
上週,我們的一位使用者跟我說,他花了整整一個下午,才把 SuperPages 上的水電工名單一筆一筆複製到試算表裡——三個小時才做了 47 列。手腕痠到不行、資料還有錯字,結果連電子郵件都沒拿到。這段經歷讓我特別有感,因為我也走過同樣的路,而這正是我們打造 想解決的問題。
SuperPages 是美國老字號的在地商家目錄之一,由 Thryv 經營,涵蓋範圍很廣,從大城市到各種產業都找得到——水電工、牙醫、律師、HVAC 技師,幾乎一應俱全。早期技術文件曾把它描述成擁有超過 1,100 萬筆商家資訊的全國黃頁資料庫,而現在這個網站依然保有大量在地商家分類。真正的挑戰不是找不到名單,而是怎麼把它們整理成乾淨、資訊完整的潛在客戶清單,還不會把自己逼瘋(或把整個下午賠進去)。
根據 HubSpot 2024 Sales Trends 報告,銷售人員每天真正拿來銷售的時間大約只有 2 小時,其餘時間都被資料輸入、研究這類工作吃掉了。而且有 81% 的銷售專業人士認為 AI 可以幫助他們減少手動作業時間。這篇指南會帶你看三種抓取 SuperPages 潛在客戶的方法——從零程式碼的 AI 工具到 Python 都有——讓你可以依照自己的技術程度挑最適合的方式,把時間留給真正能帶來成效的事情。
什麼是 SuperPages?為什麼銷售團隊這麼愛拿它找名單?
SuperPages 是一個以美國市場為主的線上商家目錄,會列出在地商家的聯絡資訊、分類、評分等資料。你可以把它想成傳統黃頁電話簿的數位升級版——只是現在能依照分類與地區搜尋,而且每筆資料也更完整。
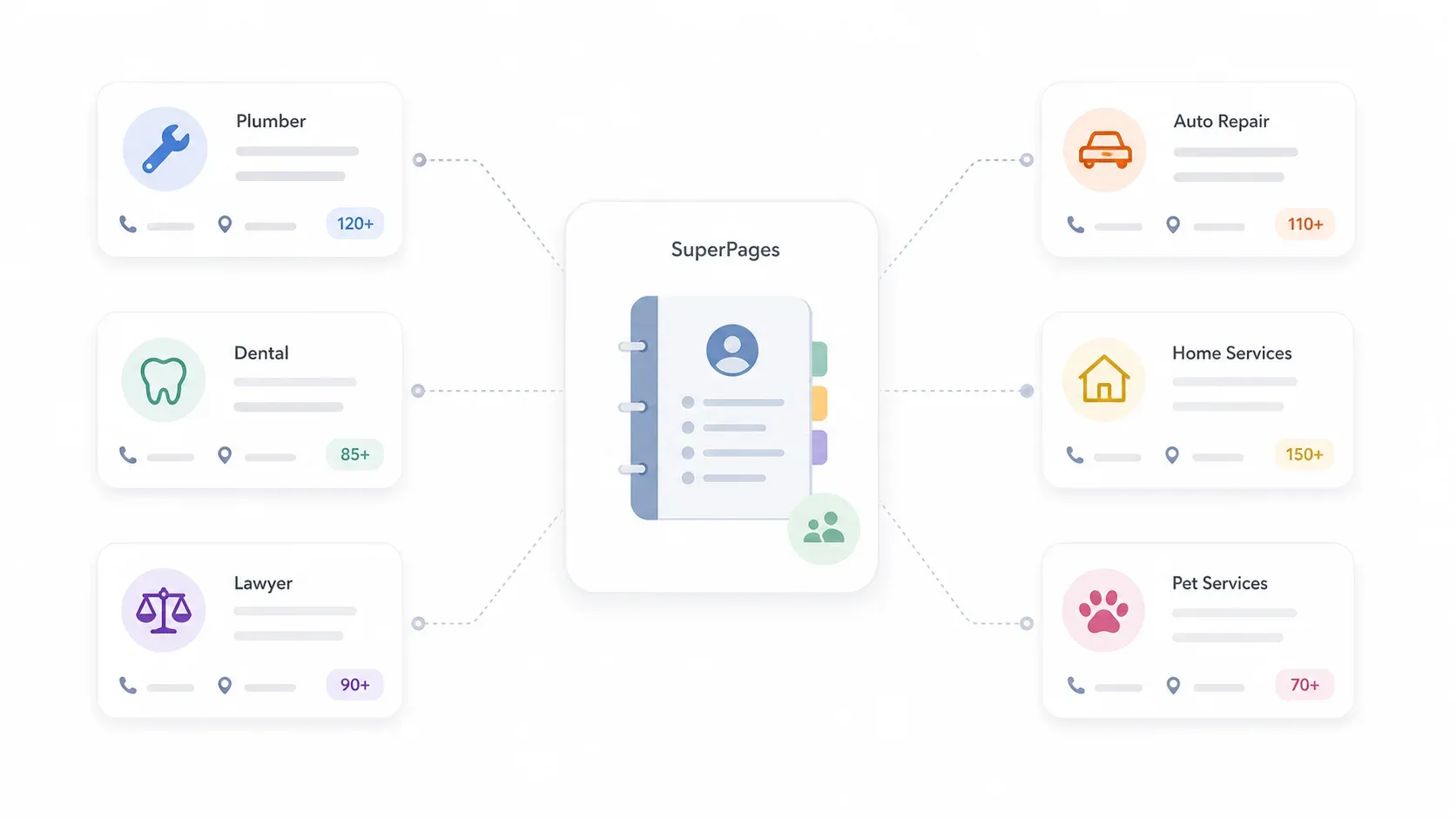
一般來說,SuperPages 的商家列表可能包含以下資訊:
- 商家名稱
- 電話號碼
- 街道地址
- 網站 URL(若有)
- 分類(例如:水電、家事法、HVAC)
- 評分與評論
- 營業時間(通常在詳情頁)
- 描述(詳情頁)
SuperPages 首頁會特別顯示熱門分類,例如居家服務、水電工、電工、牙醫、法律服務、汽車維修、餐廳與寵物服務——而這些剛好就是銷售團隊、代理商,以及在地服務供應商最常做外撥開發的目標族群。
簡單來說,SuperPages 對想開發美國在地商家的任何人來說,都是一座金礦。資料結構清楚、涵蓋面廣,而且分類也很適合直接對應實際的外撥活動。
為什麼要抓取 SuperPages 名單?常見用途有哪些?
手動瀏覽 SuperPages,再把資料複製到試算表,根本就是效率黑洞。抓取工具可以把這個流程自動化,幾分鐘內就給你一份有結構、又聚焦的名單,而不是花上好幾小時。再加上搜尋條件是你自己控制的(分類 + 城市 + 關鍵字),輸出結果通常也比一般買來的名單更精準。
以下是我們使用者最常見的應用場景:
| 使用情境 | 受益對象 | 範例 |
|---|---|---|
| 在地名單開發 | 銷售團隊、代理商 | 建立達拉斯水電工名單,用於冷開發 |
| 競品研究 | 營運、行銷 | 比較某市場中競爭對手的評分與服務 |
| 市場盤點 | 業務開發 | 找出某郵遞區號內所有牙醫,用於新品上市 |
| 供應商搜尋 | 採購、營運 | 找出某地區同時有電話與網站資訊的供應商 |
| 在地 SEO 開發 | 代理商 | 尋找沒有網站或列表資訊不足的商家 |
| 區域規劃 | 外勤業務 | 依城市、郵遞區號或服務區域整理承包商 |
美國 B2B 潛在客戶開發市場在 2024 年估值約為 85 億美元,預計到 2034 年將成長至 182 億美元——也就是說,這類資料的需求完全沒有降溫。剛抓下來、又依分類與地區整理過的名單,通常會比一般購買的名單更有針對性,但在聯繫前仍然需要驗證與去重(後面會談到)。
最終成果長什麼樣:SuperPages 抓取資料範例
在講做法之前,我想先讓你看看最後會拿到什麼。很多指南都會跳過這一步,但如果你願意投入時間,總該知道最後的回報長什麼樣。
下面是一個範例輸出表格(虛構資料,但格式真實):
| 商家名稱 | 電話 | 地址 | 網站 | 分類 | 評分 | 營業時間 | 電子郵件(補全後) |
|---|---|---|---|---|---|---|---|
| Sunset Pipe & Drain Co. | +1 213-555-0148 | 1842 W 7th St, Los Angeles, CA 90057 | sunsetpipe.example | Plumbing | 4.6 | Mon-Fri 7a-6p | service@sunsetpipe.example |
| Arroyo HVAC Pros | +1 626-555-0182 | 72 N Fair Oaks Ave, Pasadena, CA 91103 | arroyohvac.example | HVAC | 4.8 | Mon-Sat 8a-7p | hello@arroyohvac.example |
| Wilshire Family Dental | +1 323-555-0119 | 4100 Wilshire Blvd, Los Angeles, CA 90010 | wilshiredental.example | Dentists | 4.4 | Mon-Thu 9a-5p | appointments@wilshiredental.example |
| Pacific Legal Aid Group | +1 310-555-0173 | 11845 W Olympic Blvd, Los Angeles, CA 90064 | Legal Services | 4.2 | Mon-Fri 8:30a-5:30p | intake@pacificlegal.example | |
| Valley Auto Repair Center | +1 818-555-0198 | 14422 Ventura Blvd, Sherman Oaks, CA 91423 | valleyautorepair.example | Auto Repair | 4.7 | Mon-Sat 8a-6p | info@valleyautorepair.example |
| Echo Park Pet Grooming | +1 213-555-0166 | 1511 Sunset Blvd, Los Angeles, CA 90026 | echoparkpets.example | Pet Grooming | 4.9 | Tue-Sun 9a-5p | booking@echoparkpets.example |
幾個重點值得注意:
- 來自搜尋結果頁:商家名稱、電話、部分地址、分類、評分、列表 URL。
- 來自商家詳情頁(子頁面):完整地址、營業時間、描述、評論,有時還有網站。
- 來自補全:電子郵件(通常只會在商家自己的網站或透過補全工具找到)。
- 來自清理:電話格式化為 E.164、州別/郵遞區號標準化、去重鍵、來源 URL 和抓取時間。
這類輸出可以直接丟進 CRM、Google Sheet 或 Airtable,馬上開始用。
抓取 SuperPages 潛在客戶的 3 種方法:快速比較

不是每個人都一樣熟悉技術操作,也不是每個人都有同樣的耐心。所以我把三種方法並排整理,讓你可以直接挑最適合自己的方式:
| 比較項目 | Thunderbit(AI 零程式碼) | 視覺化爬蟲工具(例如 Octoparse) | Python(Requests + BS4) |
|---|---|---|---|
| 設定時間 | 約 2 分鐘(安裝擴充功能) | 約 15 分鐘(建立流程) | 約 30 分鐘(安裝套件、寫程式) |
| 需要寫程式嗎 | 不需要 | 不需要 | 需要(Python) |
| 分頁處理 | 內建(點擊或捲動) | 需設定 | 手動撰寫程式 |
| 子頁面補全 | 一鍵子頁面抓取 | 需另外建立流程/迴圈 | 需另外寫腳本 |
| 防封鎖能力 | 雲端抓取可處理 | 取決於方案/代理附加功能 | 自行處理(代理、標頭、速率限制) |
| 匯出選項 | Excel、Google Sheets、Airtable、Notion、CSV、JSON | CSV、Excel、資料庫 | 你寫得出來的都行 |
| 最適合誰 | 銷售團隊、代理商、非工程人員 | 半技術型使用者 | 想要完全掌控的開發者 |
我的建議是:如果你想在接下來 2 分鐘內就開始抓資料,直接看方法 1;如果你偏好視覺化流程,也不排斥一些設定,試試方法 2;如果你想要完全控制,而且熟 Python,就直接跳到方法 3。
方法 1:用 Thunderbit 抓取 SuperPages 潛在客戶(AI,零程式碼)
這是從「我有一個 SuperPages 搜尋結果」到「我有一份潛在客戶名單」最快的路徑。沒有程式碼、沒有流程編輯器、也不用設定代理。雖然我有點偏心——畢竟 Thunderbit 是我們自己做的——但我會老實把整個流程講清楚,讓你自己判斷。
難度:初學者
所需時間:約 5 分鐘即可完成完整分類/城市抓取
你需要準備:Chrome 瀏覽器、Thunderbit Chrome 擴充功能(免費方案可用)
第 1 步:安裝 Thunderbit 並開啟 SuperPages
前往 安裝 Thunderbit 擴充功能,大約 1 分鐘就好。安裝完成後,打開 SuperPages 的搜尋結果頁,例如在 superpages.com 搜尋「Los Angeles, CA 的 Plumbers」。
你應該會在瀏覽器工具列看到 Thunderbit 圖示,右側也會有一個可用的側邊面板。
第 2 步:點選「AI Suggest Fields」自動辨識資料欄位
打開 Thunderbit 側邊欄並點選「AI Suggest Fields」。Thunderbit 的 AI 會讀取頁面內容,根據它看到的資訊自動建議欄位——通常包括商家名稱、電話、地址、網站、分類、評分與列表 URL。
你可以在抓取前自行調整、增加或刪除欄位。想加一個像「有網站嗎?」或「服務區域?」這樣的自訂欄位?只要用 Field AI Prompt 直接用自然語言描述即可。例如,你可以要求某欄位把電話格式化成「+1XXXXXXXXXX」,或把商家分類成「住宅」與「商業」。
此時你應該會在 Thunderbit 面板中看到一個已配置欄位的表格預覽。
第 3 步:點選「Scrape」看資料自動填入
按下藍色的「Scrape」按鈕。Thunderbit 會抓取目前頁面上的所有列表,並逐列填入表格。對一般的 SuperPages 搜尋結果頁來說,這大約只要 30 到 45 秒。
Thunderbit 也會自動處理分頁——它會偵測「Next」按鈕或無限捲動,持續抓取直到沒有下一頁,或達到你設定的上限。如果你要抓大量結果(例如某大都會區所有水電工),可以切換到 Cloud Scraping 模式,讓它一次處理最多 50 頁,而且不會占用你的瀏覽器。
第 4 步:使用子頁面抓取補全每筆資料
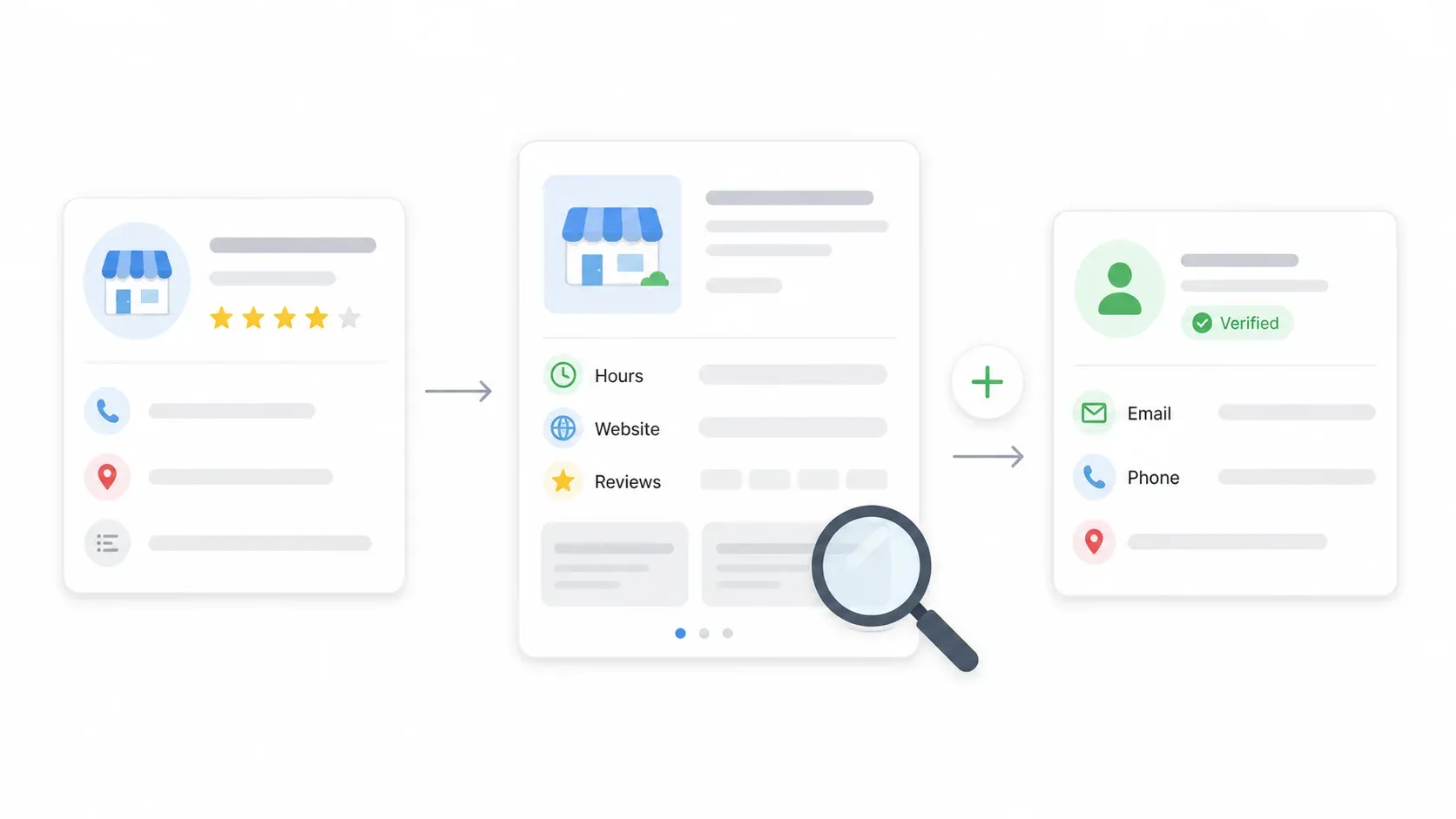
搜尋結果頁只能拿到基本資訊,但真正有價值的內容——營業時間、完整描述、評論,有時還包括 email——通常都在每家商家的詳情頁裡。點選「Scrape Subpages」後,Thunderbit 會逐一進入每筆列表的詳情頁,把營業時間、描述、網站 URL,以及頁面上可見的聯絡資訊補進來。
這整個流程只要一鍵完成。不需要另外建立流程,也不用多做設定。補全後的資料會直接追加到原本的表格中。
第 5 步:把潛在客戶匯出到 Excel、Google Sheets、Airtable 或 Notion
當資料整理滿意後,按下匯出。Thunderbit 可以直接把你的名單送到:
- Google Sheets(很適合做 CRM 前置整理與分享)
- Airtable(輕量級的銷售管線表)
- Notion(研究資料庫)
- Excel / CSV(匯入 CRM)
- JSON(交給開發者)
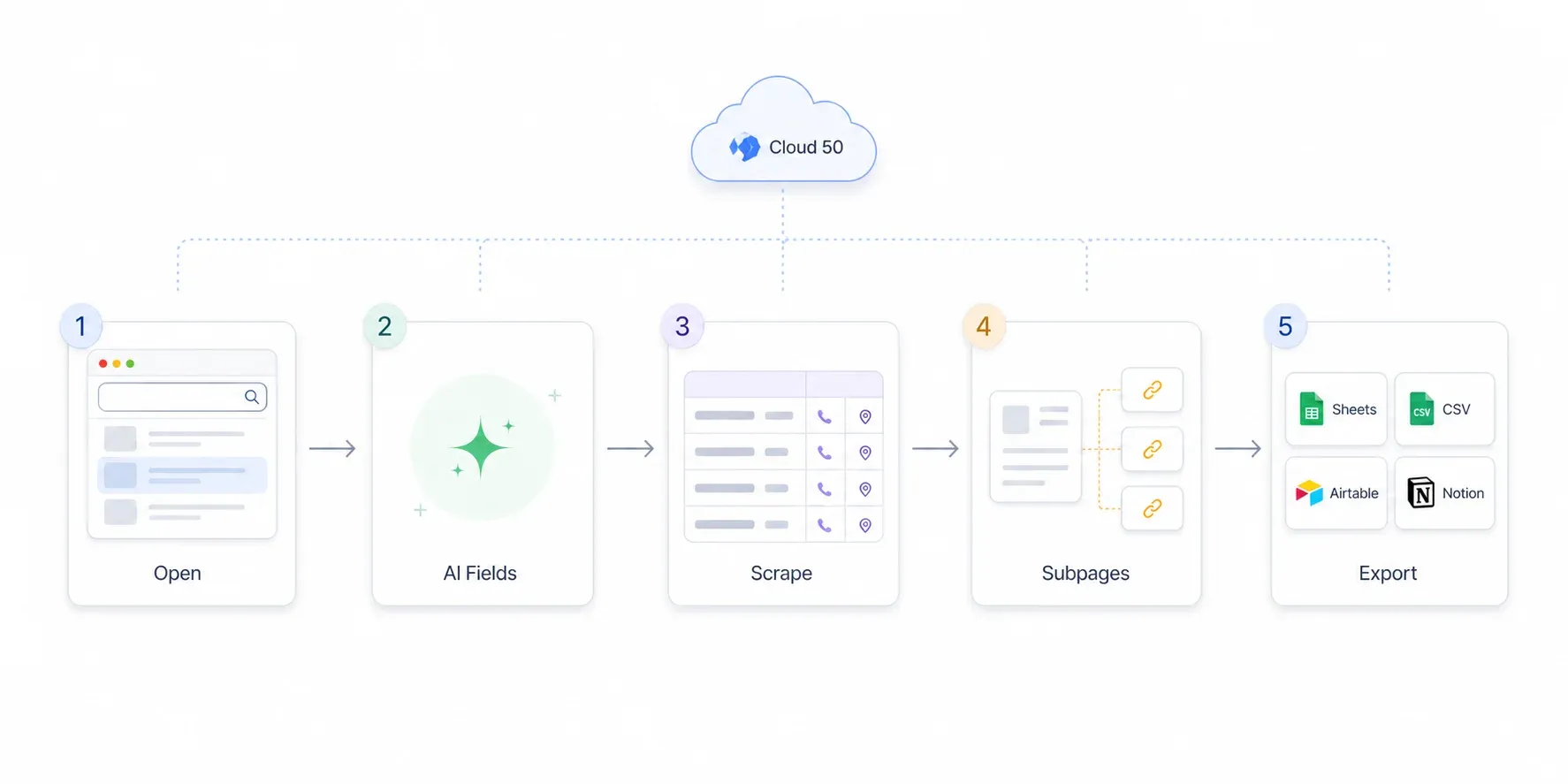
所有匯出選項都是免費的。如果你要把名單送進 HubSpot 或 Salesforce,通常匯出成 CSV 或 Google Sheets 會是最快的做法。
小技巧:最好依「分類 + 城市」抓取,而不是直接搜整個州。像「Dallas TX emergency plumbers」會比「plumbers Texas」更精準、也更能直接拿來行動。建議再加上「Source URL」和「Scraped At」欄位,方便追蹤來源。
方法 2:用視覺化抓取工具抓 SuperPages(以 Octoparse 為例)
像 Octoparse 這類視覺化抓取工具介於中間路線:不用寫程式,但設定與配置會比 Thunderbit 多一些。Octoparse 甚至有內建的 SuperPages 範本,適合較簡單的需求。
難度:中階
所需時間:約 20–30 分鐘(設定 + 抓取)
你需要準備:Octoparse 帳號(有免費方案,但功能有限)
第 1 步:建立新任務並載入 SuperPages URL
打開 Octoparse,點選「New Task」,然後貼上你的 SuperPages 搜尋 URL(例如 https://www.superpages.com/los-angeles-ca/plumbers)。內建瀏覽器會載入該頁面。
第 2 步:自動偵測或手動選取資料欄位
點選「Auto-detect」——Octoparse 會掃描頁面並標示它認為相關的資料欄位。接著查看 Data Preview 面板。依我的經驗,自動偵測通常可以抓到大部分欄位,但也可能把廣告標籤或導覽文字一起抓進來,或者漏掉幾個欄位。你大概率還是得手動補幾個、刪幾個。
根據 Octoparse 的說明文件,自動偵測會建立一個包含分頁與資料擷取步驟的基礎流程,但如果有缺漏,使用者仍需手動補資料。
第 3 步:建立流程並設定分頁
點選「Create workflow」。Octoparse 會產生一套逐步的動作流程。檢查分頁步驟,確認它會正確點擊「Next」或載入更多結果。如果你要抓每家商家的詳情頁資料(像營業時間、email、描述),就需要在流程中再加一個詳情頁迴圈或子頁面動作。這會比 Thunderbit 的一鍵子頁面方式更複雜。
第 4 步:執行任務並匯出資料
在本機執行任務(適合小規模工作),或在 Octoparse 雲端執行(適合排程或較大型工作——雲端功能屬於付費方案)。完成後,可匯出為 CSV、Excel 或 JSON。
要注意的限制:Octoparse 免費方案包含 10 個任務、每月最多 50,000 列,而且只能本機擷取。雲端執行、IP 輪換、CAPTCHA 解決以及部分匯出整合都需要付費方案(年繳方案起價約每月 69 美元)。
方法 3:用 Python 抓 SuperPages(Requests + BeautifulSoup)
這是開發者路線。你會得到完全的控制權,但也要承擔全部責任。如果你習慣寫與維護 Python 腳本,這個方法最有彈性,但也最容易讓你頭痛。
難度:進階
所需時間:約 30–60 分鐘(設定 + 開發 + 除錯)
你需要準備:Python 3.x、pip、requests、beautifulsoup4、lxml、程式編輯器
第 1 步:建立 Python 環境
1python -m venv .venv
2source .venv/bin/activate
3pip install requests beautifulsoup4 lxml pandas第 2 步:檢查 SuperPages 的 HTML 結構
在 SuperPages 的搜尋結果頁按下開發者工具(F12)。找出商家名稱、地址、電話、網站和詳情頁連結的 CSS 選擇器。要記住:HTML 結構可能隨時變動,而且通常不會先通知你,這代表你的選擇器隨時都可能失效。
第 3 步:撰寫列表抓取器並處理分頁
下面是一個簡化範例。重要提醒:我測試時,直接對 SuperPages 發送請求會回傳 Cloudflare 的「Attention Required」封鎖頁。單純的 Requests 腳本在大量抓取時可能會失敗——你可能需要瀏覽器 session、速率限制、重試機制,或其他授權方式。
1import csv, time
2from urllib.parse import urljoin
3import requests
4from bs4 import BeautifulSoup
5BASE_URL = "https://www.superpages.com"
6HEADERS = {
7 "User-Agent": (
8 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
9 "AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/125.0 Safari/537.36"
11 )
12}
13def fetch(url):
14 resp = requests.get(url, headers=HEADERS, timeout=20)
15 resp.raise_for_status()
16 if "Attention Required" in resp.text or "Cloudflare" in resp.text:
17 raise RuntimeError("已被封鎖。請放慢速度,或改用瀏覽器/雲端抓取。")
18 return BeautifulSoup(resp.text, "lxml")
19def parse_listing(card):
20 name_el = card.select_one(".business-name, a.business-name, h2 a, h3 a")
21 phone_el = card.select_one(".phones, .phone, [class*=phone]")
22 address_el = card.select_one(".street-address, .adr, [class*=address]")
23 website_el = card.select_one("a.track-visit-website, a[href*='http']")
24 rating_el = card.select_one(".rating, [class*=rating]")
25 detail_url = urljoin(BASE_URL, name_el.get("href")) if name_el and name_el.get("href") else ""
26 return {
27 "business_name": name_el.get_text(" ", strip=True) if name_el else "",
28 "phone": phone_el.get_text(" ", strip=True) if phone_el else "",
29 "address": address_el.get_text(" ", strip=True) if address_el else "",
30 "website": website_el.get("href", "") if website_el else "",
31 "rating": rating_el.get_text(" ", strip=True) if rating_el else "",
32 "detail_url": detail_url,
33 }
34def scrape_search(search_url, pages=3):
35 all_rows = []
36 for page in range(1, pages + 1):
37 page_url = f"\{search_url\}?page=\{page\}"
38 soup = fetch(page_url)
39 cards = soup.select(".result, .organic, [class*=result]")
40 if not cards:
41 break
42 for card in cards:
43 all_rows.append(parse_listing(card))
44 time.sleep(5)
45 return all_rows
46if __name__ == "__main__":
47 rows = scrape_search("https://www.superpages.com/los-angeles-ca/plumbers", pages=2)
48 with open("superpages_leads.csv", "w", newline="", encoding="utf-8") as f:
49 writer = csv.DictWriter(f, fieldnames=sorted({k for row in rows for k in row}))
50 writer.writeheader()
51 writer.writerows(rows)第 4 步:抓取詳情頁做資料補全
另外寫一個函式,逐一前往每個詳情頁 URL,擷取營業時間、email、描述和評論。這也代表你得自己處理速率限制、錯誤處理,以及可能需要代理伺服器。
第 5 步:將資料存成 CSV 或 JSON
可用 Python 的 csv 或 json 模組。另外你還需要自己寫去重、清理與匯出邏輯。
常見問題:
- SuperPages 可能會用 Cloudflare 或類似的反機器人機制阻擋請求(我測試時確實遇過)。
- 這裡的選擇器故意寫得比較寬鬆,因為 SuperPages 的標記可能會變動。
- 不要以為搜尋結果頁會有 email,幾乎不會。
- 正式上線的爬蟲需要檢查 robots/TOS、速率限制、重試/退避、結構化日誌與錯誤捕捉。
如果你想更深入了解 Python 抓取,可以看看我們的 Python 網頁爬取指南或 BeautifulSoup 教學。
從原始資料到真正可用的潛在客戶:完整流程(抓取 → 清理 → 驗證 → 匯入 CRM)
這也是大多數抓取指南會停下來的地方,但真正的價值其實才正要開始。抓取只是拿到原料;要把它變成可直接使用的名單,還需要幾個步驟。
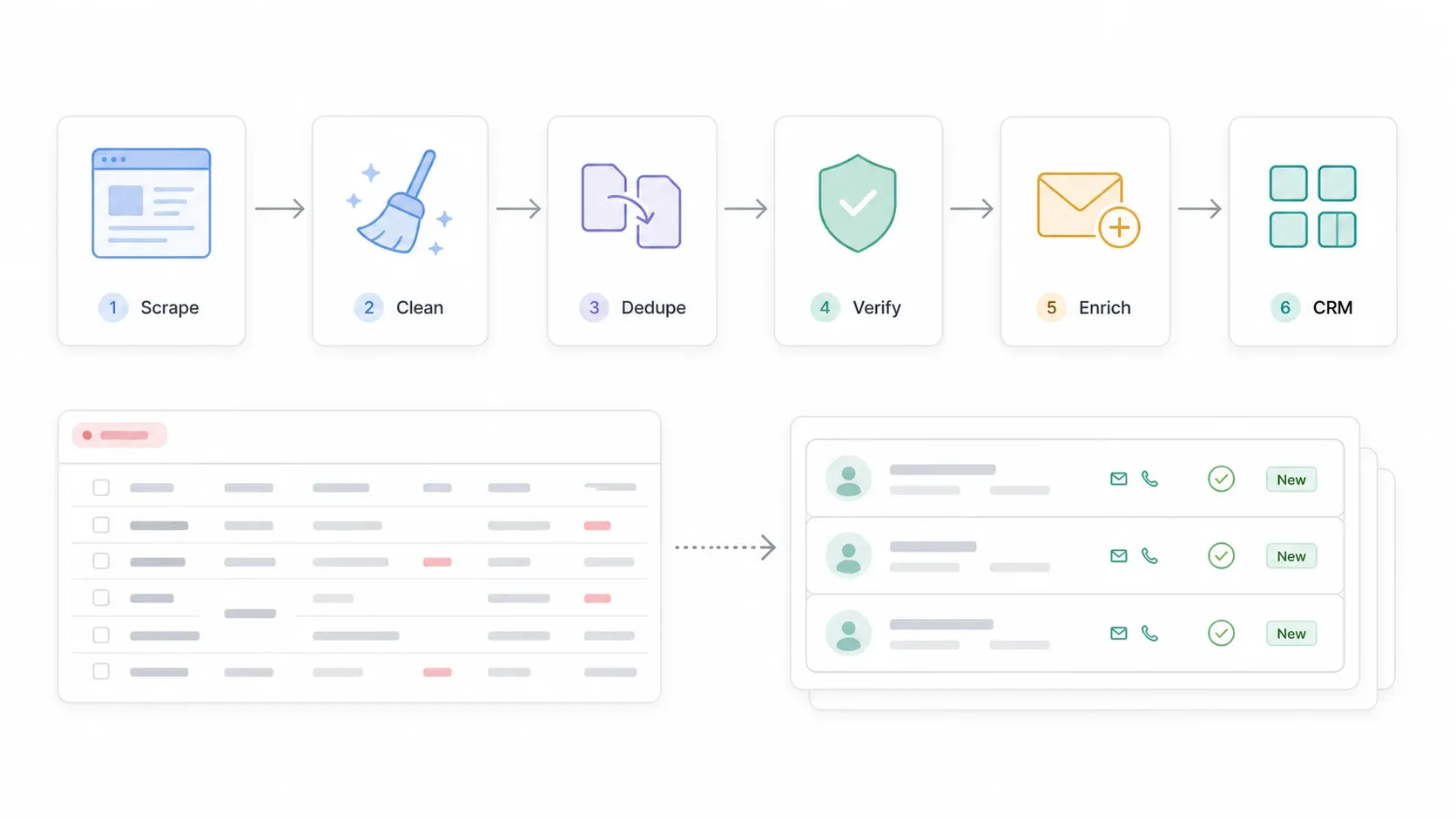
整個流程大致如下:
SuperPages 搜尋 → 抓取列表 → 抓取詳情頁/網站 → 匯出到 Google Sheets 或 CSV → 清理電話、地址、分類 → 去重 → 驗證 email/電話 → 補充缺失聯絡資訊 → 匯入 CRM → 合規開發
去重:移除重複列表
SuperPages 常會把同一家商家放在不同分類裡。如果你同時抓了某城市的「plumbers」與「drain cleaning」,就很容易出現重複資料。
- 主要去重鍵:標準化電話號碼 + 標準化街道地址。
- 次要:網域 + 城市。
- 備用:商家名稱 + 郵遞區號(連鎖品牌請人工檢查)。
在 Google Sheets 中,可以用 =UNIQUE(A:H) 做完全相同列的去重;或者建立一個輔助欄位,例如 =LOWER(REGEXREPLACE(B2&C2,"[^a-zA-Z0-9]","")),用來抓近似重複。Excel 則可使用「資料 > 移除重複項目」。
資料清理:標準化電話、地址與格式
- 將電話號碼格式化為 E.164(美國格式:+1 加 10 位數字)。這是多數 CRM 和撥號系統期望的格式。你可以在 Thunderbit 中透過 Field AI Prompt,在抓取時就自動格式化。
- 標準化地址:展開縮寫、補齊缺少的郵遞區號,必要時拆成街道/城市/州別/郵遞區號欄位。
- 移除 URL 中的 HTML 雜訊、多餘空白與追蹤參數。
- 加上
source_directory、source_url、scraped_at欄位,方便追蹤。
在聯繫前先驗證 email 與電話
不要把你抓來的每一個 email 都直接拿去發冷郵件。驗證能保護寄件者聲譽,也能降低退信率。
- Email 驗證:ZeroBounce(起價約 39 美元,可換 2,000 點數,另有每月 100 點免費額度)或 Bouncer(1,000 點 8 美元,點數永不過期)都是不錯的選擇。
- 電話驗證:Twilio Lookup 提供格式化與驗證,基本功能免費;來電顯示查詢每筆 0.01 美元。
- Thunderbit 的免費 Email Extractor 與 Phone Number Extractor 可以抓出列表頁漏掉的聯絡資訊。
補全:SuperPages 沒有 email 時怎麼找?
很多 SuperPages 列表根本不顯示 email,尤其是搜尋結果頁。可以這樣做:
- 抓取商家網站的 Contact、About 或頁尾頁面。Thunderbit 的 Subpage Scraping 或 Email Extractor 可以批次處理。
- 使用補全工具,例如 Apollo、BetterContact、Icypeas 或 Prospeo。先提醒一下:對小型在地商家(像兩人水電行、個人牙醫診所),大型 B2B 資料庫通常會找不到什麼。對這類客群來說,從網站先抓通常更有效。
- 結合多個目錄。把 SuperPages、Yellow Pages 與 Google Maps 同一分類/城市的資料都抓下來,再合併去重。重疊資料會幫你補齊更完整的紀錄。
如果你曾經把一份在地 SMB 名單丟進 Apollo,結果大多都是空白,你不是唯一一個。這也是為什麼對這種客群來說,先從網站抓資料特別重要。
匯入 CRM:把名單放進 HubSpot、Salesforce 或 Google Sheets
- HubSpot:前往 Data Management > Data Integration > Import data > Quick import(僅聯絡人)。上傳
.csv或.xlsx。HubSpot 的匯入指南會說明欄位對應。 - Salesforce:使用 Data Import Wizard。先準備 CSV,將來源欄位對應到 Salesforce 欄位,再執行匯入。
- Google Sheets / Airtable / Notion:Thunderbit 可以直接匯出到這三者,不需要先經過 CSV。
小提醒:匯入前先把你抓到的欄位對應到 CRM 欄位。先花幾分鐘做欄位映射,之後可以省下好幾個小時的人工整理。
SuperPages 與其他在地商家目錄相比,哪裡最值得抓?
SuperPages 是很好的起點,但不是唯一值得抓的目錄。下面看看它的比較表現:
| 目錄 | 名單量 | 可取得的資料欄位 | 資料新鮮度 | 反爬難度 | 最適合用途 |
|---|---|---|---|---|---|
| SuperPages | 很大(以美國為主) | 名稱、電話、地址、網站、分類、評分 | 中等 | 中等 | 居家服務、承包商、中小企業 |
| Yellow Pages | 很大(以美國為主) | 與 SuperPages 類似 | 中等 | 中等 | 一般在地商家開發 |
| Google Maps | 極大(全球) | 名稱、電話、地址、網站、評論、營業時間、照片 | 高(由業主更新) | 高(反機器人較強) | 最新的在地資料 |
| Yelp | 很大(以美國為主) | 名稱、電話、地址、評論、價格帶 | 高 | 高 | 餐廳、零售、服務業 |
| Manta | 中等 | 名稱、電話、地址、營收估算、員工數 | 中等 | 低 | B2B 開發(營收/員工資料) |
| BBB | 中等 | 名稱、電話、地址、認證、客訴 | 中等 | 低 | 重視信譽/已審核的商家 |
來源:SuperPages 首頁、VLDB SuperPages 論文、Google Places API 文件、Yelp Places API 文件、Manta 首頁、BBB 指南。
Thunderbit 可跨這些來源使用——包括 Google Maps 和 SuperPages 這類熱門網站的 Instant Templates——所以你可以把同一套流程套用到多個來源,再把名單整合起來。根據我的經驗,最好的做法通常是針對同一分類/城市抓兩到三個目錄,再去重。重疊資料會補足缺口,也能讓你看到更完整的全貌。
如果你想了解更多其他目錄的抓取方式,可以參考我們的 、 與 指南。
抓取 SuperPages 潛在客戶時的法律與倫理提醒
我不是律師,這也不是法律意見——但我在這個領域待得夠久,知道忽略合規很容易出事。下面是實務上你該知道的重點。
公開商業資料 vs. 個人資料
商家列表——公司名稱、商業電話、商業地址、公司網站——通常會被視為公開的商業資料。這和 GDPR 或 CCPA 下的個人消費者資料不同。但「公開」不代表「沒有規範」。務必先查看網站的使用條款。
SuperPages 的使用條款(2019 年 7 月更新)包含「禁止資料探勘」條款:未經 Thryv 事先同意,使用者不得使用機器人、爬蟲、蜘蛛程式或類似工具收集或擷取資料。本文雖然有介紹方法與流程,但在大規模抓取前,你還是應先審查這些條款,必要時取得授權。
開發外聯合規:CAN-SPAM 與 TCPA 基本原則
如果你打算用抓來的 email 做冷郵件,FTC 的 CAN-SPAM 指南要求你必須:
- 不可使用虛假或誤導性的寄件標頭
- 不可使用欺騙性的主旨
- 必要時需清楚標示這是廣告訊息
- 必須提供有效的實體郵寄地址
- 必須提供明確的退訂機制,且要迅速處理退訂
如果你要用抓來的電話號碼做冷電訪,請先查詢 National Do Not Call Registry,並遵守 TCPA 規範——尤其是自動撥號、預錄語音與簡訊相關限制。FTC 也在 2024 年宣布加強對欺騙性 B2B 電銷與 AI 詐騙來電的保護措施。
快速合規檢查清單
- ✅ 只抓公開列出的商業資料
- ✅ 審查 SuperPages 使用條款,必要時取得授權
- ✅ 聯繫前先驗證聯絡資訊
- ✅ Email 中要附上退訂選項
- ✅ 遵守 robots.txt 與速率限制
- ✅ 維護拒收名單與 email 屏蔽名單
- ⚠️ 避免抓取個人/消費者資料
- ⚠️ 未經法律審查,不要轉售原始抓取資料
選擇你的方法,開始建立名單吧
抓取 SuperPages 名單不只是從網頁上撈出幾列資料而已。真正的價值來自完整流程:抓取、清理、去重、驗證、補全、匯入,並且合規地展開外聯。
快速總結如下:
- Thunderbit 是銷售團隊、代理商與非工程人員最快的選擇。兩次點擊就能抓取,一次點擊就能用子頁面補全,還能免費匯出到 Google Sheets、Airtable、Notion 或 Excel。可以先免費試用。
- Octoparse 是一個不錯的視覺化流程工具,適合想要更多設定控制的半技術型使用者。
- Python 則提供開發者最大的彈性——但也帶來維護成本、反封鎖問題,以及沒有內建補全的缺點。
- 別忘了:同一套流程也適用於 Yellow Pages、Google Maps、Yelp、Manta 和 BBB。抓多個來源、合併、去重,你就能拿到盡可能完整的在地名單。
如果你想看看 Thunderbit 實際怎麼運作,可以到我們的 看教學影片,或瀏覽 找出最適合你團隊的方案。
現在就把那些目錄頁變成銷售管道吧——願你的電話號碼永遠格式正確,願你的 email 永遠已驗證。
常見問題
抓取 SuperPages 做潛在客戶開發是否合法?
抓取公開可見的商家目錄資料,用於 B2B 研究,是很常見的做法,但 SuperPages 的使用條款禁止在未經 Thryv 事先同意下進行資料探勘。務必先閱讀網站條款、在需要時取得授權,並遵守 CAN-SPAM 與 TCPA 這類外聯法規。本文僅供教學用途,如何合規使用仍由你自行負責。
我能從 SuperPages 拿到哪些資料?
一般抓取結果會包含商家名稱、電話、地址、網站、分類、評分、營業時間與描述。email 通常不會直接出現在搜尋結果頁——你通常需要進入商家詳情頁,或到商家自己的網站(透過子頁面抓取或 email 擷取工具)才能找到。
不會寫程式也能抓 SuperPages 嗎?
可以。像 Thunderbit(AI Chrome 擴充功能)和 Octoparse(視覺化抓取工具)都能讓你不用寫程式就抓 SuperPages。Thunderbit 是最快的選擇——安裝擴充功能、打開 SuperPages 搜尋頁、點「AI Suggest Fields」,再點「Scrape」即可。
抓 SuperPages 時要怎麼處理分頁?
Thunderbit 會自動處理分頁——它能偵測「Next」按鈕或無限捲動並持續抓取。Octoparse 則需要你在流程中設定分頁步驟。Python 需要自己寫頁面迴圈邏輯(例如遞增頁碼、判斷最後一頁)。
我要怎麼從 SuperPages 名單拿到 email?
大多數 SuperPages 列表不會在搜尋結果頁顯示 email。你可以用 Thunderbit 的 Subpage Scraping 進入每個詳情頁,或在商家網站上使用免費的 Email Extractor。若還有缺口,可以試試 Apollo、BetterContact 或 Prospeo 等補全工具——但對小型在地商家來說,通常「先從網站抓」會比大型 B2B 資料庫更有效。
延伸閱讀