
Most "Bright Data reviews" online read like product brochures with a star rating stapled on. They mention the 400M+ IP pool, quote the "$4/GB" promo rate, and call it a day. That's not very helpful if you're trying to figure out whether this platform is actually worth your budget. So I spent weeks digging into the real pricing math, reading through hundreds of user reviews on Trustpilot, G2, Capterra, and Reddit, and testing how Bright Data's products actually perform on protected sites. What I found is a platform that genuinely earns its "best-in-class" label for enterprise proxy infrastructure — but one that also comes with hidden cost traps, reliability gaps on hard targets, and a complexity level that's wildly mismatched for most teams who just want structured data from websites. This article is the honest Bright Data review I wish existed when I started researching.
What Is Bright Data? A Quick Overview for Non-Technical Teams
Bright Data is a premium proxy network and web data collection platform. In plain English: it routes your web requests through millions of different IP addresses around the world so you can access websites at scale without getting blocked. Think of it as a massive, global network of "disguises" for your data collection activities.
Originally called Luminati Networks (rebranded in March 2021), the company was acquired by for $200 million in 2017. Headquartered in Netanya, Israel, with offices in New York and across Europe, Bright Data now serves — including 14 of the top 20 LLM labs — and generates over .
The product lineup has expanded well beyond proxies:
- Proxy networks — residential, datacenter, ISP (static), and mobile
- Web Unlocker — an API that handles anti-bot challenges automatically
- Scraping Browser — a cloud-hosted browser for JavaScript-heavy sites
- Web Scraper API — pre-built scrapers for 437+ websites
- Pre-collected datasets — ready-made data for 120+ domains
- AI tools — Browser.AI, MCP Server, Deep Lookup (more on these later)
Here's the quick specs snapshot:
| Spec | Details |
|---|---|
| Residential IPs | 400M+ monthly (150M+ ethically sourced) |
| Datacenter IPs | 1.3M+ |
| ISP/Static IPs | 1.3M+ |
| Mobile IPs | 7M+ |
| Countries | 195 (city/state/ASN targeting) |
| Trustpilot Rating | 4.4/5 (~969 reviews) |
| G2 Rating | 4.7/5 (~295 reviews) |
| Capterra Rating | 4.7/5 (68 reviews) |
| Free Trial | 7-day (requires KYC); up to 15 DC IPs + 2 GB free |
| Starting Price | $0.60/GB (datacenter); $8.00/GB (residential PAYG) |
The target audience is primarily enterprise and technical teams. If you've got developers on staff and a five-figure monthly scraping budget, Bright Data was built for you. If you're a sales manager who needs 200 leads from a website by Friday, well — keep reading.
Bright Data Pricing: The Full Breakdown (Not Just "$4/GB")
This is where most Bright Data reviews fall apart. They quote the promotional residential rate and move on. The actual pricing is significantly more complex — and more expensive — than the marketing suggests.
Residential Proxies (Per GB)
| Plan | Per GB | Monthly Commitment | GB Included |
|---|---|---|---|
| Pay-As-You-Go | $8.00 | None | None |
| Growth | $7.00 | $499 | ~71 GB |
| Business | $6.00 | $999 | ~166 GB |
| Enterprise | $5.00 | $1,999 | ~399 GB |
That "$4/GB" number you see everywhere? It's a (code RESIGB50, 50% off for 3 months). After the promo expires, you're back to full price. The historical context matters too: PAYG residential was $10.50 before September 2023, dropped to $8.40 after March 2024, and sits at $8.00 now.
Datacenter Proxies
The most affordable option. Shared pool: PAYG. Dedicated pool: $0.90–$1.40/IP/month (standard) or $1.30–$2.20/IP/month (premium). Each IP includes a fair-use allowance — exceed it and you'll pay overage at PAYG rates.
ISP (Static Residential) Proxies

Shared: $1.30–$1.80/IP/month depending on volume. Dedicated: $2.50–$3.50/IP/month. Bandwidth plans mirror residential pricing. Same fair-use cap applies.
Mobile Proxies
Equalized with residential in April 2024 — previously $14/GB, now . Same tier structure as residential.
Web Unlocker API (Per 1,000 Successful Requests)
| Plan | CPM (per 1K results) | Monthly Cost |
|---|---|---|
| Pay-As-You-Go | $1.50 | None |
| Growth | $1.30 | $499 (~380K results) |
| Business | $1.10 | $999 (~900K results) |
| Scale | $1.00 | $1,999 (~2M results) |
The billing model here deserves a red flag. Bright Data markets Web Unlocker as "Pay Only For Success" — and that's true by default. But their reveals a critical exception: "When any of the Custom Web Unlocker API features are enabled, you'll be billed for 100% of the requests (both successful and failed)." Custom features include manual headers, cookies, and "expect" elements. So the moment you need fine-grained control — which is often when scraping hard targets — you lose the success-based billing protection.
Scraping Browser (Per GB)
Same tier structure as residential: $8.00/GB PAYG, down to $5.00/GB at Enterprise. Unlike Web Unlocker, whether failed request bandwidth is billed — which effectively means all bandwidth is billable, including from failures.
Web Scraper API
PAYG: . Scale: $1.30/1K ($499/mo for ~384K records). Includes for Amazon, LinkedIn, Glassdoor, Walmart, Zillow, and more. Only successfully delivered results are billed. 1K free records trial.
A note on the January 2025 restructuring: Bright Data while raising Web Scraper API prices by 50%, converging around a unified $1.50/1K CPM rate. If you were budgeting based on 2024 pricing, recalculate.
Pay-Per-GB vs. Pay-Per-IP: Which Model Fits?
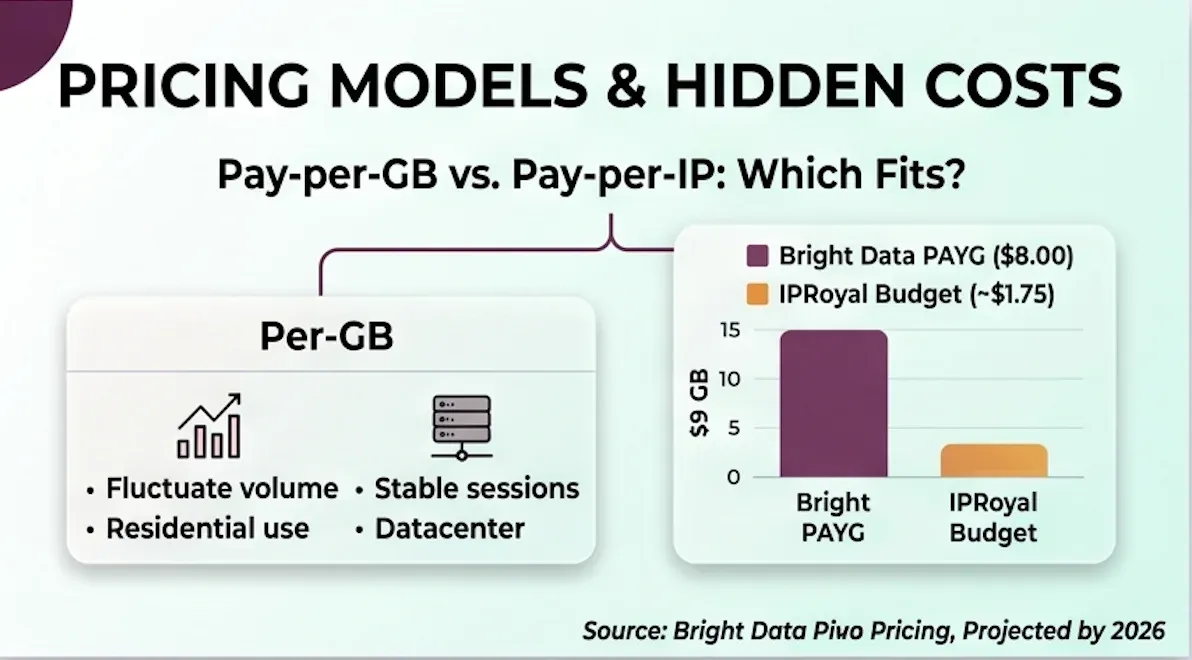
Pay-per-GB makes sense when your scraping volume fluctuates month to month — residential and mobile use cases where you're hitting many different sites. Pay-per-IP works better for stable, long-running sessions: account management, ad verification, or SEO monitoring with datacenter or ISP proxies where you need the same IPs consistently.
Quick rule of thumb: predictable IP count but variable bandwidth? Go per-IP. Predictable bandwidth but need rotating IPs? Go per-GB.
Hidden Cost Factors the Fine Print Doesn't Highlight
- Failed request billing: Web Unlocker charges for all requests when custom features are enabled. Scraping Browser charges all bandwidth regardless.
- Bandwidth overages: ISP proxies have a 100 GB/IP fair-use cap. One reviewer reported an "unexpected $300 overage bill" after burning through their allocation in 23 days.
- No middle ground: As , "There's no real middle ground between pay-as-you-go at $1.50/1K (prohibitive for volume) and the $499/month commitment."
- Promo cliff: 50% off promos last 3 months, then full rate kicks in — creating sticker shock at month 4.
Cost Scenario: 50 GB Residential Scraping Per Month
| Approach | Per-GB Rate | Monthly Cost |
|---|---|---|
| Bright Data PAYG | $8.00 | $400 |
| Bright Data Growth Plan | $7.00 | $499 (71 GB included) |
| IPRoyal (budget alternative) | $1.75 | $87.50 |
| Thunderbit Pro | Flat rate | $38/mo (credits-based, ~3,000 rows) |
That's a 4–10x price gap. For teams whose end goal is structured data in a spreadsheet — not raw proxy infrastructure — the cost math rarely favors Bright Data.
How to Cut Bright Data Costs: Practical Tips That Actually Work
Already on Bright Data (or locked into a contract)? These are the tactics that actually move the needle on your bill.
Use datacenter proxies instead of residential when the target allows it. Datacenter shared is $0.60/GB vs. residential at $8.00/GB — a 13x difference. Many non-protected sites (news, public directories, government data) work fine on datacenter.
Set per-zone spending limits in the dashboard. Bright Data's control panel lets you . Limits recalculate every 15 minutes, so a zone may overshoot by up to 15 minutes of usage. Email alerts fire at 85% of account balance consumption.
Complete KYC early for Full Access. Immediate Access (no KYC) restricts you to GET-only, ~200 pre-approved domains, and provider-imposed throttling — which means more 402 errors and more wasted bandwidth. Full Access unlocks all methods and removes most domain restrictions, so your success rate goes up and your wasted spend goes down.
Block unnecessary resources to cut bandwidth . Images, CSS, fonts, ads, and tracking scripts via request interception or CDP route blocking. This alone can halve your bill. can reduce bandwidth by up to 90% for rarely-updated pages.
Avoid enabling custom features on Web Unlocker unless you must. Once you set manual headers or cookies, you switch from success-based billing to 100%-of-requests billing. The difference on a high-failure-rate target can be dramatic.
Know when to switch entirely. If your use case is extracting structured data from websites — product listings, contact info, property data — without building custom scraping pipelines, tools like can replace the entire proxy stack. No bandwidth billing, no proxy configuration, no KYC process.
Reliability Reality Check: Where Bright Data Struggles
Bright Data advertises 99%+ uptime and high success rates. On easy targets, that's accurate. The problem? Nobody buys an enterprise proxy platform to scrape easy targets.
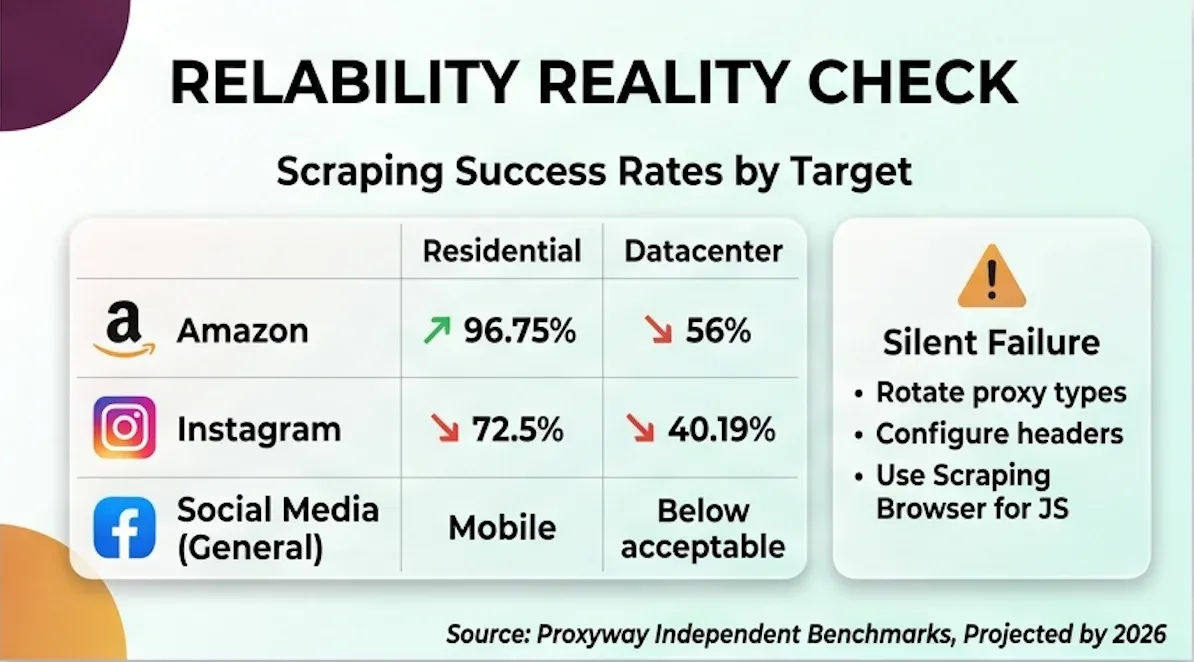
Success Rates by Target Category
| Target | Proxy Type | Success Rate | Source |
|---|---|---|---|
| Most commercial sites | Residential | 98–99% | Proxyway |
| Amazon | Residential | 96.75% | Proxyway |
| Amazon | Datacenter (shared) | 56% | Proxyway |
| Amazon | Datacenter (dedicated) | 65% | Proxyway |
| Residential | 72.5% (12.56s response) | webscraping.blog | |
| Mobile | 40.19% (17.58s) | webscraping.blog | |
| Web Unlocker | 99.3% | Various | |
| Social media (general) | Mobile | Below acceptable | Proxyway: "slow and failing more than succeeding" |
Residential proxies perform well on most commercial sites. Success rates crater on protected e-commerce (Amazon via datacenter: 56%), social media (Instagram via mobile: 40%), and sites behind aggressive WAFs like Cloudflare and PerimeterX.
provides additional context: while Bright Data advertises 400M+ residential IPs, Proxyway "only found around 3,000 UK proxies, and fewer than 1,000 Australian addresses" in testing — suggesting geographic depth varies significantly.
The Silent Failure Problem
This is the subtlest risk. Rather than returning a clear "blocked" error, some target sites return what looks like legitimate data — but it's incomplete or stale. Bright Data's own documentation acknowledges the pattern: "When a target site updates its defenses, a scraper fails silently, returning empty fields or stale data while appearing to work normally." You might not realize your data is damaged until it's already in your pipeline.
Best Practices for Improving Success Rates
Rotate proxy types, not just IPs. If residential fails on a target, try ISP or mobile — different proxy types trigger different detection patterns.
Configure proper request headers and user-agent strings to mimic real browser behavior. Default configurations are the first thing anti-bot systems flag.
Use Scraping Browser instead of Web Unlocker for JavaScript-heavy targets. Web Unlocker doesn't render JavaScript; Scraping Browser runs a full Chrome instance in the cloud. For sites that require client-side rendering (most modern SPAs), this is the difference between success and failure.
Monitor the Bright Data real-time network status page to avoid running jobs during outages. Sounds obvious, but I've seen teams waste hundreds of dollars on failed requests during a network degradation event.
For teams that don't want to troubleshoot proxy configurations at all, a no-code alternative like handles anti-bot challenges through its AI engine without requiring you to choose between proxy types, configure headers, or manage retry logic.
What 500+ Real Users Say: Aggregated Bright Data Review Sentiment
I read through hundreds of reviews across Trustpilot, G2, Capterra, and Reddit to identify the actual patterns — not just cherry-picked quotes.
Ratings Across Platforms
| Platform | Rating | Reviews | Notable |
|---|---|---|---|
| Trustpilot | 4.4/5 | ~969 | 85% five-star, 9% one-star (polarized) |
| G2 | 4.7/5 | ~295 | #1 in Proxy Network category |
| Capterra | 4.7/5 | 68 | Verified reviews |
The Trustpilot distribution is polarized. Enterprise teams with dedicated account managers leave five-star reviews. Smaller teams hitting cost and complexity walls leave one-star reviews. There's not much in between.
Sentiment by Category
| Category | Positive Signal | Negative Signal | Net Verdict |
|---|---|---|---|
| IP Pool Size & Coverage | ★★★★★ | — | Very Positive |
| Scraping Success Rate | ★★★★ | ★★ | Mixed-Positive |
| Pricing & Value | ★★ | ★★★★★ | Negative |
| Customer Support | ★★★ | ★★★ | Polarized |
| Ease of Use / Onboarding | ★★ | ★★★★ | Negative |
| Data Freshness (Datasets) | ★★ | ★★★ | Mixed-Negative |
Where Users Love Bright Data
IP pool size and global coverage are consistently praised. : "Before Bright Data, our success rate was 68% with free proxies. After, it jumped to 99.2% — daily pages went from ~2,000 to ~18,000."
Enterprise support gets high marks — dedicated account managers, 14-minute average email response for paying customers, and proactive monitoring. The Proxy Manager tool is valued by technical teams who want granular control over rotation, targeting, and session management.
Compliance and ethical sourcing matter to corporate clients, and Bright Data's SOC 2 Type II, ISO 27001, and third-party audits provide genuine assurance.
Where Users Push Back
Pricing is the single biggest complaint. Users describe it as "3–10x more expensive" than alternatives. As : "If you are a solo founder trying to gather competitor pricing data, Bright Data's complexity and cost structure can feel like bringing a firehose to water a houseplant."
Onboarding friction is real. KYC requires government ID upload, and only registered companies can complete full verification. Freelancers must do a video call in English. One Trustpilot reviewer noted: "Requiring a video session with an English-speaking interview" is a significant barrier for international users. Official approval is "48 hours" but users report 3 days to 3 weeks.
Support quality is polarized. Enterprise accounts get responsive help. Non-paying trial accounts . Phone support is locked to the $5K+/month tier. A G2 reviewer wrote: "Bright Data's web unlocker products claimed to unlock hard-to-scrape websites... in reality this was not the case as it had a very high failure rate and I was charged for unsuccessful queries."
Dashboard complexity deters non-technical users. The interface is powerful but overwhelming. Multiple reviewers described the learning curve as "days to weeks" to get comfortable. One Capterra reviewer (Emiliano G., Sep 2025) wrote: "Products have degraded rapidly, and now face high data fetching failure rates."
Bright Data's AI Pivot: Browser.AI, MCP Server, and Deep Lookup
On July 2, 2025, Bright Data launched three AI products simultaneously, explicitly repositioning from "proxy provider" to "AI data infrastructure." CEO Or Lenchner: "The intelligence of today's LLMs is no longer its limiting factor; access is."
is a serverless, cloud-based autonomous browser for AI agents. You give it a task in plain English — "go to Amazon, search for wireless headphones, collect the top 20 results" — and it opens a real Chrome in Bright Data's cloud, navigates like a human, handles CAPTCHAs, and returns structured data. showed a 98.44% success rate across seven challenging domains. Pricing: Free (2 GB), Starter $39/mo (10 GB), PAYG $8/GB.
is an open-source bridge built on Anthropic's Model Context Protocol standard. It lets AI assistants (Claude, Cursor, Windsurf, LangChain, LlamaIndex) access Bright Data's 30+ scraping tools directly. After a 3-month private beta with 15,000 developers, it went public in August 2025. . Strategically, this is probably Bright Data's most important product — it positions them as the default web data layer for the entire AI agent ecosystem.
is a natural-language research engine that searches 1,000+ public sources and returns structured, table-ready data with citations. Still in beta (5 free queries without credit card). Pay-only-for-matched-results model. Reported 90–100% match rates for lead generation and competitive intelligence.
Do You Actually Need Bright Data's AI Features?
If you're building AI models, training LLMs on web data, or constructing real-time data pipelines for machine learning — these tools are genuinely powerful and worth evaluating.
But for business teams that need structured data from websites — sales leads, product prices, real estate listings, competitive intelligence — the AI infrastructure adds complexity and cost without proportional value. Every AI product has its own billing model, and the total cost structure becomes harder to predict.
For these teams, offers a fundamentally simpler path: the AI reads the page, suggests extraction fields automatically, and delivers structured data in 2 clicks. You export to Excel, Google Sheets, Airtable, or Notion. No MCP protocols, no cloud browser infrastructure, no bandwidth billing. It's not a proxy — it's the end result without the infrastructure.
Bright Data vs. Oxylabs vs. Smartproxy vs. Thunderbit: Which Is Right for You?
Every other Bright Data review I found skips the structured comparison. Here's the one I wish they'd included — framed around use case fit, not abstract rankings:
| Feature | Bright Data | Oxylabs | Decodo (Smartproxy) | ScraperAPI | Thunderbit |
|---|---|---|---|---|---|
| Best for | Enterprise-scale proxy infra | Enterprise proxy + scraping API | Mid-market proxy teams | API-based scraping (devs) | No-code AI data extraction |
| Residential IPs | 400M+ | 175M+ | 125M+ | N/A (API service) | N/A (browser-based) |
| No-Code Option | Limited (Scraper IDE) | Limited (Web Scraper API) | Ready-made scrapers | API-only | Yes (core product) |
| Learning Curve | High | Medium–High | Medium | Low | Very Low |
| Free Tier | 7-day trial (KYC required) | 2K free results | 7-day trial | 1K credits/mo free | 6 free pages/mo |
| Starting Price | ~$8/GB residential | ~$4/GB residential | ~$8.50/GB PAYG | $49/mo | Free tier + $38/mo Pro |
| Key Strength | Largest IP pool, broadest suite | 99.95% scraper success, OxyCopilot AI | Simplest mid-market UX | Simplest API integration | 2-click AI scraping, free exports |
| Key Limitation | Complex, expensive, steep learning curve | Weaker unblocker (40–50%), higher entry | No visual scraper, enterprise gaps | 0% success on social sites | Not proxy infrastructure |
Bright Data vs. Oxylabs
Both are enterprise-grade. vs. Bright Data's 400M+. Oxylabs tends to be pricier on residential (~$4/GB entry with volume, vs. Bright Data's $8 PAYG) but delivers stronger mobile proxy performance (90–98% vs. Bright Data's inconsistent mobile results). Bright Data wins on product breadth; Oxylabs wins on focused execution and simpler UX. If you need both proxies and scraping APIs, Oxylabs' Web Scraper API achieves 99.95% average success — though with slower response times (~17.5s).
Bright Data vs. Smartproxy (Decodo)
(rebranded from Smartproxy in April 2025) is the simpler, cheaper option for mid-market teams. — a strong signal. Entry at $8.50/GB PAYG, but volume pricing is competitive ($1.50/GB at enterprise 1 TB). Simpler dashboard, faster onboarding (3-day free trial vs. Bright Data's KYC process). For teams that need solid proxies without navigating Bright Data's product maze, Decodo is worth a serious look.
When a No-Code AI Scraper Like Thunderbit Makes More Sense
This comes down to one question: do you need proxy infrastructure, or do you need data?
Most people reading this review — sales reps, ops managers, market researchers, ecommerce analysts — need data. Not IP pools. Not bandwidth management. Not proxy rotation algorithms.
Data.
Here's the workflow comparison for extracting 100 product listings:
| Step | Bright Data (technical path) | Thunderbit |
|---|---|---|
| Setup | Create account, add payment, navigate dashboard, complete KYC | Install Chrome extension |
| Configure | Choose product (Unlocker? Browser? Scraper?), research which fits | Navigate to the target page |
| Build | Write scraper or pick template, configure selectors | Click AI Suggest Fields |
| Run | Run, debug failures, adjust selectors | Click Scrape |
| Export | Download CSV/JSON | Click Export → Sheets/Excel/Airtable/Notion |
| Time | 1–2 hours (experienced dev) | ~5 minutes (anyone) |
| Cost | ~$1–5 in API costs + dev time | Free tier or $38/mo Pro |
We built Thunderbit specifically for this gap. The AI reads the page structure, suggests the right columns, handles pagination and subpages, and exports structured data — all without you ever thinking about proxies, headers, or retry logic. It's not a replacement for Bright Data's enterprise infrastructure. It's a replacement for the entire category of problems that make you think you need enterprise infrastructure.
How to Decide: A Simple Framework
| Your Situation | Best Fit | Why |
|---|---|---|
| Need massive-scale proxy infrastructure for custom pipelines | Bright Data or Oxylabs | Largest IP pools, enterprise SLAs, compliance rigor |
| Need reliable mid-market proxies without enterprise complexity | Decodo (Smartproxy) | Simpler UX, fair pricing, 125M+ IPs |
| Building AI/LLM data pipelines with real-time web feeds | Bright Data AI tools | Browser.AI, MCP Server, dataset marketplace |
| Need structured data from websites — no coding, no proxy management | Thunderbit | 2-click AI scraping, free exports, zero infrastructure |
| Developer who wants a single API call for scraping | ScraperAPI | Simplest API integration, free tier |
| One-off quick scrape for a single project | Thunderbit free tier or ScraperAPI free tier | No commitment, instant results |
The right tool depends on your team's technical capacity, budget, and what you actually do with the data. Feeding a data warehouse that powers ML models? Bright Data's infrastructure makes sense. Populating a sales spreadsheet? It doesn't.
A Quick Note on Compliance and Ethical Data Collection
Bright Data takes compliance seriously — more seriously than any competitor. That's both an advantage and a source of friction.
Certifications: SOC 2 Type II (publicly downloadable SOC 3), ISO 27001:2022 (plus 27017 and 27018), CSA STAR Level 1. Infrastructure on AWS multi-AZ, TLS 1.3 in transit, AES-256 at rest. .
Ethical IP sourcing: Residential IPs come from the integrated into partner apps. Users opt in via a clear consent screen to share idle bandwidth in exchange for ad-free or premium experiences. This is a material improvement from the original Hola VPN model (2014–2015) where users weren't adequately informed.
Two landmark 2024 legal wins worth knowing about:
- (Jan 2024): Court ruled that Facebook/Instagram Terms do not bar logged-off scraping of public data.
- (May 2024): Dismissed. Judge Alsup warned that giving social networks control over public data "risks the possible creation of information monopolies."
The tradeoff: the KYC process is thorough but adds real onboarding friction. Only registered companies can complete it. Freelancers need a video call in English. Approval takes 48 hours to 3 weeks. For teams that need data today, not next week, this is a meaningful barrier.
Thunderbit similarly focuses on legitimate business use cases — scraping publicly available data for sales, ecommerce, and research — without requiring KYC verification or ID uploads.
Is Bright Data Worth It in 2026? The Honest Verdict
Bright Data has the largest IP pool (400M+), the broadest product suite, the most rigorous compliance program, and two landmark legal victories backing its right to operate. No competitor matches that combination. For enterprise teams with technical resources, five-figure monthly budgets, and complex scraping infrastructure needs, it's the default choice for a reason.
But "biggest toolkit" and "best for you" are different questions.
Bright Data is worth it if:
- You need massive-scale proxy infrastructure with city-level geo-targeting across 195 countries
- You have dedicated technical staff to manage proxy configurations, retry logic, and scraper maintenance
- Your budget supports $500+/month minimum commitments
- You're building AI/LLM data pipelines that require real-time web data feeds
Bright Data is probably not worth it if:
- You're a small-to-mid team that needs structured data from websites
- You don't have developers on staff to manage proxy settings and debug failures
- Your primary concerns are ease of use and cost efficiency
- You'd rather spend 5 minutes getting data than 5 hours configuring infrastructure
For sales, operations, and research teams who want the fastest path from website to spreadsheet, takes a different approach entirely.
AI-powered extraction in 2 clicks. Free exports to Excel, Google Sheets, Airtable, or Notion. No KYC, no proxy configuration, no bandwidth billing.
Just data.
You can try right now — 6 free pages per month, no credit card required. See if a simpler approach gets you what you need before committing to enterprise proxy infrastructure.
FAQs
Is Bright Data worth the price for web scraping?
For large-scale enterprise operations that need 400M+ IPs, city-level geo-targeting, and compliance-grade infrastructure — yes. Bright Data delivers capabilities no competitor fully matches. For teams that simply need extracted data from websites without managing proxy infrastructure, the answer is no — simpler, cheaper alternatives like Thunderbit, ScraperAPI, or even budget proxy providers like IPRoyal deliver the end result at a fraction of the cost and complexity.
Is Bright Data legit and safe to use?
Yes. Bright Data is a well-established company with SOC 2 Type II certification, ISO 27001 compliance, including Fortune 500 companies, and two landmark legal victories (Meta v. Bright Data, X Corp. v. Bright Data) affirming the legality of public web data collection. The KYC process exists specifically to ensure legitimate use — it's thorough but adds onboarding friction.
Does Bright Data charge for failed requests?
It depends on the product. Web Unlocker uses success-based billing by default — but if you enable (manual headers, cookies, or "expect" elements), all requests are billed regardless of success. Scraping Browser charges per GB transferred, including bandwidth from failed attempts. SERP API does not bill for failed requests.
This billing nuance is one of the most common user complaints — and one Bright Data doesn't make obvious during signup.
What is the cheapest Bright Data proxy type?
Datacenter shared pool proxies at — suitable for non-protected websites like news sites, public directories, and government data. For protected sites, residential proxies start at $8.00/GB PAYG ($4.00/GB with the current promotional code, valid for 3 months). Datacenter dedicated IPs start at $0.90/IP/month with 100 GB fair-use included.
What is the best Bright Data alternative for non-technical teams?
— an AI-powered Chrome extension that extracts structured data from any website in 2 clicks. Click "AI Suggest Fields" and the AI reads the page and proposes columns. Click "Scrape" and the data populates. Export free to Excel, Google Sheets, Airtable, or Notion. No proxy management, no coding, no KYC process. The gives you 6 pages per month to test it out, and the Pro plan starts at $38/month — a fraction of Bright Data's minimum commitment.
Learn More