

如今,幾乎一半的網路流量都來自機器人,而且大多都在大規模抓取連結、資料與 URL。若你還停留在手動處理,競爭力只會越來越跟不上。
我實測了 12 款連結擷取工具——從 AI 驅動的 Chrome 擴充功能到 Python 函式庫——想看看當你需要快速抓取成千上萬個 URL 時,哪些工具真的夠力。
以下是我的測試結果。
為什麼連結擷取器很重要
說真的,網路上的資料多到滿出來,企業都在想辦法把這些雜亂資訊轉成可執行的洞察。連結擷取器 和 URL 擷取器 現在已經是很多團隊的核心工具,特別適合想要:
- 開發潛在客戶:銷售團隊可以在幾分鐘內從名錄或 LinkedIn 擷取公司頁面連結,再把這些 URL 丟進工具中抓取聯絡資訊,省去沒完沒了的點擊。
- 彙整內容並提升 SEO:行銷人員可以收集部落格中的所有文章 URL、監控競爭對手的反向連結,或檢查網站架構與失效連結。
- 監控競品並進行市場研究:營運團隊可以自動蒐集新產品、價格頁或新聞稿連結,輕鬆掌握競爭動態。
- 自動化流程並節省時間:現代連結爬蟲能處理大量 URL、爬取子頁面,並將資料匯出成結構化格式(CSV、Excel、Google Sheets、Notion,通通有)。也就是說,你再也不必長時間複製貼上,或費力整理亂七八糟的文字檔。
考量到每天都有數百億個網頁被爬取,靠人工處理根本不切實際。選對連結擷取器,就像多了一位永遠不累、永遠不漏抓連結、也不會要求喝咖啡休息的超強助理。
我們如何挑選最佳連結擷取器
市面上的工具這麼多,要挑出合適的連結擷取器,就像在科技展上快速約會——每個人都說自己是「對的人」,但真正能交出成果的只有少數幾款。我是這樣篩選出前 12 名的:
- 易用性:不會寫程式的人能不能不用懂複雜 regex 就上手?無程式碼與低程式碼方案會加分。
- 大量與多層級擷取:能不能一次處理上百個 URL?能不能自動爬子頁面並跟進連結?
- 匯出與整合:能不能匯出到 CSV、Excel、Google Sheets、Notion、Airtable,或透過 API 連接?越少手動處理越好。
- 使用者類型與彈性:是給商務使用者、分析師,還是開發者?有些工具是通用型,有些則更專精。
- 進階功能:AI 辨識、排程、雲端擴充、資料清理,以及常見網站模板。
- 價格與擴展性:免費方案、按量計費,還是企業方案?我特別比較了各自的性價比。
我也把瀏覽器擴充功能到企業級平台都納入評測,所以不管你是獨立創業者,還是 Fortune 500 的資料團隊,都能找到適合的工具。
Thunderbit:最適合商務使用者的智慧連結擷取器
先從最前面開始。Thunderbit 是我最推薦的連結擷取工具,不只是因為我有參與打造它。Thunderbit 是一款由 AI 驅動的網頁爬蟲 Chrome 擴充功能,專為想快速看到成果的商務使用者設計。
Thunderbit 的亮點是什麼?它就像一位真的聽得懂指令的 AI 實習生。你只要用自然語言描述需求(例如:「把這個頁面上的產品連結和價格都抓下來」),Thunderbit 的 AI 就會自動理解並處理後續。完全不需要調整 selector,也不用自己寫腳本。
而且它不只如此:
- 支援批量 URL:貼上一個 URL,或一次貼上數百個都沒問題,Thunderbit 都能一口氣處理。
- 支援子頁面導覽:如果你要先抓列表頁,再逐一進入詳細頁抓更多連結,Thunderbit 的多層級擷取邏輯可以一次搞定。
- 結構化匯出:擷取完連結後,你可以重新命名欄位、分類資料,並直接匯出到 Google Sheets、Notion、Airtable、Excel 或 CSV,不必再後製整理。
使用 AI 從任何網站擷取連結 Get Started Free
Thunderbit 目前已獲全球超過 30,000 位使用者信任,涵蓋銷售團隊、房地產經紀人、獨立電商賣家等。沒錯,它也有免費方案(可抓取最多 6 頁,或在試用加成下最多 10 頁),讓你可以零風險先試用看看。
Thunderbit 的亮眼功能
來看看 Thunderbit 到底強在哪裡:
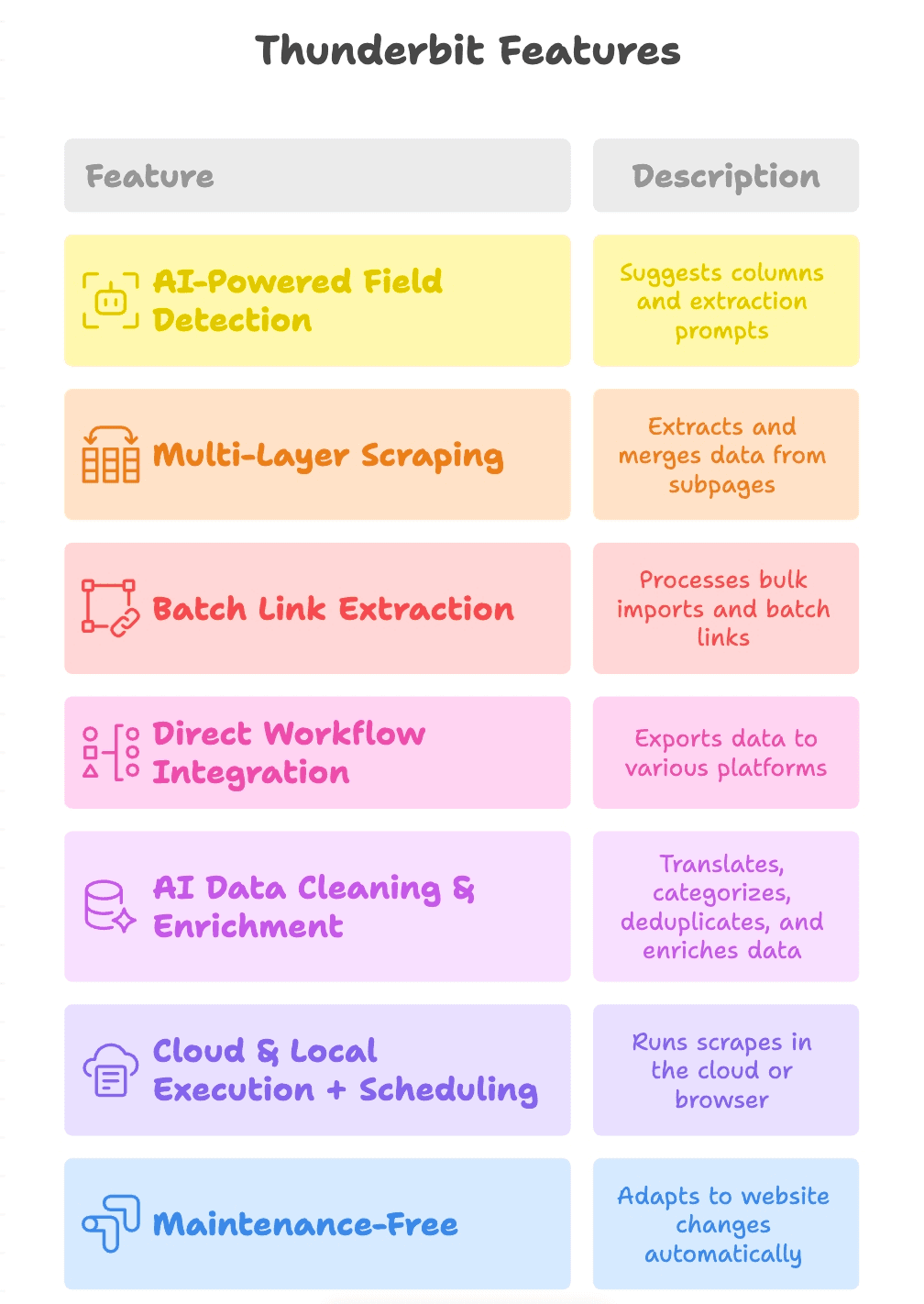
- AI 自動欄位辨識:只要點一下「AI Suggest Fields」,Thunderbit 就會讀取頁面內容,自動建議欄位(例如「產品連結」、「PDF URL」、「聯絡 Email」),甚至還會為每個欄位生成擷取提示詞。
- 多層級擷取:Thunderbit 可以從主頁一路跟進到子頁(像產品詳情頁或 PDF 下載頁),再把更多連結擷取出來,最後合併成一張表。
- 批次連結擷取:不管你是抓一頁還是一千頁,Thunderbit 都能輕鬆處理批量匯入與批次擷取。
- 直接串接工作流程:結果可直接匯出到 Google Sheets、Notion、Airtable,或下載成 CSV/Excel,資料會準確送到團隊需要的位置。
- AI 資料清理與補強:Thunderbit 在擷取時還能幫你翻譯、分類、去重,甚至補強資料,讓輸出結果不是原始亂流,而是可直接使用的內容。
- 雲端與本機執行 + 排程:你可以用雲端執行提升速度,也能在瀏覽器本機執行以處理需要登入的網站。還能設定定期排程,持續更新資料。
- 幾乎免維護:Thunderbit 的 AI 會自動適應網站變動,讓你少花時間修壞掉的爬蟲,多把時間用在產出成果上。
Octoparse:人人都能上手的無程式碼連結爬蟲
Octoparse 是無程式碼爬蟲領域的經典工具。它是一款桌面應用程式(Windows/Mac),採用視覺化、點選式介面。你只要打開網頁、點選想抓的連結,Octoparse 就會幫你處理後面的流程。
- 新手友善:完全不需要寫程式,點一點就能抓。
- 支援分頁與動態內容:Octoparse 可以點「下一頁」、捲動頁面,甚至登入網站。
- 雲端爬取與排程:付費方案可在雲端執行任務,並設定週期性工作。
- 匯出選項多:可下載成 CSV、Excel、JSON,或推送到資料庫。
免費方案對小型任務很夠用(最多 10 個任務、每月 50,000 筆資料列),但重度使用者就需要付費方案,價格約從每月 75 美元起。
Apify:適合自訂工作流程的彈性 URL 擷取器
Apify 就像網頁爬蟲界的瑞士刀。它不只有預先做好的「actors」(爬蟲工具)市集,也能讓你用 JavaScript 或 Python 自己寫腳本。
- 預建且可客製:可直接使用社群 actors 處理常見任務,也能打造自己的自訂工作流程。
- 支援大量與排程爬取:可將 URL 排隊、平行執行任務,並設定週期性爬取。
- API 優先:可匯出成 JSON、CSV、Excel 或 Google Sheets,並整合到你的資料管線中。
- 按量計費:每月有免費額度,之後依使用量計價。
Apify 很適合半技術團隊與開發者,因為它兼具彈性與擴展性。
Bright Data URL Scraper:企業級連結爬取方案
Bright Data 是為需要大規模爬取的企業打造的工具。他們的 Data Collector 提供預設的 URL Scraper,適合高流量任務。
- 支援超大規模:可抓取數千甚至數百萬頁,搭配強大的代理基礎架構降低封鎖風險。
- 預設模板:針對電商、社群、房地產等常見場景都已有現成爬蟲。
- 企業功能完整:包含合規工具、專家支援與進階反封鎖能力。
- 價格:約從 350 美元/100,000 次頁面載入起跳,明顯是為大企業設計。
如果你是新創公司,這工具可能有點過頭;但若你要的是關鍵任務級、大量爬取能力,Bright Data 絕對是強悍的選擇。
WebHarvy:用點選操作就能完成的視覺化連結擷取器
WebHarvy 是一款桌面應用程式(Windows),你只要在內建瀏覽器裡點選連結,就能開始擷取。
- 超級簡單:點一下連結,WebHarvy 會自動標出所有類似元素供你擷取。
- 支援正則表達式:內建常見任務模式,不必寫程式。
- 可匯出到 Excel、CSV、JSON、XML、SQL:很適合想用熟悉格式接收資料的商務使用者。
- 一次買斷:付一次費用,永久使用。
非常適合小型企業、研究人員,或任何想快速、不費力取得連結、又不想寫程式的人。
Web Scraper(Chrome 擴充功能):在瀏覽器內快速抓連結
Web Scraper Chrome Extension 是一款免費且開源的工具,能把你的瀏覽器變成爬蟲。
- 自訂 Sitemap:告訴它怎麼導覽,以及要擷取哪些內容。
- 支援分頁與多層級爬取:可爬分類、子分類與詳細頁。
- 可匯出 CSV/XLSX:直接在瀏覽器裡下載資料。
- 社群模板豐富:許多熱門網站都有共享 sitemap。
它很適合臨時任務、一次性工作,或預算有限的學生與小團隊。
ScraperAPI:適合開發者的可擴充連結爬蟲
ScraperAPI 專為想要大規模抓取網頁、但不想煩惱代理、封鎖或 CAPTCHA 的開發者而設計。
- API 驅動:送出 URL,就能拿回 HTML 或已擷取的資料。
- 支援規模與反機器人措施:內建代理輪換、JS 渲染與 CAPTCHA 解題。
- 可與你的程式碼整合:可搭配 Python、Node.js,或任何語言使用。
- 價格:有免費方案(約 1,000 次 API 呼叫),之後依請求量計價。
非常適合客製化爬蟲,或需要大規模穩定性與速度的情境。
ParseHub:具備進階選取能力的視覺化連結爬蟲
ParseHub 是一款桌面應用程式(Windows、Mac、Linux),可讓你用視覺化方式建立爬取專案。
- 進階選取與導覽:透過點選、迴圈與條件式擷取連結,即使是動態或隱藏元素也能抓。
- 支援巢狀頁面:可先爬分類頁,再進到詳細頁,接著擷取更多連結。
- 可匯出 CSV、Excel、JSON:付費方案還提供雲端執行與 API 存取。
- 免費方案:可建立 5 個專案,每次執行最多 200 頁。
ParseHub 是行銷人員與研究人員的熱門選擇,因為它兼具強大功能與無程式碼體驗。
Scrapy:給 Python 開發者的連結擷取利器
Scrapy 是 Python 開發者想要完全掌控爬取流程時的黃金標準。
- 以程式為核心:可建立自訂 spider,以任何規模抓取並擷取連結。
- 支援分散式爬取:效率高、非同步,且高度可客製化。
- 可匯出 CSV、JSON、XML 或資料庫:輸出格式完全由你決定。
- 開源且免費:但你需要自行維護運行環境。
如果你熟悉 Python,Scrapy 的功能幾乎無可匹敵。
Diffbot:以 AI 驅動的結構化資料連結爬蟲
Diffbot 可以說是網頁爬蟲界的「AI 大腦」。它會自動分析頁面並回傳結構化資料——包含連結——幾乎不需要手動設定。
- 自動內容辨識:輸入 URL,就能拿到結構化資料(文章、產品、連結等)。
- Crawlbot 與 Knowledge Graph:可爬整個網站,或查詢其龐大的網頁索引。
- API 驅動:可整合 BI 工具或資料管線。
- 企業級定價:約從每月 299 美元起,但你會知道自己買到什麼。
最適合想要乾淨、結構化資料、又不想自己維護爬蟲的企業。
Cheerio:適合 Node.js 的輕量級連結擷取工具
Cheerio 是一個快速、類似 jQuery 的 HTML 解析器,專為 Node.js 設計。
- 超快:HTML 解析只要幾毫秒。
- 語法熟悉:如果你會 jQuery,就會用 Cheerio。
- 很適合靜態頁面:不會渲染 JS,但對伺服器端生成內容非常合適。
- 開源且免費:可搭配 axios 或 fetch 發送請求。
非常適合想兼顧速度與簡潔的開發者,用來撰寫自訂腳本。
Puppeteer:適合進階連結爬取的瀏覽器自動化工具
Puppeteer 是一個 Node.js 函式庫,可用無頭模式控制 Chrome。
- 完整瀏覽器自動化:可載入頁面、點擊、捲動,並像真人一樣互動。
- 支援動態內容與登入流程:非常適合 JavaScript 內容很多的網站或複雜工作流。
- 控制度高:可等待元素、截圖、攔截網路請求。
- 開源且免費:但相對吃資源,而且速度比輕量工具慢。
當你要抓取那些不太配合基本爬蟲的網站時,Puppeteer 就很有用。
一眼比較:哪款連結擷取器最適合你?
以下快速比較這 12 款工具:
| 工具 | 最適合 | 批量與子頁支援 | 資料匯出選項 | 價格 |
|---|---|---|---|---|
| Thunderbit | 不會寫程式的人、商務使用者 | 是(AI、多層級) | Excel、CSV、Sheets、Notion、Airtable | 免費試用,約從每月 $9 起 |
| Octoparse | 無程式碼使用者、分析師 | 是 | CSV、Excel、JSON、雲端儲存 | 免費方案,約每月 $75 起 |
| Apify | 半技術使用者、開發者 | 是 | CSV、JSON、透過 API 匯出到 Sheets | 免費額度,按量計費 |
| Bright Data | 企業 | 是(高流量) | CSV、JSON、NDJSON,透過 API | 約 $350/10 萬頁 |
| WebHarvy | 不會寫程式的人、桌面用戶 | 是 | Excel、CSV、JSON、XML、SQL | 付費授權 |
| Web Scraper Extension | 任何人,快速/免費 | 是 | CSV、XLSX | 免費、開源 |
| ScraperAPI | 開發者、API 使用者 | 是 | JSON(透過 API 回傳 HTML) | 免費 1k 次請求,付費方案 |
| ParseHub | 不會寫程式的人、進階使用者 | 是 | CSV、Excel、JSON、API | 免費 5 個專案,付費方案 |
| Scrapy | 開發者、Python 使用者 | 是 | CSV、JSON、XML、資料庫 | 免費、開源 |
| Diffbot | 企業、AI | 是(AI 爬取) | JSON(透過 API 提供結構化資料) | 約 $299/月以上 |
| Cheerio | 開發者、Node.js | 是(自訂程式) | 自訂(JSON 等) | 免費、開源 |
| Puppeteer | 開發者、複雜網站 | 是(完整自動化) | 自訂(腳本化輸出) | 免費、開源 |
如何為你的企業選對連結爬蟲
那到底該怎麼選?這是我的速查指南:
- 不會寫程式? 先從 Thunderbit、Octoparse、ParseHub、WebHarvy 或 Web Scraper 擴充功能開始。
- 需要自訂工作流程? Apify、ScraperAPI 或 Cheerio 很適合開發者。
- 企業級規模? Bright Data 或 Diffbot 就是為你而生。
- Python 或 Node.js 開發者? Scrapy(Python)或 Cheerio/Puppeteer(Node.js)能給你完整控制權。
- 想直接匯出到 Sheets/Notion? Thunderbit 是最佳選擇。
把工具和你的技術能力、資料量與整合需求對齊即可。多數工具都有免費試用,不妨多試幾款看看。
探索更多網頁爬蟲指南 Get Started Free
Thunderbit 在 2026 年連結擷取上的獨特價值
再回頭看看 Thunderbit 為什麼與眾不同:
- AI 驅動的簡單操作:用白話描述你的需求,剩下的交給 Thunderbit 的 AI。
- 多層級擷取:從主頁抓連結、進入子頁、再抓更多 URL,一次流程完成。
- 批次匯入與批次處理:貼上數百個 URL,批量擷取連結,並立即匯出結構化資料。
- 工作流程整合:可直接匯出到 Google Sheets、Notion、Airtable,或下載成 CSV/Excel。
- 零維護成本:Thunderbit 的 AI 會適應網站變動,你不用一直修復壞掉的爬蟲。
Thunderbit 連接了「只是抓資料」與「真正能拿來用的資料」之間的落差。這是我多年來在手動資料工作中最希望早點擁有的工具。
結論:更聰明地抓取連結,提升你的工作流程
網路資料就是企業成長的燃料,而合適的連結擷取器就是你的引擎。無論你是在建立潛在客戶名單、監控競品,還是自動化研究流程,這裡總有一款工具符合你的需求與技術背景。
如果你想看看現代連結擷取到底是什麼樣子,不妨試試 Thunderbit 的免費方案。我相信你會驚訝於,只要幾下點擊就能完成多少工作。如果 Thunderbit 不是最完美的選擇,也可以試試清單中的其他工具——現在正是把繁瑣工作自動化、把時間留給真正重要事情的最佳時機。
祝你抓取順利,也希望你的連結永遠乾淨、結構清楚、隨時可用。如果你想更深入了解網頁爬蟲,歡迎前往 Thunderbit Blog 參考更多教學與技巧。
免費試用 Thunderbit 連結擷取器 Get Started Free
常見問題
1. 為什麼連結擷取器這麼重要?
如今近一半的網路流量來自機器人,而且企業也在積極擷取資料,因此連結擷取器對於把網路上的混亂資訊轉化為可執行洞察非常關鍵。它能協助自動化潛在客戶開發、內容彙整、SEO 稽核與競品監控等任務,大幅節省時間與人力。
2. Thunderbit 和其他連結擷取器相比,有什麼突出之處?
Thunderbit 用 AI 大幅簡化擷取流程——你只要用自然語言描述目標,剩下的交給它處理。它支援批量 URL 輸入、多層級擷取、智慧欄位辨識,以及無縫匯出到 Google Sheets 和 Notion 等平台。對不想碰技術細節、但又想要強大成果的商務使用者來說,Thunderbit 非常合適。
3. 有適合開發者與自訂工作流程的連結擷取工具嗎?
有。像 Apify、ScraperAPI、Cheerio、Puppeteer 和 Scrapy 都很適合開發者使用。它們提供腳本能力、API 整合,以及處理複雜爬取任務、大規模作業與進階自動化的彈性。
4. 哪些工具最適合沒有程式基礎的使用者?
Thunderbit、Octoparse、ParseHub、WebHarvy,以及 Web Scraper Chrome 擴充功能,都是非技術使用者的優選。這些工具提供視覺化介面、預建模板與 AI 功能,讓每個人都能輕鬆進行連結擷取。
5. 我該如何挑選最適合自己的連結擷取器?
請從你的技術能力、資料量與匯出需求來評估。非程式背景者可選 Thunderbit 或 Octoparse;開發者可能更偏好 Scrapy 或 Puppeteer;企業則可考慮 Bright Data 或 Diffbot 來處理大規模作業。建議先從免費試用開始,看看哪個最符合需求。




