Eine GitHub-Suche nach „tiktok scraper“ liefert . Rund wurden seit über einem Jahr nicht mehr aktualisiert, und mindestens .
Wenn du schon einmal ein beliebtes TikTok-Scraper-Repo geklont, eine Stunde mit Abhängigkeiten gekämpft und dann null Ergebnis erhalten hast, bist du nicht allein. Das meistgestarzte TikTok-Scraper-Repo auf GitHub, drawrowfly/tiktok-scraper, hat immer noch über 5.000 Sterne. Im Issue-Tracker häufen sich jedoch Threads wie und — beide melden null Ausgabe. Ich verfolge bei Thunderbit seit Monaten den Zustand von TikTok-Scraping-Repos, und das Muster ist unübersehbar: Diese Tools brechen schnell, und die meisten werden nie wieder gefixt. Dieser Artikel ist der praktische Überlebensleitfaden, den ich mir gewünscht hätte, als ich diese Repos zum ersten Mal bewertet habe. Wir schauen uns an, was noch lebt, was tot ist, was du stattdessen tun solltest und wie du aufhörst, Stunden mit Code zu verschwenden, der schon nicht mehr funktioniert, bevor du ihn überhaupt gefunden hast.
Warum die meisten TikTok-Scraper auf GitHub kaputtgehen (und es immer wieder tun)
TikTok ist kein typisches Scraping-Ziel. Die Weboberfläche ändert sich ständig. Anders als bei einer statischen Produktseite im E-Commerce oder einem Verzeichnis wechselt TikTok Endpunkte, aktualisiert Anti-Bot-Fingerprinting, ändert die Render-Methode der Seite und führt neue Session-/Token-Anforderungen ein — manchmal schon wenige Wochen nach der letzten Änderung.
Open-Source-Maintainer arbeiten ehrenamtlich. Wenn TikTok ein Update ausrollt, das den Request-Pfad des Scrapers kaputtmacht, kann das Repo tagelang, wochenlang oder dauerhaft defekt bleiben. Das ist kein Vorwurf an die Maintainer — es ist ein strukturelles Missverhältnis zwischen einer schnelllebigen, gut finanzierten Plattform und unbezahlten Entwicklern mit regulären Jobs.
Selbst die besten TikTok-Scraper-Repos leben von einer Dauerbaustelle aus Reparieren und Flicken. Wenn du eines nutzen willst, brauchst du eine Strategie, um es zu bewerten, Fehler zu beheben und einen Plan B zu haben.
TikToks Anti-Bot-Abwehr: Wogegen du antrittst
- Rate Limiting. Die dokumentieren ausdrücklich Anfragekontingente selbst für freigegebene Integrationen. Unoffizielle Scraper stoßen viel schneller an diese Grenzen.
- Cookie- und Session-Gating. Moderne Repos wie verlangen ein
ms_token; ältere Repos wie zeigen in ihren Beispielentt_webid_v2; dokumentiertmsToken,ttwid,X-BogusundA_Bogus. TikTok prüft, ob deine Anfrage so aussieht, als käme sie aus einer echten Browsing-Session. - Browser-Fingerprinting. erklärt, warum Websites Header, Cookies, TLS-Signaturen und im Browser sichtbare Merkmale mit echtem Nutzerverkehr vergleichen. Ihre behandelt Canvas, WebGL, WebRTC, Schriftarten und Laufzeitsignale. Fingerprinting ist, als würde TikTok deinen Browser-Ausweis prüfen — wenn Browser, Cookies, Timing und Netzwerksignatur nicht zusammenpassen, wirkt die Anfrage gefälscht, noch bevor Inhalte zurückgegeben werden.
- Verhaltensbasierte Erkennung. zum TikTok-Scraping erwähnen häufig, dass frische Playwright-Sitzungen CAPTCHA-Abfragen auslösen. Community-Posts aus beschreiben zunehmend Erkennung, die auf Aktions-Timing und Interaktionsqualität achtet, nicht nur auf IP-Wiederverwendung.
- Verschlüsselte/signierte Request-Parameter. Evil0ctal dokumentiert
X-BogusundA_Bogus; ältere Community-Gists drehen sich um URL-Signierung und Token-Generierung. TikTok erwartet zunehmend, dass Anfragen mit denselben „Stempeln“ ankommen wie der eigene Browser-/App-Verkehr. - CAPTCHA- und Verifizierungsabläufe. Die Existenz von und bestätigt, dass CAPTCHA weiterhin Teil der Anti-Bot-Oberfläche ist.
Warum Open-Source-Maintainer nicht mithalten können
Der Lebenszyklus ist immer derselbe. Ein Entwickler baut einen TikTok-Scraper. Er geht auf GitHub viral. TikTok patcht etwas. Der Maintainer fixt es entweder oder zieht weiter.
Zwei Repos zeigen dieses Muster besonders deutlich:
- drawrowfly/tiktok-scraper hat immer noch 5.052 Sterne und 889 Forks, aber . Es ist das meistgestarzte TikTok-Scraper-Repo mit genau dieser Suchphrase auf GitHub und wirkt wie ein historisches Artefakt: hohe Sichtbarkeit, großes Vertrauen, keine aktuelle Pflege.
- davidteather/TikTok-Api zeigt . Der zeigt substanzielle Pflege im April 2025, Juli 2025, Oktober 2025 und April 2026 — einschließlich Fixes für Video-Crawling und neue Proxy-/Session-Steuerungen. Aber selbst dieses gesündere Projekt warnt offen davor, dass TikTok Anfragen blockiert und Nutzer Proxys, Playwright und eigene Session-Logik brauchen können.
Das Muster ist einfach:
- Ein veraltetes TikTok-Scraper-Repo ist wahrscheinlich tot.
- Ein aktives TikTok-Scraper-Repo ist wahrscheinlich immer noch fragil.
- Der einzige echte Unterschied ist, ob diesen Monat noch jemand da ist, um die neuen Brüche zu beheben.
Die 60-Sekunden-Repo-Vitals-Checkliste: So bewertest du jeden TikTok-Scraper auf GitHub
Bevor du irgendetwas klonst, geh diese Checkliste durch. Das dauert weniger als eine Minute und spart dir stundenlange Frustration.
| Signal | 🟢 Gesund | 🟡 Riskant | 🔴 Tot |
|---|---|---|---|
| Letzter relevanter Push | vor < 3 Monaten | vor 3–12 Monaten | vor 12+ Monaten |
| Anzahl offener Issues | Niedrig, aktuelle Issues werden beantwortet | Wachsende Liste mit etwas Aktivität der Maintainer | Viele unbeantwortete Berichte über „broken/blocked/not working“ |
| Aktuelle Nutzerbeschwerden | Meist Setup-Fragen | Mischung aus Setup- und Fehlerberichten | Wiederholte Meldungen wie „zero output“, „403“, „still working?“ |
| Aktuelles Auth-/Session-Modell | Session-/Cookie-Pfad dokumentiert | Token-lastig, aber dokumentiert | Verwendet alte Web-Endpunkte ohne aktuelle Auth-Hinweise |
| Installationsaufwand | Reproduzierbares, getestetes Setup | Einige manuelle Schritte | Alte Abhängigkeiten, keine modernen Setup-Hinweise |
| CI/Tests | Tests existieren und sind aktuell | Tests existieren, aber Abdeckung unklar | Keine Tests oder veraltete Actions |
| Passung des Datenumfangs | Passt zu deinem echten Anwendungsfall | Deckt nur einen Teil des Anwendungsfalls ab | Löst ein ganz anderes Problem |
So prüfst du jedes Signal in unter 60 Sekunden
- Datum des letzten Pushs: Schau in den Repo-Header auf GitHub. Wenn dort „last pushed 2 years ago“ steht, kannst du es vergessen.
- Offene Issues: Klicke auf den Issues-Tab. Überfliege die neuesten Titel. Suche nach
not working,403,blocked,captchaoderzero output. - Nutzerbeschwerden: Wenn die Top 5 offenen Issues alle Variationen von „this doesn't work anymore“ sind, hast du deine Antwort.
- Auth-/Session-Modell: Öffne die README. Achte auf aktuelle Hinweise wie
ms_token, Playwright-Setup oder Proxy-Anmerkungen. Wenn in der README 2023er-Endpunkte stehen, weitergehen. - Installationsoberfläche: Prüfe, ob es eine Requirements-Datei, Docker-Support oder klare Setup-Anweisungen gibt. Wenn in der README „npm install“ steht und die letzte getestete Node-Version 14 war, wird es schwierig.
- CI/Tests: Schau im Actions-Tab nach. Wenn Tests fehlschlagen oder fehlen, ist alles Rätselraten.
- Datenumfang: Beschreibt das Repo wirklich die Datentypen, die du brauchst (Profile, Videometadaten, Kommentare, Hashtags)? Viele Repos können nur Videos herunterladen, aber keine strukturierten Daten extrahieren.
Warnsignale, bei denen du sofort gehen solltest
- Das Repo ist archiviert.
- In der README steht „no longer maintained“.
- Der letzte Commit verweist auf eine TikTok-API-Version von vor mehr als 2 Jahren.
- Issues sind voller „doesn't work“-Meldungen und der Maintainer hat seit Monaten nicht reagiert.
- Das Repo hat viele Sterne, aber keine aktuellen Forks oder Pull Requests.
Profi-Tipp: Such im Issues-Tab nach is:issue is:open "not working" oder is:issue is:open "403". Wenn die Treffer dicht und aktuell sind, ist das Repo vermutlich kaputt.
Beliebte TikTok-Scraper-GitHub-Repos: Ein ehrlicher Status-Check (2026)
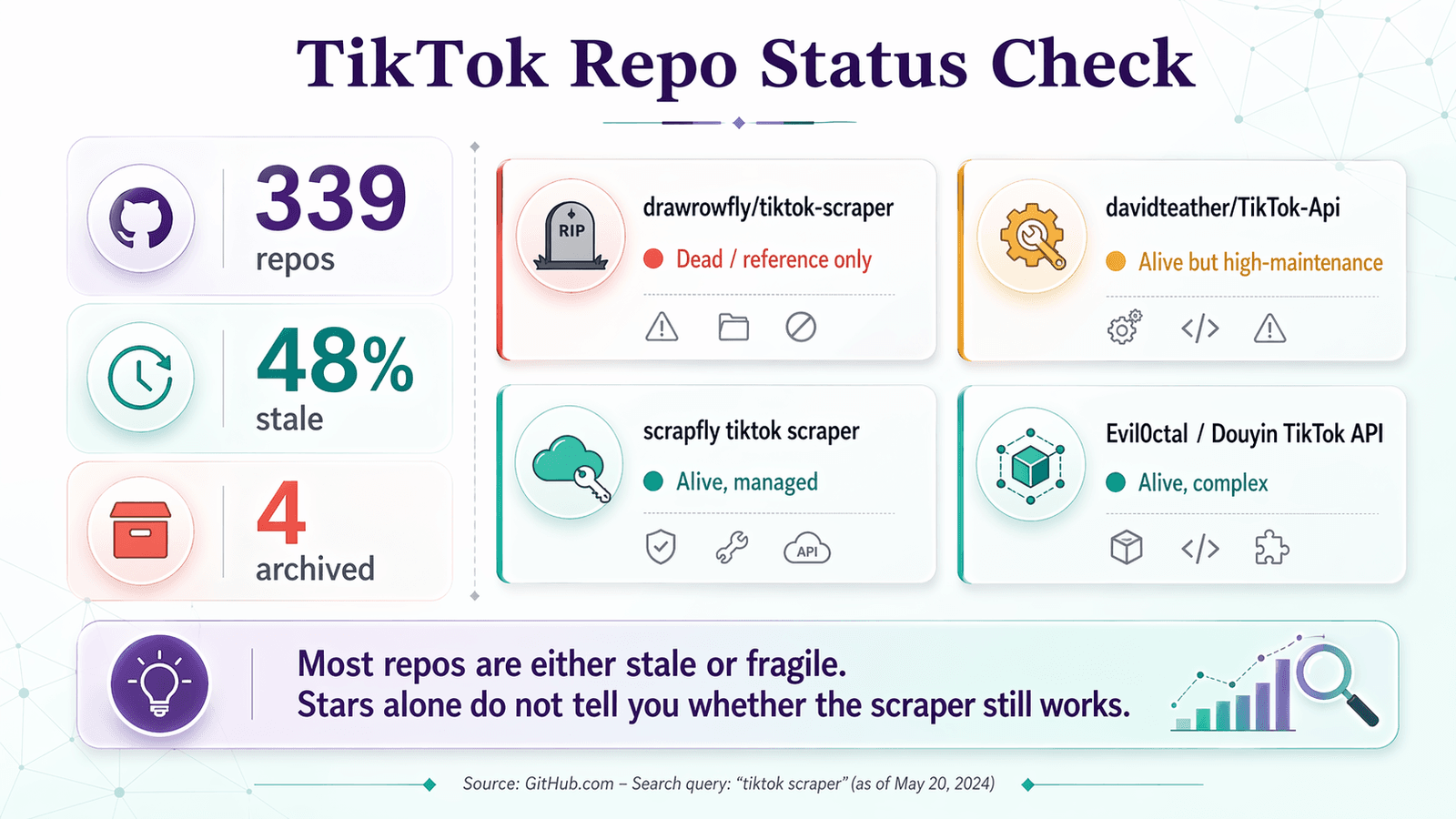
Hier ist die Repo-Vitals-Checkliste auf die Repos angewendet, auf die du bei einer GitHub-Suche nach „tiktok scraper“ tatsächlich stößt:
| Repo | Letzter Push | Sterne | Offene Issues | Urteil | Hinweis |
|---|---|---|---|---|---|
| drawrowfly/tiktok-scraper | 2023-05-19 | 5.052 | 58 | 🔴 Tot / nur als Referenz | Immer noch bekannt, aber für den produktiven Einsatz 2026 zu veraltet |
| davidteather/TikTok-Api | 2026-04-01 | 6.301 | 134 | 🟡 Lebt, aber wartungsintensiv | Stärkste OSS-Option; erwartet Playwright, Tokens und oft Proxys |
| scrapfly/scrapfly-scrapers/tiktok-scraper | 2026-04-21 | 938 (Parent) | ~0 (Monorepo) | 🟡 Lebt, aber kein reines OSS | Aktuell und nützlich, benötigt aber einen ScrapFly-API-Schlüssel |
| Evil0ctal/Douyin_TikTok_Download_API | 2025-10-12 | 17.397 | 135 | 🟡 Lebt, breit, komplex | Funktionsreiches Multi-Platform-Projekt; eher eine Power-User-Plattform |
| naseif/tiktok-scraper | 2024-07-26 | 107 | 13 | 🟡 Riskant | Kleineres Repo mit offenen Beschwerden zu User-Info- und Hashtag-Flows |
| loewehancara1rmyv/Tiktok-scraper | 2026-01-12 | 4 | 0 | 🔴 Zu neu, um vertrauenswürdig zu sein | Showcase-Repo, nicht von der Community bewährt |
drawrowfly/tiktok-scraper
Jahrelang war dieser TypeScript-Scraper/Downloader die Standardantwort auf „tiktok scraper github“ — für User-, Trend-, Hashtag- und Musik-Feeds. 2026 solltest du ihn am besten als historische Dokumentation betrachten. , und in der Issue-Warteschlange finden sich immer noch ungelöste Berichte wie und aus den Jahren 2023–2025. Wenn du diesen Artikel liest, weil du dieses Repo geklont hast und nichts herausbekommst, bist du in bester Gesellschaft.
davidteather/TikTok-Api
Die glaubwürdigste noch aktive Open-Source-Lösung für TikTok-Daten im Jahr 2026. Sie ist aktiv, hat und dokumentiert Playwright-Setup, asynchrone Nutzung, Token-Handling, Proxy-Support und Session-Recovery-Funktionen ausdrücklich. Aber das ist kein Tool zum „Klonen und Loslegen“. In der README steht selbst, dass EmptyResponseException meist bedeutet, dass TikTok die Anfrage blockiert, und die zeigt wiederkehrende Probleme mit ms_token, kaputter Kommentar-Extraktion, KeyError: 'ItemModule' und endpunktspezifischen Fehlern. Fazit: lebendig, nützlich, nur für Entwickler und wartungsintensiv.
Weitere bemerkenswerte Repos
- : Aktuell und technisch relevant, aber in der README wird ein
SCRAPFLY_KEYverlangt. Das ist ein Codebeispiel für eine verwaltete Scraping-Plattform, kein kostenloses Standalone-Tool. - : Deckt TikTok und Douyin ab, dokumentiert Signierungslogik (
X-Bogus,A_Bogus,msToken) und unterstützt Kommentare, Follower, Playlists und mehr. Technisch anspruchsvoll und zunehmend mit bezahlten API-Referenzen verknüpft. Der Issue-Tracker zeigt 2026 laufende Bugmeldungen zu Videolinks und User-Info-Endpunkten. Lebendig und funktionsreich, aber komplex. - : Kleiner, mit offenen Beschwerden. Riskant für den Produktionseinsatz.
- : 4 Sterne, 0 Issues, zu neu, um Vertrauen zu verdienen. Der Medium-Artikel, der es bewarb, tat dies ohne kritische Einordnung.
TikTok Official API vs. GitHub-Scraper vs. No-Code-Tools: Ein Entscheidungsrahmen

Die meisten Konkurrenzartikel ignorieren entweder TikToks offizielle Zugangswege oder springen direkt von „nimm GitHub“ zu „kauf unseren Service“. Hier ist ein neutraler Vergleich aller drei Wege:
| Faktor | TikTok Research API | GitHub-Scraper | No-Code-Tools (z. B. Thunderbit) |
|---|---|---|---|
| Zugangshürde | Akademischer/geschäftlicher Antrag erforderlich; ca. 4 Wochen bis zur Freigabe | Git-Klon + Setup | Browser-Erweiterung installieren |
| Datenumfang | Nur freigegebene Endpunkte (Konten, Videos, Kommentare, Shops) | Breit (Profile, Videos, Kommentare, Hashtags, Shops) | Sichtbare Seitendaten (Profile, Videos, Engagement, Hashtags) |
| Wartungsaufwand | Niedrig (offiziell, stabil) | Hoch (Repos brechen bei TikTok-Updates) | Keiner (KI passt sich Layout-Änderungen an) |
| Anti-Ban-Risiko | Keines (autorisiert) | Hoch | Niedrig (browserbasiert, imitiert echten Nutzer) |
| Kosten | Kostenlos (bei Freigabe) | Kostenlos (aber zeitintensiv) | Kostenlose Stufe verfügbar; Pläne ab 15 $/Monat |
| Programmierung erforderlich | Ja (Python/R) | Ja (Python/Node.js) | Nein |
| Am besten geeignet für | Forschende, Hochschulen, freigegebene Organisationen | Entwickler, die mit Wartung leben können | Marketing, Vertrieb, Operations, Nicht-Entwickler |
Wann die TikTok Research API sinnvoll ist
Die von TikTok ist der sauberste offizielle Weg, wenn du zugelassen bist. Berechtigte Forschende in den können sich bewerben, um öffentliche Inhalte und Kontodaten zu untersuchen. Zu den verfügbaren Datenkategorien gehören Konten, Follower/Following, gelikte Videos, angeheftete Videos, erneut gepostete Videos, Inhalte, Kommentare und Shops. Das gibt Felder wie video_description, view_count, like_count, comment_count, share_count sowie kommentarbezogene Felder wie text, reply_count und create_time frei.
Der Nachteil: Die Berechtigung ist auf akademische Einrichtungen und berechtigte gemeinnützige/individuelle Forschende in bestimmten Regionen beschränkt, plus . Wenn du ein Growth-Team oder eine Agentur bist und schnelle operative Daten brauchst, ist das nicht dein Weg.
TikTok bietet außerdem eine für Anzeigen- und Advertiser-Inhalte, die für Transparenzforschung nützlich ist, aber nicht für allgemeines Scraping.
Wann ein GitHub-Scraper noch sinnvoll ist
GitHub-Scraper machen für Entwickler weiterhin Sinn, die unoffiziellen Zugriff auf öffentliche Daten jenseits der Freigabeschranke der offiziellen API brauchen und bereit sind, den Stack zu pflegen. Dazu gehören Anwendungsfälle wie das Scrapen sichtbarer Profilraster, Hashtags, Kommentare, Playlists oder Videometadaten in einer eigenen Pipeline, in der Forken und Patchen akzeptabel ist.
Die ehrliche Einschränkung: Das ist kein einmaliges Setup. Selbst das verlässlichste Repo von 2026, , weist seine Nutzer weiterhin darauf hin, dass Playwright, Cookies/Tokens, Proxys und eigene Page-/Session-Factories nötig sein können.
Wann ein No-Code-Tool wie Thunderbit sinnvoll ist
Kein Entwickler? Oder Entwickler, aber müde vom ständigen Reparieren? Ein browserbasiertes KI-Tool ist der schnellste Weg zu strukturierten TikTok-Daten.
Wir haben als KI-Web-Scraper gebaut, der als Chrome-Erweiterung funktioniert. Auf TikTok liest es jede sichtbare Seite (Profil, Video, Hashtag, Suchergebnisse), schlägt mit „KI-Felder vorschlagen“ Spalten vor und lässt dich per Klick auf „Scrapen“ strukturierte Daten extrahieren. Die dokumentiert Felder wie Veröffentlichungsdatum, Videodauer, Likes, Shares, Speicherungen, Kommentare, Aufrufe und Hashtags. Die zeigt, wie du Vorschaubilder, URLs, Bildunterschriften, Creator-Handles und Engagement-Signale von Profilseiten sammelst. Die deckt Video-URL, Creator-Nutzername, Beschreibung, Veröffentlichungszeit, Aufrufe, Likes, Kommentare, Shares, Sound/Audio und Coverbild-URL ab.
Mit dem Scraping von Unterseiten kannst du jede Videoseite aus einer Profilauflistung aufrufen und die Tabelle mit Engagement-Metriken, Bildunterschriften und Hashtags anreichern — nützlich für Marketingteams, die Influencer-Datenbanken aufbauen, oder für Wettbewerbsanalysen von Inhalten.
Keine Wartung, kein Installations-Chaos, keine Anti-Ban-Konfiguration. Die KI passt sich Layout-Änderungen automatisch an. Der Export ist kostenlos nach Google Sheets, Excel, Airtable, Notion, CSV oder JSON.
Wenn du schon Stunden an kaputten GitHub-Repos verbrannt hast, ist das eine legitime Alternative — kein erzwungener Produkt-Pitch.
Installations-Triage: Die 5 häufigsten Setup-Fehler bei TikTok-Scrapern auf GitHub beheben
Installationsfehler sind das dritthäufigste Problem in TikTok-Scraping-Foren, und kein großer Leitfaden hilft dir wirklich beim Beheben. Hier ist, was schiefgeht.
Node.js-Versionskonflikte
Problem: Viele ältere TikTok-Scraper-Repos (vor allem drawrowfly/tiktok-scraper) wurden für Node.js 14–16 gebaut. Wenn du Node 20+ verwendest, kann npm install stillschweigend fehlschlagen oder inkompatible Binärdateien erzeugen.
Lösung: Nutze nvm (Node Version Manager), um die richtige Version zu installieren und zu wechseln:
1nvm install 16
2nvm use 16
3npm installWenn das Repo keine Node-Version angibt, prüfe das engines-Feld in package.json oder die CI-Konfiguration.
Python-Abhängigkeitsprobleme und Playwright-Setup
Problem: benötigt und Playwright mit bestimmten Browser-Binaries. Nutzer bekommen Fehler wie „browser not found“ oder Abhängigkeitskonflikte.
Lösung: Nutze immer eine virtuelle Umgebung und installiere die Playwright-Browser explizit:
1python -m venv .venv
2source .venv/bin/activate # Unter Windows: .venv\Scripts\activate
3pip install TikTokApi
4python -m playwright installWenn playwright install fehlschlägt, prüfe den Paketmanager deines Systems auf fehlende Systemabhängigkeiten (z. B. libnss3 unter Ubuntu).
Linux-/Ubuntu-Berechtigungsfehler
Problem: sudo pip install beschädigt die systemweite Python-Umgebung und führt zu Kettenreaktionen bei den Abhängigkeiten.
Lösung: Niemals sudo pip install verwenden. Erstelle immer zuerst eine virtuelle Umgebung:
1python3 -m venv .venv
2source .venv/bin/activate
3pip install -r requirements.txtSo sind die Abhängigkeiten des Scrapers von deinem System-Python getrennt.
Windows-Pfad- und Kodierungsprobleme
Problem: Die Windows-Eingabeaufforderung hat Kodierungsprobleme und Pfadlängenbeschränkungen, die Scraper-Installationen brechen, insbesondere wenn Playwright Browser-Binaries in tief verschachtelte Verzeichnisse lädt.
Lösung: Nutze WSL (Windows Subsystem for Linux) oder Git Bash statt CMD. Mit WSL bekommst du eine vollständige Linux-Umgebung in Windows:
1wsl --install
2# Dann ein WSL-Terminal öffnen und den Linux-Setup-Schritten folgenDer Docker-Kurzweg: Abhängigkeitsprobleme komplett überspringen
Problem: Alles oben Genannte.
Lösung: Wenn du mit Docker umgehen kannst, containerisiere die Scraper-Umgebung. Ein einfaches Dockerfile für einen Python-basierten TikTok-Scraper sieht so aus:
1FROM python:3.11-slim
2RUN apt-get update && apt-get install -y libnss3 libatk-bridge2.0-0 libdrm2 libxcomposite1 libxdamage1 libxrandr2 libgbm1 libasound2
3RUN pip install TikTokApi playwright && python -m playwright install --with-deps chromium
4WORKDIR /app
5COPY . .
6CMD ["python", "scrape.py"]Das garantiert eine reproduzierbare Umgebung, unabhängig vom Host-OS. Wenn der Scraper in Docker funktioniert, liegt jeder Fehler außerhalb von Docker an der Umgebung, nicht am Code.
Flowchart zur Fehlerbehebung:
- Läuft das eigene Beispiel des Repos erfolgreich? → Wenn nein, Runtime-Version prüfen.
- Runtime-Version korrekt? → Browser-/Playwright-Installation prüfen.
- Browser installiert? → Tokens/Cookies prüfen.
- Tokens/Cookies gültig? → Prüfen, ob TikTok die Session blockiert.
- Alles oben Genannte schlägt fehl? → Repo-Fehler annehmen, nicht Nutzerfehler. Tool wechseln.
Anti-Ban-Best Practices für TikTok-Scraping (ohne für Proxys zu zahlen)
Nutzer in Foren klagen immer wieder über Bans und Erkennung: „they get your accounts banned, which is an added expense“ und „without using Apify or expensive paid APIs.“ Hier sind kostenlose, praktische Workarounds, die kein kostenpflichtiges Proxy-Abo erfordern.

| Praxis | Schwierigkeit | Kosten | Wirksamkeit |
|---|---|---|---|
| Zufällige Anfrageverzögerungen (2–8 s Jitter) | Einfach | Kostenlos | Mittel |
| Session-/Cookie-Rotation | Mittel | Kostenlos | Mittel |
| Nur öffentliche Seiten ohne Login scrapen | Einfach | Kostenlos | Mittel |
robots.txt + Rate-Limit-Header respektieren | Einfach | Kostenlos | Basis |
| Fingerprinting im Headless-Browser zufällig variieren (Playwright) | Mittel | Kostenlos | Hoch |
| TikToks mobile API-Endpunkte nutzen (geringere Erkennung) | Schwer | Kostenlos | Hoch |
| Rotation von Residential Proxies | Mittel | 20–100 $/Monat | Hoch |
Kostenlose Techniken, die wirklich helfen
Zufällige Anfrageverzögerungen. Schicke Anfragen nicht in einer engen Schleife ab. Baue zwischen den Requests 2–8 Sekunden zufälligen Jitter ein. Das ist das Einfachste, was du tun kannst:
1import time, random
2time.sleep(random.uniform(2, 8))Session- und Cookie-Wiederverwendung. Erstelle nicht für jede Anfrage eine komplett neue Session. Verwende Cookies und Session-Status über einen Batch von Anfragen hinweg wieder und rotiere dann. Genau deshalb fragen moderne Repos nach ms_token, statt zustandsloses Scraping zu versprechen.
Nur ausgeloggte öffentliche Seiten scrapen. , dass es keine nutzerauthentifizierten Routen unterstützt und nur auf Daten funktioniert, die ausgeloggt sichtbar sind. Scraping ohne Login hat ein geringeres Erkennungsprofil als authentifizierte Sessions.
robots.txt respektieren. TikToks blockiert viele Agenten komplett und erlaubt für das allgemeine Crawling nur eine begrenzte Menge öffentlicher Pfade. Das ist kein Freifahrtschein für aggressives Scraping, aber das Befolgen reduziert die Chance auf sofortige IP-Blockierung.
Fortgeschrittene Techniken für höhere Erfolgsraten
Zufällige Variation des Browser-Fingerprints im Headless-Browser. Wenn du Playwright nutzt, variiere pro Session die Viewport-Größe, den User-Agent-String, die Zeitzone und die Locale. So wirkt dein Scraper jedes Mal wie ein anderer echter Nutzer statt wie derselbe Bot mit frischer IP.
TikToks mobile API-Endpunkte nutzen. Einige Community-Mitglieder berichten von geringerer Erkennung, wenn sie mobile Endpunkte statt des Web-Frontends ansteuern. Das ist schwerer umzusetzen und schlechter dokumentiert, aber für fortgeschrittene Nutzer eine reale Technik.
Wann du doch einen Proxy brauchst (und günstige Optionen)
In großem Maßstab reichen kostenlose Techniken nicht aus. Residential-Proxy-Rotation ist der Standard für TikTok-Scraping mit hohem Volumen. Ich spreche hier keine konkrete kostenpflichtige Proxy-Lösung aus, aber die allgemeine Empfehlung lautet: Meide Datacenter-Proxys (TikTok markiert sie aggressiv) und suche nach Residential- oder Mobile-Proxy-Pools mit Rotation pro Anfrage.
Browserbasierte Tools wie umgehen die Proxy-Frage dagegen weitgehend, weil sie in deiner eigenen Browsersitzung laufen und einen echten Nutzer imitieren. Das macht sie nicht unverwundbar bei großem Volumen, aber für typische Marketing- oder Research-Anwendungsfälle (Dutzende bis Hunderte Seiten, nicht Millionen) ist es ein deutlich einfacherer Weg.
Welche Daten bekommst du eigentlich? Echte Ausgabebeispiele von TikTok-Scrapern
Nutzer wollen vorab wissen, welche Daten sie tatsächlich bekommen — und die meisten Leitfäden lassen das komplett aus. Hier sind repräsentative Feldstrukturen, basierend auf der Quellen-Dokumentation.
Profildaten
| Nutzername | Anzeigename | Follower | Folgt | Gesamt-Likes | Bio | Verifiziert | Profil-URL |
|---|---|---|---|---|---|---|---|
| @examplecreator | Jane Doe | 1.240.000 | 312 | 48.700.000 | "Kochen + Comedy 🍳" | ✅ | tiktok.com/@examplecreator |
| @travelwithmark | Mark S. | 890.000 | 150 | 22.100.000 | "Reise-Vlogger 🌍" | ❌ | tiktok.com/@travelwithmark |
| @fitnessmaya | Maya L. | 2.100.000 | 88 | 91.300.000 | "Workouts & Wellness" | ✅ | tiktok.com/@fitnessmaya |
Verfügbar über: GitHub-Scraper (TikTok-Api, Evil0ctal), Research API, Thunderbit (aus sichtbaren Profilseiten).
Videometadaten
| Video-URL | Caption | Aufrufe | Likes | Kommentare | Shares | Musik | Hashtags | Veröffentlichungsdatum | Dauer |
|---|---|---|---|---|---|---|---|---|---|
| tiktok.com/@ex/video/123 | "Bester Pasta-Trick überhaupt 🍝" | 4.200.000 | 312.000 | 8.400 | 21.000 | "Italian Vibes – DJ Marco" | #pasta #cooking #hack | 2026-03-15 | 0:42 |
| tiktok.com/@ex/video/456 | "POV: Deine Katze bewertet dich" | 9.100.000 | 1.100.000 | 23.000 | 55.000 | "Original Sound" | #cat #pov #funny | 2026-04-01 | 0:18 |
| tiktok.com/@ex/video/789 | "Morgenroutine, nach der niemand gefragt hat" | 1.800.000 | 98.000 | 3.200 | 7.500 | "Chill Morning – LoFi" | #routine #morning | 2026-04-10 | 1:02 |
Verfügbar über: GitHub-Scraper (TikTok-Api, Evil0ctal), (Felder wie video_description, view_count, like_count, comment_count, share_count, music_id, hashtag_names, video_duration), Thunderbit ().
Kommentardaten
| Kommentierende Person | Kommentartext | Likes | Zeitstempel | Antworten |
|---|---|---|---|---|
| @user_abc | "Ich habe das ausprobiert, und es funktioniert wirklich 😂" | 1.200 | 2026-03-16T08:12:00Z | 14 |
| @chef_dan | "Beim nächsten Mal Knoblauch dazu, vertrau mir" | 890 | 2026-03-16T09:45:00Z | 7 |
| @randomfan99 | "Genau für solche Inhalte bin ich hier" | 340 | 2026-03-16T11:30:00Z | 2 |
Verfügbar über: GitHub-Scraper (TikTok-Api, Evil0ctal), (Felder wie text, like_count, reply_count, create_time), Thunderbit (aus sichtbaren Kommentarbereichen).
Hashtag- und Suchdaten
| Hashtag | Top-Video-URL | Gesamtaufrufe | Trendend |
|---|---|---|---|
| #pasta | tiktok.com/@ex/video/123 | 4.200.000 | Ja |
| #cooking | tiktok.com/@chef/video/321 | 11.000.000 | Ja |
| #hack | tiktok.com/@tips/video/654 | 2.900.000 | Nein |
Verfügbar über: GitHub-Scraper (je nach Repo unterschiedlich), Thunderbit ().
Hinweis: Kein einzelnes Repo garantiert alle Felder zu jeder Zeit. TikTok-Response-Strukturen ändern sich, und selbst die Maintainer weisen darauf hin. Betrachte diese Beispiele als repräsentativ, nicht als garantiert.
TikTok-Daten in 2 Klicks mit Thunderbit scrapen (Schritt für Schritt)
Genug vom Reparieren und Flicken? Hier ist der No-Code-Weg — die Notausstiegslösung für alle, die mit GitHub-Repos versucht und gescheitert sind.
- Installiere die .
- Öffne die TikTok-Seite, die du scrapen willst — ein Profil, eine Suchergebnisseite, eine Hashtag-Seite oder ein einzelnes Video.
- Klicke auf „KI-Felder vorschlagen“. Thunderbits KI liest die Seite und schlägt Spalten vor: Nutzername, Follower, Videocaption, Likes, Hashtags usw.
- Passe die Felder bei Bedarf an und klicke dann auf „Scrapen“. Die Daten erscheinen in einer strukturierten Tabelle.
- Nutze das Scraping von Unterseiten, um die Daten anzureichern. Öffne jedes Video aus einer Profilauflistung und ziehe zusätzliche Felder: vollständige Caption, Musikdetails, Kommentaranzahl, Share-Anzahl.
- Exportiere nach Google Sheets, Excel, Airtable oder Notion — komplett kostenlos.
Keine Wartung, keine Installations-Triage, keine Anti-Ban-Konfiguration. Die KI passt sich TikToks Layout-Änderungen automatisch an.
TikTok-Daten mit Subpage-Scraping anreichern
Nachdem du eine Videoliste von einer Profil- oder Hashtag-Seite gescrapt hast, klicke auf „Unterseiten scrapen“, damit die KI jede Videoseite besucht und zusätzliche Felder holt. Das ist besonders nützlich für Marketingteams, die Influencer-Datenbanken aufbauen oder Wettbewerbs-Content-Audits durchführen — du bekommst eine vollständige Tabelle mit Engagement-Daten auf Videoebene, ohne dich manuell durch Dutzende Seiten zu klicken.
Exportieren und mit deinen TikTok-Daten arbeiten
Thunderbit exportiert kostenlos nach Google Sheets, Excel, Airtable, Notion, CSV oder JSON. Häufige Anwendungsfälle:
- Daten in ein Tabellenblatt für Engagement-Analysen laden.
- An Airtable senden für ein CRM-artiges Influencer-Tracking.
- In Notion für Teamzusammenarbeit bei der Content-Recherche verwenden.
Für einen tieferen Einblick, wie Thunderbit Webdaten extrahiert, wirf einen Blick in unseren oder schau dir Tutorials auf dem an.
Legal bleiben: TikTok-Nutzungsbedingungen und Scraping-Compliance
TikToks Rechtsposition ist klar. Der sagt, dass die Nutzungsbedingungen automatisierte Skripte verbieten, die Informationen sammeln oder auf unbefugte Weise mit dem Dienst interagieren, und erwähnt ausdrücklich das Umgehen von Zugriffsbeschränkungen. Auch TikToks verbieten täuschende Versuche, über automatisierte Skripte oder Web-Crawling Informationen zu erhalten.
Praktische Hinweise:
- Beschränke dich auf öffentlich verfügbare Daten. Scrape keine privaten oder login-geschützten Inhalte.
- Beachte Rate Limits. Überlaste TikToks Server nicht.
- Halte Datenschutzgesetze ein. DSGVO und CCPA gelten weiterhin, wenn du personenbezogene Daten sammelst, speicherst oder analysierst.
- Nutze die Research API, wenn du berechtigt bist. Das ist aus Compliance-Sicht der sicherste Weg.
- Das ist keine Rechtsberatung. Sprich für deinen konkreten Fall mit einer Fachperson.
Mehr zur rechtlichen Lage findest du in unserem Leitfaden zu den .
Was tun, wenn dein TikTok-Scraper-GitHub-Repo stirbt
Die Kurzfassung:
- Führe immer die 60-Sekunden-Repo-Vitals-Checkliste aus, bevor du irgendeinen TikTok-Scraper von GitHub klonst. Die meisten Repos sind ohnehin schon tot.
- Verstehe deine Optionen. Offizielle API, GitHub-Scraper und No-Code-Tools bedienen unterschiedliche Nutzer und Anwendungsfälle.
- Wenn du den GitHub-Weg gehst, plane Zeit für Installationsprobleme und Anti-Ban-Konfiguration ein. Rechne mit laufender Wartung.
- Wisse vorher, welche Daten du wirklich bekommst. Prüfe die Ausgabefelder, nicht nur die Sternezahl.
- Wenn du kein Entwickler bist (oder genug von kaputten Repos hast), probier ein No-Code-Tool wie — zwei Klicks, strukturierte Daten, kostenloser Export.
Die TikTok-Daten, die du brauchst, sind zugänglich. Die Frage ist nur, ob du deine Zeit mit der Wartung eines Scrapers verbringen willst oder die Daten tatsächlich nutzen möchtest. Wähle den Ansatz, der zu deinem Skill-Level und deinem Anwendungsfall passt, und lass nicht zu, dass ein totes GitHub-Repo dir noch einen weiteren Nachmittag stiehlt.
FAQs
Gibt es 2026 noch TikTok-Scraper auf GitHub, die funktionieren?
Ja, aber die Liste ist kurz. ist die glaubwürdigste Open-Source-Option mit aktiver Pflege bis April 2026. lebt ebenfalls noch, ist aber komplexer. Das Repo mit den meisten Sternen, drawrowfly/tiktok-scraper, wurde seit Mai 2023 nicht mehr aktualisiert und ist praktisch tot. Führe immer die Repo-Vitals-Checkliste aus, bevor du Zeit in ein Repo investierst.
Ist das Scrapen von TikTok legal?
Die Nutzungsbedingungen von TikTok verbieten automatisiertes Scraping ausdrücklich. Öffentlich sichtbare Daten bewegen sich in einer rechtlichen Grauzone, die je nach Jurisdiktion unterschiedlich ist. Der sicherste Weg ist die offizielle für berechtigte Forschende. Wenn du öffentliche Daten scrapen willst, beschränke dich auf öffentlich zugängliche Inhalte, beachte Rate Limits und halte dich an DSGVO/CCPA. Das ist keine Rechtsberatung — wende dich für deinen Fall an eine Fachperson.
Kann ich TikTok ohne Programmieren scrapen?
Ja. Browserbasierte KI-Tools wie ermöglichen dir, strukturierte TikTok-Daten (Profile, Videometadaten, Hashtags, Engagement-Metriken) zu extrahieren, ohne eine einzige Zeile Code zu schreiben. Auch die TikTok Research API erfordert für zugelassene Antragsteller nur minimale Programmierung. Für Nicht-Entwickler sind No-Code-Tools der schnellste und zuverlässigsten Weg.
Welche Daten kann ich aus einem TikTok-Scraper bekommen?
Häufige Datentypen sind Profilinformationen (Nutzername, Follower, Bio, Verifizierungsstatus), Videometadaten (Caption, Aufrufe, Likes, Kommentare, Shares, Musik, Hashtags, Dauer, Veröffentlichungsdatum), Kommentare (Text, Likes, Zeitstempel, Antworten) sowie Hashtag-/Suchdaten (Top-Videos, Gesamtaufrufe, Trendstatus). Die genauen Felder hängen von Tool und Methode ab — siehe den Abschnitt mit den Ausgabebeispielen oben.
Warum wird mein TikTok-Scraper ständig blockiert?
TikTok nutzt mehrere Ebenen der Anti-Bot-Abwehr: Rate Limiting, Cookie-/Session-Gating, Browser-Fingerprinting, verhaltensbasierte Erkennung, verschlüsselte Request-Parameter und CAPTCHA-Abläufe. Häufige Ursachen für Blockierungen sind zu schnelle Anfragen, eine frische/neue Session für jede Anfrage, ein Headless-Browser mit Standard-Fingerprints oder Datacenter-Proxys. Siehe den Abschnitt mit den Anti-Ban-Best-Practices oben für kostenlose und kostenpflichtige Workarounds.