar ahora y hacer que la versión autohospedada quede inútil”. La comunidad incluso creó un fork llamado firecrawl-simple para resolver algunos problemas. Si cuentas con el autohospedaje como solución gratuita a largo plazo, ajusta tus expectativas: es un buen punto de partida para experimentar, pero no sustituye al producto cloud de pago a escala.
Rendimiento anti-bot de Firecrawl: dónde funciona y dónde no
Esta es la sección que más importa si te preguntas: “¿Firecrawl funcionará de verdad en los sitios que necesito extraer?”
La respuesta corta: depende por completo de lo bien protegidos que estén esos sitios.
Los números del benchmark
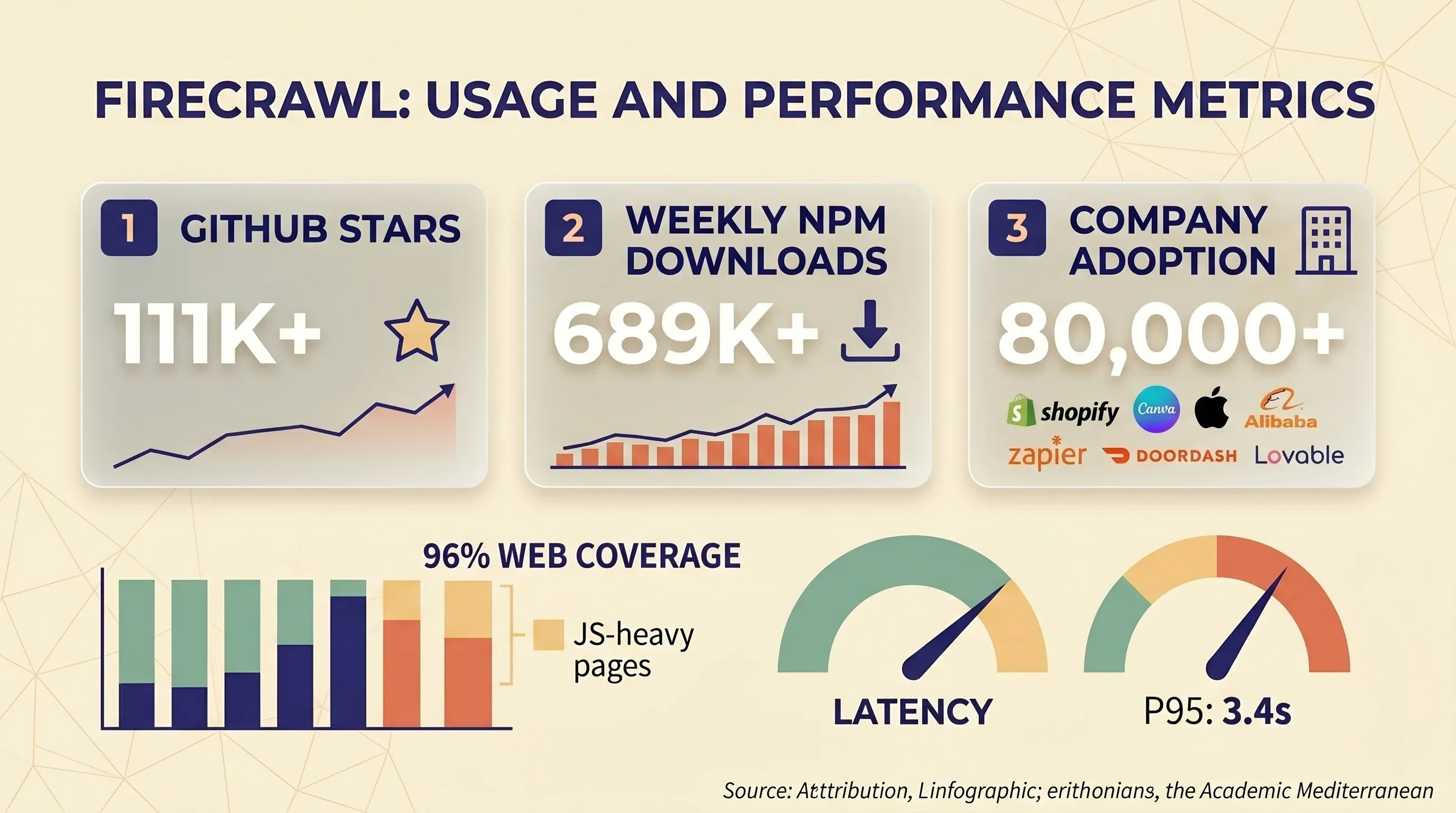
probó de forma independiente 10 API de scraping web contra 15 sitios muy protegidos por bots. Resultados de Firecrawl:
| Proveedor | Tasa de éxito (2 req/s) | Tasa de éxito (10 req/s) |
|---|---|---|
| Zyte | 93,14 % | 89,2 % |
| ScrapFly | 91,8 % | 88,5 % |
| Bright Data | 88,7 % | 84,9 % |
| Firecrawl | 33,69 % | 26,69 % |
Firecrawl quedó de 10 proveedores en sitios protegidos. Su tiempo de respuesta rápido (7,92 segundos de media) se explica en parte por una estrategia de “fallar rápido”: devuelve errores con rapidez en lugar de reintentar.
El benchmark más amplio y continuo de sitúa a Firecrawl con una tasa de éxito global del 65,4 % (por encima del 59,5 % de media del sector), con buenos resultados en objetivos fáciles, pero malos en los protegidos.
Desglose de dificultad de sitios: objetivos fáciles, medios y difíciles
| Dificultad | Sitios de ejemplo | Tasa de éxito de Firecrawl | Recomendación |
|---|---|---|---|
| Fácil | Blogs, documentación, páginas SaaS públicas | 85–98 % | Usa Firecrawl con confianza |
| Media | Catálogos de productos, sitios de noticias con protección antibot básica, Etsy, Realtor.com | 53–65 % | Prueba con cuidado, espera fallos |
| Difícil | Amazon, LinkedIn, Instagram, páginas con mucho Cloudflare | 0–33 % | No dependas de Firecrawl; usa proveedores especializados en anti-bot |
Los sitios protegidos por Cloudflare son el punto de fallo más reportado. Varios issues de GitHub documentan el problema: la detección basada en huellas de Cloudflare bloquea Firecrawl incluso cuando se usa rotación de IP. Los usuarios autohospedados son los que más sufren, ya que no cuentan con la infraestructura de proxy de Fire-engine.
Qué hacer cuando Firecrawl no basta
Para sitios muy protegidos, los usuarios suelen recurrir a servicios de proxy especializados como ScrapFly o Bright Data, o a herramientas de navegador sin cabeza con configuraciones stealth personalizadas. Si eres un usuario de negocio y no quieres lidiar con la rotación de proxies ni con cálculos de tasa de éxito, herramientas sin código como gestionan los problemas anti-bot por detrás; tú solo haces clic y obtienes tus datos.
Pros y contras de Firecrawl: un resumen honesto
Lo que Firecrawl hace bien
- Salida limpia en Markdown, lista para LLM — siempre bien formateada y con una estructura de encabezados correcta. Es, sinceramente, el mayor punto fuerte de Firecrawl.
- Sin sobrecarga de infraestructura para usuarios de la nube — sin configuración de navegador, sin gestión de proxies ni configuración de browser headless.
- Amplias integraciones con frameworks — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (más de 7 integraciones para pipelines de IA).
- Descubrimiento rápido de URLs mediante el endpoint Map — 2–3 segundos para un sitemap completo.
- Núcleo open source con — transparencia y contribuciones de la comunidad.
- Compatibilidad con servidor MCP con el modelo FIRE-1 para flujos de trabajo de agentes de IA.
- en páginas pesadas en JS (SPAs en React, Vue y Angular).
Donde Firecrawl se queda corto
- Precio doble (créditos + suscripción separada de Extract) genera sorpresas de facturación que nadie espera.
- Los multiplicadores de créditos inflan el coste real entre 5 y 9 veces por encima del precio principal.
- Rendimiento anti-bot: último lugar en el benchmark de Proxyway ( frente al mejor, con 93,14 %).
- El modo Agent tiene un consumo de créditos impredecible y no ofrece estimador previo.
- Las solicitudes fallidas siguen consumiendo créditos — 20–30 % de desperdicio en sitios inestables.
- La versión autohospedada no incluye Agent, Browser Sandbox, anti-bot Fire-engine ni panel.
- No tiene resolución nativa de CAPTCHA — una carencia importante frente a Bright Data y Zyte.
- No es accesible para usuarios no técnicos — requiere programación y conocimientos de API.
- Los 500 créditos del plan gratis son de por vida, no mensuales; insuficientes para pruebas serias.
Más allá de las herramientas para desarrolladores: alternativas sin código que las reseñas de Firecrawl nunca mencionan
Todas las reseñas de Firecrawl que he leído lo comparan exclusivamente con otras herramientas para desarrolladores: Crawl4AI, Scrapy, Playwright, Apify. Tiene sentido si eres desarrollador. Pero una parte enorme de las personas que buscan soluciones de web scraping no son desarrolladores: equipos de ventas que crean listas de prospectos, operaciones de ecommerce que vigilan precios de la competencia, marketers que recopilan datos de contenido, agentes inmobiliarios que siguen listados.
Ese es un hueco que merece la pena cubrir.
Tabla comparativa de alternativas a Firecrawl
| Herramienta | Ideal para | ¿Requiere código? | Salida lista para LLM | Precio inicial |
|---|---|---|---|---|
| Firecrawl | Desarrolladores que crean apps de IA | Sí (API) | ✅ Markdown/JSON | 19 $/mes |
| Crawl4AI | Desarrolladores que quieren gratis/OSS | Sí (Python) | ✅ Markdown | Gratis |
| Apify | Desarrolladores que necesitan escala + marketplace | Sí (SDK) | ⚠️ Con configuración | 39 $/mes |
| Thunderbit | Usuarios de negocio (sin código) | No (extensión de Chrome) | ✅ Datos estructurados | Hay plan gratis |
| ScrapingBee | Desarrolladores que necesitan proxy | Sí (API) | ❌ HTML en bruto | 49 $/mes |
| Bright Data | Equipos de datos empresariales | Sí (API/SDK) | ⚠️ Con configuración | 500 $+/mes |
Por qué Thunderbit es la opción preferida para equipos no técnicos
Trabajo en el equipo de Thunderbit, así que voy a ser transparente con eso. Thunderbit entra en esta comparación porque resuelve un problema distinto al de Firecrawl, para una audiencia distinta, sin requerir código.
El flujo de trabajo de Thunderbit son dos clics: abre la , haz clic en “Sugerir campos con IA” y luego en “Extraer”. La IA lee la página, sugiere las columnas correctas y extrae los datos estructurados en una tabla. Sin claves de API, sin selectores, sin programación. Puedes exportar gratis a Excel, Google Sheets, Airtable o Notion.
Diferenciadores clave para usuarios de negocio:
- Enriquecimiento de subpáginas — entra en páginas de detalle y extrae campos adicionales automáticamente
- IA que se adapta a cambios de diseño — no hace falta mantenimiento cuando un sitio se rediseña
- Etiquetado y traducción de datos integrados — útil para conjuntos de datos multilingües
- Plantillas instantáneas para sitios populares (Amazon, Zillow, LinkedIn, etc.)
Para desarrolladores que quieren una alternativa por API, Thunderbit también ofrece con precios más sencillos que el sistema dual de créditos y tokens de Firecrawl. No sustituirá a Firecrawl para desarrolladores de pipelines LLM. Pero para equipos de ventas, ecommerce, marketing y operaciones que necesitan datos estructurados sin escribir código, es una ruta más rápida y barata.
Construir frente a comprar: cuándo Firecrawl se amortiza y cuándo no
“Pensé en escribir mi propio scraper web… más simple que Firecrawl, pero al menos más barato.” Varios usuarios plantean este punto. En lugar de una opinión subjetiva, aquí tienes un marco de decisión estructurado.
Tabla del marco de decisión
| Factor | Construcción a medida (Scrapy/Playwright) | Comprar Firecrawl Cloud | Usar Thunderbit (sin código) |
|---|---|---|---|
| Tiempo de configuración | 10–40+ horas | ~30 minutos | ~5 minutos |
| Mantenimiento continuo | Alto (se rompen selectores) | Casi nulo (gestionado) | Nulo (la IA se adapta) |
| Gestión anti-bot | Manual (proxy, headers, reintentos) | Integrada (parcial: floja en sitios protegidos) | Integrada (modos navegador + nube) |
| Coste a 1.000 páginas/mes | 50–150 $ (servidor + proxy) | 19–108 $ (depende de las funciones) | 0–15 $ |
| Coste a 50.000 páginas/mes | 500–1.500 $ (infraestructura) | 399–1.138 $ | 39–249 $ |
| Salida lista para LLM | Requiere código a medida | Integrada (Markdown/JSON) | Tablas estructuradas (exportables) |
| Ideal para | Control total, sitios de nicho, equipos DevOps | Desarrolladores de IA/LLM, pipelines RAG | Ventas, ecommerce, marketing, operaciones |
Construir algo a medida resulta que usar APIs durante tres años para la mayoría de las organizaciones. El punto de cruce en el que lo propio sale más barato está aproximadamente en más de 10 millones de páginas al mes, una escala a la que muy pocos equipos llegan de verdad.
Veredicto honesto: ¿qué camino encaja contigo?
Firecrawl se amortiza cuando:
- Tu equipo ya programa en Python/JS y necesita Markdown limpio para pipelines LLM/RAG
- Apuntas sobre todo a sitios sin protección o con protección ligera
- Quieres infraestructura gestionada sin carga de DevOps
- El volumen se mantiene por debajo de unas 50.000 páginas/mes
Firecrawl no se amortiza cuando:
- Eres un usuario de negocio haciendo extracciones sin equipo de desarrollo → Thunderbit es más fácil y rápido
- Apuntas a sitios muy protegidos (Amazon, LinkedIn, mucho Cloudflare) → Bright Data o Zyte
- Necesitas una facturación predecible a escala → los multiplicadores de créditos hacen impredecibles los costes
- Quieres autohospedar con todas las funciones → Agent, Browser Sandbox y Fire-engine son exclusivos de la nube
Construir a medida solo tiene sentido cuando:
- Tu equipo tiene capacidad DevOps dedicada
- Estás a una escala masiva (más de 10 millones de páginas/mes)
- Necesitas control total sobre el manejo de sitios de nicho o peculiares
- Te sientes cómodo con el mantenimiento continuo de selectores
Reseña de Firecrawl: tabla comparativa lado a lado
Aquí está todo comparado:
| Herramienta | Tipo | Ideal para | ¿Requiere código? | Gestión anti-bot | Salida lista para LLM | Opción de autohospedaje | Precio inicial |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | Desarrolladores de IA/LLM | Sí | Floja en sitios protegidos | ✅ Markdown/JSON | ✅ (limitada) | 19 $/mes |
| Crawl4AI | Biblioteca de Python | Desarrolladores centrados en OSS | Sí | Ninguna (DIY) | ✅ Markdown | ✅ | Gratis |
| Apify | Plataforma cloud | Escala + marketplace | Sí | Moderada | ⚠️ Con configuración | ✅ | 39 $/mes |
| Thunderbit | Extensión de Chrome + API | Usuarios de negocio, sin código | No | Integrada | ✅ Datos estructurados | ❌ | Plan gratis |
| ScrapingBee | API | Desarrolladores centrados en proxy | Sí | Fuerte | ❌ HTML en bruto | ❌ | 49 $/mes |
| Bright Data | API + red de proxies | Equipos de datos empresariales | Sí | La mejor (~99,9 %) | ⚠️ Con configuración | ❌ | 500 $+/mes |
Veredicto final: ¿merece la pena Firecrawl?
Firecrawl es una herramienta sólida para un caso de uso concreto: equipos de desarrollo que construyen apps LLM, pipelines RAG o agentes de IA y que necesitan datos web limpios a escala moderada y se sienten cómodos con flujos de trabajo basados en API. La calidad de la salida en Markdown es realmente de primer nivel, y las integraciones con frameworks (LangChain, LlamaIndex, CrewAI) están maduras. Si tu equipo ya trabaja en Python o JavaScript y los sitios objetivo no están muy protegidos por bots, Firecrawl puede ahorrarte bastante tiempo de ingeniería.
Sin embargo, los inconvenientes son reales. El sistema de precios doble (créditos + suscripción separada de Extract) crea sorpresas de facturación de las que nadie quiere enterarse. La en sitios protegidos significa que no puedes confiar en él para Amazon, LinkedIn o objetivos con mucho Cloudflare. La versión autohospedada carece de demasiadas funciones como para ser una alternativa gratuita de verdad. Y si eres un usuario no técnico — alguien de ventas, ecommerce o marketing — Firecrawl no está hecho para ti en absoluto.
Prueba los 500 créditos gratuitos de Firecrawl para ver si la calidad de la salida encaja con tu pipeline. Pero modela tus costes mensuales reales con la calculadora de arriba antes de comprometerte con un plan de pago. Si eres un usuario de negocio que solo necesita datos estructurados de sitios web sin escribir código, empieza mejor con — estarás extrayendo datos en minutos, no en horas. Puedes probar ahora mismo la o revisar para ver qué escala mejor para tu equipo. Para tutoriales en vídeo, el tiene demos paso a paso.
Preguntas frecuentes
¿Cuánto cuesta Firecrawl por página extraída?
Un scrape o crawl básico cuesta 1 crédito por página. La extracción JSON añade 4 créditos por página (5 en total). Enhanced Mode añade otros 4 (hasta 9 en total). Search cuesta 2 créditos por cada 10 resultados, y el modo Agent puede consumir entre 100 y más de 1.500 créditos por consulta. Además, la función Extract requiere una suscripción aparte de tokens que empieza en 89 $ al mes. Consulta la sección de calculadora de costes de arriba para estimaciones realistas según el perfil de usuario.
¿Se puede autohospedar Firecrawl gratis?
Sí, el núcleo open source (AGPL-3.0) se puede autohospedar gratis. Pero perderás el modo Agent, Browser Sandbox, la rotación anti-bot/proxy (Fire-engine es de código cerrado), el procesamiento por lotes y el panel de gestión. Tendrás que aportar tus propias claves de LLM para la extracción y encargarte tú mismo de Docker, PostgreSQL y Redis. El autohospedaje sirve para pipelines básicos de rastreo a Markdown, pero no sustituye al producto cloud en producción a escala.
¿Firecrawl es bueno para extraer Amazon, LinkedIn u otros sitios protegidos?
El muestra que Firecrawl logra una tasa de éxito del 33,69 % en sitios muy protegidos por bots: el peor de los 10 proveedores probados. Funciona bien en páginas sin protección (blogs, documentación, sitios SaaS: 85–98 % de éxito), pero no es fiable para grandes plataformas de ecommerce o sociales. Para esos objetivos, considera proveedores anti-bot especializados como Bright Data o Zyte, o herramientas sin código como Thunderbit que gestionan el anti-bot por detrás.
¿Cuál es la mejor alternativa a Firecrawl para usuarios no técnicos?
es la mejor alternativa sin código. Es una extensión de Chrome en la que haces clic en “Sugerir campos con IA” y luego en “Extraer”: sin llamadas a la API, sin programación, sin selectores. Los datos se exportan gratis a Excel, Google Sheets, Airtable o Notion. Está pensado para equipos de ventas, ecommerce, marketing y operaciones que necesitan datos web estructurados sin depender de un desarrollador.
¿Firecrawl ofrece una prueba gratis?
Firecrawl ofrece sin necesidad de tarjeta de crédito. Es suficiente para probar la función básica de scrape/crawl en unas cuantas páginas, pero no para uso en producción, especialmente si activas la extracción (que consume 5 créditos por página). Los créditos no se renuevan mensualmente en el plan gratis.
Más información