

Ο ιστός μεγαλώνει με ρυθμό που, ειλικρινά, είναι δύσκολο να το χωρέσει το μυαλό. Κάθε μέρα ανεβαίνουν δισεκατομμύρια νέες σελίδες, προϊόντα, κριτικές και σύνολα δεδομένων — τροφοδοτώντας τα πάντα, από την έρευνα αγοράς και την εκπαίδευση AI μέχρι την επόμενη αγορά σας στο Amazon. Ως άνθρωπος που έχει περάσει χρόνια στον χώρο του SaaS και του αυτοματισμού, έχω δει από πρώτο χέρι πόσο καθοριστικά μπορούν να είναι τα σωστά δεδομένα για μια επιχειρηματική απόφαση. Υπάρχει όμως μια παγίδα: η συλλογή, η ενημέρωση και η ερμηνεία όλου αυτού του web data γίνεται όλο και πιο δύσκολη, όχι πιο εύκολη. Τα παραδοσιακά web scrapers δυσκολεύονται να συμβαδίσουν, ενώ οι επιχειρήσεις ψάχνουν μια πιο έξυπνη και πιο γρήγορη μέθοδο για να μετατρέψουν το διαδίκτυο σε χρήσιμες πληροφορίες. Εδώ μπαίνει ο cloud crawler — ένα εργαλείο που αλλάζει αθόρυβα τον τρόπο με τον οποίο οι οργανισμοί εντοπίζουν και αξιοποιούν web data σε μεγάλη κλίμακα.
Λοιπόν, τι ακριβώς είναι ένας cloud crawler; Πώς διαφέρει από τα web scrapers που ίσως ήδη γνωρίζετε; Και γιατί ομάδες από τις πωλήσεις μέχρι τις λειτουργίες επενδύουν σε αυτή την τεχνολογία για να μείνουν μπροστά σε έναν κόσμο που κινείται με βάση τα δεδομένα; Ας το ψάξουμε, ας ξεκαθαρίσουμε τη φασαρία γύρω από τους όρους και ας δούμε πώς οι cloud crawlers (και ειδικά η λύση του Thunderbit) αλλάζουν τα δεδομένα για τις σύγχρονες επιχειρήσεις.
Τι είναι ένας Cloud Crawler; Το επόμενο βήμα στην ανακάλυψη δεδομένων
Εξαγάγετε δεδομένα από οποιονδήποτε ιστότοπο με AI Get Started Free
Ας το πούμε απλά: ένας cloud crawler δεν είναι απλώς ένα web scraper που «ζει» στο cloud. Είναι περισσότερο μια μηχανή ανακάλυψης δεδομένων — ένα έξυπνο, cloud-based σύστημα σχεδιασμένο να εντοπίζει, να εξάγει και να αναλύει αυτόματα τεράστια σύνολα δεδομένων από όλο το διαδίκτυο. Ενώ ένα παραδοσιακό web scraper τραβά πληροφορίες από λίγες σελίδες (συχνά μία κάθε φορά και συνήθως από μία μόνο συσκευή), ένας cloud crawler λειτουργεί σε εντελώς διαφορετικό επίπεδο. Τρέχει σε πανίσχυρα cloud data centers, «σαρώνει» χιλιάδες —ή και εκατομμύρια— σελίδες ταυτόχρονα και μπορεί να επεξεργαστεί τα πάντα, από κείμενο και εικόνες μέχρι PDF, ανεξάρτητα από το πόσο σύνθετος ή εκτεταμένος είναι ο στόχος.
Σκέψου το έτσι: αν ένα web scraper είναι σαν ένας μοναχικός βιβλιοθηκάριος που αντιγράφει αποσπάσματα από ένα βιβλίο, ένας cloud crawler είναι μια ομάδα υπερυπολογιστών που σαρώνει όλα τα βιβλία της βιβλιοθήκης ταυτόχρονα, επισημαίνοντας, οργανώνοντας και αναλύοντας το περιεχόμενο καθώς προχωρά. Το αποτέλεσμα; Οι επιχειρήσεις αποκτούν πλουσιότερα, πιο φρέσκα και πιο αξιοποιήσιμα δεδομένα — χωρίς τα εμπόδια του τοπικού hardware ή της χειροκίνητης δουλειάς (Sitebulb, Octoparse).
Cloud Crawler vs. Παραδοσιακό Web Scraper: Ποια είναι η πραγματική διαφορά;
Αν έχεις χρησιμοποιήσει ποτέ web scraper, ξέρεις τα βασικά: τον κατευθύνεις σε μια σελίδα, ορίζεις τι θέλεις και τον αφήνεις να μαζέψει τα δεδομένα. Όμως όσο ο ιστός μεγαλώνει και γίνεται πιο πολύπλοκος, η παλιά προσέγγιση αρχίζει να δείχνει τα όριά της. Δείτε πώς συγκρίνονται οι cloud crawlers με τα παραδοσιακά web scrapers:
| Χαρακτηριστικό/Πτυχή | Παραδοσιακό Web Scraper | Cloud Crawler |
|---|---|---|
| Εγκατάσταση | Τρέχει στη συσκευή ή στον server σας | Τρέχει στο cloud (απομακρυσμένα data centers) |
| Κλίμακα | Περιορίζεται από τη δύναμη του υπολογιστή σας | Μαζικά παράλληλη επεξεργασία—χιλιάδες σελίδες ταυτόχρονα |
| Ταχύτητα | Πιο αργό, ειδικά σε μεγάλα έργα | Υψηλής ταχύτητας επεξεργασία σε παρτίδες |
| Συντήρηση | Χρειάζεται συχνές ενημερώσεις, χαλάει όταν αλλάζει ο ιστότοπος | Cloud-based, με αυτόματες ενημερώσεις, πιο ανθεκτικό |
| Τύποι Δεδομένων | Συνήθως κείμενο, μερικές φορές εικόνες | Κείμενο, εικόνες, PDF, σύνθετα layouts |
| Πρόσβαση | Δεμένο με τη συσκευή/το δίκτυό σας | Προσβάσιμο από παντού, από οποιαδήποτε συσκευή |
| Προγραμματισμός | Χειροκίνητος ή βασικός αυτοματισμός | Προηγμένος προγραμματισμός, επαναλαμβανόμενες εργασίες |
| Ιδανικό για | Μικρά projects, απλούς ιστότοπους | Ανάγκες μεγάλης κλίμακας, συχνά ή σύνθετα δεδομένα |
Οι cloud crawlers είναι φτιαγμένοι για τον σύγχρονο ιστό — όπου τα δεδομένα είναι παντού και η ταχύτητα μαζί με την κλίμακα δεν είναι διαπραγματεύσιμες (GPTBots, Octoparse).
Πώς οι Cloud Crawlers απογειώνουν την αποτελεσματικότητα στη συλλογή δεδομένων
Εδώ αρχίζει το πραγματικά ενδιαφέρον κομμάτι. Οι cloud crawlers αξιοποιούν τη δύναμη του cloud computing για να επεξεργάζονται χιλιάδες web pages παράλληλα. Αυτό σημαίνει ότι μπορείς να συλλέξεις ολόκληρο κατάλογο ecommerce, να παρακολουθήσεις τις τιμές των ανταγωνιστών σε δεκάδες ιστότοπους ή να συγκεντρώσεις αγγελίες ακινήτων από όλα τα μεγάλα portals — όλα σε ένα κλάσμα του χρόνου που θα χρειαζόταν ένα παραδοσιακό scraper.
Γιατί έχει σημασία αυτό; Επειδή σε κλάδους όπως το ecommerce, τα οικονομικά και τα ακίνητα, η φρεσκάδα των δεδομένων είναι το παν. Οι τιμές, τα αποθέματα και οι τάσεις της αγοράς μπορούν να αλλάξουν από λεπτό σε λεπτό. Το να περιμένεις ώρες (ή και μέρες) για να τελειώσει ένας τοπικός scraper τη δουλειά του απλώς δεν είναι επιλογή. Οι cloud crawlers δεν περιορίζονται από τη RAM του laptop σου ή το Wi‑Fi του γραφείου σου — κλιμακώνονται όσο χρειάζεται, ώστε να μπορείς να διαχειριστείς τεράστια workloads χωρίς να ιδρώσεις (Zyte, Octoparse).
Οι κλάδοι που ωφελούνται περισσότερο από αυτή την αποδοτικότητα περιλαμβάνουν:
- Ecommerce: Παρακολούθηση τιμών, συγκέντρωση καταλόγων προϊόντων, ανάλυση κριτικών
- Real Estate: Συγκέντρωση αγγελιών, παρακολούθηση τάσεων αγοράς, σύγκριση ακινήτων
- Finance: Ανάλυση ειδήσεων και sentiment, παρακολούθηση μετοχών/crypto, έλεγχος ρυθμιστικών εξελίξεων
- Sales & Marketing: Δημιουργία leads, έρευνα ανταγωνισμού, εντοπισμός τάσεων
Και, ειλικρινά, αυτά είναι μόνο η αρχή. Αν χρειάζεστε web data σε μεγάλη κλίμακα, ένας cloud crawler είναι ο νέος καλύτερός σας σύμμαχος.
Η λύση Cloud Crawler του Thunderbit: Γρήγορη, ευέλικτη και ισχυρή
Ας φορέσω για λίγο το καπέλο του Thunderbit (αν και, για να είμαι ειλικρινής, δεν το βγάζω ποτέ πραγματικά). Το Thunderbit με το cloud scraping mode είναι η δική μας απάντηση στη σύγχρονη πρόκληση των δεδομένων — ένας cloud crawler φτιαγμένος για επιχειρησιακούς χρήστες που θέλουν αποτελέσματα, όχι πονοκεφάλους.
Να τι κάνει τον cloud crawler του Thunderbit να ξεχωρίζει:
- Γρήγορο Scraping σε Παρτίδες: Συλλέξτε έως και 50 σελίδες τη φορά, με cloud servers σε ΗΠΑ, ΕΕ και Ασία για παγκόσμια κάλυψη. Τέλος η αναμονή μέχρι να «σέρνεται» το laptop σας μέσα από μια μεγάλη λίστα.
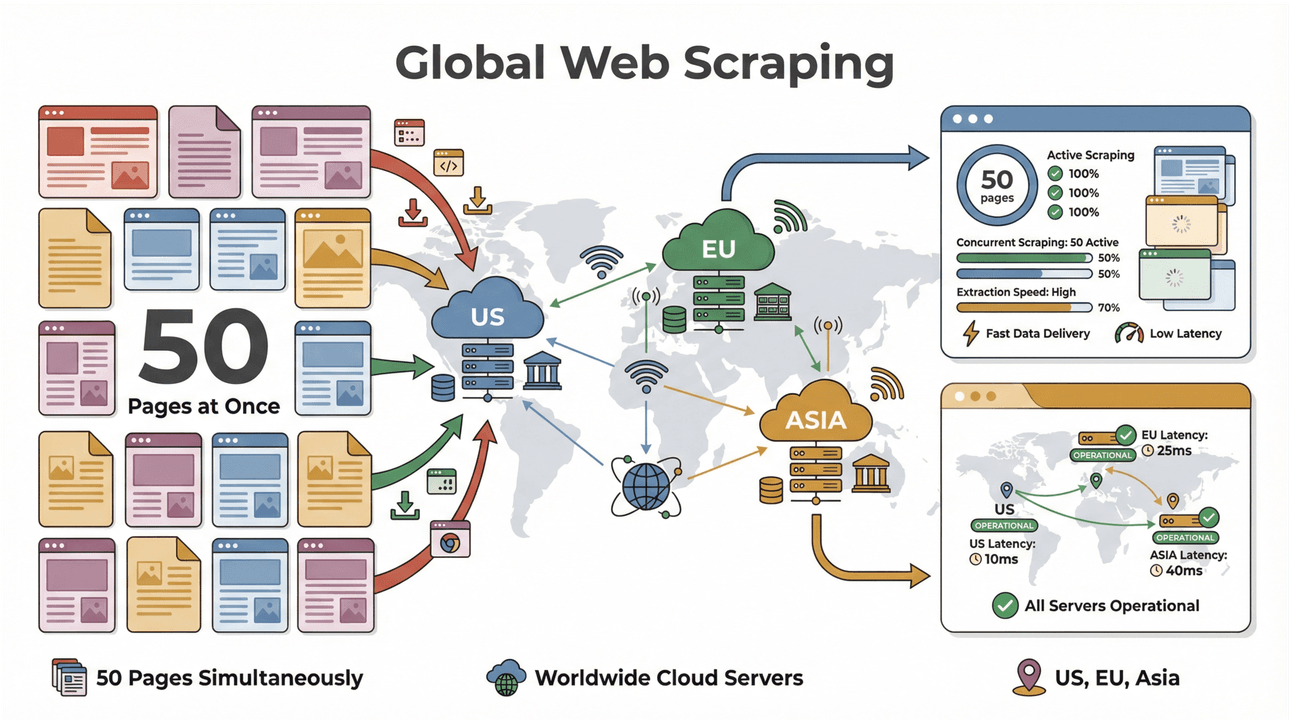
- Υποστήριξη Πολύπλοκων Σελίδων: Το AI του Thunderbit μπορεί να χειριστεί τα πάντα — από δυναμικά ecommerce sites μέχρι δύσκολα PDF και ακόμη και εξαγωγή εικόνων. Αν βρίσκεται στο web, το Thunderbit μάλλον μπορεί να το συλλέξει (Thunderbit).
- Crawling Υποσελίδων: Χρειάζεστε να εμπλουτίσετε τα δεδομένα σας με λεπτομέρειες από υποσελίδες (όπως προδιαγραφές προϊόντων ή βιογραφικά συγγραφέων); Το AI του Thunderbit μπορεί να επισκεφθεί κάθε υποσελίδα και να συνδυάσει τα αποτελέσματα στο κύριο dataset σας (Thunderbit).
- Έξυπνη Δομή Δεδομένων: Χρησιμοποιήστε το “AI Suggest Fields” για να αφήσετε το Thunderbit να διαβάσει τον ιστότοπο και να προτείνει τις καλύτερες στήλες — χωρίς κώδικα ή στήσιμο προτύπων.
- Εξαγωγή Παντού: Στείλτε τα δεδομένα σας απευθείας σε Excel, Google Sheets, Airtable ή Notion. Ή κατεβάστε τα ως CSV/JSON — ό,τι ταιριάζει στη ροή εργασίας σας (Thunderbit).
- Χωρίς Απαιτήσεις Συντήρησης: Το AI του Thunderbit προσαρμόζεται στις αλλαγές των ιστότοπων, ώστε να μην διορθώνετε συνεχώς σπασμένα scrapers (Thunderbit).
Και ναι, μπορείτε να δοκιμάσετε όλα αυτά με το free tier — οπότε δεν χρειάζεται να με πιστέψετε στα τυφλά.
Δοκιμάστε δωρεάν το Thunderbit Cloud Scraper
Εγκατάσταση Cloud Crawler: Cloud vs. Local — ποιο είναι το σωστό για εσάς;
Ένα από τα μεγαλύτερα πλεονεκτήματα των cloud crawlers είναι η ευελιξία στην εγκατάσταση. Με έναν παραδοσιακό (τοπικό) crawler, είστε δεμένοι με μια συγκεκριμένη συσκευή, ένα συγκεκριμένο δίκτυο και συχνά με πολλή ταλαιπωρία στη ρύθμιση. Αν ο υπολογιστής σας μπει σε sleep mode ή πέσει το internet, η διαδικασία σταματά. Η κλιμάκωση σημαίνει αγορά επιπλέον hardware ή εκτέλεση πολλών scripts.
Οι cloud crawlers αλλάζουν το παιχνίδι:
- Δεν χρειάζεται ειδικό hardware: Όλη η βαριά δουλειά γίνεται στο cloud. Μπορείς να ξεκινήσεις τεράστια scraping jobs από Chromebook, Mac ή ακόμη και από το κινητό σου.
- Πρόσβαση από παντού: Ταξιδεύεις; Δουλεύεις απομακρυσμένα; Κανένα πρόβλημα — ο cloud crawler σου είναι πάντα διαθέσιμος.
- Εύκολη κλιμάκωση: Χρειάζεσαι να συλλέξεις 10.000 σελίδες αντί για 100; Απλώς αυξάνεις το μέγεθος της εργασίας σου — χωρίς παρέμβαση IT.
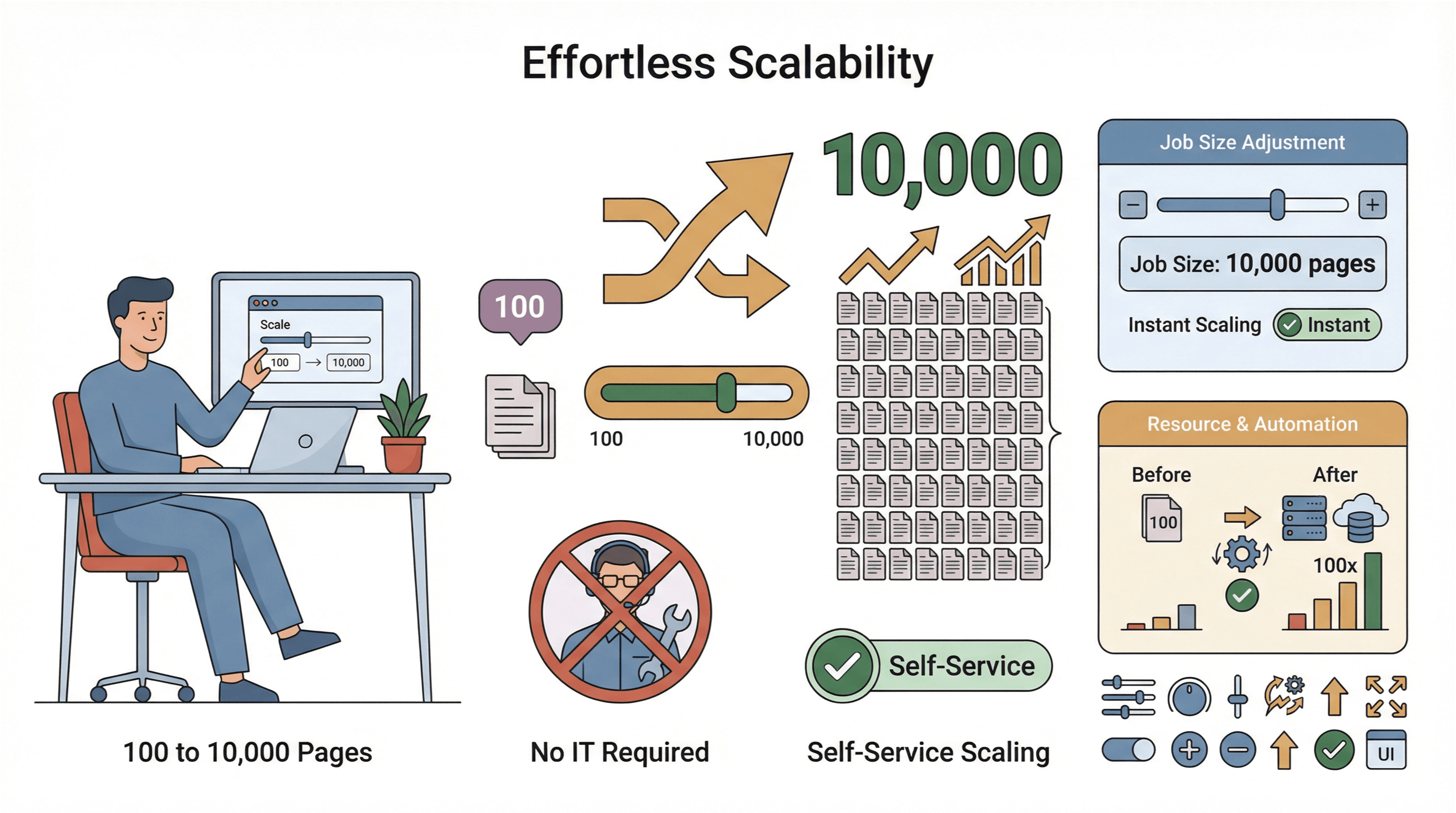
- Παγκόσμια συλλογή δεδομένων: Με cloud servers σε πολλαπλές περιοχές, μπορείς να έχεις πρόσβαση σε γεωγραφικά περιορισμένο περιεχόμενο και να διαχειρίζεσαι πιο εύκολα τη συμμόρφωση (PromptCloud).
Φυσικά, η ασφάλεια και η συμμόρφωση είναι πάντα κορυφαίες προτεραιότητες. Οι καλύτεροι cloud crawlers (συμπεριλαμβανομένου του Thunderbit) χρησιμοποιούν κρυπτογραφημένες συνδέσεις, σέβονται τους όρους των ιστότοπων και προσφέρουν δυνατότητες που σε βοηθούν να διαχειρίζεσαι υπεύθυνα ευαίσθητα δεδομένα.
Πραγματικός αντίκτυπος: Πώς οι Cloud Crawlers μεταμορφώνουν τις data-driven στρατηγικές
Ας το δούμε πρακτικά. Γιατί οι επιχειρήσεις στρέφονται στους cloud crawlers; Επειδή βλέπουν απτό και μετρήσιμο όφελος:
- Ανάλυση αγοράς σε πραγματικό χρόνο: Οι λιανέμποροι χρησιμοποιούν cloud crawlers για να παρακολουθούν σε πραγματικό χρόνο τις τιμές και τα αποθέματα των ανταγωνιστών, επιτρέποντας δυναμική τιμολόγηση και ταχύτερες αντιδράσεις στις αλλαγές της αγοράς (Zyte).
- Πρόβλεψη καταναλωτικών τάσεων: Τα brands συγκεντρώνουν κριτικές, αναρτήσεις στα social media και συζητήσεις σε forums για να εντοπίσουν αναδυόμενες τάσεις και να προσαρμόσουν τις καμπάνιες τους επιτόπου.
- Πωλήσεις & Lead Gen: Οι ομάδες πωλήσεων δημιουργούν ενημερωμένες λίστες leads από directories, event sites και ακόμη και PDFs — τροφοδοτώντας τα CRM με φρέσκες, ποιοτικές επαφές (Thunderbit).
- Λειτουργίες & Συμμόρφωση: Οι χρηματοοικονομικοί οργανισμοί χρησιμοποιούν cloud crawlers για να παρακολουθούν κανονιστικές ενημερώσεις, ειδήσεις και filings σε πολλαπλές δικαιοδοσίες — μειώνοντας τον κίνδυνο και μένοντας μπροστά από τις εξελίξεις.
Το κοινό νήμα; Οι cloud crawlers επιτρέπουν στις ομάδες να κινούνται πιο γρήγορα, να παίρνουν εξυπνότερες αποφάσεις και να ξεπερνούν τους ανταγωνιστές που ακόμα κινούνται αργά.
Βασικά χαρακτηριστικά που πρέπει να αναζητήσετε σε έναν Cloud Crawler
Δείτε τις τιμές και τα χαρακτηριστικά του Thunderbit Get Started Free
Δεν είναι όλοι οι cloud crawlers ίδιοι. Αν αξιολογείτε επιλογές, δείτε ποια χαρακτηριστικά έχουν τη μεγαλύτερη σημασία (και σε ποια το Thunderbit ξεχωρίζει):
- Κλιμάκωση: Μπορεί να χειριστεί χιλιάδες σελίδες ταυτόχρονα; Επιβραδύνεται όσο μεγαλώνει η εργασία;
- Ευκολία χρήσης: Είναι το περιβάλλον φιλικό για μη τεχνικούς χρήστες; Μπορείτε να στήσετε ένα scrape σε λίγα κλικ;
- Υποστήριξη πολλαπλών τύπων δεδομένων: Κείμενο, εικόνες, PDFs, υποσελίδες — τα διαχειρίζεται όλα;
- Ενσωμάτωση: Εξάγει στα εργαλεία που προτιμάτε (Excel, Sheets, Notion, Airtable);
- Προγραμματισμός: Μπορείτε να ορίσετε επαναλαμβανόμενες εργασίες για πάντα φρέσκα δεδομένα;
- Υποστήριξη AI: Προσφέρει έξυπνες προτάσεις πεδίων, enrichment δεδομένων και προσαρμογή στις αλλαγές του site;
- Ασφάλεια & συμμόρφωση: Προστατεύονται τα δεδομένα και τα διαπιστευτήριά σας; Σας βοηθά να παραμένετε σύμφωνοι με τους νόμους περί ιδιωτικότητας;
Το Thunderbit καλύπτει όλα τα παραπάνω, καθιστώντας το κορυφαία επιλογή για ομάδες που θέλουν δύναμη χωρίς ταλαιπωρία.
Πώς να ξεκινήσετε: Πώς να χρησιμοποιήσετε έναν Cloud Crawler για την επιχείρησή σας
Έτοιμοι να ξεκινήσετε; Δείτε πώς μπορεί να ξεκινήσει ένας τυπικός επιχειρησιακός χρήστης με έναν cloud crawler όπως το Thunderbit:
- Εγκαταστήστε το Thunderbit Chrome Extension: Γρήγορη εγκατάσταση, χωρίς ανάγκη IT.
- Επιλέξτε τον στόχο σας: Ανοίξτε τον ιστότοπο, τη λίστα ή το έγγραφο που θέλετε να συλλέξετε.
- Κάντε κλικ στο “AI Suggest Fields”: Αφήστε το AI του Thunderbit να σαρώσει τη σελίδα και να προτείνει τις καλύτερες στήλες για εξαγωγή.
- Προσαρμόστε όπως χρειάζεται: Προσθέστε, αφαιρέστε ή μετονομάστε πεδία ώστε να ταιριάζουν στις ανάγκες σας.
- Επιλέξτε Cloud Scraping Mode: Για μεγάλα jobs ή πολύπλοκους ιστότοπους, περάστε σε cloud mode για μέγιστη ταχύτητα.
- Ξεκινήστε το scrape: Το Thunderbit θα επεξεργαστεί έως και 50 σελίδες τη φορά στο cloud.
- Ελέγξτε και εξάγετε: Δείτε την προεπισκόπηση των αποτελεσμάτων σας και μετά εξάγετέ τα σε Excel, Google Sheets, Notion ή Airtable.
- Προγραμματίστε επαναλαμβανόμενες εργασίες: Για συνεχή ανάγκη, στήστε scheduled scrapes — τα δεδομένα σας θα ενημερώνονται αυτόματα (Thunderbit Docs).
Συμβουλή: Ξεκινήστε με ένα μικρό job για να εξοικειωθείτε και μετά αυξήστε την κλίμακα όσο νιώθετε άνετα. Και μην διστάσετε να χρησιμοποιήσετε την υποστήριξη ή την τεκμηρίωση του Thunderbit — είναι εκεί για να βοηθήσουν.
Ξεκινήστε το cloud crawling με το Thunderbit
Το μέλλον της συλλογής δεδομένων: Τι ακολουθεί για τους Cloud Crawlers;
Η επανάσταση των cloud crawlers μόλις ξεκινά. Να τι παρακολουθώ για τα επόμενα χρόνια:
- Εξυπνότερη εξαγωγή με AI: Οι cloud crawlers γίνονται καλύτεροι στην κατανόηση του συμφραζομένου, των σχέσεων και ακόμη και του sentiment — κάνοντας τα δεδομένα που συλλέγουν πιο πολύτιμα (GPTBots).
- Υποστήριξη για νέους τύπους δεδομένων: Περίμενε καλύτερη διαχείριση βίντεο, ήχου και διαδραστικού περιεχομένου — όχι μόνο στατικού κειμένου και εικόνων.
- Πιο βαθύς αυτοματισμός: Από τον αυτόματο προγραμματισμό μέχρι τις ειδοποιήσεις σε πραγματικό χρόνο, οι cloud crawlers θα γίνουν ακόμη πιο hands-off για τους επιχειρησιακούς χρήστες.
- Ενισχυμένη συμμόρφωση: Καθώς εξελίσσονται οι νόμοι περί ιδιωτικότητας, οι cloud crawlers θα ενσωματώνουν περισσότερα εργαλεία για να βοηθούν τις ομάδες να παραμένουν εντός κανονιστικού πλαισίου.
- Ενσωμάτωση με BI και AI εργαλεία: Άμεσες ροές από cloud crawlers προς analytics, dashboards και πλατφόρμες machine learning.
Με λίγα λόγια, οι cloud crawlers είναι έτοιμοι να γίνουν ο κορμός της ψηφιακής επιχειρηματικής στρατηγικής — τροφοδοτώντας τα πάντα, από λανσαρίσματα προϊόντων μέχρι forecasting με τη βοήθεια AI (Thunderbit Blog).
Συμπέρασμα: Γιατί οι Cloud Crawlers είναι απαραίτητοι για τις σύγχρονες επιχειρήσεις
Συνοψίζοντας: ο ιστός ξεχειλίζει από δεδομένα και οι παλιοί τρόποι συλλογής τους απλώς δεν μπορούν να ακολουθήσουν. Οι cloud crawlers είναι η επόμενη εξέλιξη — προσφέροντας ταχύτητα, κλίμακα και ευφυΐα που τα παραδοσιακά scrapers δεν μπορούν να ανταγωνιστούν. Εργαλεία όπως το Thunderbit κάνουν δυνατό για κάθε ομάδα, τεχνική ή μη, να αξιοποιήσει πλήρως τη δύναμη των web data — ενισχύοντας πιο έξυπνες αποφάσεις, ταχύτερες αντιδράσεις και πραγματικό ανταγωνιστικό πλεονέκτημα.
Αν είστε έτοιμοι να αφήσετε πίσω το χειροκίνητο scraping και τα αργά δεδομένα, τώρα είναι η στιγμή να δείτε τι μπορεί να κάνει ένας cloud crawler για την επιχείρησή σας. Δοκιμάστε το cloud scraping mode του Thunderbit και ανακαλύψτε πόσο εύκολη (και ισχυρή) μπορεί να είναι η σύγχρονη ανακάλυψη δεδομένων. Και αν θέλετε να πάτε πιο βαθιά, ρίξτε μια ματιά στο Thunderbit Blog για περισσότερους οδηγούς, tips και πραγματικά παραδείγματα.
Συχνές Ερωτήσεις
1. Τι είναι ένας cloud crawler με απλά λόγια;
Ένας cloud crawler είναι ένα cloud-based εργαλείο που ανακαλύπτει, εξάγει και αναλύει αυτόματα μεγάλες ποσότητες δεδομένων από τον ιστό. Σε αντίθεση με τα παραδοσιακά scrapers που τρέχουν στην τοπική σας συσκευή, οι cloud crawlers λειτουργούν σε πανίσχυρα data centers, επιτρέποντας τεράστια κλίμακα και ταχύτητα.
2. Πώς διαφέρει ένας cloud crawler από ένα συνηθισμένο web scraper;
Οι cloud crawlers τρέχουν στο cloud, χειρίζονται χιλιάδες σελίδες ταυτόχρονα, υποστηρίζουν σύνθετους τύπους δεδομένων (όπως εικόνες και PDFs) και δεν απαιτούν συντήρηση ή τοπικό hardware. Τα παραδοσιακά scrapers περιορίζονται από τη δύναμη της συσκευής σας και είναι καταλληλότερα για μικρότερες, απλούστερες εργασίες.
3. Ποια είναι τα βασικά οφέλη από τη χρήση ενός cloud crawler;
Οι cloud crawlers προσφέρουν γρήγορη, μεγάλης κλίμακας συλλογή δεδομένων, υποστήριξη για σύνθετους ιστότοπους, εύκολη πρόσβαση από παντού και προηγμένες λειτουργίες όπως προγραμματισμό και εξαγωγή με AI. Είναι ιδανικοί για επιχειρήσεις που χρειάζονται φρέσκα και αξιοποιήσιμα δεδομένα γρήγορα.
4. Πώς λειτουργεί ο cloud crawler του Thunderbit για επιχειρησιακούς χρήστες;
Ο cloud crawler του Thunderbit σού επιτρέπει να στήσεις ένα scrape με λίγα μόνο κλικ — χωρίς να χρειάζεται κώδικας. Μπορείς να εξαγάγεις δεδομένα από ιστότοπους, PDFs και εικόνες, να τα εμπλουτίσεις με AI και να τα εξάγεις απευθείας σε Excel, Google Sheets, Notion ή Airtable. Είναι σχεδιασμένος για μη τεχνικούς χρήστες που θέλουν αποτελέσματα, όχι πολυπλοκότητα.
5. Είναι το cloud crawling ασφαλές και σύμφωνο με τους νόμους περί ιδιωτικότητας;
Ναι, οι κορυφαίοι cloud crawlers όπως το Thunderbit χρησιμοποιούν κρυπτογραφημένες συνδέσεις και βέλτιστες πρακτικές ασφάλειας δεδομένων. Φρόντιζε πάντα να συλλέγεις μόνο δημόσια διαθέσιμα δεδομένα και να σέβεσαι τους όρους χρήσης των ιστότοπων και τους κανονισμούς ιδιωτικότητας.
Έτοιμοι να δείτε τι μπορεί να κάνει ένας cloud crawler; Κατεβάστε το Thunderbit και ξεκινήστε σήμερα να εξερευνάτε τον κόσμο της μεγάλης κλίμακας, cloud-powered συλλογής δεδομένων.
Δοκιμάστε σήμερα το Thunderbit Cloud Crawler Get Started Free
Μάθετε περισσότερα
- Τα 15 κορυφαία AI Web Crawlers που πρέπει να γνωρίζετε το 2025
- Live Web Crawling με AI: Ένας σύντομος οδηγός
- Οι 10 καλύτερες δωρεάν online επιλογές Website Crawler για το 2025
- Πώς να εξαγάγετε δεδομένα από μια web page χρησιμοποιώντας το Thunderbit
- Πώς να κατακτήσετε το Automated Data Scraping με το Thunderbit




