

Ist Web-Scraping illegal? Diese eine Frage höre ich Woche für Woche von Gründern, Marketingleuten und Daten-Nerds – und sie ist Gold wert.
Mittlerweile stammen 51 % des gesamten Internetverkehrs von Bots – automatisierter Traffic hat den menschlichen damit erstmals überholt –, und ein guter Teil davon entfällt auf Web-Scraping für Business Intelligence, Vertrieb und KI-Training. Kein Wunder also, dass alle wissen wollen, wo die rechtlichen Linien verlaufen.
Mal stolperst du über eine Schlagzeile zu einem Gerichtsurteil, wonach das Scrapen öffentlicher Daten fair und zulässig sei. Tags darauf warnen Regulierungsbehörden vor „rechtswidriger“ Datensammlung aus sozialen Medien. Das stiftet Verwirrung – sogar bei Leuten wie mir, die ihre Tage damit verbringen, bei Thunderbit KI-Web-Scraping-Tools zu bauen.
Also: Ist Web-Scraping illegal? Mit einem schlichten Ja oder Nein ist es nicht getan. Es kommt darauf an, was du scrapest, woher die Daten stammen, wie du sie verwendest und was das Gesetz in deinem Land dazu sagt.
In diesem Deep Dive lege ich die Rechtslage offen, räume mit gängigen Mythen auf und gebe dir handfeste Tipps an die Hand – samt ein paar Geschichten aus der Praxis –, damit du rechtssicher unterwegs bist, ob als Solo-Gründer oder als Teil eines Data-Teams in einem Fortune-500-Konzern.
Web-Scraping und das Recht: Gibt es eine klare Grenze?
Falls du auf eine knackige Ein-Satz-Antwort hoffst, muss ich dich enttäuschen: Das Gesetz hat fürs Web-Scraping keine glasklare Linie gezogen.
Stattdessen liegt ein Flickenteppich aus sich überlappenden Regeln vor – Datenhoheit, Datenschutz, geistiges Eigentum, Anti-Hacking-Gesetze und die berüchtigten Nutzungsbedingungen (Terms of Service, ToS). All das kann hineinspielen, und die Antwort hängt oft am konkreten Einzelfall (multilogin.com).
Hier die drei großen rechtlichen Felder:
- Datenhoheit: Grundsätzlich genießen Fakten und öffentliche Informationen (etwa Preise oder Telefonnummern) keinen Urheberrechtsschutz. Kreative Inhalte (Artikel, Bilder) und proprietäre Datenbanken können dagegen geschützt sein – vor allem in der EU mit ihren „Datenbankrechten“ (cliffordchance.com).
- Datenschutz: Moderne Datenschutzgesetze (etwa die DSGVO in Europa oder das PIPL in China) behandeln personenbezogene Daten als reguliertes Gut – selbst wenn sie öffentlich gepostet wurden. Namen, E-Mails oder Social-Media-Profile ohne Rechtsgrundlage zu scrapen, kann schnell brenzlig werden (ico.org.uk).
- Verträge (Nutzungsbedingungen): Viele Websites untersagen Scraping ausdrücklich in ihren ToS. ToS sind zwar keine Gesetze, doch Gerichte können sie als verbindliche Verträge werten. Verstöße können Klagen nach sich ziehen und in manchen Fällen sogar Anti-Hacking-Vorschriften auslösen, wenn technische Schutzmaßnahmen umgangen werden (cliffordchance.com).
Also: Ist Web-Scraping illegal? Mal ja, mal nein, und ehrlich am häufigsten: „kommt darauf an“. Der Teufel steckt im Detail.
Rechtliche Perspektiven im Vergleich: USA, EU, UK, China
Eine kurze Tabelle zeigt, wie wichtige Regionen Web-Scraping einordnen:
| Region | Scraping öffentlicher Daten | Scraping personenbezogener/private Daten | Durchsetzung & wichtige Punkte |
|---|---|---|---|
| USA | Für öffentliche Daten in der Regel erlaubt (siehe hiQ v. LinkedIn). Verstöße gegen ToS können zu Zivilklagen führen. | Eingeschränkt/illegal, wenn du Logins umgehst oder personenbezogene Daten missbrauchst. Landesgesetze (etwa CCPA) können greifen. | Unterlassungsschreiben, IP-Blocking, Klagen. Das CFAA gilt, wenn technische Hürden umgangen werden. |
| EU | Unter bestimmten Bedingungen für nicht personenbezogene, öffentliche Daten erlaubt. Datenbankrechte können greifen. Der EU AI Act (2026) bringt Transparenzanforderungen für KI-Trainingsdaten. | Unter der DSGVO stark reguliert – selbst öffentliche personenbezogene Daten brauchen eine Rechtsgrundlage. | Datenschutzbehörden können wegen Datenschutzverstößen Bußgelder verhängen. Auch Urheber- und Datenbankrechte werden durchgesetzt. Der EU AI Act verbietet das Scrapen von Gesichtsaufnahmen für KI. |
| UK | Ähnlich wie in der EU. Öffentliche, nicht personenbezogene Daten können gescrapt werden, doch Datenrechte und Verträge müssen beachtet werden. | Streng bei personenbezogenen Daten – es gilt die UK-GDPR. Der Computer Misuse Act stellt unbefugten Zugriff unter Strafe. | Das ICO kann bei Datenschutzverstößen sanktionieren. Gerichte können ToS durchsetzen. |
| China | Stark reguliert. Öffentliche, nicht personenbezogene Daten dürfen möglicherweise für den internen Gebrauch gescrapt werden, aber das Umfeld ist vorsichtig. | Stark eingeschränkt – das PIPL verlangt für personenbezogene Daten eine Einwilligung. Gesetze gegen unlauteren Wettbewerb gelten ebenfalls. | Strafverfahren bei Scraping in großem Maßstab. Gerichte nutzen das Wettbewerbsrecht, um unbefugtes Scraping zu stoppen. |
Ist Web-Scraping illegal? Wichtige rechtliche Faktoren
Was entscheidet nun wirklich darüber, ob dein Scraping-Projekt legal oder riskant ist? Das sind die zentralen Faktoren:
- Öffentliche vs. private Daten: Daten zu scrapen, die jeder im offenen Web sieht, ist meist die sicherere Variante. Alles hinter Login, Paywall oder einer technischen Hürde abzugreifen? Das ist mit hoher Wahrscheinlichkeit illegal (thunderbit.com).
- Art der Daten: Personenbezogene Daten (Namen, E-Mails, Profile) bringen Datenschutzgesetze ins Spiel. Urheberrechtlich geschützte Inhalte (Artikel, Bilder) darfst du nicht einfach vollständig kopieren. Reine Fakten (Preise, Wetter) sind in der Regel unkritisch (oxylabs.io).
- Geplanter Zweck: Interne Analysen oder Forschung werden meist milder beurteilt als das erneute Veröffentlichen oder der Verkauf gescrapter Daten. Gescrapte Daten direkt als Konkurrenz gegen die Quelle einzusetzen? Das ist eine Klage mit Ansage (thunderbit.com).
- Einhaltung der Website-Regeln: Wirf immer einen Blick auf robots.txt und ToS. robots.txt bindet rechtlich nicht, aber es gehört sich, sie zu respektieren. ToS-Verstöße können Zivilklagen oder Schlimmeres bedeuten (promptcloud.com).
- Technische Maßnahmen: Worauf es ankommt: in menschlichem Tempo scrapen und keine Sicherheitsvorkehrungen aushebeln. Einen Server zu überlasten oder CAPTCHAs zu umgehen, kann rasch in Richtung Hacking kippen (cliffordchance.com).
Was sich 2024–2026 geändert hat: Wichtige Urteile und Regeln
Die Rechtslage rund ums Web-Scraping hat sich seit 2023 spürbar verschoben. Das sind die Entwicklungen, die jeder Scraper auf dem Schirm haben sollte:
Wichtige Gerichtsentscheidungen
-
Meta gegen Bright Data (2024): Ein US-Bundesgericht entschied, dass Metas Nutzungsbedingungen das Scrapen öffentlicher Daten durch nicht eingeloggte Nutzer nicht untersagen. Der Richter stellte fest: „ein Besucher gilt nicht als ‚Nutzer‘, solange er kein Konto hat“. Kurz darauf zog Meta die übrigen Ansprüche zurück. Ein Meilenstein fürs Scraping öffentlicher Daten.
-
X Corp gegen Bright Data (2024): Twitter (heute X) verlor eine ähnliche Klage und untermauerte damit denselben Grundsatz: Das Scrapen öffentlich zugänglicher Daten ohne Login verstößt nicht gegen die ToS, weil der Scraper diesen Bedingungen nie zugestimmt hat.
-
Reddit gegen Perplexity AI (Oktober 2025): Reddit verklagte Perplexity AI und mehrere Scraping-Anbieter und stützte sich dabei auf den DMCA sowie auf die Umgehung von Anti-Bot-Systemen. Das offenbart eine neue Strategie: Plattformen greifen zunehmend zu Urheberrecht und Anti-Umgehungs-Ansprüchen statt zum CFAA.
-
NYT gegen OpenAI (März 2025): Ein Bundesrichter ließ die Urheberrechtsklage der New York Times gegen OpenAI zu und wies OpenAIs Antrag auf Abweisung zurück. Das könnte einen wichtigen Präzedenzfall dafür setzen, ob das Scrapen von Inhalten zum Training von KI-Modellen als „Fair Use“ durchgeht.
-
Anthropic-Vergleich (September 2025): Anthropic willigte ein, 1,5 Milliarden US-Dollar zu zahlen, um eine US-Urheberrechts-Sammelklage zur Nutzung geschützter Texte fürs Training seines KI-Modells beizulegen – ein deutliches Signal, dass die Kosten des Scrapings für KI sehr real sind.
Der große Trend: Vom CFAA hin zu Vertrags- und Urheberrecht
Das Muster ist eindeutig: Das CFAA (Computer Fraud and Abuse Act) verliert als Waffe gegen Scraper öffentlicher Daten an Schlagkraft. Unternehmen, die das CFAA gegen das Scrapen öffentlicher Daten ins Feld führen wollten – Meta, X, LinkedIn –, sind weitgehend gescheitert. Stattdessen verschiebt sich das juristische Schlachtfeld auf:
- Vertragsrecht (ToS-Verstöße – wobei Gerichte feststellen, dass Nicht-Nutzer nicht an ToS gebunden sind)
- Urheberrechtsansprüche (vor allem bei KI-Trainingsdaten)
- Anti-Umgehungs-Vorschriften (DMCA Section 1201)
Für Scraper heißt das: Das rechtliche Risiko ist nicht weg – es hat sich nur verlagert.
Regulatorische Änderungen
- CCPA-Updates 2026: Die überarbeiteten CCPA-Regeln Kaliforniens traten am 1. Januar 2026 in Kraft und bringen neue Vorgaben für automatisierte Entscheidungssysteme (ADMT), Risikobewertungen und Pflichten für Datenbroker.
- Neue US-Datenschutzgesetze der Bundesstaaten: Indiana, Kentucky und Rhode Island haben umfassende Datenschutzgesetze beschlossen, die 2026 in Kraft traten.
- EU AI Act: Die vollständige Durchsetzung startet am 2. August 2026 – mit der Pflicht für KI-Entwickler, Trainingsdatenquellen offenzulegen, Copyright-Opt-outs zu respektieren und das Scrapen von Gesichtsaufnahmen für KI-Systeme zu unterlassen.
- AI Accountability for Publishers Act (Februar 2026): Ein US-Gesetzentwurf, der KI-Unternehmen verpflichten würde, vor dem Scrapen von Inhalten die Erlaubnis der Publisher einzuholen und dafür zu zahlen.
Scraping-Richtlinien großer Plattformen: Was du wissen musst
Nicht jede Website verfährt gleich mit Scraping. Hier ein Überblick pro Plattform: was die größten Anbieter erlauben, was sie blockieren und was Gerichte dazu gesagt haben:
| Plattform | ToS zum Scraping | Technische Abwehrmaßnahmen | Rechtliche Durchsetzung | Was praktisch sicher ist |
|---|---|---|---|---|
| Google (Suche & Maps) | Verbietet automatisierten Zugriff in den ToS. Die Maps-Plattform hat eine ausdrückliche „No Scraping“-Klausel. | SearchGuard-JS-Challenges, CAPTCHAs, Rate-Limiting. Die robots.txt wurde 2025 aktualisiert, um KI-Crawler zu blockieren. | Klagte im Dezember 2025 mit dem DMCA gegen Scraper. Blockiert aktiv KI-Crawler (Anthropic, Meta, OpenAI). | Öffentliche Google-Maps-Geschäftsdaten zu scrapen ist rechtlich vertretbar (hiQ-Präzedenzfall), aber mit technischen Sperren ist zu rechnen. Wenn möglich, offizielle APIs nutzen. |
| Amazon | Verbietet in den Nutzungsbedingungen ausdrücklich jedes Scraping („no robot, spider, scraper, or other automated means“). | Aggressive Bot-Erkennung, CAPTCHA, IP-Blocking. robots.txt blockiert alle Bots außer Googlebot/Bingbot. Blockiert seit 2025 ausdrücklich KI-Crawler. | Verklagte Perplexity AI im November 2025. Versendet regelmäßig Unterlassungsschreiben. Aktualisierte die BSA im März 2026 um Regeln für KI-Agenten. | Öffentliche Produktdaten (Preise, Listings) sind nach US-Recht sachlich und scrapebar, aber Amazon wehrt sich massiv. Requests drosseln und keine personenbezogenen Daten erfassen. |
| Verbietet Scraping in den ToS; für den Zugriff auf Dienste ist die Zustimmung des Nutzers erforderlich. | Login-Schranken für die meisten Profildaten, Anti-Bot-Erkennung, Rate-Limiting. | Der hiQ-Fall bestätigte, dass das Scraping öffentlicher Profile kein CFAA-Verstoß ist, aber LinkedIn gewann bei Vertrags- und Wettbewerbsansprüchen, als Fake-Konten verwendet wurden. | Öffentliche Profile (ohne Login sichtbar) sind rechtlich vertretbar zu scrapen. Niemals Fake-Konten anlegen oder eingeloggte Daten scrapen. | |
| Meta (Facebook & Instagram) | ToS verbieten Scraping; getrennte Regeln für eingeloggte und ausgeloggte Daten. | Login-Schranken für die meisten Inhalte, fortschrittliche Bot-Erkennung. | Verlor 2024 gegen Bright Data – das Gericht entschied, dass ToS für nicht eingeloggte Scraper nicht gelten. Die übrigen Ansprüche wurden zurückgezogen. | Öffentliche Daten (Unternehmensseiten, öffentliche Beiträge), die ohne Login sichtbar sind, sind rechtlich sicherer. Niemals private Profile oder Daten hinter Login-Schranken scrapen. |
| X (Twitter) | Aktualisierte 2023 die ToS, um jedes Scraping und Crawling ohne schriftliche Zustimmung zu verbieten. Die frühere robots.txt-Ausnahme wurde gestrichen. | robots.txt blockiert alle Crawler (Disallow: /). Cloudflare-Turnstile-Challenges. Strenge Rate-Limits (300 Anfragen/Stunde). IP-Reputationsbewertung. | Verlor den Fall gegen Bright Data bei öffentlichen Daten, begrenzt den technischen Zugriff aber sehr aggressiv. | Öffentliche Tweets und Profile sind rechtlich vertretbar zu scrapen, aber X gehört 2026 zu den technisch schwierigsten Plattformen. Ohne Premium-Proxy-Infrastruktur sind Sperren zu erwarten. |
Fazit: Gerichte haben wiederholt entschieden, dass das Scrapen öffentlich sichtbarer Daten ohne Login nicht gegen das CFAA verstößt. Plattformen können dich aber weiterhin über Vertragsrecht, Urheberrecht oder Anti-Umgehungs-Regeln belangen – und sie machen dir mit technischen Hürden das Leben schwer. Scrape also immer mit Augenmaß.
KI-Trainingsdaten und Web-Scraping: Die neue rechtliche Front
Wer 2026 die Nachrichten verfolgt, weiß: Das Scrapen von Daten fürs Training von KI-Modellen ist zum heißesten juristischen Schlachtfeld geworden. Das spielt sich gerade ab:
- Urheberrechtsklagen häufen sich. Die New York Times, Autoren und Verlage haben OpenAI, Anthropic und andere verklagt, mit dem Argument, dass massenhaftes Scrapen geschützter Inhalte zum Training von LLMs kein „Fair Use“ sei. Anthropic legte 2025 eine große Sammelklage für 1,5 Milliarden US-Dollar bei – ein Signal, dass die Kosten des Scrapings für KI sehr real sind.
- Die „Fair-Use“-Verteidigung wackelt. US-Gerichte haben bislang nicht endgültig geklärt, ob das Training von KI mit gescrapten Daten als Fair Use zählt. Erste Entscheidungen deuten darauf hin, dass es stark davon abhängt, wie die Daten beschafft wurden und was mit der KI-Ausgabe passiert.
- Neue Gesetze sind in Arbeit. Der AI Accountability for Publishers Act (eingebracht im Februar 2026) will KI-Unternehmen verpflichten, vor dem Scrapen von Inhalten eine Erlaubnis einzuholen und Publisher zu bezahlen.
- Der EU AI Act (vollständige Anwendung ab August 2026) verlangt von KI-Entwicklern, Trainingsdatenquellen offenzulegen, maschinenlesbare Copyright-Opt-outs zu respektieren (im Rahmen der TDM-Ausnahme der Urheberrechtsrichtlinie) und KI-generierte Inhalte zu kennzeichnen. Außerdem untersagt er KI-Systeme, die Gesichtsaufnahmen aus dem Internet scrapen.
- KI-/LLM-Crawler schießen in die Höhe. KI-Crawler haben ihren Anteil am Web-Traffic in nur acht Monaten von 2,6 % auf 10,1 % vervierfacht. Allein OpenAIs GPTBot legte um 305 % zu. Als Reaktion aktualisieren große Websites (Amazon, Reddit, die NYT) ihre robots.txt, um KI-Crawler gezielt auszusperren.
Was das für dich heißt: Wenn du Daten für klassische Geschäftszwecke scrapen willst (Lead-Generierung, Preisüberwachung, Marktforschung), greifen diese KI-spezifischen Regeln nicht immer unmittelbar. Speist du gescrapte Daten aber in KI-Modelle ein, ist äußerste Vorsicht geboten – und juristischer Rat angebracht.
Web-Scraping-Gesetze weltweit: Ein kurzer Vergleich
Werfen wir einen Blick auf die globale Lage:
- Vereinigte Staaten: Kein pauschales Verbot. Das Scrapen öffentlich zugänglicher Websites ist in der Regel zulässig (hiQ v. LinkedIn), und die Urteile von 2024 in den Fällen Meta und X Corp haben das Argument fürs Scraping öffentlicher Daten weiter untermauert. Hinter Logins oder technischen Sperren kann aber weiterhin das CFAA greifen. Der Trend geht inzwischen dahin, dass Unternehmen stattdessen Vertrags- und Urheberrecht bemühen. Datenschutzgesetze breiten sich rasant aus: Das CCPA erhielt zum 1. Januar 2026 umfangreiche Updates, darunter neue Regeln für automatisierte Entscheidungen und Pflichten für Datenbroker. Auch Indiana, Kentucky und Rhode Island haben 2026 umfassende Datenschutzgesetze beschlossen.
- Europäische Union: Strenge Datenschutzgesetze. Die DSGVO gilt auch für öffentliche personenbezogene Daten. Datenbankrechte können großvolumiges Scraping strukturierter Daten unterbinden (cliffordchance.com). NEU: Der EU AI Act tritt am 2. August 2026 vollständig in Kraft und verpflichtet KI-Entwickler, Trainingsdatenquellen offenzulegen und Copyright-Opt-outs zu respektieren. Das Gesetz untersagt das Scrapen von Gesichtsaufnahmen aus dem Internet für KI-Systeme.
- Vereinigtes Königreich: Folgt nach dem Brexit weitgehend den EU-Regeln. Öffentliche Daten lassen sich scrapen, das Scraping personenbezogener Informationen ist jedoch streng reguliert. Der Computer Misuse Act kann unbefugten Zugriff unter Strafe stellen.
- China: Sehr restriktiv. Das PIPL und das Data Security Law verlangen für personenbezogene Daten eine Einwilligung. Gerichte ziehen das Recht gegen unlauteren Wettbewerb heran, um Scraping zu stoppen, das Unternehmen schadet (malwarebytes.com).
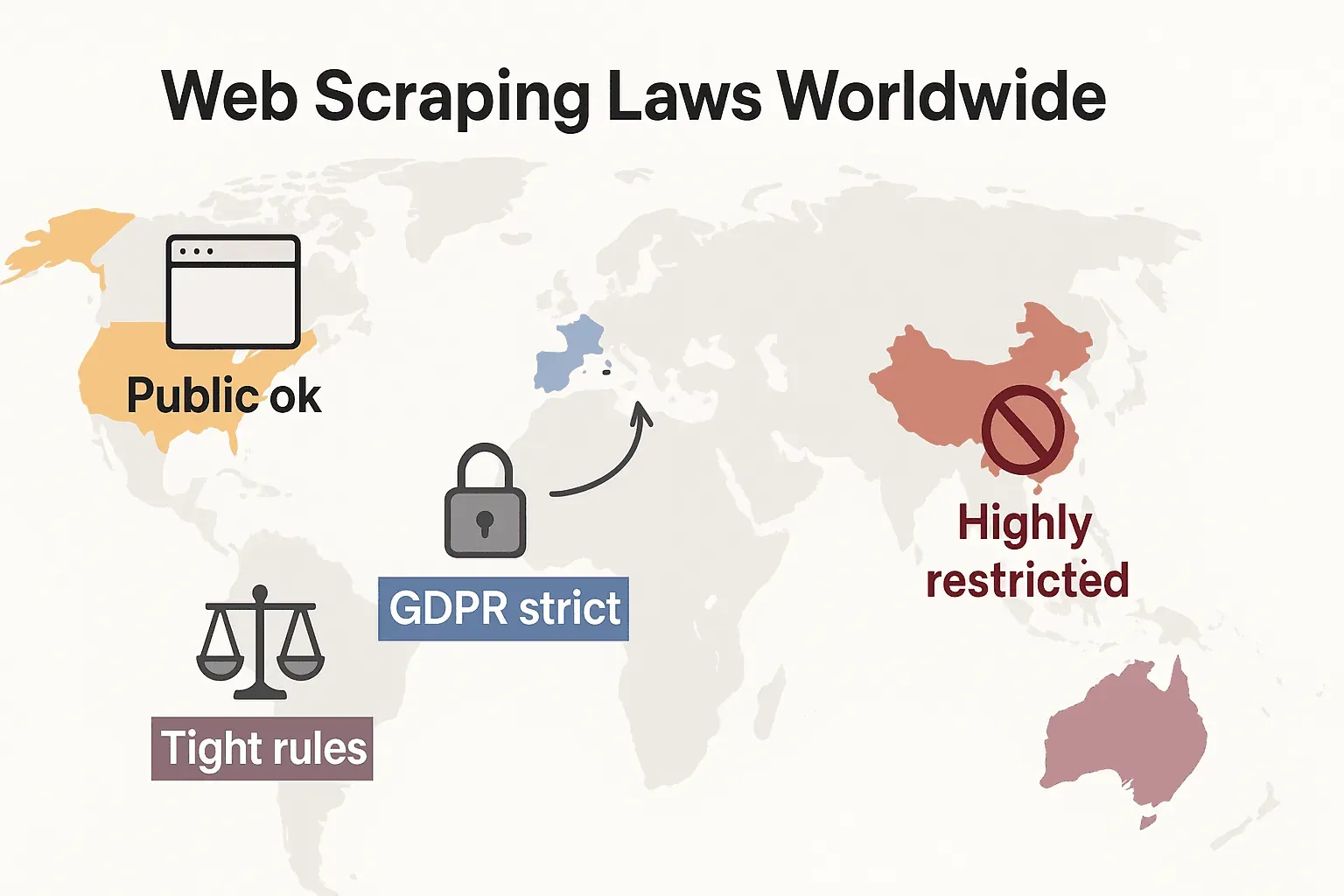
Auf den Punkt: Das Scraping öffentlicher, nicht personenbezogener Daten für den internen Gebrauch ist meist die sicherste Wahl. Alles andere? Prüfe die lokalen Gesetze und geh behutsam vor.
Häufige Mythen über die Legalität von Web-Scraping
Räumen wir mit ein paar Mythen auf, die mir ständig begegnen:
- Mythos 1: „Web-Scraping ist grundsätzlich illegal.“
Falsch. Es gibt kein Gesetz, das jedes Web-Scraping verbietet. Entscheidend ist, wie und was du scrapest (oxylabs.io). - Mythos 2: „Wenn Daten öffentlich sind, darf ich damit machen, was ich will.“
Nicht ganz. Öffentliche Daten können dennoch durch Datenschutz- oder Urheberrecht geschützt sein, und ToS können bestimmte Nutzungen einschränken (ico.org.uk). - Mythos 3: „Web-Scraping ist dasselbe wie Hacking.“
Nein. Öffentliche Webseiten zu scrapen ist kein Hacking. Logins oder technische Barrieren zu umgehen, ist eine andere Sache (calawyers.org). - Mythos 4: „Solange ich nicht erwischt werde, ist alles gut.“
Gefährliches Wunschdenken. Viele Websites setzen Anti-Bot-Technik ein und bekommen es mit. Schweigen ist keine Zustimmung. - Mythos 5: „Wenn ich Quellen nenne oder die Daten intern nutze, ist es okay.“
Eine Quellenangabe hebelt Urheber- oder Datenschutzrecht nicht aus. Interne Nutzung ist sicherer, aber kein Freibrief. - Mythos 6: „Jedes Web-Scraping verletzt den Datenschutz.“
Nicht jedes Scraping berührt personenbezogene Daten. Aber große Mengen personenbezogener Informationen ohne Schutzmaßnahmen zu scrapen, ist fast immer illegal (oxylabs.io). - Mythos 7: „Wenn eine Website in ihren ToS Scraping verbietet, ist Scraping immer illegal.“
Nicht zwingend. 2024 entschieden Gerichte in Meta v. Bright Data und X Corp v. Bright Data, dass ToS Nutzer, die ihnen nie zugestimmt haben, nicht binden – heißt: Wer ohne Login oder Konto scrapt, für den gelten die ToS der Website unter Umständen nicht. Das ist noch im Fluss, aber ein bedeutender Kurswechsel.
Wie man Daten legal scraped: Best Practices für Compliance
Das ist meine Standard-Checkliste für legales und ethisches Web-Scraping:
- Lies die Nutzungsbedingungen und halte dich daran. Steht dort „kein Scraping“, hör auf oder frag um Erlaubnis (ql2.com).
- Bleib bei öffentlichen Daten. Brauchst du ein Passwort, sind die Daten eingeschränkt – dann scrapst du sie besser nicht (thunderbit.com).
- Prüfe robots.txt und crawl höflich. Rechtlich nicht bindend, aber guter Stil. Überlaste keine Server – verteile deine Anfragen (promptcloud.com).
- Halte dich von personenbezogenen Daten fern, außer du hast eine Rechtsgrundlage. Musst du sie erfassen, richte dich nach DSGVO/CCPA und halte die Menge klein.
- Veröffentliche gescrapte Inhalte nicht 1:1 erneut. Ergänze Mehrwert oder Analyse oder hol dir eine Erlaubnis (thunderbit.com).
- Speise gescrapte Inhalte nicht ohne Urheberrechtsprüfung in KI-Modelle. Die Rechtslage ändert sich schnell – hol dir Rat, wenn das dein Use Case ist.
- Nutze offizielle APIs oder Datenexporte, wo vorhanden. Sie sind genau dafür gedacht und meist die sicherere Wahl (thunderbit.com).
- Handle transparent und verantwortungsvoll. Sammelst du personenbezogene Daten, informiere die Betroffenen und führe ein Protokoll deiner Aktivitäten.
- Minimiere und sichere deine Daten. Erhebe nur das Nötigste, halte es korrekt und speichere es sicher.
- Bleib informiert und hol dir bei Grenzfällen rechtlichen Rat. Gesetze und Urteile ändern sich schnell – besonders der EU AI Act und die US-Datenschutzgesetze der Bundesstaaten. Im Zweifel: Frag eine Fachperson.
Thunderbit Chrome-Erweiterung für regelkonformes Scraping testen
Web-Scraping-Tools legal nutzen: Was Unternehmen wissen müssen
Web-Scraping-Tools wie Thunderbit machen Datenerfassung auch für Nicht-Programmierer zugänglich – verantwortungsvoll einsetzen musst du sie trotzdem:
- Wähle Tools mit Compliance-Fokus. Thunderbit etwa scrapt nur, was du in deinem Browser sehen kannst – keine versteckten API-Hacks, keine unbefugten Zugriffe (thunderbit.com).
- Bleib bei legitimen Use Cases. Interne Analysen, Marktforschung und Wettbewerbsbeobachtung bei Preisen sind in der Regel unkritisch. Gescrapte Daten erneut veröffentlichen oder verkaufen? Deutlich riskanter.
- Stell die Tools auf Compliance ein. Lege Crawl-Verzögerungen fest, beachte robots.txt und nutze Vorlagen, die nur die nötigen Daten erfassen.
- Halte die Nutzung intern. Interne Verwendung ist sicherer als eine erneute Veröffentlichung.
- Schule dein Team. Sorge dafür, dass alle die Regeln und Best Practices kennen.
- Nutze eingebaute Compliance-Funktionen. Thunderbit warnt Nutzer vor riskanten Websites, scrapt in menschlichem Tempo und speichert deine Daten nicht auf seinen Servern.
- Erzwinge nichts mit Gewalt. Kann ein Tool eine Website nicht scrapen, versuch nicht, das System auszutricksen. Nicht alle Daten lassen sich risikolos abrufen.
Thunderbits Ansatz: Regelkonformes KI-Web-Scraping ermöglichen
Bei Thunderbit haben wir viel Hirnschmalz in das Thema Compliance gesteckt. So hilft unser KI-Web-Scraper Nutzern, auf der sicheren Seite des Gesetzes zu bleiben:
- Scrapt nur, was du sehen kannst. Thunderbit arbeitet in deiner Browser-Sitzung und kann daher keine Daten abrufen, die du nicht auch von Hand kopieren könntest.
- Lotst Nutzer mit Warnhinweisen. Versuchst du, eine Website mit strengen Anti-Scraping-Regeln zu scrapen, warnt dich Thunderbit.
- Menschliches Scraping-Tempo. Ob lokal oder in der Cloud: Thunderbit hütet sich davor, Server zu überlasten.
- Anpassbare Datenauswahl. Unsere KI schlägt relevante Spalten vor, damit du nur das erfasst, was du wirklich brauchst.
- Unterseiten und Pagination. Thunderbit navigiert wie ein echter Nutzer und respektiert die Struktur der Website.
- Datenschutz und Sicherheit. Deine Daten bleiben bei dir – Thunderbit speichert oder verwertet sie nicht weiter.
- Compliance-freundliche Exporte. Exportiere direkt nach Google Sheets, Airtable, Notion oder als CSV für die sichere interne Nutzung.
- Zeitplanung und Automatisierung. Richte wiederkehrende Scrapes in verantwortungsvollen Intervallen ein.
- Mehrsprachige Unterstützung. Die UI von Thunderbit spricht 34 Sprachen und macht Compliance weltweit zugänglich.
- Regelmäßige Vorlagen-Updates. Unsere Sofortvorlagen für beliebte Websites werden laufend an rechtliche und technische Änderungen angepasst.
Indem Compliance fest ins Produkt eingebaut ist, hilft Thunderbit Teams, die benötigten Daten zu sammeln – ohne juristischen Ärger.
Immer einen Schritt voraus: Auf rechtliche und technische Änderungen im Web-Scraping reagieren
Weitere Web-Scraping-Leitfäden entdecken Get Started Free
Web-Scraping ist kein „einrichten und vergessen“-Spiel. Gesetze und Website-Strukturen sind ständig in Bewegung. So bleibst du vorne:
- Beobachte rechtliche Entwicklungen. Das Tempo der Veränderungen hat 2024–2026 angezogen – verfolge Tech-Recht, Updates von Regulierungsbehörden und Branchenblogs (wie Thunderbits). Behalte die Durchsetzung des EU AI Act (August 2026), neue US-Datenschutzgesetze der Bundesstaaten und laufende Urheberrechtsfälle zu KI im Blick.
- Stell dich auf technische Änderungen ein. Websites bauen ständig ihre Layouts und Anti-Bot-Abwehr um. Große Plattformen (Amazon, X, Google) haben ihre Schutzmechanismen 2025–2026 deutlich verschärft. Thunderbits KI und Vorlagen sind darauf ausgelegt, sich automatisch anzupassen.
- Nutze offizielle APIs, wo vorhanden. Stellt eine Website auf ein kostenpflichtiges API-Modell um, denke aus Gründen der Zuverlässigkeit und Compliance über einen Wechsel nach.
- Prüfe dein Scraping regelmäßig. Dokumentiere deine Quellen, kontrolliere ToS- oder Richtlinienänderungen und justiere deine Strategie bei Bedarf nach.
- Nutze Thunderbits Vorlagen-Updates. Unser Team hält die Vorlagen aktuell, damit du dich nicht um Breaking Changes oder neue Compliance-Anforderungen kümmern musst.
- Bleib beweglich. Wird eine Datenquelle zu riskant, weiche auf eine andere aus oder such dir eine Partnerschaft.
Mit den richtigen Tools und der richtigen Haltung hältst du deine Datenpipeline am Laufen – ohne in rechtliche Minen zu treten.
Fazit: Sich durch die rechtliche Lage des Web-Scraping navigieren
Web-Scraping ist nicht von sich aus illegal – es ist ein schlagkräftiges Werkzeug für Business, Forschung und Innovation. Doch wie jedes Werkzeug hat es seine Regeln. Worauf es ankommt: zu verstehen, was du scrapest, wie du es scrapest und was du mit den Daten anstellst. Respektiere lokale Gesetze, halte dich an Website-Richtlinien und setze auf compliance-orientierte Tools wie Thunderbit, um rechtlich sauber zu bleiben.
Die Urteile von 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) haben das Argument fürs Scraping öffentlicher Daten gestärkt, doch rund um KI-Trainingsdaten, Urheberrechtsansprüche und den EU AI Act tun sich neue Risiken auf. Die Richtlinien der einzelnen Plattformen klaffen weit auseinander – Google, Amazon, LinkedIn, Meta und X setzen ihre Regeln jeweils anders durch –, also kenne die Lage, bevor du scrapest.
Bist du dir je unsicher, hol dir rechtlichen Rat – gerade bei großen oder heiklen Projekten. Und denk dran: Die Rechtslage ist ständig in Bewegung, also bleib informiert und beweglich.
Willst du mehr über Web-Scraping, Compliance und Automatisierung erfahren? Schau im Thunderbit Blog nach weiteren Leitfäden oder teste Thunderbits Chrome-Erweiterung selbst.
Regelkonformes Web-Scraping mit Thunderbit starten
FAQs
1. Ist Web-Scraping überall illegal?
Nein. Web-Scraping ist nicht von sich aus illegal, aber die Rechtmäßigkeit hängt davon ab, was du scrapest, wie du es scrapest und wo du dich befindest. Das Scrapen öffentlicher, nicht personenbezogener Daten für den internen Gebrauch ist in den meisten Regionen grundsätzlich erlaubt, doch das Scrapen personenbezogener oder urheberrechtlich geschützter Daten oder Verstöße gegen Website-Bedingungen können illegal sein (oxylabs.io).
2. Macht robots.txt das Scrapen illegal, wenn ich sie ignoriere?
robots.txt bindet rechtlich nicht, aber es ist guter Stil, sie zu respektieren. Sie zu ignorieren, führt für sich allein nicht zu einer Klage, kann dich im Streitfall aber wie einen „bad actor“ dastehen lassen (promptcloud.com).
3. Kann ich Google, Amazon oder LinkedIn scrapen?
Das ist verzwickt. Alle drei verbieten Scraping in ihren ToS, aber Gerichte haben entschieden, dass ToS für nicht eingeloggte Nutzer möglicherweise nicht bindend sind (siehe Meta v. Bright Data und X Corp v. Bright Data, beide 2024). Öffentlich sichtbare Daten (Produktpreise, Unternehmenslisten, öffentliche Profile) zu scrapen, ist in den USA meist rechtlich vertretbar. Allerdings setzt jede Plattform ihre Regeln anders durch: Amazon geht bei rechtlichen Schritten am schärfsten vor (es verklagte Perplexity AI im November 2025); LinkedIn setzt auf technische Sperren und Vertragsansprüche; Google nutzt zunehmend die Durchsetzung über den DMCA. Scrape stets verantwortungsvoll und rechne mit technischen Gegenmaßnahmen.
4. Kann ich Facebook oder Instagram scrapen?
Nach Meta v. Bright Data (2024) steht das Scrapen öffentlicher Daten von Facebook und Instagram ohne Login rechtlich besser da. Das Gericht entschied, dass Metas ToS für Nicht-Nutzer nicht gelten. Lege aber niemals Fake-Konten an und scrape keine Daten hinter Login-Schranken – das überschreitet die Grenze.
5. Kann ich X (Twitter) scrapen?
X hat seine ToS 2023 aktualisiert, um jedes Scraping ohne schriftliche Zustimmung zu verbieten, und fährt eine aggressive technische Abwehr auf (Cloudflare Turnstile, Rate-Limits von 300 Anfragen/Stunde, IP-Reputationsbewertung). Bright Data setzte sich vor Gericht in einem ähnlichen Zusammenhang jedoch durch – öffentlich ohne Konto gescrapte Daten sind nicht an Xs ToS gebunden. Technisch gehört X 2026 zu den am schwersten zu scrapenden Plattformen.
6. Ist das Scrapen von Daten zum Training von KI-Modellen legal?
Das ist 2026 die größte offene Frage. Große Klagen (NYT gegen OpenAI, der 1,5-Milliarden-Vergleich von Anthropic) deuten auf erhebliches rechtliches Risiko hin. Der EU AI Act verlangt die Offenlegung von Trainingsdatenquellen und die Beachtung von Copyright-Opt-outs. Der vorgeschlagene AI Accountability for Publishers Act würde Erlaubnis und Bezahlung fordern. Trainierst du für KI, hol dir vorher rechtlichen Rat.
7. Was ist der sicherste Weg, Web-Scraping-Tools wie Thunderbit zu nutzen?
Bleib bei öffentlichen Daten, halte dich an die Website-Bedingungen, meide personenbezogene Informationen, sofern du keine Rechtsgrundlage hast, und verwende die Daten intern. Thunderbit soll dir helfen, regelkonform zu bleiben, indem es nur das scrapt, was in deinem Browser sichtbar ist, und dich vor riskanten Websites warnt (thunderbit.com).
8. Kann ich Daten für kommerzielle Zwecke scrapen?
Das hängt davon ab. Gescrapte Daten für interne Analysen oder Forschung zu nutzen, ist in der Regel die sicherere Variante. Das erneute Veröffentlichen oder Verkaufen gescrapter Daten, vor allem wenn sie urheberrechtlich geschützt oder personenbezogen sind, ist deutlich riskanter und kann eine Erlaubnis oder Lizenz erfordern.
9. Wie halte ich mich über rechtliche und technische Änderungen im Web-Scraping auf dem Laufenden?
Verfolge News zum Tech-Recht, beobachte die ToS- oder Richtlinienänderungen deiner Zielseiten und setze auf Tools wie Thunderbit, die ihre Vorlagen und Compliance-Funktionen regelmäßig aktualisieren. Wichtige Themen für 2026: Durchsetzung des EU AI Act (August), laufende Urheberrechtsfälle zu KI und neue Datenschutzgesetze in den US-Bundesstaaten. Im Zweifel: Wende dich an eine juristische Fachkraft.
KI-Web-Scraper testen Get Started Free




