

Εγγραφείτε στο ScraperAPI, βλέπετε «100.000 credits» στο πλάνο Hobby και ξεκινάτε το scraping. Τρεις μέρες μετά, το dashboard δείχνει ότι το 80% από αυτά τα credits έχει κάνει φτερά — και έχετε μαζέψει περίπου 6.000 σελίδες. Τι έγινε; Αυτό που συνέβη είναι το σύστημα πολλαπλασιαστών credits, και είναι ίσως το πιο κρίσιμο κομμάτι του ScraperAPI που σχεδόν καμία αξιολόγηση δεν το εξηγεί σωστά. Έχω περάσει εβδομάδες ψάχνοντας την τεκμηρίωση του ScraperAPI, συγκρίνοντας πραγματικά δεδομένα τιμολόγησης από πέντε ανταγωνιστικούς παρόχους και διαβάζοντας κάθε thread στο Reddit και κάθε κριτική στο Capterra που κατάφερα να βρω. Αυτή η αξιολόγηση του ScraperAPI είναι αυτή που θα ήθελα να υπήρχε όταν η ομάδα μας άρχισε να εξετάζει scraping APIs. Θα σας δείξω τους πραγματικούς υπολογισμούς για τα credits, θα σας πω πού το ScraperAPI τα πάει καλά (και πού πέφτει έξω τελείως), θα μαζέψω όσα λένε πραγματικοί χρήστες στο G2, το Capterra και το Reddit και — ειλικρινά — θα σας βοηθήσω να καταλάβετε αν χρειάζεστε καν scraping API.
Τι Είναι το ScraperAPI και Για Ποιον Φτιάχτηκε;
Το ScraperAPI είναι ένα web scraping API που αναλαμβάνει όλη τη δύσκολη υποδομή πίσω από το μαζικό scraping: εναλλαγή proxies σε 40+ εκατομμύρια IPs σε 50+ χώρες, αυτόματη επίλυση CAPTCHA, απόδοση JavaScript και αυτόματες επαναλήψεις. Στέλνετε ένα URL με ένα απλό API call και σας επιστρέφει το HTML (ή parsed JSON, αν χρησιμοποιήσετε τα structured data endpoints). Η εταιρεία ιδρύθηκε το 2018 από τον Daniel Ni, έχει έδρα στο Las Vegas και πλέον εξυπηρετεί πάνω από 10.000 brands, όπως Deloitte, Sony και Alibaba — επεξεργαζόμενη 36 δισεκατομμύρια API requests τον μήνα.
Το βασικό κοινό είναι ομάδες developers και τεχνικές ομάδες operations που χτίζουν custom scraping pipelines. Αν δεν γράφετε κώδικα, το ScraperAPI δεν είναι φτιαγμένο για εσάς (θα το ξαναπιάσουμε αυτό σε λίγο).
Κύρια χαρακτηριστικά: εναλλαγή proxies, απόδοση JavaScript, γεω-στόχευση, structured data endpoints για δημοφιλή sites και αυτόματες επαναλήψεις σε αποτυχημένα requests.
Όμως υπάρχει κάτι που οι περισσότερες αξιολογήσεις το προσπερνούν: οι «μεγάλες» αριθμητικές αναφορές credits στη σελίδα τιμολόγησης του ScraperAPI είναι παραπλανητικές αν δεν καταλάβετε πώς δουλεύουν οι πολλαπλασιαστές. Από εκεί θα ξεκινήσουμε.
Πώς Λειτουργεί Πραγματικά το Σύστημα Credits του ScraperAPI (Το Κομμάτι που οι Περισσότερες Αξιολογήσεις Παραλείπουν)
Το ScraperAPI χρεώνει με βάση ένα σύστημα credits. Η βασική ιδέα είναι απλή: 1 API request = 1 credit. Με μια εξαίρεση: στην πράξη, σχεδόν ποτέ δεν ισχύει έτσι. Το πραγματικό κόστος σε credits εξαρτάται από δύο πράγματα: το domain που κάνετε scrape και τα feature flags που ενεργοποιείτε. Και αυτά προστίθενται με τρόπο καθόλου διαισθητικό.
Ο Πίνακας Πολλαπλασιαστών Credits που Κάθε Χρήστης Πρέπει να Δει Πριν Εγγραφεί

Πριν καν ενεργοποιήσετε κάποια παράμετρο, ο τύπος του website που κάνετε scrape καθορίζει το βασικό κόστος σε credits:
| Κατηγορία Domain | Βασικά Credits ανά Request | Παραδείγματα |
|---|---|---|
| Κανονικά websites | 1 | Blogs, ειδησεογραφικά sites, απλό HTML |
| E-commerce | 5 | Amazon, eBay, Walmart |
| SERP (μηχανές αναζήτησης) | 25 | Google, Bing |
| Social media | 30 |
Επιπλέον, τα feature flags προσθέτουν extra credits:
| Παράμετρος | Επιπλέον Credits | Σημειώσεις |
|---|---|---|
render=true (JS rendering) | +10 | Σε όλα τα πλάνα |
screenshot=true | +10 | Σε όλα τα πλάνα |
premium=true (premium proxy) | +10 | Σε όλα τα πλάνα |
ultra_premium=true | +30 | Μόνο στα paid πλάνα |
| Anti-bot bypass (Cloudflare, DataDome, PerimeterX) | +10 το καθένα | Εντοπίζεται αυτόματα — δεν το επιλέγετε εσείς |
premium=true + render=true μαζί | +25 | ΟΧΙ +20 |
ultra_premium=true + render=true μαζί | +75 | ΟΧΙ +40 |
Αυτή η τελευταία γραμμή είναι το ζουμί. Ο συνδυασμός χαρακτηριστικών κοστίζει ΠΕΡΙΣΣΟΤΕΡΟ από το άθροισμα των επιμέρους χρεώσεων. Premium proxy (+10) συν JavaScript rendering (+10) λογικά θα έπρεπε να κοστίζει +20 credits, αλλά το ScraperAPI χρεώνει +25. Ultra-premium (+30) συν JavaScript rendering (+10) θα έπρεπε να κοστίζει +40, όμως στην πράξη είναι +75 — σχεδόν διπλάσιο. Αυτό το μη γραμμικό stacking δεν τεκμηριώνεται ξεκάθαρα, και είναι ο βασικός λόγος που οι χρήστες λένε ότι τα credits εξαφανίζονται πολύ πιο γρήγορα απ’ όσο περίμεναν.
Παράμετροι που δεν κοστίζουν επιπλέον credits: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Τι Σας Δίνει Πραγματικά Κάθε Πλάνο: Από Free έως Enterprise
Αυτά είναι τα τρέχοντα πλάνα του ScraperAPI:
| Πλάνο | Μηνιαία Τιμή | Ετήσιο (ανά μήνα) | API Credits | Ταυτόχρονα Threads | Γεω-στόχευση |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Όχι |
| Hobby | $49 | $44 | 100.000 | 20 | Μόνο US & EU |
| Startup | $149 | $134 | 1.000.000 | 50 | Μόνο US & EU |
| Business | $299 | $269 | 3.000.000 | 100 | Σε επίπεδο χώρας (50+ χώρες) |
| Scaling | $475 | $427 | 5.000.000 | 200 | Σε επίπεδο χώρας |
| Enterprise | Custom | Custom | 5.000.000+ | 200+ | Σε επίπεδο χώρας |
Και τώρα, ιδού το πραγματικό κόστος ανά 1.000 requests για κάθε βαθμίδα, αν λάβουμε υπόψη τους πολλαπλασιαστές:
| Πλάνο | Standard (1×) | JS Rendering (10×) | E-commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
Ένα πλάνο $49/μήνα που διαφημίζεται ως «100.000 credits» δίνει μόλις 1.333 πραγματικά requests όταν κάνετε scrape σε προστατευμένα sites με ultra-premium και JavaScript rendering. Αυτό αντιστοιχεί σε $36,75 ανά 1.000 σελίδες — ακριβότερο από πολλές πλήρως διαχειριζόμενες scraping υπηρεσίες.
Γιατί τα Credits Εξαφανίζονται Πιο Γρήγορα Απ’ Ό,τι Περιμένετε
Τρία πράγματα ξαφνιάζουν τους χρήστες.
Πρώτον: η τιμολόγηση με βάση το domain εφαρμόζεται αυτόματα. Δεν επιλέγετε εσείς τον πολλαπλασιαστή 5× για Amazon ή 25× για Google. Εφαρμόζεται τη στιγμή που το ScraperAPI εντοπίσει το domain. Το ίδιο ισχύει και για τα anti-bot bypass credits (+10 για Cloudflare, DataDome, PerimeterX) — μπαίνουν αυτόματα όταν εντοπιστούν.
Δεύτερον: τα credits ΔΕΝ μεταφέρονται στον επόμενο μήνα. Τα αχρησιμοποίητα credits λήγουν στο τέλος κάθε κύκλου χρέωσης. Δεν μαζεύονται.
Και τρίτον — αυτό πονάει — το Pay-As-You-Go είναι διαθέσιμο μόνο από το πλάνο Scaling ($475/μήνα) και πάνω. Αν είστε σε Hobby, Startup ή Business και τελειώσουν τα credits στη μέση του κύκλου, απλώς μένετε εκτός μέχρι την επόμενη περίοδο χρέωσης. Η μόνη επιλογή σας είναι να πάτε σε ανώτερο πλάνο.
Ένας χρήστης στο Reddit ανέφερε ότι του έδωσαν προσφορά $3.600 για 60 εκατομμύρια credits με 1 credit ανά Amazon request, αλλά μετά την πληρωμή εφαρμόστηκε multiplier 5 credits χωρίς προειδοποίηση. Το πλάνο των 60M credits στην πράξη άξιζε μόνο 12M requests — δηλαδή ένα κενό 80% σε σχέση με αυτό που περίμενε.
Η Παγίδα Credits του DataPipeline
Η no-code λειτουργία DataPipeline του ScraperAPI (προγραμματισμένο scraping με παράδοση μέσω webhook) χρησιμοποιεί ξεχωριστό και αισθητά πιο ακριβό σύστημα χρεώσεων σε credits. Ένα βασικό κανονικό request κοστίζει 6 credits στο DataPipeline αντί για 1 credit μέσω του standard API:
| Τύπος Request | Standard API | DataPipeline | Αναλογία |
|---|---|---|---|
| Βασικό κανονικό request | 1 | 6 | 6× |
| Βασικό e-commerce | 5 | 10 | 2× |
| Βασικό SERP | 25 | 30 | 1,2× |
| Ultra-premium + JS (κανονικό) | 75 | 80 | 1,07× |
Όσοι στήνουν no-code pipelines περιμένοντας το standard κόστος credits, ανακαλύπτουν ότι καίνε credits 6× πιο γρήγορα ακόμη και για απλά requests. Αυτό αναφέρεται στην τεκμηρίωση, αλλά πρέπει να το ψάξετε για να το βρείτε.
Πραγματικό Κόστος ανά Request: ScraperAPI vs. Ο Ανταγωνισμός
Η τιμή που βλέπετε δεν σημαίνει τίποτα αν δεν υπολογίσετε τους πολλαπλασιαστές. Πήρα τρέχουσες τιμές από πέντε παρόχους και έκανα σύγκριση σε επίπεδο περίπου $300/μήνα σε τρία συνηθισμένα σενάρια.
Βασικό HTML Scrape (Χωρίς JS, Χωρίς Premium Proxy)
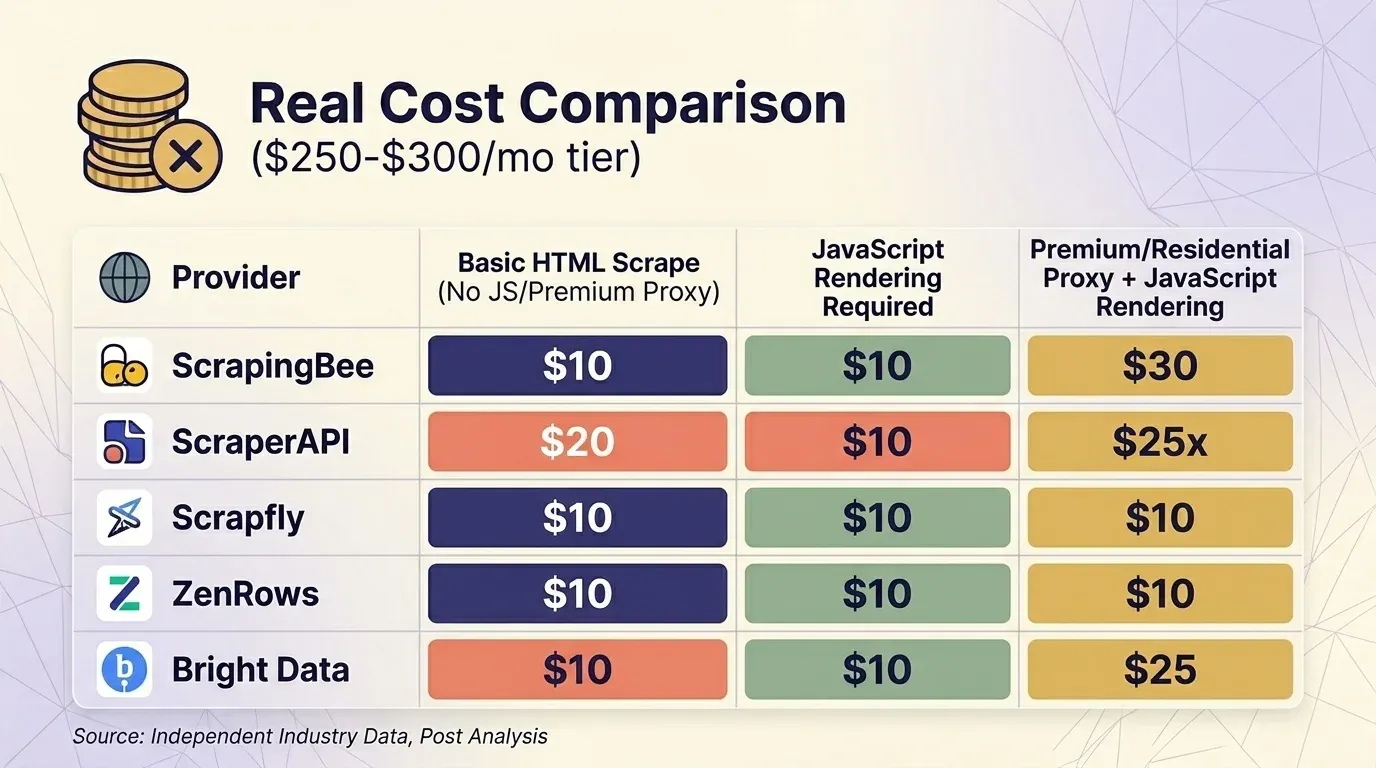
| Πάροχος | Πλάνο | Credits ανά Request | Πραγματικά Requests | Κόστος ανά 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1.071.000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200.000 | $1.50 |
Απαιτείται Απόδοση JavaScript
| Πάροχος | Πλάνο | Credits ανά Request | Πραγματικά Requests | Κόστος ανά 1K |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (ενεργό εξ ορισμού) | 600.000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1.40 |
| Bright Data | PAYG | flat | ~200.000 | $1.50 |
Premium/Residential Proxy + Απόδοση JavaScript (Προστατευμένα Sites)
| Πάροχος | Πλάνο | Credits ανά Request | Πραγματικά Requests | Κόστος ανά 1K |
|---|---|---|---|---|
| Bright Data | PAYG | flat | ~200.000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7.00 |
Το Web Unlocker της Bright Data είναι ο μόνος πάροχος που δεν χρεώνει επιπλέον για JavaScript rendering — όλα τα requests κοστίζουν την ίδια σταθερή τιμή. Στο επίπεδο των περίπου $300, το ScrapingBee και το ScraperAPI είναι ανταγωνιστικά για scraping προστατευμένων sites, ενώ το ZenRows είναι το ακριβότερο.
Μια σημαντική παρατήρηση στη χρήση: το ScrapingBee ενεργοποιεί από προεπιλογή το JavaScript rendering με κόστος 5×. Αν συγκρίνετε ScrapingBee και ScraperAPI απευθείας, βεβαιωθείτε ότι συγκρίνετε τις ίδιες ρυθμίσεις rendering.
Ανεξάρτητη ανάλυση από το Scrape.do έδειξε ότι το ScraperAPI κοστίζει κατά μέσο όρο $8,49 ανά 1.000 requests — «περισσότερο από κάθε άλλον πάροχο που δοκιμάστηκε» — με μέσο χρόνο απόκρισης 15,7 δευτερόλεπτα, κάτι που το κάνει «έναν από τους πιο αργούς παρόχους που υπάρχουν». Καλό είναι να το ξέρετε πριν δεσμευτείτε.
Ποσοστά Επιτυχίας Ανά Site: Πού Αποδίδει το ScraperAPI και Πού Δυσκολεύεται
Καμία scraping API δεν αποδίδει το ίδιο καλά σε κάθε website. Ανεξάρτητα benchmarks από το Scrapeway (Απρίλιος 2026) δείχνουν μια αρκετά διχασμένη εικόνα.
Απόδοση ανά Κατηγορία Site
| Στόχος Site | Ποσοστό Επιτυχίας | Μέση Ταχύτητα | Κόστος ανά 1K (Business Plan) |
|---|---|---|---|
| Zillow | 100% | 10,5s | $0.49 |
| Etsy | 99% | 4,8s | $4.90 |
| Amazon | 98% | 6,5s | $2.45 |
| 95% | 17,8s | $14.70 | |
| Walmart | 93% | 11,4s | $2.45 |
| Indeed | 90% | 15,8s | $4.90 |
| StockX | 84% | 3,9s | $4.90 |
| Realtor.com | 12% | 11,8s | $0.49 |
| 0% | — | — | |
| Booking.com | 0% | — | — |
| Twitter/X | 0% | — | — |
Συνολικό μέσο ποσοστό επιτυχίας: 62,8–63,7%, λίγο πάνω από τον μέσο όρο του κλάδου που είναι 58,2–59,5%. Μέσος χρόνος απόκρισης: 5,2–7,3 δευτερόλεπτα, καλύτερος από τον μέσο όρο του κλάδου που είναι 9,8 δευτερόλεπτα.
Πού το ScraperAPI Αποδίδει Καλά
Το ScraperAPI είναι πραγματικά δυνατό στο e-commerce (Amazon, Walmart, Etsy) και στο real estate (Zillow). Τα structured data endpoints για αυτά τα sites επιστρέφουν parsed JSON με υψηλή αξιοπιστία. Αν το βασικό σας use case είναι scraping σε σελίδες προϊόντων Amazon ή σε Google SERPs, το ScraperAPI είναι λογική επιλογή.
Πού το ScraperAPI Υστερεί
Τα social media είναι νεκρή ζώνη. Το Instagram, το Twitter/X και το Booking.com εμφανίζουν ποσοστό επιτυχίας 0% σε ανεξάρτητες δοκιμές. Το LinkedIn λειτουργεί στο 95%, αλλά με 30 credits ανά request το κόστος ανεβαίνει πολύ.
Sites με υποχρεωτικό login είναι ρητά εκτός ορίων. Το ScraperAPI υποστηρίζει session persistence μέσω της παραμέτρου session_number, αλλά απαγορεύει το scraping δεδομένων πίσω από login walls. Δεν μπορεί να χειριστεί συμπλήρωση φορμών, two-factor authentication ή σύνθετα auth flows.
Παρωχημένα δεδομένα σε προστατευμένους στόχους. Το ScraperAPI εφαρμόζει υποχρεωτική cache 10 λεπτών σε δύσκολους στόχους, πράγμα που σημαίνει ότι αν κάνετε scrape δεδομένα που αλλάζουν γρήγορα (τιμές, διαθεσιμότητα αποθεμάτων), μπορεί να πάρετε αποτελέσματα έως και 10 λεπτά παλιά.
Στο benchmark του 2025 από το Proxyway, το ScraperAPI είχε το χειρότερο ποσοστό επιτυχίας από όλους τους παρόχους στο Google, με 81,72%.
Σύνοψη Απόδοσης ανά Κατηγορία Site
| Κατηγορία Site | Απόδοση ScraperAPI | Γνωστά Προβλήματα | Πιθανή Εναλλακτική |
|---|---|---|---|
| Amazon / e-commerce | ✅ Ισχυρή (SDP endpoints) | Μεγάλη κατανάλωση credits σε κλίμακα | Thunderbit templates (1 click, χωρίς credits ανά row για το template) |
| Google SERPs | ✅ Ισχυρή | Η γεω-στόχευση κοστίζει έξτρα· σε ένα benchmark είχε τη χαμηλότερη επιτυχία στο Google | — |
| Real estate (Zillow) | ✅ Εξαιρετική (100%) | — | — |
| Instagram / social media | ❌ 0% επιτυχία | Πλήρης αποτυχία | Playwright + proxies (DIY) |
| JS-heavy SPAs | ⚠️ Μέτρια | Απαιτεί 10× credits για headless rendering | Scrapfly, ZenRows |
| Sites που απαιτούν login | ❌ Απαγορεύεται από τους όρους | Χωρίς υποστήριξη session/auth | Thunderbit browser scraping (χρησιμοποιεί τη δική σας login session) |
| Booking.com / travel | ❌ 0% επιτυχία | Πλήρης αποτυχία | Bright Data |
Τι Λένε οι Πραγματικοί Χρήστες: Σύνοψη Συναισθήματος από G2, Capterra και Reddit
Συγκέντρωσα σχόλια από τρεις πλατφόρμες. Αυτές είναι οι τρέχουσες βαθμολογίες:
| Πλατφόρμα | Βαθμολογία | Κριτικές |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Υποβαθμολογίες Capterra: Ευκολία χρήσης 4.9/5, Εξυπηρέτηση πελατών 4.6/5, Χαρακτηριστικά 4.5/5, Value for Money 4.5/5.
Σύνοψη Συναισθήματος ανά Θέμα
| Θέμα | Θετικά Σήματα | Αρνητικά Σήματα |
|---|---|---|
| Ευκολία εγκατάστασης / docs | «Πολύ εύκολο στο στήσιμο. Ξεκινάς scraping μέσα σε λίγα λεπτά.» — Latenode community; Capterra Ease of Use 4.9/5 | — |
| Διαφάνεια τιμολόγησης | «Προσιτό entry tier» (πολλαπλές κριτικές στο Capterra) | «Η ανάλυση του κόστους σε credits μπορεί να μπερδέψει» — John S., Founder, Capterra (Φεβ. 2025)· «Οι τιμές αυξήθηκαν 1000% και η ποιότητα χειροτέρεψε» — CTO, Online Media, Capterra (Σεπτ. 2022) |
| Αξιοπιστία | «Δουλεύει άψογα για Amazon/Google» (G2, Capterra) | «Το ScraperAPI γίνεται ασταθές σε βαριές εργασίες» — emcarter, Latenode· «80% failure rate σε ορισμένους στόχους» (Reddit) |
| Υποστήριξη πελατών | «Ανταποκρινόμενη ομάδα» (Capterra) | Χρήστης ανέφερε ότι του έδωσαν μία τιμή και μετά χρεώθηκε με 5× rate χωρίς προειδοποίηση (Reddit) |
| Αξία με την πάροδο του χρόνου | Χρεώνει μόνο για επιτυχημένα requests (200/404) | «Αν τρέχετε μεγάλης κλίμακας operations, τα έξοδα ανεβαίνουν γρήγορα» και το να χτίσετε δική σας υποδομή είναι «πιο οικονομικό μακροπρόθεσμα» — mikezhang, Latenode |
Το συμπέρασμα: το ScraperAPI έχει καλή φήμη για την ευκολία αρχικής εγκατάστασης και είναι αξιόπιστο σε δημοφιλείς, καλά υποστηριζόμενους στόχους. Τα παράπονα συγκεντρώνονται γύρω από εκπλήξεις στην τιμολόγηση (multipliers, απρόσμενες αυξήσεις) και την αξιοπιστία σε πιο δύσκολους στόχους.
Τα Structured Data Endpoints του ScraperAPI: Αξίζουν τα Premium Credits;
Το ScraperAPI προσφέρει 18 structured data endpoints σε 5 πλατφόρμες, επιστρέφοντας parsed JSON αντί για ακατέργαστο HTML:
- Amazon (3 endpoints): Λεπτομέρειες προϊόντος βάσει ASIN, αποτελέσματα αναζήτησης, προσφορές ανταγωνιστών. Επιστρέφει 18+ πεδία, όπως τιμή, αξιολογήσεις, περιγραφές, κριτικές, BSR, εικόνες, πληροφορίες πωλητή. Υποστηρίζει 21 περιφερειακά marketplaces.
- Google (5 endpoints): SERP (οργανικά αποτελέσματα, knowledge graph, βίντεο, related questions, pagination), Shopping, Maps, News, Jobs.
- Walmart (4 endpoints): Product, Search, Category, Reviews.
- eBay (2 endpoints): Product, Search.
- Redfin (4 endpoints): Search, Agent Details, Rental Properties, For Sale.
Τα SDEs είναι διαθέσιμα σε όλα τα πλάνα, ακόμα και στο Free. Το ScraperAPI ισχυρίζεται ποσοστό επιτυχίας 99,99% για τα υποστηριζόμενα SDE domains — αν και τα ανεξάρτητα benchmarks δείχνουν μια πιο σύνθετη εικόνα, ανάλογα με το site.
Πληρότητα Δεδομένων
Το Amazon SDP είναι η πιο δυνατή προσφορά του ScraperAPI. Επιστρέφει πλήρες σύνολο πεδίων: τιμή, κριτικές, BSR, variants, εικόνες, πληροφορίες πωλητή και άλλα. Το Google SERP SDP επιστρέφει οργανικά αποτελέσματα, διαφημίσεις, featured snippets και People Also Ask. Η πληρότητα των δεδομένων είναι πραγματικά καλή για αυτές τις δύο πλατφόρμες.
Αποδοτικότητα Credits: SDP vs. DIY Parsing
Στο Business πλάνο ($299/μήνα, 3M credits), το scraping 10.000 προϊόντων Amazon μέσω του SDE κοστίζει 50.000 credits (5 credits το καθένα) — περίπου $5 αξίας του πλάνου. Το να φτιάξετε δικό σας parser με standard request (1 credit το καθένα) θα κόστιζε μόνο 10.000 credits, αλλά θα επενδύατε χρόνο ανάπτυξης και συντήρησης.
Για μικρές ομάδες χωρίς developers, τα SDEs γλιτώνουν πραγματικό χρόνο.
Για ομάδες με engineering δυνατότητα που κάνουν scraping σε μεγάλη κλίμακα, το premium 5× σε credits δύσκολα δικαιολογείται.
Πώς Συγκρίνονται τα SDPs με τα No-Code Scraper Templates
Αυτή η σύγκριση είναι πιο σημαντική απ’ όσο παραδέχονται οι περισσότερες αξιολογήσεις. Η Thunderbit προσφέρει έτοιμα scraper templates για Amazon, Shopify, Zillow και 50+ ακόμη sites που δεν χρειάζονται καθόλου κώδικα και δεν έχουν per-row credit κόστος για το ίδιο το template.
Δοκιμάστε τα Thunderbit Templates για Scraping με 1 Κλικ
| Παράγοντας | ScraperAPI SDP (Amazon) | Thunderbit Amazon Template |
|---|---|---|
| Χρόνος εγκατάστασης | 30–60 λεπτά (κώδικας + ενσωμάτωση API) | ~2 λεπτά (εγκατάσταση extension, άνοιγμα Amazon, κλικ στο template) |
| Κόστος ανά 1.000 προϊόντα (Business plan) | ~$5 (50.000 credits με $0.10/credit) | ~$16.50 (1.000 rows × 1 credit στο $0.0165/credit στο Pro) |
| Πεδία που επιστρέφονται | 18+ (πλήρες) | Όνομα προϊόντος, τιμή, βαθμολογία, κριτικές, εικόνες, URL και άλλα |
| Επιλογές εξαγωγής | JSON (απαιτεί κώδικα για parsing) | Excel, CSV, Google Sheets, Airtable, Notion — με 1 κλικ |
| Συντήρηση | Το ScraperAPI συντηρεί το SDP | Η ομάδα της Thunderbit συντηρεί τα templates |
| Τεχνικές γνώσεις | Απαιτείται Python/Node.js | Καμία |
Για ομάδες developers που κάνουν υψηλού όγκου scraping στο Amazon, το SDP του ScraperAPI είναι πιο αποδοτικό ανά προϊόν σε μεγάλη κλίμακα. Για business users που θέλουν δεδομένα Amazon σε spreadsheet χωρίς κώδικα, η Thunderbit είναι πολύ πιο γρήγορη στο στήσιμο και στη χρήση.
Χρειάζεστε Πράγματι Scraping API; Η No-Code Διαδρομή που οι Περισσότερες Αξιολογήσεις Αγνοούν
Πολλοί που ψάχνουν για «Scraper API review» δεν έχουν ακόμη κλειδώσει σε API-based workflow. Απλώς προσπαθούν να καταλάβουν αν το χρειάζονται καν.
Και πολλοί τελικά δεν το χρειάζονται. Η αγορά των web scraping APIs είναι κλάδος αξίας $2,03 δισεκατομμυρίων με ανάπτυξη 14–18% CAGR, αλλά αυτή η ανάπτυξη έρχεται κυρίως από enterprise engineering ομάδες — όχι από τον sales ops manager που θέλει 500 leads από ένα website.
Scraping API vs. No-Code Tool: Ένα Πλαίσιο Απόφασης Δίπλα-Δίπλα
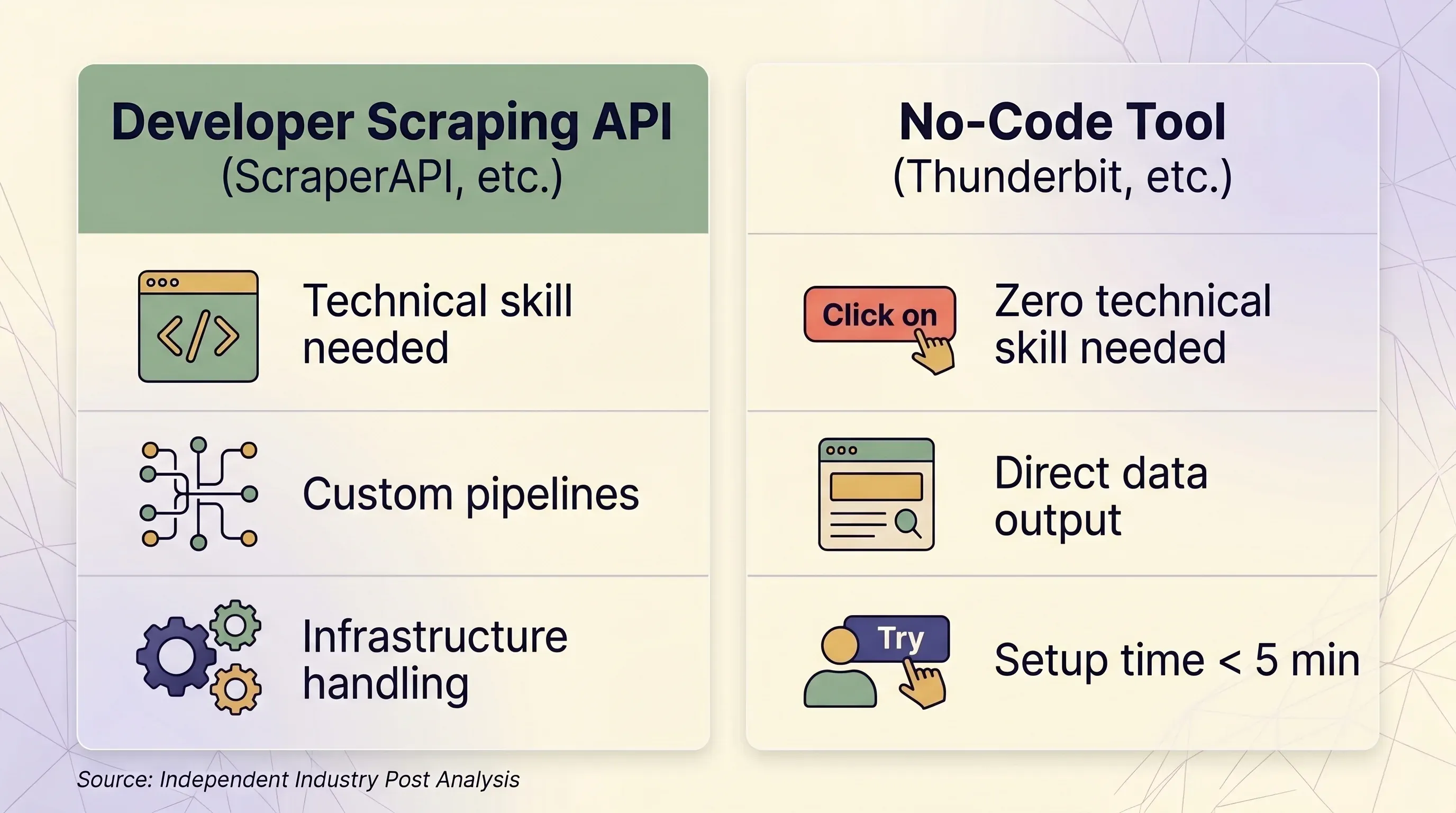
| Παράγοντας | Scraping API (ScraperAPI κ.λπ.) | No-Code Tool (Thunderbit κ.λπ.) | |---|---|---|---| | Ιδανικό για | Developers που χτίζουν data pipelines σε κλίμακα | Business users, marketers, sales teams, ερευνητές | | Απαιτούμενες τεχνικές γνώσεις | Python/Node.js, HTTP concepts, JSON parsing | Καμία — point-and-click στο browser | | Χρόνος εγκατάστασης | Τουλάχιστον 1–2 ώρες (κώδικας + test + debug) | Κάτω από 5 λεπτά | | Αντιμετώπιση anti-bot | Premium proxies (10–75 credits/request) | Πραγματική browser session — παρακάμπτει φυσικά το fingerprinting | | Sites με login | ❌ Απαγορεύεται από τους όρους του ScraperAPI | ✅ Το Browser Scraping χρησιμοποιεί την υπάρχουσα session σας | | Κλίμακα (σελίδες/ημέρα) | 100K–3M+ requests/μήνα | Ad-hoc, συνήθως κάτω από 1.000 σελίδες/ημέρα | | Έξοδος δεδομένων | Raw HTML ή JSON (απαιτεί κώδικα parsing) | Δομημένες γραμμές/στήλες — έτοιμες για χρήση | | Εξαγωγή | JSON, CSV (μέσω κώδικα) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Συντήρηση | Πρέπει να ενημερώνετε selectors, retry logic, υποδομή | Καμία — η AI ξαναδιαβάζει τη δομή της σελίδας κάθε φορά | | Μονάδα τιμολόγησης | Per-request credits (μεταβλητό: 1–75 credits/request) | Per-row credits (1 credit = 1 row, 2 για subpages) | | Τιμή εισόδου | $49/μήνα για 100K credits | $9/μήνα για 5.000 credits (ετήσιο) | | Free tier | 1.000 credits/μήνα, 5 ταυτόχρονες εκτελέσεις | 6 σελίδες/μήνα, 30 credits/σελίδα | | Προβλεψιμότητα τιμής | Χαμηλή — οι πολλαπλασιαστές φέρνουν εκπλήξεις | Υψηλή — 1 row πάντα = 1 credit |
Πότε Έχει Νόημα ένα Scraping API
- Έχετε developer ή engineering ομάδα
- Χρειάζεται να κάνετε scrape 100K+ σελίδες την ημέρα προγραμματισμένα
- Χρειάζεστε βαθιά παραμετροποίηση σε headers, sessions και retry logic
- Οι στόχοι σας είναι καλά υποστηριζόμενοι (Amazon, Google, Walmart, Zillow)
Πότε Έχει Περισσότερο Νόημα ένα No-Code Tool όπως η Thunderbit
- Εργάζεστε σε sales, e-commerce ops, marketing ή real estate — όχι engineering
- Χρειάζεστε δεδομένα από δεκάδες διαφορετικά sites χωρίς να χτίζετε custom parsers για το καθένα
- Θέλετε άμεση εξαγωγή σε Excel, Google Sheets, Airtable ή Notion
- Χρειάζεται να κάνετε scrape σε sites που απαιτούν login (το browser scraping της Thunderbit χρησιμοποιεί τη δική σας session)
- Θέλετε η AI να διαβάζει τη σελίδα από την αρχή κάθε φορά — χωρίς συντήρηση κώδικα όταν αλλάζουν τα layouts
- Χρειάζεστε scraping υποσελίδων: η Thunderbit μπορεί να επισκεφθεί κάθε detail page και να εμπλουτίσει αυτόματα τις γραμμές
Η ροή εργασίας του Thunderbit Chrome Extension είναι πραγματικά απλή: εγκαθιστάτε το extension, ανοίγετε οποιαδήποτε σελίδα, πατάτε «AI Suggest Fields», πατάτε «Scrape» και κάνετε export. Η AI καταλαβαίνει ποια δεδομένα υπάρχουν στη σελίδα και προτείνει στήλες — δεν χρειάζεται να γράψετε selectors ή κώδικα. Για περισσότερα σχετικά με το πώς δουλεύει, δείτε τον οδηγό αρχαρίων για web scraping.
Το 62% των επιχειρήσεων αντιμετώπισε υπερβάσεις στο κόστος cloud το 2024, και οι εταιρείες που χρησιμοποιούν usage-based pricing χωρίς σωστές δικλείδες ασφαλείας βλέπουν 23% υψηλότερα churn rates λόγω bill shock. Η προβλεψιμότητα ενός per-row credit μοντέλου αξίζει σοβαρή σκέψη αν έχετε ήδη «καεί» από μεταβλητά API κόστη.
Δοκιμάστε το AI Web Scraper της Thunderbit
ScraperAPI: Πλεονεκτήματα και Μειονεκτήματα με μια Ματιά
| Πλεονεκτήματα | Μειονεκτήματα |
|---|---|
| Ισχυρή υποδομή proxy (40M+ IPs, 50+ χώρες) | Μπερδεμένο σύστημα πολλαπλασιαστών credits — ο συνδυασμός χαρακτηριστικών κοστίζει παραπάνω από το άθροισμα |
| Εξαιρετική τεκμηρίωση και εύκολη αρχική εγκατάσταση (Capterra Ease of Use: 4.9/5) | Τα credits ΔΕΝ μεταφέρονται από μήνα σε μήνα |
| Αξιόπιστο σε Amazon, Google, Zillow, Etsy | 0% επιτυχία σε Instagram, Twitter/X, Booking.com |
| Χρεώνει μόνο για επιτυχημένα requests (200/404) | Τα 404 responses επίσης καταναλώνουν credits |
| 18 structured data endpoints με parsed JSON output | Τα sites που απαιτούν login απαγορεύονται ρητά |
| Διαθέσιμο σε όλα τα πλάνα, ακόμα και στο Free | Το Pay-As-You-Go υπάρχει μόνο στο Scaling ($475/μήνα) και πάνω |
| Πολιτική επιστροφής χρημάτων 7 ημερών χωρίς ερωτήσεις | Υποχρεωτική cache 10 λεπτών σε δύσκολους στόχους — κίνδυνος παρωχημένων δεδομένων |
| Ανάπτυξη εσόδων 30–35% YoY δείχνει ενεργή εξέλιξη | Το DataPipeline κοστίζει έως και 6× τα standard API credits |
| — | Η γεω-στόχευση πέρα από US & EU απαιτεί Business plan ($299/μήνα) |
| — | Δεν υπάρχουν προληπτικές ειδοποιήσεις χρήσης — πρέπει να ελέγχετε χειροκίνητα το dashboard |
Πρακτικές Συμβουλές για να Πάρετε το Μέγιστο από το ScraperAPI (Αν Αποφασίσετε να το Χρησιμοποιήσετε)
Παρακολουθείτε την Κατανάλωση Credits Καθημερινά
Το dashboard του ScraperAPI δίνει στατιστικά χρήσης, όπως μέση καθυστέρηση, domains που έχουν γίνει scrape και metrics ταυτόχρονης εκτέλεσης. Όμως, δεν υπάρχουν προληπτικές ειδοποιήσεις χρήσης — ούτε email ούτε SMS όταν τελειώνουν τα credits. Πρέπει να το κοιτάτε χειροκίνητα. Το ιστορικό analytics περιορίζεται σε 2 εβδομάδες στα πλάνα Hobby/Startup και σε 6 μήνες στα Business+.
Βάλτε υπενθύμιση στο ημερολόγιό σας να ελέγχετε το dashboard κάθε μέρα τον πρώτο μήνα. Πρέπει να αποκτήσετε αίσθηση για το πόσο γρήγορα καίγονται τα credits στους δικούς σας στόχους.
Ξεκινήστε από το Free Tier για να Δοκιμάσετε τα Target Sites σας
Χρησιμοποιήστε τα 1.000 δωρεάν credits (συν 7ήμερη δοκιμή με 5.000 credits) για να δοκιμάσετε τα ποσοστά επιτυχίας στα δικά σας sites πριν δεσμευτείτε σε paid πλάνο. Καταγράψτε ποια sites χρειάζονται JavaScript rendering ή premium proxies, ώστε να υπολογίσετε ρεαλιστικό μηνιαίο κόστος με τους πολλαπλασιαστές.
Απενεργοποιήστε τα Premium Features Εκτός Αν τα Χρειάζεται ο Στόχος
Το ScraperAPI ΔΕΝ ενεργοποιεί αυτόματα premium proxies ή JavaScript rendering — πρέπει να ορίσετε ρητά render=true, premium=true ή ultra_premium=true. Όμως η χρέωση βάσει domain ΕΙΝΑΙ αυτόματη: το Amazon κοστίζει πάντα 5 credits, το Google πάντα 25, το LinkedIn πάντα 30. Τα anti-bot bypass credits (+10 για Cloudflare, DataDome, PerimeterX) επίσης προστίθενται αυτόματα όταν εντοπιστούν. Να το έχετε αυτό στο μυαλό σας πριν ρίξετε μαζικά requests.
Χρησιμοποιήστε τα Structured Data Endpoints για τα Υποστηριζόμενα Sites
Αν κάνετε scrape στο Amazon ή στο Google, τα SDEs γλιτώνουν χρόνο ανάπτυξης ακόμη κι αν κοστίζουν περισσότερα credits. Για μη υποστηριζόμενα sites, δείτε αν ένα no-code εργαλείο θα ήταν πιο γρήγορο και πιο φτηνό από το να φτιάξετε custom parser.
Έχετε Εναλλακτικό Πλάνο για Μη Αξιόπιστους Στόχους
Αν το ποσοστό επιτυχίας του ScraperAPI σε κάποιο site είναι κάτω από 90%, σκεφτείτε να δρομολογήσετε αυτά τα requests μέσω άλλου παρόχου ή να χρησιμοποιήσετε browser-based εργαλείο. Για sites που απαιτούν login, το ScraperAPI απλώς δεν θα δουλέψει — θα χρειαστείτε ένα εργαλείο όπως το Thunderbit που λειτουργεί μέσα στη δική σας browser session.
Γνωρίστε τις Παγίδες
- Τα 404 responses καταναλώνουν credits — το ScraperAPI χρεώνει τόσο για status codes 200 όσο και 404
- Τα ακυρωμένα requests χρεώνονται αν τα ακυρώσετε πριν ολοκληρωθεί το παράθυρο επεξεργασίας των 70 δευτερολέπτων
- Υποχρεωτική 10λεπτη cache σε δύσκολους στόχους — μπορεί να πάρετε παρωχημένα δεδομένα
- Το Pay-As-You-Go υπάρχει μόνο στο Scaling ($475/μήνα) και πάνω — οι χρήστες χαμηλότερων πλάνων που εξαντλούν τα credits μένουν εκτός
- Η γεω-στόχευση πέρα από US & EU απαιτεί το Business plan ($299/μήνα)
Κύρια Συμπεράσματα: Είναι το ScraperAPI το Κατάλληλο Εργαλείο για Εσάς;
Να πού κατέληξα μετά από όλη την έρευνα:
- Το ScraperAPI είναι καλή επιλογή για developer ομάδες που κάνουν scraping σε μεγάλους όγκους και σε καλά υποστηριζόμενους στόχους όπως Amazon, Google, Walmart και Zillow. Τα structured data endpoints είναι πραγματικά χρήσιμα, η υποδομή proxy είναι μεγάλη και η τεκμηρίωση είναι πάνω από τον μέσο όρο.
- Το σύστημα πολλαπλασιαστών credits είναι ο μεγαλύτερος κίνδυνος. Αν δεν καταλάβετε πώς αθροίζονται οι πολλαπλασιαστές, θα ξεφύγετε σε κόστος. Το κενό ανάμεσα στα advertised credits και στα πραγματικά requests μπορεί να είναι 5–75×. Κάντε τους υπολογισμούς για τη δική σας χρήση πριν δεσμευτείτε σε paid πλάνο.
- Η αξιοπιστία εξαρτάται από το site. Το ScraperAPI είναι εξαιρετικό σε e-commerce και real estate, μέτριο σε job boards και social media, και εντελώς άχρηστο σε Instagram, Twitter/X και Booking.com. Μην υποθέτετε ότι θα δουλεύει το ίδιο παντού.
- Για μη τεχνικές ομάδες, το ScraperAPI είναι το λάθος εργαλείο. Αν δουλεύετε σε sales, marketing ή operations και θέλετε δομημένα δεδομένα χωρίς να γράψετε κώδικα, ένα no-code εργαλείο όπως το Thunderbit σας δίνει αποτέλεσμα σε δύο κλικ — με AI-powered field detection, άμεση εξαγωγή σε spreadsheet, εμπλουτισμό υποσελίδων και μηδενικό overhead συντήρησης. Δείτε το Thunderbit Chrome Extension ή παρακολουθήστε tutorials στο Thunderbit YouTube Channel.
- Για developers με περιορισμένο budget, δοκιμάστε το free tier του ScraperAPI στους συγκεκριμένους στόχους σας και μετά συγκρίνετε το πραγματικό κόστος ανά request με ScrapingBee, Scrapfly και Bright Data πριν αποφασίσετε. Η φθηνότερη επιλογή εξαρτάται ολοκληρωτικά από το use case και τις ανάγκες σε features.
Θέλετε να δείτε πώς βγαίνουν οι αριθμοί για τις δικές σας ανάγκες scraping; Ξεκινήστε με το free tier του ScraperAPI για να δοκιμάσετε τα target sites σας ή εγκαταστήστε το Thunderbit για να δείτε πόσο μακριά μπορούν να σας πάνε δύο κλικ. Για περισσότερα σχετικά με την τιμολόγηση, δείτε τα πλάνα μας.
Συχνές Ερωτήσεις
Είναι δωρεάν το ScraperAPI;
Ναι, το ScraperAPI προσφέρει free tier με 1.000 API credits τον μήνα και 7ήμερη δοκιμή με 5.000 credits. Όμως, οι πολλαπλασιαστές credits για JavaScript rendering, premium proxies ή ακριβές κατηγορίες domain (Amazon = 5×, Google = 25×, LinkedIn = 30×) σημαίνουν ότι η πραγματική σας δυνατότητα μπορεί να είναι πολύ χαμηλότερη από 1.000 requests. Στο free tier, τα ultra-premium proxies δεν είναι διαθέσιμα.
Πόσο κοστίζει το ScraperAPI ανά request;
Εξαρτάται πολύ από τα feature flags και το target domain. Ένα standard request σε απλό HTML site κοστίζει 1 credit. Ένα request στο Amazon κοστίζει 5 credits. Ένα Google SERP request κοστίζει 25 credits. Η ενεργοποίηση JavaScript rendering προσθέτει 10 credits. Ο συνδυασμός ultra-premium proxy με JavaScript rendering κοστίζει 75 credits ανά request. Στο Hobby πλάνο ($49/μήνα, 100K credits), αυτό μεταφράζεται από $0.00049 ανά request (standard) έως $0.0368 ανά request (ultra-premium + JS). Δείτε τους πλήρεις πίνακες κόστους παραπάνω για λεπτομέρειες.
Είναι το ScraperAPI καλό για scraping στο Amazon;
Το Amazon Structured Data endpoint του ScraperAPI είναι ένα από τα πιο δυνατά χαρακτηριστικά του, με 98% success rate σε ανεξάρτητα benchmarks και πλήρες parsed JSON output (18+ πεδία). Ωστόσο, κάθε Amazon request κοστίζει τουλάχιστον 5 credits, οπότε το κόστος ανεβαίνει πολύ σε κλίμακα. Για μικρότερες ομάδες που θέλουν δεδομένα Amazon σε spreadsheet χωρίς κώδικα, το Amazon template της Thunderbit προσφέρει εναλλακτική 1 κλικ με άμεση εξαγωγή.
Ποιες είναι οι καλύτερες εναλλακτικές του ScraperAPI;
Για developers: ScrapingBee (το φθηνότερο για βασικό HTML), Scrapfly (καλό για JavaScript rendering), Bright Data (το καλύτερο για προστατευμένα sites — σταθερή χρέωση ανεξάρτητα από rendering) και ZenRows. Για μη τεχνικούς χρήστες: Thunderbit — ένα no-code, AI-powered Chrome extension με άμεση εξαγωγή σε Excel, Google Sheets, Airtable και Notion. Δείτε τη σύγκρισή μας με τα καλύτερα AI web scrapers για πιο αναλυτική ματιά.
Μπορεί το ScraperAPI να κάνει scrape sites που απαιτούν login;
Το ScraperAPI υποστηρίζει session persistence μέσω της παραμέτρου session_number (ίδιο IP σε πολλαπλά requests), αλλά απαγορεύει ρητά το scraping δεδομένων πίσω από login walls. Δεν μπορεί να χειριστεί συμπλήρωση φορμών, two-factor authentication ή σύνθετα auth flows. Για sites που απαιτούν login, browser-based εργαλεία όπως το Thunderbit — που χρησιμοποιεί την υπάρχουσα browser session σας για να κάνει scrape ό,τι βλέπετε — είναι η πιο αξιόπιστη επιλογή.
Μάθετε Περισσότερα




