如果您曾經試著從網站裡精準抓出想要的資料——可能是競爭對手的價格清單、產品型錄,或是一批最新的銷售名單——您一定懂那種感覺:一般的爬蟲工具可以完成 80%,但剩下那關鍵的 20% 呢?真正的魔法(也是最惱人的地方)就在那裡。如今這個以資料為核心的世界裡,企業不能只停留在「差不多正確」。客製化擷取與資料擷取服務,已經成為現代營運的中樞;全球網頁爬蟲市場預計將從 2024 年的 7.54 億美元,成長到 。如果您的資料策略沒有納入客製化爬取,您可能早就已經在市場上失去能見度了。
這些年來,我一直在協助各種團隊——從精實的新創到成熟企業——跨越複製貼上的漫長苦工,以及那些脆弱、千篇一律的工具。差別在哪?就是掌握客製化資料擷取。這篇指南裡,我會帶您了解客製化擷取真正的意思、為什麼它不可或缺、(我和團隊打造的人工智慧網頁爬蟲)如何把這件事變得極簡,還有怎麼替您的業務挑選合適的資料擷取服務。我也會分享幾段真實經驗——畢竟,做資料的人總有幾個血淚故事。
什麼是客製化擷取?解鎖量身打造的資料擷取服務潛力
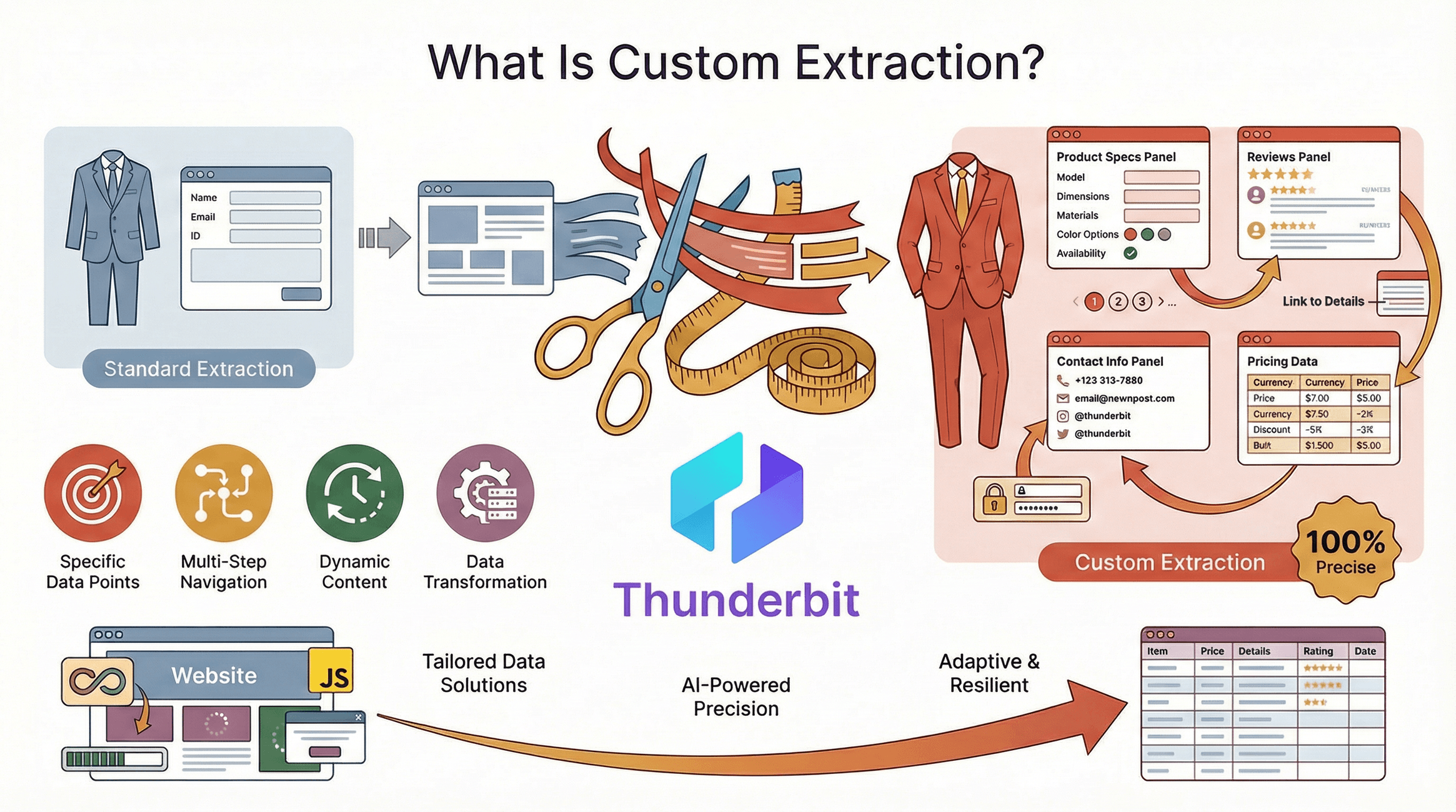 先從基礎說起:客製化擷取的核心,就是從對您的業務最重要的網站中,精準取得您要的資料,並且用您想要的格式輸出。和只會抓取容易取得或肉眼可見內容的標準爬蟲工具不同,客製化資料擷取更精準、更有彈性,也更能承受變化——就算網站結構複雜、動態生成,或是幾乎每兩週就改版一次也一樣。
先從基礎說起:客製化擷取的核心,就是從對您的業務最重要的網站中,精準取得您要的資料,並且用您想要的格式輸出。和只會抓取容易取得或肉眼可見內容的標準爬蟲工具不同,客製化資料擷取更精準、更有彈性,也更能承受變化——就算網站結構複雜、動態生成,或是幾乎每兩週就改版一次也一樣。
可以把它想成訂做西裝,而不是買現成成衣。使用客製化擷取時,您不會被預設欄位或模板綁死。您可以:
- 挑選特定資料點(像是產品規格、評論或聯絡資訊)
- 處理多步驟導覽(分頁、子頁面、登入)
- 因應動態內容(無限捲動、JavaScript 載入資料)
- 在擷取過程中直接格式化、清理或轉換資料
為什麼這很重要?因為真實的商業需求很少簡單。也許您需要先抓產品列表,再逐一點進連結取得詳細規格與評論;又或者您想監控數十個頁面的競品定價,但只針對特定 SKU。標準工具往往會失敗、漏抓資料,或逼您變成業餘的 HTML 偵探。相反地,客製化擷取服務就是為這類情境而生——而且常常還有 AI 和自然語言處理的加持。
如果您想更深入了解客製化與標準爬取的差異,可以看看 。
為什麼客製化資料擷取服務對企業成長很重要
來談實際一點的。為什麼您應該在意客製化資料擷取?因為它不只是技術升級,而是推動業務成長的加速器。以下是客製化擷取服務在真實世界中帶來成果的方式:
| 商業需求 | 客製化資料爬取解決方案 | 典型成效/投資報酬率 |
|---|---|---|
| 潛在客戶開發 | 從名錄、LinkedIn 或評論網站擷取最新聯絡資訊 | 人工研究時間最多可減少 80%;名單更大也更精準 |
| 競爭對手價格監控 | 追蹤競品網站的價格與庫存,即使版面動態變化也能應對 | 動態定價帶來 4% 以上的銷售提升;利潤率最高可改善 15% |
| 市場情報與研究 | 大規模彙整新聞、評論或監管申報資料 | 資料使用率成長 50% 以上;決策更快、更有依據 |
| 產品型錄更新 | 從多個來源抓取產品資訊,處理子頁面與變體 | 型錄始終保持最新;錯誤與人工更新更少 |
| 營運自動化 | 排程定期爬取報表、合規或庫存資料 | 資料上市時間快 85%;蒐集成本降低 73% |
(, )
結論很簡單:客製化擷取不是奢侈品,而是競爭必需品。真正掌握它的公司,能更快應對市場變化,搶先一步看見推動成長的洞察。
Thunderbit 的做法:把客製化資料擷取變簡單
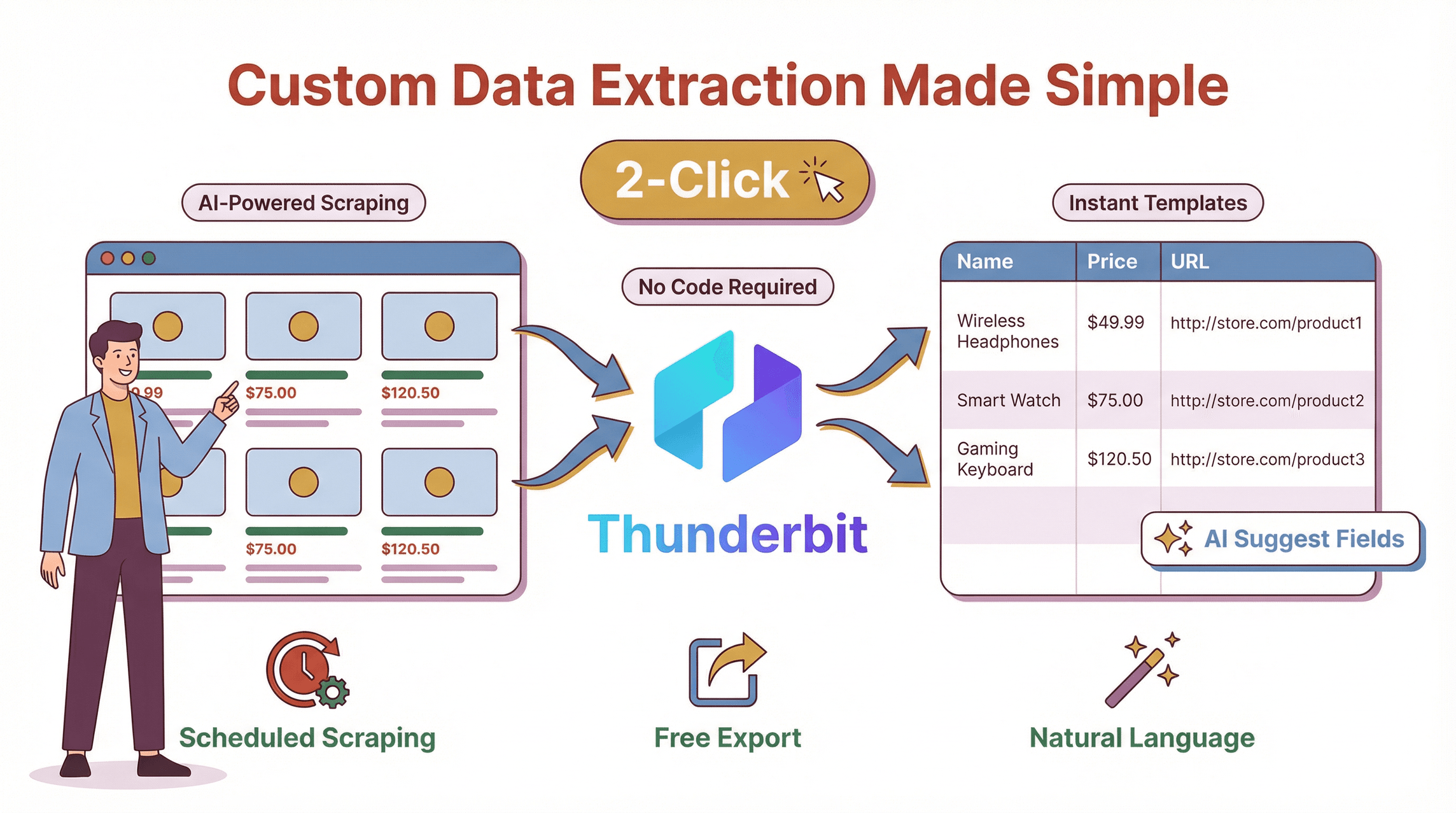
老實說,我打造 Thunderbit 的原因,就是受夠了看團隊被那些笨重、滿是程式碼的爬蟲折磨;網站只要一有風吹草動,它們就壞掉。Thunderbit 是一款,目標是讓客製化資料擷取人人都能上手,不只侷限於開發者。
Thunderbit 的不同之處在於:
- AI 驅動欄位建議: 點一下「AI 建議欄位」,Thunderbit 就會掃描頁面,推薦最適合擷取的欄位——像是「產品名稱」、「價格」、「圖片網址」或「電子郵件」。不用再猜,也不用調 selectors。
- 自然語言提示: 想擷取日期、翻譯描述,或替項目分類?直接用白話告訴 Thunderbit 即可。AI 會自己判斷怎麼做。
- 2 步驟爬取: 前往目標網站、開啟 Thunderbit,然後按下「爬取」就好。沒有程式碼,沒有模板(除非您想用),也沒有頭痛。
- 可處理複雜頁面: Thunderbit 能應付分頁、無限捲動、子頁面,甚至 JavaScript 載入的動態內容。網站一變,它也能跟著調整。
- 子頁面爬取: 如果您需要每個項目的更多細節,Thunderbit 可以自動拜訪每個子頁面(例如產品詳情頁),並補充到表格中。
- 排程爬取: 用自然語言設定重複爬取(像是「每週一上午 9 點」),剩下的就交給 Thunderbit。
- 即時模板: 對 Amazon、Zillow 或 LinkedIn 這類熱門網站,Thunderbit 提供一鍵模板,不需要任何設定。
- 免費資料匯出: 將資料匯出到 Excel、Google Sheets、Airtable、Notion、CSV 或 JSON,沒有付費牆,也沒有額度限制。
Thunderbit 的使命很簡單:讓商務使用者只要描述自己想要什麼,剩下的技術重工就交給 AI。它就像一位永遠不會累、也不會抱怨咖啡的 AI 研究助理。
逐步教學:用 Thunderbit 進行客製化資料爬取
讓我們用 Thunderbit 走一遍真實世界的客製化擷取流程。我會用產品型錄當範例,但不論是名單、評論或其他內容,步驟都差不多。
步驟 1:安裝 Thunderbit
前往 並加到您的瀏覽器。註冊免費帳號即可,免費方案不需要信用卡。
步驟 2:打開目標網站
前往您想爬取的頁面(例如包含產品列表的分類頁)。
步驟 3:啟動 Thunderbit 並使用 AI 建議欄位
點擊 Thunderbit 圖示。按下「AI 建議欄位」——Thunderbit 的 AI 會掃描頁面,並建議像「產品名稱」、「價格」、「圖片網址」等欄位。您可以依需要重新命名、新增或刪除欄位。
步驟 4:用欄位 AI 提示詞自訂
想擷取某個特定內容?針對每個欄位,您都可以加入自訂指令,例如「將日期擷取為 YYYY-MM-DD 格式」或「將描述翻譯成西班牙文」。Thunderbit 的 AI 會在擷取過程中套用您的規則。
步驟 5:啟用分頁或子頁面爬取(如需要)
如果您的資料分布在多個頁面,請開啟分頁功能。如果您需要子頁面的細節(例如產品詳情頁),請使用子頁面爬取——Thunderbit 會逐一拜訪連結,並把額外資訊抓進表格。
步驟 6:點擊「爬取」,看資料流入
Thunderbit 會自動處理導覽與格式化,開始擷取您的資料。進行時,您會看到預覽表格。
步驟 7:匯出您的資料
當您對結果滿意後,可以直接匯出到 。您也可以下載為 CSV 或 JSON。
就是這麼簡單。沒有程式碼,沒有模板(除非您想用),也不會再出現「怎麼還是不行?」的崩潰時刻。想了解更多,請參考 。
Thunderbit 與其他資料擷取服務的比較
來稍微 geek 一點。Thunderbit 與 Azure AI Document Intelligence 或傳統爬蟲相比,表現如何?
| 功能/標準 | Thunderbit | Azure AI Document Intelligence | 傳統爬蟲(例如 Octoparse、Scrapy) |
|---|---|---|---|
| 易用性 | 無需程式碼、AI 驅動、2 步驟設定 | 以開發者為導向、以 API 為主 | 學習曲線陡峭,通常需要寫程式 |
| 客製化擷取 | 自然語言提示詞、AI 欄位 | 文件專用的自訂 ML 模型 | 手動設定、選擇器、腳本 |
| 可處理網頁 | 可以(HTML、動態內容、子頁面) | 不行(專注於文件/PDF) | 可以,但處理動態網站時較吃力 |
| 可處理文件/PDF | 可以(透過瀏覽器/PDF 模式) | 可以(OCR、ML) | 有時可以,但功能有限 |
| 適應性 | AI 會隨版面變化調整 | ML 會適應新文件 | 網站一改版就容易壞,需要更新 |
| 排程 | 內建,自然語言設定 | 透過 API,需要整合 | 有時有,但通常較複雜 |
| 匯出選項 | Sheets、Excel、Airtable、Notion、CSV、JSON | API/JSON,需要開發整合 | CSV、Excel、資料庫,視情況而定 |
| 支援 | 現代 SaaS、回應快速 | 企業級、正式支援 | 社群或供應商,視情況而定 |
| 定價 | 免費方案、按量計費點數 | 依用量計價、偏企業導向 | 免費(開源)或月費方案 |
Thunderbit 的甜蜜點,是為那些想要力量、又不想承受痛苦的商務使用者提供網頁資料擷取。Azure 非常適合大規模文件處理,但不是拿來爬網站的。傳統爬蟲在對的人手上很強大,但需要技術能力與持續維護。
想看更深入的比較,請參考 。
如何為您的需求選擇合適的客製化資料擷取服務
挑選資料擷取服務,不只是看功能,還要看適配度。以下清單可以幫您做決定:
- 資料品質與可靠性: 它能提供準確、乾淨、完整的資料嗎?可以針對您的目標網站進行測試嗎?
- 彈性與自訂性: 它能處理您的特定網站、動態內容、登入或子頁面嗎?能定義自訂欄位或轉換規則嗎?
- 合規與倫理: 它是否遵循法律與倫理規範?是否尊重隱私法與網站條款?
- 擴充性與效能: 它能處理您的資料量與頻率嗎?是否提供雲端爬取或平行處理?
- 整合與工作流程: 可以把資料匯出到您的工具(Sheets、Excel、CRM 等)嗎?支援排程或自動化嗎?
- 支援與文件: 是否有回應快速的支援與清楚的文件?有教學或知識庫嗎?
- 安全性: 它是否能安全處理您的資料?登入資訊有加密嗎?有合規認證嗎?
- 成本: 價格是否透明,並且符合您的需求且具成本效益?有沒有隱藏費用或付費牆?
把每個候選工具都實際試用一次。實際爬一個網站、匯出資料,看看它是否符合您的工作流程。想看更多建議,可以參考 。
將客製化資料爬取整合進您的商業工作流程
擷取資料只是第一步,真正的價值在於把它變成日常營運的一部分。以下是把客製化資料擷取嵌入您業務的方法:
- 自動化重複任務: 使用排程爬取,讓資料保持最新——每日價格檢查、每週名單更新等等。
- 把資料餵進您的工具: 直接匯出到 。再搭配 Zapier、Make 或 n8n 進一步自動化(例如把新名單推送到 CRM)。
- 設定通知: 整合 Slack 或電子郵件,接收關鍵變動通知——例如競爭對手降價或新品上架。
- 在雲端協作: 使用共享資料庫(Airtable、Notion),讓整個團隊都能存取爬下來的資料。
- 端到端自動化: 把爬取與 BI 工具(Tableau、Power BI)結合,建立即時儀表板,或根據爬到的資料觸發動作(例如重新定價)。
想找靈感,可以看看 。
最大化客製化資料擷取服務價值的最佳做法
想把客製化擷取效益發揮到最大?以下是我學到的經驗(有時是很痛的方式):
- 先定義清楚目標: 明確知道您需要哪些資料,以及為什麼需要。不要只是因為可以爬就去爬——要有目的地爬。
- 小規模起步、頻繁測試: 先做小型試驗、檢查資料,確認沒問題再擴大。
- 監控資料品質: 定期抽查結果。建立驗證規則或異常通知。
- 最佳化頻率: 需要多常爬就多常爬,但不要更頻繁。爬太兇可能會被封鎖(也會惹惱您的 IT 團隊)。
- 保持倫理與合規: 尊重網站條款、隱私法與倫理規範。不要爬取敏感或受限制的資料。
- 善用欄位提示詞: 在擷取時利用 AI 提示詞清理、格式化或補強資料。
- 保護您的資料: 妥善處理憑證與爬到的資料——使用加密與存取控制。
- 記錄流程: 紀錄您在爬什麼、從哪裡爬、多久爬一次。這會讓您之後少很多麻煩。
- 持續迭代與改善: 把客製化擷取視為持續演進的流程。隨著需求變化,不斷調整方法。
想看更多最佳實務,可以參考 。
結論與重點摘要:用客製化擷取升級您的資料策略
客製化資料擷取與資料爬取服務,不只是資料控的玩具,而是任何想要快速行動、保持競爭力、做出更聰明決策的企業都必備的工具。手動複製貼上和脆弱腳本的時代已經過去。有了像 這樣的 AI 工具,任何人都能掌握客製化擷取——不需要寫程式。
以下幾點請記住:
- 客製化擷取 = 精準擷取。 取得對的資料,而不只是更多資料。
- 商業價值有實證。 從銷售、營運到市場研究,客製化爬取都能帶來真實 ROI。
- 易用性已經到位。 像 Thunderbit 這類工具,讓每個人都能享受資料擷取的便利。
- 整合才是關鍵。 讓爬下來的資料成為日常流程的一部分,而不是孤島。
- 明智選擇。 根據需求挑工具——測試、比較、再迭代。
- 最佳實務會帶來勝利。 清楚的目標、品質檢查與倫理標準,能讓您的資料策略更強韌。
準備好升級您的資料能力了嗎?,針對一個真實的商業問題試做一次客製化爬取。或者,如果您還想更深入了解,請到 看看深度解析、教學,以及 AI 驅動資料擷取的最新資訊。
網路就是洞察的金礦——客製化擷取就是您的十字鎬。祝您爬取愉快!
常見問題
1. 什麼是客製化資料擷取?它和標準爬取有什麼不同?
客製化資料擷取是指依照您的需求,從任何網站精準抓取您要的資料,並輸出成您想要的格式,即使網站很複雜或是動態內容也沒問題。和只會抓容易取得內容的標準工具不同,客製化擷取會根據您的業務需求與網站版面變化進行調整。
2. 哪些人最能從客製化資料擷取服務中受益?
銷售團隊(用於名單)、行銷(用於競品追蹤)、營運(用於自動化)、產品經理(用於型錄更新)以及市場研究人員(用於情報蒐集),都能從客製化擷取中獲得很大的效益——尤其是當標準工具無法勝任時。
3. Thunderbit 如何讓客製化擷取更簡單?
Thunderbit 會用 AI 建議欄位、處理複雜導覽(分頁、子頁面),並讓您用白話描述想要的內容。沒有程式碼,沒有模板(除非您想用),而且可以立刻匯出到您常用的工具。
4. 在挑選資料擷取服務時,我應該看哪些重點?
請聚焦在資料品質、彈性、合規性、擴充性、整合選項、支援、安全性與成本。在真正採用之前,先用您的實際需求測試每一個服務。
5. 我如何把客製化資料爬取整合進企業工作流程?
自動化重複任務、把資料匯出到 Sheets/Excel/Notion、建立通知,並使用 Zapier 或 n8n 等工作流程工具。目標是:讓網路資料成為日常營運中有生命的一部分,而不是一次性的專案。
準備好看看客製化擷取能為您的業務做到什麼了嗎?,開始把網路混亂轉化為商業清晰。
了解更多