Thunderbit’s Bild-Extraktor hilft dir dabei, Bild-URLs und zugehörige Seitendaten aus Übersichts- und Detailseiten zu extrahieren – und nutzt anschließend KI, um alles in eine saubere Tabelle zu bringen, die du überallhin exportieren kannst. So sammelst du Produktbilder für E-Commerce-Prozesse oder ziehst Social-Media-Thumbnails für Content-Analysen – in nur wenigen Klicks mit dem KI-Web-Scraper.
🖼️ Was ist der Bild-Extraktor
Der KI-gestützte Bild-Extraktor ist ein , mit dem du Bilder (inklusive Kontext) von Websites wie Amazon oder TikTok auslesen kannst. Du öffnest einfach die gewünschte Seite, klickst auf AI Suggest Fields, damit die KI die sinnvollsten Spalten vorschlägt (z. B. Bild-URL, Titel, Preis, Post-Link u. v. m.), und klickst dann auf Scrape, um strukturierte Daten zu erzeugen, die du nach Excel, Google Sheets, Airtable oder Notion exportieren kannst.
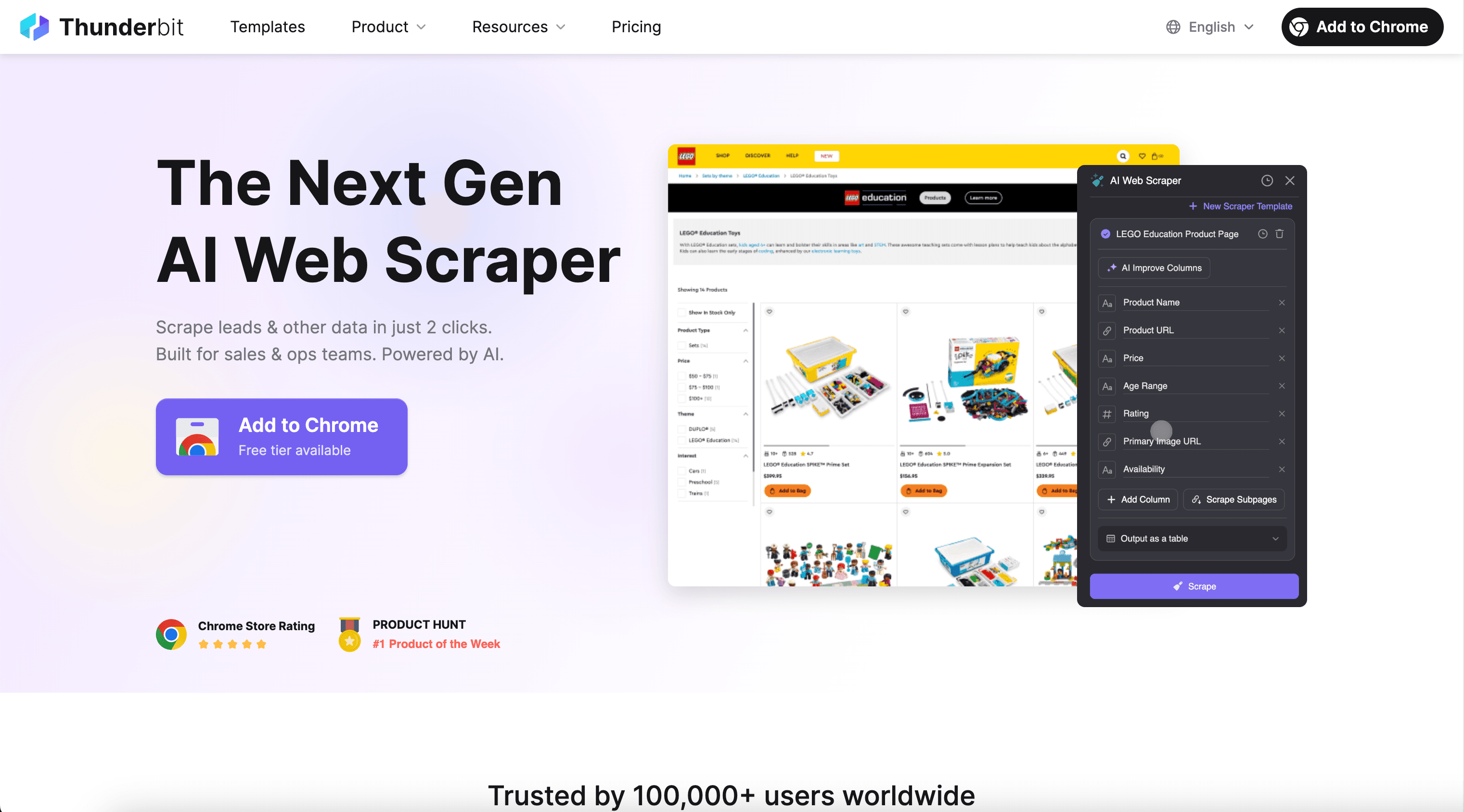
🧲 Was du mit dem Bild-Extraktor scrapen kannst
Egal, ob du eine Produktbild-Bibliothek aufbaust, Wettbewerber-Listings beobachtest oder Social-Thumbnails für kreative Recherchen sammelst: Thunderbit’s Bild-Extraktor erfasst sowohl Bild-Assets als auch Metadaten direkt von derselben Seite. Zusätzlich kannst du mit Subpage Scraping jede Detailseite besuchen und deinen Datensatz um weitere Bilder, Varianten oder Beschreibungen erweitern.
🛍️ E-Commerce: Produktbilder aus Listings scrapen
Aus einer Amazon-Suchergebnisseite wie der kannst du Produkt-Thumbnails, Titel, Preise, Bewertungen und Produkt-URLs sammeln. Das ist hilfreich für Katalogaufbau, Wettbewerbsbeobachtung, Merchandising-Research und Creative-Tests.
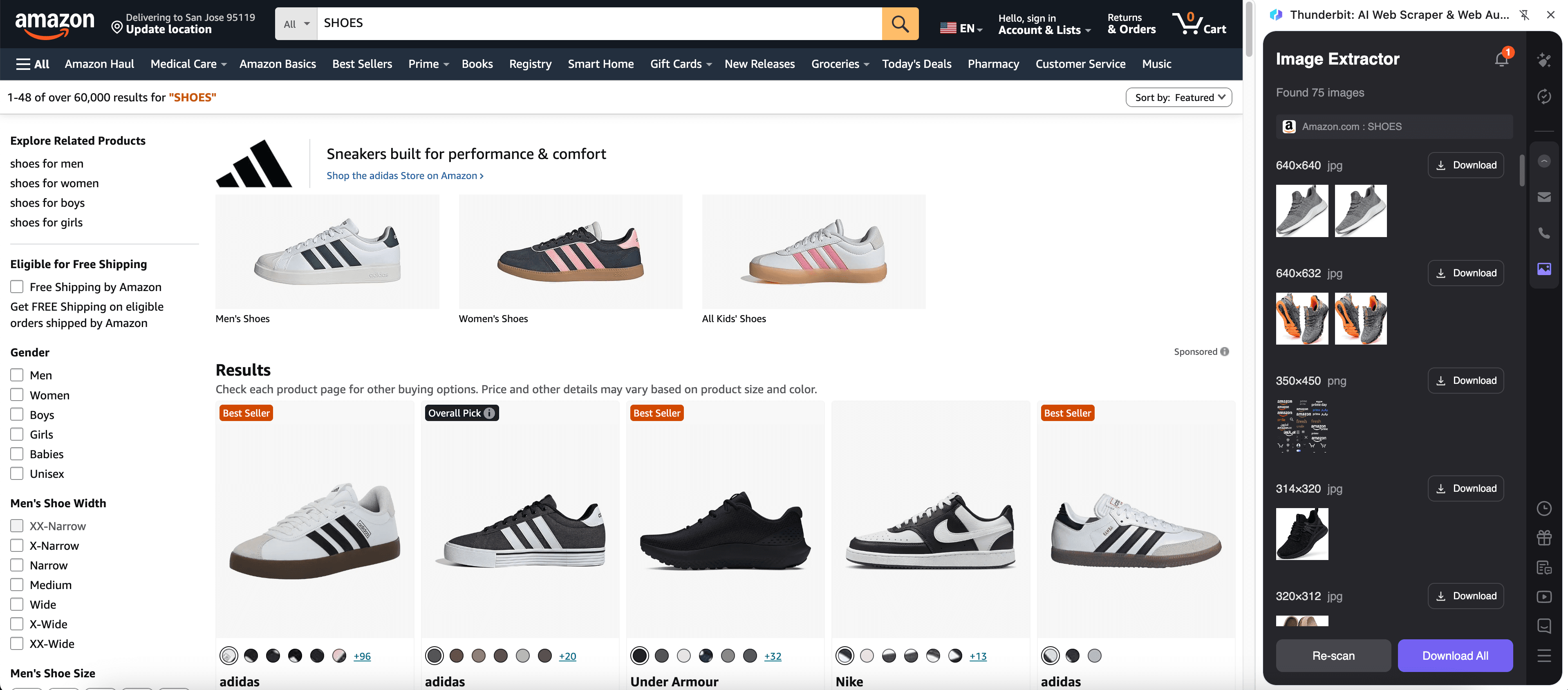
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: .
- Klicke auf AI Suggest Fields – Thunderbit schlägt Spaltennamen und Datentypen für Bilder und Produktattribute vor.
- Klicke auf Scrape, starte den Scraper und exportiere anschließend nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 🖼️ Bild-URL | Link zum Produkt-Thumbnail aus der Listing-Seite (ideal zum Aufbau einer Bildbibliothek). |
| 🏷️ Produkttitel | Produktname, wie er in den Suchergebnissen angezeigt wird. |
| 🔗 Produkt-URL | Link zur Produktdetailseite für Subpage-Anreicherung. |
| 💲 Preis | Angezeigter Preis (falls vorhanden), als Zahl für Analysen erfasst. |
| ⭐ Bewertung | Durchschnittliche Sternebewertung im Listing. |
| 🧾 Anzahl Bewertungen | Gesamtzahl der angezeigten Rezensionen. |
| 🏪 Marke / Shop | Marken- oder Shopname, sofern auf der Karte vorhanden. |
| 📦 Prime-/Versand-Badge | Sichtbare Versand-/Prime-Hinweise auf der Listing-Karte. |
Tip: Nach dem Scrape der Listing-Seite kannst du mit Scrape Subpages jede Produktseite öffnen und zusätzliche Bilder (Galerie), Varianten oder ausführlichere Beschreibungen einsammeln.
🎬 Social Media: Influencer-Content über Bilder analysieren
Aus einem TikTok-Profil wie kannst du Post-Thumbnails, Post-URLs, Captions (falls sichtbar) und Engagement-Signale erfassen. Das unterstützt Content-Audits, Inspiration-Boards, Influencer-Recherche und Trend-Tracking.
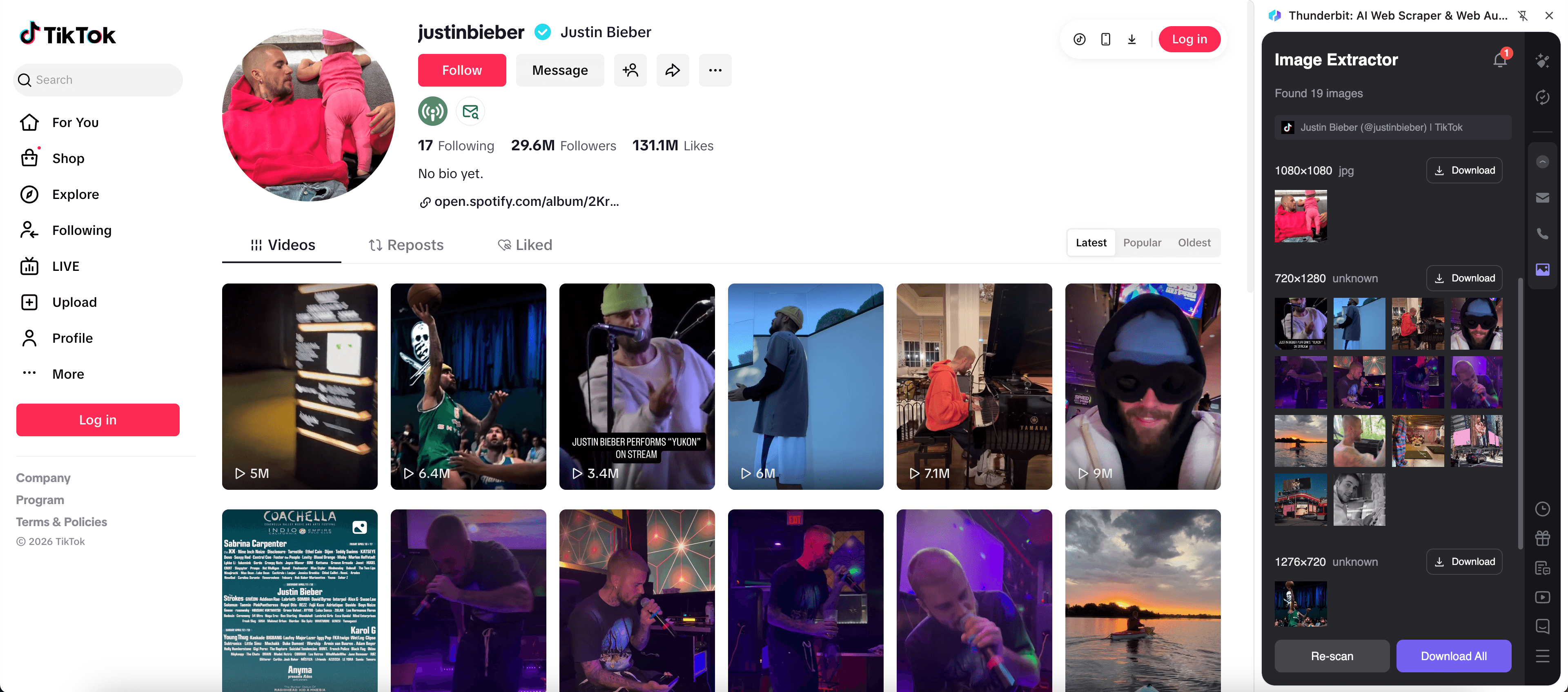
Schritte:
- Lade die herunter und registriere ein Konto.
- Öffne die Zielseite, z. B.: .
- Klicke auf AI Suggest Fields, um Spalten für Thumbnails, Links und sichtbare Metadaten zu erzeugen.
- Klicke auf Scrape, sammle die Daten und exportiere sie in dein bevorzugtes Tool.
Spaltennamen
| Spalte | Beschreibung |
|---|---|
| 🖼️ Thumbnail-Bild-URL | Vorschaubild für jeden Post im Profil-Grid. |
| 🔗 Post-URL | Direkter Link zur Post-Seite für tiefere Analysen per Subpage Scraping. |
| 📝 Caption / Text | Post-Beschreibung, sofern auf der Seite verfügbar. |
| 👤 Creator-Handle | Account-Handle, das dem Content zugeordnet ist. |
| 📅 Post-Datum | Datum/Uhrzeit, sofern verfügbar (oft am besten über die Post-Subpage erfassbar). |
| ▶️ Views | View-Zahl im Grid (falls angezeigt). |
| ❤️ Likes | Like-Zahl, sofern sichtbar (oft am besten über die Post-Subpage). |
| 🧩 Tags / Hashtags | Hashtags aus der Caption, sofern vorhanden. |
Tip: TikTok lädt Inhalte häufig dynamisch nach. Wenn du eingeloggt bist oder exakt deine Browser-Session brauchst, wähle Browser Scraping. Ist die Seite öffentlich zugänglich, ist Cloud Scraping oft schneller.
🎯 Warum ein Bild-Extraktor sinnvoll ist
Beim Scrapen von Bildern geht es selten nur darum, Dateien zu „holen“. Meist brauchst du Bild + Kontext (Titel, URL, Preis, Creator, Engagement), um später gezielt zu suchen, zu filtern und auszuwerten.
So nutzen verschiedene Teams einen KI-gestützten Image-URL-Scraper:
- E-Commerce-Teams: Wettbewerber-Bildsets aufbauen, Sortimentsänderungen verfolgen und Preise direkt neben den Visuals vergleichen.
- Marketing-Teams: Creative-Referenzen sammeln, Ad-Inspiration-Boards strukturieren und Visuals mit Performance-Signalen verknüpfen.
- Sales-Teams: Lead-Listen mit Brand-Assets und Seitenkontext anreichern, um Outreach zu personalisieren.
- Immobilien-Teams: Exposé-Fotos plus Adresse, Preis und Objektdetails erfassen (besonders stark mit Subpage Scraping).
- Analysten & Research: Aus unübersichtlichen Seiten strukturierte Datensätze erstellen – ohne fragile Selektoren zu pflegen.
Thunderbit ist für Business-Workflows gebaut, in denen Tempo, Genauigkeit und minimale Einrichtungszeit zählen – plus Exporte, die zu deinem bestehenden Stack passen.
🧩 So nutzt du die Bild-Extraktor Chrome Extension
- Thunderbit Chrome Extension installieren: Hol sie dir im und erstelle dein Konto auf .
- Zu einer bildreichen Seite wechseln: Öffne eine Listing-Seite (z. B. ) oder ein Profil-Grid (z. B. ).
- KI-Scraper aktivieren: Klicke auf AI Suggest Fields, um Spaltennamen und Datentypen zu generieren, und passe sie bei Bedarf an (z. B. „Image Alt Text“ oder „Variant“ ergänzen).
- Scrapen und mit Subpages anreichern: Klicke auf Scrape für die aktuelle Seite und nutze danach Scrape Subpages, um jede Produkt-/Post-URL zu besuchen und zusätzliche Bilder sowie Details zu erfassen.
Für einen tieferen Einstieg in KI-Scraping-Workflows helfen diese Guides:
💳 Preise für den Bild-Extraktor
Thunderbit’s Bild-Extraktor arbeitet mit einem Credit-System, bei dem 1 Credit = 1 Ergebniszeile in deiner Tabelle ist. Wenn du eine Seite scrapest und 120 Zeilen (Produkte oder Posts) erhältst, verbraucht dieser Lauf 120 Credits.
Wichtige Punkte:
- KI-gestütztes Scraping ist in Thunderbit enthalten – du kannst sofort loslegen.
- Im Free-Tarif kannst du 6 Seiten pro Monat scrapen (seitenbasierte Freimenge).
- Mit einer kostenlosen Testphase kannst du 10 Seiten gratis scrapen – ideal, um Listing- plus Subpage-Scraping im echten Workflow zu testen.
- Der Export nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON ist kostenlos.
Wenn du regelmäßig Bilder scrapest (tägliches Monitoring, große Kataloge oder mehrere Märkte), sind die Jahrespläne meist günstiger, da sie einen Rabatt enthalten. Vergleiche die Optionen auf .
❓ FAQ
-
Was ist der KI Powered Image Scraper?
Der KI Powered Image Scraper ist ein Tool in , das Bild-URLs und passende Metadaten aus Webseiten extrahiert und in strukturierte Zeilen und Spalten umwandelt. Statt Selektoren manuell zu konfigurieren, klickst du auf AI Suggest Fields – Thunderbit’s KI schlägt ein Tabellenschema vor, das zur Seite passt. -
Was ist Thunderbit?
Thunderbit ist eine KI-Web-Scraper Chrome Extension für Business-Anwender, die schnell strukturierte Webdaten ohne Programmierung benötigen. Dazu kommen Produktivitätsfunktionen wie Subpage Scraping, Pagination-Handling, Geplanter Scraper sowie kostenlose Extraktoren für E-Mails, Telefonnummern und Bilder. -
Kann man Bilder scrapen und gleichzeitig den Seitenkontext (Titel, Preis, Link) erfassen?
Ja. Thunderbit ist darauf ausgelegt, Bilder und die relevanten Felder drumherum zu scrapen – z. B. Produkttitel, Preis, Bewertung oder Post-URL. Das ist besonders praktisch, wenn du Bilder nach Attributen filtern oder später mit anderen Datensätzen verknüpfen willst. -
Wie hilft Subpage Scraping beim Sammeln von Bildern?
Viele Websites zeigen im Listing nur ein Thumbnail, während die Detailseite eine komplette Galerie enthält. Mit Subpage Scraping kann Thunderbit jede Produkt- oder Post-URL öffnen und zusätzliche Spalten wie weitere Bild-URLs, Beschreibungen oder Varianteninfos an dieselbe Tabelle anhängen. -
Lädt Thunderbit die Bilddateien herunter oder extrahiert es nur Bild-URLs?
Thunderbit extrahiert in erster Linie Bild-URLs und bildbezogene Felder in einen strukturierten Datensatz. Beim Export in Tools wie Airtable oder Notion können Bildfelder in deren Bildbibliotheken übernommen werden – so lässt sich der Datensatz leichter durchsuchen und nutzen. -
Was ist der Unterschied zwischen Cloud Scraping und Browser Scraping bei Bildseiten?
Cloud Scraping ist schneller und kann bis zu 50 Seiten auf einmal scrapen – ideal für öffentliche Seiten wie viele E-Commerce-Listings. Browser Scraping läuft in deiner Chrome-Session und ist besser, wenn Login, Regionseinstellungen oder dynamische Inhalte eine Rolle spielen, die von deinem lokalen Browserzustand abhängen. -
Kann man Seiten mit Infinite Scroll oder Pagination scrapen?
Ja. Thunderbit unterstützt sowohl klickbasierte Pagination als auch Infinite-Scroll-Patterns. Das ist beim Bild-Scraping wichtig, weil viele Listings beim Scrollen weitere Produkte oder Posts nachladen – und Thunderbit kann weiter Zeilen sammeln, während die Liste wächst. -
Was kostet es, 500 Zeilen mit Bildern zu scrapen?
Da 1 Credit = 1 Ergebniszeile ist, verbraucht das Scrapen von 500 Zeilen 500 Credits. Die tatsächlichen Kosten hängen von der Credit-Menge deines Monats- oder Jahresplans ab. Am besten schätzt du den Bedarf, indem du zuerst einen kleinen Testlauf machst. -
Ist es okay, Bilder von Amazon oder TikTok zu scrapen?
Du solltest immer die Nutzungsbedingungen der Website beachten, Urheberrecht und Datenschutz respektieren und alle geltenden Gesetze und Vorschriften einhalten. Thunderbit stellt die Technik zum Extrahieren bereit – wie du die Daten nutzt, sollte zu deinen rechtlichen und Compliance-Anforderungen passen.
📚 Mehr erfahren
- Starte mit der
- Tutorials und Workflows im entdecken
- Scraping-Grundlagen:
- Listendaten aufbauen:
- Saubere Tabellen schnell exportieren:
- Wenn du zusätzlich Text aus Dokumenten extrahieren willst: