Hoy en día, todo el mundo habla de tomar decisiones basadas en datos, pero casi nadie menciona lo pesado y lento que puede ser recolectar esa información. Si alguna vez te tocó recopilar datos a mano, sabes lo cansado que es. He visto a muchas empresas quedarse atascadas en sus estrategias por no tener una recolección de datos ágil. Si te sentís identificado, acá vas a encontrar soluciones innovadoras.
💡 En este artículo te metés de lleno en el mundo del data scraping y cómo la tecnología está revolucionando este proceso. Vamos a repasar las limitaciones de los métodos clásicos, los beneficios del scraping con IA y te voy a dar consejos prácticos para que lo apliques en tu día a día.
¿Qué es el Data Scraping?
El data scraping, o , es básicamente extraer información estructurada de páginas web usando herramientas especializadas (normalmente en formato de tablas). Es una manera súper eficiente de juntar grandes volúmenes de datos en poco tiempo. Por ejemplo, podés sacar datos públicos de para generar leads, extraer SKUs de e-commerce de para reventa o análisis de mercado, o recopilar reseñas de para conocer la opinión de los clientes.
La evolución tecnológica del Data Scraping
Antes, recolectar datos era cosa de expertos en tecnología (o implicaba copiar y pegar a mano). Pero en 2025, la inteligencia artificial cambió las reglas del juego. El data scraping ya no es solo para programadores ni se limita a automatizaciones básicas.
¿Por qué los métodos tradicionales ya no alcanzan?
Las webs modernas traen nuevos desafíos: contenido dinámico (con frameworks como React o Vue), datos multimodales (texto, video, imágenes) y estructuras nada estandarizadas (varias plantillas en una sola página). Estudios recientes marcan tres grandes problemas de los :
-
Costos de mantenimiento altos Los raspadores web clásicos requieren ajustes manuales todo el tiempo (unas 3-5 horas al mes por sitio). Cuando una web cambia su diseño o framework, el 60% de los selectores XPath dejan de funcionar. Las herramientas con IA, gracias a sus modelos de lenguaje y capacidades de programación, se adaptan solas al 90% de los cambios estructurales, bajando los costos de mantenimiento entre un 60% y 80%. En sitios modernos hechos con React/Vue, la IA mantiene el scraping estable gracias a su comprensión semántica, incluso si cambian los nombres de las clases.
-
Limitaciones en el tipo de datos Los métodos clásicos solo extraen datos estructurados, perdiendo info valiosa como:
- Datos dentro de imágenes
- Texto en artículos
- Información no estructurada sin etiquetas HTML
-
Problemas de calidad de datos El scraping tradicional falla con contenido dinámico, lo que genera datos incompletos o erróneos:
- En datos paginados (como listados de productos), solo capturan entre el 30% y 50% de la primera página.
- En páginas con scroll infinito (como redes sociales), se pierde más del 60% de la información relevante.
- Alta tasa de errores al asociar datos no estructurados (listas desalineadas).
Acá es donde herramientas con IA como Thunderbit hacen la diferencia. Te cuento sus ventajas.
El boom del Data Scraping con IA
En 2025, la IA —sobre todo los grandes modelos de lenguaje (LLM)— demostró capacidades increíbles. Estos modelos entienden y generan lenguaje natural, resuelven análisis complejos y ofrecen soluciones mucho más eficientes. Muchas herramientas de scraping ya integran LLM para superar las limitaciones de los métodos clásicos. Después de probar 13 en los últimos meses, mi recomendación es .
¿Por qué Thunderbit es diferente?
-
Interacción revolucionaria: Podés dar instrucciones en lenguaje natural y el sistema arma automáticamente el plan de scraping, bajando el tiempo de configuración en un 87% frente a las herramientas tradicionales.
-
Ventajas del scraping local: Como extensión de navegador, Thunderbit te da:
- Extracción de datos al instante
- Soporte para páginas dinámicas y con scroll infinito
- Acceso a páginas que requieren login
-
Procesamiento multimodal avanzado: Thunderbit puede manejar distintos tipos de datos, como:
- Extraer texto de artículos
- Obtener tablas financieras de PDFs
- Reconocer datos en imágenes y convertirlos en tablas
- Extraer y resumir subtítulos de videos
Con Thunderbit, podés encarar cualquier escenario de recolección de datos sin drama. Mirá cómo se usa.
Cómo hacer Data Scraping con IA
Seguí estos cuatro pasos para aprovechar el :
-
Instalá la extensión del navegador Andá al sitio de Thunderbit y bajate la extensión desde Chrome Web Store. Una vez instalada, fijala en la barra de herramientas de tu navegador.
-
Registrate y conseguí créditos gratis Registrate desde la extensión para obtener créditos de prueba. Así podés probar funciones clave como el scraping con IA, autocompletado de formularios y resúmenes inteligentes. Te recomiendo probar primero en el playground gratuito antes de gastar tus créditos para ver qué tan bien funciona.
-
Arrancá el scraping inteligente Lanza una plantilla desde la barra lateral de Thunderbit. Describí en lenguaje natural el tipo de datos que querés, el formato de extracción o cualquier detalle extra. Después, hacé clic en el botón de scraping para empezar.
Funciones avanzadas de scraping (Pro Tier)
Si te suscribís al (o probás la demo gratuita), desbloqueás estas funciones:

-
Procesamiento multimodal Resuelve escenarios complejos como (informes financieros/manuales), extracción de datos de imágenes (etiquetas de precios/fichas técnicas) y scraping de subtítulos de video. El sistema estandariza automáticamente los datos no estructurados.
-
Scraping profundo de subpáginas Accedé a todos los subenlaces de una página (como /reseñas de usuarios), reconoce datos relacionados y los integra automáticamente en la tabla principal. Ideal para catálogos de e-commerce, listados inmobiliarios y más.
-
Biblioteca de plantillas prearmadas Usá al instante optimizadas para más de 30 plataformas como , y , adaptándose automáticamente a los cambios de estructura. Los nuevos usuarios ahorran en promedio un 83% del tiempo de configuración.
-
Scraping masivo Ejecutá varias tareas de scraping a la vez, importando listas de URLs para extracción por lotes.
-
Gestión inteligente de paginación Reconoce y extrae automáticamente contenido paginado (incluyendo botones "ver más" y navegación por páginas), soportando scroll infinito. Probado para extraer más de 200 páginas de listados de productos.
Guía práctica de Thunderbit
Escenario 1: Recolección de datos inmobiliarios
Si sos agente inmobiliario y necesitás recopilar información de propiedades en Zillow, o sos inversor buscando oportunidades, un raspador web confiable es tu mejor aliado. El raspador IA de Thunderbit te permite extraer fácilmente datos clave de Zillow, manteniéndote actualizado y competitivo. Mirá este video tutorial sobre cómo extraer datos de Zillow con Thunderbit.
Escenario 2: Prospección de talento y clientes
Si trabajás en recursos humanos buscando talento o en ventas buscando nuevos leads, un raspador web confiable puede ser tu mejor asistente. Thunderbit te permite extraer fácilmente información relevante de , agilizando la búsqueda de talento y la gestión de prospectos. Después de usarlo, vas a ver que las búsquedas manuales y el copiar-pegar quedan en el pasado. Acá tenés un tutorial sobre cómo extraer datos de LinkedIn con Thunderbit.
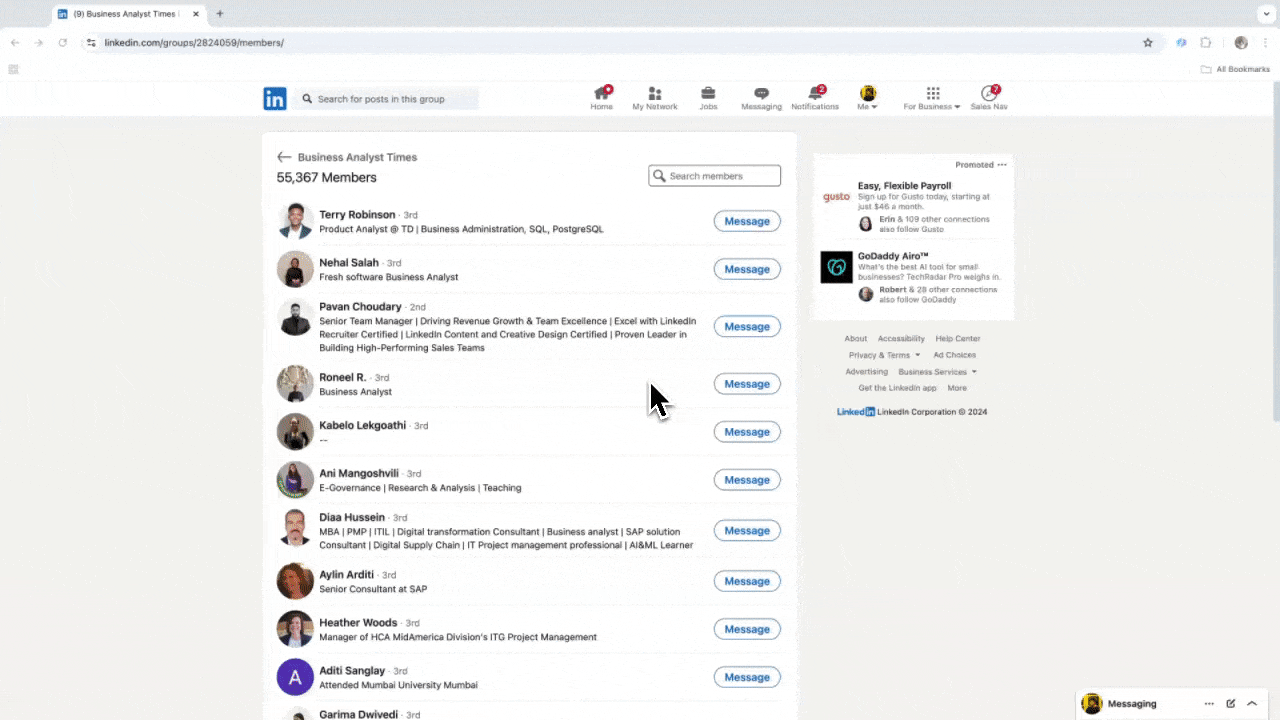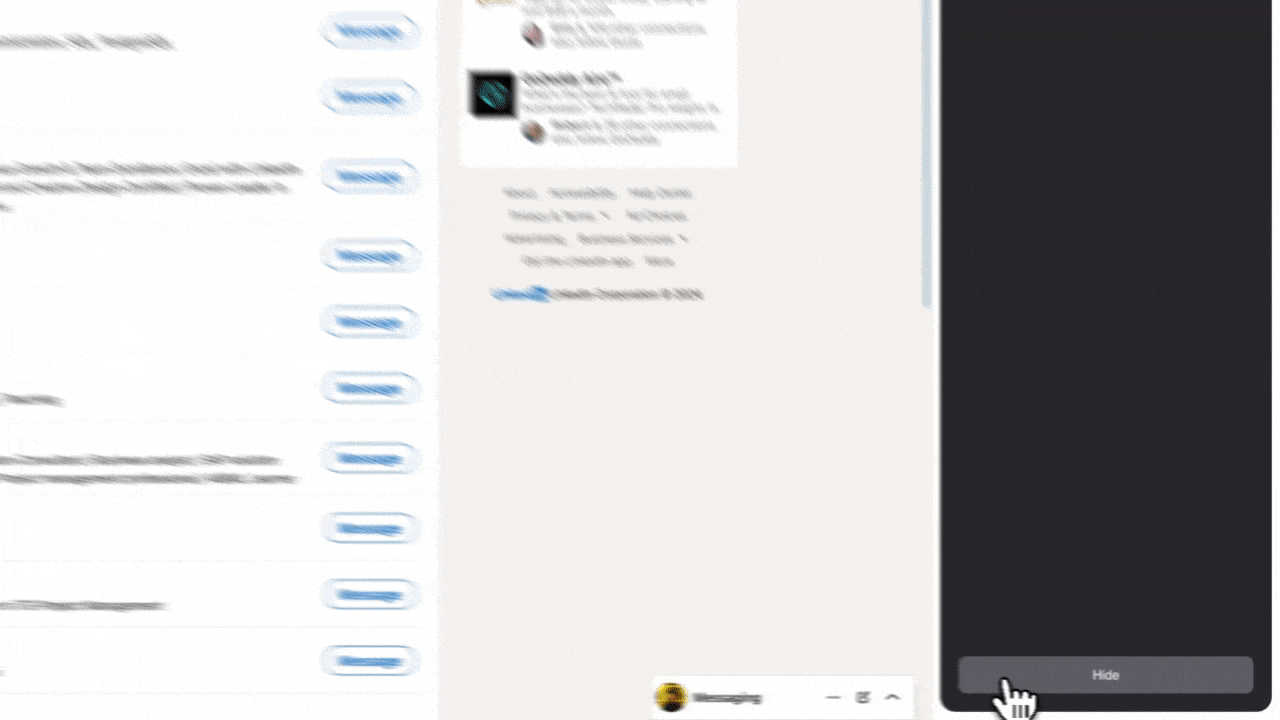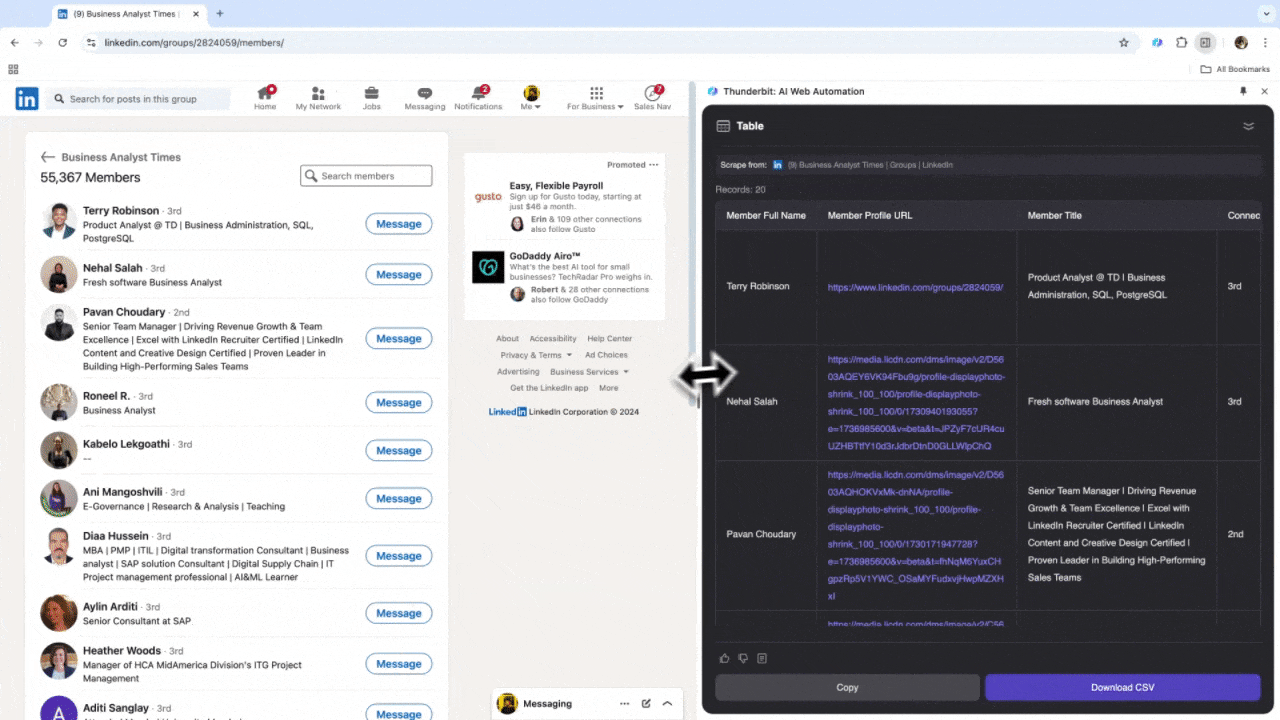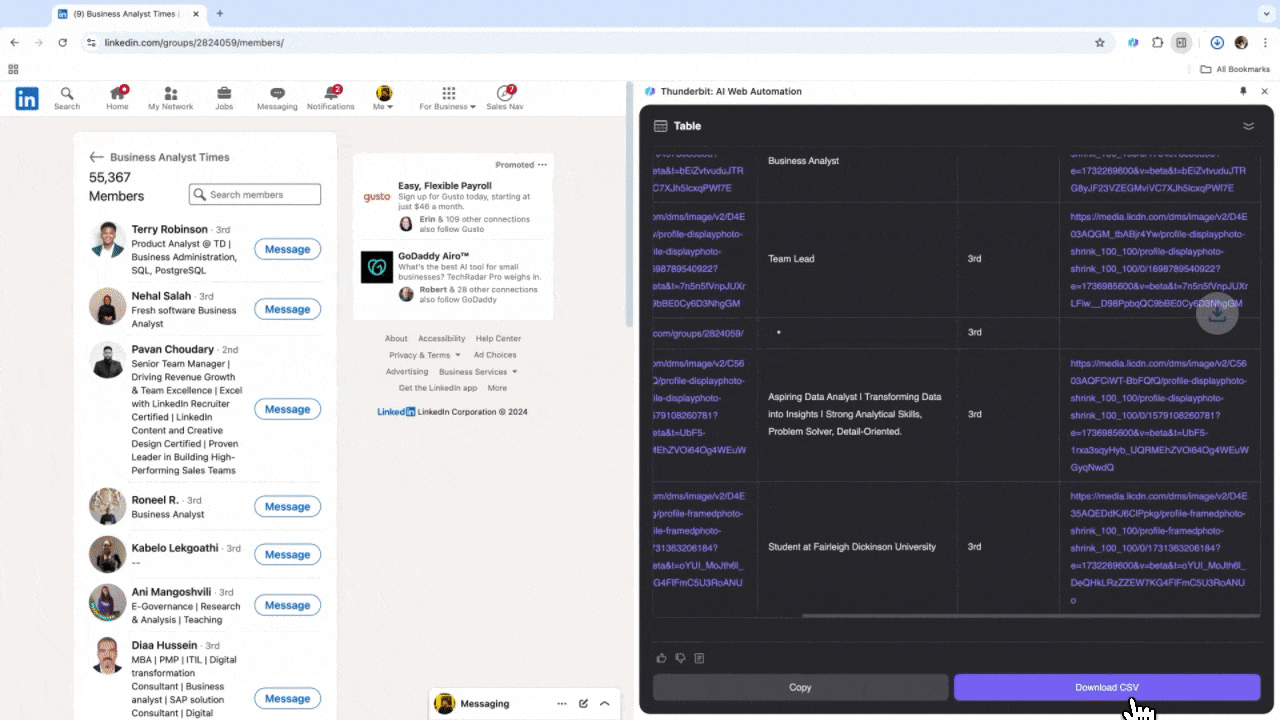
Escenario 3: Análisis de mercado y segmentación de clientes
Si tenés un negocio y necesitás datos geolocalizados para análisis de mercado, o trabajás en ventas buscando leads locales, un raspador web confiable puede marcar la diferencia. Thunderbit te permite extraer fácilmente información clave de , ayudándote a tomar mejores decisiones y optimizar tu alcance.
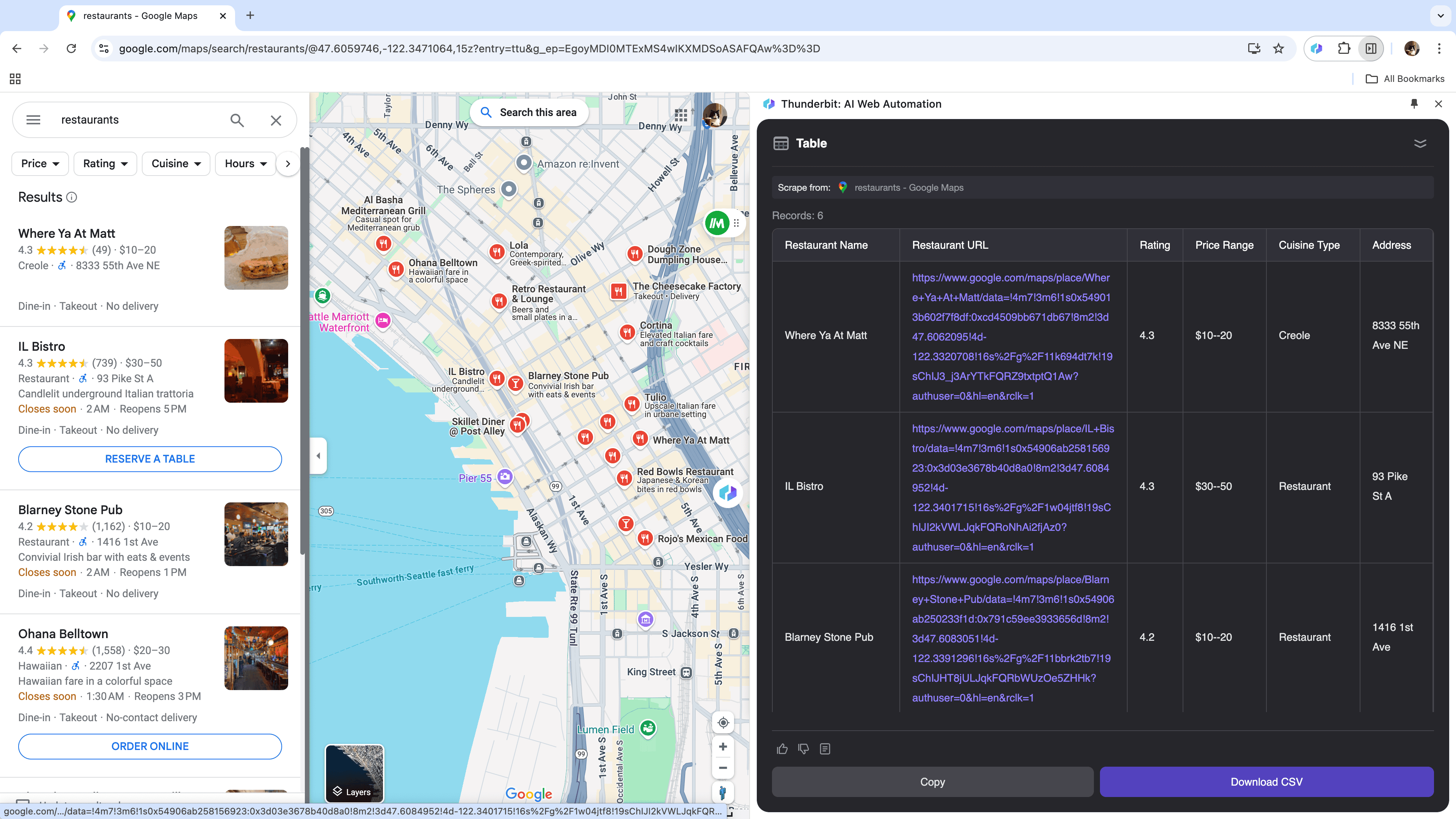
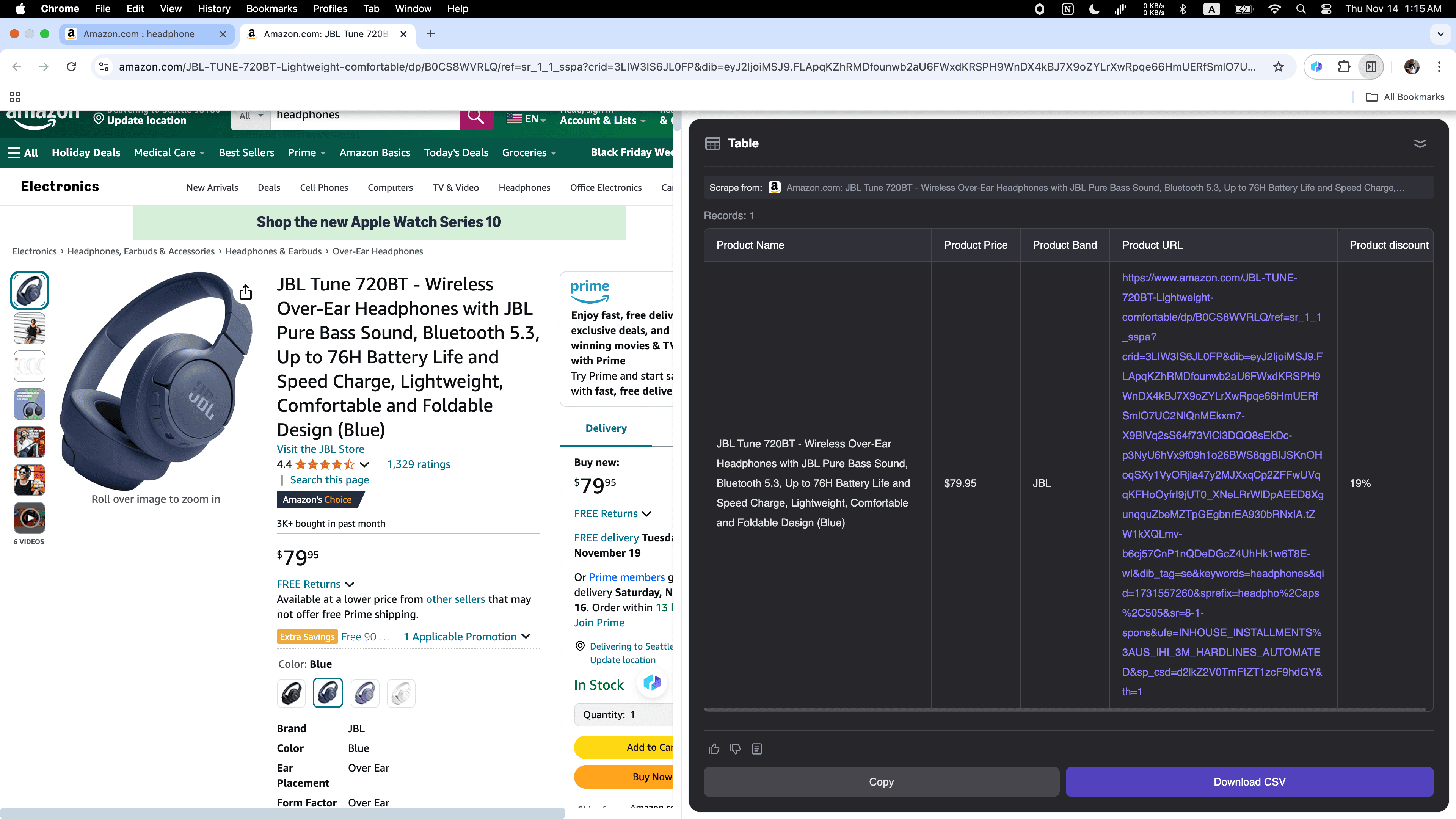
Escenario 4: Análisis de datos de e-commerce
Si vendés online y querés conocer a tu competencia o sos emprendedor siguiendo tendencias, Thunderbit es tu herramienta ideal. Puede recopilar fácilmente datos de productos de , incluyendo descripciones, precios y .
El raspador web IA de Thunderbit cambia la forma en que los usuarios de negocio recopilan datos, haciéndolo más rápido, simple y eficiente que nunca. Ya sea que busques propiedades, clientes potenciales o analizar tendencias de mercado, los raspadores IA pueden ahorrarte horas de trabajo y dolores de cabeza. Aprovechá el poder de la IA en el scraping web y llevá tu productividad al próximo nivel. ¿Listo para arrancar? Probá Thunderbit y da el primer paso hacia un scraping más inteligente.
Tips exclusivos para limpiar datos
Con los raspadores tradicionales, el verdadero lío empieza después del scraping: la limpieza de datos. La IA de Thunderbit puede limpiar los datos durante la extracción usando LLM, bajando el trabajo de limpieza en un 83% gracias a estas funciones innovadoras:
Tip 1: Alineación inteligente de campos
Cuando trabajás con datos de distintas fuentes (como LinkedIn y Zillow al mismo tiempo), la IA de Thunderbit arma relaciones semánticas automáticamente:
- Detecta coincidencias entre campos de diferentes fuentes (por ejemplo, "price" ↔ "precio" ↔ "Price")
- Fusiona campos parecidos (como "área" y "metros cuadrados")
- Estandariza datos entre plataformas (por ejemplo, "puesto actual" de LinkedIn y "estado de la propiedad" de Zillow como etiquetas)
Tip 2: Completado contextual
Gracias a la comprensión contextual de los LLM, Thunderbit logra un 99% de tasa de completado de datos:
- Completa direcciones: rellena ciudad/estado a partir del código postal (ejemplo: 10001 → Nueva York, NY)
- Inferencia de trayectoria profesional: predice experiencias laborales posibles según la formación en LinkedIn
Tip 3: Optimización de datos
- Traducción multilingüe (traducción en tiempo real a 12 idiomas, incluyendo inglés, chino y japonés)
- Resúmenes inteligentes (condensa una descripción de producto de 500 palabras en tres puntos clave)
- Unificación de unidades (convierte automáticamente pies cuadrados ↔ metros cuadrados, Fahrenheit ↔ Celsius)
- Estandarización de formatos (fechas en formato AAAA-MM-DD, moneda en USD)
Tip 4: Verificación de calidad
- Corrección inteligente de errores: arregla automáticamente errores de formato (ejemplo: teléfono +01 138-1234-5678 → +113812345678)
- Validación lógica: asegura que el "año de construcción" sea anterior a la "última reforma"
Tip 5: Etiquetado inteligente con IA
Genera etiquetas automáticas usando procesamiento de lenguaje natural:
- Etiquetas de sentimiento (clasifica reseñas como positivas/negativas/neutras)
- Etiquetas de valor de negocio (marca "clientes de alto potencial" o "propiedades a seguir")
- Etiquetas de sector (clasifica perfiles de LinkedIn como "tecnología|finanzas|salud")
Desventajas del Data Scraping
Aunque el data scraping suma un montón de valor, hay que tener en cuenta los desafíos. El tema legal es clave: normativas como GDPR y CCPA exigen cumplir sí o sí con la privacidad de los datos. Además, muchos sitios usan defensas avanzadas como Cloudflare para detectar y bloquear el scraping mediante restricciones de IP.
El futuro del Data Scraping en la era de la IA
La IA está transformando el scraping web en una solución intuitiva para empresas. Imaginá solo poner un dominio (como zillow.com) y tu pedido (por ejemplo, "extraer todos los listados de propiedades en Nueva York"), y ver cómo la IA identifica automáticamente cada dato relevante —desde detalles de propiedades hasta tendencias de precios— sin configuraciones manuales. Estos sistemas inteligentes van a integrar los datos extraídos directo en los flujos de trabajo, mandando prospectos de LinkedIn al CRM o métricas de e-commerce a paneles de análisis. El reconocimiento avanzado de patrones va a permitir un scraping predictivo que monitoree cambios de inventario o tendencias emergentes. Además, la IA va a gestionar el cumplimiento normativo en tiempo real, adaptando los parámetros de scraping según las regulaciones y manteniendo registros transparentes.
Este cambio de paradigma democratiza el acceso a la inteligencia de negocio y redefine cómo las organizaciones interactúan con los datos web. A medida que estas tecnologías maduren, quienes adopten soluciones de scraping con IA como Thunderbit van a sacar ventajas competitivas clave en la toma de decisiones basada en datos.
Preguntas frecuentes
-
¿Qué es Thunderbit? es una extensión inteligente para navegador basada en grandes modelos de lenguaje (LLM), pensada para la recolección de datos moderna. Ofrece e integra procesamiento multimodal, permitiendo extraer datos de páginas dinámicas, PDFs, imágenes y videos. Como solución local, puede acceder a páginas que requieren login (como LinkedIn) y adaptarse automáticamente a cambios en frameworks modernos.
-
¿Cómo funciona el raspador web IA de Thunderbit? El raspador IA de Thunderbit usa inteligencia artificial para extraer datos estructurados de sitios web. Podés hacer clic en "AI Suggest Columns" para que la IA sugiera cómo extraer datos del sitio actual y después en "Scrape" para recolectar la información. Permite procesar datos de cualquier web, PDF o imagen en solo dos clics.
-
¿Cuál es la diferencia entre scraping de listas y de subpáginas? El scraping de listas está optimizado para escenarios paginados (como listados de productos), reconociendo la lógica de paginación y extrayendo miles de registros. El scraping de subpáginas usa una estructura en árbol (por ejemplo, listados de propiedades en Zillow → fichas → planos), armando relaciones entre tablas principales y secundarias mediante asociación semántica.
-
¿Pueden usar Thunderbit personas sin conocimientos técnicos? Thunderbit está pensado para interactuar en lenguaje natural: solo describí lo que necesitás (por ejemplo, "nombre, email, teléfono") y el sistema arma automáticamente el plan de scraping. Según nuestros datos, el 85% de los usuarios completan su primera extracción en menos de 10 minutos, sin saber programar.
-
¿Qué tipos de datos puede manejar Thunderbit? Thunderbit reconoce de forma inteligente muchos tipos de datos:
- Datos estructurados: tablas, listas (por ejemplo, especificaciones de productos en Amazon)
- Datos no estructurados: textos de reseñas, PDFs (reconocimiento automático)
- Datos multimodales: etiquetas de precios en imágenes, extracción de subtítulos de video
- Datos dinámicos: contenido con scroll infinito, imágenes de carga diferida
- Datos relacionados: mapeo de relaciones entre páginas (por ejemplo, contactos de LinkedIn → información de empresa)
-
¿Cómo empiezo a usar Thunderbit? Descubrí más sobre nuestras o explorá nuestra para arrancar ya mismo.
Más info: