
Letzte Woche erzählte mir einer unserer Nutzer, er habe einen ganzen Nachmittag damit verbracht, Klempner-Einträge von SuperPages in eine Tabelle zu kopieren — 47 Zeilen in drei Stunden. Seine Handgelenke taten weh, seine Daten hatten Tippfehler, und E-Mail-Adressen hatte er immer noch keine. Diese Geschichte kam mir sehr bekannt vor, denn ich war selbst schon in genau so einer Situation. Und genau für solche Probleme haben wir gebaut.
SuperPages ist eines der langjährigen US-Verzeichnisse für lokale Unternehmen und wird von Thryv betrieben. Es deckt große Städte und zahlreiche Kategorien ab — von Klempnern über Zahnärzte und Anwälte bis hin zu HVAC-Technikern. Ältere technische Dokumentationen beschrieben es als landesweite Gelbe-Seiten-Datenbank mit über 11 Millionen Einträgen, und auch heute noch bietet die Seite umfangreiche lokale Kategorien. Die Herausforderung besteht nicht darin, Einträge zu finden. Es geht darum, daraus eine saubere, angereicherte Lead-Liste zu machen, ohne den Verstand zu verlieren (oder den ganzen Nachmittag).
Laut HubSpot’s Sales Trends Report 2024 verbringen Vertriebsteams nur rund 2 Stunden pro Tag tatsächlich mit Verkaufen — der Rest geht für Aufgaben wie Dateneingabe und Recherche drauf. Und 81 % der Sales-Profis sagen, dass KI ihnen helfen könnte, weniger Zeit mit manueller Arbeit zu verbringen. In diesem Leitfaden zeige ich drei Wege, wie Sie SuperPages für Leads scrapen können — von No-Code-KI bis Python — damit Sie die Methode wählen können, die zu Ihrem Skill-Level passt, und sich wieder den Aufgaben widmen, die wirklich Ergebnisse bringen.
Was ist SuperPages – und warum lieben Sales-Teams es als Lead-Quelle?
SuperPages ist ein US-fokussiertes Online-Verzeichnis für lokale Unternehmen, in dem Firmen mit Kontaktdaten, Kategorien, Bewertungen und mehr gelistet sind. Man kann es als digitale Weiterentwicklung der alten Gelben Seiten sehen — nur dass es heute nach Kategorie und Standort durchsuchbar ist und pro Eintrag deutlich mehr Daten liefert.
Ein typischer SuperPages-Eintrag kann Folgendes enthalten:
- Firmenname
- Telefonnummer
- Straße und Hausnummer
- Website-URL (falls verfügbar)
- Kategorie (z. B. Sanitär, Familienrecht, HVAC)
- Bewertungen und Rezensionen
- Öffnungszeiten (meist auf der Detailseite)
- Beschreibung (Detailseite)
Auf der Startseite von SuperPages werden beliebte Kategorien wie Home Services, Plumbers, Electricians, Dentists, Legal Services, Auto Repair, Restaurants und Pet Services hervorgehoben — also genau die Branchen, die Sales-Teams, Agenturen und lokale Dienstleister für Outbound-Kampagnen anvisieren.
Kurz gesagt: SuperPages ist eine Goldgrube für alle, die in den USA nach lokalen Unternehmen suchen. Die Daten sind strukturiert, die Abdeckung ist groß, und die Kategorien passen sauber zu realen Akquise-Kampagnen.
Warum SuperPages für Leads scrapen? Die wichtigsten Anwendungsfälle
SuperPages manuell zu durchsuchen und Daten in eine Tabelle zu übertragen, ist ein echter Produktivitäts-Killer. Scraping automatisiert diesen Prozess und liefert Ihnen in wenigen Minuten statt Stunden eine gezielte, strukturierte Liste. Und weil Sie die Suche selbst steuern (Kategorie + Stadt + Keyword), ist das Ergebnis oft relevanter als eine generische, gekaufte Lead-Liste.
Hier sind die häufigsten Anwendungsfälle, die ich von unseren Nutzern sehe:
| Anwendungsfall | Wer profitiert | Beispiel |
|---|---|---|
| Lokale Lead-Generierung | Vertriebsteams, Agenturen | Eine Liste von Klempnern in Dallas für Kaltakquise erstellen |
| Wettbewerbsanalyse | Operations, Marketing | Bewertungen und Leistungen von Wettbewerbern in einem Markt vergleichen |
| Markt-Mapping | Business Development | Alle Zahnärzte in einer PLZ für einen Produktlaunch identifizieren |
| Lieferantensuche | Einkauf, Operations | Anbieter in einer Region mit Telefon + Website finden |
| Lokale SEO-Recherche | Agenturen | Unternehmen ohne Website oder mit schwachen Listing-Daten finden |
| Gebietsplanung | Außendienst | Handwerksbetriebe nach Stadt, PLZ oder Servicegebiet gruppieren |
Der US-Markt für B2B-Lead-Generierung wurde 2024 auf 8,5 Milliarden USD geschätzt und soll bis 2034 auf 18,2 Milliarden USD wachsen — die Nachfrage nach dieser Art von Daten nimmt also nicht ab. Eine frisch gescrapte, nach Kategorie und Ort gefilterte Liste kann zielgerichteter sein als eine generische gekaufte Liste, muss aber vor der Ansprache noch verifiziert und dedupliziert werden (dazu später mehr).
So sieht das Endergebnis aus: Beispiel für gescrapete SuperPages-Daten
Bevor wir zum Wie kommen, möchte ich Ihnen zeigen, was Sie am Ende tatsächlich erhalten. Genau das fehlt in den meisten Anleitungen — aber wenn Sie Zeit investieren, sollten Sie wissen, wie das Ergebnis aussieht.
Hier ist eine Beispielausgabe (fiktive Daten, aber realistische Struktur):
| Firmenname | Telefon | Adresse | Website | Kategorie | Bewertung | Öffnungszeiten | E-Mail (angereichert) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Sanitär | 4,6 | Mo–Fr 7–18 Uhr | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4,8 | Mo–Sa 8–19 Uhr | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Zahnärzte | 4,4 | Mo–Do 9–17 Uhr | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Rechtsdienstleistungen | 4,2 | Mo–Fr 8:30–17:30 Uhr | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Autoreparatur | 4,7 | Mo–Sa 8–18 Uhr | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Tierpflege | 4,9 | Di–So 9–17 Uhr | booking@echoparkpets.example |
Ein paar wichtige Punkte dazu:
- Aus den Suchergebnissen: Firmenname, Telefonnummer, teilweise Adresse, Kategorie, Bewertung, Eintrags-URL.
- Von der Unternehmens-Detailseite: Vollständige Adresse, Öffnungszeiten, Beschreibung, Rezensionen, manchmal Website.
- Durch Anreicherung: E-Mail-Adresse (oft nur auf der Unternehmenswebsite oder über Anreicherungstools auffindbar).
- Durch Bereinigung: Telefonnummer im E.164-Format, normalisierte Bundesland-/PLZ-Felder, Dedupe-Keys, Quell-URL und Scrape-Datum.
Genau diese Art von Output können Sie direkt in ein CRM, ein Google Sheet oder eine Airtable-Datenbank übernehmen und sofort damit arbeiten.
3 Wege, SuperPages für Leads zu scrapen: Der Schnellvergleich

Nicht jeder hat das gleiche technische Komfortniveau — oder die gleiche Geduld. Deshalb hier drei Methoden im direkten Vergleich, damit Sie die passende auswählen können:
| Kriterium | Thunderbit (KI, No-Code) | Visuelles Scraper-Tool (z. B. Octoparse) | Python (Requests + BS4) |
|---|---|---|---|
| Einrichtungszeit | ~2 Min. (Extension installieren) | ~15 Min. (Workflow anlegen) | ~30 Min. (Bibliotheken installieren, Code schreiben) |
| Programmierung nötig | Nein | Nein | Ja (Python) |
| Pagination | Integriert (Klick oder Scroll) | Konfiguration erforderlich | Manueller Code |
| Subpage-Anreicherung | 1-Klick-Subpage-Scraping | Separater Workflow/Loop nötig | Separates Skript |
| Anti-Blocking | Cloud Scraping übernimmt das | Abhängig von Plan/Proxy-Add-on | Selbst umsetzen (Proxys, Header, Rate Limits) |
| Export | Excel, Google Sheets, Airtable, Notion, CSV, JSON | CSV, Excel, Datenbank | Alles, was Sie selbst programmieren |
| Am besten geeignet für | Vertriebsteams, Agenturen, Nicht-Entwickler | Halb-technische Nutzer | Entwickler mit vollem Kontrollbedarf |
Meine Empfehlung: Wenn Sie in den nächsten 2 Minuten loslegen wollen, nehmen Sie Methode 1. Wenn Sie visuelle Workflows mögen und etwas Konfiguration okay finden, probieren Sie Methode 2. Wenn Sie volle Kontrolle wollen und Python beherrschen, springen Sie zu Methode 3.
Methode 1: SuperPages-Leads mit Thunderbit scrapen (KI, No-Code)
Das ist der schnellste Weg von „Ich habe eine SuperPages-Suche“ zu „Ich habe eine Lead-Liste“. Kein Code, keine Workflow-Builder, keine Proxy-Konfiguration. Ich bin natürlich voreingenommen — wir haben Thunderbit gebaut — aber ich zeige Ihnen exakt, wie es funktioniert, damit Sie sich selbst ein Bild machen können.
Schwierigkeit: Anfänger
Benötigte Zeit: ~5 Minuten für einen vollständigen Kategorie-/Stadt-Scrape
Was Sie brauchen: Chrome-Browser, Thunderbit Chrome Extension (die Gratisversion reicht)
Schritt 1: Thunderbit installieren und SuperPages öffnen
Gehen Sie zur und installieren Sie die Thunderbit-Erweiterung. Das dauert etwa eine Minute. Wechseln Sie danach zu einer SuperPages-Suchergebnisseite — suchen Sie zum Beispiel auf superpages.com nach „Plumbers in Los Angeles, CA“.
Sie sollten nun das Thunderbit-Symbol in der Browser-Toolbar sehen und ein Seitenpanel, das bereit ist.
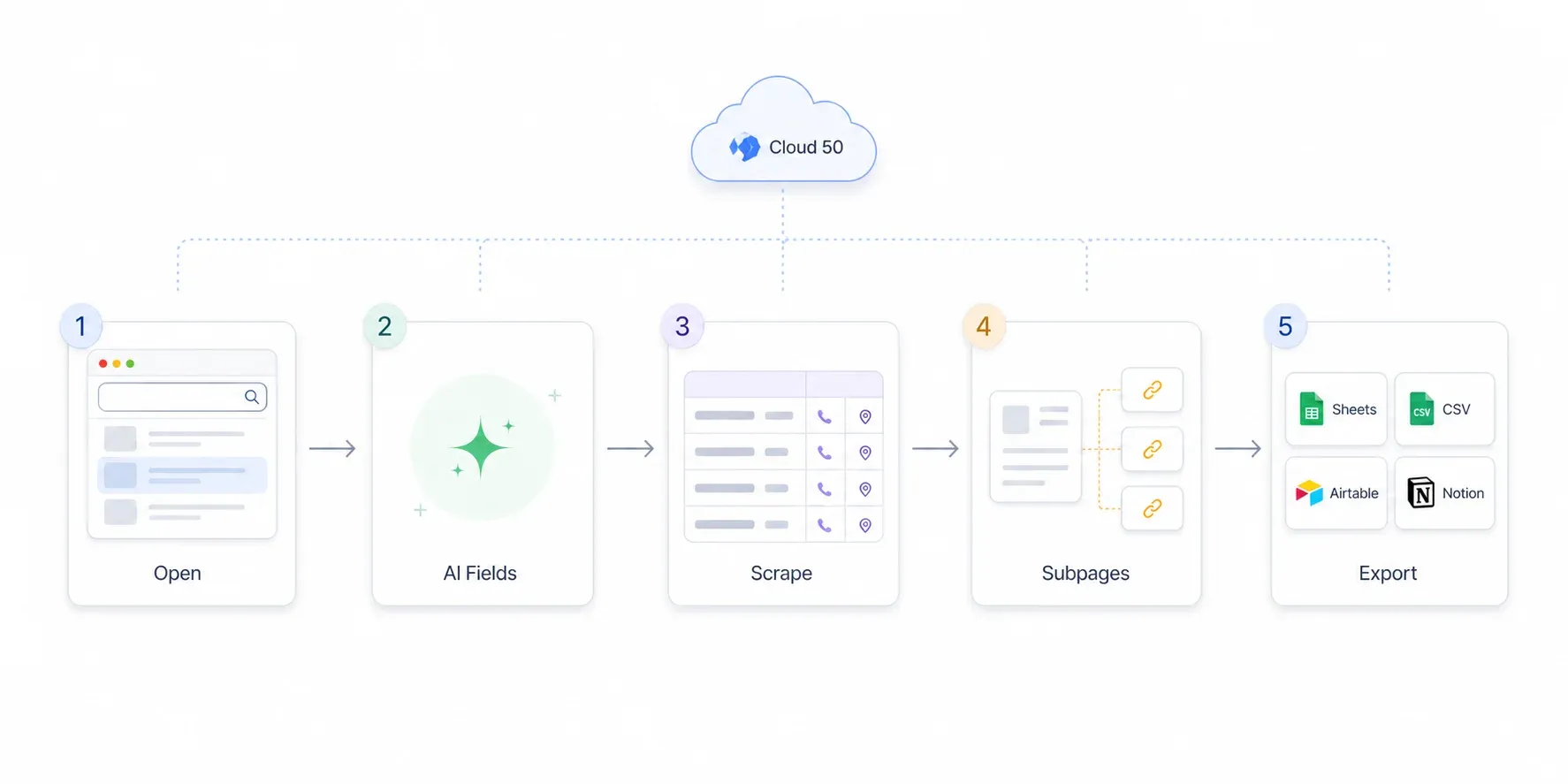
Schritt 2: Auf „AI Suggest Fields“ klicken, um Spalten automatisch zu erkennen
Öffnen Sie die Thunderbit-Seitenleiste und klicken Sie auf „AI Suggest Fields“. Die KI von Thunderbit liest die Seite und schlägt automatisch Spalten vor, die zu den gefundenen Informationen passen — typischerweise Firmenname, Telefon, Adresse, Website, Kategorie, Bewertung und Eintrags-URL.
Sie können die Spalten vor dem Scrapen anpassen, hinzufügen oder entfernen. Möchten Sie eine benutzerdefinierte Spalte wie „Hat Website?“ oder „Servicegebiet?“ hinzufügen? Dann geben Sie einfach eine Beschreibung in normalem Deutsch im Field AI Prompt ein. Sie könnten zum Beispiel anweisen, eine Spalte so zu formatieren, dass Telefonnummern als +1XXXXXXXXXX ausgegeben werden, oder Firmen als „privat“ vs. „gewerblich“ zu klassifizieren.
Sie sollten nun im Thunderbit-Panel eine Tabellenvorschau mit den konfigurierten Spalten sehen.
Schritt 3: Auf „Scrape“ klicken und zusehen, wie die Daten einlaufen
Klicken Sie auf den blauen Button „Scrape“. Thunderbit extrahiert alle Einträge auf der aktuellen Seite und füllt Ihre Tabelle Zeile für Zeile. Bei einer typischen SuperPages-Ergebnisseite dauert das etwa 30–45 Sekunden.
Thunderbit behandelt Pagination automatisch — es erkennt „Next“-Buttons oder Infinite Scroll und macht weiter, bis keine Seiten mehr übrig sind oder Ihr Limit erreicht ist. Wenn Sie einen großen Ergebnissatz scrapen, etwa alle Klempner in einer Metropolregion, wechseln Sie in den Cloud-Scraping-Modus. Damit lassen sich bis zu 50 Seiten gleichzeitig verarbeiten, ohne den Browser zu blockieren.
Schritt 4: Mit Subpage Scraping jeden Eintrag anreichern
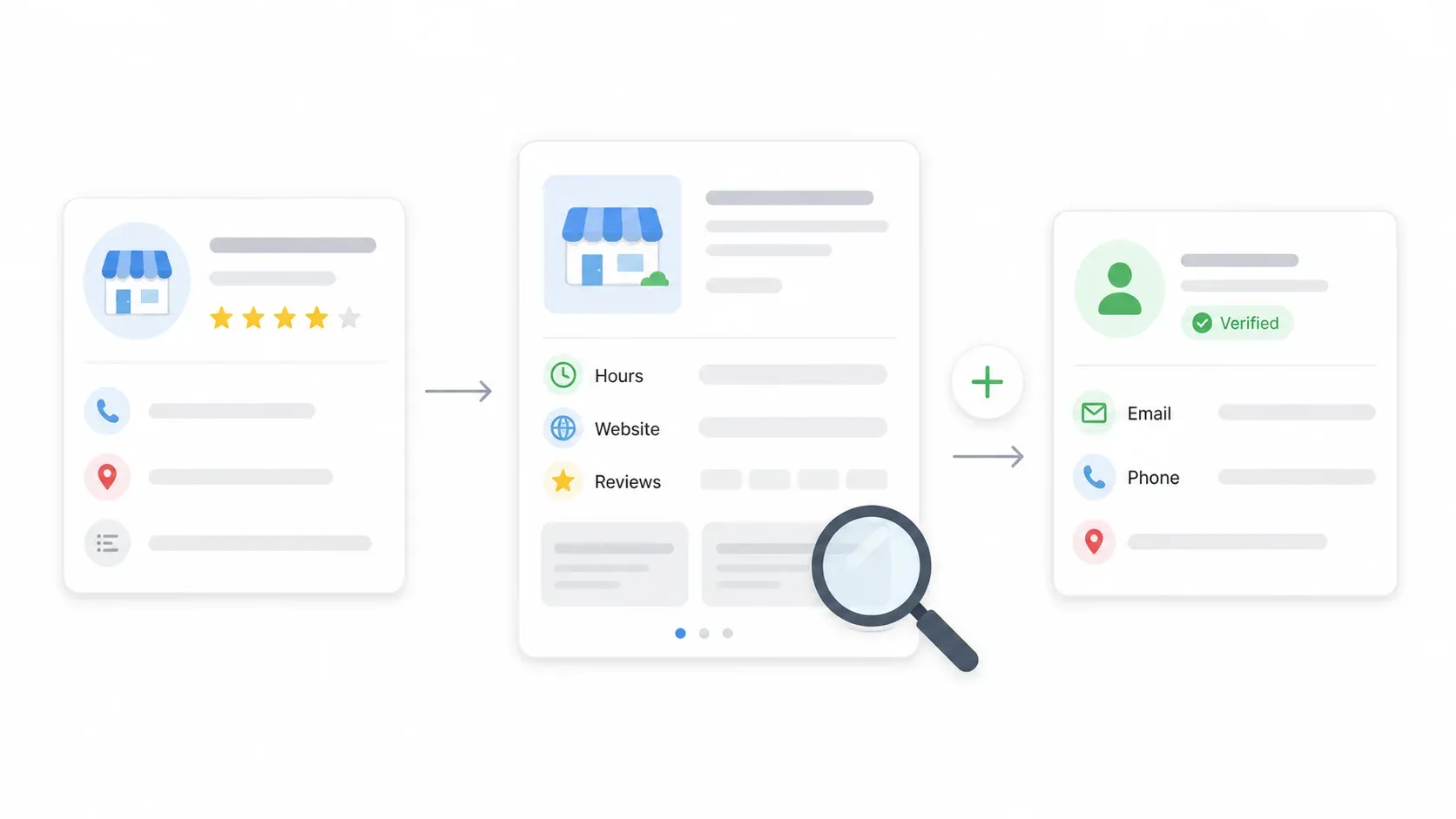
Die Suchergebnisse liefern die Grundlagen, aber die wirklich wertvollen Daten — Öffnungszeiten, vollständige Beschreibungen, Bewertungen, manchmal E-Mail — stehen auf der Detailseite jedes Unternehmens. Klicken Sie auf „Scrape Subpages“ und Thunderbit besucht jede Detailseite und zieht angereicherte Felder wie Öffnungszeiten, Beschreibung, Website-URL und alle dort sichtbaren Kontaktdaten hinein.
Das geht mit einem Klick. Kein separater Workflow, keine Konfiguration. Die angereicherten Daten werden direkt an Ihre bestehende Tabelle angehängt.
Schritt 5: Leads nach Excel, Google Sheets, Airtable oder Notion exportieren
Wenn Sie mit Ihren Daten zufrieden sind, klicken Sie auf Export. Thunderbit kann Ihre Leads direkt an folgende Ziele senden:
- Google Sheets (ideal für CRM-Vorbereitung und Zusammenarbeit)
- Airtable (leichte Pipeline-Tabellen)
- Notion (Recherche-Datenbanken)
- Excel / CSV (für CRM-Importe)
- JSON (für Entwickler-Übergabe)
Alle Exportoptionen sind kostenlos. Wenn Sie Leads in HubSpot oder Salesforce einspielen, ist der Export nach CSV oder Google Sheets meist der schnellste Weg.
Profi-Tipp: Suchen Sie lieber nach Kategorie + Stadt statt nach großen bundesweiten Suchbegriffen. „Notfall-Klempner Dallas TX“ liefert eine deutlich schärfere und praktischere Liste als „Klempner Texas“. Fügen Sie für die Nachverfolgung Spalten wie „Source URL“ und „Scraped At“ hinzu.
Methode 2: SuperPages mit einem visuellen Scraper scrapen (Beispiel Octoparse)
Visuelle Scraping-Tools wie Octoparse liegen irgendwo dazwischen: kein Code, aber mehr Setup und Konfiguration als bei Thunderbit. Octoparse hat sogar eine vorgefertigte SuperPages-Vorlage für einfachere Anwendungsfälle.
Schwierigkeit: Mittel
Benötigte Zeit: ~20–30 Minuten für Setup + Scrape
Was Sie brauchen: Octoparse-Konto (kostenloser Plan verfügbar, mit Einschränkungen)
Schritt 1: Neuen Task erstellen und SuperPages-URL laden
Öffnen Sie Octoparse, klicken Sie auf „New Task“ und fügen Sie Ihre SuperPages-Such-URL ein (z. B. „https://www.superpages.com/los-angeles-ca/plumbers“). Der integrierte Browser lädt die Seite.
Schritt 2: Felder automatisch erkennen lassen oder manuell auswählen
Klicken Sie auf „Auto-detect“ — Octoparse scannt die Seite und hebt Datenfelder hervor, die es für relevant hält. Prüfen Sie den Data-Preview-Bereich. Nach meiner Erfahrung erkennt die automatische Erkennung meist die meisten Felder, nimmt aber manchmal Extras mit (z. B. Anzeigenlabels oder Navigationstext) oder übersieht einzelne Felder. Wahrscheinlich müssen Sie einige Felder manuell hinzufügen oder entfernen.
Laut der Octoparse-Hilfe erstellt die Auto-Erkennung einen Basis-Workflow mit Pagination- und Extraktionsschritten, Nutzer müssen fehlende Daten aber oft manuell ergänzen.
Schritt 3: Workflow bauen und Pagination konfigurieren
Klicken Sie auf „Create workflow“. Octoparse erzeugt eine Schritt-für-Schritt-Aktionskette. Prüfen Sie den Pagination-Schritt genau — stellen Sie sicher, dass er korrekt auf „Next“ klickt oder weitere Ergebnisse lädt. Wenn Sie Daten von jeder Unternehmens-Detailseite möchten (Öffnungszeiten, E-Mail, Beschreibung), müssen Sie im Workflow einen Detailseiten-Loop oder eine Subpage-Aktion ergänzen. Das ist deutlich komplexer als Thunderbits Ein-Klick-Subpage-Ansatz.
Schritt 4: Task ausführen und Daten exportieren
Führen Sie den Task lokal aus (für kleinere Jobs) oder in Octoparse Cloud (für geplante oder größere Jobs — Cloud ist kostenpflichtig). Nach Abschluss können Sie als CSV, Excel oder JSON exportieren.
Wichtige Einschränkungen: Der Gratisplan von Octoparse umfasst 10 Tasks, bis zu 50.000 Zeilen/Monat und nur lokale Extraktion. Cloud-Runs, IP-Rotation, CAPTCHA-Lösung und einige Export-Integrationen erfordern einen kostenpflichtigen Plan (ab etwa 69 USD/Monat bei jährlicher Abrechnung).
Methode 3: SuperPages mit Python scrapen (Requests + BeautifulSoup)
Das ist der Weg für Entwickler. Volle Kontrolle, volle Verantwortung. Wenn Sie sich mit Python-Skripten wohlfühlen und diese pflegen können, haben Sie hier die größte Flexibilität — aber auch die meisten Stolpersteine.
Schwierigkeit: Fortgeschritten
Benötigte Zeit: ~30–60 Minuten (Setup + Code + Debugging)
Was Sie brauchen: Python 3.x, pip, requests, beautifulsoup4, lxml, ein Code-Editor
Schritt 1: Python-Umgebung einrichten
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandasSchritt 2: HTML-Struktur von SuperPages prüfen
Öffnen Sie die Entwicklerwerkzeuge (F12) auf einer SuperPages-Ergebnisseite. Identifizieren Sie CSS-Selektoren für Firmenname, Adresse, Telefon, Website und den Link zur Detailseite. Bedenken Sie: Die HTML-Struktur kann sich ohne Vorwarnung ändern, wodurch Ihre Selektoren jederzeit brechen können.
Schritt 3: Scraper für Listeneinträge schreiben und Pagination behandeln
Hier ein vereinfachtes Beispiel. Wichtiger Hinweis: In meinen Tests lieferte ein direkter Request an SuperPages eine Cloudflare-Seite mit „Attention Required“. Ein naives Requests-Skript kann in großem Maßstab scheitern — Sie brauchen möglicherweise Browser-Session-Kontext, Rate-Limiting, Retries oder autorisierte Alternativen.
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("Blocked. Slow down or switch to browser/cloud scraping.")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)Schritt 4: Detailseiten für Anreicherung scrapen
Schreiben Sie eine separate Funktion, die jede Detailseiten-URL besucht und Öffnungszeiten, E-Mail, Beschreibung und Bewertungen extrahiert. Das bedeutet: Rate Limits, Fehlerbehandlung und möglicherweise Proxys selbst verwalten — alles liegt bei Ihnen.
Schritt 5: Daten als CSV oder JSON speichern
Nutzen Sie dazu die Python-Module csv oder json. Außerdem müssen Sie Ihre eigene Logik für Deduplizierung, Bereinigung und Export schreiben.
Typische Fallstricke:
- SuperPages kann Requests mit Cloudflare oder ähnlichen Anti-Bot-Systemen blockieren (in meinen Tests bestätigt).
- Die Selektoren sind hier absichtlich breit gehalten, weil sich das Markup von SuperPages ändern kann.
- Gehen Sie nicht davon aus, dass Suchergebnisse E-Mail-Adressen enthalten. Das tun sie fast nie.
- Ein produktionsreifer Scraper braucht eine Prüfung der robots-/Nutzungsbedingungen, Rate-Limiting, Retry-/Backoff-Logik, strukturiertes Logging und Fehlererfassung.
Wenn Sie tiefer in Python-Scraping einsteigen möchten, sehen Sie sich unseren Leitfaden zum Web Scraping mit Python oder das BeautifulSoup-Tutorial an.
Von Rohdaten zu echten Leads: Die komplette Pipeline (Scrape → Bereinigen → Verifizieren → CRM)
Hier hören die meisten Scraping-Guides auf — und genau hier beginnt der eigentliche Wert. Scraping liefert Rohmaterial. Daraus eine nutzbare Lead-Liste zu machen, braucht noch ein paar weitere Schritte.
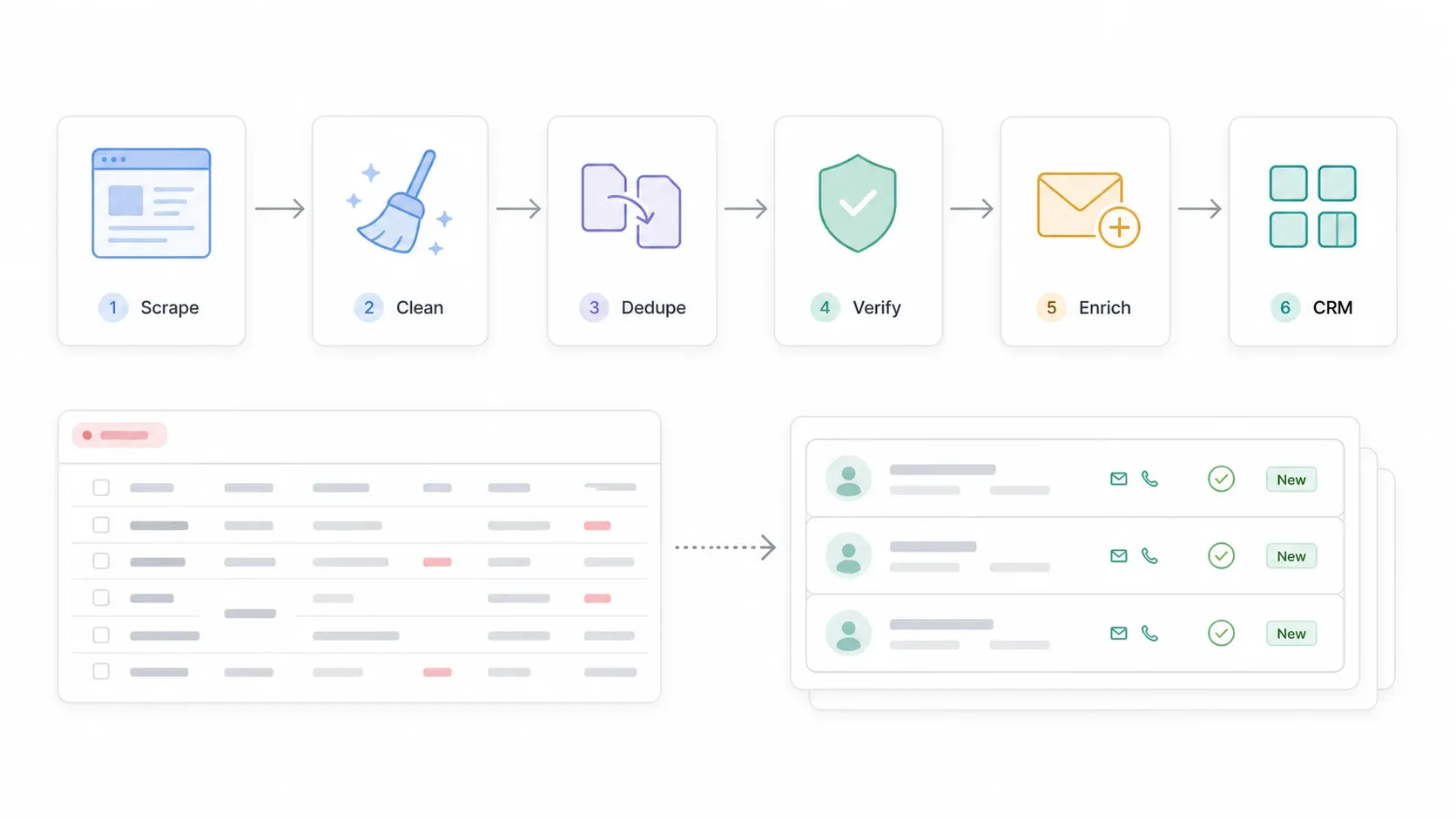
Die Pipeline sieht so aus:
SuperPages-Suche → Einträge scrapen → Detailseiten/Websites scrapen → nach Google Sheets oder CSV exportieren → Telefonnummern, Adressen und Kategorien bereinigen → deduplizieren → E-Mails/Telefonnummern verifizieren → fehlende Kontakte anreichern → ins CRM importieren → regelkonforme Ansprache
Deduplizierung: doppelte Einträge entfernen
SuperPages zeigt ein Unternehmen oft in mehreren Kategorien an. Wenn Sie in derselben Stadt nach „plumbers“ und „drain cleaning“ scrapen, erhalten Sie Überschneidungen.
- Primärer Dedupe-Key: normalisierte Telefonnummer + normalisierte Straßenadresse.
- Sekundär: Domain + Stadt.
- Fallback: Firmenname + PLZ (bei Franchises manuell prüfen).
In Google Sheets können Sie =UNIQUE(A:H) für exakte Zeilen verwenden oder eine Hilfsspalte wie =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")) anlegen, um nahezu doppelte Einträge zu erkennen. In Excel nutzen Sie Daten > Duplikate entfernen.
Datenbereinigung: Telefonnummern, Adressen und Format vereinheitlichen
- Telefonnummern im E.164-Format speichern (für die USA: +1 gefolgt von 10 Ziffern). Genau dieses Format erwarten die meisten CRMs und Dialer. Mit einem Field AI Prompt in Thunderbit können Sie das schon beim Scrapen automatisch formatieren lassen.
- Adressen normalisieren: Abkürzungen ausschreiben, fehlende PLZ ergänzen, bei Bedarf Straße/Stadt/Bundesland/PLZ in separate Spalten aufteilen.
- HTML-Reste, zusätzliche Leerzeichen und Tracking-Parameter aus URLs entfernen.
- Spalten wie
source_directory,source_urlundscraped_atfür die Nachvollziehbarkeit hinzufügen.
E-Mail- und Telefonverifikation vor der Ansprache
Versenden Sie nicht einfach Kaltmails an jede gescrapte Adresse. Verifizierung schützt Ihren Absender-Ruf und hält die Bounce-Rate niedrig.
- E-Mail-Verifizierung: ZeroBounce (ab ca. 39 USD für 2.000 Credits, plus 100 kostenlose monatliche Credits) oder Bouncer (8 USD für 1.000 Credits, Credits verfallen nie) sind solide Optionen.
- Telefonvalidierung: Twilio Lookup bietet Formatierung und Validierung kostenlos; Caller-ID kostet 0,01 USD pro Request.
- Thunderbits kostenlose Email Extractor- und Phone Number Extractor-Tools können Kontaktdaten holen, die auf den Listing-Seiten fehlen.
Anreicherung: Kontakte finden, wenn SuperPages keine E-Mail hat
Viele SuperPages-Einträge zeigen überhaupt keine E-Mail — besonders nicht in den Suchergebnissen. Dann gehen Sie so vor:
- Scrapen Sie die Kontakt-, About- oder Footer-Seiten der Unternehmenswebsite. Thunderbits Subpage Scraping oder Email Extractor kann das in großen Mengen übernehmen.
- Nutzen Sie Anreicherungstools wie Apollo, BetterContact, Icypeas oder Prospeo. Hinweis: Bei kleinen lokalen Unternehmen (z. B. eine Klempnerfirma mit zwei Personen oder ein einzelner Zahnarzt) liefern große B2B-Datenbanken oft keine Treffer. Website-first-Extraktion funktioniert hier meist besser.
- Kombinieren Sie mehrere Verzeichnisse. Scrapen Sie SuperPages, Yellow Pages und Google Maps für dieselbe Kategorie/Stadt und mergen Sie die Daten anschließend. Die Überschneidungen sorgen für vollständigere Datensätze.
Wenn Sie schon einmal versucht haben, eine lokale SMB-Liste durch Apollo laufen zu lassen und dabei fast nur leere Felder zurückbekommen haben, sind Sie nicht allein. Genau deshalb ist der Website-first-Ansatz für diese Zielgruppe so wichtig.
CRM-Import: Leads in HubSpot, Salesforce oder Google Sheets bringen
- HubSpot: Gehen Sie zu Data Management > Data Integration > Import data > Quick import (nur Kontakte). Laden Sie Ihre
.csv- oder.xlsx-Datei hoch. Der HubSpot-Importleitfaden erklärt das Feld-Mapping. - Salesforce: Nutzen Sie den Data Import Wizard. Bereiten Sie eine CSV vor, ordnen Sie Quellfelder den Salesforce-Feldern zu und starten Sie den Import.
- Google Sheets / Airtable / Notion: Thunderbit exportiert direkt in alle drei — ohne CSV-Umweg.
Tipp: Ordnen Sie Ihre gescrapten Spalten vor dem Import den CRM-Feldern zu. Ein paar Minuten Mapping sparen später Stunden manueller Nacharbeit.
SuperPages vs. andere lokale Verzeichnisse: Wo findet man die besten Leads?
SuperPages ist ein guter Startpunkt, aber nicht das einzige Verzeichnis, das sich lohnt zu scrapen. So schlägt es sich im Vergleich:
| Verzeichnis | Lead-Volumen | Verfügbare Datenfelder | Datenaktualität | Schwierigkeit beim Scraping | Am besten für |
|---|---|---|---|---|---|
| SuperPages | Groß (US-Fokus) | Name, Telefon, Adresse, Website, Kategorien, Bewertungen | Mittel | Mittel | Home Services, Handwerksbetriebe, SMBs |
| Yellow Pages | Groß (US-Fokus) | Ähnlich wie SuperPages | Mittel | Mittel | Allgemeine lokale Akquise |
| Google Maps | Sehr groß (global) | Name, Telefon, Adresse, Website, Bewertungen, Öffnungszeiten, Fotos | Hoch (vom Inhaber gepflegt) | Hoch (aggressive Anti-Bot-Maßnahmen) | Aktuellste lokale Daten |
| Yelp | Groß (US-Fokus) | Name, Telefon, Adresse, Bewertungen, Preisspanne | Hoch | Hoch | Restaurants, Handel, Dienstleistungsbetriebe |
| Manta | Mittel | Name, Telefon, Adresse, Umsatzschätzungen, Mitarbeiterzahl | Mittel | Niedrig | B2B-Prospecting (Umsatz-/Mitarbeiterdaten) |
| BBB | Mittel | Name, Telefon, Adresse, Akkreditierung, Beschwerden | Mittel | Niedrig | Vertrauenswürdige/geprüfte Unternehmen |
Quellen: SuperPages-Homepage, VLDB-SuperPages-Paper, Google-Places-API-Dokumentation, Yelp-Places-API-Dokumentation, Manta-Homepage, BBB-Leitfaden.
Thunderbit funktioniert bei all diesen Quellen — inklusive Instant Templates für beliebte Seiten wie Google Maps und SuperPages — sodass Sie denselben Workflow auf mehrere Quellen anwenden und Ihre Lead-Listen zusammenführen können. Meiner Erfahrung nach ist es oft am besten, zwei oder drei Verzeichnisse für dieselbe Kategorie/Stadt zu scrapen und anschließend zu deduplizieren. Die Überschneidungen schließen Lücken und ergeben ein vollständigeres Bild.
Weitere Infos zum Scraping anderer Verzeichnisse finden Sie in unseren Leitfäden zu , und .
Rechtliche und ethische Tipps für das Scraping von SuperPages-Leads
Ich bin kein Anwalt, und das hier ist keine Rechtsberatung — aber ich verbringe genug Zeit in diesem Bereich, um zu wissen, dass man sich mit Compliance schnell verbrennt, wenn man sie ignoriert. Hier die praktische Kurzfassung.
Öffentliche Geschäftsdaten vs. personenbezogene Daten
Firmen-Einträge — Firmenname, geschäftliche Telefonnummer, Geschäftsadresse, Firmenwebsite — gelten in der Regel als öffentliche kommerzielle Daten. Das ist etwas anderes als personenbezogene Verbraucherdaten im Sinne von DSGVO oder CCPA. Aber „öffentlich“ bedeutet nicht automatisch „regelfrei“. Prüfen Sie immer die Nutzungsbedingungen der Website.
Die Nutzungsbedingungen von SuperPages (Stand Juli 2019) enthalten eine Klausel „Data Mining Prohibited“: Nutzer dürfen Bots, Crawler, Spider oder ähnliche Werkzeuge nicht ohne vorherige Zustimmung von Thryv zur Datensammlung oder -extraktion einsetzen. Der Artikel beschreibt Methoden und Workflows, aber Sie sollten diese Bedingungen prüfen und bei Bedarf eine Genehmigung einholen, bevor Sie in großem Umfang scrapen.
Compliance bei der Ansprache: CAN-SPAM und TCPA-Grundlagen
Wenn Sie gescrapte E-Mail-Adressen für Cold Outreach verwenden, verlangt der FTC-Leitfaden zu CAN-SPAM unter anderem:
- keine falschen oder irreführenden Header
- keine täuschenden Betreffzeilen
- Kennzeichnung als Werbung, wenn erforderlich
- gültige physische Postanschrift
- klare Opt-out-Möglichkeit und schnelle Umsetzung des Abmeldewunsches
Wenn Sie gescrapte Telefonnummern für Kaltanrufe verwenden, prüfen Sie das National Do Not Call Registry und halten Sie sich an die TCPA-Regeln — vor allem bei automatisierten Anrufen, vorab aufgezeichneten Nachrichten und SMS. Die FTC kündigte 2024 Änderungen an, um den Schutz vor irreführendem B2B-Telemarketing und KI-gestützten Betrugsanrufen zu stärken.
Schnelle Compliance-Checkliste
- ✅ Nur öffentlich gelistete Geschäftsdaten scrapen
- ✅ SuperPages-Nutzungsbedingungen prüfen und bei Bedarf Erlaubnis einholen
- ✅ Kontakte vor der Ansprache verifizieren
- ✅ In E-Mails eine Abmeldemöglichkeit einbauen
- ✅ robots.txt und Rate Limits respektieren
- ✅ DNC- und E-Mail-Suppression-Listen pflegen
- ⚠️ Keine persönlichen/verbraucherbezogenen Daten scrapen
- ⚠️ Rohdaten nicht ohne rechtliche Prüfung weiterverkaufen
Wählen Sie Ihre Methode und starten Sie mit Ihrer Lead-Liste
SuperPages für Leads zu scrapen bedeutet nicht nur, Zeilen aus einer Webseite zu extrahieren. Der eigentliche Wert entsteht durch die gesamte Pipeline: scrapen, bereinigen, deduplizieren, verifizieren, anreichern, importieren und regelkonform ansprechen.
Hier die Kurzfassung:
- Thunderbit ist der schnellste Weg für Vertriebsteams, Agenturen und Nicht-Entwickler. Zwei Klicks zum Scrapen, ein Klick zur Anreicherung über Subpages, kostenloser Export nach Google Sheets, Airtable, Notion oder Excel. Testen Sie es kostenlos.
- Octoparse ist ein solides visuelles Workflow-Tool für halb-technische Nutzer, die mehr Konfigurationskontrolle möchten.
- Python gibt Entwicklern volle Flexibilität — bringt aber Wartungsaufwand, Anti-Blocking-Probleme und keine eingebaute Anreicherung mit.
- Und denken Sie daran: Derselbe Workflow gilt auch für Yellow Pages, Google Maps, Yelp, Manta und BBB. Wenn Sie mehrere Quellen scrapen, zusammenführen und deduplizieren, erhalten Sie die vollständigste lokale Lead-Liste.
Wenn Sie Thunderbit in Aktion sehen möchten, schauen Sie auf unserem vorbei oder werfen Sie einen Blick auf , um zu sehen, was zu Ihrem Team passt.
Jetzt verwandeln Sie diese Verzeichnisseiten in echte Pipeline — und mögen Ihre Telefonnummern immer korrekt formatiert und Ihre E-Mail-Adressen immer verifiziert sein.
FAQs
Ist es legal, SuperPages für Leads zu scrapen?
Das Scrapen öffentlich zugänglicher Verzeichnisdaten für B2B-Recherche ist weit verbreitet, aber die Nutzungsbedingungen von SuperPages verbieten Data Mining ohne vorherige Zustimmung von Thryv. Prüfen Sie immer die Website-Bedingungen, holen Sie bei Bedarf eine Genehmigung ein und halten Sie sich an Outreach-Regeln wie CAN-SPAM und TCPA. Dieser Artikel erklärt Methoden und Workflows zu Bildungszwecken — die regelkonforme Anwendung liegt in Ihrer Verantwortung.
Welche Daten kann ich von SuperPages bekommen?
Ein typischer Scrape liefert Firmenname, Telefon, Adresse, Website, Kategorie, Bewertungen, Öffnungszeiten und Beschreibungen. E-Mail-Adressen sind in den Suchergebnissen selten sichtbar — meist müssen Sie die Detailseite des Unternehmens oder die eigene Website des Unternehmens besuchen (über Subpage Scraping oder einen E-Mail-Extractor), um sie zu finden.
Kann ich SuperPages ohne Code scrapen?
Ja. Tools wie Thunderbit (KI-Chrome-Extension) und Octoparse (visueller Scraper) ermöglichen das Scrapen von SuperPages, ohne eine einzige Zeile Code zu schreiben. Thunderbit ist die schnellste Option — Extension installieren, SuperPages-Suche öffnen, auf „AI Suggest Fields“ klicken und dann auf „Scrape“.
Wie gehe ich beim Scrapen von SuperPages mit Pagination um?
Thunderbit übernimmt Pagination automatisch — es erkennt „Next“-Buttons oder Infinite Scroll und macht weiter. Octoparse verlangt, dass Sie im Workflow einen Pagination-Schritt konfigurieren. In Python müssen Sie die Seitenlogik manuell schreiben (Seitennummern erhöhen, letzte Seite erkennen).
Wie bekomme ich E-Mail-Adressen aus SuperPages-Einträgen?
Die meisten SuperPages-Einträge zeigen auf der Suchergebnisseite keine E-Mail-Adressen an. Nutzen Sie Thunderbits Subpage Scraping, um jede Detailseite zu besuchen, oder den kostenlosen Email Extractor auf der Website des Unternehmens. Für verbleibende Lücken können Sie Anreicherungstools wie Apollo, BetterContact oder Prospeo ausprobieren — bei kleinen lokalen Unternehmen funktioniert die Website-first-Extraktion aber oft besser als große B2B-Datenbanken.
Mehr erfahren