El software de extracción de datos en 2026 ya no es una categoría única con un solo tipo de comprador. Algunos equipos necesitan una herramienta pensada para el navegador que convierta sitios web en hojas de cálculo en minutos. Otros necesitan APIs de rastreo, infraestructura de proxies o una canalización gobernada que alimente un data warehouse. Meter todos esos casos en un mismo ranking, sin contexto, es la forma más rápida de que los compradores pierdan tiempo y compren de más.
Esta revisión anual actualizada está pensada para hacer una sola cosa bien: ayudarte a construir una lista corta con rapidez. Las 15 herramientas de abajo siguen cubriendo la mayoría de las rutas reales de compra del mercado, pero resuelven problemas muy distintos. Si necesitas extracción rápida de sitios web con mínima configuración, tu selección debe ser muy distinta a la de un equipo que compra ELT y gobernanza.
Nota de revisión: esta recopilación anual se revisó el 7 de mayo de 2026. Próximo responsable de revisión: el equipo editorial de Thunderbit.
Empieza por el tipo de herramienta correcto
Antes de comparar proveedores, decide qué trabajo intentas resolver de verdad:
- ¿Necesitas datos de un sitio web en una hoja rápidamente, sin encargarte de la infraestructura de scraping? Empieza con herramientas de navegador con IA o sin código, como Thunderbit, Octoparse, Data Miner o Browse AI.
- ¿Necesitas páginas renderizadas, entrega por API o infraestructura anti-bots para equipos de producto? Mira ScrapingBee, Diffbot, Bright Data o Captain Data.
- ¿Necesitas centralizar datos de apps SaaS, APIs y bases de datos en un data warehouse? Enfócate en Airbyte, Hevo, Fivetran, Talend, Matillion o Integrate.io.
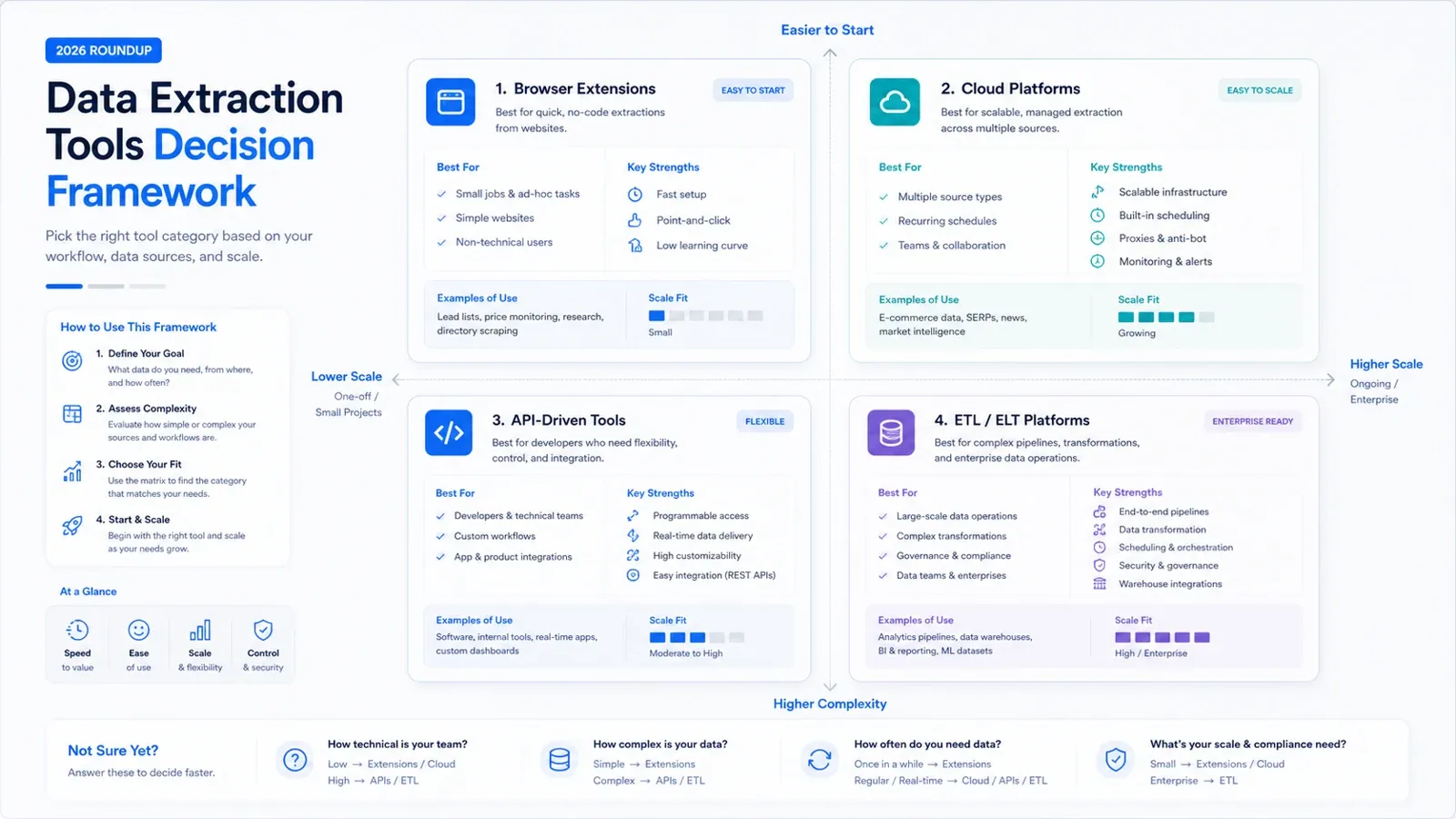
Tabla comparativa rápida: mejores herramientas de extracción de datos en 2026
| Herramienta | Ideal para | Lo que más destaca | Modelo de precios |
|---|---|---|---|
| Thunderbit | Usuarios de negocio que quieren datos web rápidamente | Sugerencia de campos con IA, subpáginas, paginación, exportación a hojas de cálculo | Nivel gratuito; suscripción de pago + créditos |
| Diffbot | Equipos que construyen productos de datos web estructurados | API de extracción, Crawlbot, Knowledge Graph | Prueba gratuita; créditos API de pago; plan empresarial a medida |
| Captain Data | Equipos de growth y operaciones que automatizan flujos outbound | Flujos multiusuario sin código en sitios web y herramientas SaaS | Según uso / orientado a ventas |
| ScrapingBee | Desarrolladores que extraen páginas con mucho JavaScript | Renderizado sin navegador visible, rotación de proxies, entrega por API sencilla | Prueba gratuita; planes API de pago |
| Octoparse | Analistas que quieren scraping visual con ejecuciones en la nube | Constructor de tareas punto y clic, plantillas, trabajos programados en la nube | Nivel gratuito; planes de pago |
| Data Miner | Usuarios de navegador que extraen listas y tablas bajo demanda | Extracción en el navegador basada en recetas con exportaciones rápidas | Nivel gratuito; planes de pago |
| Browse AI | Equipos que se preocupan por el monitoreo y las alertas de cambios | Robots entrenados, monitoreo programado, entrega a Sheets/Zapier | Nivel gratuito; planes de pago |
| Bardeen | Usuarios que combinan scraping con automatización del flujo en el navegador | Playbooks de IA, automatizaciones del navegador, integraciones con apps | Nivel gratuito; planes de pago |
| Bright Data | Recolección empresarial a gran escala | Red de proxies, desbloqueador, datasets, plataforma de scraping | Según uso / contrato |
| Airbyte | Equipos de ingeniería que construyen pipelines para el warehouse | Conectores abiertos, opción autogestionada, enfoque en el warehouse | Autogestionado gratis; niveles cloud + enterprise |
| Talend / Qlik Talend Cloud | Empresas que necesitan integración con alta gobernanza | Integración, calidad, gobernanza, controles empresariales | Suscripción con presupuesto a medida |
| Matillion | Equipos de datos en la nube que trabajan con warehouses modernos | ELT nativo en la nube y transformación dentro del warehouse | Basado en consumo |
| Integrate.io | Equipos de mercado medio que quieren pipelines gestionados | Integraciones gestionadas entre SaaS y bases de datos | Suscripción orientada a ventas |
| Hevo Data | Equipos que quieren sincronización gestionada casi en tiempo real | Conectores gestionados, enfoque en tiempo real, configuración ligera | Nivel gratuito; planes de pago |
| Fivetran | Equipos que priorizan la fiabilidad sobre la personalización | Conectores gestionados, manejo de esquemas, simplicidad operativa | Plan gratuito; precios MAR basados en uso |
Qué cambió en 2026
Ahora pesan más tres cambios que los típicos discursos genéricos sobre “automatización”:
- La extracción centrada en IA ya es mainstream. Cada vez más compradores esperan que una herramienta infiera campos, gestione variaciones básicas de las páginas y exporte tablas limpias sin configurar selectores.
- La infraestructura se ha separado de las herramientas de flujo. Algunos productos se compran mejor como APIs o capas de proxy, mientras que otros se compran mejor como flujos completos para usuarios de negocio.
- Los compradores anuales están examinando más de cerca el coste de mantenimiento. Una herramienta más barata en teoría puede ser peor si tu equipo tiene que vigilar selectores, sincronizaciones con el warehouse o rodeos anti-bot cada semana.
Por eso esta página mantiene la lista corta separada por modelo operativo, en vez de fingir que todas las herramientas compiten cara a cara.
Las mejores herramientas de extracción de datos con IA y sin código
1.
Thunderbit sigue siendo la mejor opción para equipos no técnicos que quieren datos de un sitio web en una tabla estructurada rápidamente. Su ventaja principal no es solo que no requiere código, sino que el producto está diseñado para reducir al mínimo la fricción de configuración. Abres una página, pides a la IA que sugiera campos, ajustas la tabla si hace falta y exportas.
- Ideal para: ventas ops, ecommerce ops, reclutamiento, investigación y cualquiera que pase del navegador a la hoja de cálculo.
- Lo que más destaca: sugerencia de campos con IA, extracción de subpáginas, gestión de paginación, exportación a Sheets / Excel / Airtable / Notion.
- Precios: nivel gratuito disponible; los planes de pago escalan mediante suscripción y uso de créditos.
2.
Octoparse sigue siendo uno de los productos de scraping sin código más consolidados para equipos que prefieren un constructor visual de tareas más explícito. Requiere más configuración que Thunderbit, pero a cambio ofrece un control más sólido para usuarios dispuestos a modelar el flujo de trabajo.
- Ideal para: analistas, investigadores y equipos de operaciones que extraen datasets recurrentes a escala moderada.
- Lo que más destaca: diseño visual de tareas, programación en la nube, plantillas de tareas, compatibilidad con inicios de sesión y páginas dinámicas.
- Precios: nivel gratuito más planes de pago para capacidad en la nube y funciones de equipo.
3.
Data Miner sigue siendo útil para extracción táctica desde el navegador. Es especialmente bueno cuando alguien quiere capturar rápidamente una lista, un directorio o una tabla y se siente cómodo usando o adaptando recetas.
- Ideal para: extracción nativa del navegador de tablas, directorios y elementos repetidos de página.
- Lo que más destaca: amplia biblioteca de recetas, flujo rápido en el navegador, exportación familiar a CSV / hojas de cálculo.
- Precios: nivel gratuito con mejoras de pago para usos más intensivos.
4.
Browse AI es más fuerte cuando el trabajo no es solo extraer, sino monitorear. Si un comprador quiere un robot que vuelva a visitar una página, vigile cambios y envíe resultados a otros sistemas, Browse AI sigue siendo relevante.
- Ideal para: monitoreo recurrente, alertas de cambios y extracción programada sencilla.
- Lo que más destaca: robots entrenados, ejecuciones recurrentes, flujos tipo alerta, entrega a Sheets y herramientas de automatización.
- Precios: nivel gratuito más planes de pago basados en capacidad de ejecución.
5.
Bardeen se sitúa en la frontera entre la extracción y la automatización del flujo de trabajo en el navegador. Es menos un scraper puro y más una capa de productividad del navegador que puede recopilar datos y enviarlos al resto del flujo.
- Ideal para: equipos que automatizan tareas repetitivas del navegador alrededor del scraping, el enriquecimiento y la entrega.
- Lo que más destaca: playbooks de IA, automatizaciones del navegador, integraciones profundas con apps.
- Precios: nivel gratuito más planes de pago.
Las mejores herramientas de extracción basadas en API, flujos e infraestructura
6.
Diffbot sigue siendo una de las opciones más claras cuando el comprador quiere extracción como producto API, en lugar de un flujo de navegador. Está pensado para entender la web estructurada a escala y sigue siendo más orientado a desarrolladores y productos de datos que las herramientas sin código anteriores.
- Ideal para: equipos que construyen productos de datos, sistemas de enriquecimiento o pipelines web estructurados a gran escala.
- Lo que más destaca: APIs de extracción, Crawlbot, Knowledge Graph, productos de datos orientados a entidades.
- Precios: prueba gratuita y niveles de créditos API de pago, con opciones empresariales.
7.

Captain Data sigue siendo relevante porque trata la extracción como un paso dentro de un flujo go-to-market más amplio. Es más útil cuando la tarea real no es “extraer una página”, sino “captar leads, enriquecerlos, derivarlos y actualizar los sistemas posteriores”.
- Ideal para: equipos de growth, outbound y revenue operations.
- Lo que más destaca: flujos multi paso, acciones de enriquecimiento, entrega a CRM, automatización de procesos outbound.
- Precios: basado en uso y orientado a ventas.
8.
ScrapingBee sigue siendo una opción práctica de API para desarrolladores que quieren compatibilidad con páginas renderizadas y abstracción de infraestructura, sin construir desde cero una pila completa de scraping.
- Ideal para: equipos de producto y desarrolladores que integran scraping en apps o herramientas internas.
- Lo que más destaca: renderizado de JavaScript, gestión de proxies, modelo de petición sencillo, API pensada para desarrolladores.
- Precios: planes API de pago con acceso de prueba.
9.
Bright Data sigue siendo la opción a escala empresarial cuando el reto no es un flujo aislado, sino el volumen de recolección, la geografía, la infraestructura de desbloqueo y los requisitos operativos con mucha carga de cumplimiento.
- Ideal para: recolección web a escala empresarial, cargas de trabajo intensivas en proxies y programas avanzados de adquisición.
- Lo que más destaca: red de proxies, herramientas de desbloqueo, productos de datos e infraestructura de recolección a escala empresarial.
- Precios: basado en uso y con contrato.
Las mejores plataformas ELT y de canalización de datos con capacidades de extracción
10.
Airbyte es la candidata adecuada cuando el trabajo es más amplio que la extracción web y el equipo quiere conectores, movimiento hacia el warehouse y control sobre la arquitectura de la canalización. No sustituye a un web scraper, pero sí es una de las mejores respuestas para centralizar datos de SaaS, APIs y bases de datos.
- Ideal para: equipos liderados por ingeniería que quieren conectores abiertos y control orientado al warehouse.
- Lo que más destaca: ecosistema abierto, opción autogestionada, oferta cloud, flexibilidad de conectores.
- Precios: ruta autogestionada gratuita más niveles cloud y enterprise.
11.

Talend sigue siendo una opción de integración empresarial para organizaciones que valoran más el movimiento gobernado, la calidad, el linaje y el control que una configuración ligera.
- Ideal para: empresas con requisitos de gobernanza, calidad e integración entre sistemas.
- Lo que más destaca: gobernanza empresarial, herramientas de calidad, amplitud de integraciones, dirección cloud gestionada bajo Qlik.
- Precios: suscripción con presupuesto a medida.
12.
Matillion sigue encajando con equipos de datos en la nube que quieren un ELT muy alineado con warehouses modernos y patrones de transformación dentro del warehouse.
- Ideal para: equipos de Snowflake, Databricks, BigQuery y warehouses modernos.
- Lo que más destaca: ELT nativo en la nube, transformación centrada en el warehouse, flujos de equipo para analytics engineering.
- Precios: basado en consumo.
13.
Integrate.io sigue siendo relevante para equipos que quieren una capa de integración gestionada sin tener que construir y mantener por su cuenta una pila más amplia y pesada de ingeniería.
- Ideal para: equipos de mercado medio que prefieren integraciones gestionadas entre apps SaaS y bases de datos.
- Lo que más destaca: postura de implementación gestionada, conectividad entre sistemas de negocio, modelo operativo con poca fricción.
- Precios: suscripción orientada a ventas.
14.
Hevo Data sigue atrayendo a equipos que quieren una canalización gestionada y fácil de configurar, con sincronización casi en tiempo real y una carga operativa relativamente baja.
- Ideal para: equipos de analítica que quieren mover datos rápidamente desde sistemas operativos a un warehouse.
- Lo que más destaca: conectores gestionados, sincronización casi en tiempo real, configuración accesible.
- Precios: nivel gratuito y planes de pago.
15.
Fivetran sigue siendo una de las selecciones más seguras cuando el comprador valora más la fiabilidad, el mantenimiento de conectores y la simplicidad operativa que la eficiencia de costes o la libertad de personalización.
- Ideal para: equipos de datos que quieren un estándar de conectores gestionados y están dispuestos a pagar por ello.
- Lo que más destaca: conectores gestionados, manejo de esquemas, alta madurez operativa, enfoque de bajo mantenimiento.
- Precios: plan gratuito más precios MAR basados en uso.
Cómo elegir sin comprar de más
La forma más rápida de acertar es evitar resolver el problema equivocado.

- Si sobre todo necesitas datos de un sitio web en una hoja de cálculo, no empieces por una plataforma ELT.
- Si necesitas una canalización gobernada para el warehouse, no fuerces a un scraper de navegador a convertirse en tu plataforma de datos.
- Si lo más difícil del flujo es el renderizado de JavaScript, los bloqueos o la entrega por API, compara primero las herramientas de infraestructura.
- Si lo más difícil es la adopción por parte del equipo y la rapidez de configuración, compara primero herramientas de IA y sin código.
Una regla útil de compra en 2026 es esta: compra con el menor nivel de complejidad que permita tu flujo real. El coste de mantenimiento se acumula más rápido que el ahorro en el precio de lista.
Selección final por tipo de equipo
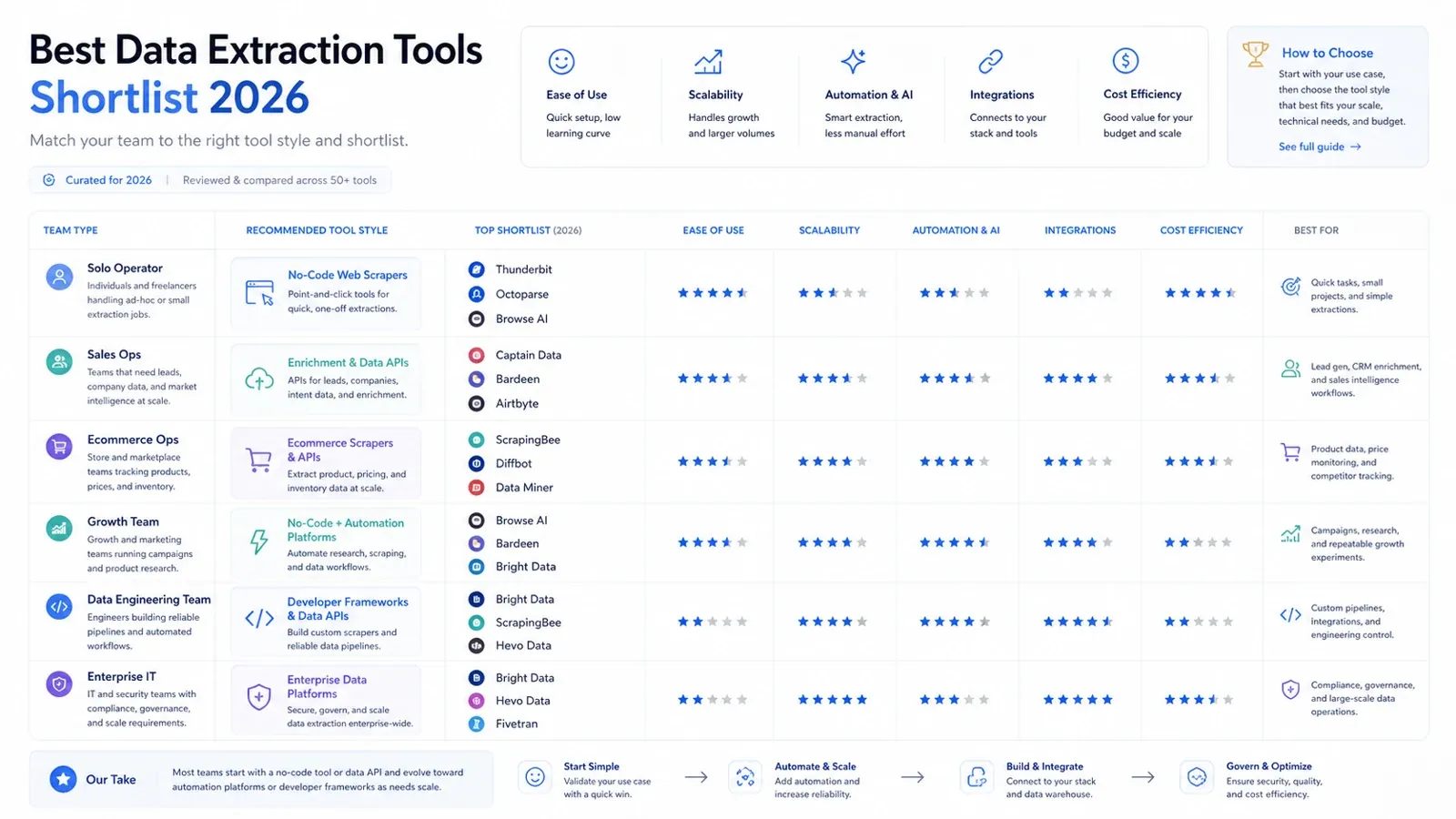
Aquí está la versión práctica de la lista corta:
- Operador individual o usuario de negocio: Thunderbit, Data Miner, Browse AI.
- Equipo de operaciones de ventas o de flujo de growth: Thunderbit, Captain Data, Bardeen.
- Equipo de operaciones ecommerce: Thunderbit, Octoparse, Bright Data.
- Equipo de ingeniería de datos: Airbyte, Fivetran, Matillion, Hevo.
- Comprador corporativo de TI / integración gobernada: Talend, Fivetran, Integrate.io, Bright Data.
- Desarrollador que construye productos de datos: Diffbot, ScrapingBee, Bright Data.
Si tuviera que reducir todo este mercado a la lista de inicio más corta y útil para la mayoría de los compradores en 2026, sería:
- Thunderbit para extracción rápida de sitios web asistida por IA para equipos no técnicos.
- ScrapingBee para desarrolladores que necesitan infraestructura API con páginas renderizadas.
- Bright Data para recolección a escala empresarial e infraestructura de desbloqueo.
- Airbyte para pipelines de warehouse liderados por ingeniería con flexibilidad.
- Fivetran para fiabilidad de conectores gestionados.
Preguntas frecuentes
P1: ¿Las herramientas de extracción de datos y las herramientas ETL son lo mismo?
No. Una herramienta de extracción de datos puede centrarse en sitios web, PDFs o captura estructurada a nivel de página, mientras que una plataforma ETL o ELT se centra en mover y transformar datos entre sistemas hasta llevarlos a un warehouse. Algunos compradores necesitan ambas, pero no deberían evaluarlas como si resolvieran el mismo problema inicial.
P2: ¿Cuál es la mejor opción para un equipo no técnico en 2026?
Para una extracción rápida de sitios web con mínima configuración, las herramientas con IA y sin código siguen siendo el mejor punto de partida. Thunderbit, Octoparse, Browse AI y Data Miner son las primeras opciones más relevantes, según cuánto control frente a velocidad necesite tu equipo.
P3: ¿Qué herramientas son mejores para casos de uso de desarrolladores o empresas?
Para desarrolladores, ScrapingBee y Diffbot son buenos puntos de partida, según si quieres infraestructura de renderizado o APIs de datos web estructurados. Para recolección a escala empresarial o infraestructura con altas exigencias de cumplimiento, Bright Data sigue siendo una candidata clave. Para pipelines internos gobernados, Airbyte, Fivetran, Talend, Matillion, Hevo e Integrate.io encajan mejor.