

En muchas oficinas está pasando algo que casi nadie comenta, y no tiene que ver con las mesas de ping-pong ni con el café de especialidad. Hablo de algo más útil: por fin cualquiera puede sacar datos de la web en minutos, sin saber programar. Si alguna vez te has quedado mirando una página pensando «ojalá pudiera llevarme estos nombres, estos precios o estos correos a una hoja de cálculo de una vez», ya somos dos. Y, sinceramente, no eres ningún bicho raro: comerciales, gente de marketing y equipos de operaciones me sueltan siempre la misma frase, «¿por qué sigue costando tanto?».
La verdad es que la demanda de formas sencillas de hacer scraping no para de crecer. El State of AI 2025 de McKinsey cifra en el 71 % las organizaciones que ya usan IA generativa en al menos una función del negocio, frente al 65 % de principios de 2024, y la extracción de datos web es uno de los usos que más rápido sube. El mercado del scraping apunta a 1.170 millones de dólares en 2026 y a 2.230 millones en 2031, con los perfiles de negocio —sobre todo los que no tocan código— tirando del carro hacia herramientas que conviertan extraer datos en algo tan tonto como copiar y pegar. Ahora bien, ¿qué es exactamente eso de la «extracción web fácil» y cómo te sirve para aligerar tu día a día? Te lo cuento por partes.
Prueba la extracción web fácil con Thunderbit (gratis)
Extracción web fácil para perfiles no técnicos: sin código y sin quebraderos de cabeza
Vamos con lo básico: ¿qué significa «extracción web fácil»? En el fondo, es coger la web —ese caos cambiante— y convertirla en tablas limpias y ordenadas, sin escribir una sola línea de código. Para quien no es técnico, esto marca un antes y un después. Se acabó pedir favores a sistemas, se acabó pelearse con scripts de Python y se acabó tirar la toalla porque una web rediseñó su maquetación de un día para otro.
¿Por qué importa tanto justo ahora? Porque la web está más viva que nunca. El scroll infinito, los pop-ups y el JavaScript enrevesado revientan los scrapers de toda la vida cada dos por tres. Y, al mismo tiempo, a los equipos de negocio se les exige información rápida como nunca antes. En retail y ecommerce, el 98 % de las organizaciones considera que los datos públicos de la web son cruciales o muy importantes para su operativa, y más de la mitad los consulta a diario.
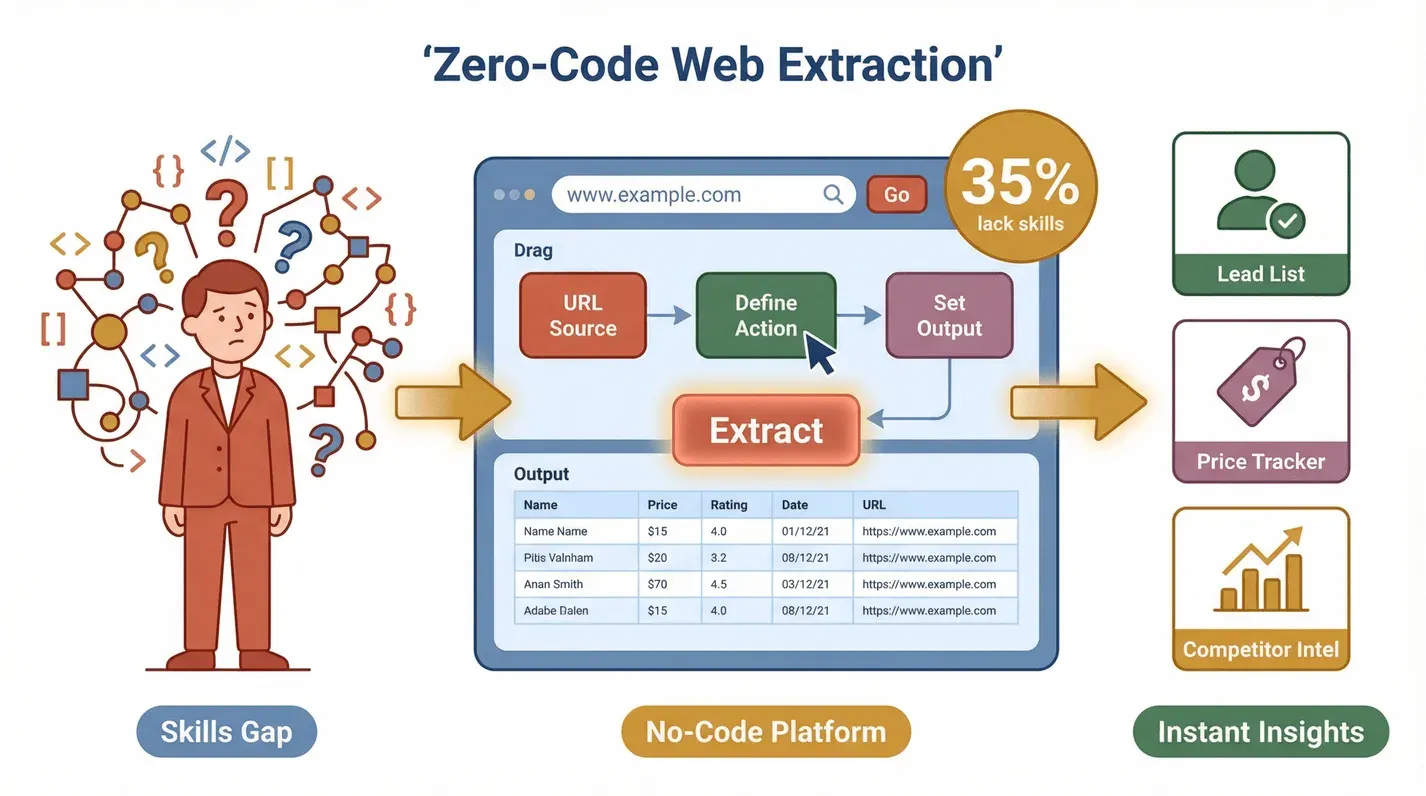
Pero aquí está el meollo: casi ninguno de esos equipos es técnico. Una encuesta reciente reveló que el 35 % de las organizaciones no tiene las competencias necesarias para extraer datos web y que al 33 % le faltan las herramientas adecuadas. Ahí hay un hueco enorme para las soluciones sin código. Cuando cualquiera puede sacar datos de la web y usarlos, se abre otra liga de productividad: tanto da que estés montando una lista de leads, vigilando a la competencia o siguiendo precios.
El movimiento no-code/low-code: por qué te interesa
El despegue de las herramientas no-code y low-code va de democratizar la tecnología. No es una moda pasajera de Silicon Valley; es un cambio de fondo en cómo trabajamos. Llevado al scraping, se traduce en esto:
- Cero programación: extrae datos cualquiera, no solo el equipo de ingeniería.
- Velocidad: tienes resultados en minutos, no en días.
- Flexibilidad: te adaptas al vuelo a sitios nuevos y a datos nuevos.
- Menos errores: la automatización corta los fallos típicos del copia y pega.
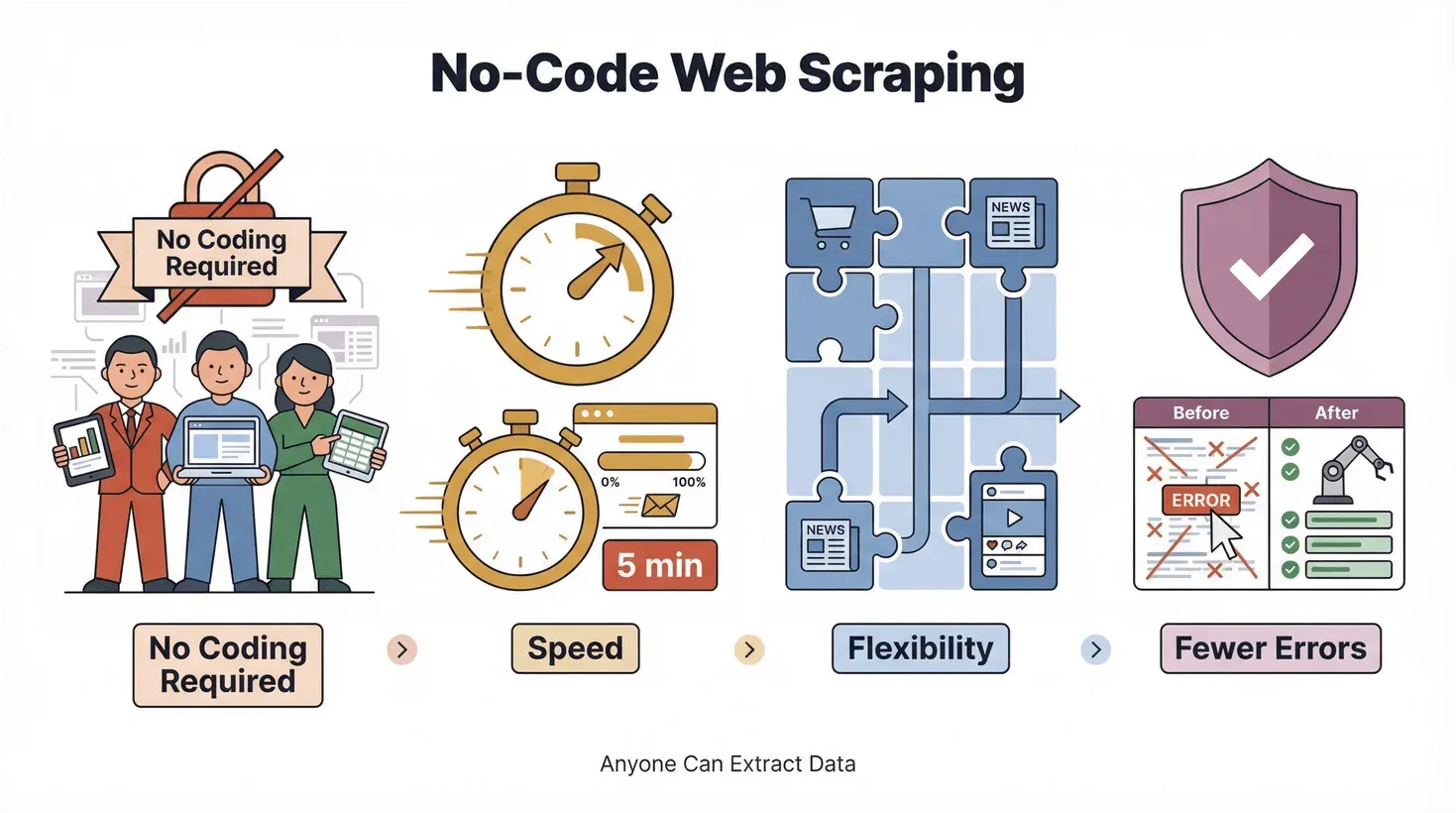
Y lo mejor: no tienes que volverte un gurú de la tecnología para sacarle partido.
Por qué las herramientas clásicas de scraping te sacan de quicio
Seamos francos: las herramientas de scraping de toda la vida parecen hechas por desarrolladores y para desarrolladores, no para quien trabaja en negocio. Lo he visto un montón de veces: un equipo se ilusiona con un proyecto y choca de frente con un muro en cuanto la herramienta le pide selectores CSS, XPath o expresiones regulares. Y llegan las caras de circunstancia y el correo de «mejor lo vemos el trimestre que viene».
Esto es lo que suele torcerse:
- Hay que programar: la mayoría de las herramientas clásicas te obligan a escribir scripts o a montar plantillas complicadas.
- Configuración pesada: toca mapear campo a campo, gestionar los inicios de sesión y montar proxies para esquivar bloqueos.
- Lógica frágil: el sitio cambia el diseño y, de golpe, tu scraper deja de funcionar. Ya estás depurando código en vez de trabajar.
- Mantenimiento sin fin: cada vez que la web se actualiza, vuelta a empezar.
No extraña que los mismos equipos que se quejan de falta de competencias se quejen también de falta de herramientas: la encuesta de Bright Data de 2024 constató que al 35 % de las organizaciones le faltan las competencias adecuadas y al 33 % las herramientas adecuadas para trabajar con datos públicos de la web. Hasta los equipos más rodados sudan con los bloqueos de IP, el contenido dinámico y los CAPTCHAs.
Mientras tanto, los perfiles de negocio solo quieren una forma sencilla y fiable de llevar los datos a su hoja de cálculo o a su CRM. Y ahí es donde entran la extracción web fácil y los métodos de scraping sencillos.
Cómo Thunderbit hace posible la extracción web fácil
Extrae datos de cualquier sitio web con IA Get Started Free
Aquí me crezco un poco, porque este es justo el problema que nos propusimos resolver en Thunderbit. Nuestra misión es hacer el scraping tan simple que lo pueda usar cualquiera, tenga el nivel técnico que tenga.
Thunderbit es una extensión de Chrome de AI Web Scraper que reduce la extracción a dos clics. Funciona así:
- Di qué necesitas: en lenguaje natural, le indicas a Thunderbit qué datos quieres. Por ejemplo: «Saca todos los nombres y precios de producto de esta página».
- Pulsa «AI Suggest Fields»: la IA de Thunderbit lee la página y propone las mejores columnas, tipo «Nombre», «Precio», «Email» o «Imagen».
- Pulsa «Scrape»: Thunderbit se encarga del resto: paginación, subpáginas e incluso contenido tras inicio de sesión si hace falta.
Y ya. Sin código, sin plantillas, sin sufrir en la configuración. La interfaz está pensada para perfiles de negocio —ventas, marketing, ecommerce, inmobiliario— que lo único que quieren son resultados.
El flujo con IA de Thunderbit: más listo, no más complicado
La magia de verdad está en la IA. Thunderbit no adivina a ciegas lo que buscas: lee la página, entiende el contexto y estructura los datos sola. Si quieres hilar más fino, puedes añadir instrucciones a medida para cada campo (por ejemplo, «clasifica esta columna» o «traduce al inglés»), aunque la mayoría de la gente pulsa y a otra cosa.
Este enfoque con IA significa:
- Menos errores: la IA se ajusta a maquetaciones distintas, así que el resultado es consistente aunque el sitio cambie.
- Configuración más rápida: ni plantillas ni scripts.
- Datos que sirven: Thunderbit etiqueta, categoriza e incluso enriquece tus datos mientras los extrae.
Si quieres rascar más, échale un ojo a la documentación de Thunderbit o a nuestro artículo sobre extracción automatizada de datos. También tienes más guías en el Blog de Thunderbit, como Cómo extraer cualquier web usando IA y Qué es el data scraping y cómo hacerlo en 2025.
Funciones propias de Thunderbit para un scraping sencillo
Lo que distingue a Thunderbit no es solo la IA, sino todo el flujo, diseñado para necesidades de negocio reales. Estas son algunas de las funciones que más enganchan a nuestros usuarios:
- Paginación automática: Thunderbit se apaña con sitios de varias páginas y scroll infinito sin que toques nada.
- Extracción de subpáginas: ¿quieres más detalle? Thunderbit entra en cada subpágina (fichas de producto, perfiles de LinkedIn) y enriquece tu conjunto de datos solo.
- Exporta a donde quieras: lleva tus datos directos a Excel, Google Sheets, Airtable o Notion, o descárgalos como CSV/JSON. Adiós a las sesiones maratonianas de copia y pega.
- Va en páginas con inicio de sesión: extrae de sitios que exigen cuenta; como Thunderbit corre en tu navegador, ve lo mismo que ves tú.
- Etiquetado y categorización con IA: añade instrucciones para clasificar, etiquetar o traducir los datos sobre la marcha.
- Scraping programado: monta tareas recurrentes para tener los datos siempre frescos, perfecto para seguir precios o leads.
Y sí, todo esto está en una herramienta en la que confían más de 100.000 usuarios en todo el mundo.
Paginación automática y extracción de subpáginas
Uno de los mayores dolores de cabeza del scraping es lidiar con listas paginadas o con páginas de detalle anidadas. Con Thunderbit te olvidas. La IA detecta la paginación —da igual que sea un botón de «Siguiente» o un scroll infinito— y sigue sola los enlaces a las subpáginas. Es decir, puedes sacar cientos o miles de registros de una tacada, sin ir clicando a mano.
Por ejemplo, si estás extrayendo un listado de productos de Amazon, Thunderbit captura todos los productos de las distintas páginas y luego entra en cada ficha a por reseñas, valoraciones o datos del vendedor. Como tener un becario que nunca se cansa.
Exportación en varios formatos e integración con tu CRM
Los datos solo valen si de verdad los puedes usar. Thunderbit te deja exportar en el formato que necesite tu equipo: Excel, Google Sheets, Airtable, Notion o CSV/JSON. Y puedes mandar los datos directos a tu CRM o a tus herramientas de trabajo, para que ventas y operaciones tengan siempre lo último.
Esa conexión directa te ahorra un montón de tiempo. Se acabó limpiar exportaciones desordenadas o recolocar columnas: de eso se ocupa la IA de Thunderbit.
Casos reales de extracción web fácil
Entonces, ¿dónde se nota más la extracción web fácil? Te dejo algunos escenarios reales que veo entre usuarios de Thunderbit:
Extracción de leads para ventas
Los equipos comerciales se juegan el pan con sus listas de leads. Con Thunderbit sacas datos de contacto de LinkedIn, Google Maps o directorios de empresas en minutos. Abres la página, pulsas «AI Suggest Fields» y dejas que Thunderbit lleve nombres, correos, teléfonos y datos de empresa a una hoja lista para usar.
Un responsable comercial me contó que antes echaban horas a la semana copiando y pegando leads. Ahora, con Thunderbit, montan listas segmentadas en una fracción del tiempo y el equipo se centra en prospectar, no en meter datos.
Ecommerce y vigilancia de mercado
Los equipos de ecommerce usan Thunderbit para seguir SKUs, precios y reseñas de la competencia en Amazon, Shopify y demás. ¿Quieres controlar cambios de precio o lanzamientos? Programa una extracción y recibe datos frescos cada mañana en tu Google Sheet.
La extracción de subpáginas de Thunderbit viene de perlas aquí: consigues detalles de producto, imágenes y hasta reseñas de clientes sin mover un dedo.
Recopilación de datos inmobiliarios
Los profesionales del inmobiliario tiran de Thunderbit para reunir anuncios, precios e información de agentes en sitios como Zillow o Realtor.com. La IA se encarga de la paginación y las subpáginas, así que tienes una foto completa y al día del mercado, ideal para análisis o informes a clientes.
Un analista del sector me decía que algo que antes le ocupaba toda la tarde ahora se resuelve en unos clics. Eso es lo que dan los métodos de scraping sencillos.
Métodos tradicionales frente a métodos de scraping sencillos
Pongámoslo todo junto en una comparativa cara a cara:
| Función | Scrapers tradicionales | Extracción web fácil (Thunderbit) |
|---|---|---|
| Hace falta programar | Sí (scripts, selectores) | No (IA + lenguaje natural) |
| Tiempo de configuración | Alto (plantillas, configuración) | Bajo (2 clics) |
| Mantenimiento | Frecuente (se rompe con cambios del sitio) | Mínimo (la IA se adapta) |
| Gestiona paginación | Configuración manual | Automático |
| Extracción de subpáginas | Lógica compleja | 1 clic |
| Formatos de exportación | A menudo limitados | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Funciona en páginas con inicio de sesión | A veces (con configuración) | Sí (basado en navegador) |
| Etiquetado/categorización de datos | Posprocesado manual | Integrado, impulsado por IA |
| Programación/monitorización | A veces (avanzado) | Sí (configuración sencilla) |
La diferencia es de otro planeta. Con Thunderbit, cualquiera extrae, ordena y usa datos web sin tener ni idea de técnica.
Hacia dónde va la extracción web fácil y el scraping sencillo
Mirando al futuro, el panorama pinta de maravilla. La IA cada vez es más espabilada y la demanda de herramientas sin código sube como la espuma. Según el State of AI 2025 de McKinsey, el 88 % de las organizaciones ya usa IA con regularidad en al menos una función, frente al 78 % del año anterior, y los sistemas agénticos —IA capaz de gestionar flujos web de varios pasos— están despegando.
¿Y qué supone esto para quien trabaja en negocio? Más potencia y menos líos. A medida que la IA mejore, veremos:
- Detección de campos aún más fina: la IA entenderá datos y relaciones más complejas.
- Mejor integración: conexiones directas con más herramientas y plataformas de empresa.
- Más fiabilidad: menos fallos y resultados más consistentes, incluso en sitios dinámicos o protegidos.
- Más al alcance de todos: extraer datos web será una destreza estándar, no cosa de perfiles técnicos.
Y sí, Thunderbit está justo en la primera línea de ese movimiento.
Conclusión y puntos clave
Consulta los planes y créditos de Thunderbit Get Started Free
La web es la mayor base de datos del mundo, pero hasta hace nada solo le sacaban jugo quienes programaban. Eso está cambiando a toda velocidad. Con la extracción web fácil y los métodos de scraping sencillos, cualquiera convierte sitios web en datos útiles en cuestión de minutos.
Esto es lo que he aprendido —y lo que espero que te lleves—:
- El scraping sin código ha venido para quedarse: herramientas como Thunderbit hacen que cualquiera recopile y use datos web, sin saber técnica.
- La IA es la clave: al automatizar la selección de campos, la paginación, las subpáginas y el etiquetado, los scrapers con IA ahorran tiempo y recortan errores.
- El impacto en el negocio es real: ventas, ecommerce e inmobiliario ya notan más productividad, datos más frescos y mejores decisiones.
- Y lo que viene es aún mejor: según evolucionen la IA y el no-code, extraer datos web será tan habitual como mandar un correo.
Si estás harto de copiar y pegar a mano, frustrado con scrapers que se rompen o simplemente con curiosidad por lo que se puede hacer, prueba Thunderbit. Puedes descargar la extensión de Chrome y empezar a extraer datos gratis, sin configuración, sin código y sin complicaciones.
Y si te quedas con ganas de más, pásate por el Blog de Thunderbit, donde encontrarás guías, consejos y ejemplos reales.
Preguntas frecuentes
1. ¿Qué es la «extracción web fácil» y a quién va dirigida?
La extracción web fácil son métodos de scraping sin código e impulsados por IA que permiten a cualquiera —y muy en especial a perfiles de negocio sin base técnica— sacar datos estructurados de sitios web rápido y sin complicarse. Encaja de maravilla con equipos de ventas, marketing, ecommerce y operaciones que necesitan datos útiles sin meterse en líos técnicos.
2. ¿En qué se diferencia Thunderbit de las herramientas de scraping de siempre?
Thunderbit usa IA para automatizar la selección de campos, la paginación y las subpáginas. A diferencia de los scrapers tradicionales, que piden código o plantillas complicadas, con Thunderbit describes lo que quieres en lenguaje natural y extraes los datos en dos clics.
3. ¿Thunderbit se apaña con sitios dinámicos o de varias páginas?
Sí. Thunderbit detecta y gestiona la paginación de forma automática, incluido el scroll infinito, y puede seguir enlaces a subpáginas para una extracción más a fondo, todo con una configuración mínima.
4. ¿Qué opciones de exportación admite Thunderbit?
Thunderbit te deja exportar directo a Excel, Google Sheets, Airtable, Notion, CSV o JSON. Además, lo puedes integrar con CRMs y otras herramientas de trabajo para que el proceso fluya.
5. ¿Es seguro y ético usar herramientas como Thunderbit?
Thunderbit anima a hacer un scraping responsable y ético. Respeta siempre las condiciones de servicio de cada sitio, evita sacar datos personales sin consentimiento y aplica limitación de velocidad para no tumbar el servicio. Para profundizar en buenas prácticas, échale un ojo a la guía de Thunderbit sobre web scraping.
¿Te animas a exprimir el potencial de los datos web? Prueba Thunderbit hoy y comprueba cómo la extracción web fácil puede darle la vuelta a tu forma de trabajar.
Prueba Thunderbit para la extracción web fácil
Prueba el AI Web Scraper de Thunderbit Get Started Free
Más información




